
Всем привет! Меня зовут Костя Гусев @nevoy, и в М.Видео-Эльдорадо моя команда развивает внутренние и партнёрские продукты. Эти сервисы, как и всем привычные B2C продукты: сайты и мобильные приложения – помогают нашему бизнесу лучше понимать клиентов и удовлетворять их потребности, но делают это за счет изменения наших внутренних операций и процессов взаимодействия с поставщиками товаров.
Так, например, в прошлом году мы запустили дата-сервис по планированию «идеального» ассортимента магазинов (прочитать об этом можно здесь), а сейчас мы работаем над движком ценообразования, который сможет предсказывать оптимальную цену на наши товары на основе действий конкурентов и модели ценовой эластичности. Эти продукты влияют на клиентский опыт, переопределяя саму суть нашего товарного предложения.
Несмотря на их специфику (малая пользовательская аудитория, длинный цикл R&D, высоконагруженная архитектура), в работе над этими сервисами мы придерживаемся классического продуктового подхода, частью которого является регулярная проверка гипотез с помощью A/B-тестов. Так, возвращаясь к примерам выше, перед тем, как менять ассортимент или цены на полках 1 300 розничных магазинов, нужно быть абсолютно уверенным, что новое товарное предложение, как минимум, не приведёт к оттоку текущих покупателей, а еще лучше – привлечет новых.
Для проведения подобных экспериментов мы переработали подход к A/B-тестированию с учетом нашей офлайн-специфики, о чем и хотим рассказать в этой статье.
Часть 1. От теории к практике
В теории проведение A/B-теста не представляет особой сложности. Предположим, мы хотим оценить эффект от некого изменения в онлайне (на сайте или в мобильном приложении) или офлайне (в розничном магазине). Для этого разобьем множество исследуемых объектов на две группы: контрольную (“A”) и пилотную (“B”) – и решим, эффект на какую метрику мы хотим замерить: трафик, конверсию, средний чек и т.д. Внедрив изменение на изолированной пилотной группе, замерим разницу полученного эффекта с контрольной группой и сделаем выводы о ее статистической значимости. Если эффект на пилотном множестве превышает эффект на контрольном, открываем шампанское и празднуем успех.
Однако на практике есть несколько нюансов, которые усложняют применение этой, казалось бы, простой концепции, особенно в ритейле с большим офлайн присутствием. Вот несколько из них.
Магазин как объект наблюдения
Бывает так, что нововведение настолько масштабно, что эффект от него виден невооруженным глазом. Ну, например, применение скидки 20% и последующий рост продаж. Такой эффект все еще требует статистической проверки, однакочаще всего нововведения носят оптимизационный характер, а эффекты от них исчисляются единицами процентов. Здесь мы упираемся в то, что сам эффект является случайной величиной, колебания которой могут быть соизмеримы с тем выигрышем, который мы хотим найти.
Предположим, мы сделали какое-то изменение в работе наших магазинов. Пусть речь идет об изменении схем выкладки товара в торговом зале. Для замера эффекта мы взяли по 50 магазинов в пилотной и контрольной группах. Эффект определили как суммарные продажи всех 50 магазинов в каждой из групп за один месяц. Далее, рассчитали разницу и получили 3% – пилотная группа в выигрыше. Далее решили взять не месяц, а 6 недель, снова посчитали разницу и получили минус 1% – пилотная группа в проигрыше. Мы можем продолжать делать это бесконечно и все время получать различные значения. Все это происходит потому, что выручка магазина – это случайная величина, которая колеблется день ото дня. Сегодня магазин мог продавать на одну сумму, завтра на другую и так далее.

Соответственно, чтобы провести A/B-тест, нам нужно ответить, как минимум, на три вопроса:
Как измерять эффект?
Как долго измерять эффект, чтобы это измерение было значимым?
Как ускорить срок измерения этого эффекта?
Забегая вперёд, скажем, что простой ответ на первый вопрос – взять среднее по набору замеров. Однако одного среднего недостаточно, чтобы сделать выводы о результатах нашего теста, о чем поговорим далее. Что касается продолжительности замеров, то мы, например, можем и дальше измерять суммарную выручку магазинов за месяц, но в этом случае за год у нас будет всего 12 наблюдений и наш A/B-тест растянется на неопределенное время.
