
В свете последних событий, происходящих на политической арене, а именно - введение санкций в отношении arm процессоров и arm архитектуры вообще, и, как следствие, введение мер по импортозамещению, возникает необходимость в инструменте для написания программ уже на отечественном оборудовании.
Выше под понятием инструмента, в первую очередь, имеется в виду язык программирования, поскольку адекватный разработчик разрабатывать системный уровень (операционная система с необходимыми зависимостями) с использованием существующих решений (языки C, C++) вряд ли будет.
Достаточно беглого взгляда на ядро популярнейшего Linux, чтобы обнаружить абсолютно нечитаемый код, состоящий из статических глобальных констант, двойных нижних подчеркиваний, огромного количества уровней абстракций и т.п. Если к этому добавить еще и невыразительность языка C++, например методы stoi(), stod(), empty(), то желание, не то что изучать лучшие практики, а вообще программировать исчезнет.
Задача
С чего начинается программирование? С простановки задачи. В вышеописанном контексте задачей является управление работой процессора посредством трансляции набора команд. Вообще производитель любого процессора уже решил эту задачу, предоставив потребителю спецификацию с набором поддерживаемых процессором команд. Такая спецификация содержит инструкции (команды) ассемблера и, возможно, рекомендации по использованию этих инструкций.
Однако в программировании существует понятие абстрации и уровня абстракции. Так, если бы программист писал программу на языке ассемблера, программа получилась бы многословной, нечитаемой, сложной в отладке и т.д. Т.е. время разработки существенно возросло. Однако с введением понятия уровня абстракции ситуация улучшается.
По этой причине, для упрощения управления процессором, программисты создают программы на один уровень выше ассемблерного кода, например - виртуальная машина LLVM. Она упрощает управление памятью, операциями процессора, взаимодействие с защищенным уровнем. Однако виртуальная машина запрограммирована на языке более высокого уровня, чем ассемблер (в случае LLVM и подобных - C++).
Таким образом, требуется язык программирования компактный но достаточно выразительный, лишенный недостатков своих предшественников. И, собственно, кроссплатформенный компилятор, который транслирует команды одной платформы (языка программирования) на команды другой платформы (например, ассемблера).
Распознание
Внимательный читатель может задать вопрос: "При чем здесь арифметика и язык программирования?". Если изучить историю языков программирования, то можно обнаружить, что первые из них создавались для решения математических задач. Т.е. пользователь вводил выражение с помощью клавиатуры, а компьютер решал это выражение. Отсюда берут начало и многие конструкции современных языков программирования - вложенность в скобки, объявление неизвестных (переменных), наличие классов, определяющих допустимые операции над ними и т.д. Поэтому связь прямая, более того, чтобы разобраться в том, как компилятор распознает сложные конструкции, следует начать с простого - распознания (парсинга) арифметических выражений.
Вкратце для того, чтобы распознать и решить выражение требуется:
Преобразовать исходную строку в набор токенов, описывающих каждую лексему (например, [literal: 1] [punctuator: +] [literal: 1] [punctuator: =] [literal: 2]).
На основе токенов построить бинарное дерево всего выражения.
Вычислить значение каждого узла бинарного дерева.
Звучит довольно просто, но предлагаю рассмотреть каждый из пунктов подробнее.
Преобразование в токены
Поскольку пример, описываемый в настоящей статье учебный, то условимся, что в качестве исходной строки могут быть выражения, содержащие целые и дробные числа, операторы +, -, *, / и любое количество скобок. Для примера рассмотрим выражение (1.2 + 2) * 2.5.
