
Всем привет. Меня зовут Таня, я работаю системным аналитиком в МТС. В этой статье я расскажу о том, как писать документацию для разработки микросервисов.
Моя команда развивает несколько виджетов на главном экране мобильного финтех-приложения. Когда мы «пилим» новую фичу, как правило, мы разрабатываем под нее новый микросервис. Я, как системный аналитик команды, проектирую наш будущий сервис и пишу документацию для разработки. Так как почти каждая новая фича требует создания своего микросервиса, мне часто нужно писать под это дело документацию. Поэтому хочу поделиться с хабровчанами тем, как это делается у нас в команде.

Единый подход
Начну свое повествование с напоминания о том, как важно стремиться к единообразию. Когда компания становится большой, то появляется много команд и, соответственно, аналитиков. Приходит осознание того, что документация без единого шаблона становится слишком разной, она пестрая, не структурированная. Появляется потребность в разных формах стандартизации документации. Про важность единого подхода и о том, как плохо без него, я уже писала в статье «Как мы создали шаблон функциональных требований в разработке ПО» в соавторстве с моей коллегой Лизой Марковой.
Если кратко – не стандартизированная документация приводит к тому, что легко что-то упустить, а разработчикам приходится каждый раз привыкать к новому виду документации. Кроме того, не ясно, по каким критериям ревьюить эту самую документацию. Именно поэтому и у нас в стриме принят шаблон, о котором я и буду рассказывать.
Из чего состоит шаблон
Наш шаблон требований к микросервису состоит из следующих частей:
общее описание микросервиса;
-
методы;
алгоритм;
входящие данные;
исходящие данные;
исключения;
база данных;
справочники;
нефункциональные требования;
маппинги.
Это части необходимы для того, чтобы требования были полными.
Сразу скажу, что здесь вы не увидите данных о мониторинге сервиса. Это не потому, что его нет. Просто этот раздел мы не включаем пока в наш шаблон. Для постановки сервиса на мониторинг у нас разработан небольшой процесс, который требует также результатов нагрузочного тестирования и согласований с отделом, отвечающим за качество разрабатываемого ПО.
Итак, перейдем к детальному описанию каждого из разделов.
Описание микросервиса
Для того, чтобы каждому, кто придет смотреть документацию на наш сервис, было понятно, что это за сервис (для чего он нужен, кому принадлежит и в рамках какой задачи разрабатывался), у нас есть головная страница с описанием. Выглядит она так:

На данной странице располагается название сервиса. Важно дать понятное название, которое будет описывать главную функцию сервиса. У нас в команде название сервису мы придумываем все вместе – накидываем варианты и выбираем лучший.
Далее идет таблица с интересным макросом. Называется он JIRA и выглядит так:

Добавив этот макрос, вы сможете вставить на страницу в Confluence список задач из Jira. Даже можно вписать JQL запрос и отобразить отфильтрованные задачи.
Подробнее о JIRA Query Language (JQL) можно почитать, пройдя по ссылке. Это очень удобный инструмент для всех, кто работает с Jira.
Далее идет стандартное отображение включенных страниц. В последней части этой страницы располагается таблица, куда можно добавить владельцев сервиса, его краткое описание и ссылки на Jira.
Головная страница собирает все включенные в нее страницы, что помогает в навигации по спецификации. Эта страница может претерпевать изменения, подстраиваться под сервис и команду.
API для сервиса
Далее по важности в первой вложенности следует описание API. Я покажу вам нашу реализацию на примере описания REST API. Методы в свою очередь тоже описываются по шаблону. В шаблон REST API входят:
общее описание;
алгоритм;
входящие данные;
исходящие данные;
исключения.
Важно то, что каждый раздел в описании метода описан на отдельной странице. Так удобно редактировать какую-то одну часть метода и иметь историю изменений именно по этой части, например, по алгоритму.
Итак, начнем с первой описательной части метода.

Здесь мы даем название методу. Как и в случае с сервисом, название методу нужно сделать интуитивно понятным для людей, которые будут сталкиваться с вашей документацией. Далее в таблице приводим тестовый UPI и ссылку на JIRA. У нас каждый метод разрабатывается в рамках отдельной таски.
Далее необходимо написать о назначении метода и, если это имеет значение, какую-то дополнительную информацию о методе. В конце мы кратко описываем результат этого метода.
Далее идет страница с описанием алгоритма метода. Алгоритм – это та логика, которую проворачивает сервис для получения результата по конкретному методу. Так сказать, его сердце.