База сравнения
Если не придать этому особого значения, мы можем ошибочно сформировать пилотную и контрольную группы таким образом, что они будут изначально сильно отличаться друг от друга. Чтобы далеко не уходить от примера с магазинами, мы можем включить в пилотную группу наиболее успешные объекты по метрике выручки, а в контрольную наоборот. Мы увидим разницу, но разве она будет вызвана нашим нововведением? Другими словами, на старте тестирования мы должны уметь доказать, что выборки пилотной и контрольной групп значимо не отличались до проведения A/B-теста. Для этих целей, как и в случае, с онлайн-сервисами, мы проводим A/A-тесты, о дизайне которых также расскажем ниже.
Сопоставимостью объектов задача формирования целевой и контрольных выборок не заканчивается. Давайте для примера возьмём телевизор диагональю 85 дюймов стоимостью более полумиллиона рублей. Наша задача оценить его продажи в двух группах магазинов. Предположим, мы поставили этот телевизор на полки магазинов в небольших городах, где средняя заработная плата не превышает 40 тыс. рублей в месяц. В этом случае можно будет говорить, что этот телевизор не будет продаваться ни в пилотной, ни в контрольной группах, и никакой эффект мы не замерим. Таким образом, для пилотной группы нам нужно уметь выбирать объекты, на которых в целом резонно ожидать эффект от наших нововведений.
Бизнес-контекст
Представим, что мы хотим протестировать наш рекомендательный сервис планирования ассортимента, о котором мы говорили в самом начале статьи. Для целей A/B-теста наполним полки пилотных магазинов в соответствии с рекомендациями сервиса, полки в контрольной группе оставим без изменений и будем считать, что товар в пилотной группе будет лучше продаваться по метрике выручки.
И вот мы сформировали целевую и контрольную группу, настроили ассортимент в соответствующем приложении и ждем эффектов. Однако, магазины же не пустуют, там уже есть товар. В обычной жизни требуется время на то, чтобы новый ассортимент мог встать на полку. В разных категориях ассортимента срок оборачиваемости товара разный и иногда очень длительный. Проблема здесь не только в долгом ожидании, а еще и в том, что часть нового ассортимента встанет на полку раньше, часть позже (за счет естественной оборачиваемости), а часть может и вовсе не доехать до магазинов в силу ограниченных остатков на складах. Получается, что эффект мы еще не доказали, а в большом количестве магазинов уже может частично стоять наш «пилотный» ассортимент. Поскольку он стоит частично, то эффект замерить мы все еще не можем. Поскольку он «пилотный», то возможно, он менее эффективный, чем тот, что стоял бы на полке вместо него. Как результат, получаем недовольство менеджмента из-за потенциально негативного влияния пилота на выручку компании.
Следовательно, при подготовке к проведению любого A/B-теста (особенно розничного) важно также синхронизировать все смежные процессы, физические и виртуальные, которые потенциально влияют на его результат и продолжительность.
Теперь обо всем подробнее.
Часть 2. Решения: статистические и не очень
Вернёмся к самому первому и главному вопросу – как измерить разницу между контрольной и пилотной группами? Получить статистически значимый результат можно через серию наблюдений. Давайте сначала поймем, где мы их возьмём. Для этого применим несколько манипуляций, статистических и не очень.
Сначала применим чисто понятийный подход. Он заключается в увеличении гранулярности замеров. Этот подход в зависимости от того, что мы измеряем, все время будет разный. Рассмотрим наш пример изменений в ассортименте магазинов. Сначала возьмём только разницу продаж всех магазинов помесячно и получим 12 наблюдений в год – немного. Альтернативно сравним все магазины по отдельности и понедельно и получим количество замеров равное количеству магазинов в нашей выборке помноженное на количество недель. Уже больше. Далее, предположим, что продажи разных категорий товаров независимы между собой и получим количество замеров равное количеству магазинов, умноженное на количество категорий, умноженное на количество недель. Идеально.
