
Введение
Благодаря бессерверным предложениям AWS повышаются возможности разработки, снижается нагрузка на управление, а развернутые приложения могут воспользоваться различными возможностями из коробки, такими как высокая доступность, производительность и оптимизация затрат.
AWS Lambda, API Gateway, DynamoDB — это примеры отличных бессерверных предложений, и ранее мы уже обсуждали, как AWS SAM упрощает процесс создания и развертывания бессерверных приложений.
Давайте воспользуемся полученными знаниями и создадим бэкенд очень простого веб‑приложения. Это упражнение поможет нам построить фундамент, который в дальнейшем мы сможем расширить для выполнения более сложных задач.
Предполагается, что вы уже знакомы с бессерверными предложениями AWS, так как мы не станем подробно разбирать основы. Однако, если вы новичок в этой теме, пожалуйста, ознакомьтесь со следующими постами для справки:
Что мы строим
Следующий скриншот показывает готовое приложение, где обычная веб-страница (HTML, JavaScript, CSS) делает ajax-запросы с регулярным интервалом к бэкенду API, чтобы извлечь данные (случайные цитаты) и отобразить их на веб-странице.
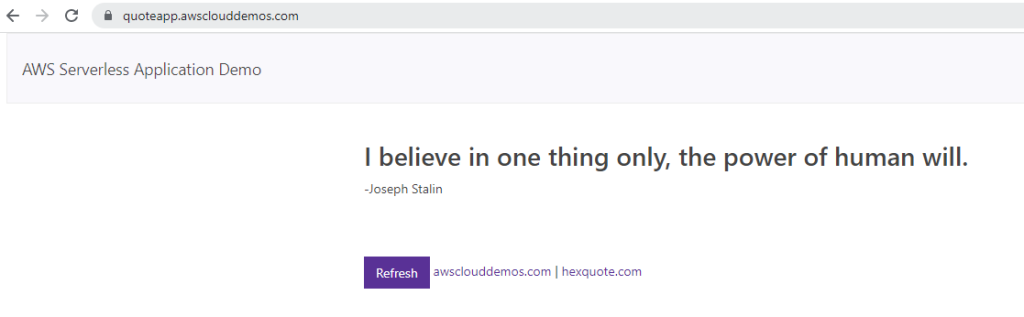
Для этого веб-фронтенда мы создадим простой бэкенд (NodeJS), состоящий из двух лямбда-функций. У нас будет AWS S3 бакет для хранения файлов, а также мы будем использовать Amazon DynamoDB для сохранения данных.
Давайте рассмотрим эти компоненты по очереди в последующих разделах.
Ввод данных
У меня есть json-файл (quotes.json), который содержит цитаты разных авторов.
В нашем решении у нас будет S3 бакет (цитата-json-данные), куда мы/пользователь загрузим json-файл.
Вот как выглядят данные

Поэтому, как только файл будет загружен в S3 бакет, мы подключим событие S3 для инициации лямбда‑функции (функция импорта). Эта лямбда‑функция будет читать данные из json‑файла, а затем сохранять их в таблице DynamoDB. Как только данные будут сохранены, входной json‑файл будет удален из S3 бакета с помощью лямбда‑функции. На следующем рисунке показаны компоненты для этой части:

На этом ввод данных завершен. Теперь посмотрим, как они будут считаны.
Чтение данных
Для этой части мы напишем еще одну лямбда-функцию, которая будет читать ранее сохраненные данные о котировках из таблицы DynamoDB, и сделаем их доступными через API Gateway.
Итак, очень простое действие HTTP Get для чтения случайных цитат и предоставления их вызывающему пользователю. На следующем рисунке показаны добавленные компоненты:

Использование данных (веб-страница)
Хотя это не является основной темой данного поста, но у нас будет обычное веб-приложение с простой функцией JavaScript для выполнения ajax-запроса к эндпойнт API при чтении информации о случайной цитате через регулярные промежутки времени (каждые 12 секунд) и обновления на веб-странице:

Однако мы не будем использовать SAM-шаблон для этой части. Вы можете просто ее пропустить и использовать Postman, например, для тестирования API.
Итак, это и есть наше общее решение, давайте посмотрим, как настроить ресурсы и выполнить деплой бессерверной функции с помощью SAM.
Создание ресурсов в AWS
Я создал git-репозиторий для шаблона SAM и соответствующего кода лямбда-функций и статических ассетов сайта. Вот как выглядит решение в visual studio code:

У нас есть две лямбда‑функции, определенные в шаблоне SAM, и соответствующие папки с кодом. Пожалуйста, ознакомьтесь с файлом sam‑template.yaml и папками кода для получения более подробной информации.
На следующем рисунке показана функция Import, которая инициирована при создании нового объекта в S3 бакете (загрузка файла). Обратите внимание, что в качестве переменной окружения мы передаем имя таблицы DynamoDB, в которую наша лямбда‑функция будет сохранять данные из json‑файла:

Далее, для API Gateway (шлюза) и соответствующей лямбда-функции (QuoteAPIFunction):

Обратите внимание, что bucket‑name (название бакета) передается в эту лямбда‑функцию как переменная окружения, Access задается Policies (политика доступа), и вы можете проверить код лямбда‑функции в папке первоисточника из git‑репо.
Также в шаблоне SAM таблица DynamoDB и S3-бакет (для json‑файла) определены следующим образом:

Как видите, мы используем один и тот же входной параметр для S3 бакета и таблицы DynamoDB.
Деплой ресурсов
Файл README, прилагаемый к исходному коду, содержит команду:

Мы разбирали эти команды в предыдущих постах, ниже приведен результат их выполнения:
команда package (“запаковать”)

команда deploy ("развернуть")

и если мы перейдем в консоль CloudFormation, то сможем проследить статус процесса деплоя более наглядно:

На данном этапе все ресурсы бэкенда AWS созданы. Однако в таблице DynamoDB по-прежнему нет данных.
Поэтому мы можем загрузить файл quotes.json в S3 бакет и посмотреть рабочий процесс (инициировать лямбда-функцию -> сохранить данные в DynamoDB)

после загрузки файла мы можем проверить, сохранились ли данные в таблице DynamoDB:

Кроме того, в рамках деплоя SAM создается Web API, и мы можем проверить, возвращает ли он данные, перейдя по URL:

и вот данные, возвращенные из API:

Наше бэкенд‑решение существует и работает так, как ожидалось. Теперь мы можем осуществить деплой статического сайта и сделать ajax‑запросы к эндпойнт API, чтобы извлечь случайные цитаты и отобразить их на веб‑странице.
Статический сайт
Я уже рассказывал о хостинге статических сайтов с помощью S3 в другой статье, которую вы можете просмотреть для получения более подробной информации.
Ниже приведен код JavaScript, выполняющий ajax‑запросы к эндпойнт API:

с этой схемой мы можем выполнить деплой вебсайта. Посмотрите пример уже развернутого приложения на сайте https://quoteapp.awsclouddemos.com/.
Проектирование решения
Вот наша схема решения для справки:

Код приложения
Сейчас мы не обсудили подробно бэкенд NodeJS и верстку HTML-сайта. Весь исходный код и шаблон SAM доступны в этом git-репозитории. Сам код приложения очень прост и понятен. Тем не менее, я расскажу о составляющих кода приложения более подробно в отдельном посте по мере продвижения.
Резюме
В этом посте мы построили базовый бэкенд бессерверного веб-приложения AW, используя основные бессерверные сервисы AWS.
Мы применили AWS SAM для упаковки и деплоя кода нашего приложения, а также для создания ресурсов и настройки их подключения. Теперь мы можем повторно использовать этот шаблон для подобных приложений или расширять/изменять его по мере необходимости.
Через пару дней пройдет открытое занятие «Обзор облачных инструментов СУБД и кешей». На этом открытом уроке рассмотрим разные виды СУБД. Обсудим СУБД масштабируемые по потребности (on-demand), создание и настройку облачной СУБД, а также работу с данными в созданном СУБД. Записаться можно на странице онлайн-курса "Cloud Solution Architecture".
brmn
Хорошая статья для новичков. Но, для запросов
getя бы предпочёл нативную интеграцию API Gateway -> DynamoDB. Плюсы такой интеграции - минимальный latency, нет glue code (читай не платим за лямбду), ну и, в конце концов, это красиво ;) Но, это мое, чисто субъективное, мнение.