

Программирование на ассемблере
Это руководство по созданию симулятора простого 8-битного ассемблера на Javascript.
CPU
Внутри центрального процессора (CPU) содержится несколько ячеек памяти, называемых регистрами. В данном случае эти регистры занимают один байт (8 бит) памяти. Таким образом, в любой момент времени каждый из этих 8-битных регистров хранит одно значение от 0 до 255, или от $00 до $FF в шестнадцатеричной системе.
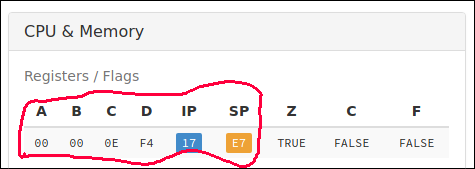
Внутри этого процессора также есть несколько ячеек памяти, называемых флагами, каждый из которых занимает один бит памяти и используется для представления булевых значений. Таким образом, в любой момент времени каждый из этих 1-битных флагов имеет значение TRUE, либо FALSE.

Эти регистры и флаги вместе определяют внутреннее состояние процессора в любой момент времени и служат для различных целей, о которых вы сейчас узнаете!
Данный процессор имеет четыре регистра общего назначения, которые называются A, B, C и D. Они так называются (общего назначения), потому что программист сам решает, как их использовать. Часто бывает удобно и даже необходимо иметь место для временного хранения значений, которыми манипулируют, и вот тут-то и пригодятся эти регистры.
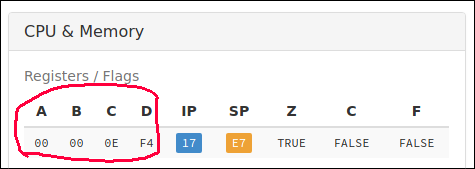
Также в CPU есть два регистра специального назначения - указатель инструкций (IP) и указатель стека (SP). Они называются указателями, потому что в них хранится значение, отображающее ячейку в оперативной памяти. Иными словами, они указывают на место в памяти.
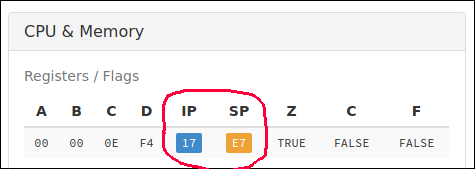
Указатель инструкции показывает на следующую инструкцию программы в памяти, которая должна быть выполнена, а указатель стека — на текущую вершину стека (подробнее об этих двух флагах позже).
Этот процессор имеет три флага: флаг нуля (Z), флаг переноса (C) и ... честно говоря, я понятия не имею, для чего здесь еще нужен F флаг :) Так что давайте пока просто проигнорируем его. Эти флаги используются для хранения результатов выполнения различных операций. Программист может прочитать эти результаты и использовать их, чтобы решить, что делать дальше. Например, при вычитании двух чисел флаг нуля устанавливается в TRUE, если результат равен 0. Точное использование этих флагов зависит от инструкции, поэтому мы вернемся к этому позже.
Память
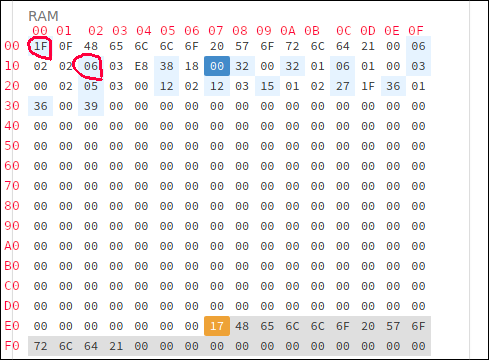
К этому смоделированному процессору подключен блок из 256 байт оперативной памяти (RAM). Каждый из этих байтов расположен в порядке сверху слева вниз направо и имеет назначенный номер, который является адресом памяти этого байта. Например, на скриншоте значение в ячейке памяти $00 равно $1F, а значение в ячейке памяти $12 равно $06. Программист может дать процессору команду читать и записывать значения байтов в/из каждого адреса памяти в произвольном порядке (отсюда название "память с произвольным доступом (random access memory. RAM)".
Ввод/вывод
На самом деле, у этого моделируемого процессора нет средств ввода, но у него есть некоторая форма вывода: 24-ячеечный ASCII-дисплей !