Теперь применим статистическую манипуляцию – сформируем из нашей выборки много подвыборок и сравним их между собой. Таким образом мы искусственно еще раз увеличим количество замеров. Этот метод увеличения количества замеров называется бутстрапированием (bootstrapping). Метод бутстрапирования нам потребуется также позже для формирования доверительных интеровалов.
В контексте наших манипуляций возникает два новых вопроса:
Можно ли бесконечно увеличивать гранулярность, чтобы сократить продолжительность теста?
Как оценить, сколько замеров необходимо?
Гранулярность замеров, размер выборки и продолжительность теста
Итак, что будет если рассматривать не уровень категории, а уровень товара. То есть не сравнивать продажи категории телевизоры в разных магазинах, а зайти внутрь категории и сравнивать продажи конкретных моделей или, например, групп моделей в разрезе диагоналей. В этом случае возникает риск, что наши замеры будут зависимыми. Нужно иметь абсолютную уверенность (читай – провести отдельный статистический тест для каждой группы товара), что продажи телевизоров разных моделей и диагоналей независимы между собой. Если они зависимы, то каждый новый замер не добавляет ценной информации в наш тест. Кроме этого, ввиду того что мы сравниваем ассортимент, возникает риск, что каких-то товаров просто может не быть в контрольной или целевой группах. Таким образом, спускаться глубже в иерархию товаров нужно с осторожностью.
Хорошо, а что если просто перейти от замеров на уровне недели к уровню дня, часа или минуты. Здесь однозначного ответа нет, нужно считать. В некоторых случаях увеличение гранулярности добавит информацию, а в некоторых – приведёт к зашумленности. Ведь наши продажи – это случайная величина, которая, даже при более-менее стабильных показателях колеблется изо дня в день, от часа к часу. Соответственно, добавляя шум, мы никак не приближаемся к нашей цели проверить гипотезу за наименьшее время.
Что касается размера выборки, то для ее определения обратимся к историческим данным. Берём исторические продажи тех магазинов, которые мы выбрали и в той гранулярности, которую считаем разумной. Считаем за какой период наблюдений у нас получится набрать необходимое количество замеров, чтобы наша гипотеза стала статистически значимой. Период оказался слишком долгим? Меняем гранулярность и пробуем снова. Так повторяем до тех пор, пока не найдём правильное решение для гранулярности, чтобы обеспечить то время замеров, которое нас устроит.
Статистическую значимость определяем также на основе бутстрапирования в комбинации с тестом Стьюдента, о чем подробнее позже.
Идём дальше.
Подбор контрольной группы
Для пилотной и контрольной выборок нам необходимо подобрать схожие объекты, в нашем примере – схожие магазины. Очевидно, нет смысла сравнивать между собой изначально разные объекты. Так, из-за разницы структуры и уровня спроса магазин в регионе и магазин в центре Москвы могут торговать по-разному. Также у этих магазинов может быть разная площадь, разный ассортимент и множество других факторов, из-за которых их сравнение будет нерелевантным. Соответственно, еще до начала нашего теста нужно доказать, что выбранные для него магазины не отличаются друг от друга, т.е. провести A/A-тест.
Дизайн таких тестов в нашем случае отличается от аналогичных экспериментов в онлайне.Чтобы решить эту задачу мы используем два подхода: векторное расстояние и критерий Стьюдента. Следуем тому подходу, который даст наилучшие результаты с точки зрения ошибок.
Первый подход заключается в том, что каждый объект выборки (в нашем случае магазин), мы представляем точкой в многомерном пространстве, или вектором. Магазины, например, очень просто векторизовать – достаточно взять подневные продажи каждого из них, например, за 60 дней. Таким образом, каждый магазин предстанет вектором в 60-ти мерном пространстве. Далее, по правилам векторной алгебры, мы можем находить расстояние между векторами. Соответственно, для каждого магазина мы можем найти другой магазин, который к нему ближе всего по расстоянию. Такой магазин и будет парой в контрольной выборке. Бизнес-смысл такой векторной математики в том, что для каждого магазина мы находим магазин, который по совокупности подневных продаж максимально к нему близок.
