
Большое количество модулей Maven замедляет сборку проекта и время прогона тестов. Для того, чтобы сохранить многомодульную структуру проекта и быстро прогонять тесты, мы в Wrike написали новый инструмент — Maven Modules Merger, который сократил время некоторых сборок с 50 до 12 минут. В статье подробно расскажу о том, с какими проблемами нам помог справиться Maven Modules Merger и поделюсь подробностями его создания.

В Wrike мы разрабатываем одноименную SaaS-платформу для управления проектами.

Более 53 000 тестов в проекте автотестов Wrike помогают нам обеспечивать высокое качество продукта. 16 000 из них — это REST API тесты, остальные 37 000 — Selenium-тесты. Около 30 scrum-команд каждый месяц добавляют по 1000 новых тестов, а также постоянно изменяют старые.
В проекте автотестов мы используем Java 17, JUnit 5 и Maven как инструмент сборки. Selenium-тесты мы пишем с помощью библиотеки HtmlElements 2, а тесты на внутренний API — с помощью библиотеки Retrofit.
Все тесты распределены по 250 модулям Maven и находятся в одном проекте, который содержит более 1.6 млн строк. Модуль Maven — это подпроект. С ним можно работать независимо от других модулей: например, запускать тесты или компилировать код.
Почему мы решили использовать многомодульную структуру проекта
У такой структуры есть ряд преимуществ по сравнению с одномодульной.
Многомодульная структура позволяет логически разделить тесты на разные компоненты продукта. Такого же эффекта можно добиться при разделении кода на пакеты, однако разделение на пакеты не имеет других преимуществ многомодульного проекта.

Разнесение кода по модулям помогает избежать неправильного использования классов. Когда все классы находятся в одном модуле, есть вероятность, что разработчик ошибется и неправильно использует класс с похожим именем.
Например, в нашем случае классы TSDateInputSteps (Typescript-версия), DateInputSteps (Dart-версия) и DateTimeInputSteps находятся в разных модулях. Это гарантирует, что один класс не будет случайно использован вместо другого. Если разработчик захочет использовать другой класс, ему явно придется указать зависимость в pom-файле, а это будет бросаться в глаза при проведении code review.
Многомодульная структура позволяет запускать тесты отдельно в каждом модуле. Для запуска тестов из определенных модулей понадобится -pl — ключ Maven, в который передается список модулей через запятую. При передаче списка только эти модули и их зависимости будут скомпилированы (вместо компиляции всего проекта). Это позволяет сэкономить время: например, на моем ноутбуке компиляция всего проекта занимает 19 минут, а компиляция одного модуля среднего размера — 1 минуту. Характеристики моего ноутбука: MacBook Pro (16-inch, 2019), CPU 2,6 GHz 6-Core Intel Core i7, RAM 16 GB 2667 MHz DDR4.
В модуле можно делать изменения и добавлять новые тесты, абстрагируясь от других модулей. В IDE можно отдельно открыть один модуль и работать с ним как с маленьким проектом.
Разделить многомодульный проект на отдельные проекты гораздо проще. В этом случае каждый модуль может стать самостоятельным проектом.
Почему просто не сделать 250 отдельных проектов? Изначально мы думали об этом, и разделение на модули было своеобразной «страховкой» на случай, если мы решим распиливать монолит. Оказалось, что поддерживать большое количество сильно связанных проектов очень сложно: изменения происходят постоянно, и часто есть вероятность возникновения конфликтов разных версий проектов.
Распливание монолита уже было актуально для backend-проекта. Прочитать об этом подробнее можно в этой статье.
При небольшом количестве модулей многомодульная структура работала достаточно хорошо, но со временем количество модулей стало исчисляться сотнями, и у нас начали появляться проблемы:
Нам стало сложно регулировать количество потоков для параллельного запуска тестов.
Перезапуски тестов после каждого модуля занимали до 50% от времени всего прогона.
