
Много раз при обсуждении преимуществ и прелестей Go, как языка разработки, мне приходилось слышать что-то вроде «у вас даже нет дженериков» или «вот завезут дженерики, тогда и поговорим». Так вот, дженерики завезли, давайте посмотрим что из этого вышло.
Меня зовут Павел Грязнов. Я уже несколько лет пишу на Go в прод, хотя знакомство с языком начал с самых ранних версий. Видел как Garbage Collector мог сделать stop the world на пару секунд, страдал от отсутствия системы зависимостей и других проблем. В этой статье я расскажу о дженериках в Go. Что изменилось с выпуском релиза 1.18, в чём особенность синтаксиса дженериков, когда они нужны и когда лучше обойтись другими инструментами. Всё на примерах, одна практика.
Чтобы лучше показать работу дженериков на контрасте, я сравню примеры их использования на двух языках — Python и Go. C Python последний раз работал слишком давно, поэтому вторую часть доклада мне помогли сделать коллеги из Evrone. Пойдем по порядку: разберем, для чего нужны дженерики и какие задачи они решают. Посмотрим, как выглядит мир без дженериков, на их синтаксис, ограничения, бенчмарки и немного затронем функциональное программирование.

Важная роль дженериков в том, что они сокращают количество ошибок в работе с кодом.
Для языков со статической типизацией, когда типы указывает разработчик, дженерики позволяют уменьшать дублирование кода, при этом сохраняя безопасность.
Для языков с динамической типизацией, которые выбирают типы во время исполнения, дженерики позволяют более гибко давать Type hints (аннотации типов), чтобы наши средства проверки также избавили нас от ошибок во время написания и во время выполнения кода.
В обоих случаях у разработчика меньше шансов написать что-то не то.
В период, когда дженерики в Go только вводили, в сообщество активно обсуждало, какими они будут. Мы читали много негативных мнений, что это ненужная штука, они усложняют язык, делают наш прекрасный, простой Go каким-то подобием Java, и все мы закончим очень плохо.
После того, как дженерики вышли, плохие прогнозы не сбылись и негативные высказывания пропали. На мой взгляд, всё хорошо. Но давайте посмотрим, какие альтернативы у нас были до выхода дженериков.
Ручная мономорфизация
Этот безусловно используемый каждым разработчиком паттерн позволяет нам не потерять в скорость за счёт удобства. Переводя на понятный язык – копипаста. Если вы скопировали функцию min() для Int, изменив тип на Int-64 – вы провели ручную мономорфизацию.
Проблема такого подхода в том, что всё это надо поддерживать. Если есть какие-то изменения в функциях, нужно менять каждую. Следить за этим спагетти кодом не самое приятное дело.
Интерфейсы
С интерфейсами можно, пожертвовав статической типизаций, избежать излишнего повторения. Стоит ли оно того? Вроде бы приводить интерфейсы к определённым типам дело несложное, но это дополнительное пространство для ошибок и дополнительный слой абстракции. Как результат: интерфейсы всегда будут медленнее, да и удобны далеко не для каждого кейса.
Рефлексия
Наш могущественный пакет Reflect, который позволяет заглядывать в структуры данных, в интерфейсы и выяснять, что там. Штука достаточно сложная и требует определенного опыта применения от разработчика. Сложность кода увеличивается, скорость работы уменьшается кратно (даже сравнивая с интерфейсами), количество ошибок не снижается.
Кодогенерация
В этом случае не нужно менять код, всё генерируется автоматически. Статическую типизацию и снижение числа ошибок мы тоже получаем. На мой взгляд, из четырех альтернатив этот вариант самый лучший.
Проблема в том, что это уже дополнительный шаг в изучении Go. Недостаточно знать Go и его синтаксис, надо узнать что такое yacc грамматика. Я видел не так много разработчиков, активно использующих этот инструмент. Честно скажу, что и сам я его в повседневной работе не применяю.
Как видите, альтернативы дженерикам есть, но каждая из них не лишена минусов.
