

Добрый день! Меня зовут Евгений Овчинцев, я работаю в компании Neoflex и в настоящее время являюсь архитектором продукта Dognauts. В данной серии статей я планирую рассказать о том, как создавался и развивался продукт: почему принимались те или иные решения, с какими проблемами пришлось столкнуться и что из всего этого получилось.
Наша компания уже много лет занимается разработкой, а также внедрением решений в области Big Data, и в какой-то момент в рамках этих проектов стала возникать потребность по организации инфраструктуры для работы Data Science команд. Сначала такие решения были простыми: например, установка JupyterHub на виртуальную машину или развёртывание экземпляров ApacheZeppelin в контейнерах Docker в нужном количестве (отдельный для каждого члена команды, чтобы не пересекаться в процессе работы), подключение их к кластеру Hadoop и обеспечение автоматического перезапуска для высвобождения аллоцированных под задачи ресурсов. Уже тогда перед командой внедрения стояли базовые вопросы и задачи MLOps: как организовать отдельное пространство файлов и вычислительных ресурсов для каждого из участников процесса и что делать с простаивающими серверами Jupyter, аллоцировавшими на себя много вычислительных ресурсов.
В процессе работы над новыми проектами всё чаще в качестве инфраструктурного слоя для управления приложениями проектов стал выступать Kubernetes. Он зарекомендовал себя как удобное средство оркестрации контейнеров. Постепенно на рынке и в открытом доступе стало появляться всё больше инструментов, работающих поверх Kubernetes, а также связанных с обеспечением работы дата-сайентистов и жизненным циклом моделей ML. Мы проводили много RnD в этом направлении и на этом фоне экспертиза сотрудников компании в области MLOps росла. Стали появляться первые проекты по внедрению именно этой практики и построению инфраструктурных решений для работы команд дата-инженеров и дата-сайентистов с целью совместной разработки моделей машинного обучения и вывода их в эксплуатацию.
В рамках первого проекта построения MLOps-платформы для команд дата-сайентистов из разных отделов была организована платформа разработки и эксплуатации моделей машинного обучения. Архитектуру системы, разработанной в рамках данного проекта, можно представить следующим образом:
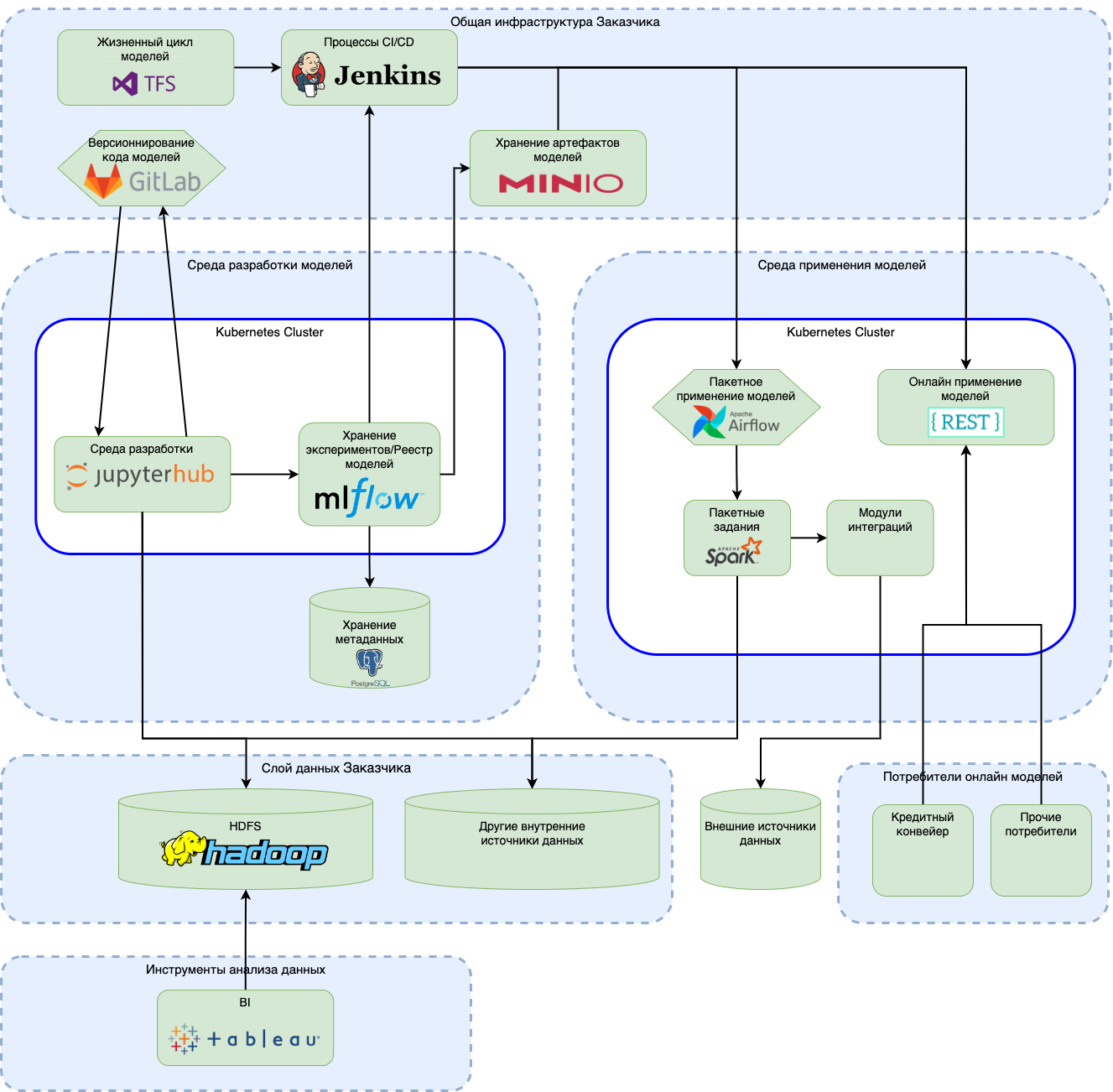
На этом проекте мы обкатали выбранный технологический стек и столкнулись с рядом новых проблем, которые предстояло осмыслить и решить. Выделим наиболее важные среди них:
Отсутствие готовых Helm чартов для деплоя MLflow в Kubernetes. В 2022 году появился полноценный Community чарт, но на этапе реализации проекта были только очень примитивные поделки от рядовых пользователей и пришлось писать собственный чарт;