Проблема управления количеством потоков
Из-за большого количества тестов невозможно использовать последовательный запуск. Если бы мы запускали все тесты последовательно, то нам бы пришлось ждать результатов работы тестов больше двух месяцев. Поэтому обычно мы запускаем тесты в TeamCity в 80-150 потоков в зависимости от типа сборки.
При большом количестве модулей становится сложно управлять количеством потоков, которое используется для прогона тестов. Если в модуле тестов меньше, чем число потоков, которое используется при запуске, то количество параллельно запущенных тестов будет равняться количеству тестов в модуле.
Например, если мы запускаем тесты в 80 потоков, то для модуля с 10 тестами будет использоваться только 10 потоков. При этом каждый модуль будет ждать окончания тестов предыдущего модуля.
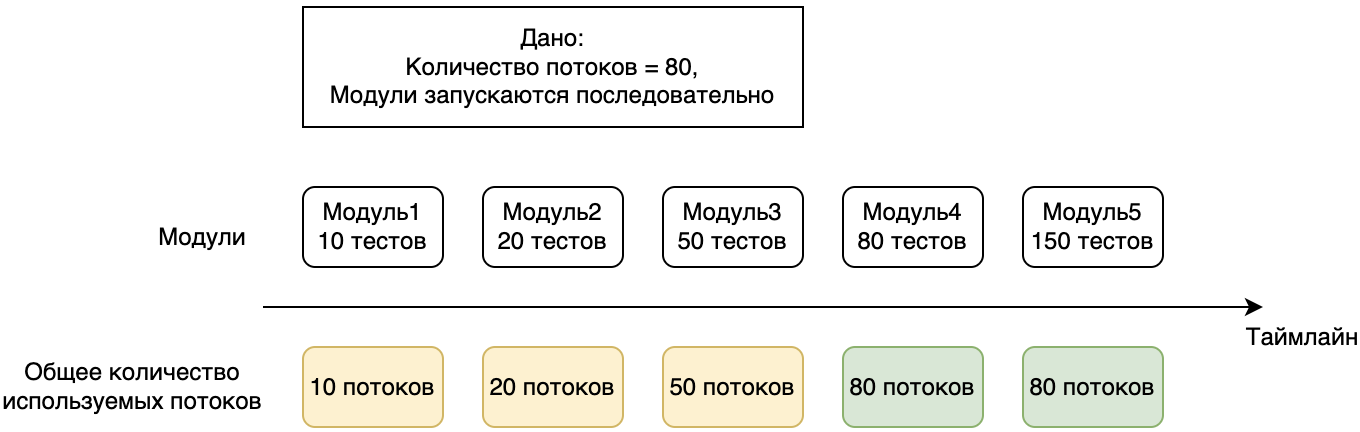
Если в модуле находится 81 тест, а тесты запускаются в 80 потоков, то 1 тест будет запущен только в одном потоке.
Чтобы решить эту проблему, можно попробовать запустить модули параллельно с помощью -T %number%. -T — это ключ Maven, который параллельно запускает сборку %number% модулей параллельно, если это возможно.
