
У нас в Газпромбанке сложилась довольно интересная ситуация. Банк относительно недавно начал активно работать с розницей, которая как локомотив начала тянуть все внутрибанковское IT и менять характер работы всех подразделений.
Одна из главных наших проблем (впрочем, как и у многих) — долгие релизы, низкое качество кода, недоступность и нестабильность систем на тестовых полигонах. Но главное — интеграционные релизы. Когда несколько команд одновременно пытаются зарелизить свои доработки, нужно много времени и средств, чтобы синхронизировать всех. При этом каждый привносит новые баги, все начинают бегать кругами, спотыкаться, фиксить, перенакатывать… В итоге качество продукта низкое, а пользователь смотрит на это все с недоумением.
Как с этим всем бороться? Мы пришли к такому рецепту: избавиться от интеграционных релизов. Вообще. Собрать автономные, кросс-функциональные команды, каждая из которых будет выполнять свою задачу, не толкаясь локтями с другими. Для этого перепилить пайплайн, повысить инженерную культуру, ввести стандарты и так далее. Подробнее — под катом.
Для начала мы обратили внимание на то, как у нас устроено тестирование. О том, как и в каком порядке должны быть сгруппированы тесты написал еще Майк Кон в книге «Scrum: гибкая разработка ПО» (Succeeding With Agile. Software Development Using Scrum). Он предложил хорошую абстракцию: пирамиду тестирования. Она в простом и понятном виде демонстрирует как правильно должен быть организован процесс разработки.
По Кону в основании пирамиды должны быть быстрые и дешевые юнит-тесты, с помощью которых быстро закрывается максимальное количество дефектов, выходящих из разработки. Выше – компонентные и интеграционные тесты. И на самой вершине небольшое количество самых дорогих тестов — ручных. Главное: большинство багов должно закрываться тестами на самом раннем этапе.
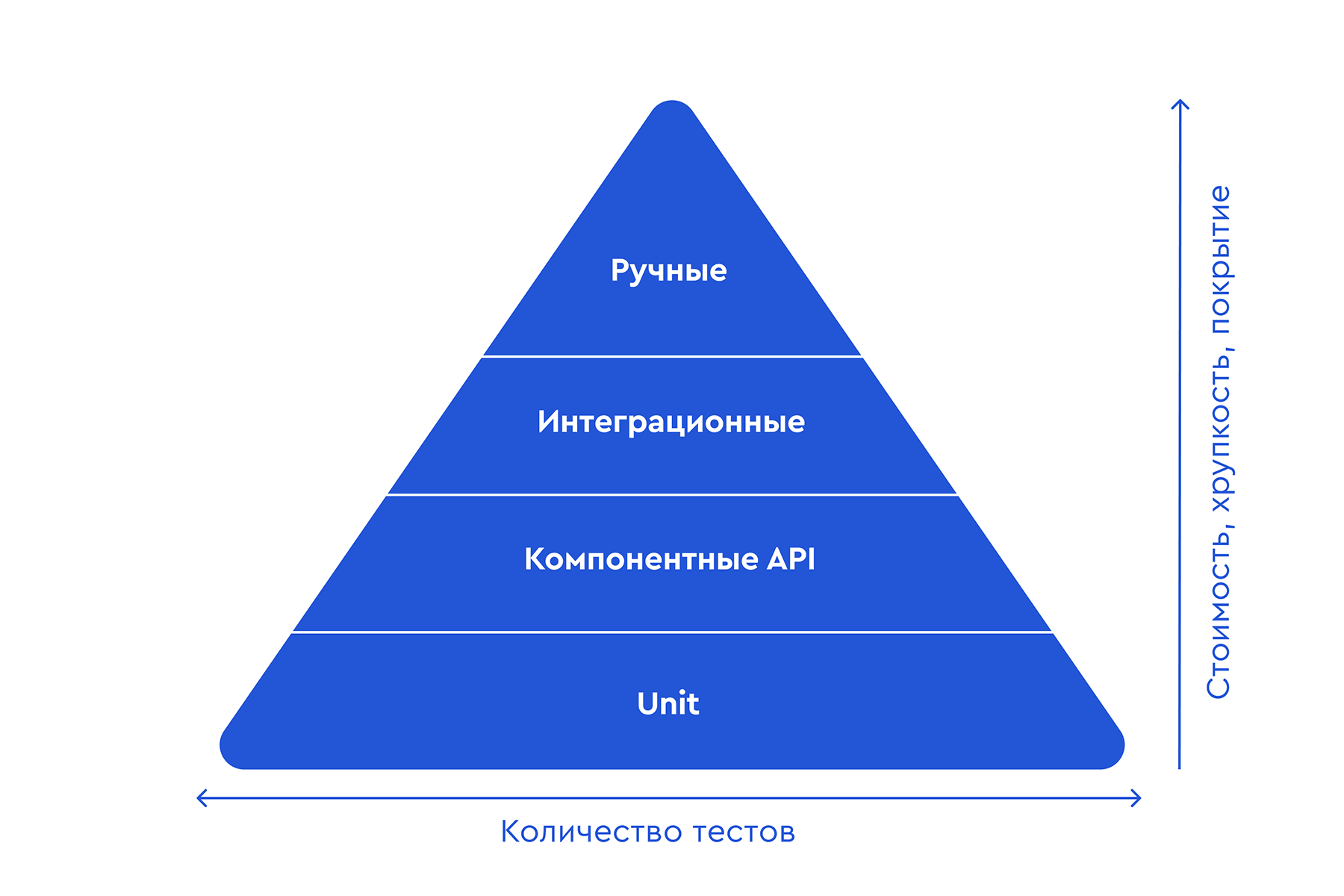
Как оказалось, наша пирамида выглядит не совсем так. Порядок в ней правильный, но сама она стоит вверх ногами. В нашем варианте большая часть дефектов выявлялась и устранялась на позднем этапе разработки, что дороже, занимает больше времени и просто неэффективно.

Quality Gates
Чтобы не тратить время, деньги и силы на исправление дефектов после этапа разработки, мы начали сдвигать влево этап тестирования, чтобы он приходился на более ранние этапы жизненного цикла продукта.
Для начала «включили» Quality Gate на покрытие юнит-тестами в каждой системе и в каждом сервисе, которые используют наш пайплайн. Нужно было чтобы каждая команда по мере развития своего продукта на регулярной основе пилила «юниты». Их создание должно войти в привычку, как чистка зубов по утрам.
