
Доброго дня всем заинтересованным в теме. Пару дней назад столкнулся я с одной настолько неочевидной и вместе с тем опасной особенностью выполнения SQL в Teradata, что не мог не поделиться. Хотя допускаю, что post mortem поведение ее (Терадаты) выглядит по-своему логичным, но все же для тех, кто не специализируется конкретно на Teradata и при этом много работает с данными в разных типах хранилищ, подобное поведение является первоклассной расческой ловушкой, и мне пока не удалось найти другую БД, в которой она есть.
Постараюсь кратко.
Представим, что у нас есть огромная таблица с критичными данными:
select * from pcast.huge_tableID |
VALUE |
0 |
zero |
1 |
one |
2 |
two |
3 |
three |
4 |
four |
5 |
five |
6 |
six |
7 |
seven |
8 |
eight |
9 |
nine |
777 |
too much |
Также есть небольшая таблица со списком ключей, которые требуется удалить из большой критичной таблицы:
select * from pcast.small_tableID |
VALUE |
777 |
Boss asked to remove this key from huge table |
Удалим данные из большой таблицы по списку ключей, содержащихся в в малой:
delete
from pcast.huge_table ht
where ht.id in
(select ht.id
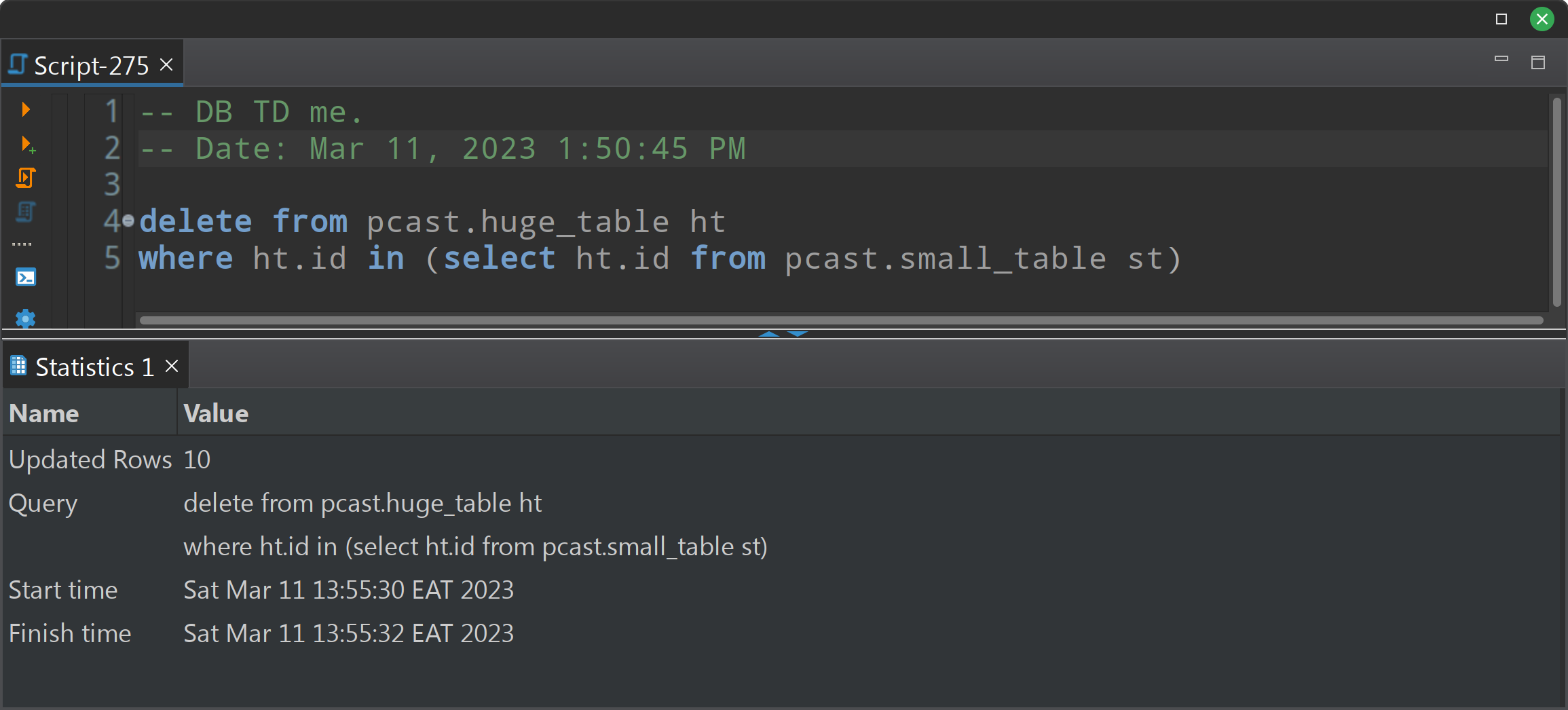
from pcast.small_table st)Кто читает эту строку и уже видит ошибку, тому большой респект.
Кто не увидел и выполнил, тому привет ) Вы удалили ВСЕ данные из таблицы. Бегите за бэкапом, если сделали коммит. Казалось бы, подзапрос не имеет смысла, но не для Терадаты. В любой другой системе подобный скрипт упал бы с ошибкой вроде "не найдено поле ht.id в подзапросе" :
MySQL:

Databricks:

Но Терадата поступает по-своему. Ниже explain delete для такого запроса. Выделена самая интересная строка:

Как видим, ht.id - в рамках всего запроса для Терадаты есть поле известное, потому оно найдено, и это то же самое поле, с которым идет сравнение. Таким образом, условие where раносильно 1=1, delete срабатывает весьма успешно, и горе тому, кто не оценил Updated rows:
Я хотел привести правдивое описание реальных последствий подобных действий над парой таблиц в сотни миллионов строк, но оказалось, что оно превращается в отдельную статью о том, что бывает, если не думать о правильности алгоритмов генерации суррогатных ключей при проектировании хранилищ данных и затем потерять данные, например, при помощи описаного в статье способа. Это тема для отдельной статьи, возможно когда-то, когда меня перестанет трясти, я напишу и об этом.
Будьте внимательны и осторожны!