Если в алгоритме есть несколько фильтрацией или валидаций, то можно указать их в таблице для наглядности. Шаги описанные в алгоритме – это не обязательно то, как будет реализована последовательность проверок в коде. Главное – описать все, что нужно сервису для получения результата. Далее разработчик сам реализует так, чтобы сервис отрабатывал оптимальным образом.
Для визуализации мы добавляем диаграмму последовательности UML. Конечно, я напомню и о том, что есть прекрасный инструмент PlantUML, который позволяет делать такие диаграммы с помощью написания кода.
Вернемся к описанию методов. Далее мы описываем входящие и исходящие параметры, добавляя пример JSON-сообщения с помощью двух макросов Раскрыть и Блок кода.

Для того, чтобы описать все параметры и их структуру в запросе и ответе мы также использует таблицу со следующими столбцами:
параметр;
тип параметра;
формат данных;
кратность (обязательность);
описание.


Для выделения Типа параметра и Формата данных можно использовать Статус. Добавлю скрин из Confluence, где показано как его найти.
Как вы видите на скрине алгоритма, некоторые исключения описаны именно в нем. Но метод также может содержать бизнесовые ошибки. Их возможно описать в исходящих данных следующим образом:

На этом описание метода подошло к концу. Перейдем к следующем разделу нашей спецификации.
База данных
Куда же без описания структуры хранения данных в нашем микросервисе? Для того, чтобы узнать, что хранится в нашей БД, не обязательно получать к ней доступ. Достаточно зайти в нашу документацию.
Из нее можно узнать, какие таблицы есть в БД, какие сущности хранятся в этих таблицах, как они связаны, какие форматы данных у полей и так далее. Каждая таблица описана на отдельной странице. Как ни странно, но для описания таблицы мы используем другую таблицу со следующими полями:
name;
type;
nullable;
description.

Также мы добавляем ER-диаграмму для того, чтобы визуально показать связи между таблицами. Для создания этой и многих других диаграмм можно использовать встроенный макрос Drow.io Diagram.

В целом, описать структуру БД достаточно просто. Но иногда знаний одного аналитика недостаточно. В таком случае на помощь может прийти архитектор или разработчик.
Если в БД находится какая-то справочная информация (так называемые справочники), то мы выносим их описание в отдельный раздел.
Справочники
В этот раздел помещается все, что можно оценить как справочник, например, перечисление платформ, мест показа фичи, каких-нибудь триггеров, условий и так далее. Цель описания справочника в том, чтобы можно было увидеть хранящиеся варианты в БД, не заходя в БД. Чтобы было понятнее, приведу пример:
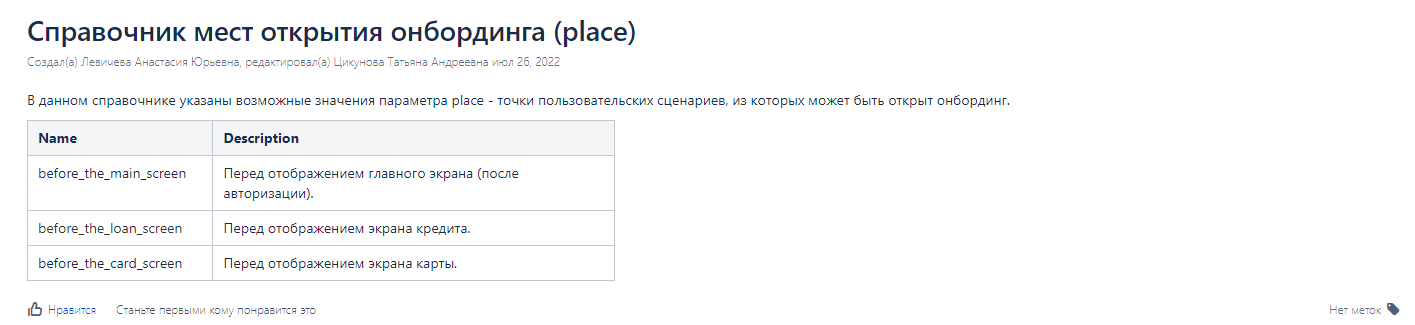
У нас есть фича Онбординг в мобильном приложении. Онбординг может открываться в нескольких местах. Мы фиксируем эти места и обновляем данные по мере расширения функционала по приложению.
Итак, мы уже описали несколько разделов, но это еще не все. Любой аналитик спросит – а как же НФТ (нефункциональные требования)? Вот про них я сейчас расскажу подробнее.
Нефункциональные требования
Начнем с пояснения. НФТ – это требования, определяющие свойства, которые система должна демонстрировать, или ограничения, которые она должна соблюдать, не относящиеся к поведению системы. Например, производительность, удобство сопровождения, расширяемость, надежность, факторы эксплуатации.
В требованиях важно зафиксировать главные параметры, например, скорость ответа на вызов.
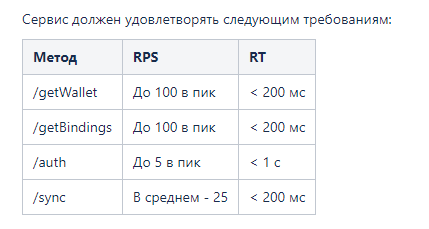
В данном разделе может содержаться таблица со следующими характеристиками:
производительность;
безопасность;
масштабируемость;
надежность;
совместимость;
доступность;
особенности хранения данных;
поддерживаемость;
тестируемость;
ремонтопригодность;
концептуальная целостность;
удобство использования.
Маппинг
Это следующий опциональный раздел в описании микросервиса. Маппинг данных – процесс сопоставления полей данных (определенных элементов источника или всего источника) и связанных с ними полей данных в другом месте назначения. Так что если в вашем сервисе присутствует маппинг – его необходимо описать. Самое простой способ – создать таблицу с 3 столбцами. В первый столбец поместите названия параметров первой системы, во второй столбец – названия соответствующих параметров из второй системы, ну а в третий – описание этих параметров.