Этот несложный дисплей просто отображает символы, соответствующие закодированным значениям ASCII, присутствующим в определенной части памяти, а именно в ячейках от $E8 до $FF. Это пример ввода-вывода с отображением в памяти, который означает, что некоторые формы системного ввода и/или вывода могут быть доступны путем чтения из определенного места в памяти или записи в него.

Программы
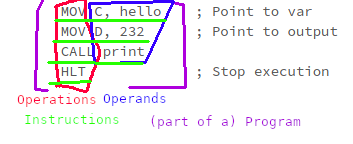
Программа — это последовательность инструкций, которые указывают центральному процессору, что делать. Большинство инструкций состоит из операции и одного или нескольких операндов, в зависимости от операции.
Операция — это как функция, встроенная в процессор и предоставляемая программисту для немедленного использования. Каждая операция имеет короткое запоминающееся имя, называемое мнемоникой. В письменном языке ассемблера операции обозначаются этой мнемоникой.
Операнд — это как аргумент операции. Операндом может быть регистр процессора, ячейка памяти или литеральное значение.
В конце концов, центральный процессор понимает только цифры. Когда вы нажимаете кнопку "Assemble", код ассемблера преобразуется в числовое представление программы, называемое машинным кодом, а затем помещается в память.
Помимо мнемоники, каждая операция имеет соответствующее представление в числовой форме, называемое опкодом. Между каждой мнемоникой и каждым опкодом существует прямая корреляционная зависимость. Когда инструкция собрана в машинный код, мнемоники системно заменяются на соответствующие им опкоды.
Режимы адресации
Режим адресации — это способ обращения к фактическому значению, используемому в качестве операнда.
Непосредственная адресация — это когда значение указывается сразу после указания операции. Она называется непосредственной адресацией, потому что закодированное значение помещается непосредственно после опкода в машинном коде.
Прямая адресация — это когда используемое значение находится где-то в памяти. Вместо прямого указания значения указывается адрес значения в памяти. Это называется прямой адресацией в отличие от косвенной адресации.
Косвенная адресация — это когда используемое значение находится где-то в памяти, и его адрес также находится там. Вместо того чтобы указывать значение напрямую или указывать адрес значения в памяти, указывается адрес адреса. Это называется косвенной адресацией, потому что... ну... она довольно косвенная, вам не кажется :) Она используется не так часто, как другие, но все же полезна в ситуациях, когда вы не знаете заранее, где находится значение.
Стек
Стек — это структура данных, которая выглядит подобно обычной стопке предметов. Это структура LIFO (last in first out. последним пришёл — первым ушёл), то есть первым из стека достается то, что было помещено в него последним. Представьте себе стопку блоков. Единственный блок, который вы можете снять с вершины стека, это последний блок, который был туда помещен.
Стек в памяти реализован как последовательность значений, составляющих элементы, плюс указатель стека. Указатель всегда показывает на то, что считается вершиной стека.
Каждый раз, когда вы хотите загрузить элемент в стек (другими словами, поместить новый элемент на вершину стека), вы просто копируете значение в место в памяти, на которое указывает указатель стека, а затем увеличиваете (или уменьшаете, в зависимости от направления роста стека) указатель стека, чтобы он указывал на следующее свободное место, место прямо над элементом, который вы только что добавили в стек.
Каждый раз, когда вы хотите убрать элемент из стека (другими словами, удалить последний элемент, который был помещен на вершину стека), вы просто перемещаете указатель стека обратно вниз. Если вам нужно значение, которое вы только что выгрузили, просто обратитесь к значению в памяти, на которое теперь показывает указатель стека.
Этот процессор имеет один встроенный стек! Его указатель содержится в собственном регистре указателя стека процессора. В данном случае стек растет вниз, и при перезагрузке процессора указатель стека инициализируется значением $E7, что означает, что нижняя часть стека находится в ячейке памяти $E7. Но эти детали не важны для фактического использования стека.
Центральный процессор предоставляет операции PUSH и POP, которые позволяют "заталкивать" и "выталкивать" значения в стек и из стека. При работе со стеками операции занесения и извлечения элемента являются основными. Программист сам решает, как использовать стек, но обычно он используется при временном сохранении значений, во время передачи аргументов между функциями или для отслеживания адресов возврата (подробнее об этом позже).
