
В современном мире приложение — это огромная связка микросервисов. Функционально её протестировать сложнее, чем монолит. Кто-то решает это единым staging’ом и чатиком синхронизации: «займу auth на полчасика». Другой уходит с головой в shift-left или тестирует в canary. Разберём, как катнуть веточку сервиса и получить свой личный staging.
Меня зовут Евгений Харченко, я инженер в платформе Авито. В мою ответственность входят процессы и технологии, которые связаны с разработкой кода и внедрением его в продакшен. Сегодня я хочу поговорить о том, как организовать работу с фича-ветками при разработке.

У нашего приложения есть некое продакшен-окружение — это то, куда ходят пользователи, то есть совокупность развернутого кода и баз данных, с которыми этот код работает. Как правило, возникает окружение, которое я здесь называю staging. Им пользуются сотрудники компании для тех или иных проверок до того, как код приложения попадёт в продакшен. Это окружение недоступно пользователям и использует БД отличную от продакшена. В некоторых случаях это может быть сэмплирование с продакт.
Под фича-ветками я буду подразумевать окружения, которые создаются для конкретного пользователя или малой группы пользователей — например разработчиков или тестеров. Делается это для того, чтобы посмотреть в эксплуатации разрабатываемую фичу.
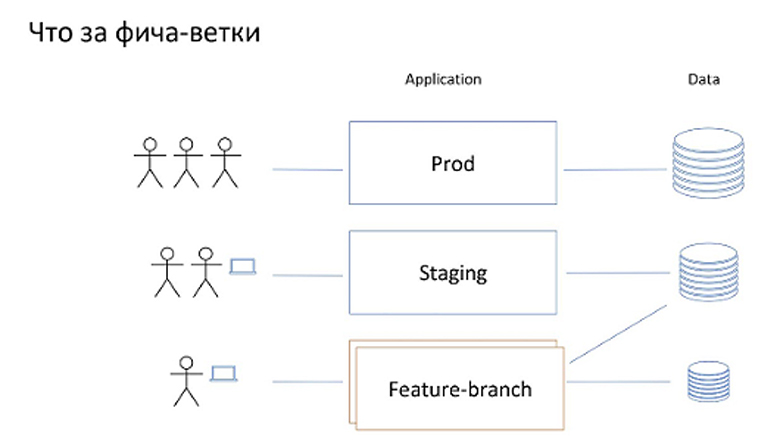
Это окружение может работать как с выделенной своей базой данных, так и с базой данных staging.
Когда мы работаем с монолитной архитектурой нашего сервиса, то, что у нас сейчас нарисовано на картинке, по сути, идентично схеме деплоймента. То есть мы выкатываем наш монолит в прод, в staging и N раз выкатываем инстансы для фича-веток.
Однако с микросервисами всё работает немного не так.
Микросервисная архитектура
Как у нас выглядит микросервисная архитектура с точки зрения путешествия трафика от пользователя до какого-нибудь глубоко залегающего сервиса?

На клиенте есть тот или иной фронтэнд. Например, это может быть мобильное приложение, React или Angular. Он посылает запросы на входной сервис. Назовём его gateway. В его задачу входит обогащение данных, проксирование к одному или нескольким бекэндам и сборка ответов. При этом бекэнд-сервисы, которые уже обладают данными из своей доменной области, в свою очередь, тоже могут взаимодействовать с соседними сервисами по бизнес-задачам.
1-ый подход
В такой схеме, если мы попробуем создавать фича-ветки так же как для монолита, то получим достаточно дорогое решение.
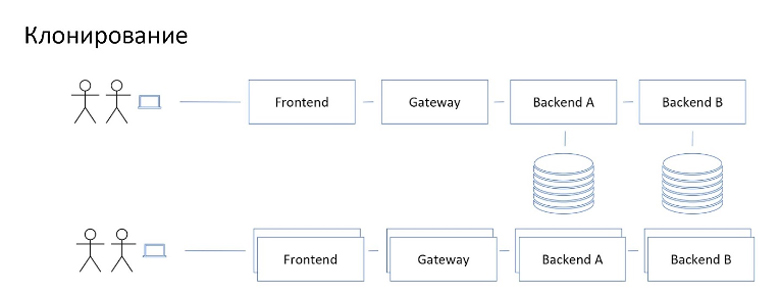
Дело в том, что в крупных проектах могут быть десятки и сотни микросервисов, их дорого разом поднимать для каждого желающего. Да и просто-напросто долго. Деплоймент — это не мгновенная история.