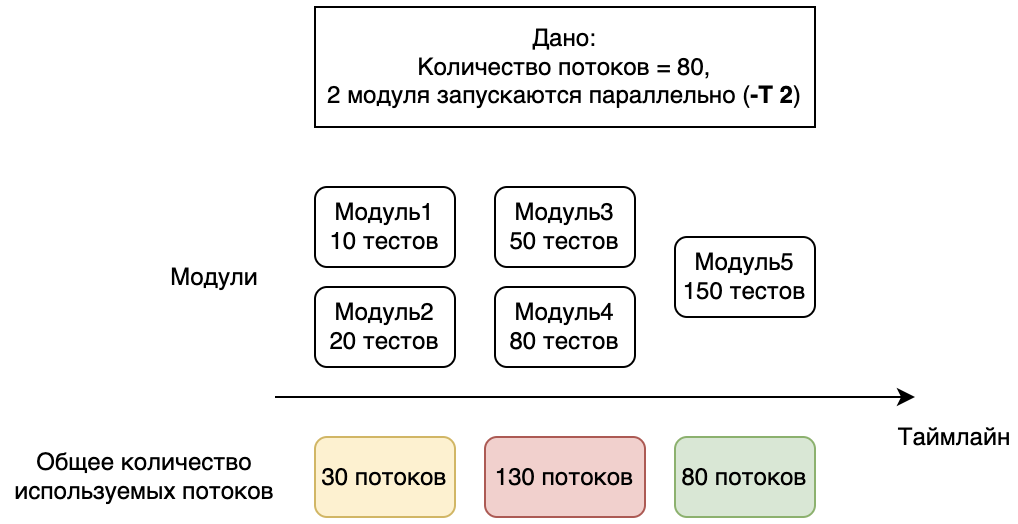
Но у этого решения есть несколько недостатков:
Для модулей с небольшим количеством тестов мы все еще будем получать небольшое количество параллельно запущенных тестов (первый и второй модуль).
Для модулей с большим количеством тестов мы будем получать слишком большое количество потоков (третий и четвертый модуль).
Maven не всегда может запустить модули параллельно (возможность связана с зависимостью модулей друг от друга).
В одномодульном проекте такой проблемы не возникает: мы всегда можем легко настроить необходимое количество потоков.
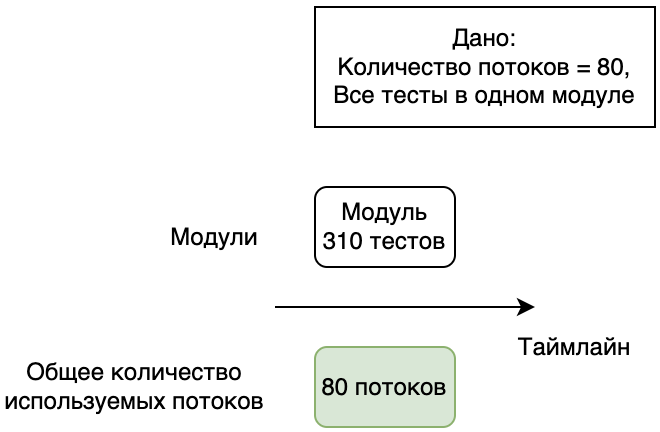
Проблема долгих перезапусков тестов
В Wrike мы используем модифицированный surefire test runner, который умеет перезапускать упавшие тесты. Он собирает их и пробует повторно запустить после всех остальных тестов. Если в каждом модуле упадет по одному тесту, то упавшие тесты будут перезапускаться в один поток, а тесты из следующего модуля — ждать один тест. Если тесты находятся в одном модуле, то на их перезапуск потребуется гораздо меньше времени.

Получается, что многомодульность проекта отрицательно влияет на время прогона тестов.
Но мы не хотели отказываться от преимуществ многомодульного проекта и не стали объединять все модули в один. Нам пришла мысль: что если объединять все модули в один каждый раз, когда мы запускаем тесты в TeamCity? Тогда мы сможем пользоваться преимуществами многомодульного проекта на этапе разработки тестов и преимуществами одномодульного — на этапе запуска.
Идея нового инструмента оказалась проста: нужно просто объединить все файлы в одном новом модуле, сгенерировать pom.xml со всеми зависимостями и запустить тесты в новом модуле. Мы назвали это инструмент Maven Modules Merger (Merger).
Maven Modules Merger
Рассмотрим детали реализации Merger.
На вход Merger подаются:
Список модулей для объединения, разделенный запятыми.
Путь к проекту Maven.
Путь к файлу для записи результата.
Режим работы: sources для исходного кода или target для скомпилированного проекта.
Зачем передавать список модулей, если можно просто объединить все модули? Мы передаем список модулей в Maven c помощью ключа -pl. Это позволяет запускать тесты только из определенных модулей (в каждой сборке мы хотим объединять только необходимые модули).