Второй подход состоит в том, что для каждой пары магазинов мы проверяем гипотезу о том, что они не отличаются до начала нашего теста. Другими словами, гипотезу о том, что их продажи равны с точностью до случайных отклонений. Для этого мы снова используем бутстрапирование, чтобы из подневных продаж собрать максимальное количество наблюдений. Далее с помощью критерия Стьюдента проверяем гипотезу о том, что магазины не отличаются. В примере ниже p-value = 0, и мы отклоняем нулевую гипотезу о равенстве магазинов – A/A-тест не пройден, подбираем пары магазинов дальше.
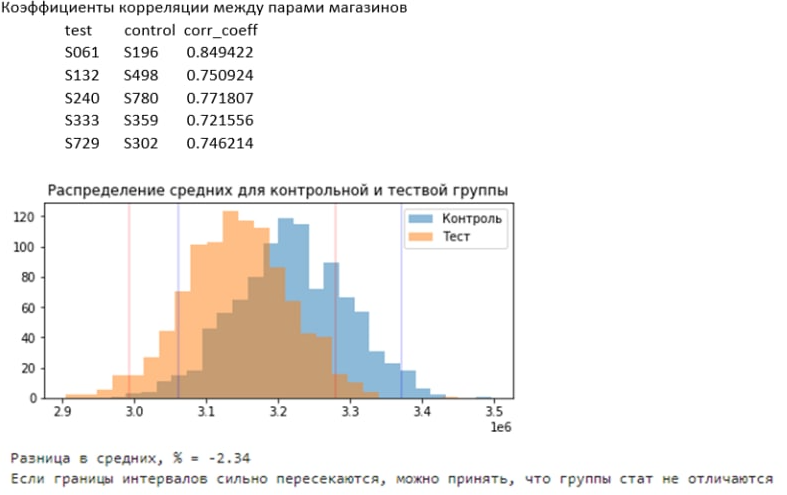
В обоих случаях мы можем оценивать ошибку, которая в одном случае следует из расстояния, а в другом из применения критерия Стьюдента. Для того случая, где ошибка меньше, мы и берём парный магазин.
Оценка эффекта
Ура, у нас есть замеры в достаточном количестве! Теперь мы могли бы взять среднее значение всех попарных разностей продаж магазинов в нужной гранулярности между пилотной и контрольной выборками. Однако, это будет случайная величина и нужно будет доказать, что разница между пилотной и контрольной группой не обусловлена случайными колебаниями значений этой величины. Для этого разницу средних необходимо нормировать на этот диапазон колебаний этой величины, или по-другому, на ее дисперсию. Однако, само по себе это тоже будет неким случайным значением.
Чтобы ответить на вопрос о наличии эффекта мы используем механизм проверки гипотез из математической статистики. Наши гипотезы состоят в том, что пилотная и контрольная группы после наших изменений отличаются на некоторый процент, например, 1, 5 или 10. Мы берем разные проценты, так как чем меньше процент, тем больше измерений требуется, чтобы подтвердить гипотезу о его наличии. Каждый раз мы задаем серию последовательных вопросов: есть ли эффект в 10%, да или нет? Если нет, а есть ли эффект в 5% и так далее.
Чтобы подтвердить или опровергнуть наши гипотезы мы используем упомянутый выше критерий Стьюдента. Он основывается на использовании разницы средних между пилотной и контрольной выборках, которые нормируют на дисперсию величин и размер выборки. Другими словами, критерий Стьюдента показывает отличие разницы средних при условии фиксирования допустимой ошибки принятия гипотезы. То есть, если мы согласны, что ошибка принятия неверной гипотезы не превышает 5 процентов (обычно берут это значение), то при соблюдении условий критерия значения средних или совпадают, или отличаются. Это именно то, что нам и нужно проверить .
