
В прошлых статьях мы много рассказывали о том, как Data Science помогает металлургу, что такое Self-Service Analytics и как простой технолог может командовать моделями машинного обучения. В этом посте хочется раскрыть больше технических деталей по последнему пункту.
Хардкорный дата-сайентист может собрать нейросеть даже из спичечных коробков. Однако CDS — это про решение производственных задач малой кровью и в разумные сроки. И для таких решений необходим соответствующий инструментарий.
Привет, на связи снова Андрей Косинцев из ЕВРАЗа, и под катом вы узнаете, как самообучаются ML-модели и самоверстается фронтенд.
Я был там, Гэндальф
Возможно, вы ещё помните то время, когда в России не было проблем с использованием зарубежных сервисов. В те счастливые годы для нужд машинного обучения мы использовали Azure AutoML. Нам нравилось, что там есть автоматический подбор типа модели: на одном и том же датасете параллельно обучались несколько разных архитектур, затем выбиралась та, что лучше всего показывает метрики на тестовой выборке. Для CDS’а, прошедшего интенсивные, но короткие курсы Data Science, это было прекрасное подспорье. Вместо того, чтобы гадать, какой тип модели лучше подойдёт, CDS получал ответ на блюдечке. Обученные модели затем экспортировались из Azure, чтобы их можно было встроить в Knime workflows с помощью библиотеки EVRAZ ML.
Однако всё хорошее когда-нибудь заканчивается, и в силу известных причин Microsoft сделал нам ручкой. Однако там, где другие видят проблему, пытливый ум ищет возможность. Мы решили заняться импортозамещением «здорового человека» — создать собственную систему AutoML, заточенную именно под наши нужды. Спойлер: мы в этом преуспели, и теперь ни в какой AzureML нас даже силком не затащишь.
По щучьему веленью
Как всё это выглядит со стороны пользователя? Очень и очень просто.
Сперва CDS должен подготовить датасет. Этот этап полностью автоматизировать невозможно, но, как мы уже рассказывали в предыдущих статьях, Knime значительно облегчает задачу.
А вот дальше начинается магия. Открывается вот такая минималистичная веб-страница:

CDS заполняет необходимые поля, загружает датасет (csv, xls, xlsx), указывает, какой параметр модель должна будет прогнозировать. Выбирает тип задачи: регрессия или классификация. Опционально можно загрузить также Knime workflows, с помощью которого формировался датасет. Workflows никак не используется в процессе обучения AutoML, он хранится в качестве артефакта запуска — чтобы потом можно было воспроизвести эксперимент, сформировав датасет из сырых данных заново. Повторяемость экспериментов — наше всё.
Заполнив поля, CDS жмёт кнопку «Сделать хорошо» «Запуск» — и начинается самое интересное.

Театр начинается с вешалки
Данные, отправленные CDS’ом, сперва на бэкенде проверяются на валидность. Например, в таблице должна быть минимум сотня строк, иначе слишком мало для обучающей выборки, для задачи регрессии целевой столбец должен быть числовым, проверяется наличие категориальных столбцов (для последующего one-hot encoding) и не слишком ли много уникальных категорий в столбце (не стремится ли их число к бесконечности) и т. д. Если всё валидно, на основании данных планируется эксперимент, а если нет, пользователь получит сообщение, что не так с данными.
Через веб-интерфейс можно посмотреть список всех экспериментов: запланированных, проводящихся в настоящий момент и завершённых. А также — их результаты.

В общих чертах, суть та же, что и в любом AutoML — несколько различных моделей обучаются на одной и той же выборке данных. Радость, однако, кроется в деталях. Поначалу вместо создания своего собственного AutoML, мы пробовали использовать встроенные ML-модели в Knime, а также узлы Knime AutoML, но модели в нём были «чёрным ящиком»: нельзя было посмотреть внутрь, оценить адекватность (читай — технологичность) модели, понять, на каких признаках она основывает свои предсказания. Модель в EVRAZ AutoML — это «серый ящик». Разумеется, в её основе — машинлёрнинговая магия, которая в общем случае из коробки явно не интерпретируема слабым человечьим мозгом. Тем не менее, можно подглядеть внутрь одним глазком, посмотреть метрики качества, начертить SHAP-графики — и всё-таки понять, от чего отталкивается модель в своем мировоззрении и как она видит влияние факторов на прогнозируемый целевой параметр.
Каково быть летучей мышью
Первое, на что можно посмотреть — на различные метрики моделей. Выбрать лучшую модель — звучит просто, но не всегда понятно, какая из них лучшая. Допустим, у одной выше точность, у другой — F1 score. Какую взять оракулом — зависит от проекта, от того, ошибки какого рода в нём обойдутся дороже.

