
Значение данных для эффективного управления организацией расчет с тех пор как больше ста лет назад Фредериком Уинслоу Тейлором были заложены основы научной организации труда. Появление компьютеров позволило вывести их обработку и использование на принципиально новый уровень. Объем используемых человечеством данных растет по экспоненте. По прогнозам экспертного сообщества их объем уже через три года (в 2025 году) достигнет 180–200 Зеттабайт.
Ручная обработка больших объемов информации практически невозможна и мы вынуждены все больше полагаться на сложные алгоритмы обработки, подготовки и анализа. Агрегация данных становится все более и более высокоуровневой, десятки и сотни миллионов записей в базах данных сводятся машинами в одностраничную табличку, на основе которой принимаются стратегические решения.
Но ошибки в исходных данных вызывают ошибки в расчетах производных, в лучшем случае алгоритмы оказываются неспособны их обработать и процесс аварийно останавливается, а в худшем – менеджер получает результат анализа, не осознавая, что ошибки привели к абсолютно неадекватному результату. Образно говоря, он начинает грызть футбольный мяч, будучи уверен, что это арбуз.
Здесь мы приходим ко вполне предсказуемому, но все еще неочевидному для многих выводу: управление современной организацией невозможно без создания системы управления данными и, в частности, системы управления КАЧЕСТВОМ данных.
В начале славных дел
Созданный в Газпромбанке в начале 2020 года офис CDO (Chief Data Officer) столкнулся с рядом вызовов, главным из которых стал именно вопрос повышения качества данных.
Начались исследовательские работы. Оперировать современными объемами данных, не опираясь на мощную и функциональную ИТ-платформу, не представлялось возможным. Казалось, это не должно стать проблемой: рынок предлагал на выбор различные решения от именитых и не очень поставщиков, сеть изобиловала информацией, а на многочисленных конференциях коллеги наперебой рассказывали об успешных внедрениях того или иного продукта.
Но всегда есть какое-то НО: высокая стоимость лицензий, дорогостоящая поддержка, зависимость от экспертизы поставщика, отсутствие гибкости и адаптивности – вот далеко не полный перечень того, чем приходится платить за выбор решения «из коробки».
Тогда мы решили положиться на народную мудрость, периодически приписываемую то Наполеону Бонапарту, то Фердинанду Порше: «Если хочешь сделать что-то хорошо, сделай это сам». Так родилась идея создания собственной платформы управления качеством данных с использованием стека Open Source. Вот требования, которым должна была соответствовать платформа:
Возможность создания настраиваемых пользовательских проверок качества данных любой сложности;
Графическая визуализация работы проверок качества данных;
Пользовательский веб-интерфейс для создания проверок и их настройки;
Возможность подключения к любому источнику данных, независимо от используемых в нем технологий;
Рассылка почтовых уведомлений о результатах проверок;
Интеграция с Jira для заведения обращений по качеству данных при срабатывании определенных правил;
Прозрачная ролевая модель доступа к системе;
Портируемость решения на другую платформу обработки данных в случае необходимости.
Качество — это когда все делаешь правильно, даже если никто не смотрит
Нам нужно было сформировать у потребителя доверие, дать ему возможность выстраивать свои бизнес-процессы на основе качественных и проверенных данных. Как можно решить эту задачу в разумные сроки, без огромного бюджета и перестройки всего ИТ-ландшафта?
Мы начали выстраивать контроль качества данных на уровне единого консолидированного слоя и на уровне прикладных витрин. Ключевой элемент — проверки — мы сделали заключительным этапом процесса трансформации и подготовки данных.
Проверки качества данных
Мы выделили простые и сложные проверки качества данных. Простые — это проверки, которые могут создаваться массово и автоматически (или автоматизировано) с минимальными трудозатратами. Вот примеры простых проверок:
Проверка ссылочной целостности;
Проверка заполнения атрибутов;
Проверка на допустимые значения атрибутов.
Чтобы полностью покрыть проверками критические атрибуты консолидированных данных требуются тысячи простых проверок. Именно поэтому критически важны скорость и простота их создания. У нас они могут быть созданы с помощью пользовательского веб-интерфейса, в конструкторе. Перед тем, как проверка будет установлена на регламент, выполняется автоматическая предварительная валидация – проверяется SQL-синтаксис, наличие объектов над которыми выполняется запрос и наличие прав доступа к этому объекту.