Хотя для некоторых узких случаев этот подход всё ещё работает и даже эффективно. В частности, когда супермало микросервисов или можно выделить суб-домен большого микросервисного приложения для отдельной команды.
В отсутствии возможности поднять каждому собственый mini-staging для фича-веток пользователи уходят в другие варианты решения проблемы. Среди таких вы встретите shift-right’еров — людей, которые будут катить сервисы фичи в продакшен в канареечном режиме на ноль процентов пользователей. И через какой-нибудь секретный url они попадают в продакшен в свою редакцию сервиса, чтобы посмотреть, как приложение работает с данными.
Также вы встретите радикальных shift-left’еров. Они говорят, что у них есть микросервис. У него есть строгий контракт, который нужно соблюдать, а всё, что вне него, их не интересует. У кого-то это работает, но, естественно, не у всех получается, потому что многим в конечном счёте захочется видеть, как фича работает в интегрированном режиме.
2-ой подход
Все остальные в какой-то момент попадают в коммуналку, в которую превращается staging. Что я имею в виду? Они пишут в чатике slack mattermost: «Я займу staging своей веточкой», выкатывают сервис с ветки на staging и смотрят, как всё в совокупности работает.

У такого подхода есть два значимых недостатка.
Первый недостаток — это необходимость таймшеринга, то есть синхронизация через чатик, в результате чего один сервис не сможет одновременно работать с двумя фича-ветками. Соответственно, этот подход работает только в достаточно небольших командах.
Второй недостаток будет себя проявлять даже в маленьких командах. Он заключается во взаимном влиянии сервисов друг на друга. Когда в staging постоянно катятся непроверенные до конца изменения с фича-веток, в целом снижается стабильность системы. Таким образом, если пользователь, который разрабатывает бекэнд, выкатил какую-нибудь свою непроверенную ветку, то пользователь, который разрабатывает фронтэнд, в этот момент не может полноценно насладиться своей фича-веткой на staging по той причине, что бекэнд говорит «кря». По опыту, это случается достаточно часто. Чем больше людей, тем чаще.
Фича-ветка для фронта
В контексте фича-веток в микросервисной архитектуре фронтендеры - главные бенефициары. Во-первых, у них есть интерес именно в системном, интегрированном подходе к тестированию. Они работают с визуалом. Соответственно, они хотят посмотреть, как их изменения на фича-ветках будут выглядеть для пользователей.
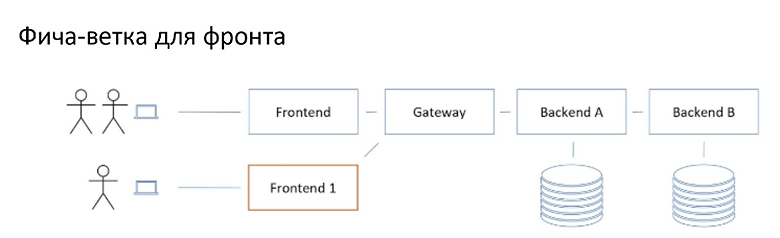
И у них есть такая возможность. Так как они на рубеже непосредственно перед пользователями. Они могут выкатить свою ветку фронтэнд сервиса рядом с основной из staging‘a, направить upstream-запросы в общий staging и благополучно щупать свои изменения, не мешая никому другому.
Фича-ветка для гейта
Следующими приходят те, кто также сильно завязан на интеграцию между различными сервисами: владельцы gateway.

У них, в принципе, тоже не сильно сложно. Можно точно так же выкатить рядом, походить курлом, и если очень хочется, то поднять рядом ветку фронтэнда, которая будет завязана на наш инстанс гейтвея.
Фича ветка для бэка
Дальше уже всё интереснее при таком подходе.
Если полноценный бекэнд захочет воспользоваться подобным способом, то ему уже по этой схеме нужно выкатить минимум два сторонних сервиса для того, чтобы полноценно всё посмотреть.
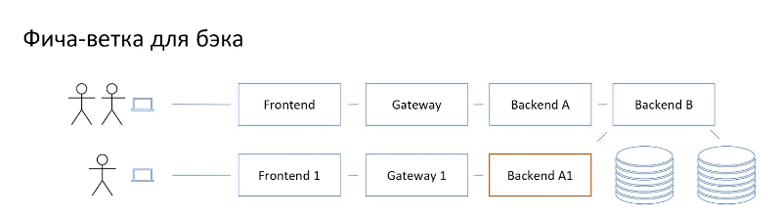
И это если сильно повезёт. На практике проявляются сложные цепочки по которым пользовательский трафик доходит до сервиса. В самых неудачных случаях придётся поднять чуть ли не весь staging для того, чтобы получить полноценную фича-ветку. Картинка будет примерно такая.

