
Я очень люблю визуализации. Человек лучше всего воспринимает информацию через образы. Для трех часто встречающихся баз (MSSQL, Postgres и MySQL) я смастерил плагины к проекту Bell, хотя этот код на Python можно использовать и отдельно. Поэтому для каждой визуализации я буду в скобочках писать имя файла из репозитория GitHub - вы можете этот файл вытащить и использовать его отдельно от проекта (для этого нудны минимальные модификации).
Отмечу только, что я считаю себя экспертом только в MSSQL, а то что сделал с другими базами - сделал по наитию. Кроме того, в отличие от MSSQL у меня нет реальных баз под большой нагрузкой для Postgres и MySQL. Поэтому ошибки/пожелания для скриптов Postgres и MySQL очень и очень welcome!
В основном я задействовал TreeMap
Размеры таблиц, индексов и баз
MSSQL
Мы моем построить TreeMap для всех таблиц сервера во всех базах (MSSQLsrvtreemap.py), так и в отдельной базе (MSSQLdbtreemap.py). В первом случае у нас возникают уровни: база - схема - таблица - индекс, а во втором схема - таблица - индекc, то есть на один уровень меньше. По хорошему можно добавить еще один уровень - разделы, это нужно кому-нибудь?
На реальном сервере в PROD это выглядит так:

Разумеется, имена таблиц я заменил. Цвета означают:
Зеленый - clustered indexes
Синий - nonclustered indexes
Красный привлекает внимание к HEAP tables.
Желтый - COLUMNSTORE indexes
Magenta - все остальные типы индексов - xml, spatial etc.
Также можно построить TreeMap для отображения дисков и расположения файлов на них (MSSQLdrvtreemap.py):
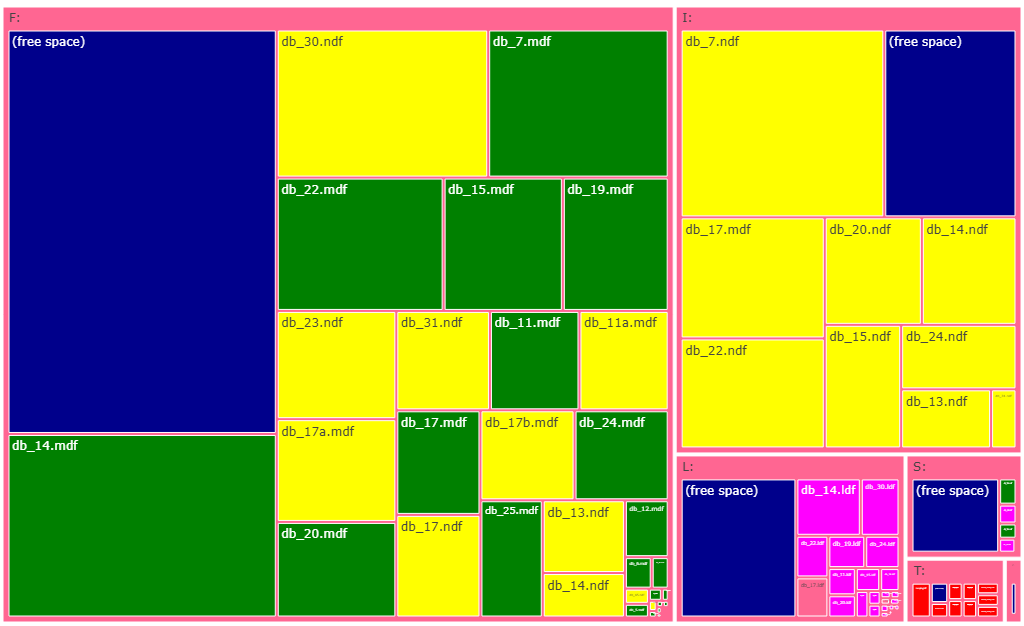
Опять таки, данные с боевого сервера и мне пришлось заменить названия баз (кроме системных) на номера. В правом нижнем углу вы видите диск T: и файлы tempdb, отмеченные красным. Кстати, это не tempdb маленькая, это остальные базы огромные.
Первый файл (mdf) показывается зеленым, остальные файлы данных (часто там индексы) - желтым, файлы лога - цвет magenta (убеждаемся, что они собраны на диске L:) и, наконец, свободное место показано синим. Скрипт не видит размера обычных файлов (не баз), так как я не могу рассчитывать на то, что процедура xp_cmdshell разрешена, это может немного искажать статистику (особенно на C:).
Postgres
Для Postgres данные также доступны как для всего сервера (уровни база - схема - таблица - индекс - PGsrvtreemap.py), так и для конкретной базы (уровни схема - таблица - индекс - PGdbtreemap.py).