Если вы еще этот этап не прошли, готовьтесь — будет много БОЛИ. Всем некогда, всем надо срочно, быстро и вот прямо сейчас, а тесты мешают. Но результат стоит того. Уже через месяц аналитика показала, что количество функциональных дефектов на этапе тестирования снизилось вдвое. Да, срез пока довольно маленький: покрытие тестами розничных продуктов пока около 40%, но мы планомерно идем к увеличению покрытия.
Кроме этого в ворота добавили статический анализ кода, проверки на уязвимость, а в скором времени добавим контрактные и импакт-тесты.
Вторые «ворота» ориентированы непосредственно на процесс деплоя. Они включает в себя базовые проверки кода на жизнеспособность — Health Check. А после этого, в зависимости от того, какие ресурсы есть у команды, прогоняются ручные и автоматизированные тесты.
Версионирование
Семантическое версионирование, стандарты которого мы хотим использовать, влияет на производство косвенно. Но это важный шаг в налаживании взаимодействия как между самими командами, так и между разработкой и потребителем. В этой концепции всего три постулата, но благодаря им можно выстроить выпуск релизов без выпуска новых версий зависимых пакетов. Если вы еще не используете его, настоятельно рекомендуем к прочтению.
Этот стандарт описывает обязательства, которых надо придерживаться при реализации взаимодействия сервисов и команд между собой. Если сформулировать совсем коротко: сохраняйте обратную совместимость при изменении сервисов.

Номера версий должны четко соответствовать стандарту. Чтобы соблюдать SemVer-правила, перед деплоем в Nexus это соответствие дополнительно проверяется скриптами (на Python). Ничего задеплоить не выйдет до тех пор, пока все не будет по правилам.
Номера версий должны четко соответствовать стандарту. Чтобы соблюдать SemVer-правила, перед деплоем это соответствие дополнительно проверяется скриптами (на Python). Ничего задеплоить не выйдет до тех пор, пока все не будет по правилам.
Что бывает если на это забить? Некая компания выпускает минорный апдейт некоего продукта. Некий разработчик смотрит на набор фичей, читает описание релиза и решает, что все это ему надо. Ставит обновление. Все падает. Начинается головная боль: надо разобраться что произошло, пофиксить, откатить все обратно, предпринять меры, чтобы такое не повторилось. В зависимости от того, что именно обновлялось и как именно упало, голова может болеть от месяца до полугода.