Как выглядит мир без дженериков
Переходим к практике. Возьмем Python и Go, сделаем простую функцию, которая что-то складывает, и поместим туда два числа. Пока никаких дженериков, функция максимально простая, но что будет если мы будем её неправильно использовать? Например, передадим туда число и строку — получим exception.
def add(a, b):
return a + b
add(1, 1) == 2
add(1, "1") # Exception :(Go нас от подобных результатов оберегает, так что даже exception мы получить не сможем – компилятор просто откажется собирать исполняемый файл. В Go код придётся копировать под каждый тип данных.
func add(a, b int) int {
return a + b
}
func add64(a, b int64) int64 {
return a + b
}
func add32(a, b int32) int32 {
return a + b
}
...С дженериками мир выглядит интереснее. После того, как в Python мы ввели дополнительный тип данных, дженерик-тип, наши средства проверки кода смогут указать нам на наши ошибки. Это помогает избежать ошибок в рантайме.
Python
T = TypeVar("T")
def add(a: T, b: T) -> T:
return a + b
add(1, 1) == 2
add(1, "1") # Type check error :)Go
func add[T additive](a T, b T) T {
return a + b
}Вот он, этот редкий момент, когда код на Go компактнее, чем код на Python, и при этом достаточно понятен.
Синтаксис дженериков на Go
Теперь разберём синтаксис дженериков.
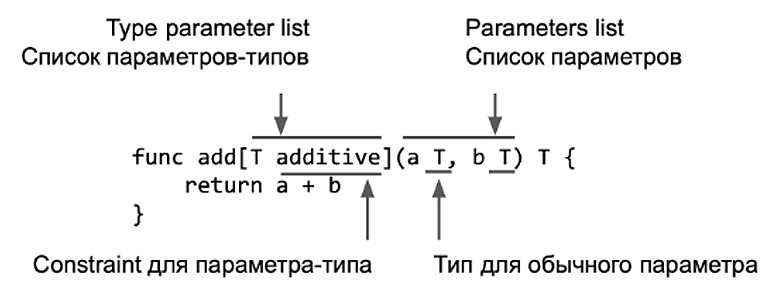
Квадратные скобки [...] — это место для описания дженерика.
Т — это название дженерик-типа.
Additive — ограничение для дженерика или Constraint.
Теперь, вместе с обычным списком параметров – parameter list — у нас есть type parameter list.
Также есть список для обычного параметра, тип для нашего типа и Constraint, ограничение для дженерика.
Ограничения для дженериков
Первый вариант ограничения дженериков – «снизу», или по типам. В данном примере компилятор проверит используем ли мы нужный тип, а также тот факт что типы переменных одинаковы.
Python
T = TypeVar("T", int, float, complex)
def add(a: T, b: T) -> T:
return a + b
add(1.0, 1.0) == 2
add("foo", "bar") # Type check errorGo
type additive interface {
int|~uint64
}
func add[T additive](a T, b T) T {
return a + b
}
// Constraint literal
func add[T int|~uint64](a T, b T) T {
return a + b
}Ограничения или contraint’ы для дженериков задаются через уже знакомые нам интерфейсы. Теперь в них можно указывать не только список функций/методов, но и список типов. При этом, для ограничения не обязательно вводить отдельный интерфейс. Можно прямо в функции перечислить типы, которые вы хотите использовать. Стоит отметить, что включать в интерфейс одновременно методы и типы нельзя.
В этом перечислении обратите внимание на новый символ перед uint64. Перед нами новый токен «~». Это ещё одно нововведение в Go.
Тильда «~» означает, что мы не просто используем тот тип, который указали, а что мы можем использовать все типы, которые к нему сводятся. Другими словами, мы можем определять свои типы поверх стандартных, определять для них методы и использовать их в наших дженерик-функциях.
type additive interface {
int|uint|~uint64
}
type myUint uint64
func add[T additive](a T, b T) T {
return a + b
}
x, y := myUint(0), myUint(1.18)
z := add(x, y)Второй способ — ограничения дженериков «сверху».
Python
T = TypeVar("T", bound=Sized)
def longer(x: T, y: T) -> T:
if len(x) > len(y):
return x
else:
return yGo
type Stringer interface {
String() string
}
func Tos[T Stringer](s []T) []string {
var ret []string
for _, v := range s {
ret = append(ret, v.String())
}
return ret
}Когда в Python задаём Bound-Sized, то получаем ограничение на то, что у нас переменная должна иметь какую-то длину.
