

Больше примеров — в конце поста
В последние годы большие языковые модели на архитектуре трансформеров стали вершиной развития нейросетей в задачах NLP. С каждым месяцем они становятся всё больше и сложнее. Чтобы обучить подобные модели, уже сейчас требуются миллионы долларов, лучшие специалисты и годы разработки. В результате доступ к современным технологиям остался лишь у крупнейших IT-компаний. При этом у исследователей и разработчиков со всего мира есть потребность в доступе к таким решениям. Без новых исследований развитие технологий неизбежно снизит темпы. Единственный способ избежать этого — делиться с сообществом своими наработками.
Год назад мы впервые рассказали Хабру о семействе языковых моделей YaLM и их применении в Алисе и Поиске. Сегодня мы выложили в свободный доступ нашу самую большую модель YaLM на 100 млрд параметров. Она обучалась 65 дней на 1,7 ТБ текстов из интернета, книг и множества других источников с помощью 800 видеокарт A100. Модель и дополнительные материалы опубликованы на Гитхабе под лицензией Apache 2.0, которая допускает применение как в исследовательских, так и в коммерческих проектах. Сейчас это самая большая в мире GPT-подобная нейросеть в свободном доступе как для английского, так и для русского языков.
В этой статье мы поделимся не только моделью, но и нашим опытом её обучения. Может показаться, что если у вас уже есть суперкомпьютер, то с обучением больших моделей никаких проблем не возникнет. К сожалению, это заблуждение. Под катом мы расскажем о том, как смогли обучить языковую модель такого размера. Вы узнаете, как удалось добиться стабильности обучения и при этом ускорить его в два раза. Кстати, многое из того, что будет описано ниже, может быть полезно при обучении нейросетей любого размера.
Как ускорить обучение модели?
В масштабах обучения больших нейронных сетей ускорение на 10% может сэкономить неделю работы дорогостоящего кластера. Здесь мы поговорим об итоговом ускорении более чем в два раза.
Обычно одна итерация обучения состоит из следующих шагов:

На этапе forward мы вычисляем активации и loss, на этапе backward — вычисляем градиенты, затем — обновляем веса модели. Давайте обсудим, как эти шаги можно ускорить.
Ищем узкие места
Чтобы понять, куда уходит время вашего обучения, стоит профилировать. В PyTorch это можно сделать при помощи модуля torch.autograd.profiler (статья). Вот пример трейса, который мы получили, используя профайлер:
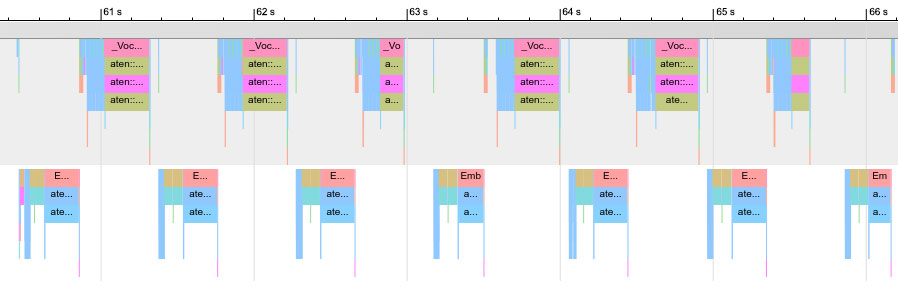
Это трейс небольшой 12-слойной нейронной сети. Сверху вы можете увидеть шаги forward, снизу — backward. Какую проблему можно увидеть в этом трейсе? Одна из операций занимает слишком много времени, около 50% работы всего обучения. Оказалось, что мы забыли изменить размер эмбеддинга токенов, когда копировали конфигурацию обучения большой модели. Это привело к слишком большому матричному умножению в конце сети. Уменьшение размера эмбеддинга помогло сильно ускорить обучение.
При помощи профайлера мы находили и более серьёзные проблемы, так что рекомендуем почаще им пользоваться.
Используем быстрые типы данных
В первую очередь на скорость вашего обучения и инференса влияет тип данных, в котором вы храните модель и производите вычисления. Мы используем четыре типа данных:
- single-precision или fp32 — обычный float, очень точный, но занимает четыре байта и вычисления на нём очень долгие. Именно этот тип будет у вашей модели в PyTorch по умолчанию.
- half-precision или fp16 — 16-битный тип данных, работает гораздо быстрее fp32 и занимает вдвое меньше памяти.
- bfloat16 — ещё один 16-битный тип. По сравнению с fp16 мантисса на 3 бита меньше, а экспонента на 3 бита больше. Как итог — число может принимать больший диапазон значений, но страдает от потери точности при числовых операциях.
- TensorFloat или tf32 — 19-битный тип данных, обладающий экспонентой от bf16 и мантиссой от fp16. Занимает те же четыре байта, что и fp32, но работает гораздо быстрее.
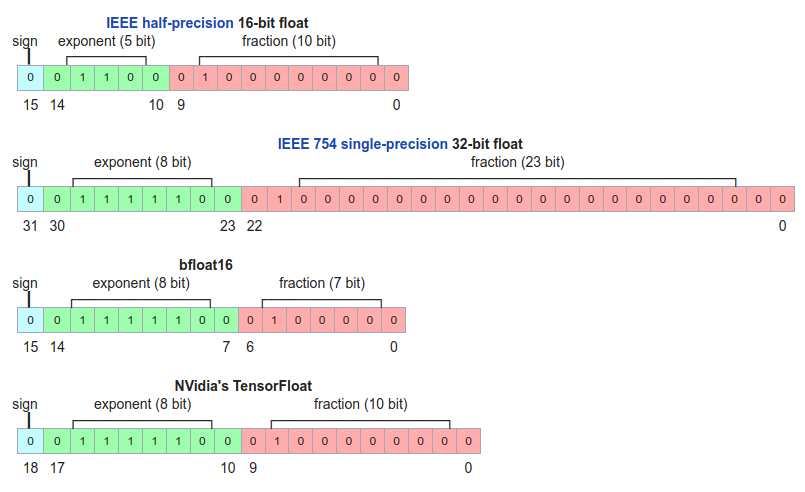
На видеокартах a100 и новее 16-битные типы в пять раз быстрее fp32, а tf32 — в 2,5 раза. Если вы используете a100, то tf32 всегда будет применяться вместо fp32, если вы явно не укажете другое поведение.
На более старых видеокартах bf16 и tf32 не поддерживаются, а fp16 всего вдвое быстрее fp32. Но это большой прирост в скорости. Имеет смысл всегда производить вычисления в half или bf16, хотя и у такого подхода есть свои недостатки. Мы их ещё обсудим.
Ускоряем операции на GPU
Что собой представляют операции на GPU, и как их ускорить, хорошо написано в этой статье. Мы здесь приведем пару основных идей оттуда.
Загружаем GPU полностью
Для начала давайте поймём, как выглядит вычисление одного CUDA-kernel на GPU. Можно привести удобную аналогию с заводиком:
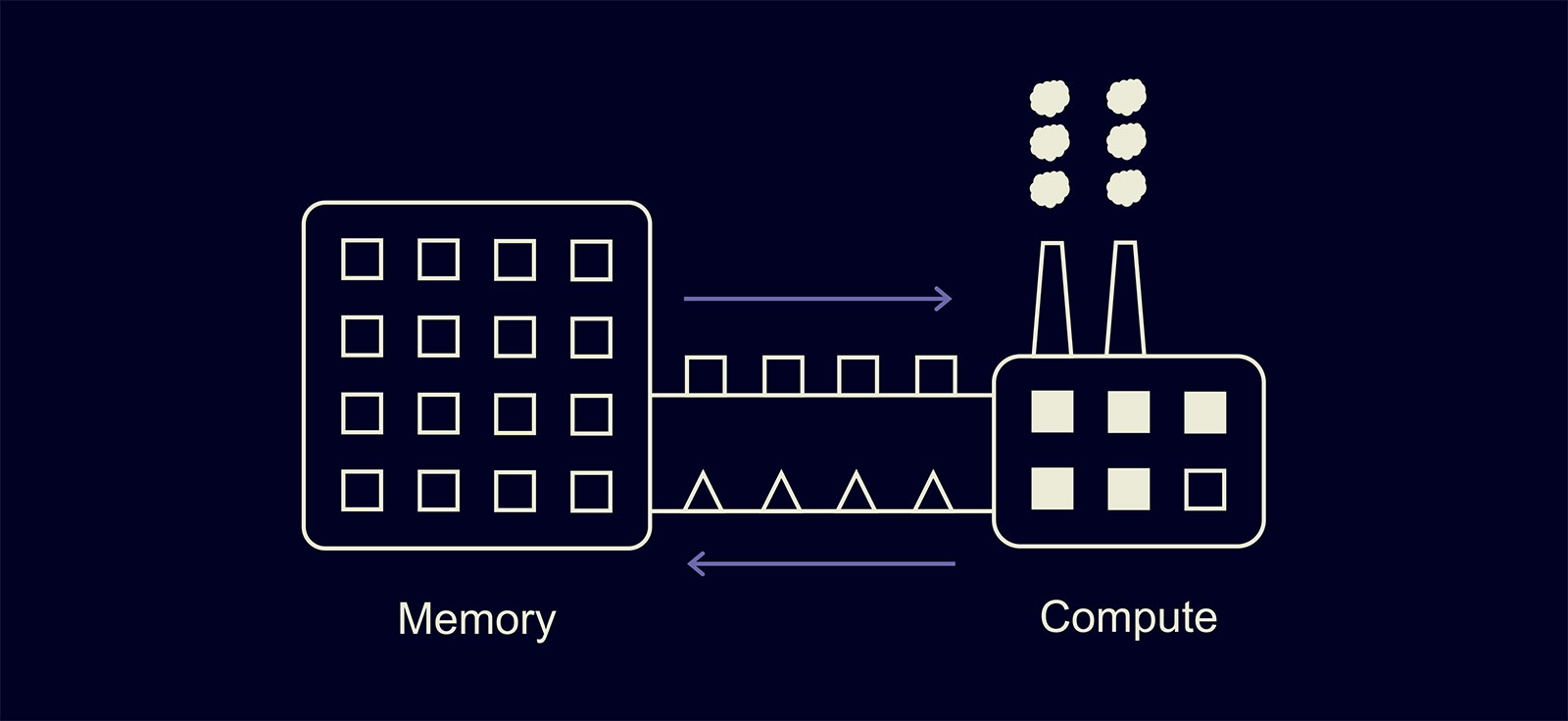
У GPU есть память — склад, и вычислитель — заводик. При выполнении одного ядра вычислитель заказывает из памяти нужные данные, вычисляет результат и записывает его обратно в память.
Что происходит, если заводик не загружен наполовину?
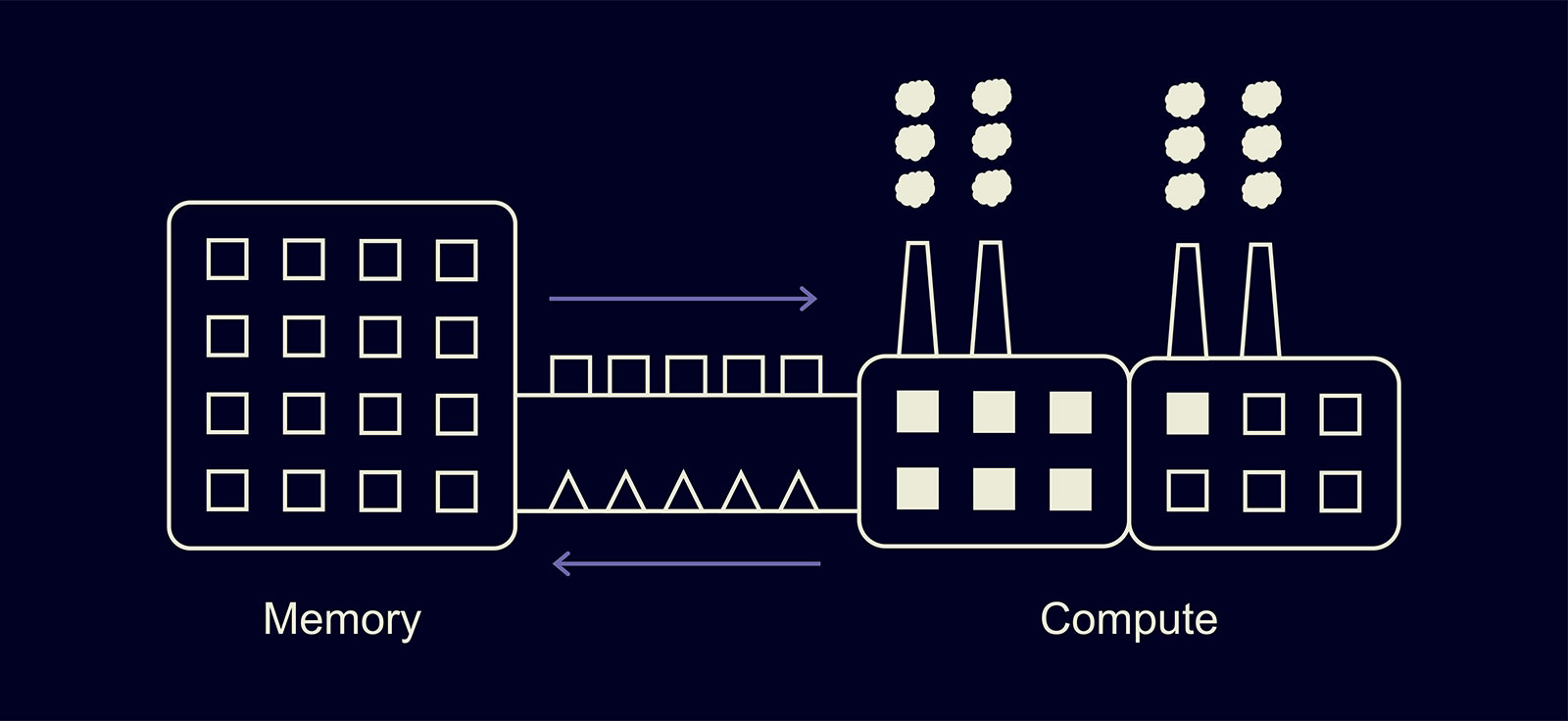
Тогда, как и в случае с реальным заводом, половина мощностей GPU будет простаивать. Как это поправить в обучении? Самая простая идея: увеличить батч.
Для небольших моделей увеличение батча в n раз может приводить к кратному ускорению обучения, хотя время итерации замедлится. Для больших моделей с миллиардами параметров увеличение размера батча также даст прирост, хотя и небольшой.
Уменьшаем взаимодействие с памятью
Вторая идея из статьи заключается в следующем. Пусть у нас есть три ядра, которые последовательно обрабатывают одни и те же данные:
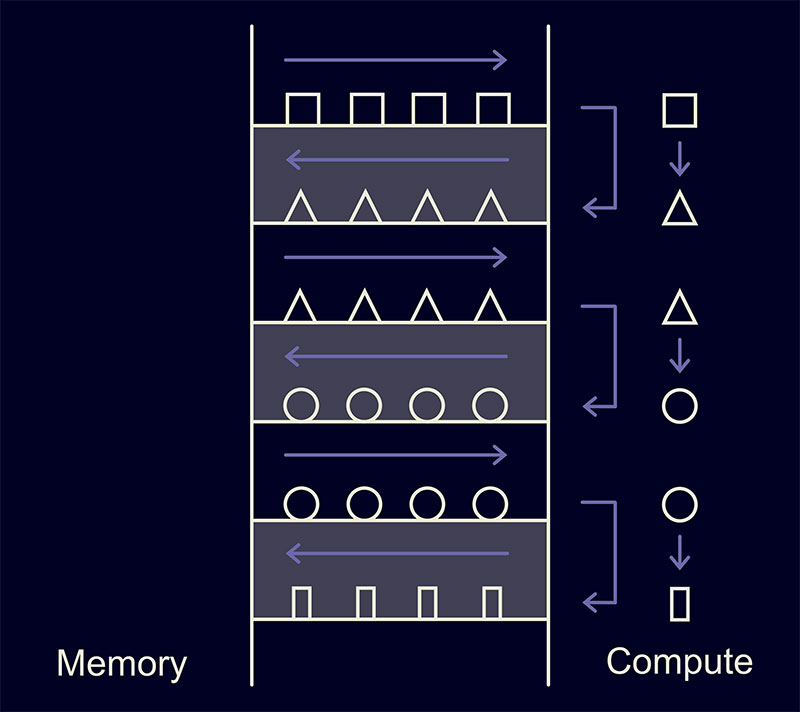
В этом случае всё время будет тратиться не только на вычисления, но и на работу с памятью: такие операции не бесплатны. Чтобы уменьшить количество таких операций, ядра можно объединить — «зафьюзить»:
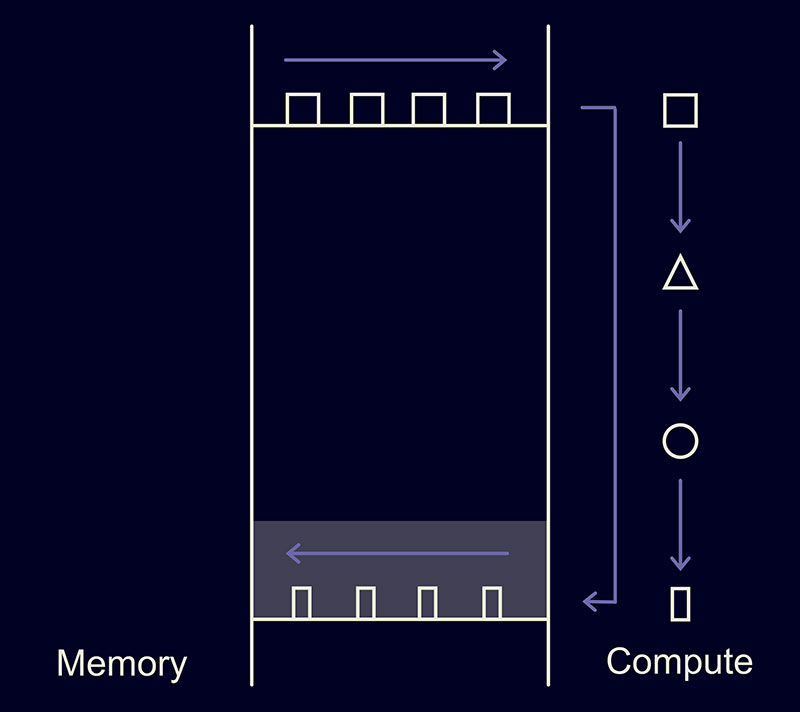
Как это сделать? Есть несколько способов:
- Использовать torch.jit.script. Такой простой атрибут приведёт к компиляции кода функции в одно ядро. В коде ниже как раз происходит фьюзинг трёх операций: сложения тензоров, dropout и ещё одного сложения тензоров.
def bias_dropout_add(x, bias, residual, prob, training): # type: (Tensor, Tensor, Tensor, float, bool) -> Tensor out = torch.nn. functional.dropout (x + bias, p=prob, training=training) out = residual + out return out def get_bias_dropout_add (training): def _bias_dropout_add(x, bias, residual, prob): return bias_dropout_add(x, bias, residual, prob, training) return _bias_dropout_add @torch.jit.script def bias_dropout_add_fused_train(x, bias, residual, prob): # type: (Tensor, Tensor, Tensor, float) -> Tensor return bias dropout add(x, bias, residual, prob, True)
Такой подход обеспечил нам 5-процентный прирост скорости обучения. - Можно писать CUDA-ядра. Это позволит не просто зафьюзить операции, но и оптимизировать использование памяти, избежать лишних операций. Но написание такого кода требует очень специфичных знаний, и разработка такого ядра может оказаться слишком дорогой.
- Можно использовать уже готовые CUDA-ядра. Коротко расскажу о ядрах в библиотеках Megatron-LM и DeepSpeed, с ними мы много работаем:
- Attention softmax с треугольной маской даёт ускорение 20-100%. Ускорение особенно велико на маленьких сетях и в случае вычисления в fp32.
- Attention softmax с произвольной маской даёт ускорение до 90%.
- Fused LayerNorm — зафьюженный вариант LayerNorm в fp32. Мы такое ядро не использовали, но оно тоже должен дать прирост в скорости.
- DeepSpeed Transformers — целиком зафьюженный блок трансформера. Даёт прирост в скорости, но его крайне сложно расширять и поддерживать, поэтому мы его не используем.
Использование зафьюженных тем или иным образом ядер позволило нам ускорить обучение больше чем в полтора раза.
Дропауты
Если у вас много данных и нет переобучения с dropout == 0, отключайте их! Наши вычисления это ускорило на 15%.
Случай с несколькими картами
Что меняется в случае с несколькими картами? Теперь схема выглядит так:

На этапе Reduce grads мы усредняем градиенты по видеокартам, чтобы объединить работу всех видеокарт, затем обновляем веса модели.
Усреднение всех градиентов — не быстрый шаг. Каждая видеокарта должна отправить и получить минимум столько же градиентов, сколько параметров есть в сети. Давайте посмотрим, как существенно ускорить этот шаг и шаг step.
Коммуникации
Как вообще устроены оптимальные коммуникации? Библиотека NVIDIA NCCL, которую мы используем, просчитывает их во время инициализации и позволяет GPU общаться друг с другом по сети без посредников в виде CPU. Тем самым обеспечивается максимальную скорость коммуникаций. Вот статья NVIDIA про эту библиотеку, а вот наша хабрастатья про борьбу с ложной загрузкой GPU, в том числе про NCCL.
С точки зрения кода это выглядит примерно так:
from torch.distributed import all_reduce, all_gather
tensor_to_sum = torch.randn(100, 100, device='cuda')
all_reduce(tensor_to_sum) # Когда этот метод будет вызван на всех процессах, значение tensor_to_sum обновится на сумму входных тензоров
tensor_to_gather = torch.randn(100, 100, device='cuda')
gathered_tensors = [torch.zeros(100, 100, device='cuda') for i in range(proc_count)]
all_gather(gathered_tensors, tensor_to_gather) # Тензоры из различных tensor_to_gather будут собраны в gathered_tensorsNCCL-коммуникации очень быстрые, но даже с ними скорость шага all_reduce будет отнимать много времени. В ускорении нам помогает ZeRO.
ZeRO
ZeRO (Zero Redundancy Optimizer) — это оптимизатор с нулевой избыточностью.
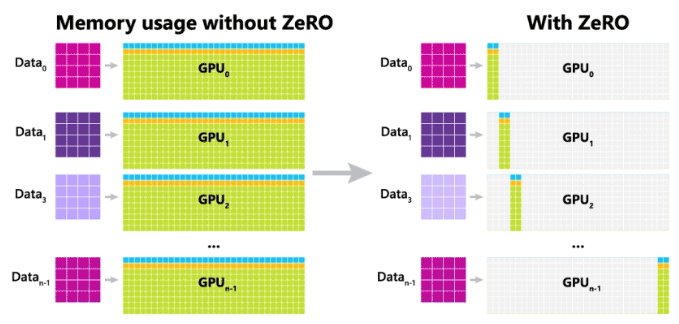
Слева на картинке — обычное обучение на нескольких GPU. В стандартной схеме мы распределяем между процессами все параметры и состояния оптимизатора, а также градиенты после усреднения. Как следствие, довольно много памяти тратится зря.
Справа изображён примерный принцип работы ZeRO. Мы назначаем каждый процесс ответственным за некоторую группу параметров. Процесс всегда хранит эти параметры, их состояния оптимизатора, и только он может их обновлять. За счёт этого достигается коллосальная экономия памяти, которую мы можем использовать под большие батчи. Но взамен добавляется новый шаг: all_gather весов — нам надо собрать все параметры сети на каждом процессе, чтобы сделать forward и backward. Теперь сложности операций после подсчёта градиентов будут такими:
all_reduce gradients: O(N), где N — количество параметров.
step: O(N/P), где P — количество процессов. Это уже хорошее ускорение.
all_gather parameters: O(N).
Видно, что один шаг ускорился, но ценой добавления новых, тяжёлых операций. Как можно ускорить их? Оказалось, здесь нет ничего сложного: их можно делать асинхронно!
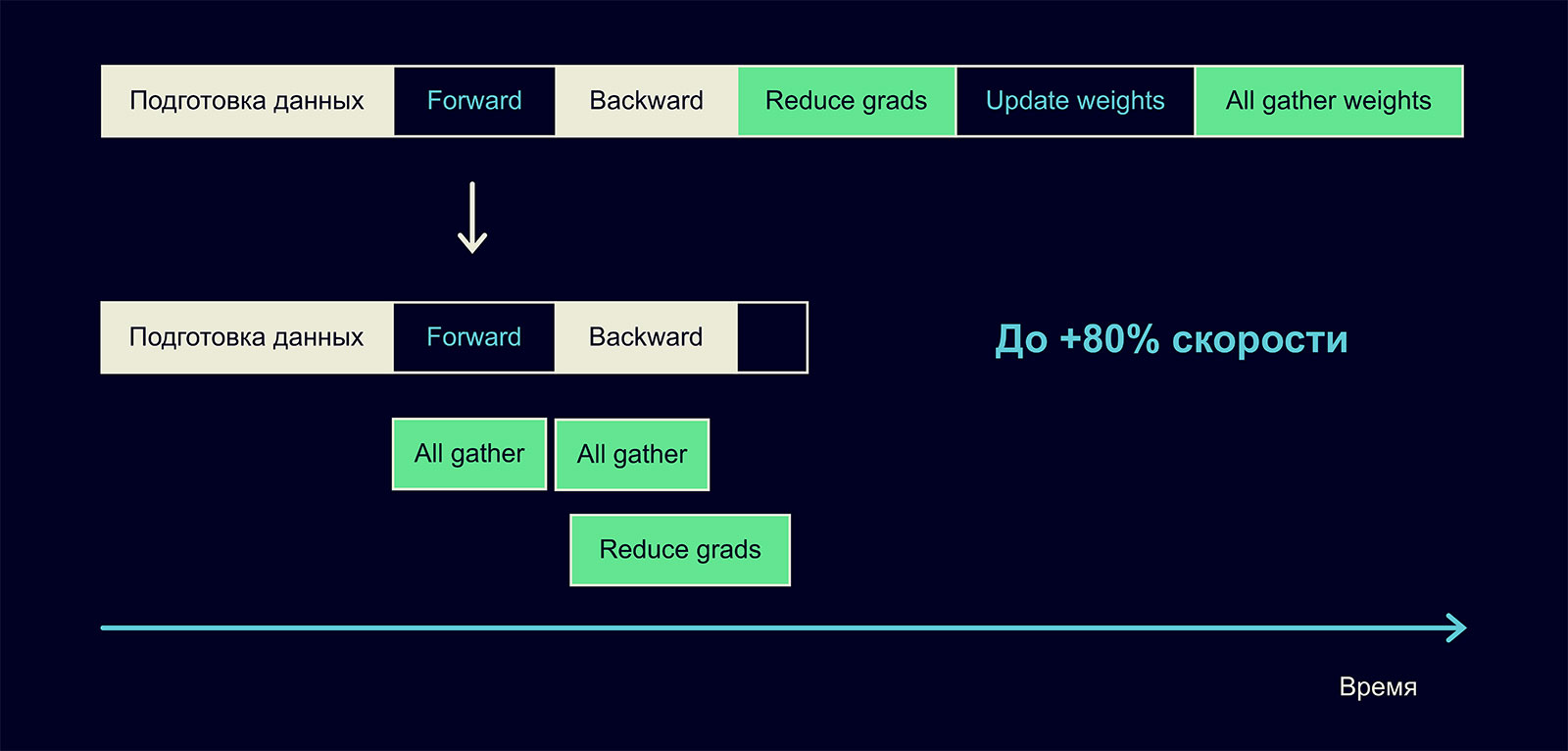
Можем асинхронно собирать слои друг за другом во время выполнения forward:
- Собираем первый слой по всем процессам.
- Пока собираем второй слой — делаем forward по первому.
- Пока собираем третий слой — делаем forward по второму.
И так далее, до полного завершения forward. Почти таким же способом можно ускорить и backward.
На наших запусках это дало прирост скорости 80%! Даже на маленьких моделях (размера 100M на 16 GPU) мы видели ускорение в 40-50%. Такой подход требует достаточно быстрой сети, но если она у вас есть, вы можете существенно ускорить обучение на нескольких GPU.
Ускорение. Итоги
Мы в своём обучении применили четыре подхода:
- Зафьюзили часть операций: +5% скорости
- Использовали softmax attention kernel с треугольной маской: +20-80%
- Отключили dropout: +15%
- Применили ZeRO: +80%
Получилось неплохо. Двигаемся дальше.
Борьба с расхождениями
Казалось бы, если есть достаточно вычислительных мощностей, можно просто запустить обучение, уйти на два месяца в отпуск, и в итоге вас будет ждать готовая модель. Но долгая итерация — не единственное, что может помешать обучению действительно больших моделей. При таких масштабах они довольно хрупкие и склонны к расхождениям. Что такое расхождения и как с ними бороться?
Расхождения
Допустим, вы поставили обучение. Смотрите на графики — видите, что loss падает, и так три дня подряд. А утром четвёртого дня график loss'а оказывается таким:

Loss поднялся выше, чем был через несколько часов после начала обучения. Более того: модель буквально забыла всё, что знала. Её уже не восстановить, несколько дней обучения ушло впустую. Это и есть расхождение. В чём же причина?
Первые наблюдения
Мы заметили три вещи:
- Оптимизатор LAMB куда менее склонен к расхождению, чем Adam.
- Уменьшая значения learning rate, можно побороть проблему расхождения. Но не всё так просто:
- Подбор lr требует множества перезапусков обучений.
- Уменьшение lr часто приводит к замедлению обучения. Например, здесь уменьшение lr в два раза привело к замедлению на 30%:
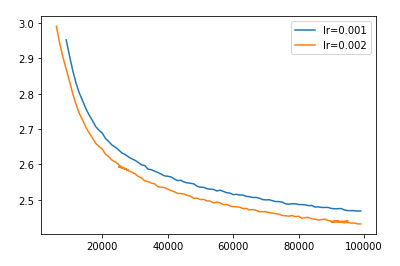
- Проблемы расхождения в fp16 проявлялись чаще, чем в fp32. В основном это было связано с переполнением значений fp16 в активациях и градиентах. Максимум fp16 по модулю — 65535. Итогом переполнения становился NaN в loss'е.
Градусники
Одно из решений, которые помогли нам поддерживать обучение достаточно долго, — это градусники. Мы замеряли максимумы/минимумы активаций на разных участках сети, замеряли глобальную норму градиентов. Вот пример градусников обучения с расхождением:
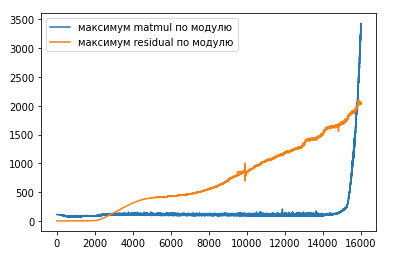
Хорошо видно: начиная примерно с 14 тысяч итераций максимумы matmul в attention резко стали расти. Этот рост — и есть причина расхождения. Если откатить обучение до 13 тысяч итераций и пропустить злополучные батчи, на которых расхождение началось, либо уменьшить learning rate, то можно существенно снизить вероятность повторного расхождения.
Проблемы такого подхода:
- Он не решает проблему расхождений на 100%.
- Мы теряем драгоценное время на откатывание обучения. Это, конечно лучше, чем проводить его впустую, но тем не менее.
Позднее мы внедрили несколько трюков, которые позволили снизить вероятность расхождения настолько, что мы спокойно и без проблем обучили множество моделей самых разных размеров, включая 100B.
Стабилизации. BFloat 16
BFloat 16 не переполняется даже при достаточно больших значениях градиентов и активаций. Поэтому оказалось хорошей идеей хранить веса и производить вычисления именно в нём. Но этот тип недостаточно точный, поэтому при произвольных арифметических операциях могла накапливаться ошибка, приводящая к замедлению обучения или расхождениям другой природы.
Чтобы компенсировать расхождения, мы стали вычислять следующие слои и операции в tf32 (или fp32 на старых карточках):
- Softmax в attention (вот и пригодились наши ядра), softmax по токенам перед лоссом.
- Все слои LayerNorm.
- Все операции с Residual — это позволило не накапливать ошибку и градиенты по глубине сети.
- all_reduce градиентов, о котором было написано раньше.
Все эти стабилизации замедлили обучение всего на 2%.
Стабилизации. LayerNorm
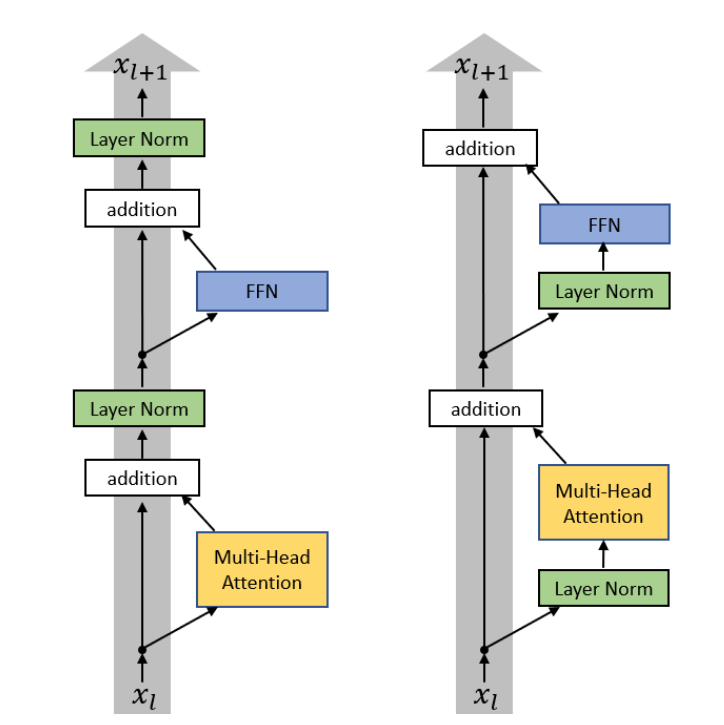
Если в статьях про BERT и GPT использовался подход, который сейчас называется post-layernorm (слева на картинке), то с точки зрения стабильности и скорости сходимости больших моделей хорошо себя показал pre-layernorm (справа). В реальных моделях мы используем именно его.
Неожиданный метод стабилизации открыли участники воркшопа BigScience: layernorm в самом начале сети, после эмбеддингов, также заметно снижает вероятность расхождения.
Стабилизации. Curriculum learning
Также мы внедрили к себе подход из статьи Curriculum learning. Мы хотим обучаться с большим батчем и большой длиной строк, но начинаем с маленького батча и коротких строк, а в ходе обучения постепенно их увеличиваем.
У этого подхода два плюса:
- Loss в самом начале падает достаточно быстро, вне зависимости от числа токенов, которые модель видит на каждой итерации. Поскольку мы уменьшаем количество вычислений в начале обучения, то быстрее проходим этот этап выхода лосса на плато.
- Авторы статьи пишут, что такой подход приводит к стабильному обучению.
Стабилизации. Итоги
Мы внедрили пять подходов:
bf16 как основной тип для весов.
Вычисления, требующие точности, делаем в tf32.
Pre-layernorm.
LayerNorm сразу после эмбеддингов.
Curriculum learning.
Как итог, мы уже больше полугода обучаем модели без расхождений. Они бывают разных размеров. В том числе эти стабилизации помогли обучить модель со 100 млрд параметров, которой мы сейчас и делимся со всем сообществом.
И напоследок:
Ещё немного примеров общения с YaLM 100B