Сложными мы называем проверки, которые невозможно (ввиду сложности алгоритмов) сгенерировать из метаданных в исполняемый код, либо создать с помощью конструктора запросов. Пример — отчет о сходимости балансов. Алгоритм этой проверки содержит тысячи срок кода. Сложная проверка создается в виде отдельного ETL процесса, который запускается в рамках регламентного потока задач.
Все проверки имеют ряд настроечных параметров, позволяющих управлять их жизненным циклом. Например:
Статус проверки (черновик/эксплуатация/архив);
Владелец проверки и ответственный за мониторинг дата стюард проверки;
Длина доверительного интервала — количество дней, в течение которых рассчитывается доверительный интервал отклонения;
Порог рассылки почтовых уведомлений — метрика, превышение которой приводит к рассылке почтового уведомления;
Список адресатов рассылки;
Условие автоматического заведения обращения в Jira.
Сейчас в системе реализовано больше более 25 типов параметров для жизненного цикла сложных проверок.

Все проверки качества данных в системе запускаются и рассчитываются автоматически в соответствии с индивидуальными настройками.
Важным инструментом выстраивания процессов управления качеством данных является своевременное уведомление ответственных сотрудников о выявленных проблемах. Для этого мы сделали два типа автоматических рассылок почтовых уведомлений: уведомления о статусе исполнения проверок качества данных и детальные отчеты о результатах конкретных проверок.
Первые сообщают, что проверка (или группа проверок) успешно выполнены, либо возникла аварийная ситуация во время расчета и требуется вмешательство администратора. В случае успешного завершения, уведомление содержит агрегированные результаты проверок, а в случае неудачи — детализацию причины.

Детальный отчет содержит перечень записей, в которых выявлено нарушение (например, выход значений за доверительный интервал, превышение допустимых значений метрики, отсутствие ссылочной целостности и т.д.).

Визуализация
С учетом изначальной ориентации на Open Source, для реализации дашбордов мы выбрали Grafana, которая в банке уже используется. Cделали удобные для дата-стюардов и потребителей данных дашборды: интегральные тепловые карты и светофоры, графики, отображающие динамику изменения метрик качества данных с доверительными интервалами, фильтры для отбора отдельных филиалов, автоматизированных систем, таблиц и атрибутов. С их помощью можно обеспечить возможность углубленного анализа до уровня конкретных ошибок в данных.