Выполнение программы
В процессе работы центральный процессор выполняет инструкции в памяти одну за другой. Сначала он ищет инструкцию в памяти, на которую ссылается указатель. Это включает в себя опкод, а также любые значения байтов операндов, которые могут быть использованы в зависимости от операции. Затем он выполняет эту инструкцию, вероятно, воздействуя на внутреннее состояние процессора и/или содержимое памяти. В итоге указатель инструкции устанавливается в местоположение, следующее непосредственно за только что выполненной инструкцией, и процесс продолжается.
При перезагрузке процессора указатель инструкций устанавливается в 0, что означает, что первой выполняемой инструкцией будет та, которая находится в самом начале памяти. Когда процессор запущен, он будет работать до тех пор, пока не встретит инструкцию остановки (HLT), в этот момент он зависнет. В качестве альтернативы вы можете выполнять по одной инструкции за раз (так называемый степпинг).
Язык ассемблера
Инструкция записывается на языке ассемблера, начиная с мнемоники, за которой следуют любые операнды, разделенные запятыми.
Литеральные значения можно использовать в качестве операндов, просто включив в них численное значение или символ ASCII, заключив его в одинарные кавычки. Это непосредственная адресация.
Содержимое регистров процессора можно использовать в качестве операндов, просто написав имя регистра процессора. Например, A относится к регистру A.
Значения, находящиеся в памяти, можно использовать в качестве операндов, заключив другое значение в фигурные скобки [ и ]. Например, значение по адресу памяти $20 можно использовать в качестве операнда, записав [$20]. Это прямая адресация.
Вы также можете поместить имя регистра между [ и ], чтобы использовать в качестве операнда значение в памяти, расположенное по адресу, содержащемуся в этом регистре. Например, если регистр A содержит $5, то [A] ссылается на значение, находящееся в памяти по адресу $5.
Вместо явного указания адресов памяти гораздо более распространенным и удобным является использование меток для обозначения ячеек памяти в программном коде. Вы можете поместить метку в ассемблерный код, чтобы отметить скомпонованный адрес того, что следует непосредственно за ним, написав имя, после которого следует двоеточие. Например, start: создает метку с именем "start". Затем вы можете использовать имя start в любом другом месте программы вместо адреса памяти для ссылки на это место в коде.
Вы можете включать произвольные данные в свою программу с помощью директивы DB. Это означает "байт данных" и не является мнемоникой для операции процессора, а скорее служит инструкцией для ассемблера включить некоторые бинарные данные в эту точку, а не собирать там код. Это полезно для включения в программу предопределенных постоянных значений.
Наконец, комментарии в языке ассемблера обычно обозначаются при помощью точки с запятой.

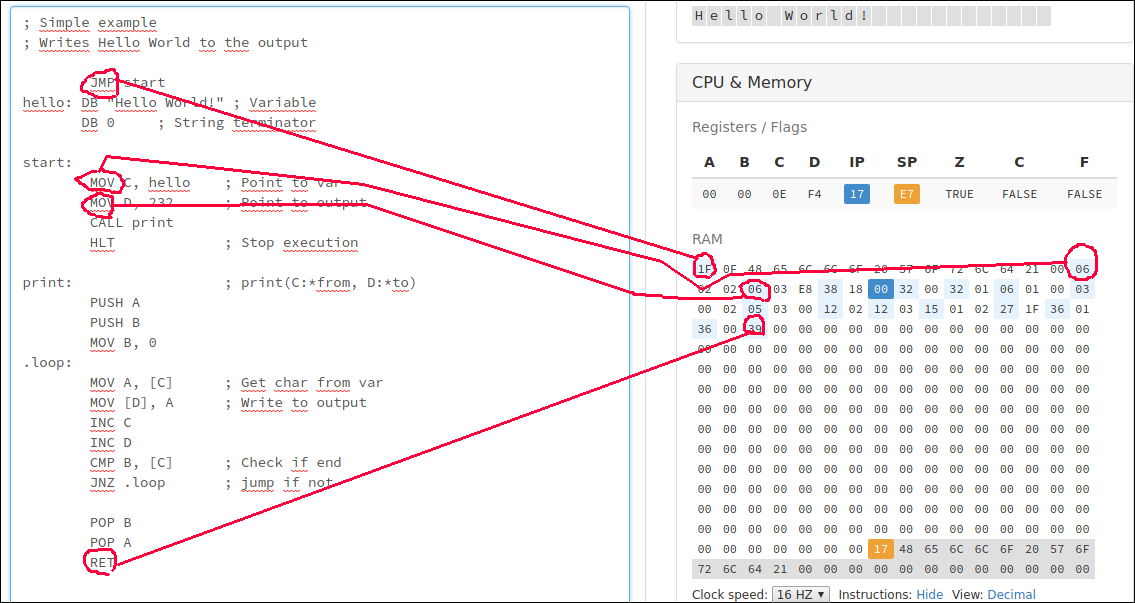
Hello World!