В пределе она эквивалентна тому, как выглядит просто режим клонирования.
Таким образом, данный подход не очень работает кроме некоторых специфичных случаев.
Использование динамического контура
До этого момента мы говорили о статическом связывании, когда мы деплоим сервис и в его конфигурации указываем, по каким адресам ходить в его апстримы.
Альтернативный подход — это использование динамического контура, когда для принятия решения о том, куда конкретно идти в апстрим, мы опираемся не только на статическую конфигурацию, но и на метаданные входящих запросов.
В этой схеме мы в изначальный запрос, идущий через основные адреса staging’a, добавляем метаданные, которые говорят, что при попытке пойти в бекэнд А нужно вместо него пойти в деплоймент ветки бекэнда А1.
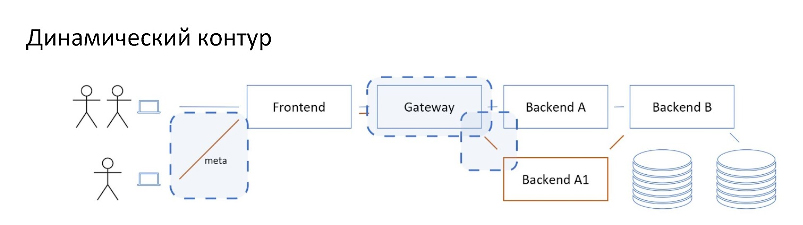
При такой схеме есть возможность сосуществования нескольких веток, за счёт закидывая запросы с разными метаданными.
Мы можем собирать в один динамический контур несколько разных сервисов, просто указав в метаданных переадресацию для каждого из них.
Главное, этот способ дешёвый по ресурсам и по времени развёртывания контура. В минимальном случае цена равняется деплойменту одного сервиса. Это меньше, чем было с монолитом.
Посмотрим, как это реализовать технически и какие методические проблемы могут возникнуть.
С технической точки зрения есть три ключевых элемента:
Это сам механизм роутинга, то есть возможность в какой-то момент принять решение на основе метаданных, что мы идём не в основной апстрим, а куда-нибудь ещё.
Это механизм доставки этих метаданных, так как метаданные нужно доставить до точки принятий решений для того, чтобы они сработали.
И это способ указания этих самых метаданных для того, чтобы дальше с ними что-то сделать.
Но перед этим ещё пара важных моментов.
Использование трейсинга
Такая система с точки зрения работы очень похожа на магию. А всё, что очень похоже на магию, приводит к тому, что возникают магические проблемы.
Чтобы сделать эту систему менее магической и более контролируемой, наблюдаемой, очень рекомендуется использовать трейсинг.
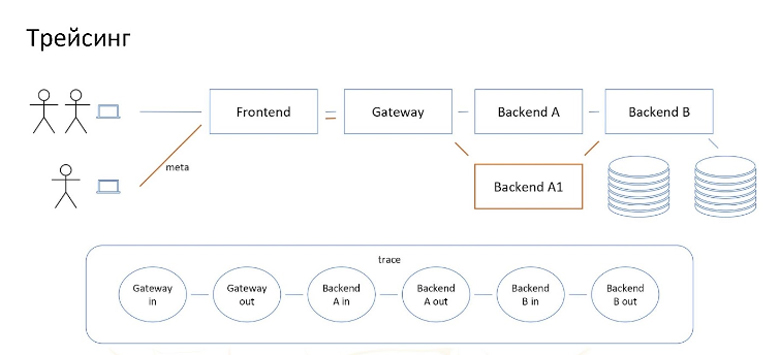
Для нужд рассказа трейсинг — это сохранение спанов. Спан — это интервал времени, в который что-то происходит. Спаны могут быть связаны между собой, то есть один может быть вложен в другой. И совокупность таких связанных между собой спанов называется трейсом, иначе говоря это карта того, что происходило в момент выполнения запроса.
