
Хабр, привет! Меня зовут Вера Кокотова, я тимлид группы технической архитектуры и разработки в направлении 1С. В посте хочу рассказать, как мы в проектах управляем жизненным циклом приложений от инфраструктуры до развернутого в web-сервиса с помощью подхода Infrastructure as Code.
До автоматизации процессов мы тратили до 40 часов на то, чтобы поднять сервер со сборочной линией, и 1-2 дня на сам стенд разработки и автотесты. Сейчас – 40 минут и довольные инженеры, которые смогли почти полностью уйти от рутины системного администрирования и сосредоточиться на развитии практик в рамках группы.
Как мы пришли к такому happy end и что у системы под капотом – читайте после ката.

Как все устроено в проектах
Под каждый проект мы поднимаем стенд разработки. До этого года в основном на Windows, но сейчас (по понятным причинам) значительно выросла доля проектов на стеке Linux + Postgres. Стенд поднимается в нашем Облаке КРОК, а не у заказчика – по крайней мере до передачи системы в эксплуатацию. Также под каждый проект у нас поднимается стенд со сборочной линией под каждую конфигурацию и опционально сборочная линия для прогона автотестов. Сервер, на котором расположены сервисы CI/CD, разворачивается на Linux. Автотесты тоже на линукс или возможно размещение базы под автотесты на сервере разработки.
В итоге процесс выглядит так: развернуть инфраструктуру, взять некоторое количество серверов, установить на них определенную ОС, установить и настроить другое нужное ПО, настроить скрипты автоматизации, выполнить настройки интеграции сервисов, создать пользователей.
Основная трудоемкость лежит в разворачивании стенда со сборочной линией. Стенд предоставляет сервисы:
СППР
сервис хранилищ конфигурации;
Gitlab – сервис распределенной системы контроля версий;
Сервис на базе Gitsync, который раскладывает версии хранилища в Git;
Sonar Qube – сервис проверки качества кода;
Автотесты;
Jenkins, который обеспечивает автоматический запуск задач.

Все эти сервисы связывают работу участников проекта в единый процесс. Консультанты фиксируют требования к системе в СППР, описывают бизнес-процессы. Потом мы формируем каталог бизнес-процессов и на этапе проектирования описываем доработки (в терминах объектов метаданных, которые загружаются из хранилища 1С).
Доработки выполняются в хранилище 1С, конфигурация каждой версии хранилища с помощью сервиса синхронизации раскладывается на исходники и отправляется в Git-репозиторий. Все происходит автоматически после коммита, анализ проверки качества кода и прогон автотестов – тоже. Результаты – на почте :)
Под каждый проект мы разворачиваем ноду, на которой работают сервисы СУБД, сервер 1С, веб-сервер. Состав сервисов от стека не зависит. У нас есть:
эталонная база – прообраз базы продуктива с необходимыми настройками и НСИ;
база моделирования – общая база для сквозного тестирования процессов;
демо-база – типовая демо-база без доработок;
по индивидуальной базе для каждого разработчика и консультанта.
Плюс в этих базах (кроме демо) создается набор пользователей – по составу участников проектной команды.
И в чем проблема?
Итак, есть проект, сервисы, стенды, проектная команда, понимание на каком стеке мы работаем и какие задачи хотим автоматизировать. Самый тривиальный способ – отдать все инженеру и погрузиться в ожидание. И тут как раз есть проблемы – инженер, в силу специфики своей работы, участвует во многих проектах, и поэтому процесс разворота может затянуться. Плюс требуются специальные знания, то есть не каждый сможет такую инфраструктуру поднять. Соответственно, когда мы выполняем много ручных действий, то и вероятность ошибки выше – инженер может забыть запустить какой-то скрипт, потом будет разбираться почему не работает. И пошло-поехало.
В общем, процесс хоть и рабочий, но слишком долгий (напомню, что это несколько дней, а то и неделя). К тому же, если хорошему инженеру постоянно давать однотипные задачи, он в итоге загрустит.
Путь к автоматизации
В первой итерации сервисы поднимали на Windows, но почти сразу мы перешли на Linux, в том числе, потому что это экономит затраты на инфраструктуру. С Linux мы сразу же стали использовать Docker. Схема была такая: создали шаблон виртуальной машины с Docker, который донастраивался в процессе разворачивания стенда под новый проект. В такой конфигурации прожили несколько лет. Но даже при таком подходе оставалось достаточно много рутинных действий – инициализация репозиториев, создание хранилищ, настройка интеграций. С тех времен сохранилась инструкция по “донастройке” – это где-то 20 листов дополнительных действий.
В итоге пошли в сторону еще большей автоматизации – по сути сейчас стенд разворачивается по одной кнопке с помощью Terraform и Ansible. В дальнейшем к этому процессу подключили разворот стенда разработки на Linux и стенда с пайплайном под автотесты.
Как теперь это выглядит под капотом
Расскажу по порядку кратко про каждый инструмент.
Docker
Большинство сервисов стенда работают в докер-контейнерах. В классическом подходе для установки программы нужно совершить несколько действий: выполнить скрипт, изменить файлы настроек и так далее. В этом процессе не исключена вероятность человеческой ошибки: инженер запустит скрипт два раза, перепутает последовательность или что-то забудет. Контейнеры позволяют полностью автоматизировать этот процесс, так как включают в себя все нужные зависимости и порядок выполнения действий. По сути, Docker-файл автоматизирует процесс сборки приложения, что делает процесс повторяемым.