Давайте рассмотрим образец Hello World!
Для справки здесь приведен код примера из симулятора:
; Simple example
; Writes Hello World to the output
JMP start
hello: DB "Hello World!" ; Variable
DB 0 ; String terminator
start:
MOV C, hello ; Point to var
MOV D, 232 ; Point to output
CALL print
HLT ; Stop execution
print: ; print(C:*from, D:*to)
PUSH A
PUSH B
MOV B, 0
.loop:
MOV A, [C] ; Get char from var
MOV [D], A ; Write to output
INC C
INC D
CMP B, [C] ; Check if end
JNZ .loop ; jump if not
POP B
POP A
RETКак упоминалось ранее, когда процессор перезагружается, указатель инструкций устанавливается в 0, а это означает, что начало программы находится в верхней части файла. Поэтому первая инструкция в программе будет такой:
JMP startОперация JMP просто устанавливает указатель инструкции на свой операнд. То есть она переходит к заданному месту в памяти и продолжает выполнение программы оттуда. В этом случае операндом является start — метка, обозначающая данную часть кода:
start:
MOV C, hello ; Point to var
MOV D, 232 ; Point to output
CALL print
HLT ; Stop executionПосле выполнения перехода следующая инструкция будет такой:
MOV C, hello ; Point to var Инструкция MOV копирует свой второй операнд в место, описанное первым операндом. Иными словами, она перемещает данные. В данном случае второй операнд — hello, а первый — C. Это означает, что адрес памяти, обозначенный меткой hello, копируется в регистр C. hello отмечает это в коде:
hello: DB "Hello World!" ; VariableЭто необработанная строка "Hello World!", которая будет напечатана. Итак, теперь регистр C содержит местоположение строки, которую мы собираемся напечатать. Другими словами, регистр C указывает на строку.
Следующая инструкция — это еще один MOV:
MOV D, 232 ; Point to outputЭто помещает значение 232 в регистр D. 232 ($E8 в шестнадцатеричном исчислении) — это адрес памяти для нашего отображаемого в памяти дисплея вывода символов. Таким образом, если мы запишем строку в память, начиная с этого места, она появится на нашем дисплее.
Напомним, что на данном этапе выполнения регистр C указывает на строку, которую мы хотим вывести на экран, а регистр D указывает на саму память дисплея. Все, что нам теперь нужно сделать, это скопировать строку, на которую указывает C, в место, на которое указывает D.
Следующая инструкция — это вызов нашей функции print:
CALL printОперация CALL очень похожа на JMP тем, что она также переходит к другому месту в памяти для дальнейшего выполнения. Разница лишь в том, что перед переходом она помещает текущее значение указателя инструкции в стек. Ячейка памяти, в которую был выполнен переход, предназначена для начала функции (на языке ассемблера она также называется сабрутиной (subroutine)).
Как правило, последней инструкцией в функции является инструкция RET. Операция RET, как вы догадались, возвращает из функции. Она делает это, устанавливая указатель инструкции на адрес возврата, полученный путем извлечения его из стека. Это возможно потому, что операция CALL "выталкивает" адрес возврата перед переходом к функции.
В ассемблере существует несколько способов передачи аргументов функциям. Способ, используемый здесь, заключается в предварительной загрузке регистров процессора значениями для передачи функции. В данном случае наша функция печати принимает два аргумента: указатель на строку, которую нужно напечатать, и указатель на ячейку в памяти, куда ее нужно напечатать. Она ожидает, что эти аргументы будут переданы через регистры C и D соответственно. Именно поэтому мы ранее загрузили эти регистры этими значениями!