Заключение
Безусловно, это не исчерпывающий список того, что можно включить в спецификацию для микросервиса. Пока мы остановились на таком наборе, но если функционал сервиса требует описать дополнительно какой-нибудь раздел, – его легко можно включить в шаблон. Мы стараемся не останавливаться на том, что у нас есть сейчас. Каждый аналитик или другой специалист может привносить что-то новое в наш шаблон. Главное, чтобы эти новшества делали шаблон удобнее.
Кстати, в разделе Инструменты для пространства можно создать шаблоны для каждого из приведенных мной примеров и поместить в доступные варианты, которые будут видны при создании новой страницы.
На этом я заканчиваю свой рассказ, спасибо вам за внимание! Буду очень рада пообщаться в комментариях о том, что вам откликнулось, а что вы бы сделали иначе.
Комментарии (21)

LabEG
00.00.0000 00:00+1А не логичнее будет заносить эту информацию в код и уже из кода генерировать документацию для конфлюенса, свагера и др? Это же гораздо проще чем синхронизировать код с конфлюенсом.

Tatiana_TSikunova Автор
00.00.0000 00:00По нашим процессам - это ТЗ для разработчика, он смотрит на доку и пишет код. А вы предлагаете заносить эту инфу в код.. Кто, как вы думаете, это должен делать? Поделитесь, плиз, видением..
LabEG
00.00.0000 00:00+1Насчет должности не знаю, но так то это и системный аналитик может делать. Освоить базу языка это просто. Этот человек должен описать в коде контракт и документацию к нему, но не реализовывать логику. Далее из этого контракта сгенерируется документация в необходимые места, а разработчик напишет логику. Тем самым вы сильно сократите объем работы и жизнь разработчику. И это еще не трогая таких моментов что СА не ванга, и не может со 100% точностью описать контракт заранее, что бы его не пришлось править разработчику.
Tatiana_TSikunova Автор
00.00.0000 00:00Спасибо за пояснение. Да, это было бы удобно в случае, если аналитик может базово кодить или разработчик сам проектирует API. Время до выпуска апи на тест сократилось бы.

AntonMF
00.00.0000 00:00+1Любопытный подход. Если с генерацией сваггера из кода в целом понятно (есть много библиотек, например, для спринга: springdoc-openapi и тд), то вот вот остальная документация (описания алгоритма, какие-нибудь общие требования и контекст, напрямую не связанные с механикой общения между сервисами) не понимаю, как можно генерить по коду. Есть какие-то библиотеки интересные на эту тему, как со сваггером у спринга?