Еще один плюс – возможность поместить образ после тестирования в Docker Registry и переиспользовать на других виртуальных машинах. Один контейнер соответствует одному запущенному сервису. Экземпляр приложения запускается в изолированной среде со своей ОС и настройками, не влияющей на основную операционную систему. Если приложение в контейнере завершится с ошибкой или зависнет, это никак не затронет основную ОС. И, конечно, использование Docker помогает нам ускорить процесс развертывания всех сервисов.
Terraform и Ansible
Сами хосты, где запускаются контейнеры, размещены в облаке. Для их разворачивания мы используем утилиту Terraform, а для донастройки ОС, сервисов интеграций – Ansible. Terraform предоставляет декларативный способ управления инфраструктурой – мы указываем требуемую конфигурацию виртуальной машины, а Terraform, взаимодействуя с API облака, разворачивает и запускает виртуальный хост.

В чем преимущества Terraform для нас?
Используем единообразный подход к различающимся в зависимости от облака API. Не используем консоль облака – все операции можно выполнять из командной строки.
Terraform умеет хранить состояние виртульных машин (state) – локально или в специальном хранилище. Это позволяет при необходимости быстро вносить изменения в работающие ВМ без их пересоздания.
Файл описания ВМ параметризуем – конфигурацию создаваемой машины можно привязать, например, к количеству пользователей, которые будут с ней работать. Параметры можно передавать как в командной строке, так и в хранить в отдельных файлах.
Теперь про Ansible. После того, как Terraform развернула виртуальную машину в облаке, мы получили ее IP и ID. Мы отдаем его в Ansible, и он уже заканчивает настройку ОС. Установка агентов не требуется, что очень удобно.
Почему мы вообще выбрали Ansible? У него низкий порог вхождения по сравнению с остальными системами управления конфигурациями. У Ansible много модулей, при желании можно написать свой модуль на Python. Если это понадобится, мы сможем легко это сделать, так как команда знакома с языком, у нас есть скрипты на Python, которые используем в проде. А еще по Ansible много документации, она регулярно обновляется и если что, информацию найти легко.
Суммирую, как теперь выглядит процесс создания стенда.
Мы запускаем задачу в Jenkins, передаем туда необходимые параметры, вид стенда, проектную команду, версию платформы. Jenkins подключается к Git-репозиторию, в котором хранится сама настройка этого pipeline: Jenkinsfile, - и необходимые настройки конфигурационных файлов Terraform и Ansible. Далее происходит разворот, создается виртуальная машина Terraform, потом она донастраивается Ansible. На заключительном этапе создается новая ветка для развернутой ноды, ее состояние пушится в Git-репозиторий, чтобы мы видели на основе чего эта нода была развернута.


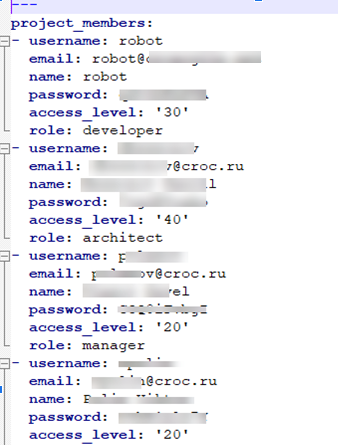
Здесь показана сама задача Jenkins, как выглядит ее запуск и файлик с участниками проектной команды, т.е. мы указываем не только логин и пароль, но и почту, и саму роль участника проектной команды.
Выводы
Теперь создание стенда происходит намного быстрее, буквально по кнопке, а время сократилось до 40 минут. Участие инженера необходимо, но в намного меньшем объеме, так как требуется только пересоздать контейнеры с другой версией платформы (зачастую они меняются от проекта к проекту). Каждый участник команды может внести в этот процесс свои изменения и подключиться к развитию этого инструмента. Ноды между собой едины и так называемого configuration drift нет.
И самое главное – высокое качество разработки и довольные инженеры с меньшим количеством рутины.
В статье упоминаю opensource-продукты – все собрала в таблицу.
Вот здесь
Продукт |
Вендор/Автор |
Ссылка 1 |
Ссылка 2 |
1С |
1С |
||
1С: СППР |
1С |
||
1С: ДО |
1С |
||
Git |
SFC |
||
Gitlab |
Gitlab |
||
Jira |
Atlassian |
||
ReportPortal |
EPAM Systems, Inc. |
||
SonarQube |
SonarSource |
||
Jenkins |
Косукэ Кавагути |
||
SourceTree |
Atlassian |
||
xUnitFor1C |
artbear |
||
Gitsync |
EvilBeaver |
||
SonarQube 1C (BSL) Community Plugin |
nixel2007 |
||
Ansible |
Михаэль ДеХаан/ Red Hat и Ansible |
||
Terraform |
Mitchell Hashimoto и др./HashiCorp |
||
Docker |
Соломон Хайкс/ Docker |
R72
Здесь СППР назвали сервисом хранилищ конфигурации, а по тексту в статье там только требования фиксируются и бизнес-процессы и это всё связывается с метаданными из конф. Где ж тут аж цельный сервис хранилищ?
SnowyV Автор
оу, вы все верно поняли, это опечатка. должно быть два отдельных пункта: СППР и сервис хранилищ
R72
У нас в чате по СППР в телеграм (https://t.me/SPPR_1C) этой темой интересуются и были бы признательны, если бы вы к нам зашли и немного рассказали про опыт работы с СППР. Я писал в КРОК на почту контактов с общественностью, просил прийти в чат, рассказать, ответить на ряд вопросов, но ни ответа ни привета не получили.
А наши читатели следят за темой, они знают и помнят старую статью КРОКа нескольколетнейдавности про опыт с СППР и с проектированием архитектуры. Сравнивают с этой вашей статьёй, пытаются понять что изменилось, много ли сумел КРОК в части цифровизации проектирования продвинуться...