Вначале введем понятие токена:
#include <string>
#include <map>
#include <any>
#include <vector>
#include "../Ace.h"
using namespace std;
namespace Lexer {
struct Token {
public:
enum Kind {
keyword,
identifier,
punctuator,
literal
};
Kind kind;
any specifier;
string value;
Token(Kind kind, any specifier, string value);
bool operator==(const Token &other) const;
string description();
optional<Ace::Keyword> to_keyword();
optional<Ace::Punctuator> to_punctuator();
optional<Ace::Literal> to_literal();
private:
string description(Kind kind);
template<typename T>
optional<T> kind_cast(Kind kind) {
if (this->kind != kind) {
return {};
} else {
return any_cast<T>(specifier);
}
}
};
}#include "../../include/Lexer/Token.h"
#include "../../include/Ace.h"
using namespace Lexer;
Token::Token(Kind kind, any specifier, string value) {
this->kind = kind;
this->specifier = specifier;
this->value = move(value);
}
bool Token::operator==(const Token &other) const {
bool is_kind_equal = kind == other.kind;
bool is_specifier_equal;
bool is_value_equal = value == other.value;
switch (kind) {
case Kind::keyword: {
auto lhs = any_cast<Ace::Keyword>(specifier);
auto rhs = any_cast<Ace::Keyword>(other.specifier);
is_specifier_equal = lhs == rhs;
break;
}
case Kind::punctuator: {
auto lhs = any_cast<Ace::Punctuator>(specifier);
auto rhs = any_cast<Ace::Punctuator>(other.specifier);
is_specifier_equal = lhs == rhs;
break;
}
case Kind::literal: {
auto lhs = any_cast<Ace::Literal>(specifier);
auto rhs = any_cast<Ace::Literal>(other.specifier);
is_specifier_equal = lhs == rhs;
break;
}
case Kind::identifier: {
is_specifier_equal = is_value_equal;
break;
}
}
return is_kind_equal && is_specifier_equal && is_value_equal;
}
string Token::description() {
string kind_description = description(kind);
string specifier_description;
switch (kind) {
case Kind::keyword: {
auto keyword = any_cast<Ace::Keyword>(specifier);
specifier_description = Ace::description(keyword);
break;
}
case Kind::punctuator: {
auto punctuator = any_cast<Ace::Punctuator>(specifier);
specifier_description = Ace::description(punctuator);
break;
}
case Kind::literal: {
auto literal = any_cast<Ace::Literal>(specifier);
specifier_description = Ace::description(literal);
break;
}
case Kind::identifier:
specifier_description = "";
break;
}
return "Kind: " + kind_description + ", " + "Specifier: " + specifier_description + ", " + "Value: " + value;
}
optional<Ace::Keyword> Token::to_keyword() {
return kind_cast<Ace::Keyword>(Kind::keyword);
}
optional<Ace::Punctuator> Token::to_punctuator() {
return kind_cast<Ace::Punctuator>(Kind::punctuator);
}
optional<Ace::Literal> Token::to_literal() {
return kind_cast<Ace::Literal>(Kind::literal);
}
string Token::description(Kind kind) {
switch (kind) {
case Kind::keyword:
return "keyword";
case Kind::punctuator:
return "punctuator";
case Kind::literal:
return "literal";
case Kind::identifier:
return "identifier";
}
}Можно увидеть, что токен содержит такие поля как kind, specifier и value. Этих полей достаточно для того, чтобы описать тип, уточнить тип и сохранить значение лексемы.
Далее нужен, непосредственно парсер, который в качестве входного аргумента принимает исходную строку, а в результате возвращает набор токенов.