В Go для подобных ограничений можно использовать любой интерфейс. Тем не менее, если есть возможность просто использовать интерфейс, лучше так и делать. Это будет не только понятнее, но и быстрее (более подробно в разделе про бенчмарки).
Также есть встроенные сontraint'ы, например Comparable. Он позволяет задать ограничения для сравниваемых типов (имеются в виду только операторы эквивалентности и неэквивалентности, то есть == и !=).
// comparable
// ==
// !=
func Index[T comparable](s []T, x T) int {
for i, v := range s {
if i == x {
return i
}
}
return -1
}Неограниченные дженерики
Итак, у дженериков есть ограничения, но мы можем их использовать и не задавая никаких ограничений.
В Python в этом плане мало что поменяется: если не задать ограничений в функции add, то мы будем проверять только тот факт, что аргументы имеют одинаковый тип.
T = TypeVar("T") # Что угодно
def add(a: T, b: T) -> T:
return a + b
add(foo, bar)В Go всё не так просто. Для функции сложения использовать неограниченные дженерики не получится, поскольку Go компилятор проверяет все возможные случаи использования дженерика. И так как мы не можем сложить два интерфейса, две структуры, два слайса или две хэш-таблицы, то должны задать ограничения таким образом, чтобы все типы которые могут им удовлетворить работали с оператором «+». В данном случае подойдёт “constraints.Ordered”.
func add[T constraints.Ordered](a T, b T) T {
return a + b
}
func add[T interface{}](a T, b T) T {
return a + b // Error
}Ещё одно нововведение для неограниченных дженериков — ключевое слово any. Это синоним интерфейса.
func add[T additive](a T, b T) T {
return a + b
}
// any это interface{}, не умеет складываться
func add[T any](a T, b T) T {
return a + b // Error
}Дженерики в классах и структурах
Используя дженерики в классах Python, можно сделать например Bucket, который что-то хранит. Нам не важно что, конкретный тип мы определим только в момент инициализации структуры.
class Bucket(Generic[K, V]):
add(val: V) -> K: ...
get(key: K) -> V: …В Go точно такой же Bucket будет задаваться немного по-другому: нужно будет повторять описание дженерика (или дженериков) в каждом методе.
type Bucket[K, V any] struct {
...
}
func (b *Bucket[K, V]) add(v V) K { ... }
func (b *Bucket[K, V]) get(k K) V { ... }После того, как мы описали эти классы и структуры, их нужно инициализировать. Для этого мы явно указываем тип, который будем использовать в структуре. Так как в итоге структура данных будет содержать какой-то конкретный тип, который удовлетворяет нашему констрейнту, указывать тип при инициализации обязательно.
Python
# Только для классов
bucket = Bucket[str, int]()
key = bucket.add("answer")Go
var b Bucket[string, int]
key = b.add("wine")Когда мы говорим о функциях, указать её тип в Python невозможно. В Go мы можем указать тип дженерик функции при вызове.
func Switch[T any](v interface{}) int {
switch v.(type) {
case T:
return 0
default:
return 1
}
}
S0 := Switch[string]("x") // return 0
S1 := Switch[int]("x") // return 1Но это не обязательно, потому что чаще всего компилятор выводит тип функции самостоятельно. Такой вывод он может сделать исходя из типа аргументов которые мы туда передаем. Если на место дженерика мы передали строку, очевидно, что мы хотим в данном случае функцию, работающую со строкой, если передали число, значит с числом.
func Ret[T any](v T) T {
return v
}
// "Type inference": вывод типов
S0 = Ret("a") + "bc" // "abc"
S1 = Ret(1) + 2 // 3Параметризирование дженериков: составное и комплексное.
Python
T = TypeVar("T")
def scale(list[T], T) -> list[T]:
...Go
func Scale[S []~E, E int](s S, sc E) S{
r := make(S, len(s))
for i, v := range s {
r[i] = v * c
}
return r
}С появлением дженериков мы наконец-то смогли делать функции для работы со слайсами любого типа и хэш-таблицами любого типа. Это и называется составным параметризованием.