AYamangulov
00.00.0000 00:00+2Нарушен прицип "specs firs". С OpenAPI (бывший swagger) так работать непродуктивно. Лучше наоборот - написать спеку в формате OpenAPI (ее как раз уже хорошие системные аналитики вполне могут сделать), а разработчик уже нагенерирует из нее и модели, и заготовки для серверов и много что еще может, в том числе и отдельную документацию. И при этом код уже будет аннотирован и размечен как нужно информацией из вашей спеки. Вот онлайн редактор https://editor.swagger.io/, в нем уже по дефолту некоторый пример залит, как нужно размечать. Можно работать прямо онлайн. Справочные материалы в меню About )
Tatiana_TSikunova Автор
00.00.0000 00:00Очень интересно. Спасибо большое за рекомендации. У нас в стриме как-то не прижился, к сожалению, OpenAPI. Но, возможно, стоит пересмотреть отношение к этому формату

LaRN
00.00.0000 00:00А если в процессе разработки многое меняется, то нужно постоянно актуализировать описание? Т.е. работаю в паре разработчик и аналитик всякий раз?
Tatiana_TSikunova Автор
00.00.0000 00:00У нас именно так. Как правило, когда аналитик передает такую доку в разработку, то она считается очень хорошо проработанной, поэтому меняется очень мало. Но если меняется, то да, разработчик просит аналитика актуализировать.

zilent771
00.00.0000 00:00+1Хорошая статья, очень пригодится для начинающих аналитиков и тем, кто только вливается в проект с нуля и надо как то стандартизировать документацию
Tatiana_TSikunova Автор
00.00.0000 00:00спасибо за ваш комментарий. Да, действительно начинающим аналитикам очень важны шаблоны, по ним легче всего начать описывать функциональности

kredis31
00.00.0000 00:00+1С перечисленными пунктами в ТЗ интересно, полезно. Но с их реализацией есть вопросы. Как уже сказали описать контракты и схемы БД в ручную требуется время, при этом в момент разработки они чаще всего меняются. Поэтому эти пункты должны лежать ближе к коду, это позволит разработчику поправить их, при реализации. Мы генерируем схему БД и OpenAPI из кода.
Интересно по пункту со поведенческой схемой, у вас достаточно это программистам? А схема компонентов? А сценарии(UseCase) в виде блок-схем?
Tatiana_TSikunova Автор
00.00.0000 00:00Спасибо за ваш комментарий. Что вы имеете ввиду под сценариями в виде блок-схем? Если вы про usecases, то они у нас прописаны в документации на фронт. Писала про это в статье: https://habr.com/ru/company/ru_mts/blog/686570/
А для микросервисов достаточно того, что описано в статье. По крайней мере доп.запросов не было еще.

Kanamaha
00.00.0000 00:00Заголовок "Как создать шаблон", а содержание - чем заполнить шаблон. Или тема не раскрыта, или заголовок не подходит к тексту.
Tatiana_TSikunova Автор
00.00.0000 00:00Добрый день. Спасибо за комментарий. Возможно, но если так, то второе. Задумка была, именно, написать о том, из чего состоит наш шаблон.

seregagl
00.00.0000 00:00+1Покритикую немного
Описание API в текстовом виде в конфлюенсе - зло. Такое описание может вполне сойти за ТЗ разработчику, который погружен в проект и у которого аналитик всегда под рукой, но для внешних пользователей бесполезно. Для внешних пользователей это должна быть спецификация openapi и примеры рабочих (с корректной авторизацией и корректными dto) запросов, которые можно выполнить самостоятельно.
Описание БД в текстовом виде в конфлюенсе тоже считаю избыточным. Разрабу оно не нужно и оно устареет после первого спринта. Если на помощь все равно нужны или архитектор или разработчик, то легче выгрузить модель из реальной БД.
Но в целом статья понравилась своим целостным подходом.
akurilov
Сам следую давно похожему подходу.
Но есть одно но. Такая мелкогранулированная и сильно привязанная к конкретному модулю документация должна храниться вместе с исходным кодом в виде, например, файла README.md
В конфлюенсах лучше держать что-то более общее
Tatiana_TSikunova Автор
Cпасибо за комментарий. Мы тоже об этом думаем, но пока не пришли к подходу хранения доки рядом с кодом.
Что-то более общее, это вы про что? Сможете привести пример? и что из этих разделов кажется слишком мелких для condluence?
proanalitika
Мы храним документацию в коде при помощи asciidoc +pluntUML. Достаточно удобная структура, но есть нюансы в том, что когда документ попадает в код, то все что было в конфе становится неактуальным и приходится архивировать.
Tatiana_TSikunova Автор
Спасибо за информацию!
Kazikus
Советую обратить внимание на https://backstage.io/. Можете получить удобство confluence/notion. При этом хранить документацию и рядом с кодом, и отдельно