За несколько месяцев работы мы поняли, что Grafana нас полностью устраивает и искать другие инструменты не нужно.
Архитектура
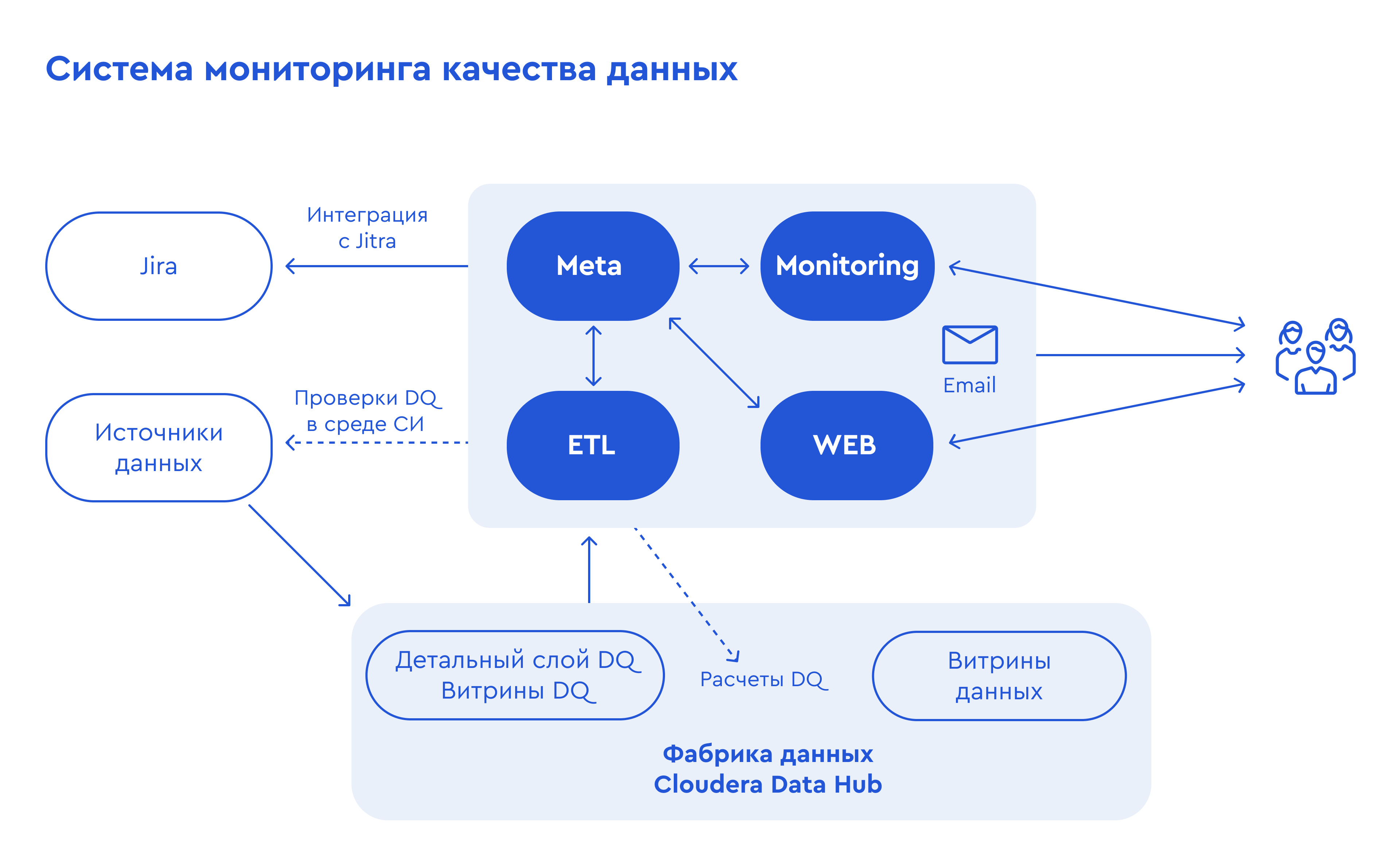
Первым, с чем следовало определиться при проектировании, была базовая единая платформа данных. Ее реализовали на базе Hadoop. А регламентные расчеты и процессы управления качеством данных реализовали с использованием единого набора промышленных ETL-инструментов.
Каждый элемент процесса контроля является частью общего регламентного процесса сбора и подготовки данных. Все результаты расчета проверок качества данных материализуются и сохраняются в общий детальный слой проверок, а также передаются в СУБД Postgres для визуализации в Grafana.
Что дальше
Наша команда смогла быстро разработать и внедрить самодостаточный продукт, основанный на Open Source, позволивший решить ключевые задачи управления качеством данных. Наличие пользовательского конструктора проверок, систем визуализации, рассылки уведомлений, а также интеграций с внешними системами позволяет в кратчайшие сроки выстраивать процессы контроля основных показателей и интегрировать их в бизнес-процессы.
Теперь у нас есть постоянный мониторинг качества данных, внедрены процессы управления их качеством, мы ежедневно выявляем и устраняем инциденты качества. Но останавливаться на этом не собираемся. Следующая цель – максимальная автоматизация процессов управления, расширение покрытия данных проверками качества и сокращение времени реагирования на инциденты.
GromovBI
отличный солюшн! если я правильно понял, то продукт все-таки не автоматический, а по сути его тоже надо с нуля программировать (разрабатывать эти дэшборды проверки и тд)? были ли какие-то проблемы с совместимостью компонент open source или все встало и заработало как родное? сколько человек и с какими скиллами трудятся над поддержкой такого решения? статья есс-но написана в позитивном ключе (и это радует), но все-таки были ли какие-нибудь трудности/проблемы?
CDO_Alex
Сергей, добрый день!
Изначально дэшборды и проверки приходилось программировать с нуля, сейчас уже внедрен конструктор, который позволяет типовые проверки делать путем настройки параметров на Web.
Понятно, что остается некий процент очень сложных проверок (например, балансовые сверки), которые невозможно собрать в конструкторе, их приходится кодить.
Трудности и проблемы, как всегда, были. Особенно в области совместимости.
Например, при переходе с 13-й версии Postgres Pro на 14-ю получили современный алгоритм шифрования SHA256, а наш не очень современный ETL-инструмент работал только с MD5. Хоть и с большим трудом, но все удалось найти и настроить соответствующие драйверы.
Также была проблемы с:
nGinx - для выполнения всех требований информационной безопасности пришлось делать кастомную сборку;
Дополнительными библиотеками для Python - подбирали наиболее подходящую версию для интеграции с Jira;
Apache Airflow - довольно трудоемкое развертываение в кластерной конфигурации.
Многие сложности были связаны с выполнением требований информационной безопасности.
Но так как Блок ИБ у нас очень передовой и проактивный, то мы совместно смогли разрешить все проблемы, иногда прибегая к компенсирующим мерам.
Системной поддержкой (БД PostgreSQL, Linux-сервера, системы виртуализации, сетевое взаимодействие) занимаются централизовано профильные ИТ-подразделения.
Прикладную часть сопровождают: 3 разработчика и 1 аналитик (естественно, это не единственная их задача). Координация обычно идет либо через менеджера системы, либо через архитектора. Квалификация у ребят высокая и позволяет решать вопросы достаточно эффективно.
GromovBI
супер! спасибо за ответы!