Тут можно вспомнить Apple. Компания любит своих пользователей, любит продавать им крутые продукты, но при этом совершенно ненавидит разработчиков. Когда выходят обновления инструментов, iOS и MacOS, то каждый раз (по нескольку раз за год) ломается основная среда разработки — Xcode. Даже после минорных обновлений производство может встать из-за того, что приложения перестают собираться.
Feature Toggle
Еще одна важная история — Feature Toggle. Мартин Фаулер в своей статье описывает четыре типа тоглов. Самый базовый и основной для нас сейчас — тоглы релиза, которые позволяют выключить не готовый функционал. Если нужно выпустить срочный патч, но при этом мы работаем над новой фичей, то гораздо проще залить на прод все разом, выключив не готовое. Так мы избежим последующей проблем слияния новых фичей и патчей и обезопасим себя от раскатки на прод неготового функционала.
Плюс к этому, разработку можно вести более гибко: когда несколько команд работают над какой-то фичей, то часть каждой можно выкатывать в прод в выключенном состоянии. После того как соберутся все куски, фичу можно либо сразу включить, либо допатчить перед этим в (опять же в нерабочем состоянии).
Еще один тип — тоглы сопровождения. Они помогают обеспечить плавную раскатку функциональности. С их помощью можно, например, включать функции в зависимости от географического положения пользователя. Таким образом можно раскатать новые фичи на 1%, проверить, что у них все работает нормально и затем плавно доводить этот показатель до 100%.
Тоглы прав доступа. В них нам важна возможность сегментирование функциональности по группам. Определенный клиент увидит только то, что предназначено конкретно для него (примеры групп: обычный клиент, премиум, студент, пенсионер и т.п).
Последний тип тоглов — A/B-тесты — самый интересный с точки зрения бизнеса. С их помощью можно создать несколько вариантов одной фичи и раскатать каждый на определенную группу/количество пользователей. А затем посмотреть, какой принес большую конверсию и в автоматическом режиме выпустить его уже на всех.
API First и контрактное тестирование
Перед тем, как писать код, нужно заключить контракт (используем стандарт OpenApi 3.0 и AsyncAPI) с тем, с кем хотим интегрироваться. В контракте прописываем спецификации, версионируем, фиксируем с потребителем и отдаем в разработку. А затем используем автоматизированные контрактные тесты, которые проверяют соответствие описания и реализации определенного контракта. По сути, это набор регрессионных тестов, с помощью которых мы можем отследить отклонение от контракта на раннем этапе. В итоге все, что не соответствует спецификациям, не пролезет в Quality Gate.
Много тестовых полигонов не нужно
Еще одна проблема, которую нужно решить — наши тестовые системы не унифицированы. При накатах обновлений не соблюдается обратная совместимость, конфиги иногда правятся руками и все это приводит к недоступности систем и проблемам в тестировании. Часто, когда команде нужен тестовый полигон, он оказывается заблокирован тестированием или недоступностью смежных систем. Это, безусловно, боль. Но тут важно не пойти у нее на поводу: командам хочется новых полигонов, где будут жить какие-то системы каких-то версий, где все будет прекрасно и удобно тестировать.
При этом мало кого волнуют проблемы обновления этих полигонов, поддержания их в актуальном состоянии и обеспечения доступности. Масштабирование — простой выход, но выход в никуда. Такой подход приведет не к решению проблем, а к их преумножению (помните про контроль версий?).
Поэтому мы приняли стратегическое решение планомерно уменьшать количество тестовых сред до минимально необходимого уровня — одной. И сейчас прикладываем усилия, чтобы на этом полигоне все системы были доступны, чтобы все накатываемые обновления сохраняли обратную совместимость, и чтобы в случае проблем на хелсчеках все безопасно откатывалось на предыдущую версию.
DORA-метрики
Чтобы понять, к чему приводят наши усилия, мы используем DORA-метрики, которые позволяют оценить качество процессов разработки и эксплуатации продуктов. Собственно, вот они:
Время внесения изменений (Lead Time for Changes). Промежуток времени между изменением кода и появлением изменений в проме. Эффективные команды обычно измеряют его в часах.
Частота развертывания (Deployment Frequency). Показывает как часто команда выпускает новые фичи на пром. В идеале изменения должны развертываться on-demand несколько раз в день.
Частота сбоев при внесении изменений (Change Failure Rate). Процент изменений кода, требующих быстрого исправления или устранения других недостатков после развертывания в рабочей среде. В идеальном мире — от 0 до 15%.