Допустим, CDS выбрал модель, которая больше всего нравится ему по метрикам. Что с ней делать дальше? Ну, например, можно попытаться понять, насколько она адекватно себя ведёт на всех значениях целевого параметра. Самое простое — посмотреть график сравнения результата с предсказанием. Гадание по форме графика — это, конечно, дисциплина не вполне научная, но если предсказание почти везде хорошо совпадает с фактом, а в одном месте провал — разумно предположить некий неучтённый фактор. Если понять, что это за фактор, включить его в датасет и обучить новую модель — скорее всего, станет сильно лучше.
 и фактических значений (ось Y) на тестовой выборке. Идеальная модель — точки вдоль серой прямой")
Помимо всего прочего, без понимания, что модель думает так, как на самом деле работает производство — никуда. В ЕВРАЗе модели в формате «чёрный ящик выдаёт идеальные метрики» не нужны. Потому в модуль AutoML мы внедрили SHAP-графики, которые показывают влияние того или иного входного признака на целевой параметр. С таким графиком не стыдно и к технологу пойти: обсудить, действительно ли наблюдается такая зависимость на основе его опыта и опыта его коллег.
 на целевой признак (механическая прочность M25). Меньше Sigma_r — больше целевой признак")

Можно посмотреть сводный график по важности влияния всех параметров и понять, какие факторы в большей степени влияют на предсказание. Если влияние каких-то факторов пренебрежимо мало — их можно выкинуть из выборки и упростить модель. Если на предсказание влияют какие-то неожиданные факторы (грубо говоря, содержание углерода в чугуне определяется фазой Юпитера) — это также стоит обсудить с технологами. Возможно, они скажут, что Юпитер никак не может воздействовать на техпроцесс, поскольку железо — сфера влияния Марса. Иначе говоря — что корреляция ложная и сломает результат на новой выборке. Но может случиться и обратное: вы откроете технологам какую-то ранее незамеченную физико-химическую закономерность. В любом случае, поговорить есть о чём.
 между всеми переменными датасета — полезно для поиска базовых зависимостей")

Помимо всего прочего, можно посмотреть на свойства датасета самого по себе. Вывести на экран корреляционную матрицу, посмотреть — вдруг какие-то параметры линейно зависимы. Можно использовать это как повод сократить датасет на один столбец, а можно опять же удивить технологов внезапно обнаруженной закономерностью. Посмотреть распределение величин — тоже можно найти инсайты, увидеть явные выбросы или подтасовки в данных (привет, ручной ввод технологических параметров людьми!).
Помимо картинок, нельзя не упомянуть артефакты получившихся моделей. В рамках каждого эксперимента итоговая модель обучена на всех данных (метрики мы логируем по сплитам и для итоговой модели усредняем).
В интерфейсе доступен уникальный идентификатор эксперимента mlflow id (забегая вперед: он пригодится нам для запуска в хостинг этой модели), перечень входных фичей и их тип, requirements и пример запуска кода (могут пригодится, если хочешь запустить модель локально, но это нестандартный путь запуска модели AutoML, не для CDS).