#include <optional>
#include "Token.h"
#include "../Ace.h"
using namespace std;
namespace Lexer {
class Parser {
public:
vector<Token> parse(const string &source_code);
private:
Token create_token(string lexem);
bool is_literal(string lexem);
bool is_identifier(string lexem);
optional<Ace::Literal> parse_literal(string lexem);
optional<string> parse_identifier(string lexem);
};
}#include "../../include/Lexer/Parser.h"
#include "../../include/lib/StringManager.h"
#include "../../include/Literals/Parser.h"
#include <any>
using namespace Lexer;
vector<Token> Parser::parse(const string &source_code) {
vector<Token> tokens;
StringManager string_manager;
auto predicate = [](char c) { return isspace(c); };
auto split_by_space = string_manager.split(source_code, predicate);
vector<string> components;
for (auto component : split_by_space) {
auto predicate = [](char c) {
auto str = string(1, c);
return Ace::punctuators.contains(str);
};
auto split_by_punctuator = string_manager.split(component, predicate, true);
for (auto subcomponent : split_by_punctuator) {
components.push_back(subcomponent);
}
}
for (auto component : components) {
Token token = create_token(component);
tokens.push_back(token);
}
return tokens;
}
Token Parser::create_token(string lexem) {
Token::Kind kind;
any specifier;
if (Ace::keywords.contains(lexem)) {
kind = Token::Kind::keyword;
auto keyword = Ace::keywords[lexem];
specifier = keyword.value();
} else if (Ace::punctuators.contains(lexem)) {
kind = Token::Kind::punctuator;
auto punctuator = Ace::punctuators[lexem];
specifier = punctuator.value();
} else if (is_literal(lexem)) {
kind = Token::Kind::literal;
auto literal = parse_literal(lexem);
specifier = literal.value();
} else if (is_identifier(lexem)) {
kind = Token::Kind::identifier;
auto identifier = parse_identifier(lexem);
specifier = "";
}
return { kind, specifier, lexem };
}
bool Parser::is_literal(string lexem) {
Literals::Parser parser;
return parser.is_literal(lexem);
}
bool Parser::is_identifier(string lexem) {
// TODO: check identifier grammar
return true;
}
optional<Ace::Literal> Parser::parse_literal(string lexem) {
Literals::Parser parser;
return parser.parse(lexem);
}
optional<string> Parser::parse_identifier(string lexem) {
return lexem;
}Здесь потребовалось реализовать несколько зависимостей в виде библиотеки для string и еще одного парсера литералов. [1] Подробно останавливаться на зависимостях не будем. Лишь коротко стоит указать, что первая содержит вспомогательные методы, такие как split() - для разбиения строки на компоненты и trim() для удаления незначащих символов на концах строки. А вторая зависимость распознает литералы целых и дробных чисел, строк, символов и булевых значений.
Таким образом пример (1.2 + 2) * 2.5 будет преобразован в токены:
Kind: punctuator, Specifier: opening parenthesis, Value: (
Kind: literal, Specifier: double, Value: 1.2
Kind: punctuator, Specifier: plus, Value: +
Kind: literal, Specifier: integer, Value: 2
Kind: punctuator, Specifier: closing parenthesis, Value: )
Kind: punctuator, Specifier: asterisk, Value: *
Kind: literal, Specifier: double, Value: 2.5
Составление бинарного дерева
Перед тем, как бросаться на амбразуры бинарного дерева следует определить грамматику, т.е. правила, задающие приоритет операторов и скобок, а также присвоение значения (либо к левому операнду, либо к правому). Итак, грамматика состоит из следующих правил:
Expression -> | Expression + A_Term
| Expression - A_Term
| A_Term
A_Term -> | A_Term * B_Term
| A_Term / B_Term
| B_Term
B_Term -> | (Expression)
| C_Term
C_Term -> 0…9
Напомню, что нетерминальные символы - это Expression, A_Term, B_Term и C_Term, а терминальные - это числа и операторы со скобками. Очевидно, что чем ниже находится нетерминальный символ, тем выше его приоритет.