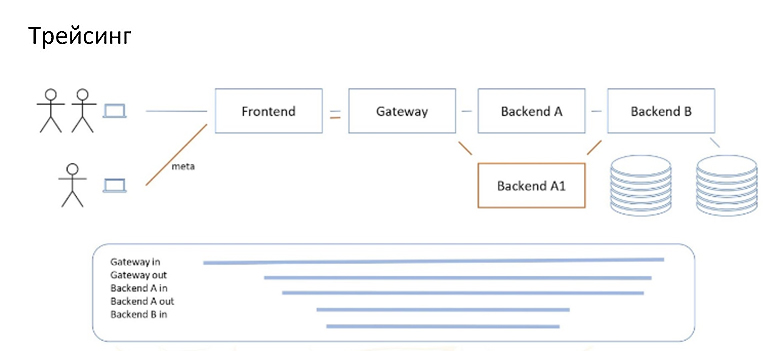
Нас интересуют, в первую очередь, спаны запроса входящего в сервис и исходящего из сервиса. Обратите внимание, что это отдельные сущности. Здесь они вложены, но с точки зрения того, как трафик доходит до какого-нибудь глубокого сервиса, мы можем вполне нарисовать их в виде цепочки пар входящего и исходящего спанов.
Хранилища данных
Ещё один важный методический момент заключается в том, как мы относимся к хранимым данным при обработке запроса в схеме с заменой одного сервиса на другой.
У нас есть два варианта. Мы можем для фича-ветки использовать:
Отдельный инстанс базы данных, не связанный со staging’ом.
Тот же инстанс базы, в который ходит staging.
Подход с отдельным инстансом часто интуитивно выбирается из соображений, что в такой ситуации проще накидывать те или иные мок-данные, ведь “мы не обязаны заботиться о сохранности данных, которые там есть”. Например, можем бесконечно играться с миграциями, зная что не испортим staging и день всем остальным разработчикам.
Но при этом, к сожалению, возникают интеграционные конфликты. Допустим, у нас есть бекэнды А и Б, каждый из которых со своей базой. Они вроде бы отделены, но на самом деле фактически cвязаны между собой через id объектов. Например, у нас есть сервис, который обеспечивает транзакции аренды самокатов, и мы разрабатываем на фича-ветке сервис, который занимается хранением данных самих самокатов.
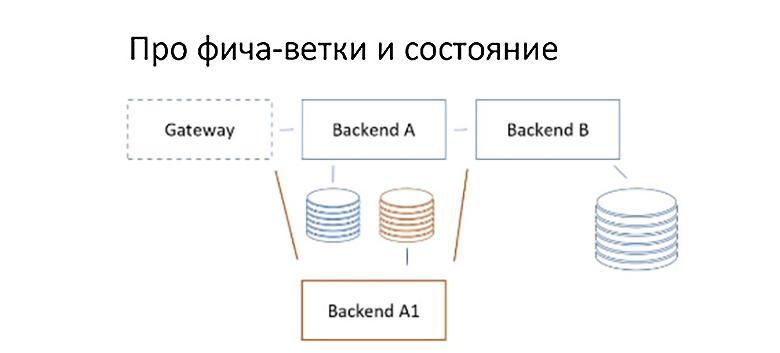
Всё бы хорошо, но когда мы смотрим со стороны staging’a, то есть со стороны любого другого пользователя нашего бекофиса, то он может увидеть сеанс проката самоката созданный на базе в стейджинге, но ссылающийся на id самоката, в стейджинге несуществующего. Потому что этот самокат окажется в отдельной выделенной базе нашей фича-ветки.
Даже если в системе хорошо организован graceful degradation по данным, то всё равно будут так или иначе вылезать подобные конфликты в неожиданных местах. Самое неприятное в таких ситуациях — это то, что за разруливание этих проблем отвечает не одна команда, а разные, которые владеют разными сервисами. Как известно, там, где возникают межкомандные взаимодействия, стоимость работы увеличивается в разы.
Во втором подходе, когда используется общая база со staging’ом, подобные сложные внешние конфликты отсутствуют. Однако мы можем доиграться с миграциями и попортить экстерминату staging’a.
С другой стороны, если мы действительно нашими миграциями или несовместимой работой с данными испортим staging, то давайте радоваться, что это произошло на staging’е, а не на проде. На проде микросервисы, high availability, значит естественным образом присутствует требование того, чтобы соседние версии одного сервиса могли одновременно работать с одной и той же базой данных. Если на staging’е не увидеть проблему с миграциями или с совместной работой с данными, то рискуем увидеть её на проде, а там цена ошибки очевидно выше.
По этой причине мы рекомендуем в качестве основного режима работы с ветками сервисов использовать тот же экземпляр базы, что использует staging, то есть второй подход. Однако мы не запрещаем при большом желании поднимать отдельную базу для этой цели.
Техническая реализация
Роутинг
Первым пунктом в реализации у нас идёт механизм роутинга, то есть направление трафика, основываясь на метаданных имеющихся в запросе.
