

PyTorch — среда глубокого обучения, которая была принята такими технологическими гигантами, как Tesla, OpenAI и Microsoft для ключевых исследовательских и производственных рабочих нагрузок.
PyTorch-Ignite — это библиотека высокого уровня, помогающая гибко и прозрачно обучать и оценивать нейронные сети в PyTorch. Основная проблема с реализацией глубокого обучения заключается в том, что коды могут быстро расти, становиться повторяющимися и слишком длинными. Рассматривать данную библиотеку буду, решая задачу оценки вероятности отнесения изображения к определенному классу на примере датасета CIFAR10. Чуть позже расскажу о нем подробнее. А сейчас начнем подготовку с установки и импорта необходимых библиотек.
Установка и импорт необходимых библиотек
Советую работать в сервисе GoogleColab
!pip install pytorch-igniteimport numpy as np
import matplotlib.pyplot as plt
import torch
from torch import nn, optim
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import torchvision
from torch.utils.data import sampler
from torch.utils.data.sampler import SubsetRandomSampler
from ignite.engine import Events, create_supervised_trainer, create_supervised_evaluator
from ignite.metrics import Accuracy, Loss, RunningAverage, ConfusionMatrix
from ignite.handlers import ModelCheckpoint, EarlyStoppingТеперь подробнее рассмотрим датасет CIFAR10. Он содержит 60 000 изображений в 10 классах. Все изображения размером 32х32. С помощью следующего блока кода разобью данные на тестовые, тренировочные и валидационные.
transform = transforms.Compose( [transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = datasets.CIFAR10('./data', download=True, train=True, transform=transform)
train_loader = DataLoader(trainset, batch_size=4, shuffle=True)
validationset = datasets.CIFAR10('./data', download=True, train=False, transform=transform)
classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')
validation_split = .2
shuffle_dataset = True
random_seed= 42
dataset_size = len(validationset)
indices = list(range(dataset_size))
split = int(np.floor(validation_split * dataset_size))
if shuffle_dataset :
np.random.seed(random_seed)
np.random.shuffle(indices)
val_indices, test_indices = indices[split:], indices[:split]
val_sampler = SubsetRandomSampler(val_indices)
test_sampler = SubsetRandomSampler(test_indices)
val_loader = torch.utils.data.DataLoader(validationset, batch_size=4,
sampler=val_sampler)
test_loader = torch.utils.data.DataLoader(validationset, batch_size=4,
sampler=test_sampler)
print(f'Кол-во валидационных данных {len(val_loader)}')
print(f'Кол-во тестовых данных {len(test_loader)}')
print(f'Кол-во обучающих данных {len(train_loader)}')Предлагаю посмотреть, как выглядят наши изображения. Код ниже выводит изображение из датасета и подписывает к какому классу оно принадлежит.
def imshow(img):
img = img / 2 + 0.5
npimg = img.numpy()
print(f'Размер изображения {npimg.shape}')
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
train_loader = DataLoader(trainset, batch_size=1, shuffle=True)
dataiter = iter(train_loader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
# print(' '.join('%5s' % classes[labels[j]] for j in range(1)))
print(f'Класс изображения {" ".join("%5s" % classes[labels[j]] for j in range(1))}')
train_loader = DataLoader(trainset, batch_size=64, shuffle=True)Теперь разберу архитектуру модели. На изображении ниже схематично показано, как работают сверточные нейронные сети. У нас есть 2 основных слоя: Conv_1 и Conv_2. Между ними идет увеличение найденных уникальных признаков Max-polling. После прохождения по всем слоям происходит подключение функции активации Relu. Перед тем как сеть определит, к какому классу принадлежит изображение, подключается dropout, чтобы избежать переобучения модели. И после этого на выходе получается предполагаемый класс изображения.

Далее разберу основные компоненты сети.
class Mod(nn.Module):
def __init__(self):
super(Mod, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 5)
self.pool = nn.MaxPool2d(2, 2)
self.bn1 = nn.BatchNorm2d(16)
self.conv2 = nn.Conv2d(16, 32, 5)
self.bn2 = nn.BatchNorm2d(32)
self.fc1 = nn.Linear(32 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.bn1(x)
x = self.pool(F.relu(self.conv2(x)))
x = self.bn2(x)
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
# return x
return F.log_softmax(x,dim=1)Метод Conv2d создает набор сверточных фильтров, их задача состоит в обработке изображений небольшим фильтром, который переходит по изображению небольшими шагами. Это основа сети.
BatchNorm2d выполняет функцию нормализации.
Maxpooling сохраняет наиболее активные пиксели из предыдущего слоя, укрупняет масштаб полученных признаков. Другими словами, ключевые области, которые определяют изображение к определённому классу, делает более крупными.