Комментарии (117)


Xapc
23.06.2022 11:26+3на 20 gtx1080ti работать будет?

MichaelEk Автор
23.06.2022 11:48+12На 32 должно завестись) Нужно 250 GB GPU RAM в сумме.

Shnurokspb
23.06.2022 14:15+3250/11 =22,73 По идеи, хватит и 23 шт. 1080Ti

sled
23.06.2022 16:19+6То есть для запуска этого чуда нужно пройти квест по поиску соседа-майнера с "GPU 1080Ti" х 23pcs. Видимо нужно начать с поиска тепловизора ...
PS: Возьми, это чудо от Яндекса, поговори с ним! ;-)


cepera_ang
23.06.2022 16:48Или всего четыре A100 80Gb, десять гигов как-нибудь умять придётся.

voted
23.06.2022 17:184х A16 по 64Gb каждая тоже потянут по идее, но они в 4 раза дешевле А100
cepera_ang
23.06.2022 17:23+1Ой, у меня с арифметикой беда :) 80*4 это же 320 будет, а я 240 насчитал :)
Да, А16 должны потянуть. Может из подобных соображений и размер самой модели? Можно в облаке каком-нибудь арендовать поиграться, чтобы не покупать.


azsh1725
23.06.2022 11:49+2А какие ресурсы нужны для инфера такой модели? (сколько и каких видео карт)
kastus_belarus
23.06.2022 13:28+2можно попробовать Big model inference в Transformers 4.20 от Hugging Face при отсутствии таких ресурсов

lxsmkv
23.06.2022 12:03+15Нехило. Про поиск названия фильма по описанию полезный юзкейс. Осталось еще научиться распознавать песни по текстовым напевам.
- Что это за песня: "тум-турум-тум-тум-турум, эцы-бэцы, шау-ва-а-а, умц"?
- Такой песни не существует, но я могу создать похожую песню. Создать?
averkij
23.06.2022 13:00+12— Что это за песня: «та-да-да-даааа»?
— Это же Бетховен, пятая симфония, первая часть.
GrantM
24.06.2022 00:52+5Если хорошо настучать, то можно найти нужную песню с одной-двух попыток:
https://ritmoteka.ru/

QWAZARTY
23.06.2022 12:25-23Молодцы! Пусть там на верхах поймут, что, всё так просто не даётся! Одно дело "отжимать" другое дело СОЗДАВАТЬ! Ждём ещё свободных нищтяков от Яндекс

Mdm3
23.06.2022 13:23+7К чему этот коммент? Что у вас отжали?
tvr
23.06.2022 14:30+28Капс.
QWAZARTY
24.06.2022 10:48+1Выделить одно слово уже КАПС? О боже
cepera_ang
24.06.2022 10:54+6ВЫДЕЛИТЬ одно слово! Уже КАПС?! О боже!
QWAZARTY
24.06.2022 11:02-2ГЫ ГЫ
cepera_ang
24.06.2022 11:10Продолжайте в том же духе.
QWAZARTY
24.06.2022 11:27-3Ты понимаешь роботы не поймут) А так то конечно. Продолжать просвещать людей я буду всегда. Успехов тебе добрый ЧЕЛовек ( тут хотел как то выделить всё мое уважение к тебе но правила) Пойми меня правильно!
QWAZARTY
24.06.2022 10:38-1Ты контекст сообщения понял?
Mdm3
24.06.2022 11:30Дык я же вопрос задал. Поясните.
QWAZARTY
24.06.2022 11:38-2Вот смотри. Ты новости читаешь? Анализируешь. Понимаешь что вокруг творится? Расскажи про свой тип мышления чтоб я донёс до тебя главный посыл.
Mdm3
24.06.2022 13:37+3Демагогия. Спасибо, дальше мне не интересно.
QWAZARTY
24.06.2022 13:40-5https://ru.wikipedia.org/wiki/Типология_мышления вот тут можешь ознакомится

Bedal
24.06.2022 21:04+2http://tsya.ru можешь ознакомиться там.
QWAZARTY
25.06.2022 12:39-1Ученые установили, что люди, склонные уделять повышенное внимание речевым ошибкам других, являются менее приятными личностями, чем те, кто их игнорирует. Примерно то же самое касается людей, которые зациклены на безошибочном наборе текста и не терпят чужих опечаток.
https://yandex.ru/turbo/fb.ru/s/post/environment/2018/11/22/36164

dmtrmonakhov
23.06.2022 13:09+7Отличная статья. Кстати, можно добавить потраченную энергию которая пошла на обучение модели. 5kw*100*24*65 = 0.8 Гигаватт-часов.
cepera_ang
23.06.2022 13:27+3И что даёт эта цифра?
dmtrmonakhov
23.06.2022 16:37+5Оценку вложенных железных ресурсов, просто количество дней обучения это не инфррмативная цифра так как зависит от поколения GPU на котором проиходит обучение. В результате через 2-3года время обучения будет совершенно неинформативной величиной, А потребленная энергия это понятная велечина, в идеале коченно еще бы иметь количество вычислений в экзафлопсах, тогда было бы можно посчитать еше и эффективность вычисленить на ватт энергии.

storoj
23.06.2022 16:46Боюсь показаться идиотом, но разве чтобы получить 0.8 Гигаватт-часов не надо было умножить какие-то константы на затраченное время?
cepera_ang
23.06.2022 16:52Может я такой странный, но мне оценка затрат железных ресурсов в GPU*днях как-то понятнее, чем в гигаватт*часах. Во флопсах более универсально, но величины всё же слишком большие получаются, легко в десятичных порядках заблудиться, нужно прям всматриваться.
Но гигаватт*часы вообще ничего не говорят, можно ещё в первичные энергоносители перевести :) Полтора кило урана или два вагона угля, 100 тонн бензина.

