
Прим. переводчика: автор статьи рассказывает о причинах, побудивших его команду обновить кластер Elasticsearch размером более 3 петабайт, и приводит результаты замеров работоспособности нового кластера в сравнении со старым.
Еще в 2018 году, то есть пять лет назад, в нашем блоге был опубликован пост с описанием нашего кластера Elasticsearch на 400+ узлов. Тогда была затронута важная тема:
Мы решили не обновлять кластер. Хотелось бы, но пока есть более срочные задачи. Да и как именно будет происходить обновление, пока не решено. Один из вариантов — создать новый кластер, а не обновлять старый.
Что ж, долгожданный день обновления, наконец, наступил.

Несколько недель назад завершились последние мероприятия по ликвидации старого кластера Elasticsearch на 1100 узлов и сопутствующей инфраструктуры. На тот момент все зависимые приложения уже были переброшены в новый кластер Elasticsearch. Само отключение прошло для пользователей незаметно, но для нашей команды это была важная веха и достойное завершение многолетнего проекта.
Мы решили подготовить серию статей, чтобы поделиться полученными знаниями и описать некоторые трудности, с которыми столкнулись в процессе, а также то, как мы их преодолели.
В первой части вы найдете краткое описание проекта и проблем, с которыми мы столкнулись в старом кластере. Также речь пойдет о рамках, в которых приходилось работать. Остальные публикации серии будут посвящены другим интересным темам. Статьи планируется выпускать каждую неделю вплоть до Рождества примерно по такому графику:
Часть 2 — Два согласованных кластера (18 ноября).
Часть 3 — Производительность поиска и подстановочные знаки (25 ноября).
Часть 4 — Токенизация для быстрой работы на всех языках (2 декабря).
Часть 5 — Процесс разработки (9 декабря).
Часть 6 — Стратегия тестирования и внедрения (16 декабря).
Часть 7 — Итоговая архитектура и выводы (23 декабря).
Так что следите за обновлениями.
Предыстория и сценарии использования
Как описывалось ранее, Meltwater использует поисковую систему Elasticsearch с открытым исходным кодом. В ней хранятся около 400 млрд сообщений из социальных сетей и статей из различных новостных источников. Платформа предоставляет клиентам результаты поиска, графики, аналитику, высокоуровневую информацию, а также позволяет экспортировать датасеты.
До прошлого месяца с этим огромным массивом данных мы управлялись с помощью собственной версии Elasticsearch, которую сами и поддерживали. Кластер содержал около 1100 AWS-узлов i3en.3xlarge и насчитывал много тысяч индексов, почти 100 000 шардов и около 1 ПБ первичных данных (более 3 ПБ с учетом реплик).
После обновления датасет даже слегка подрос — 3,5 ПБ (по причинам, которые мы раскроем в одной из последующих статей), а общее число узлов снизилось «всего» до 320 (в основном это инстансы i3en.6xlarge). Но самое главное — теперь используется официально поддерживаемая версия Elasticsearch!
Причины обновления
Elastic и Amazon не рекомендуют использовать более 100 узлов в кластерах со старыми версиями Elasticsearch. Но как вы, вероятно, догадываетесь, мы уже давно преодолели этот рубеж. Постоянные обновления и улучшения обеспечили рост бизнеса и расширение сценариев использования.
Однако по мере роста кластера ограничения, связанные со старой версией, становились все острее. Например, она не очень хорошо обрабатывала инкрементные обновления состояния кластера. На каждый из 1100 узлов отправлялось всё состояние (размером более 100 Мб), и делалось это при каждом изменении состояния. В результате глобальным узким местом становилась пропускная способность нашей 100-гигабитной сети на мастер-узлах.
Кроме того, были и другие проблемы при работе со старой версией Elasticsearch:
Непредсказуемое поведение при выходе из/присоединении узлов и шардов к кластеру.
-
Работа с резервными копиями S3:
-
Из-за неэффективности работы старой версии Elasticsearch с хранилищами типа S3 старые резервные копии не получалось удалять достаточно быстро, чтобы успевать за притоком новых данных. Поэтому наши бекапы постоянно увеличивались в размерах.