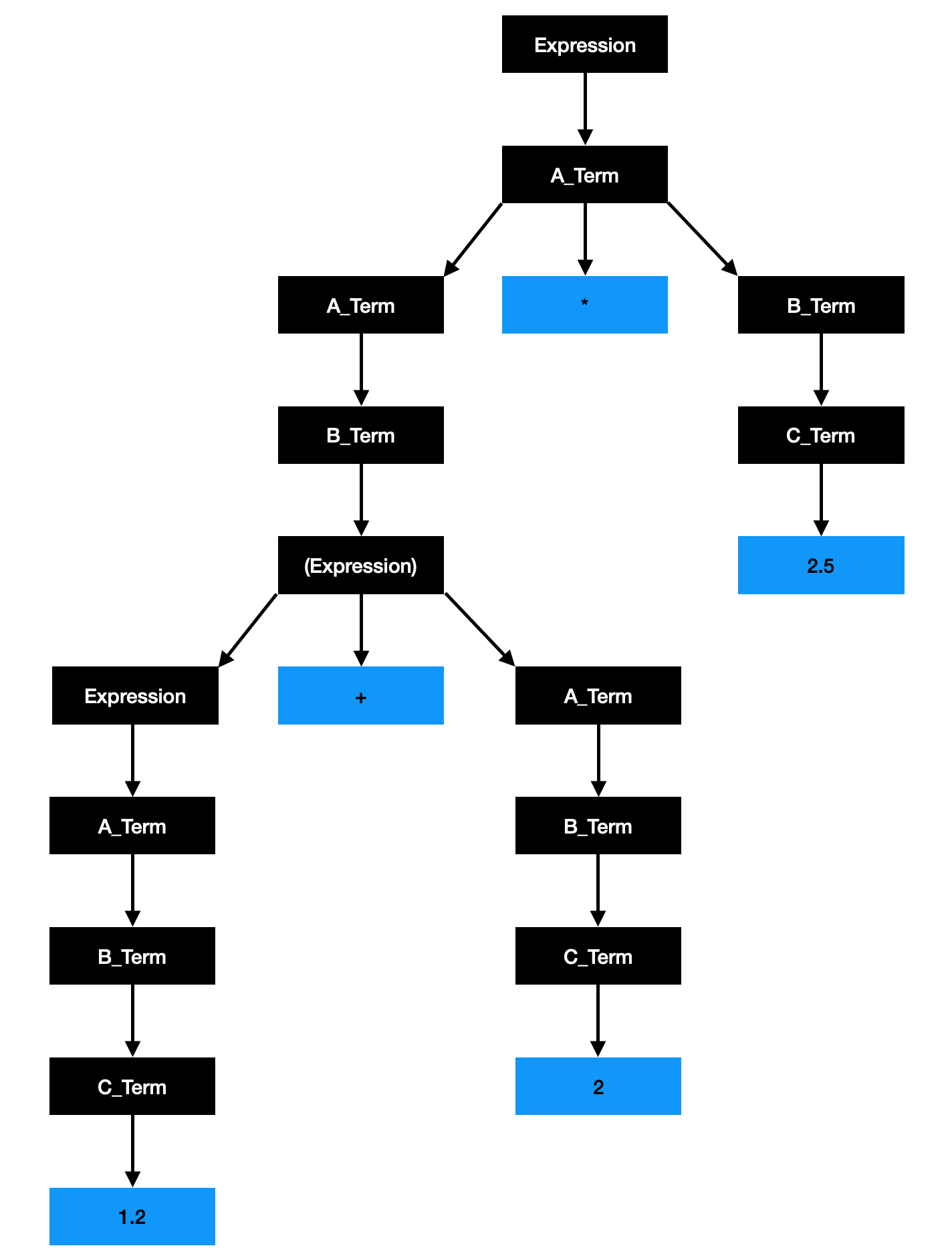
Разбирать подробно граф бинарного дерева не имеет смысла, поскольку в общем доступе большое количество ресурсов достаточно ясно описывающих идею компьютерной грамматики и идею бинарных деревьев. [2, 3]
Для описания дерева необходим объект, соответствующий узлу дерева. Из изображения видно, что у узла может быть одна ветвь, либо две ветви. Также узел может хранить значение оператора, либо операнда.
#include <optional>
#include "../Ace.h"
using namespace std;
namespace Expression {
struct Node {
enum class Kind {
expression,
a_term,
b_term,
c_term
};
Kind kind;
optional<Ace::Operator> _operator;
optional<double> number;
Node *left;
Node *right;
};
}Основным преимуществом такой структуры данных является возможность использования рекурсии при программировании.