Итого, весь процесс проведения теста выглядит следующим образом. Сначала формируем целевую и контрольные группы. Далее выбираем гранулярность замеров. Берём исторические данные и инжектируем в них наш ожидаемый эффект на метрику (например, 5%). Считаем на исторических данных замеры исходя из выбранной гранулярности и далее прогоняем замеры через критерий Стьюдента. Смотрим, сколько времени нам нужно, чтобы получить подтверждение гипотезы об эффекте в 5% (который точно есть, так как мы его сами инжектировали) на исторических данных. Если срок нас не устраивает, то корректируем гранулярность и снова считаем критерий. Так делаем до тех пор, пока не получим ту продолжительность теста, которая нам подходит. После этого начинаем тест на реальных данных и ждем, пока проверится одна из наших гипотез.
Так, в случае с тестированием нового ассортиментного наполнения магазинов, нам потребовалось от трех до четырех недель, чтобы подтвердить эффекты на выручку нескольких категорий в 3-5%.
Например, таблица ниже на примере категории “Холодильники” показывает зависимость количества наблюдений (в ячейках), которое нам необходимо, от размера эффекта (по строкам), который мы хотим найти, и той ошибки при оценке эффекта (по столбцам), которую мы согласны допустить.

Для верификации оценки нашего эффекта мы также используем метод доверительных интервалов. Помните бутстрапирование, о котором мы говорили выше? Мы берем разницу многих средних между целевой и контрольной группами и каждую такую разницу обозначаем точкой. Получаем множество точек (значений) или по-другому множество значений оценки разницы. Среди всех этих оценок берем 2.5% и 97.5% перцентиль – это и есть наш доверительный интервал, в котором будет находиться наш эффект. Если диапазон значений эффекта сочетается с нашими ожиданиями, хорошо, если нет, то продолжаем тест, как описано выше. Если доверительный интервал пересекает ноль, то это значит, что эффекта может не быть вообще и тест нужно однозначно продолжать. Однако, в нашем случае такого быть не должно, так как мы заранее проверяли наличие эффекта с помощью критерия Стьюдента.
Влияние смежных процессов
Перейдем к третьему “нюансу”, о котором мы говорили ранее – процессам. Про них все часто забывают. Вспомним, зачем мы вообще затевали А/B тесты – замерить эффект от каких-либо изменений. Однако, если сами изменения не происходят так, как мы планировали, или мы по каким-то причинам не можем собрать сами замеры, тест обречен на провал.
На что стоит обратить внимание при подготовке к тесту?
Во-первых, нужно реализовать запланированные изменения. Если мы что-то меняем на сайте и хотим измерить динамику конверсии, сделать это довольно просто: случайным образом делим трафик на два потока, часть направляем на старую версию, а часть – на новую. В этом случае у нас нет никаких проблем в реализации запланированных изменений или они минимальны. В физических магазинах все по-другому. Например, чтобы поменять ассортимент в магазинах, нужно товар сначала закупить, потом привезти в магазины, потом поставить на полку, при условии, что на этой полке есть место. Далее, необходимо мониторить, что «пилотный» ассортимент не закончился, так как он «пилотный» и регулярно не закупается.
В условиях розничных пилотов изменения часто происходят поверх регулярных процессов компании. Само проведение таких А/B-тестов превращается в серьезный управленческий кейс, который требует высокой вовлеченности не только от самого продукта, но и от бизнес-команды: коммерсантов, логистов, мерчендайзеров, сотрудников магазинов и прочих специалистов. Чем гибче ваша организация, тем проще вам будет провести А/B-тест, но в любом случае к этой задаче стоит подходить как к серьёзному проекту.
Во-вторых, важно контролировать ход A/B-теста. Для этого мы разработали набор дэшбордов, которые позволили нам в реальном времени следить за прогрессом и реагировать на отклонения. Для задачи с ассортиментом нам было важно отслеживать две вещи. Первое, поведение ключевых метрик: выручки, маржи и количества чеков, чтобы быть уверенными, что мы не “роняем” экономику пилотных магазинов. Второе, наполненность магазинов товарами относительно нашей пилотной ассортиментной матрицы. Примеры дэшбордов приведены ниже.

Пример 1. Выручка и маржа. Обратите внимание, что мы начали замер метрик за 3 недели до начала теста, так как нам было важно понимать поведение пилотных и контрольных магазинов до внесения изменений.