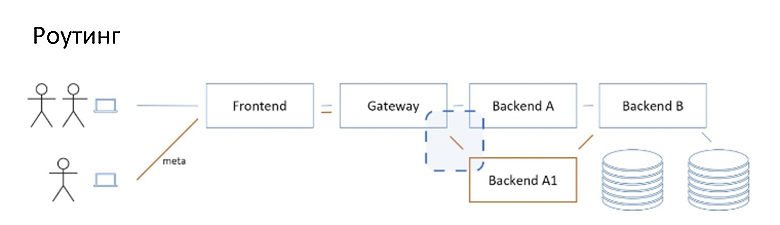
Есть опенсорсное решение от «Авито» под названием Netramesh. Используется в Авито на staging’е довольно долго, хорошо себя зарекомендовало. Что оно из себя представляет?

Это сайдкар, то есть в одном поде Кубернетиса вместе с контейнером сервиса запускается контейнер Netra, на который перенаправляется весь входящий и исходящих трафик сервиса. Что это даёт? Во-первых, Netra умеет работать с трейсингом, то есть весь входящий трафик и исходящий трафик она превращает в спаны и отправляет в коллектор. Таким образом, без подключения дополнительных библиотек внутри сервиса можно получить карту путешествия трафика в нашей системе.
Во-вторых, на исходящем трафике Netra умеет смотреть на HTTP заголовок X-Route, и при его наличии матчить значение в заголовке Host запроса. Если хост совпадает с тем, что передано в карту X-Route, то она выполняет перенаправление на указанный хост-подмену. Вот так просто. Вот пример минимальной для запуска конфигурации в кубернетисовских манифестах:

Исходники его есть на Github.
Здесь можно обратить внимание на наличие initContainer. Задача этого контейнера — перенаправить входящий и исходящий трафик на Netra.
В runtime контейнерах есть непосредственно сам сервис, который что-то делает, и контейнер с Netra. Через env задаются параметры того, что Netra будет отправлять в коллектор и какие порты слушать, а самое главное –— параметры, которые включают роутинг. Сам роутинг осуществляется на хедере X-Route. Его тоже можно переопределить, если хочется.
Конечно, перенаправление можно реализовать разными способами: можно написать плагин к envoy, можно делать его на уровне стандартных библиотек-клиентов внутри кода сервиса.
Доставка
Следующий вопрос, который нас интересует, это доставка.
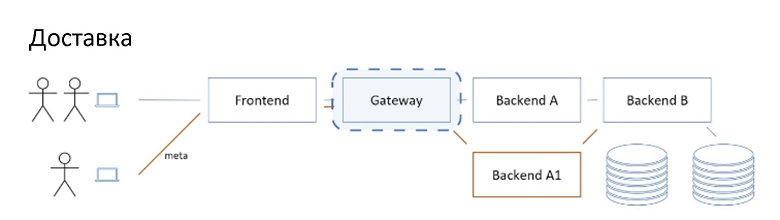
Сайдкару нужно сделать два дела: корректное сохранение трейса в Джагер и роутинг. Поэтому важно, чтобы каждый сервис на исходящих запросах, которые инициированы каким-то входящим трафиком, пробрасывал входящие метаданные дальше на выход. При процессинге нужно как-то выковырять метаданные входящего запроса, аккуратненько донести их до точек инициации исходящих запросов, и подложить.
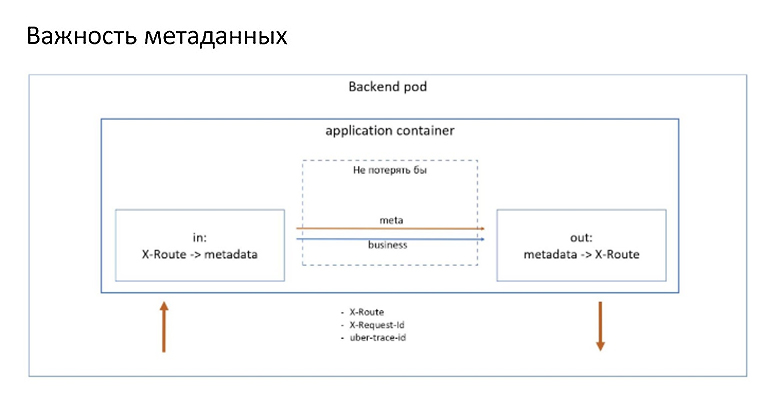
К таким метаданным в случае с Netra относятся два главных заголовка:
Это X-Route, который отвечает за роутинг, и X-Request-Id — хедер, который связывает исходящие и входящие спаны сервиса в единый трейс. Иначе никто никак не сможет понять, что этот исходящий спан инициирован именно этим входящим, а не другим, который исполнялся параллельно. Также стоит использовать стандартные трейсинговые хедеры.