Слои Linear и Dropout, нужны для того чтобы избежать переобучения.
В качестве функции активации используем Relu. Relu все отрицательные числа делает равным 0, а положительные остаются без изменения. Блок кода ниже создает экземпляр созданной ранее сверточной сети, а также задает функцию потерь и скорость обучения. Теперь можно провести небольшое исследование с переменной lr(Learning rate), чтобы посмотреть, как меняется результат в зависимости от скорости обучения. На графике оранжевая линия означает lr=0.001, а синяя lr=0.1. Как видим, данная переменная играет важную роль в настройке модели.

model_classification = Mod()
criterion = nn.CrossEntropyLoss()
def opt(rate):
optimizer = optim.SGD(model_classification.parameters(), lr=rate, momentum=0.9)
return optimizer
optimizer = opt(0.001)Воспользуемся метриками из ignite.metrics, которые хотим рассчитать для модели: Accuracy, ConfusionMatrix и Loss. Далее передам их механизмам оценки, которые будут вычислять эти показатели для каждой итерации.
epochs = 12
trainer = create_supervised_trainer(model_classification, optimizer, criterion)
metrics = {'accuracy':Accuracy(),'nll':Loss(criterion),'cm':ConfusionMatrix(num_classes=len(classes))}
train_evaluator = create_supervised_evaluator(model_classification, metrics=metrics)
val_evaluator = create_supervised_evaluator(model_classification, metrics=metrics)
training_history = {'accuracy':[],'loss':[]}
validation_history = {'accuracy':[],'loss':[]}
last_epoch = []Отследить потери для каждого шага можно, запустив данный блок.
RunningAverage(output_transform=lambda x: x).attach(trainer, 'loss')Теперь настрою обработчик потерь EarlyStopping.
def score_function(engine):
val_loss = engine.state.metrics['nll']
return val_loss
handler = EarlyStopping(patience=20, score_function=score_function, trainer=trainer)
val_evaluator.add_event_handler(Events.COMPLETED, handler)Данный обработчик может приостановить процесс обучения. В случае, если потери проверочного множества не уменьшатся, процесс обучения остановится досрочно.
Далее просмотрим 2 функции, которые печатают результаты работы с набором данных. Одна функция делает это с обучающими данными, а другая с данными для проверки (валидационными).
Первая функция использует декоратор “trainer.on()”. Это означает, что декорируемая функция будет прикреплена к тренировочной функции и будет вызываться в конце каждого прогона обучения.
@trainer.on(Events.EPOCH_COMPLETED)
def log_training_results(trainer):
train_evaluator.run(train_loader)
metrics_trian = train_evaluator.state.metrics
accuracy = metrics_trian['accuracy']*100
loss = metrics_trian['nll']
last_epoch.append(0)
training_history['accuracy'].append(accuracy)
training_history['loss'].append(loss)
print(f"Training Results - Epoch: {trainer.state.epoch} TRAIN_accuracy: {round(accuracy,2)} TRAIN_loss: {round(loss,2)}".format(trainer.state.epoch, accuracy, loss))Вторая функция предполагает использование метода add_event_handler. При этом достигается тот же результат, что и выше.
def log_validation_results(trainer):
val_evaluator.run(val_loader)
metrics_val = val_evaluator.state.metrics
accuracy = metrics_val['accuracy']*100
loss = metrics_val['nll']
validation_history['accuracy'].append(accuracy)
validation_history['loss'].append(loss)
print(f"VAL_Training Results - Epoch: {trainer.state.epoch} VAL_accuracy: {round(accuracy,2)} VAL_loss: {round(loss,2)}".format(trainer.state.epoch, accuracy, loss))
trainer.add_event_handler(Events.EPOCH_COMPLETED, log_validation_results) Теперь проверю модель. Это важный шаг, так как процессы обучения могут занимать много времени и, если по какой-то причине во время обучения что-то пойдет не так, контрольная точка модели может помочь перезапустить обучение с точки отказа.
Буду использовать обработчик Ignite ModelCheckpoint для проверки моделей в конце каждого прогона обучения.
checkpointer = ModelCheckpoint('./saved_models', 'CIFAR10', n_saved=2, create_dir=True, save_as_state_dict=True, require_empty=False)
trainer.add_event_handler(Events.EPOCH_COMPLETED, checkpointer, {'CIFAR10': model_classification})Далее запущу обучение нашей модели на 24 epochs. Другими словами, модель пройдет обучение 24 раза. И после каждого раза будет виден результат обучения.
trainer.run(train_loader, max_epochs=24)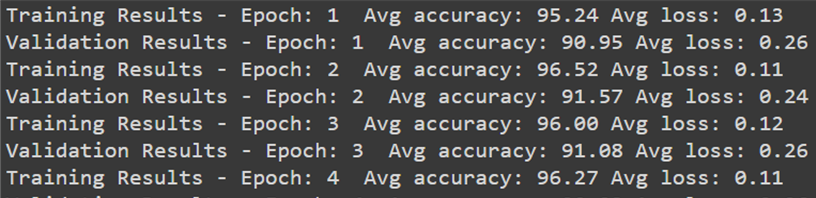
Результат обучения модели
Если при тесте данной модели вы увидите accuracy 100, это может означать два варианта:
Модель начала переобучение. Она, как студент, который просто заучивает правильные ответы и даже не понимает, что учит.