Собственно таблица показывается зеленым, а индексы - желтым (есть что нибудь еще и возможно нужны еще цвета?)
MySQL
Для него также доступны данные как по всему серверу (MySQLsrvtreemap.py), так и по каждой базе отдельно (MySQLdbtreemap.py). Однако я рассматривал только файлы InnoDb. Возможно то же самое можно делать и для других типов файлов (а часто надо?) и показывать их другими цветами.

Сама таблица показывается как "PRIMARY", зеленым, а индексы - желтым.
Интенсивность ввода - вывода
MSSQL
Используя статистику, накопленную функцией sys.fn_virtualfilestats, мы можем построить TreeMap диаграммы для интенсивности ввода и вывода:

Здесь два уровня - диск и файл, но на домашнем компьютере у меня есть только диск C: Цвета условны. Диаграмма для Writes строится аналогично. Файл MSSQLiotreemap.py
Postgre
В отличие от MSSQL, Postgres позволяет показать hits потаблично, при этом для каждой таблицы доступен отдельно cache hits:

Доступно для сервера и для отдельной базы. Непрерывное цветовое пространство показывает cache hits ratio. Размер фигур соответствует количеству обращений, включая кешированные. Файл PGtableio.py
MySQL
Для InnoDB файлов я нашел ввод и вывод для каждого файла, что дает две диаграммы - одну для ввода, другую для вывода, но выглядят они похоже (MySQLiotreemap.py):

Job history.
Этот плагин существует только для MSSQL. Я дам картинку, а потом объясню, что происходит (MSSQLjobsview.py):

Опять таки, вместо имен jobs мне пришлось вывести их GUIDs. Что мы видим?
По горизонтали (ось X) у нас отложены сутки (смотрите внизу - от 0h до 24h). Для top 20 jobs, которые занимают больше всего времени в сутки, рисуем время их последнего выполнения. Если в джобе несколько шагов, то рисуем их разным цветом в палитре зеленый-голубой. А вот красная черточка вверху показывает, что выполнение шага закончилось ошибкой.
Скорее всего, та же джоба работала и вчера и позавчера и каждый день. Предыдущие запуски ее рисуются с небольшим смещением вверх, но все бледнее и бледнее. Таким образом, вы можете увидеть тенденции - работала ли джоба раньше быстрее, медленнее, поменялось ли расписание итд.
Комментарии (7)

gleb_l
16.04.2023 16:38+2Очень наглядно. Еще бы добавить степень фрагментации индексов (кластерных и некластерных) в виде полосатости тех квадратов, которые они отображают

Tzimie Автор
16.04.2023 16:38+2Хорошая идея. Я как раз дефрагментацией больших таблиц занимаюсь.
Единственная проблема, анализ фрагментации идёт долго, на одном из моих серверов 12 часов, так что запустить и увидеть не получится, эти данные надо собрать заранее

Slipeer
16.04.2023 16:38Для Postgres наверное было бы полезно видеть соотношение "мёртвых" и "живых" по таблицам. Можно цветом это соотношение как-то отразить.
Tzimie Автор
16.04.2023 16:38А какие квери это делают?
Slipeer
16.04.2023 16:38+1Например
pg_stat_all_tables
https://www.postgresql.org/docs/current/monitoring-stats.html#MONITORING-PG-STAT-ALL-TABLES-VIEW
sshikov
Разумеется нужно (если на то есть время и желание). Я бы даже больше сказал — у некоторых баз отдельно хранятся LOB-ы, и их размеры тоже стоит учесть.
grgdvo
я бы еще добавил заполняемость партиций (насколько эффективно использовали "формулу" распределения) и еще можно прицепить статистику по партициям, к какой сколько больше обращались (какие горячие на момент построения)