Таким образом, в этом случае вызывается функция, помеченная меткой print, поэтому адрес возврата помещается в стек, а затем указатель инструкции устанавливается на начало функции печати, и мы продолжаем оттуда.
Первая пара инструкций в функции печати выглядит следующим образом:
PUSH A
PUSH B
MOV B, 0Это типично для пролога функции. Пролог функции — это некоторый начальный код в функции, который подготавливает стек и регистры процессора к использованию.
В данном случае мы помещаем регистры A и B в стек, чтобы их значение сохранилось. Так мы поступаем потому, что тело этой функции собирается исказить содержимое регистров. Сначала сохранив их значения, затем мы сможем восстановить их перед возвратом из программы. Таким образом, любой части кода, вызывающей эту функцию, не придется беспокоиться о том, что содержимое регистров будет изменено после вызова функции.
После вставки мы также инициализируем регистр B, чтобы он содержал значение 0. Скоро вы увидите, почему.
Первое, что находится в теле нашей функции после пролога, — это цикл:
.loop:
MOV A, [C] ; Get char from var
MOV [D], A ; Write to output
INC C
INC D
CMP B, [C] ; Check if end
JNZ .loop ; jump if notМетка .loop отмечает начало цикла. (Не обращайте внимания на точку в начале имени. Это просто обычный способ обозначения локальных меток. Меток, чья значимость ограничена некоторой локализованной частью кода. Например, в вашей программе может быть много циклов, ни один из которых не должен ссылаться друг на друга, и нам не хочется давать каждому циклу уникальное имя).
Я заранее расскажу вам, что делает этот цикл: он копирует каждый символ из исходной строки в пункт назначения.
Поскольку C в настоящее время указывает на исходную строку, первое, что нужно сделать, это захватить первый символ, символ по адресу указателя:
MOV A, [C] ; Get char from varЭто копирует значение в памяти, на которое указывает содержимое регистра C, в регистр A.
Следующим шагом будет копирование полученного символа на выходной дисплей, куда в данный момент указывает регистр D:
MOV [D], A ; Write to outputЭто копирует символ (в A) в память, на которую указывает D.
Теперь, когда мы успешно скопировали первый символ на выходной дисплей, пришло время заняться следующим! Для этого нам просто нужно увеличить исходный и указатель назначения на единицу, чтобы мы могли получить следующий символ из исходной строки и записать его в следующую ячейку на дисплее символов. Операция INC делает именно это, она инкрементирует (увеличивает) содержимое регистра на единицу:
INC C
INC D В этот момент мы могли бы просто использовать операцию JMP для возврата к началу цикла в .loop, чтобы скопировать остальные символы. Единственная проблема заключается в том, что это создаст бесконечный цикл, поскольку не будет никакой возможности узнать, что нужно остановиться, когда будет достигнут конец строки.
Вместо этого нам нужен способ вернуться в начало цикла, только в том случае, если мы не закончили копирование строки. Более того, нам также нужен способ узнать, закончено ли копирование строки или нет. Это можно узнать, пометив конец строки нулевым терминатором, который представляет собой байт со значением 0, помещенный в памяти непосредственно после строки. Вот почему за значением строки в программе следует DB 0:
hello: DB "Hello World!" ; Variable
DB 0 ; String terminatorТеперь все, что нам нужно сделать, это проверить, не окажется ли следующий символ 0, прежде чем продолжить цикл. Если это не 0, вернитесь в начало цикла. Если это 0, то мы закончили, продолжаем выполнение программы, минуя цикл.
Для того чтобы проверить, является ли следующий символ 0, мы можем использовать операцию CMP:
CMP B, [C] ; Check if endОперация CMP сравнивает два своих операнда и соответственно устанавливает флаги процессора. Для нашего случая достаточно знать, что если два операнда численно равны, флаг нуля устанавливается в TRUE. (Логика заключается в том, что для сравнения двух чисел операция CMP производит внутреннее вычитание второго из первого, и если результат равен 0, она устанавливает флаг нуля. Конечно, разница в 0 означает, что два операнда эквивалентны).