Но сейчас важно подчеркнуть отличие в типизации между Pythonом и Go. Именно из-за этих особенностей функция на Go включает два дженерик-типа, а не один, как в Python.

Дело в том, что в Python — structural typing, а в Go – nominal typing. Для того чтобы лучше показать различия, давайте мы возьмём один дженерик-тип Е и просто укажем переменную как список, как слайс из этого Е.
func Scale[E int](s []~E, sc E) []E {
r := make([]E, len(s))
for i, v := range s {
r[i] = v * c
}
return r
}
type Point []int
func (p Point) String() string { ... }
func ScaleAndPrint(p Point) {
r := Scale(p, 2)
fmt.Println(r.String())
}В целом функция получится рабочая. Но, если мы проскалируем нашу точку, а потом попробуем вызвать один из её методов от результата, мы получим ошибку. Дело в том, что Go сведёт нашу точку к слайсу, как мы и указали в определении функции который мы передали. В данном случае []E станет []int и мы просто потеряем тип нашей точки.

Поэтому для того, чтобы сохранить тип, который мы передаём в функцию, нужно ввести новый type-parameter.
func Scale[S []~E, E int](s S, sc E) S{
r := make(S, len(s))
for i, v := range s {
r[i] = v * c
}
return r
}
type Point []int32
func (p Point) String() string { ... }
func ScaleAndPrint(p Point) {
r := Scale(p, 2)
fmt.Println(r.String())
}Комплексное параметризирование
За этим термином скрывается тот случай, когда мы вводим новые дженерики в методах класса или структуры. Т.е. не те что мы указали при определении структуры, а те что мы хотим добавить для этого конкретного метода. В Python это делать можно, а в Go, к сожалениею, пока такую фичу не завезли. Есть определенные сложности с компиляцией, а именно с тем чтобы оставить её такой же простой и быстрой как сейчас..
Почитать об этом подробнее можно в Type Parameters Proposal. Можно, даже поучаствовать в обсуждениях того как это всё же реализовать и предложить какое-нибудь новое решение этой проблемы. Кто знает, может когда-нибудь в Go появится и комплексное параметризирование.
Benchmarks part.
Бенчмарки: время работы и время компиляции
Сначала посмотрим на скорость работы дженериков. Спойлер: они получились быстрыми.
Время работы
Чтобы проверить скорость, сделаем функцию Contains, которая проверит, что в слайсе есть какой-то искомый элемент. Реализуем её в двух вариантах: с дженериками и основанную на пакете reflect.
Go 1.18 (generic)
func ContainsG[T comparable](s []T, e T) bool {
for _, a := range s {
if a == e {
return true
}
}
return false
}Go 1.17 (reflect)
func ContainsR(in interface{}, elem interface{}) bool{
inValue := reflect.ValueOf(in)
if inValue.Type().Kind() != reflect.Slice {
panic("'in' is not a Slice")
}
for i := 0; i < inValue.Len(); i++ {
if equal(elem, inValue.Index(i)) {
return true
}
}
return false
}
func equal(e interface{}, val reflect.Value) bool {
if val.IsZero() {
return val.Interface() == e
}
return reflect.DeepEqual(val.Interface(), e)
}Обратите внимание какой большой получилась реализация на reflect. Скажу вам больше: эта реализация не покрывает всех возможных случаев, то есть могло быть ещё сложнее. А теперь сравним скорость работы:
Тест
const l = 1000
func Benchmark____(b *testing.B) {
s := make([]int, l)
for i := 0; i < l; i++ {
s[i] = i
}
for n := 0; n < b.N; n++ {
Contains___(s, l-1)
}
}Результаты
[0] $ gotip test -bench=.
goos: linux
goarch: amd64
cpu: Intel(R) Core(TM) i5-8365U CPU
Reflect 19527 64353 ns/op
Generic 3909652 292.7 ns/op
Native 3977557 307.3 ns/opКак мы видим (и как многие уже знают) reflect работает очень медленно. А дженерики работают также же быстро, как нативный код. В данном случае даже чуть-чуть быстрее, но это не закон, а скорее погода на Марсе. С каждым запуском, то дженерики, то нативная имплементация будет быстрее.