#include <string>
#include <vector>
#include <map>
#include "Node.h"
#include "../Lexer/Parser.h"
#include <list>
#include "../lib/Array/Array.h"
using namespace std;
namespace Expression {
class Parser {
public:
class Error: exception {
public:
enum class Reason {
invalid_parenthesis,
invalid_operand,
invalid_operator
};
const Reason reason;
explicit Error(Reason reason);
const char * what() const noexcept override;
};
Node* parse(vector<Lexer::Token> &tokens);
private:
typedef Array<Lexer::Token> Buffer;
Node* create_expression(Buffer buffer);
Node* create_a_term(Buffer buffer);
Node* create_b_term(Buffer buffer);
Node* create_c_term(Buffer buffer);
Buffer::iterator first_operator(Node::Kind non_terminal_kind, Buffer &buffer);
Buffer::iterator first_punctuator(Ace::Punctuator kind, Buffer &buffer);
Buffer::iterator last_punctuator(Ace::Punctuator kind, Buffer &buffer);
bool is_parenthesis_correct(Buffer buffer);
bool is_operands_correct(Buffer buffer);
bool is_operators_correct(Buffer buffer);
};
}#include "../../include/Expression/Parser.h"
#include <iterator>
#include <set>
using namespace Expression;
Parser::Error::Error(Reason reason): reason(reason) {}
const char *Parser::Error::what() const noexcept {
switch (reason) {
case Error::Reason::invalid_parenthesis:
return "invalid parenthesis";
case Error::Reason::invalid_operand:
return "invalid literal";
case Error::Reason::invalid_operator:
return "invalid operator";
}
}
Node* Parser::parse(vector<Lexer::Token> &tokens) {
Buffer buffer { tokens };
if (!is_parenthesis_correct(buffer)) {
throw Error { Error::Reason::invalid_parenthesis };
}
if (!is_operands_correct(buffer)) {
throw Error { Error::Reason::invalid_operand };
}
if (!is_operators_correct(buffer)) {
throw Error { Error::Reason::invalid_operator };
}
return create_expression(buffer);
}
Node* Parser::create_expression(Buffer buffer) {
auto operator_iterator = first_operator(Node::Kind::expression, buffer);
if (operator_iterator == buffer.end()) {
// Expression -> A_Term
auto right_child = create_a_term(buffer);
return new Node { Node::Kind::expression, right: right_child };
}
// Expression -> Expression + A_Term
// Expression -> Expression - A_Term
auto lhs_buffer = buffer.slice(buffer.begin(), operator_iterator);
auto left_child = create_expression(lhs_buffer);
auto rhs_buffer = buffer.slice(operator_iterator + 1, buffer.end());
auto right_child = create_a_term(rhs_buffer);
auto token = *operator_iterator;
auto punctuator = token.to_punctuator();
auto _operator = Ace::define_operator(punctuator.value());
return new Node { Node::Kind::expression, _operator: _operator.value(), left: left_child, right: right_child };
}
Node* Parser::create_a_term(Buffer buffer) {
auto operator_iterator = first_operator(Node::Kind::a_term, buffer);
if (operator_iterator == buffer.end()) {
// A_Term -> B_Term
auto right_child = create_b_term(buffer);
return new Node { Node::Kind::a_term, right: right_child };
}
// A_Term -> A_Term * B_Term
// A_Term -> A_Term / B_Term
auto lhs_buffer = buffer.slice(buffer.begin(), operator_iterator);
auto left_child = create_a_term(lhs_buffer);
auto rhs_buffer = buffer.slice(operator_iterator + 1, buffer.end());
auto right_child = create_b_term(rhs_buffer);
auto token = *operator_iterator;
auto punctuator = token.to_punctuator();
auto _operator = Ace::define_operator(punctuator.value());
return new Node { Node::Kind::a_term, _operator: _operator.value(), left: left_child, right: right_child };
}
Node* Parser::create_b_term(Buffer buffer) {
auto opening_parenthesis = first_punctuator(Ace::Punctuator::opening_parenthesis, buffer);
