
Привет, дорогие читатели! Меня зовут Алина, я работаю операционным менеджером в компании Training Data, которая занимается сбором и разметкой данных. Я веду проекты по разметке, а еще благодаря знанию python пишу скрипты для автоматизации работы своей команды. У меня накопилось много интересного опыта, которым я хочу с вами поделиться.
Своей первой статьей я открываю рубрику разбора любопытных кейсов, с которыми столкнулись я и мои коллеги во время организации разметки данных в CVAT.
“Computer Vision Annotation Tool (CVAT) – это инструмент с открытым исходным кодом для разметки цифровых изображений и видео. Основной его задачей является предоставление пользователю удобных и эффективных средств разметки наборов данных. “ - цитата из статьи создателей.
Все мы с вами прекрасно знаем детскую игру на развитие внимательности и наблюдательности - поиск отличий на картинках. Она встречалась нам в журналах, на календарях, а позже - на сайтах и мемах в VK. Но кто бы мог подумать, что подобная забава дойдет и до разметки данных для обучения нейронных сетей?

С каждым днем появляется всё больше запросов на разметку данных для самых разных нейронок, сфера деятельности которых порой удивляет, смешит или шокирует. Но для каких же направлений деятельности нейронке необходимо научиться находить отличия? Примеров можно найти кучу: пустоты на полках, забытые вещи, счетчик движения и т.д.
Передо мной встала задача организовать разметку данных покадровой съемки помещений, в которых люди случайно или специально оставляли предметы. Разметчикам необходимо было выделить область изменения на кадрах с помощью bbox (прямоугольника), также необходимо было, чтобы область изменения была зафиксирована на двух кадрах: кадр "до изменения", кадр "с изменением". Странные запросы от ребят из команды разработчиков нейронки я получаю не в первый раз, поэтому без лишних вопросов приступаем к задаче.
Инструмент для разметки данных CVAT не позволяет показывать в одной рабочей области сразу два и более отдельных изображений. Присутствует возможность лишь перелистывать изображения.

Поэтому на этапе загрузки изображений в CVAT я столкнулась со следующей проблемой: как показывать разметчику (человеку, который будет размечать данные) сразу несколько кадров?
Если выполнять эту задачу "в тупую", то мы просто заливаем в CVAT все кадры в их порядке, и разметчику нужно будет листать кадры вперед-назад, чтобы определить на них отличия. Далее нужно будет разметить bbox на одном кадре и сделать точно такой же bbox на другом. Времени такой метод займет очень много, качество будет сомнительным, разметчики будут быстро уставать. Поэтому начинаем придумывать оптимизацию.
Самое простое решение для проблемы с перелистыванием кадров - соединить соседние кадры в одно изображение.
Плюсы: легко и быстро программируется на Python через PIL; разметчику удобно сравнивать два кадра.
Минусы: увеличивается вес изображений, что ведет к повышению времени ожидания загрузки изображения в CVAT (однако и это можно пофиксить при желании).
Пример функции glue_together, которая выполняет "склеивание" двух изображений в одно:
from PIL import Image
import os.path as osp
def glue_together(image1, image2, out_path):
img1 = Image.open(image1)
img2 = Image.open(image2)
width = img1.size[0]*2 #определяем ширину будущего "склеенного" изображения
height = img1.size[1] #берем высоту первого изображения
img = Image.new('RGB', (width, height))
img.paste(img1, (0,0))
img.paste(img2, (img1.size[0], 0))
img.save(osp.join(out_path,
f'{osp.basename(image1)}__{osp.basename(image2)}'))В функции использовались две библиотеки: PIL (pillow) и os. Первая позволяет обрабатывать изображения (я лично отдаю этой библиотеке большее предпочтение, чем OpenCV), вторая в данном случае нацелена на помощь в написании пути к файлу.
Обращаю внимание на то, что в моем кейсе все изображения имели одинаковую ширину и высоту, что позволило не запариваться с тем, чтобы подгонять файлы разной величины друг под друга.
Для примера я обрезала двух осьминожек:


И, использовав функцию glue_together, склеила их:
")
Отлично! Теперь разметчику будет легче ориентироваться среди кадров. Однако уже перед началом разметки появляются новые вопросы:
Как мне точно узнать, где заканчивается один кадр и начинается другой?
Выделение одинаковых областей "на глаз" на двух кадрах - достаточно сложно и займёт много времени, можем как-то ускорить? Можем как-то упростить?
Вопросы действительно толковые и решение их приведет к более быстрой и качественной разметке. Если не решить их, то разметчику придется:
а) запоминать параметры первого bbox'а, чтобы сделать точно такой же второй;
б) постоянно ориентироваться на "прицел" в CVAT, который поможет в определении верхней и нижней границы bbox;
в) стараться попасть в такую же точку левого верхнего угла первого bbox'а при создании второго bbox'а, ведь "прицел" не помогает определить правую и левую границы, поэтому придется работать "на глаз".