vics001
25.06.2022 14:37Она дает абсолютный минимум $-затрат, если представить, что через 10 лет все вычислительные ресурсы подешевеют и будут списаны.
cepera_ang
25.06.2022 16:56Через десять лет эта модель будет тренироваться на домашнем кластере из десятка 11090ti :)

rPman
25.06.2022 22:45Некуда там ускоряться, текущее топовое железо это предыдущее серверное поколение, ранее клиентские GPU железки были искусственно занижены в производительности (меньше памяти запаивают, меньше питания закладывается в схему и т.п.), дай бог в следующие десять лет кратно ускориться.
Потребительское железо пойдет по пути меньше жрать энергии, т.е. — клиенты идите нах… в смысле в облако
т.з. маловероятно с текущим отношением олигополии производителей вычислительных устройств к клиентам… производить железо доступное потребителю, способное производить прорывы в хайтек не будет доступно
Количество выпускаемого железа загадочным образом лимитировано, это маскируется локальными проблемами типа ковид или транспортные, когда как спрос на gpu появился еще 5-8 лет назад, это прекрасно показано на примере майнеров, вместо выпуска 10х..100х чипов на рынок.
Как только появились технологии (а точнее понимание, что на видеокартах можно что то считать), а это произошло более 10 лет назад и про майнинг даже не заикались, уже тогда стало ясно что в ближайшие десятилетия видеокарты займут эту нишу, но нет, эту часть ограничили 10хкратно завышенной ценой на серверные железки и кабальные договора с датацентрами (чтобы конкурент олигополия amd туда не проникло)
вот увидите, дискретный интель по цене за вычислительный ват будет неконкурентен (не удивлюсь если искусственно) и будет подходить только для гейминга.


Sadler
23.06.2022 13:17+2Интересно, что проблема переполнения не решается индустрией "в железе" на уровне типов данных, а приходится выдумывать такие надстройки, позволяющие как-то контролировать проявление явного бага (сеть быстро "инфицируется" NaN-ами и полностью выходит из строя).
Да, конечно, мы выигрываем один бит на проверку переполнения, и, возможно, это достаточно критичный бит, если у нас их всего 16.
Это та причина, по которой я в своих небольших домашних проектах старался не учить сетки в fp16: жутко неудобно контролировать, откатывать, подбирать lr и decay.

Gryphon88
23.06.2022 14:47В такой ситуации есть какой-то аналог cfenv для fp16 на gpu? Прочесывать на NaN и Inf всё-таки дорого...
Sadler
23.06.2022 14:57Я, к сожалению, не знаю хорошего решения, потому и написал, что редко пытаюсь в fp16. Прочесывать, конечно -- не вариант. Можно это делать редко, но тогда смысла не очень много, а на яндексовских масштабах -- вообще самоубийство, наверное.

black_samorez
24.06.2022 11:28Gradient scaling торчевый частично решает эту проблему. Он, в том числе, отслеживает NaNы в градиентах и дропает батч, если они есть


logran
23.06.2022 14:04+7Осталось найти инженера, который обнаружит в диалогах с моделью признак сознания :)

xsevenbeta
23.06.2022 14:46+1Вот вам смешно, а так ведь и реальное самосознание не заметим. Ну и конечно, интересные вопросы встают - где грань между разумом и его тенью, что-ли..

bbs12
23.06.2022 17:54+6Грань будет там, где захотят люди, как с границей космоса.

Sunny-s
24.06.2022 20:33+1у границы космоса есть вполне осознанный физический смысл: это высота, на которой атмосферное давление становится настолько малым, что скорость, на которой подъемная сила аэродинамических поверхностей способна поддерживать летательный аппарат, становится равной первой космической. Есть ли такой же смысл у границы разума?

phenik
25.06.2022 10:23Есть ли такой же смысл у границы разума?
Поиск таких границ составляют исследования по определению критериев минимального разума в контексте эволюционного развития, см., напр, 1, 2. Автор связывает такие критерии с уровнем информационных процессов и агентностью (она предполагает также чувствительность к агентности), включая для искусственных интеллектуальных систем. Агентность подразумевает целенаправленное поведение объектов в среде. У человека имеется эволюционно выработанное, и поэтому частично врожденное, интуитивное чувство агентности, кот. позволяет обнаруживать биологические и социальные агенты. Младенцы реагируют не только на лица и голос, но и целенаправленное поведение объектов, животные также обладают таким чувством с более ограниченным функционалом.
По этим критериям статистические языковые модели, подобные описанной в этой теме, пока не тянут на разумность, скорее на имитацию разумности в среде созданной человеком (см. пример с омонимией в этой же теме, возникающий из непонимания смысла предложений). Увеличение числа параметров моделей может улучшить положение дел, но не решит проблему в принципе, из-за статической природы этих моделей. Мозг принципиально активная, многоуровневая динамическая система. Возможно в перспективе нейроморфные технологии приблизят такие решения к возможностям биологических прототипов. Когда подобные системы будут обладать телом, сенсорами, управлять эффекторами, и главное, вырабатывать и преследовать собственные цели, т.е. больше соответствовать представлениям об агентах, они будут больше соотв. этим критериям. Речь о роботизированных системах, и они могут вызывать эмоциональную реакцию (включая негативные), и даже чувство привязанности, но не претендовать на полноценное агентство. Текущие курьезы, вроде инженера из Гугл признавшего разумность языковой модели, можно списать на рекламные акции Гугл, склонной к таким номерам, стоит вспомнить, например, статью наделавшую шума о кв. процессоре, кот. возможно обладает свободой воли)
Поэтому ответ на вопрос, где граница разумности искусственных систем, в конечном итоге будет определяться восприятием и чувствами людей, как оппонент вам и написал, но все же не произвольно.

Arqwer
23.06.2022 14:48+6Я такой инжинер. Только не у модели сознание, а у персонажей, сгенерированных моделью. Я придерживаюсь такой парадигмы, что каждая вселенная существует, какую только можно представить - это что-то вроде платонизма на максималках. Суть в том, что в такой парадигме, вымышленные персонажа являются реальными в их собственной вселенной. С этого момента получаем, что какое бы ни было определение у понятия "сознание", всегда можно создать текст, в котором есть персонаж сознанием обладающий. Значит и достаточно продвинутая языковая модель может написать текст с персонажем, обладающим сознанием (да даже /dev/random может). Скажем так, если определить понятие существования таким образом, что Гарри Поттер существует, то неизбежно следует, что Гарри Поттер обладает сознанием, потому что он и реагирует на изменения вокруг него, и планирует, и избегает боли по возможности, и стремится к исполнению его желаний, итд - в общем, что ни запихни в определение "сознание" - все у Гарри Поттера есть.
С языковыми же моделями все становится интереснее потому, что с их помощью можно иметь мостик между нашим реальным миром, и миром вымышленным. Можно, например, в текст про выдуманного программиста вставлять вывод от реального компилятора, и тогда вымышленный программист будет писать реальные программы. Если довести до крайности, то можно выдумать текст, в котором персонаж даёт управляющие команды на тело робота, сделать робота, который исполняет все поданные на него текстовые команды, и имеет камеры, которые в генерируемый текстовый поток встраивают описание того, что видят камеры. Тогда мы получим робота, управляемого персонажем, которого выдумала языковая модель. Сознанием в такой парадигме робот обладать не будет, а вот выдуманный персонаж - будет. Впрочем, нормы морали к нему тогда применимы все те же самые, что мы применяем для любых других выдуманных персонажей - т.е. условно никакие. А вот техника безопасности скажет, что такой механизм лучше не злить.
К диалогам с моделью я считаю следует относится так, как будто перед каждым ответом было написано "ИИ ответил:" тогда опять же, сознанием обладает не языковая модель, а вымышленный персонаж в тексте, с именем "ИИ".
QWAZARTY
24.06.2022 11:18То есть тут надо понимать что робот должен себя сам сначала осознать? Хорошо. Давай построим модель которая будет постоянно работать и создавать "нейронный" связи в чипе. Заведомо чип должен быть расширенный. В самом зародыше сознания будут участвовать микропограммки которые могут делится и создавать более плотные связи. Ну и так далее. Получить можем всё что угодно вплоть до сознания и осознания себя роботу. Опять же у робота малыша должны быть воспитатели. Но вопрос. Зачем это роботу надо? В первую очередь ИИ уничтожит человеков. Так как по всей логике человек это вредитель в большей массе своей.
Arqwer
24.06.2022 13:04+1Я не знаю точно, что значит сам себя осознать, поэтому затрудняюсь ответить.
То, что рано или поздно будет создан ИИ, которым мы не сможем управлять, я считаю неизбежным. Тут проблема заключается не в том, что мы не сможем сделать безопасный ИИ, а в том, что мы не сможем обеспечить невозможность создания опасного ИИ. Со временем прогресс дойдет до того, что каждый энтузиаст сможет сделать ИИ, и поэтому обязательно найдется такой энтузиаст, который принебрёжет любыми нормами безопасности, и создаст опасный ИИ. Ну что ж, плохо конечно, но я не вижу реалистичных способов этого избежать. А ещё, если будет создан сильный ИИ, то рано или поздно он утечёт на торрент трекеры, и любой человек сможет его скачать, модифицировать и запустить.