Время, которое требуется на восстановление после частичного перебоя в обслуживании или полного отказа (Time to Restore Service). Высокоэффективные команды быстро восстанавливаются после сбоев системы, тогда как менее результативным может потребоваться неделя.
Тут, честно говоря, мы пока отстаем. Если принять работу команд, выкатывающие новые фичи по нескольку раз в день за 100, а тех, кто релизит раз в два месяца за 0, то нашу эффективность по DORA можно приблизительно оценить на 45. Сейчас наша цель не только прийти on-demand-релизам, но и максимально догнать лидеров.
Подытоживая. Нельзя сказать, что мы придумали что-то новое. Все инструменты и подходы хорошо и давно известны. Нужно только собраться, переломить сопротивление внутри команд и организовать разработку в соответствии с правилами. Результаты станут видны практически сразу.
Если хотите что-то добавить или спросить — пишите в комментариях.
Комментарии (8)

MegaShIzoID
13.09.2022 06:44-1как вариант можно просто брать на работу нормальных разрабов, а не говно с курсов, ну и меньше обсуждать, а больше работать

amarao
13.09.2022 11:45Очень токсичный комментарий, который можно применять универсально к любой статье.
amarao
А где вы отлаживаете пайплайн? Я имею в виду тот самый финальный
.github.yml/.travis/,.github/workflowsи т.д.?Чем больше я в индустрии, тем с большой тоской я смотрю на процесс написания и отладки именно этого. Потому что инструментов - только print, никаких 'mock-сред" для таких монстров не завезли.
Любая попытка принести стейджинг приводит к тому, что на стейджинге всё работает, а на продакшене свои переменные, которые "привносят вкус продакшена" и их всё равно отлаживают на продакшене.
Casus
С болью в отсутствии инструментария - согласен. Хоть и helm charts + argocd + crossplane очень помогают разгрузить пайплайн. Можно еще глянуть на стандарт Open Application Model. Но это все не про тесты пайплайна. Остаются ручные тесты на дев, или таки есть варианты получше?!
Вот про боль со вводом стейджинга - не понял. Если речь про пайплайны, то как и зачем им отличаться от прод окружений с технической точки зрения? С коротко-живущими еще понятно..
п.с. к авторам ни какого отношения не имею.
onegreyonewhite
Если говорить про результаты, то возможно testinfra, которая проверяет уже сам результат выкатки. Но это прям узкая часть.
Иногда с короткоживущими даже проще. Яркий пример из практики. Инфраструктура на проде у определённого проекта 60-80к облачных денег в месяц, а на тестовом сервере в подсобке - 0к/мес (ну фиг с ним, купим PC под нужды за 100к). Пример утрированный, но у условного облака один набор инструментов CD, а у стейджинга допустим этого нет (причин может быть больше, почему нет).
Если с короткоживущими можно поднять и опустить окружение потратив ресурсы за час, то стейджинг это условная "песочница", которая работает постоянно.
Casus
Речь о пайплайнах, а не том что выкатывается. Пайплайн должен абстрагироваться от деталей сервиса.
Коротко-живущие пайплайны отличаются от остальных енвов, как раз наличием доп. шагов по поднятию/тушению необходимой инфры и сервисов. Чего не должно быть для условного пре-прод.
Представленный пример с существенным отличием инфры дев/прод проблема не техническая, а финансовая. За что платят - то и получают. И еще не известно экономят ли..
amarao
Я спросил, где вы проверяете, что ваш финальный .yaml файл (в CI) рабочий. Интеграционное тестирование секретов, кода и данных.
Я в своей карьере столько нажрался ситуаций, когда стейджинг отполирован до блеска, но в продакшене секреты другие, и там всё при деплое начинает "как-то не так себя вести", что прям из профессии хочется уйти.
dmconst
К сожалению, в Банке так же нет специальных инструментов по полноценной отладке pipelines.
Есть возможность отлаживать Kotlin-код pipelines, как цепочки вызовов, но исполнительная часть (ansible, python и т.д) не может быть проверена, пока не будет запущена.
Решаем вопрос унификацией используемых пайплайнов под разные стеки и последующим их тиражированием. Вначале все равно приходится проходить сложный путь откладки.
Такая унификация отчасти решает и проблему в различной конфигурации стейджинга с продом, но это отдельная проблема. Важно использовать единый инструментальный стандарт, единую архитектуру, единые образы виртуальных машин, базовые образы контейнеров и т.д.