if (opening_parenthesis == buffer.end()) {
// B_Term -> C_Term
auto right_child = create_c_term(buffer);
return new Node { Node::Kind::b_term, right: right_child };
}
auto closing_parenthesis = last_punctuator(Ace::Punctuator::closing_parenthesis, buffer);
// B_Term -> (Expression)
auto _buffer = buffer.slice(opening_parenthesis + 1, closing_parenthesis);
auto right_child = create_expression(_buffer);
return new Node { Node::Kind::b_term, right: right_child };
}
Node* Parser::create_c_term(Buffer buffer) {
// C_Term -> 0...9
if (buffer.is_empty()) {
throw Error { Error::Reason::invalid_operator };
}
auto token = buffer[0];
auto value = stod(token.value);
return new Node { Node::Kind::c_term, number: value };
}
Parser::Buffer::iterator Parser::first_operator(Node::Kind non_terminal_kind, Buffer &buffer) {
auto is_non_terminal_operator = [&](Ace::Operator _operator) {
switch (non_terminal_kind) {
case Node::Kind::expression: {
auto is_addition = _operator == Ace::Operator::addition;
auto is_subtraction = _operator == Ace::Operator::subtraction;
return is_addition || is_subtraction;
}
case Node::Kind::a_term: {
auto is_multiplication = _operator == Ace::Operator::multiplication;
auto is_division = _operator == Ace::Operator::division;
return is_multiplication || is_division;
}
default: {
return false;
}
}
};
Buffer::iterator result = buffer.end();
int parenthesis_count = 0;
for (auto iterator = buffer.begin(); iterator != buffer.end(); iterator++) {
auto token = *iterator;
auto punctuator = token.to_punctuator();
if (!punctuator.has_value()) {
continue;
}
if (punctuator == Ace::Punctuator::opening_parenthesis) {
parenthesis_count += 1;
continue;
}
if (punctuator == Ace::Punctuator::closing_parenthesis) {
parenthesis_count -= 1;
continue;
}
if (parenthesis_count > 0) {
continue;
}
auto _operator = Ace::define_operator(punctuator.value());
if (!_operator.has_value()) {
continue;
}
if (is_non_terminal_operator(_operator.value())) {
result = iterator;
}
}
return result;
}
Parser::Buffer::iterator Parser::first_punctuator(Ace::Punctuator kind, Buffer &buffer) {
Buffer::iterator result = buffer.end();
for (auto iterator = buffer.begin(); iterator != buffer.end(); iterator++) {
auto token = *iterator;
auto punctuator = token.to_punctuator();
if (!punctuator.has_value()) {
continue;
}
if (punctuator.value() == kind) {
result = iterator;
break;
}
}
return result;
}
Parser::Buffer::iterator Parser::last_punctuator(Ace::Punctuator kind, Buffer &buffer) {
Buffer::iterator result = buffer.end();
for (auto iterator = buffer.begin(); iterator != buffer.end(); iterator++) {
auto token = *iterator;
auto punctuator = token.to_punctuator();
if (!punctuator.has_value()) {
continue;
}
if (punctuator.value() == kind) {
result = iterator;
}
}
return result;
}
bool Parser::is_parenthesis_correct(Buffer buffer) {
int opening_parenthesis_count = 0;
int closing_parenthesis_count = 0;
for (auto iterator = buffer.begin(); iterator != buffer.end(); iterator++) {
auto token = *iterator;
auto punctuator = token.to_punctuator();
if (!punctuator.has_value()) {
continue;
}
if (punctuator == Ace::Punctuator::opening_parenthesis) {
opening_parenthesis_count += 1;
continue;
}
if (punctuator == Ace::Punctuator::closing_parenthesis) {
closing_parenthesis_count += 1;
continue;
}
}
return opening_parenthesis_count == closing_parenthesis_count;
}
bool Parser::is_operands_correct(Expression::Parser::Buffer buffer) {
bool is_correct = true;
set<Lexer::Token::Kind> allowed_tokens {
Lexer::Token::Kind::literal,
Lexer::Token::Kind::punctuator
};