Первое, что приходит на ум - сделать сетку поверх изображения. Идея достаточно годная, и она даже решит все вышеупомянутые проблемы. Но мне подсказали более крутой вариант: не просто нарисовать сетку на исходном изображении, а создать сетку в виде разметки в самом CVAT, чтобы разметчикам оставалось лишь менять классы bbox'ов, не тратя время на их создание.
Супер, круто, офигенно! Но... как это реализовать?
Делюсь пошаговой инструкцией:
Так как файлы мы уже залили в CVAT, у нас создался таск и, значит, сгенерировался xml файл с разметкой. Для того, чтобы скачать его, необходимо зайти на страницу таска, в правом верхнем углу кликнуть на Actions, выбрать Export task dataset, в списке Export format выбрать CVAT for images 1.1 и нажать OK.У вас скачается архив, в котором лежит xml файл с разметкой. Откроем его.

Тег <meta>, описывающий всю инфу о таске, нам не нужен, с ним мы работать не будем. Наше внимание обращаем на тег <image>. Как раз в нём должна быть информация о разметке на конкретном изображении. Создадим рандомный bbox на фотографии и посмотрим как изменится файл.

Под тегом <meta> появился тег <box>. В нем мы видим название класса (label) и координаты bbox'а: xtl (x top left) - левая верхняя точка по x, ytl (y top left) - левая верхняя точка по y, xbr (x bottom right) - правая низшая точка по x, ybr (y bottom right) - правая низшая точка по y.
Для работы с xml воспользуемся библиотекой ElementTree:
import xml.etree.ElementTree as ET
from tqdm import tqdm
import os.path as osp
def make_patches(w, h, numb_lines=10): #создание списка координат bbox'a
step = int(h / numb_lines)
coords = []
for x in range(0, w, step):
for y in range(0, h, step):
x1, y1, x2, y2 = x, y, x + step, y + step
coords.append((x1, y1, x2, y2))
return coords
def pre_annotation(empty_annotation, pre_annotation):
#создание нового файла разметки
tree = ET.parse(empty_annotation)
root = tree.getroot()
for child in tqdm(root):
if child.tag not in {'version', 'meta'}:
image_coords = make_patches(int(child.attrib['width']),
int(child.attrib['height']), 10)
for coord in image_coords:
bbox = ET.Element('box', label="без изменений", occluded="0",
source="pre_annotated",
xtl=str(coord[0]), ytl=str(coord[1]),
xbr=str(coord[2]),
ybr=str(coord[3]),z_order="0")
child.append(bbox)
xml_str = ET.tostring(root, encoding='utf-8', method='xml')
with open(osp.join(pre_annotation,'pre_annotation.xml'), 'wb') as xmlfile:
xmlfile.write(xml_str)
xmlfile.close() Для того, чтобы загрузить наш файл с предразметкой - pre_annotation.xml, необходимо снова зайти на страницу таска, в правом верхнем углу кликнуть на Actions, выбрать Upload annotations, в выпадающем списке выбрать CVAT 1.1 и указать путь к файлу pre_annotation.xml.
Предразметка загрузится на таск и CVAT об этом сообщит:

Откроем изображение и посмотрим что получилось:
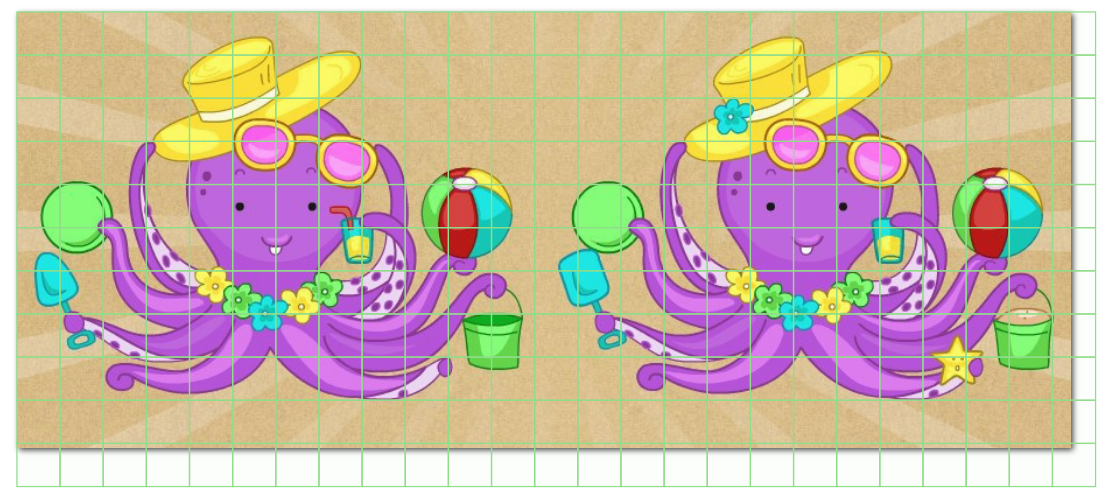
Как мы видим, сетка наложилась удачно. Однако она не ориентирована на то, что наше изображение состоит из двух кадров, и нам необходимо, чтобы каждый bbox для каждого кадра имел одинаковые координаты, когда мы будем обрабатывать результат разметки. В данном же примере координаты левого верхнего bbox'а левого кадра НЕ равны координатам левого верхнего bbox'a правого кадра. Для этого даже не нужно залезать в xml и просчитывать разметку отдельно для каждого кадра, это видно сразу по тому, как bbox'ы съехали за правую границу склеенного изображения.
Данный недочет необходимо исправить. А также появилась новая идея: сделать так, чтобы при выборе одного бокса, второй бокс-дубликат с другого кадра автоматически изменялся. Я видела два варианта решения этого вопроса:
1. создать такую сетку, где bbox'ы будут связаны;
2. решить этот вопрос при обработке файла разметки
Первый вариант выглядел наиболее интересным, потому что я не представляла как это можно сделать. Но решение проблемы рано или поздно всплывает в голове, и вот что было решено сделать:
создать полигон из 8-ми точек

Для этого был написан следующий код:
import xml.etree.ElementTree as ET
from tqdm import tqdm
import os.path as osp
from PIL import Image
def new_glue_together(image1, image2, out_path):
img1 = Image.open(image1)
img2 = Image.open(image2)
width = img1.size[0]*2+int(img1.size[0]/80)
height = img1.size[1]
img = Image.new('RGB', (width, img1.size[1]))
img.paste(img1, (0,0))
img.paste(img2, (img1.size[0]+int(img1.size[0]/80), 0))
img.save(osp.join(out_path, f'{osp.basename(image1)}__{osp.basename(image2)}'))
def new_make_patches(w_start, h_start, ROWS_PER_IMAGE = 10):
coords = []
frame_w = w_start//2-int((w_start//2)*0.005964)
side = h_start//ROWS_PER_IMAGE
x, y, w, h = (0, 0, side, side)
while y < h_start:
x = 0
while x < frame_w:
w_ = min(w, frame_w - x)
h_ = min(h, h_start - y)
coords.append([
(x+w_,y),
(x+w_,y+h_),
(x,y+h_),
(x,y),
(x+w_ + frame_w + int(frame_w/80), y),
(x+w_ + frame_w + int(frame_w/80), y+h_),
(x + frame_w + int(frame_w/80), y+h_),
(x + frame_w + int(frame_w/80), y)
])
x += w
y += h
return coords
def pre_annotation(empty_annotation, pre_annotation):
tree = ET.parse(empty_annotation)
root = tree.getroot()
for child in tqdm(root):
if child.tag not in {'version', 'meta'}:
image_coords = new_make_patches(int(child.attrib['width']),
int(child.attrib['height']), 10)
for coord in image_coords:
str_coords = ""
for c in coord:
if c != coord[-1]:
str_coords += str(c[0])+', '+str(c[1])+'; '
else:
str_coords += str(c[0])+', '+str(c[1])
bbox = ET.Element('polygon', label="без изменений", occluded="0",
source="pre_annotated", points=str_coords,
z_order="0")
child.append(bbox)
xml_str = ET.tostring(root, encoding='utf-8', method='xml')
with open(osp.join(pre_annotation,'pre_annotation.xml'), 'wb') as xmlfile:
xmlfile.write(xml_str)
xmlfile.close()Что изменилось:
переписана функция glue_together:
а) добавлено создание "перегородки" между изображениями, имхо так легче понимать, где кончается один кадр и начинается другойпереписана функция make_patches:
а) список координат собирается под полигон, а не бокс
б) учитывается добавленная "перегородка" между кадрамипереписана функция pre_annotation:
а) теперь она заточена на добавление полигонов, а не bbox'ов
Результат:

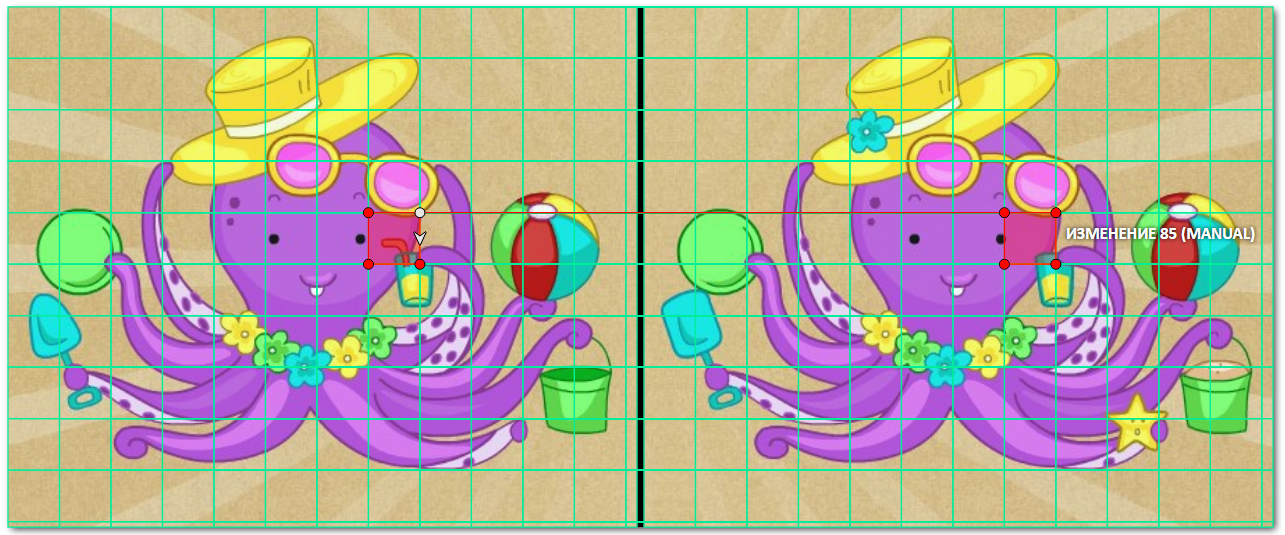
Вуаля! Скучная разметка данных превратилась в игру-головоломку.
Теперь можно подвести итоги
Посредством того, что мы визуализировали 2 кадра на одном изображении и создали сеточную предразметку, нам удалось добиться:
создания комфортного процесса разметки для разметчиков;
повышения качества разметки;
повышения скорости разметки;
предотвращения быстрой переутомляемости разметчиков.
Таким образом, мы выполнили запрос разработчиков, которые хотели чтобы область изменения была зафиксирована на двух кадрах. Конечно, чтобы создать удовлетворяющий файл-результат разметки нужно написать еще один скрипт, который преобразует xml-файл из CVAT'а в понятный для разработчиков вид. Стоит отметить, что это влечет за собой еще больше нагрузки на человека, который занимается технической поддержкой проектов разметки (в данном случае нагрузка падает на меня). Но в подобных задачах упор всегда делается на то, чтобы оптимизировать по-максимуму время работы разметчиков, потому что процесс ручной разметки почти всегда идет дольше, чем процесс написания дополнительного скрипта.
P.S. Исходные скрипты и фотографии можно найти на моем профиле гитхаба.
Комментарии (11)

