

Наверное самое популярное действие, которое приходится выполнять для исследования криптографии сегодня это процедура анализа зловредного кода, который блокирует чьи-то данные с использованием кастомного или общепринятого алгоритма. Попробуем в этой статье рассмотреть зловред и понять какие криптографические алгоритмы он использует.
ВНИМАНИЕ: Вся информация представленная в статье предоставляется исключительно в образовательных целях. Все файлы, которые будут рассматриваться в качестве примеров ни в коем случае нельзя запускать или исследовать вне тестовой виртуальной среды!
Объект исследования
Для поиска алгоритма будем использовать файл с вот такой контрольной суммой - 38035325b785329e3f618b2a0b90eb75.
Файл можно найти на просторах сети. Файл является 32 битной версией исполняемого файла для операционной системы windows. Попробуем идентифицировать алгоритмы шифрования, которые использует данный файл.
Для анализа будем использовать операционную систему Kali Linux с инструментом Ghidra на борту.
Анализ файла 38035325b785329e3f618b2a0b90eb75
Загружаем файл в ghidra и пробуем искать данные, которые могли бы нам помочь идентифицировать используемый зловредом алгоритм шифрования. Из прошлого выпуска статьи мы знаем, что для идентификации можно использовать:
Пробуем искать функции, которые используются для криптографии через WinAPI.
Константы, которые зашиты в алгоритм.
Куски кода, которые наиболее эффективно выполняют базовые операции с данными.
Каждый зловред, который обладает схожим функционалом обязательно будет скрывать содержимое своего файла. Достигается это обычно использованием кастомного алгоритма шифрования сегментов кода, такое преобразование легко заметить, если рассматривать файл в шестнадцатеричном редакторе. В глаза будет бросаться структура файла, которая практически не будет иметь пустого места. В таком случае файл придется предварительно распаковать чтобы продолжить поиски. С этим файлом нам повезло, поэтому можно сразу искать необходимые данные.
И так, файл не использует библиотеки операционной системы для криптографии, это видно по функциям импорта:

Обычно для ускорения процесса поиска алгоритма шифрования используют скрипты, которые содержат наиболее распространенные константы. К сожалению, таких констант обнаружить не удалось, но пролистав немного код, удалось найти вот такой интересный участок:

Это ни что иное как инициализация большого числа нулями, то есть ОЧЕНЬ большого числа. Можно предположить, что алгоритм приложения либо выделяет очень много памяти для дальнейшей обработки, либо перед нами алгоритм ассиметричной криптографии.
Такие алгоритмы обычно используют достаточно большие числа, которые становятся основой для генерации данных необходимых для проведения шифрования. А так как современное компьютерное железо не в состоянии сразу выделять такое количество памяти в стандартных регистрах процессора, поэтому приходится данные обрабатывать порционно. Обычно шаг для выбора размера числа это 1024.
Чтобы понять какой длины наше число нужно посчитать количество строк, которые заполняются нулями, мы получим следующее число: DWORD*64=2048 это как раз размер данных, который подходит для работы ассиметричного алгоритма.
А вот теперь плохие новости, придется смотреть алгоритм в виде ассемблерного листинга, чтобы понять какие операции происходят далее. Это должно подсказать что это за алгоритм.
Что конкретно стоит ждать от алгоритма далее. Ассиметричная криптография целиком и полностью базируется на математически неразрешенных проблемах. Или проблемах, которые имеют решение только в заданном количестве случаев. Для таких проблем очень часто примитивными операциями являются математические действия:
умножения
возведения в степень
взятие по модулю.
Для этих операций процессор intel может использовать вот такие команды:
SBB
RCL/RCR/ROL/ROR
ADC
Ниже мы можем заметить вот такие куски кода:

Судя по преобразованиям это часть так называемой операции возведения в степень. Здесь через оптимальный способ проводится сдвиг битов на 1. Что эквивалентно умножению на 2, но так как работа происходит не с одним значением, а по сути с 32х битной последовательностью, то возмещение в степень будет работать только с небольшими корректировками, которыми занимается алгоритм на фото ниже:

Стоит так же заметить, что здесь происходит процедура взятия модуля, то есть можно предполагать, что происходит возведение в степень по какому-то заданному модулю. Такие операции могут указывать на алгоритм RSA. Его подробное описание можно найти тут.
Попробуем поискать еще алгоритмы. Теперь для поиска воспользуемся базой популярных сигнатур для определения алгоритма.
В качестве теста попробуем найти вот этот набор констант:
A5 63 63 C6 84 7C 7C F8И вот результат:
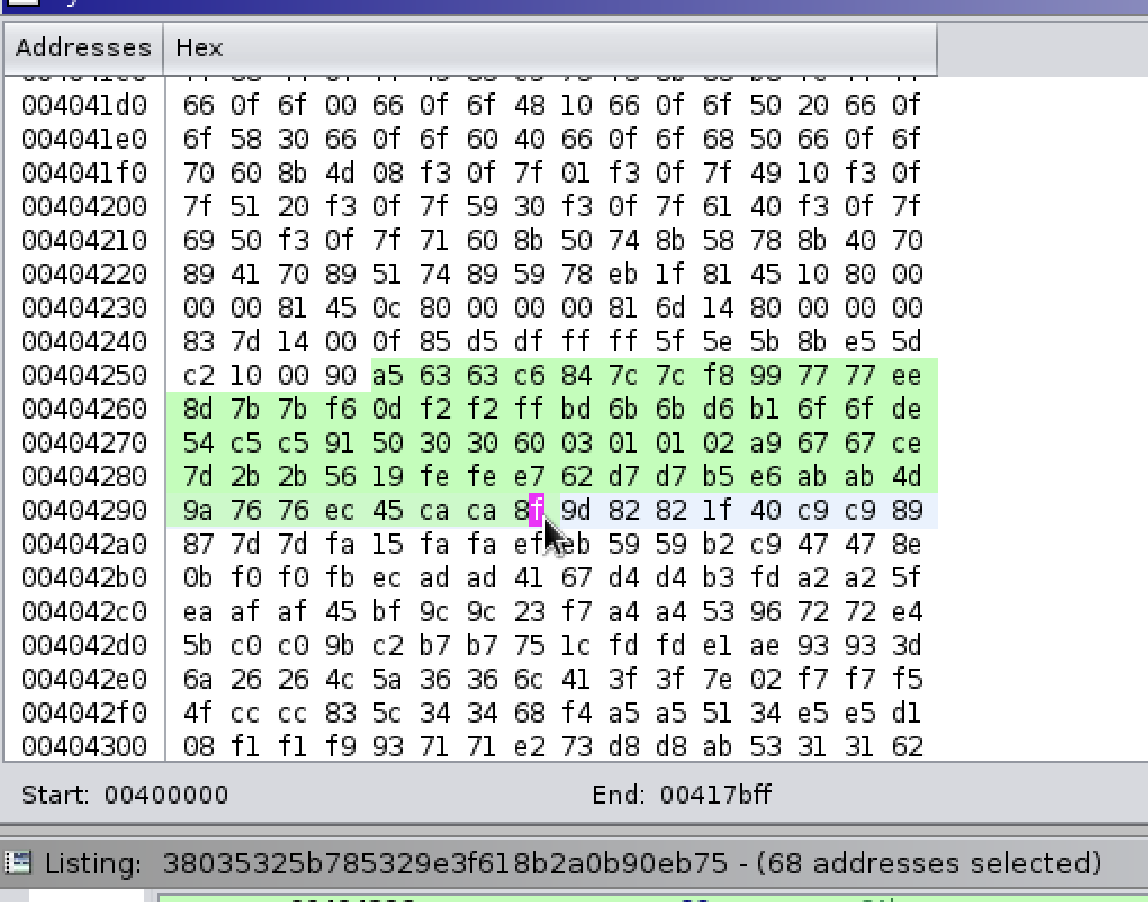
И вот этот код будет его использовать:

Итого, у нас 2 алгоритма шифрования ассиметричный RSA и семмитричный AES. Судя по всему такой набор не случаен и будет использоваться открытый ключ для проведения процедуры шифрования, а затем ключ будет удаляться, после этого удаления только злоумышленник сможет снова восстановить файлы, так как скорее всего только у него будет на руках закрытый ключ от этого зловреда.
Таким образом можно выяснять какие алгоритмы используются зловредами и далее анализировать насколько хороши имплементации. В случае, если злоумышленник ошибся, то возможно есть шанс получить данные обратно.
В качестве задания для самостоятельного изучения - попробуйте найти еще один криптографический алгоритм, который спрятан в этом файле.
Статья подготовлена в преддверии старта курса Reverse-Engineering от OTUS
SnailGolden
Спасибо