for (auto iterator = buffer.begin(); iterator != buffer.end(); iterator++) {
auto token = *iterator;
if (!allowed_tokens.contains(token.kind)) {
is_correct = false;
break;
}
auto literal = token.to_literal();
if (!literal.has_value()) {
continue;
}
switch (literal.value()) {
case Ace::Literal::integer:
case Ace::Literal::_double:
continue;
default:
is_correct = false;
break;
}
break;
}
return is_correct;
}
bool Parser::is_operators_correct(Expression::Parser::Buffer buffer) {
bool is_correct = true;
set<Ace::Punctuator> allowed_punctuators {
Ace::Punctuator::opening_parenthesis,
Ace::Punctuator::closing_parenthesis
};
for (auto iterator = buffer.begin(); iterator != buffer.end(); iterator++) {
auto token = *iterator;
auto punctuator = token.to_punctuator();
if (!punctuator.has_value()) {
continue;
}
if (allowed_punctuators.contains(punctuator.value())) {
continue;
}
auto _operator = Ace::define_operator(punctuator.value());
if (!_operator.has_value()) {
is_correct = false;
break;
}
}
return is_correct;
}Вычисление значения
Но, пожалуй, главное преимущество этого дерева в том, что очень легко вычислить его значение. Достаточно начать с нижнего узла и, поднимаясь вверх, посчитать значения каждого из узлов.
Соответственно, интерпретатор - объект, который принимает в качестве входного аргумента начальный узел (root) дерева, а возвращает значение этого дерева, является очень компактным.
#include "../Expression/Node.h"
class Interpretator {
public:
class Error: exception {
public:
enum class Reason {
division_by_zero
};
const Reason reason;
explicit Error(Reason reason);
const char * what() const noexcept override;
};
double calculate(Expression::Node *node);
};#include "../../include/Interpretator/Interpretator.h"
#include "../../include/Ace.h"
Interpretator::Error::Error(Interpretator::Error::Reason reason) : reason(reason) {}
const char * Interpretator::Error::what() const noexcept {
switch (reason) {
case Reason::division_by_zero:
return "Division by zero";
}
}
double Interpretator::calculate(Expression::Node *node) {
if (node->number.has_value()) {
return node->number.value();
} else if (node->_operator.has_value()) {
auto _operator = node->_operator.value();
auto lhs = calculate(node->left);
auto rhs = calculate(node->right);
switch (_operator) {
case Ace::Operator::addition:
return lhs + rhs;
case Ace::Operator::subtraction:
return lhs - rhs;
case Ace::Operator::multiplication:
return lhs * rhs;
case Ace::Operator::division:
if (rhs == 0) {
throw Error { Error::Reason::division_by_zero };
}
return lhs / rhs;
}
} else {
return calculate(node->right);
}
}Вот и все, не самая сложная задача для программиста.
Заключение
Главное, на что стоит обратить внимание - это техника программирования, поскольку теория уже была разработана математиками в далекие 50-е. [2, 3] Автор статьи придерживался принципов SOLID с упором на читаемость кода. [4, 5] Исходный код проекта [1] можно найти в разделе ссылки.
Ссылки
Комментарии (20)

andy_p
28.11.2022 23:56+15Если к этому добавить еще и невыразительность языка C++, например методы stoi(), stod(), empty()
Это не С++.
По поводу статьи:
Вы изобрели lex и yacc.

OldNileCrocodile
29.11.2022 01:06-1Хуже. Автор написал этот код вручную, когда мог использовать lex/yacc, чтобы получить исходники парсера. Кроме того, как уже писали выше, для арифметики есть обратная польская запись (Reversed Polish Notation - RPN).

oleg_shamshura
29.11.2022 15:49lex и yacc -- конечные автоматы.
https://www.cs.man.ac.uk/~pjj/cs2111/ho/node6.html


apro
29.11.2022 00:04+17поскольку адекватный разработчик ... с использованием существующих решений (языки C, C++) вряд ли будет.