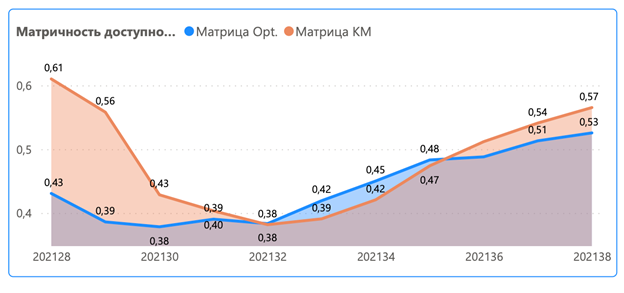
Пример 2. Наполненность матрицы. По графику видно, что в течение нескольких недель магазины «просели» по представленности товара в матрице. Однако, эта просадка была зафиксирована как в контрольной (Матрица КМ), так и в пилотной (Матрица Opt.) группах, а, следовательно, была связана с проблемой доступности товара в целом, а не с самим А/B-тестом.
В-третьих, важно управлять ожиданиями команд. Когда мы только начали внедрять культуру А/B-тестирования в нашей компании, в одном из подразделений нас попросили посчитать экономический эффект от проведения теста, чтобы решить, стоит ли его вообще проводить. То есть, еще до того, как мы что-то померили, нас уже попросили оценить эффект. Надо понимать, что проведение пилота в рознице – это инвестиция. В магазинах вам нужно поставить другой товар, который по замыслу должен быть лучше текущего, но, в теории, может оказаться хуже. Но тест нужно сделать, чтобы это узнать.
Другая часть управления ожиданиями – это заранее предполагать разумные эффекты. Если ваши стейкхолдеры предполагают, что эффект внедряемого изменения на метрику составит 30%, а вы находите только 3%, вероятно, результаты ваших тестов понравятся не всем.
И наконец, выше в этой статье мы разбирались с определением продолжительности теста. Ее следует чётко оговорить и согласовать с основными стейкхолдерами вашего продукта.
Выводы
1. Продукты, которые прямо или косвенно влияют на опыт клиента в офлайне, во многом отличаются от привычных онлайн-сервисов, но равным образом требуют проверки гипотез с помощью A/B-тестов.
2. Объектом наблюдения в случае офлайн-экспериментов становятся процессы на базе физической инфраструктуры (магазина, отделения банка, любой другой точки продаж), что предполагает альтернативный подход к дизайну A/B-теста: выбору метрики, подбору пилотной и контрольной групп, продолжительности и гранулярности замеров.
3. Успех розничного A/B-теста зависит не только от качества тестируемой фичи и усилий продуктовой команды, но и от того, как эта фича будет реализована в объектах наблюдения.
Если все это кажется ваш знакомым, офлайн A/B-тестирование может быть актуально для вашего продукта. Чтобы не наступить на те же грабли, что и в свое время мы, и правильно подготовиться к нему, предлагаем руководствоваться следующим набором шагов:
Определите на какую бизнес-метрику оказывает влияние ваша новая фича.
Сформируйте пилотную группу и обсудите ее состав и релевантность с экспертами от бизнеса.
Подберите контрольную группу и проведите A/A-тест с помощью векторных расстояний и критерия Стьюдента.
Выберите гранулярность замеров и оцените продолжительность теста с помощью инжектирования эффекта в исторические данные и применения статистических критериев проверки гипотез.
Согласуйте продолжительность теста и его ожидаемые результаты со всеми заинтересованными лицами.
Соберите мультидисциплинарную команду экспертов от ключевых бизнес-подразделений для управления тестом.
Выберите подходящее время для запуска теста (например, не в «высокий сезон») и момент старта замеров (например, чтобы товар успел доехать).
Настройте мониторинг прохождения теста и целевой метрики с помощью дэшбордов.
Регулярно рассказывайте команде о ходе прохождения теста, чтобы все понимали, ради чего временно неподтвержденные изменения влияют на основной бизнес.
Сравните результат пилотной группы с контролем и сделайте вывод о статистической значимости проведенных изменений.
В работе над этим текстом нам помогали наши друзья из Студии Данных. Мы вместе внедряли практики A/B-тестирования и работы с данными в проекты команд М.Видео-Эльдорадо.