Увеличение размеров snapshot’ов Периодически приходилось переключать бакет S3, а несколько раз в год — начинать с нуля новый snapshot, чтобы поддерживать стоимость хранения данных на приемлемом уровне.
-
-
Скачкообразное использование heap-памяти в сочетании с недостаточными (или отсутствующими) прерывателями и защитными сетями (safety nets):
Неоднократно случалось так, что плохо написанный пользовательский запрос допускался к выполнению и отводил слишком много памяти, в результате чего узлы попадали в так называемый «мусорный ад» и падали.
-
«Мусорный ад» — это ситуация, когда узел тратил все свое время и ресурсы CPU на сборку мусора и не успевал выполнять другую полезную работу (например, отвечать на кластерные пинги или выполнять поиски). Такой узел замедлял работу всего кластера, поскольку запросы мастера и остальных узлов к подобному «адовому» инстансу заканчивались таймаутами. (Сборка мусора в Java — безусловно увлекательная тема, но выходит за рамки этой статьи).

Использование heap-памяти виртуальной машиной Java Даже когда узлы работали в «нормальном» режиме, использование heap-памяти было очень резким и непредсказуемым.
-
Слишком большой объем данных сегментов хранился в heap-памяти:
Только для сегментных данных использовалось более 10ТиБ оперативной памяти, или около 40% от общей доступной heap-памяти Java во всем кластере. Heap-память Java (а не диск или процессор) была основной метрикой масштабирования для всего кластера.
-
Невозможность использовать более новые версии Java и более современные алгоритмы сборки мусора:
Мы не могли использовать более 30 Гб heap-памяти Java на узел, даже если в ОС было доступно несколько сотен гигабайт оперативной памяти.
В свою очередь это вынуждало нас масштабироваться горизонтально (т.е. увеличивать число машин), а не вертикально (наращивать их мощность), что не всегда оптимально.
Все вышеперечисленные проблемы и многие другие, как мы полагали, уйдут после перехода на более позднюю версию Elasticsearch.
Наконец, мы знали, что Meltwater будет расти и дальше. В будущем потребуется поддерживать еще больше данных, больше пользователей и больше сценариев использования. Мы чувствовали, что приближаемся к жесткому пределу, который старая версия Elasticsearch налагает на размер кластера.
В итоге было решено инвестировать в многолетний проект по модернизации кластера Elasticsearch.
К чему мы в итоге пришли
Как упоминалось ранее, речь о миграции пойдет в будущих статьях. Для начала же следует сказать пару слов о преимуществах, которые принесло обновление. Наиболее выразительно их раскроют конкретные цифры.
На всех рисунках ниже светло-синий цвет — старый кластер, темно-синий — новый кластер.
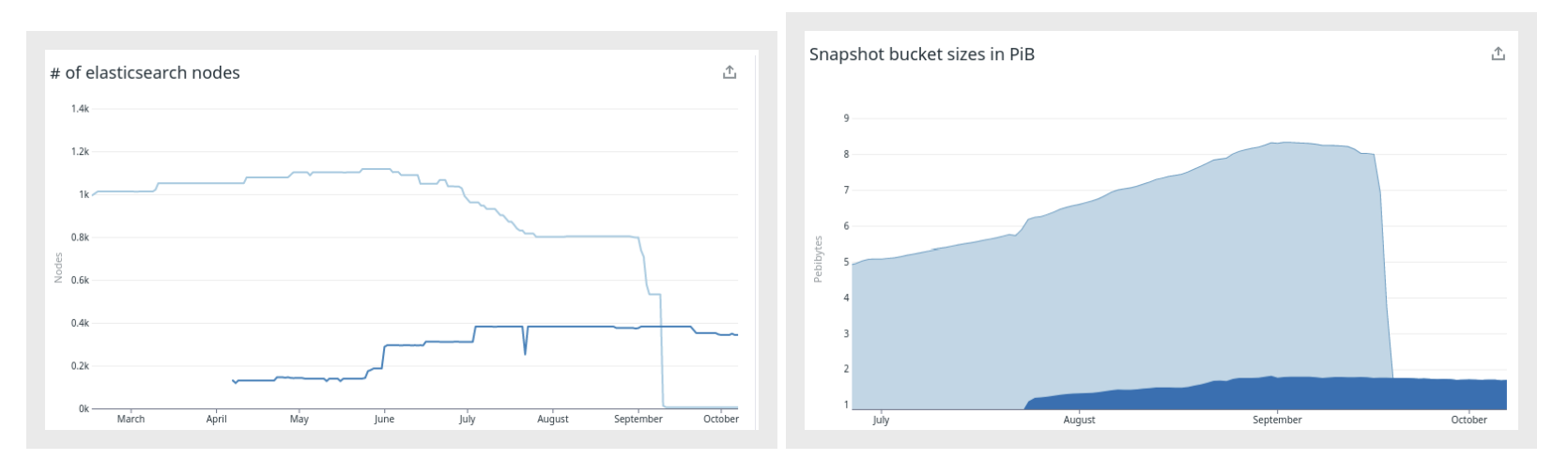
Как видно из левого рисунка, количество узлов удалось сократить с 1100+ примерно до 320. На нем также показана параллельная работа кластеров и как постепенно увеличивалось/уменьшалось количество узлов по мере переноса данных и поисковых запросов из старой системы в новую.
Правый рисунок показывает, что неконтролируемый рост размера snapshot’ов был исправлен в новой версии Elasticsearch, и теперь можно снизить затраты на резервное копирование.