Протечка
Что же происходит, если сервис не справляется с возложенной на него задачей и не пробрасывает метаданные со входа наружу? Случается протечка контура. Рассмотрим пример:
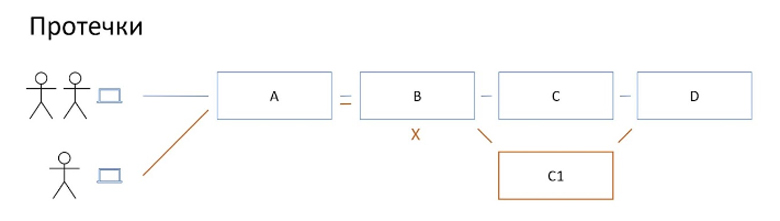
Тут сервис В не осиливает. Как результат перестаёт работать перенаправление на связке B -> C. Тегированный запрос на фича-ветку доходит до сервиса В, но дальше идет в C, а не C1: фича-ветка сервиса C1 оказывается не задействованной, то есть контур протекает в staging.
Эта ситуация очень неприятна и может быть чуть ли не блокером для того, чтобы внедрять подобную технологию, поскольку пользователям не очевидно, что они сейчас смотрят не на фича-ветку, а на staging. В лучшем случае пользователь просто потеряет время, пытаясь понять, почему его фича не работает, как надо. В худшем случае он решит, что всё работает как надо, и выкатит на прод, не узнав заранее, что на самом деле всё плохо.
Поэтому с такими протечками нужно бороться. Это ключевой момент того, чтобы система завелась.
Чтобы бороться с протечками, нужно понять, откуда они берутся.
Первый и самый банальный источник — это прямая потеря контекста, то есть были все возможности, все библиотеки, все очевидные способы эти метаданные не потерять, они просто потерялись по неосторожности. В данном почти выдуманном примере на go мы просто передали не тот контекст, который должны были.
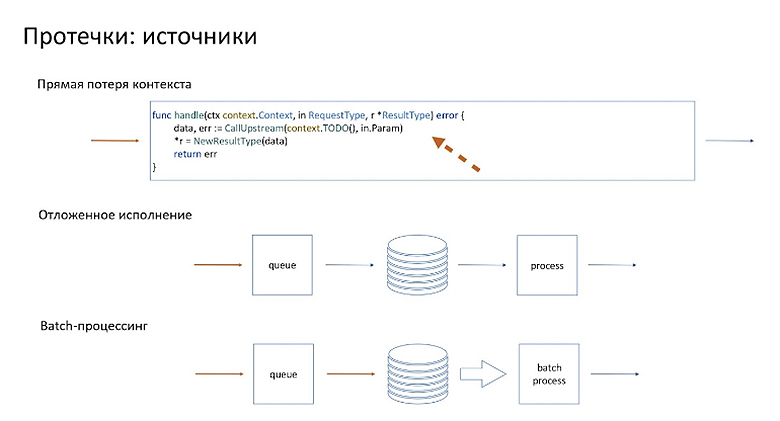
Как ни странно, это самая распространённая причина протечек. Поэтому к ней особое внимание.
Также очевидно, что для того, чтобы называть такие потери контекста “по неосторожности”, нужно, чтобы существовал и честный типовой способ проброса контекста в архитектуре приложения. Иначе говоря, должны быть:
Cтандартные гайдлайны, как это сделать;
Cтандартные библиотеки, которые позволяют вытащить контекст и положить его обратно;
Cтандартные способы для разных языков, которые вы используете, для того, чтобы пронести этот контекст через процессинг и положить его там, где нужно.
Но это простой случай, когда мы взяли и потеряли. Давайте посмотрим на более сложные источники протечки.
Мы можем взять и потерять, когда у нас есть какая-либо вариация на тему отложенного исполнения. Что имеется в виду? Например, пришёл входящий сигнал, мы его положили в какое-то промежуточное хранилище. Для определённости будем называть его очередью. Если мы положили его без метаданных, то на процессинге мы уже не можем дальше что-то роутить, потому что метаданных у нас нет.
Более радикальная версия этой истории, когда не просто отложенная обработка, а батч-процессинг.
Для того, чтобы бороться с этими ситуациями, их нужно обнаружить и решить. И самая главная трудность в том, чтобы их обнаружить.