biff_33
08.12.2022 00:59+3Проще


alinyao Автор
08.12.2022 01:01+2Хахахах! Ну да, это намного проще в рамках таких детских картинок.)) Они использовались для примера только. Реальные кадры были не с такими четкими и явными изменениями, поэтому то и требовалась ручная разметка.
Но в целом, как варик, твое решение почти полностью заменяет мою статью xD
freebsn
08.12.2022 09:33+1Привет, в рамках детских картинок я на них смотрю как на стереопару, когда надо быстро найти отличия, с вашей картинкой, уменьшил масштаб страницы до 60%, свел взгляд как при стереопаре и сразу же увидел все отличия и совочек, который не сразу заметил.
Правда при длительном смотрение таким образом это утомительно
и можно ли это как то использовать в процессе не знаю.


ilikeMagic
08.12.2022 16:25Алина, благодарю за статью. Если требуется не типовая разметка, то сколько времени обычно уходит на подготовку предразметки для асессоров?
alinyao Автор
08.12.2022 16:29На самом деле все очень ситуативно. Но обычно подобные задачи можно выполнить в течение одного дня, если другой нагрузки нет. У меня раньше уходило больше времени, чем сейчас: с 4-6 часов до 2-4 часов. Уже набила много шишек и сходу придумываются разные варианты подхода к не типовым задачкам.)

nikman-ru
08.12.2022 16:31
Спасибо. Хорошая статья. CVAT умеет показывать сетку. У нее есть несколько применений. Разработчики используют ее, чтобы UI дебажить и выравнивать элементы. Некоторые пользователи используют ее, чтобы не размечать объекты слишком маленькие или большие.
alinyao Автор
08.12.2022 16:45Привет! Да, это так. CVAT действительно умеет показывать сетку. Причем мы сами можем настроить ее размер и цвет. И если бы моя задача решалась только тем, что мы добавляем сетку поверх изображения, то да, можно было бы вообще не писать код.)
Проблема сетки из CVAT в том, что она только для UI и годна. Что в целом очень даже хорошо, для многих задач этого правда достаточно. Но в моем случае асессору (разметчику) все равно придется затрачивать дополнительное время, чтобы точно "прицелиться" в квадрат.
Но тут, как вариант, можно было бы потом просто с помощью скрипта обработать файл-результат разметки. И везде, где координаты на боксах соседних изображений похожи и имеют один и тот же класс, высчитать среднее значение этих координат и заменить их на двух кадрах. Тогда в результате мы получим одинаковые координаты одного бокса на двух кадрах подряд.
Также только лишь добавление сетки не очень помогает с вопросом "перелистывания" кадров. А если мы и соединяем два кадра в одно изображение, то нам придется "играться" с размером сетки CVAT, пока центральная вертикальная линия не ляжет точно посередине на склейке кадров. И здесь мы уже впадаем в зависимость от разметка сетки.
А с помощью моего скрипта можно сделать сетку любого размера и разметчику не придется листать кадры и максимально точно ставить боксы, попадая в края сетки CVAT.
Как вывод, хочу сказать, что встроенная сетка CVAT - топ! Будет очень круто если ее сделают лучше так, чтобы при создании боксов или полигонов точки "примагничивались" к ней.nikman-ru
08.12.2022 17:00Присылайте запрос на фичу с примагничиванием. Когда-нибудь разработчики добавят, особенно, если это будет ускорять какие-то сценарии. В вашем случае не нужно размечать обе картинки. Достаточно разметить левую. Координаты для второй картики, если парные картинки одинакового размера, будут такие же.

jsilverhand
10.12.2022 12:39Хорошая статья, если задача по разметке типовая, то действительно имеет смысл заранее упрощать процесс для разметчиков.
Сама задача забавная)
mst_72
Шикарная статья :) Чётко, просто, по делу.
Одна мелкая ремарка:
Это Join. Не надо так строки складывать :)
Не вдаваясь в подробности str(c[0]) лучше было бы как-то так попробовать
alinyao Автор
Спасибо!
Да, согласна, можно просто через join было сделать.)
Это у меня довольно старый кейс, тогда я питон не оч хорошо знала, но сейчас, когда дописывала статью, код решила не менять. Работает? Работает. Это главное.))
Но мейби для тех, кто будет его юзать, будет полезно прочитать твой коммент.