Left Click, Left Click — и в продакшен
Одна из проблем, с которыми часто сталкиваешься, а хотелось бы пореже — деплой. Для CDS’ов мы эту проблему порешали радикально. Прямо из интерфейса эксперимента можно в пару кликов задеплоить любую понравившуюся модель на сервер (в OpenShift), после чего она сразу доступна по REST API. Любое приложение, которое умеет формировать запросы, может обращаться к запущенной модели, передавать ей набор данных и получать в ответ предсказание.
Такая модель легко интегрируется в Knime workflows: как уже рассказывалось в предыдущих статьях, есть готовые ноды для работы с сетевым API, но мы, дабы упростить жизнь CDS, сделали готовый узел Knime для обращения к запущенным в хостинг EVRAZ AutoML моделям. Ранее для запуска обученных моделей (pickle) в Knime нужно было изрядно помучиться: поставить Python на машину, где будем запускать Knime, установить все зависимости (а от модели к модели они могут отличаться), используя узлы библиотеки ЕВРАЗа подгрузить модель — мероприятие совсем не интересное, а для CDS, который не пользовался никогда Python и virtual env, совсем не тривиальное.

Впрочем, при желании можно скачать к себе модель локально в виде pickle-файла. Тогда, очевидно, модель деплоится вместе с остальным приложением. Такой подход с pickle-файлом можно использовать для быстрого тестирования модели локально, без необходимости запускать/останавливать модели на сервере, благо для этого остались ноды EVRAZ ML Knime для интеграции pickle-моделей.
Использовать ли двухкликовый хостинг или модель в виде файла в периметре Knime — это зависит от многих факторов. Если планируете регулярно скармливать ей свежие данные, то удобнее, когда она деплоится на сервере: тогда приложение пересобирать не придется. Если нет — то, в общем-то, всё равно. Там, где хостится приложение, хороший доступ в интернет/интранет? Если оно на контроллере где-то посреди поля, то доступ к REST API может быть осложнён. Наконец, продуктивизация производится силами CDS или IT-отдела? Конкретному CDS’у может быть просто удобнее работать с API или моделью в виде файла.
О том, что происходит под капотом при запуске хостинга, расскажем ниже.
Самоверстающийся фронтенд
AutoML и деплой модели — это, безусловно, хорошо. Однако конечному пользователю (как правило, технологу на заводе) совершенно не хочется руками формировать запросы к модели через API. Ему хочется, чтоб красиво и удобно, а CDS’у — чтоб легко и быстро. На пересечении их потребностей и возник SSA ML Toolbox, или, как мы его называем, SSAMaLeT (Self-Service Analytics MAchine LEarning Toolbox).
Через админскую панель CDS может программировать мышкой веб-страницы различных типов. Например: вывод графика на основе данных, которые он передал через Knime, или создавать формы ручного ввода значений от пользователя. Веб-страницы общаются только с базой данных SSAMaLeT’a, они не обращаются напрямую ни к Knime, ни к ML-модели (независимо от того, хостится она внутри или снаружи). Фронт лишь отображает данные, уже хранящиеся в БД приложения, либо кладет в БД данные ручного ввода (например, то, что ранее заносилось в бумажный журнал, теперь можно заносить в SSAMaLeT и визуализировать).
Knime запускается с какой-то периодичностью и работает с БД SSAMaLeT’a, а также с внешними ресурсами. Например: берёт из производственной сети данные по какому-то параметру, кладёт их в БД, проводит очистку, генерирует сетку параметров (в случае оптимизации), затем обращается к ML-модели через API, получает предсказания, находит лучшее значение для оптимизации и его тоже кладёт в БД. Затем на основании этих данных веб-страница рисует график «рекомендация vs факт».
")