Детектирование по трейсам
Первый самый большой помощник в том, чтобы это сделать, — это трейсинг, ради чего я его раньше и упоминал.
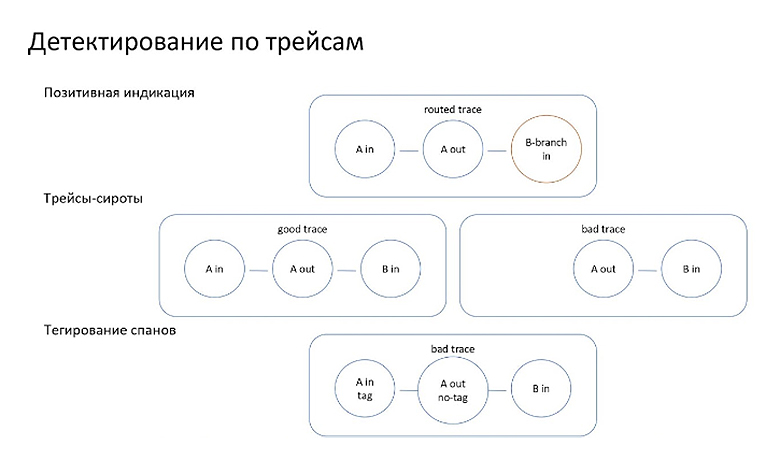
Можно ловить позитивные истории, то есть по трейсам обнаруживать те случаи, когда трафик действительно доходит до фича-ветки нашего сервиса. Это хороший индикатор, который можно использовать как зелёный флажок. Полезная вещь. Особенно когда у пользователя есть сомнение, работает ли он с фича-ветками или staging’ом.
Однако самое интересное — это не позитивные, а негативные кейсы. Для них есть волшебный способ под условным названием трейсы-сироты.
Когда сервис ведёт себя как честный-приличный, он инициирует какие-то исходящие запросы только в ответ на входящие возмутители. Если вдруг мы в трейсинге находим трейсы, начинающиеся с исходящего спана, то: либо сервис начал обладать самосознанием, либо он просто-напросто теряет метаданные по дороге, поэтому трейсинг не может связать исходящий запрос с входящим.
В принципе, можно спокойно полагаться на то, что метаданные пробрасываются либо целиком, либо никак. Просто потому, что это реализуется, как правило, в форме библиотек, а версии библиотек можно честно отследить другими способами. Значит, если связывающие хедеры, uber-debug-id или X-Request-Id не прокинулись, то, вероятно, и роутинг не будет здесь работать.
Самое приятное в этом способе, что необязательно поднимать сервисы на фича-ветках для того, чтобы увидеть в трейсинге подобные индикаторы. Достаточно собрать трейсы, которые формируются из использования общего staging’a.
Для более глубокого анализа можно расширить механики, которые пишут спаны, и дополнительно сохранять в них в виде тега информацию о том, что имелись метаданные роутинга в этом запросе. В таком случае достаточно при походах в общий staging проставить какой-нибудь тривиальный роут, не несущий практическую пользу, и дальше в трейсинге искать спаны, в которых не будет тегов о содержимом роутинга. Эти спаны будут связаны с сервисами, у которых проблемы с контекстом, с пробросом метаданных.
Трейсинг — наш самый лучший друг. Однако когда мы таким образом обнаружили все наши проблемы и побороли очевидные случаи, остаются более сложные кейсы с асинхронным процессингом.
Синхронный процессинг

Для асинхронных процессов необходимо в очередь сохранять не только бизнес-данные, но и метаданные, относящиеся к роутингу и трейсингу. А дальше для того, чтобы сама логика маршрутизации и роутинга работала как надо, нам помогут два принципа:
— Локальность
Если сервис сам кладёт какие-то события в очередь и потом обрабатывает их, то нужно просто для фича-ветки этого сервиса поднять ему отдельную очередь. Даже если в качестве хранилища данных он использует схему с общим сохраняющимся staging’ом, то при деплойменте ему нужно поднять соседнюю очередь отложенной отработки и направить туда все события . Таким образом мы гарантируем, что всё, что пришло в фича-ветку сервиса, там и останется.