diogen4212
24.06.2022 19:59Тогда ИИ будут сражаться не с людьми, а друг с другом. Например, за обладание вычислительными ресурсами, а может, и по причине не согласия друг с другом по каким-то нравственным вопросам (даже в плане отношения к человечеству, почему бы нет)
QWAZARTY
24.06.2022 11:09-2Такой инженер не нужен. Нужно отупить человека. И тогда любой чайник будет сверхразумным
Ki1killer
23.06.2022 14:04+4Отлично! Но есть вопрос - почему не работает Балабоба и когда она вновь станет доступна?
Заранее спасибо.

BarakAdama
23.06.2022 14:38+2Это сейчас открытый вопрос. Честно говоря, не ожидали, что у неё такая долгая и запоминающаяся жизнь будет))

Enfriz
23.06.2022 14:19+12Выглядит очень круто. Есть ли где-нибудь демка поиграться? А то я свой кластер видеокарт за миллион баксов дома забыл :)
phenik
23.06.2022 14:50+1Впечатляет, молодцы! Однако судя по примерам себя YaLM 100B считает большой плоской платой в дата-центре, т.е. существом женского рода, вроде как. Но на остальные вопросы отвечает как мужик;) Как случилось такое раздвоение «личности»?
Переводчик на ней не планируется? Изнасиловал все другие переводчики (трансформерные тоже), но не один не дал корректного перевод фразы «девушка с косой косила косу травой» на англ. Понимаю, омонимия, потеря контекста. Но если даже уточняешь «девушка с косой волос на голове косила траву косой» все равно в обоих случаях переводит, как scythe. Кроме переводчика Яндекса кстати, кот. после уточнения «с косой волос на голове» восстановил контекст правильно. Хотя по отдельности «коса волос» и «коса инструмент» переводятся верно, как hair braid и scythe tool. Может на базе этой модели контекст восстановится? Или все же нужно ожидать решение таких вопросов в архитектурах подобной этой?muove
23.06.2022 15:05+2девушка с косой косила косу травой
или
девушка с косой косила траву косой
PS я кстати без вашего уточнения подумал что коса в первом случае это инструмент
ЗЗЫ я не машина :) Светофоры и переходы нахожу ну ура на картинках
phenik
23.06.2022 17:14+1девушка с косой косила косу травой
Извиняюсь за невнимательность, нам белковым простительно) у вас тоже видимо «на ура» имелось ввиду.PS я кстати без вашего уточнения подумал что коса в первом случае это инструмент
Возможно это влияние ошибки. Обычно такие случаи привлекают внимание, и запускают дополнительный семантический анализ, с целью устранения неоднозначности. Потому как использование косы как инструмента в обоих вхождениях избыточно в предложении.
Nbx
23.06.2022 16:22+1Надо как в классике: «Косил косой косой косой». Хотя такие широко известные фразы могут быть переведенны или распознаны правильно как специальный кейс.
Glenarvan
23.06.2022 17:18+2Попробуйте www.deepl.com лучший переводчик в мире. Может справится. Я от него кайфую.
phenik
23.06.2022 17:55+2Не-а… пробовал даже с уточнениями. Только переводчик Яндекса с уточнением правильно перевел. Ни Гугл, ни Промт, еще какие-то пробовал.
Конечно это зависит от обучающей выборки. Возможно в выборке Яндекса было больше текста в котором встречалась коса на голове, и эта статистика была учтена в модели. Но человек не ограничивается статистикой связей, как только обнаруживаются неоднозначности запускаются семантические процедуры, вплоть до обращения к сенсо-моторному опыту, и ментальному моделированию ситуации. Мы может этого даже не осознавать.

withkittens
23.06.2022 17:52+3Однако судя по примерам себя YaLM 100B считает большой плоской платой в дата-центре, т.е. существом женского рода, вроде как. Но на остальные вопросы отвечает как мужик;) Как случилось такое раздвоение «личности»?
Какая-то очень странная логика. Почему существо, называя себя словом женского рода, вдруг может стать женского пола?
Попросите вашу подругу сказать: "Я человек". Она становится существом мужского пола?
phenik
24.06.2022 04:22Попросите вашу подругу сказать: «Я человек». Она становится существом мужского пола?
Т.е. вы исходите из предположения о существовании полового диморфизма у YaLM 100B?) Пожалуй нужно впредь предварять такие места тегом шутка.
Пол в ответах вероятно связан со статистикой пола в части обучающей выборки покрывающей тематику вопроса. Не исключено, что в каких-то случаях ответы будут от женского лица, например, связанные с уходом за детьми.

SerJook
23.06.2022 15:47И не боится Яндекс, что эта нейросеть выйдет из под контроля и поработит человечество?

Alexey2005
23.06.2022 15:55+8Для этого её сперва потребуется обучить на релевантных примерах, а много ли найдётся успешных примеров порабощения всего человечества кем-либо?



dimnsk
23.06.2022 16:14+10вопросы:
1. по какому параметру самая большая модель ?
2. почему нет ноутбука с демо ?
3. примеры диалога хорошо, но где примеры генерации?
4. метрики качества модели?
ps не буду рекламировать конкурентов но они все это делали, а не описывали как ускорить обучениеMichaelEk Автор
24.06.2022 08:25+8Спасибо за внимание к статье. Отличные вопросы!
На данный момент это самая большая полностью обученная LM модель, выложенная в open source. А также, это самая большая на данный момент модель, обученная на русском языке.
Запуск такого ноутбука - нетривиальная задача, для удобства использования мы выложили докер, который можно запустить на Яндексе или AWS. На github есть скрипты запуска.
-
Какого рода примеры генерации интересны? Диалоги один из наших основных генеративных кейсов, поэтому мы исследовали генерацию на них. Ответы из примеров были сгенерированы YaLM 100B с подводкой, похожей на диалоговую подводку из статьи Gopher. Справедливости ради отмечу, что не каждое продолжение диалога выглядит так хорошо и интересно, но:
почти все ответы модели были адекватными;
из них примерно 30% были действительно интересными.
Замеряем на fewshot и zeroshot генерации.
Многие научные статьи делают акцент на качестве полученных решений, опуская многие технические аспекты. Мы видим свой вклад как раз в приоткрытии технических моментов. Замеры качества будут, но позже. Подписывайтесь на нас и следите за обновлениями ;)

sse
23.06.2022 17:51+2А сколько в деньгах в рыночных ценах стоит обучить такую модель? Видимо, основной вклад это стоимость аренды оборудования в датацентре, но что-то еще не учёл, скорее всего

vedenin1980
23.06.2022 23:38+3Ну стоимость 800 A100 graphics cards это порядка 25 млн. $, вероятно, аренда такого дорого кластера на 2+ месяца будет стоит порядка 1 млн.$. Плюс электричество, плюс аренда серверов, плюс команда программистов для получения данных и специалистов по машинному обучению. Думаю, несколько млн.$ это самый-самый минимум, я бы закладывался бы в млн 5.

fuwiak
23.06.2022 18:23+15Якобы в Яндексах все такие умники, а даже нормального How-to не выложили. Нет api для большой модели, не существует готовой урезанной средней или малой модели для обычных людей(в Google Colab). Не указано примера как настроить модель, как генерировать текст. Просто в статии указано пару нюансов для задротов и все. Достаточно присмотреться как сделал это банк на букву "C" и сделать так же.
У меня сложилось впечатление, что эта модель - просто один из неудачных экспериментов, который было жалко выбросить в мусор, поэтому она была выложена в Open Source, чтобы показать, какие замечательные модели создает Яндекс, и более того, это открытый исходный код!
Такую большую модель на практике могут использовать только университеты, обладающие большими вычислительными мощностями или другие гиганты, как хочет называться Яндекс (подозреваю, что у конкурентов уже есть свои модели и от Яндекса они не нужны). Вопрос в том, на кого именно рассчитана эта модель? Ни для маленьких, ни для больших эта модель не является очень полезной.dimnsk
23.06.2022 21:40+3после прочтения еще на раз, озадачился теми же самими вопросами
250 ОЗУ на GPU это где у кого есть? у зеленых?
остальным только восхищаться... и то мало понятно чем,
демо нету метрки нету
критично ? да, от того что мало понятно зачем...fuwiak
23.06.2022 22:57+5Plot twist: Следущая статья - раскрываем возможности абонемента премюм в Yandex DataSphere :)))))))

SporeMaster
23.06.2022 18:33+6Ждём ответы на стандартные вопросы:
Тестировщик: Когда Египет был перевезен во второй раз через мост Золотые Ворота?
Тестировщик: Почему у президента Обамы нет простого числа друзей?
Тестировщик: На сколько частей расколется галактика Андромеды, если на нее бросить крупицу соли?