Эти два рисунка показывают улучшения, достигнутые в моделях использования heap-памяти. Из левого видно, что использование heap-памяти в новом кластере практически не меняется во времени. На правом изображен суммарный объем heap-памяти для старого и нового кластера (14 ТиБ против 22 ТиБ). Он снизился, хотя это и не было самоцелью.
Также на приведенных выше рисунках видно, что после завершения миграции получилось дополнительно оптимизировать и отмасштабировать вниз новый кластер. Это было бы невозможно в старой версии, где постоянно приходилось масштабировать кластер вверх из-за роста датасета.
Но давайте не будем забегать вперед. Эта серия статей посвящена не только итоговому результату, но и тому, как и почему это было сделано.
Так что вернемся к истории о миграции.
Требования к развертыванию
Meltwater — международная компания, поэтому наши системы должны работать и быть доступными 24 часа в сутки, 7 дней в неделю.
Периодические простои для обслуживания отдельных компонентов системы допустимы, однако остановка движка, который обеспечивает работу всех поисковых и аналитических функций Meltwater, была попросту исключена. Таким образом, любая стратегия развертывания без безопасной стратегии отката была неприемлема.
Единственным вариантом было планирование такого обновления, которое прошло бы незаметно для клиентов, службы поддержки и 30 с лишним команд разработчиков.
Кроме того, развертывание должно было проходить постепенно, позволяя переключать отдельные запросы/пользователей/приложения между новой и старой системой.
Короче говоря, нужно было покумекать над тем, как сделать развертывание системы постепенным, обратимым и беспростойным.
На этом пока все. Следите за обновлениями: в следующей части мы расскажем, как удовлетворили эти требования с помощью двух параллельно работающих кластеров Elasticsearch, поставляющих одни и те же данные.
P.S.
Читайте также в нашем блоге:
Комментарии (5)

liponex
23.11.2022 11:07+2Спасибо за перевод, жду следующих частей! У самого появились трундности подобного рода для переноса Elasticsearch, так что с удовольствием почитаю продолжение.

chistya
23.11.2022 11:08Ну нет, запустить рядом второй кластер, это не интересно. А вот обновлять все ноды через rolling update, спотыкнуться обо все, что только можно, что было объявлено depricated, версии три назад, вот это был бы разговор ))))))
AnyKey80lvl
Спасибо за перевод!
1100 узлов i3en.xlarge даже с reserved это $780k в месяц.
Умеют люди зарабатывать на покрытие такого OPEXа, моё почтение!
320 x i3en.6xlarge (reserved) = $453k, да, поприятнее.
speshuric
В финансовых отчетах выручка примерно по $110М в первом и втором квартале 2022. EBITDA ~$6M/Q.