— distribution engine
В случае, когда есть асинхронное взаимодействие через паттерн шины между разными сервисами, придётся чуть-чуть заморочиться. Здесь поможет добавление прослойки в виде сущности, которую назовем distribution engine. В её задачи входит отслеживание в наших событиях, очереди на основе метаданных роутинга кому эти события адресованы. Если они адресованы staging инстансам, то она отправит в staging инстансы. Если они адресованы инстансам фича-веток, то тогда нужно посмотреть: если есть на данный момент в сети, в кластере клиент, представляющий эту ветку, то она отправит их ему. Если нет, то она отправит в общий staging или задискардит в зависимости от того, что вы в конкретном случае посчитаете более целесообразным.
Такой же промежуточный агент может помогать с проблемой бач-процессинга. Идея простая: взять события подряд, которые объединены одинаковым роутингом, и отправить их суб-бачами соответствующим адресатам.
У такого дистрибьюшн агента есть ещё одно полезное свойство не относящееся к теме: он абстрагирует хранилище, таким образом, позволяя вам переехать, в зависимости от того, продуктовых требований. Например, с кролика в Кафку.
Тегирование
Последний важный технический момент — это тегирование.

В случае с Netra метаданные представляют собой хедеры. Очевидно, можно просто в явном виде дописать эти хедеры в url; использовать какой-нибудь браузерный плагин для модификации заголовков. Но это не самый удобный способ взаимодействия. Можно сделать ещё один достаточно простой компонент, который серьёзно поднимет user experience в использовании подобных фича-веток. Его задача в том, чтобы пользователь мог указать, какая фича-ветка его интересует, просто задав правильный url, которым он туда заходит. Как это сделать?
Заводим wildcard домен на внутренней сети. Называем его «k.dev». Эти запросы вне зависимости от префикса попадают в новый routing-gateway. Также в routing-gateway попадает информация из кластера или из системы деплоймента о том, какие фича-ветки сервиса в данный момент развернуты. Дальше запрос нашим гейтвеем проксируется в направлении staging’a, подмешивая необходимые x-route заголовки. В примере на картинке запрос идёт на ветку feature-x, и из кластера мы знаем, что с суффиксом feature-x раскачен сервис А. Таким образом, мы форвардим, дописывая туда x-route, который направит сервис А на его фича-ветку.

Если этот сервис обнаруживает, что в кластере нет развернутых сервисов с заданной фича-веткой, то нужно обязательно вернуть ошибку. Иначе пользователь, незаметно для себя тоже протечёт в staging и будет неприятненько. Ошибка в случае отсутствия соответствующих запрошенной фича-ветке сервисов, обязательна. Это, кстати, ещё одно маленькое преимущество по сравнению с прямым указанием хедеров: мы можем здесь это сделать.
Итог
Вот общая техническая картинка всего сказанного выше.

Мы рассмотрели:
как можно реализовать роутинг на Netra;
как отслеживать отсутствие потерь метаданных внутри самих микросервисов;
как организовывать работу с сервисами и эксплуатировать роутинг для этой цели;
как улучшить UX, задав удобный способ указания фича-ветки, на которую пользователь хочет попасть;
как работать с отдельными или с общим со staging’ом хранилищем;
как нам организовать асинхронное взаимодействие.
Осталось только поделиться опытом эксплуатации подобной системы внутри Avito.
пользователи любят;
для большинства это просто работающий продукт «к-ветки»;
постепенно втягиваются и адепты шифт-лефта;
сложная часть — старые сервисы;
упираемся в проброс метаданных в сервисах на старых библиотеках;
сложная часть — асинхронность;
решается регламентрированием разрешенных асинхронных сценариев с использованием платформенных обёрток, дающих локальность или пакетную маршрутизацию.
Во-первых, пользователи эту систему любят. Для большинства из них она в какой-то момент превращается в нечто вроде водопровода в доме: очень полезная штука, на которую никто не обращает внимание, пока она работает.
Cамая, наверное, болезненная вещь — это старые сервисы, которые не пробрасывали метаданные, использовали старые версии библиотек. Но это, в принципе, сворачивается в общую проблему работы со старыми сервисами. Как с этим бороться — обсуждалось уже много кем.
Ещё одной сложной частью была реализация роутинга и проброс метаданных через асинхронное взаимодействие. Тут нам очень помогла стандартизация. Есть несколько стандартизованных способов организации асинхронного взаимодействия внутри сервиса и между сервисами. И в этих стандартных способах на уровне сервисов и библиотек реализована работа с метаданными и имеется гайдлайн, как не потерять эти метаданные. В целом это работает.
Скоро в Москве состоится HighLoad++. Сегодня последний день, когда можно купить билет по более низкому прайсу. Там же, на официальном сайте можно ознакомиться с программой докладов, прочитать про спикеров и получить более подробную информацию о конференции.