В этом случае флаг нуля устанавливается в TRUE, если следующий символ в строке равен 0. (Помните, мы только что инкрементировали содержимое C для указания на следующий символ в строке, а в прологе функции мы инициализировали B в 0. Вот почему мы это сделали!)
Наконец, мы используем операцию JNZ, чтобы вернуться в начало цикла только в том случае, если флаг нуля был установлен в TRUE:
JNZ .loop ; jump if notОперация JNZ аналогична JMP, за исключением того, что она выполняет переход только в том случае, если флаг нуля в данный момент FALSE. Другими словами, она (j)umps, если (n)ot (z)ero (переходит, если не ноль). Если флаг нуля в данный момент FALSE, то ничего не происходит, и программа продолжает выполнение следующей инструкции.
Которая в данном случае является эпилогом функции! Эпилог функции — это аналог пролога функции. Здесь стек и регистры процессора подготовлены к возврату из функции. В нашем случае мы просто восстанавливаем ранее сохраненные значения регистров A и B, чтобы та часть кода, которая первоначально вызвала эту функцию, не знала, что регистры A и B вообще использовались. Это важно для случая, когда вызывающий код будет использовать A и B в своих собственных целях:
POP B
POP AНаконец, мы возвращаемся из функции с помощью операции RET, которая, как уже говорилось ранее, "выталкивает" адрес возврата из стека, который был первоначально вставлен соответствующей инструкцией CALL, а затем помещает этот вытащенный адрес обратно в регистр указателя инструкций.
Последней инструкцией нашей программы является HLT:
HLT ; Stop executionИнструкция HLT останавливает работу процессора, обозначая завершение выполнения программы.
Приглашаем на открытое занятие «Как работают компиляторы», которое поможет понять устройство компиляторов и работу языков программирования.
На занятии узнаем, что такое алфавит, грамматика, форма Бэкуса-Наура и попробуем построить формальное определение простейшего языка программирования. Рассмотрим ключевые стадии (лексический, синтаксический анализ), определения и алгоритмы разбора программ, описанных подобными грамматиками. Построим схему построения компилятора и реализуем отдельные части компилятора на Golang (C/Python).
Комментарии (7)

Myclass
04.08.2022 23:49+3С этим симулатором хорошо показать различные проблемы, например с переполнением стека. Потому что многие вроде понимают, что это такое, но как к этому приходит - не ясно. А написав несколько примеров, где например ret и goto перемешиваются так, что в стек остаётся всегда что-то, что не должно - то и работы программы нарушается.
Второй пример для переполнение стека , когда например при вызове функции сохраняются два регистра с командой push, а перед возвратом берём только один регистр назад с командой Pop. И если вызов такой функции повторяется какое-то n-колличество раз, то и наглядно как стек 'нежелательно' заполняется и когда-то переполняется. И в какой-то момент настолько, что встречается с местом, где уже находится и код. Вроде банальность, но именно так новички понимают, как работают внутренние вещи в процессоре или операционной системе.

Tyusha
Похоже, колесо сансары замкнулось. Идëм на второй круг. Когда ожидать симулятор .NET поверх этого всего?
Myclass
Нет, это не для этого и ваши слова здесь не совсем подходят. Этот симулятор например я показываю студентам, которые никогда в жизни настоящий ассемблер проходит или использовать не будут. А тут есть возможность потрогать и получить первое представление. И так как мои лекции о процессорах и их архитектуре проходят до этого, то и первое понимание самой сути ассемблер на этом симуляторе вполне себя оправдывает. Почти никто из моих студентов может быть никогда и не будет программистом в ассемблере, но представление от него он получит. Разве это плохо?
saboteur_kiev
Прям с языка сорвали.
Тут идеальный пример низкоуровневой архитектуры, на уровне процессора z80, чтобы понять как оно там работает в простом виде, когда еще нет предсказывающих ветвлений, защищенного режима, многоядерности и пары сотен регистров.
И запустить можно ВЕЗДЕ, в браузере.
Как раз самое то, чтобы не только показать, но и пощупать и написать простейшую программу. Для этого и 24-символьного дисплея в принципе достаточно.
Myclass
Конечно, на простом ассемблере и написать например сортировку массива - этот симулятор самое то.