Благодаря простоте и гибкости этой архитектуры SSAMaLeT позволяет быстро разрабатывать сложные приложения для производственных нужд.
А внутре у ней неонка
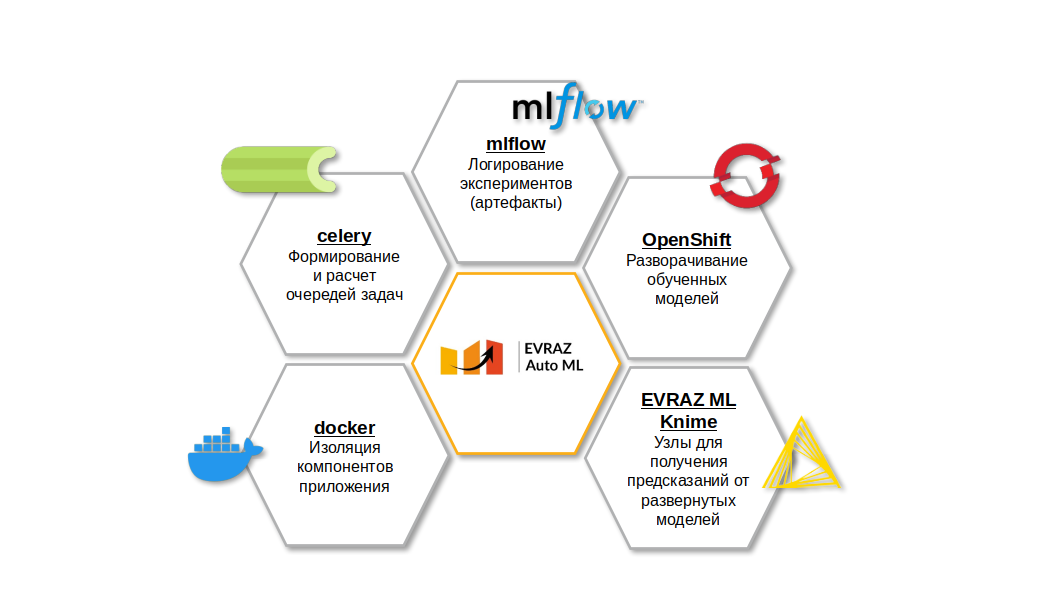
Наверное, вам интересно, что у SSAMaLeT’а и EVRAZ AutoML под капотом. А может, и не очень интересно, но мы всё равно вам расскажем.

Docker — индустриальный стандарт в области контейнеризации. OpenShift — известное энтерпрайзное решение для оркестрации контейнеров. В евразовском облаке OpenShift находится та самая Вальгалла, куда попадают ML-модели, лучше всего проявившие себя в бою. Остальные лепестки нашего цветика-пятицветика интереснее.
EVRAZ ML Knime — это набор кастомных узлов для Knime, позволяющих общаться с развёрнутыми моделями, получать от них предсказания. Конечно, работать с REST API можно и вручную, но CDS — это же про скорость и эффективность разработки. Готовые узлы, упрощающие эту типовую задачу, весьма способствуют.
MLflow — опенсорсная платформа, которая умеет практически всё, связанное с ML. Запуск экспериментов по обучению моделей, логирование метрик, логирование и сохранение разного рода артефактов в подключенном S3-хранилище — за всем этим обращайтесь к MLflow. Для упрощения взаимодействия с mlflow в ЕВРАЗе мы создали собственную библиотеку evraz-datascience. Она позволяет в два клика подключаться к нашему mlflow, а также исключить все стандартные действия с числовыми моделями: построить корреляции, гистограмы распределения для датасета в одну строчку, обучить ML-модель с кросс-валидацией в пару строк, увидеть все базовые метрики на тестовой и тренировочной выборках и добавить все эти сгенерированные полезности в S3-хранилище.
Celery — отличная штука, если нужно что-то распараллелить или поставить в очередь. Эта библиотека позволяет раскидать задачи на сервере по worker’ам, ядрам процессора, планировать их выполнение так, чтобы одновременно выполнялось не более N, а также упрощает логирование и отслеживание статуса каждого эксперимента, позволяя DS'у / CDS’у увидеть статус работы процесса в удобном виде (привет, celery flower).
При отладке нового функционала или при непредвиденных ошибках в запуске экспериментов обучения моделей очень выручает celery flower, который я уже упоминал. Этот инструмент подключается к celery и позволяет просмотреть список всех worker’ов, которые готовы обсчитывать запускаемые задачи и их состояние. Также можно посмотреть все задачи, которые запускались, их статус (в очереди / выполнена / выполняется / завершена с ошибкой), входные данные для задачи, а также узнать, что вернула та или иная задача, а в случае ошибки из того же интерфейса доступен весь стек-трейс ошибки, таким образом это помогает нам понять, что пошло не так в новом кейсе, для которого наших входных проверок данных оказалось недостаточно. Лучше, конечно же, без багов, но все мы знаем, что так не бывает :-)