Пробуем другой эксперимент.
Давайте предположим, что дженерики вводят некий уровень абстракции при вызове функции и он нам чего-то стоит. Для проверки этой гипотезы – сделаем рекурсивную функцию которая будет вызывать себя множество раз. Отдадим дань классике и реализуем вычисление элемента ряда фибоначчи. Один вариант с интерфейсами (которые точно добавляют нам слой виртуализации), с дженериками и нативную.
Тест
func Benchmark__(b *testing.B) {
for n := 0; n < b.N; n++ {
Fib__(20)
}
}
func Fib_(a T)T {
if a <= 1 {
return a
}
return Fib_(a-1) + Fib_(a-2)
}Результаты
[0] $ gotip test -bench=.
goos: linux
goarch: amd64
cpu: Intel(R) Core(TM) i5-8365U CPU
Interface 13354 88085 ns/op
Generic 37729 32275 ns/op
Native 39980 32544 ns/opКак мы можем видеть, дженерики снова работают со скоростью нативного кода, в то время как интерфейс — медленно. Разрыв не такой большой как с reflect, но замедление в данном случае значительное.
Время компиляции
Если дженерики работают также быстро, как нативная функция, то что же со временем компиляции? Были опасения, что проекты будут очень долго собираться. Спойлер: всё в порядке.
Чтобы продемонстрировать это, сгенерируем 10 000 абсолютно одинаковых функций Max с дженериками и 10 000 с нативными типами.
Go 1.18 (generic)
type number interface {
~int | ~int32 | ~int64 | ~float32 | ~float64 | ~uint | ~uint64
}
func MaxGeneric0001[T number](a, b T) T {
if a > b {
return a
}
return b
}Go 1.17 (native)
func MaxInt0001(a, b int) int {
if a > b {
return a
}
return b
}Выглядит всё почти одинаково. Попробуем скомпилировать.
Сначала я скомпилировал всё без реальных вызовов функции (функция просто вводила «Hello, world»), и у нас была дополнительная нагрузка в виде 10 000 функций. Компилировалось довольно долго, я даже не ожидал что это займёт целых 3,5 секунды на моём ноуте. Каково же было моё удивление, когда запустив компиляцию для примера с дженериками я получил бинарник меньше чем через секунду.
Статическая типизация
[0] $ time gotip build -o ogo static.go dummy_main.go
real 0m1.347s
user 0m3.566s
sys 0m0.192sДженерики
[0] $ time gotip build -o ogo generics.go dummy_main.go
real 0m0.499s
user 0m0.843s
sys 0m0.097sОтсюда можно сделать следующий вывод: если в коде объявлена дженерик-функция, то компилятор будет собирать реальные функции, только для тех типов, на которых она была вызвана.
То есть, теоретически код на дженериках может быть быстрее. На практике это маловероятно, вряд ли вы захотите определять кучу функций которые вы не используете. Скорее всего код будет компилироваться столько же времени, или даже чуть дольше. Хотя, в случае подключения библиотек с набором из тысяч функций дженерик функции могут компилироваться быстрее.
Если мы добавим 10 000 вызовов функций которые мы сгенерировали, то мы уже не получим значительной разницы в скорости компиляции.
Статическая типизация
[0] $ time gotip build -o ogogo static.go calls_main.go
real 0m5.614s
user 0m9.924s
sys 0m0.423sДженерики
[0] $ time gotip build -o ogogo generics.go calls_main.go
real 0m5.419s
user 0m10.395s
sys 0m0.409sДженерики компилируются дольше, ведь компилятору нужно проверить какие функции и на каких типах были вызваны чтобы их компилировать. С моей субъективной точки зрения разница незначительна.
Что ещё нужно знать про производительность и скорость дженериков
Примеры, которые я показал с нативными типами — это самые простые варианты применения дженериков. С нативными типами дженерики действительно работают очень быстро. Но, например, с указателями всё будет немного иначе.
С одной стороны, при использовании стандартных типов и структур дженерики сделают мономорфизацию, то есть внутри исполняемого файла будет функция под каждый тип. Но вот для указателей, прямо в рантайме будет создана хэш-таблица, которая будет хранить словарь указателей на функции. Следуя документации, отдельная функция из дженерик-функции в Go будет скомпилирована не под каждый тип, а под каждый так называемый GC Shape. Напомню, что большая часть методом вызывается на указателях, а значит их вызов будет также требовать поиска по хэш-таблице.