Ваши тестовые данные такие же, как тренировочные. Важно следить за качеством данных и не забывать их менять.
Визуализирую данные об обучении модели на обучающих и валидационных данных.
Вывод графика истории на обучающих данных.
plt.plot(training_history['accuracy'],label="Training Accuracy")
plt.plot(validation_history['accuracy'],label="Validation Accuracy")
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(frameon=False)
plt.show()Вывод графика истории на валидационных данных.
plt.plot(training_history['loss'],label="Training Loss")
plt.plot(validation_history['loss'],label="Validation Loss")
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(frameon=False)
plt.show()Код ниже будет использоваться для вывода данных из модели и визуализации результатов.
classes = ['plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck']
def predict_class(batch_size):
test_loader = torch.utils.data.DataLoader(validationset, batch_size=batch_size,sampler=test_sampler)
dataiter = iter(test_loader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
outputs = model_classification(images)
_, predicted = torch.max(outputs, 1)
print(labels)
print('DATA: '+' '.join(f'{classes[labels[j]]}' for j in range(batch_size)))
print('PRED: '+' '.join(f'{classes[predicted[j]]}'for j in range(batch_size)))
label_dataset = [classes[predicted[j]] for j in range(batch_size)]
label_predict = [classes[labels[j]] for j in range(batch_size)]
kol = 0
for i in range(batch_size):
if label_predict[i] == label_dataset[i]:
kol+=1
print(f'Правильно классифицировано: {(kol/batch_size)*100}%')
predict_class(40)Результат:

В заключении я сравню реализацию нескольких задач с данной библиотекой и без нее.
Первая задача вывод значений accuracy и loss.
PyTorch-Ignite
train_evaluator.run(train_loader)
metrics_trian = train_evaluator.state.metrics
accuracy = metrics_trian['accuracy']*100
loss = metrics_trian['nll']
print(f"Training Results - Epoch: {trainer.state.epoch} TRAIN_accuracy: {round(accuracy,2)} TRAIN_loss: {round(loss,2)}".format(trainer.state.epoch, accuracy, loss))PyTorch
train_epoch_loss=0
train_epoch_accuracy=0
def metrics_accuracy(pred, train):
pred = torch.log_softmax(pred, dim = 1)
_, pred = torch.max(pred, dim = 1)
res = (pred == train).sum().float()
accuracy =res/train.shape[0]
accuracy = torch.round(accuracy * 100)
return accuracy
for train_img, train_label in train_loader:
optimizer.zero_grad()
label_train_pred = model_classification(train_img).squeeze()
train_loss = criterion(label_train_pred, train_label)
train_accuracy = metrics_accuracy(label_train_pred, train_label)
train_loss.backward()
optimizer.step()
train_epoch_loss += train_loss.item()
train_epoch_accuracy += train_accuracy.item()Вторая задача преждевременная остановка обучения.
PyTorch-Ignite
handler = EarlyStopping(patience=10, score_function=score_function, trainer=trainer)
val_evaluator.add_event_handler(Events.COMPLETED, handler)PyTorch
val_loss_list.append(val_epoch_loss/len(val_loader))
if len(val_loss_list)>1:
if val_loss_list[-2] < val_loss_list[-1]:
trigger_times += 1
if trigger_times > patience:
print('Early stopping!')
break
else:
trigger_times = 0Даже по двум задачам видно, на сколько данная библиотека сокращает объем кода.
Я рассмотрел основные функции данной библиотеки, а также сравнил выполнение некоторых задач без использования PyTorch-Ignite и с использованием.
george3
Это аналог pytorch-lighting/fast.ai или есть еще какие плюшки?
george3
сам нашел) https://towardsdatascience.com/pytorch-lightning-vs-pytorch-ignite-vs-fast-ai-61dc7480ad8a
NewTechAudit Автор
Lightning И Ignite выполняют примерно одни и те же задачи, одно из ключевых отличий, у Lightning есть возможность вызывать некоторые функции из коробки, которых нет в Ignite. Например обучение на нескольких графических процессорах. А у Fast.ai нет некоторых функций например преждевременной остановки обучения или сохранения контрольных точек.