Алгоритм работы Merger выглядит так:
Вычисление списка модулей для объединения.
Копирование файлов.
Создание pom-файла для merged_modules модуля.
Добавление в корневой pom-файл merged_modules модуля как дочерний модуль.
Запись полученных модулей в файл.
Разберем каждый шаг алгоритма подробно.
Шаг 1: вычисление списка модулей для объединения. В начале мы хотели разрешить объединять все модули, но в ходе реализации столкнулись с трудностями. Директория resources всех модулей объединяется в одну директорию, а наши модули имеют разные конфигурационные файлы, которые хранятся в этой директории.
Мы используем файл test/resources/allure.properties для того, чтобы в Allure разделять тесты на API и Selenium. Мы решили объединять только модули с allure.properties для Selenium-тестов, а остальные модули (backend-тесты и другие) оставлять «как есть». Модулей, которые запускают не Selenium-тесты, оказалось всего 8 из более чем 250, они не будут объединятся.
На этом шаге мы собираем модули с одинаковой конфигурацией и удаляем дубликаты.
Шаг 2: копирование файлов. На этом этапе мы копируем файлы из переданных модулей в новый модуль с именем merged_modules в корне проекта.
Для режима sources копируются все файлы, которые находятся в директории src, для режима target — файлы из директорий target/classes и target/test-classes. Второй режим работы может быть полезен, если у вас есть уже скомпилированный проект, и вы не хотите компилировать код заново после работы Merger. Мы храним скомпилированную версию кода главной ветки, чтобы экономить время на многократной компиляции одного и того же кода в разных сборках TeamCity.
В нашем проекте довольно часто встречались пересечения имен файлов между файлами разных модулей, что приводило к конфликтам во время копирования. Чтобы решить эту проблему, мы дали пакетам в разных модулях уникальные имена, которые совпадают с названием модуля.
Шаг 3: создание pom-файла для merged_modules модуля. Чтобы превратить директорию merged_modules в модуль, нужно добавить в нее pom-файл. В pom-файле merged_modules модуля есть только список зависимостей, который состоит из зависимостей объединенных модулей.
Иногда модули могут зависеть от разных версий одних и тех же библиотек. В нашем проекте все модули имеют версию 1.0-SNAPSHOT, поэтому конфликтов версий при их использовании в качестве зависимостей не возникает. Конфликты могут возникнуть при использовании сторонних библиотек, поэтому их версии настраиваются в корневом pom-файле.
Шаг 4: Добавление в корневой pom-файл merged_modules как дочерний модуль. Следующим шагом необходимо добавить созданный модуль merged_modules как дочерний в корневой pom-файл, чтобы структура модулей Maven была правильной, и Maven смог запустить тесты в новом модуле.

Шаг 5: Запись полученных модулей в файл. На последнем этапе мы через запятую записываем merged_modules и все модули, которые не были объединены. Это список модулей в дальнейшем будет использоваться для передачи в -pl ключ Maven.
После выполнения алгоритма мы получаем проект с новым модулем, в котором объединена большая часть модулей и файл с новым списком модулей.
Время выполнения такого алгоритма на проекте с 12000+ файлами и более чем 240 модулями на удаленном агенте TeamCity занимает 1-2 секунды.
Чтобы договоренности не нарушались, мы добавили новые юнит-тесты и правила PMD. О том, как настроить Checkstyle и PMD, вы можете прочитать в другой нашей статье.
Как мы используем Merger
Мы используем Merger в сборках TeamCity. Для этого мы создали отдельный шаблон, в котором пытаемся объединить модули. Если что-то идет не так, мы запускаем тесты по запасному варианту без использования Merger.
Блок-схема работы такой сборки:

Результаты внедрения Merger
Сборки, которые запускались по большому количеству модулей, значительно ускорились.
Так, например, сборка компонентных тестов, которая запускает 11000 тестов на фронтендные компоненты в 138 модулях, ускорилась ровно в два раза.