Если вы хотите детально разобраться в том, что такое GC Shape и какой конкретно эффект этот уровень виртуализации оказывает на ваш код – предлагаю сделать это с помощью потрясающей статьи Generics can make your Go code slower. На хабре есть перевод этой статьи, но я очень рекомендую заглянуть в оригинал, так как в нём есть анимированные ассемблерные вставки. С ними понятность материала поднимается на качественно новый уровень.
С названием, кстати, я согласиться не могу. Я бы хотел назвать её Generics can make your Go code a little bit slower. По факту этот уровень виртуализации вносит задержку сравнимую с задержкой которую вносят интерфейсы. Хоть это и мешает нам использовать дженерики в местах где производительность критична, для всех остальных случаев значительного оверхеда не будет. Реальное замедление измеряется в единицах микросекунд.
Функциональное программирование
Пользуясь случаем, хочу немного про рассказать про функциональное программирование в Go. В своей работе я очень часто применял такую библиотеку как go-funk. В ней есть множество примеров функционального программирования — Map, Reduce, ForEach и другие. Но, к сожалению, всё на интерфейсах и reflect. Соответственно, все возвращаемые типа надо проверять, плюс работает это медленно.
strs := funk.Map([]int{1, 2, 3}, strconv.Itoa).([]string)
fmt.Println(strings.Join(strs, " + "), " = 6")
func Map(arr interface{}, mapFunc interface{}) interface{} {
... // что-то сложное
}Теперь посмотрим на имплементацию Map с дженериками: она короткая, понятная, возвращает известный нам тип который не надо проверять и работает на порядок быстрее.
func Map[F, T any](s []F, f func(F) T) []T {
r := make([]T, len(s))
for i, v := range s {
r[i] = f(v)
}
return r
}
strs := Map([]int{1, 2, 3}, strconv.Itoa)
fmt.Println(strings.Join(strs, " + "), " = 6")К моменту написания этой статьи появилась новая библиотека для функционального программирования на Go с использованием дженериков.
Выводы
Подведем итог, когда дженерики полезны и когда их удобно применять:
Для составных типов данных таких как slice и map. Теперь не нужно реализовывать отдельные функции под каждый тип данных который мы туда кладем – можно использовать дженерики.
В структурах общего назначения. Мы можем использовать алгоритмические библиотеки для деревьев, которые хранят что угодно, и при этом использовать преимущество строгой типизации. Теперь можно делать библиотеки для связных списков, двусвязных списков, деревьев и подобного.
Когда нужно избежать повторений — если код выглядит одинаково для разных типов, дженерику в этой функции самое место.
Случаи когда дженерики не нужны и даже вредят довольно очевидны:
Когда всё что вам нужно это вызвать метод: если есть возможность обойтись интерфейсом, лучше использовать интерфейс.
Когда имплементация общего метода для разных типов отличается: если мы передаем разные значения, то ожидаем разное поведение от функции.
Резюмируя в одном предложении: дженерики стоит использовать, чтобы избежать повторения, и не стоит использовать, пока вы не начали повторяться.
И напоследок, вот вам материал для дополнительного чтения, который использовался для подготовки статьи.
Go generics: the hard way — репозиторий с исследованием работы дженериков
GopherCon: R Griesemer & Ian Lance Taylor — лекция от создателей дженериков
Уже скоро в Москве начнется HighLoad++. До 24 ноября есть время определиться и ознакомиться с программой докладов . Если коротко: будет 8 секций и 120 новых докладов. Все подробности на официальном сайте конференции.


lazy_val
Объясните, пожалуйста, бестолковому, что это за две звезды после имени функции? Go 1.19 такую конструкцию отказывается понимать
GRbit Автор
Нда, если со стороны посмотреть как-то неоднозначно вышло. Я их отводил для номера функции, типа что я сгенерировал функции MaxInt0001, MaxInt0002 и так далее. Пожалуй, лучше заменить на номер. Спасибо)