Если к этому добавить еще и невыразительность языка C++
Поэтому далее мы напишем программу на... (барабанная дробь) C++.

Boilerplate
29.11.2022 00:11+5Если уж решили писать разбор синтаксиса какого-то кода на с++, то используйте также наследование и полиморфизм, а не пачки switch caseов. И как верно уже сказали - вы переизобрели flex + bison / lex + yacc. И, кстати, дерево выражение не всегда бинарное. Например if (expression) { statements } else { statements } имеет три листа.
Про мусор в начале статьи я уж и не говорю.


KvanTTT
29.11.2022 00:44-4Блин, плюсанул, почти не читая, особенно вступление. Извините. А еще говорят, что на хабре много минусуют. Видимо, я какая-то аномалия, раз неоднократно плюсую сомнительные статьи из-за добрых побуждений.

Refridgerator
29.11.2022 08:06-3Вступление вполне норм, если бы после него последовало действительно импортозамещение ну или хотя бы просто интересное и красивое решение, а не очередная поделка на дереве и case-ах.

JYE
29.11.2022 04:49+1На втором курсе на ассемблере написал программу, которая с клавиатуры считывала строку с формулой и и числами и преобразовывала это все соотв вызовы. Поддерживались комплексные числа (ради них эта прога и писалась, т.к. вручную считать лабы и курсачи по ТОЭ задалбывался).
Это был 1992 год. Компьютер БК-0010.01, архитектура PDP-11. И про интернет я еще не знал.


cadovvl
29.11.2022 11:59Народ, соберитесь.
Увидел оценку, прочитал первый абзац, и сразу в коментарии - а тут как-то тухловато. Болеют все, что ли?Refridgerator
29.11.2022 12:36Я слышал, что программирование на с++ вызывает необратимое изменение мозга.

Refridgerator
29.11.2022 20:10Для хранения и вычисления арифметического выражения вовсе не обязательно использовать дерево — достаточно линейного списка с постфиксной записью. Это также позволит объединять несколько выражений через временные переменные. Вводить специальные сущности для функции/оператора/числа/etc также не обязательно — достаточно определить один базовый класс «ВычислительнаяЕдиница», наследниками которого являются и функции, и операторы, и числа. Разница с обычным подходом в том, что например синус — это не глобальная процедура или метод статического класса, а экземпляр класса, который помимо перегруженного метода «Вычислить» сохраняет результат этого вычисления у себя в свойствах, а не в глобальном стеке.
Можно пойти ещё дальше и реализовать полноценную data-flow диаграмму, которая также прекрасно помещается в линейный список. Дополнительным бонусом к этому будет возможность у функций иметь не только несколько входов, но и несколько выходов, а также возможность прозрачной реализации «грязных» функций, то есть с внутренним состоянием (типа линий задержек, фильтров, связи с внешним миром и т.д.).


Dr_Dash
01.12.2022 12:28С чего начинается программирование? С простановки задачи. В вышеописанном контексте задачей является управление работой процессора посредством трансляции набора команд. Вообще производитель любого процессора уже решил эту задачу, предоставив потребителю спецификацию с набором поддерживаемых процессором команд. Такая спецификация содержит инструкции (команды) ассемблера и, возможно, рекомендации по использованию этих инструкций.
Что такое, товарищи, дебют и что такое, товарищи, идея?Дебют, товарищи, это quasi una fantasia. А что такое, товарищи, значит идея? Идея, товарищи, – это человеческая мысль, облеченная в логическую шахматную форму.
staticmain
Первые 8 абзацев - что угодно, политическая повестка, обмазывание код ядра Linux говном, какой-то бессистемный исторический экскурс, но не тема самой статьи.
К самому коду тоже есть претензии, но это литье воды целую страницу текста отбивает любое желание в нем подробно разбираться.
Вместо создания громоздкого создания дерева разбора грамматики можно было просто избавиться от этого используя RPN.