Некоторые сборки запускали определенный набор тестов по всем 250+ модулям. С внедрением Merger такие сборки ускорились в 2-4 раза. Например, сборка, в которой запускались все тесты, делающие снимок экрана, стала работать 12 минут вместо 50.

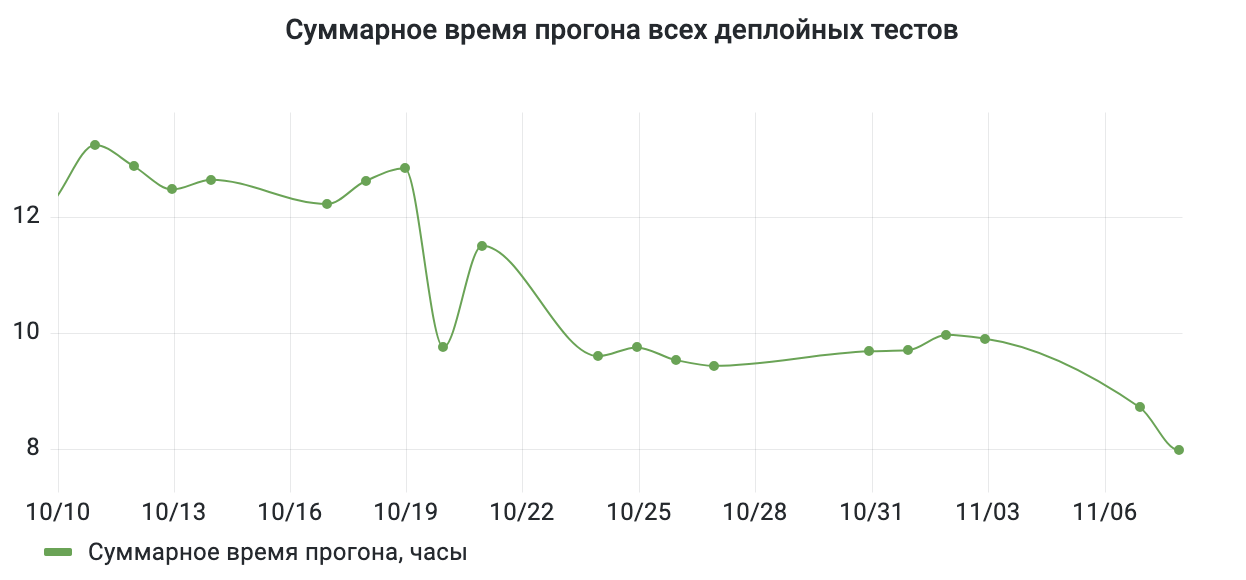
В Wrike деплой новой функциональности продукта происходит каждый день. Перед деплоем мы запускаем абсолютно все тесты в проекте, а некоторые из них запускаются в разных браузерах. Суммарное время запуска всех тестов после внедрения Merger упало больше, чем на треть — с 12.5 часов до 8!
Общее время прогона 61000+ тестов теперь составляет 50 минут. Это стало возможным, потому что мы запускаем некоторые сборки параллельно, а количество потоков в каждой сборке равно 150.
Исходный код Merger можно найти на странице Wrike в Github. Надеемся, что инструмент окажется полезным и в ваших проектах. Пользуйтесь! Мы будем рады вашим комментариям и дополнениям!
insomnia77
Добрый вечер, спасибо за статью. Тоже часто приходилось работать с Maven Reactor и большим кол-вом JUnit тестов. Но у меня не возникало проблем с распараллеливанием. Вы не могли бы объяснить проблему с параллельными запусками подробнее? Я использовал подход, что для каждого модуля отдельная job в Team City/Circle CI/GitLab и мы для модуля задаем количество потоков в Custom Strategy в JUnit 5 https://junit.org/junit5/docs/snapshot/user-guide/#writing-tests-parallel-execution-config
То есть вопрос в том, зачем запускать сборки по большому количеству модулей в одной Team City job? Одна команда автоматизаторов переиспользует тесты от нескольких других команд?