Хостинг моделей реализован отдельным от обучения моделей компонентом. Используя UI EVRAZ AutoML, юзер авторизуется в системе через keycloak и, если есть доступ к хостингу моделей, переходит к деплою модели в OpenShift. Для деплоя нужны только mlflow id (берется из UI mlflow для уже обученной модели) и желаемое имя модели.
Для запускаемой модели создается deployment и запускается pod в namespace кластера EVRAZ AutoML, создается service и формируется url для модели с помощью ingress. По факту разворачивания делается запись в БД о том, что такая-то модель с такими-то параметрами должна быть запущена. На случай, если мы обновим версию приложения или кто-то удалит под/деплоймент/сервис, отдельный сервис MLModel checker, который следит за всеми запущенными моделями и теми, которые должны быть запущены, задеплоит модель самостоятельно.
Deployment для модели основан на базовом docker image, который реализует несколько несложных API. Пользователь, который задеплоил модель, может обращаться в соответствующий url в корпоративной сети, который содержит имя модели и id её эксперимента: для этого надо знать имя модели и mlflow id (все запущенные модели видны в UI). Для получения прогноза достаточно передать в теле запроса данные, разбитые по строкам с уникальными идентификаторами строк, а на выходе будет предсказание для каждой строки.
В первую очередь, AutoML — это инструмент для CDS, а CDS пользуются для создания пайплайнов обработки данных Knime. Поэтому для CDS мы создали узел Knime, который позволяет без особого труда и ничего не зная о GET- и POST-запросах, зная лишь имя задеплоенной модели и её mlflow id, передавать табличные данные модели и получать предсказания. Аналогично Knime можно использовать любые другие инструменты, которые могут реализовывать обращения: именно такой подход позволяет изолировать все зависимости и модели и применять их в различных средах.
Пару слов про стек SSAMaLeTа. Каждый SSAMaLeT — это отдельное приложение с набором готовых компонентов. В нём есть:
Приложение Knime
База данных
Бэкенд (api)
Фронтенд
Сервис авторизации keycloak
Сервис отслеживания активности пользователей matomo


Почему это круто?
Наверное, у каждого айтишника (и особенно — у каждого «войтишника») был период ошеломления от обилия новых технологий, методологий, инструментов. Входить в айти со стороны CDS не проще, чем с какой-либо другой. За короткое время нужно усвоить множество нетривиальных вещей — а затем сразу научиться применять их на пользу народного хозяйства.

Связка Knime + EVRAZ AutoML + SSAMaLeT крутая, потому что это единое интегрированное решение, а не набор отдельных компонентов. CDS’у не приходится думать о том, как заставить целый зоопарк технологий работать сообща — он думает над задачей, а не над технологиями. Начиная с этапа сбора данных и заканчивая продуктовизацией решения, CDS знает, что и каким инструментом должен делать. Это способствует не только продуктивности, но и психологическому комфорту: отработанный воркфлоу становится островом стабильности в бушующем айтишном море.
И что дальше?
Крутой инструмент — не значит идеальный инструмент. Сейчас у нас большие планы на EVRAZ AutoML, на самое его сердце — алгоритмы автоматического обучения.
Сейчас лучшая модель ищется простым перебором из десятка возможных вариантов. Мы хотим добавить, во-первых, возможность подбора гиперпараметров модели. Во-вторых, мы хотим, чтобы алгоритм AutoML мог поиграть с входным датасетом: либо урезать его (выкинуть какие-то параметры и посмотреть, не были ли они лишними, бесполезными для предсказания), либо наоборот — обогатить синтетическими признаками.
Под обогащением я подразумеваю добавление новых производных параметров: скажем, квадратов имеющихся величин или их произведений с другими величинами и т. д., благо для этого уже придумали готовые библиотеки. В случае, если встретится сложная задача с неявными зависимостями, то производные синтетические параметры помогут её решить с лучшим качеством, но это всегда переход от отлично интерпретируемых моделей к менее явным, потому такие кейсы очень редко применяются у нас в компании.
Мне всегда приятно говорить о своих любимых проектах, надеюсь, вам было не менее приятно о них читать. А если у вас возникли вопросы о каких-то компонентах нашей системы — не стесняйтесь задавать их в комментариях.
CrazyElf
Сейчас каждая крупная компания делает свой AutoML. Могу только пожелать успеха. Там поле работы очень обширное даже для простых казалось бы табличных данных. )