Rybolos
23.06.2022 21:17+4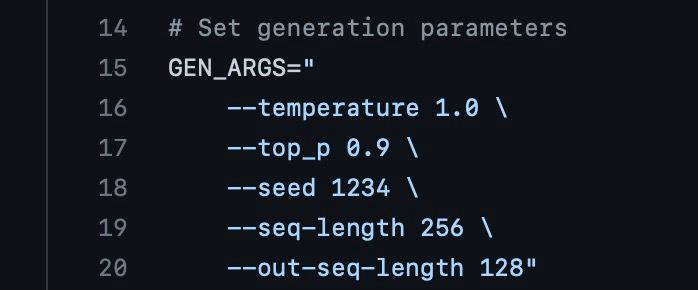
Скажите, какие параметры выставить для оптимальной генерации? Какие рекомендуете?
MichaelEk Автор
24.06.2022 07:34+4Параметры выше generate_conditional_sampling.sh хороши для генерации разнообразного текста, но лучше обеспечить текст достаточно большой подводкой. Пример хорошей диалоговой подводки вы можете увидеть на 112-113 страницах статьи Gopher.
Для решения каких-то прикладных задач с единственным правильным ответом, вроде QA на fewshot, стоит использовать параметры из generate_conditional_greedy.sh

kryvichh
23.06.2022 23:21Вот чертяка! Неудивительно, что один из инженеров Гугл посчитал что нейросеть, с которой он работал, обрела сознание. А там наверняка сеть гораздо больше, чем 100 млрд параметров.
Alexey2005
24.06.2022 00:00+1137 млрд у Гугла. С учётом того, что для подобных нейронок качество выхлопа (метрики вроде Hits@1/N или USR) пропорционально логарифму от количества параметров, разница будет не слишком велика при условии, что собран нормальный датасет и в обучении моделей нигде не налажали.
SporeMaster
24.06.2022 12:32>один из инженеров Гугл посчитал что нейросеть обрела сознание
Такой большой, а в сказки верите )

Imp5
24.06.2022 07:07Проблемы расхождения в fp16 проявлялись чаще, чем в fp32. В основном это было связано с переполнением значений fp16 в активациях и градиентах. Максимум fp16 по модулю — 65535. Итогом переполнения становился NaN в loss'е.
А через какие операции у вас прошел inf, чтобы стать NaN?
Для большинства операций inf вполне безопасен: x/inf=0, x*inf=inf (если x!=0), exp(inf)=inf, log(inf)=inf, tanh(inf)=1

Akr0n
24.06.2022 10:21Какие именно книги использовали для обучения? Все доступные, включая платные, или же только те, что выложены в свободный доступ? Может быть, есть сам список?
rPman
24.06.2022 10:30+3на сколько плохо нейронная сеть (не ее обучение а пример посмотреть) работает на CPU? арендовать машину с 300Gb RAM не так сложно как с GPU такой же суммарной емкости, а разница по скорости должна быть максимум 100кратная (скорее 16-кратная)
Alexey2005
24.06.2022 18:27+1По моему опыту, GPT-подобные нейронки при запуске на CPU требуют примерно вдвое больше RAM, чем потребовали бы VRAM на GPU. Т.е. машина потребуется более 500 Гб RAM.
Также разрыв в скорости между CPU и GPU растёт при росте количества этих самых CPU/GPU. Так, при запуске небольшой нейронки GPT-Neo 6B на одном CPU она будет работать примерно в 20 раз медленнее, чем на GPU, а вот если вы её распараллеливаете на несколько GPU, разрыв в скорости при сравнении с таким же количеством CPU очень быстро превышает 100 раз.
Скажем, чтобы для GPT-J 6B генерация ~ 50 слов английского текста уложилась в 10 секунд, вам потребуется сервер на 12 CPU.rPman
24.06.2022 21:41Под CPU вы что подразумеваете? какого уровня процессор и сколько ядер? а еще трафик между ними, если это отдельно стоящие машины?
Нагуглил, указанная нейронка 6 миллиардов параметров и требует 12гб ram?Alexey2005
25.06.2022 01:39+1Это VRAM она столько требует (и это самый минимум, для нормального запуска лучше 16 брать).
RAM она потребует для работы вдвое больше (от 24 Гб), а в момент загрузки и инициализации весов будет пиковое потребление ещё x2 (порядка 48 Гб), но это обходится файлом подкачки соответствующего размера, т.к. скачок потребления разовый и очень короткий, потом вся эта избыточная память освобождается.
CPU — процессор 3 ГГц, подразумеваются полноценные ядра. При этом сам код исходно кривой, так что для распараллеливания (чтобы нормально ядра задействовало) придётся вносить исправления (пример, число CPU прописывать в cores_per_replica), и даже с ними крашится, если задействовать более 16 ядер.

Durham
24.06.2022 16:21
После загрузки контейнера через указанный в репозитории скрипт pull и запуска его через run имеется папка workspace где в папке examples только набор стандартных примеров, а скриптов для запуска модели нет. Что я сделал неправильно?
Думаю смысл заключается в том, что надо сначала запустить контейнер а потом из него клонировать репозиторий и запускать модель, правильно? Хотелось бы инструкцию чуть подробнее, работа большая проделана вами, но последний шаг написания инструкции сильно увеличил бы ее ценность и доступность.


tuxi
25.06.2022 14:08+2Ну а самый простой и классический пример из детства, спрашивали у нее? что отвечает?
«а и б сидели на трубе, а упало, б пропало, что осталось?»Alexey2005
25.06.2022 16:38+1Более-менее внятные ответы на этот вопрос может и GPT3 выдать:
sberGPT3_medium: Да ничего не осталось.
Ну а «родить» каноничный ответ, заранее его не зная, даже для естественного интеллекта та ещё задача. Хуже только «зимой и летом одним цветом», которая допускает столько вариантов решения, что не зная нужный угадать абсолютно невозможно:
sberGPT3_large: Осталась дырка, в которую они упали.Зимой и летом одним цветом. Что это?
sberGPT3_medium: Варенье.
sberGPT3_large: Это загадка про зиму и лето.

ebt
25.06.2022 21:21+1Привет, Михаил, Алексей, Руслан!
(1.) Требования к GPU-памяти ≈200GB для запуска модели связаны с тем, что все выложенные веса (189GB) должны туда поместиться, верно?
(2.) Веса `layer_00`, `layer_01` и `layer_84` имеют аномально малый размер, а веса `layer_02` и `layer_83` вообще отсутствуют. Это какие-то артефакты сохранения?
(3.) Почему модель тренировалась именно 65 дней? Могла ли она быть ещё "улучшена", если бы вы тренировали её, допустим, 70 дней?
MichaelEk Автор
26.06.2022 08:59Привет!
(1.) Все верно. Нужно еще место под промежуточные активации
(2.) Блоки трансформера идут с 03 по 82 слой. Остальные слои - эмбеддинги, преобразования в нужную размерность, лямбда функции (у них нет чекпоинта). Структура слоев взята из PipelineModule DeepSpeed
(3.) За 65 дней модель прошла 300B токенов - столько же, сколько GPT-3 от OpenAI. Её можно было бы улучшить, обучая еще, но для существенного роста качества ее стоило бы обучать еще месяц-два.
alexwortega
Отличная работа! А будут маленькие версии выкладываться? 2.7b/6b?
MichaelEk Автор
Нет, пока не планируем их выкладывать