Отсутствие в MLflow аутентификации и авторизации. Вопрос с авторизацией так и не удалось решить на том этапе, а аутентификацию пришлось реализовывать средствами сайдкара с Nginx, использующий для аутентификации OIDCплагин. Благо библиотека MLflow уже тогда позволяла передавать данные для аутентификации в хедерах;
Отсутствие в JupyterHub for Kubernetes гибкого механизма управления конфигурацией сервера и выделяемыми ресурсами. Особенности его реализации ограничивали работу дата-сайентистов одним запущенным сервером Jupyter и только в той конфигурации (в его терминах это называется профиль), которая была задана при развёртывании самого JupyterHub;
Не был подобран полноценный фреймворк для онлайн применения ML моделей. Seldon Core тогда только набирал популярность и ещё не был так известен, а MLflow включал весьма ограниченные возможности по запуску моделей с помощью Docker, поэтому пришлось писать свою реализацию на Flask;
Из предыдущей вытекает ещё одна проблема – необходимость реализации бизнес мониторинга (фактически логирования запросов и ответов модели) для отслеживания корректности работы ML моделей. На этом этапе данный вопрос также был решён средствами сайдкара с Nginx, использующего соответствующий плагин для логирования запросов и ответов во внешнюю систему.
Несмотря на указанные выше проблемы, уже тогда был частично сформирован костяк технологического стека платформы:
Kubernetes – как средство оркестрации приложений;
MLflow для отслеживания экспериментов и ведения реестра моделей;
Airflow – как оркестратор процессов ETL, обучения моделей на больших объёмах данных и пакетного применения моделей;
Minio для хранения артефактов моделей;
Prometheus Grafana – в качестве средства построения технических информационных панелей.
Вслед за данным проектом стали появляться и новые проекты внедрения MLOps-платформы. Следующее внедрение выросло из потребности бизнеса в привлечении внешних команд дата-сайентистов к разработке моделей на основе большого объёма данных, накопленного в компании. Здесь в качестве основы решения было предложено использовать CodaLab для упрощения организации процесса проведения соревнований между командами и Kubeflow – для организации инфраструктуры разработки моделей, подготовки универсальных пайплайнов обучения и тестирования полученных моделей, а также визуализации результатов. После ряда переговоров было решено сначала развернуть подобную платформу на основе Kubeflow без CodaLabи обкатать её на внутренней команде дата-сайентистов, после чего масштабировать подход на внешние команды.
Совместно с сотрудниками заказчика были проанализированы требования, проработана архитектура и развёрнуто две среды: одна для организации контура разработки моделей машинного обучения командами Data Science, вторая – для их применения в пакетном режиме. Между средами были организованы процессы CI/CD обеспечения сборки образов, публикации шаблонов ML пайплайнов и их доставки между средами. Ниже представлена концептуальная схема системы:
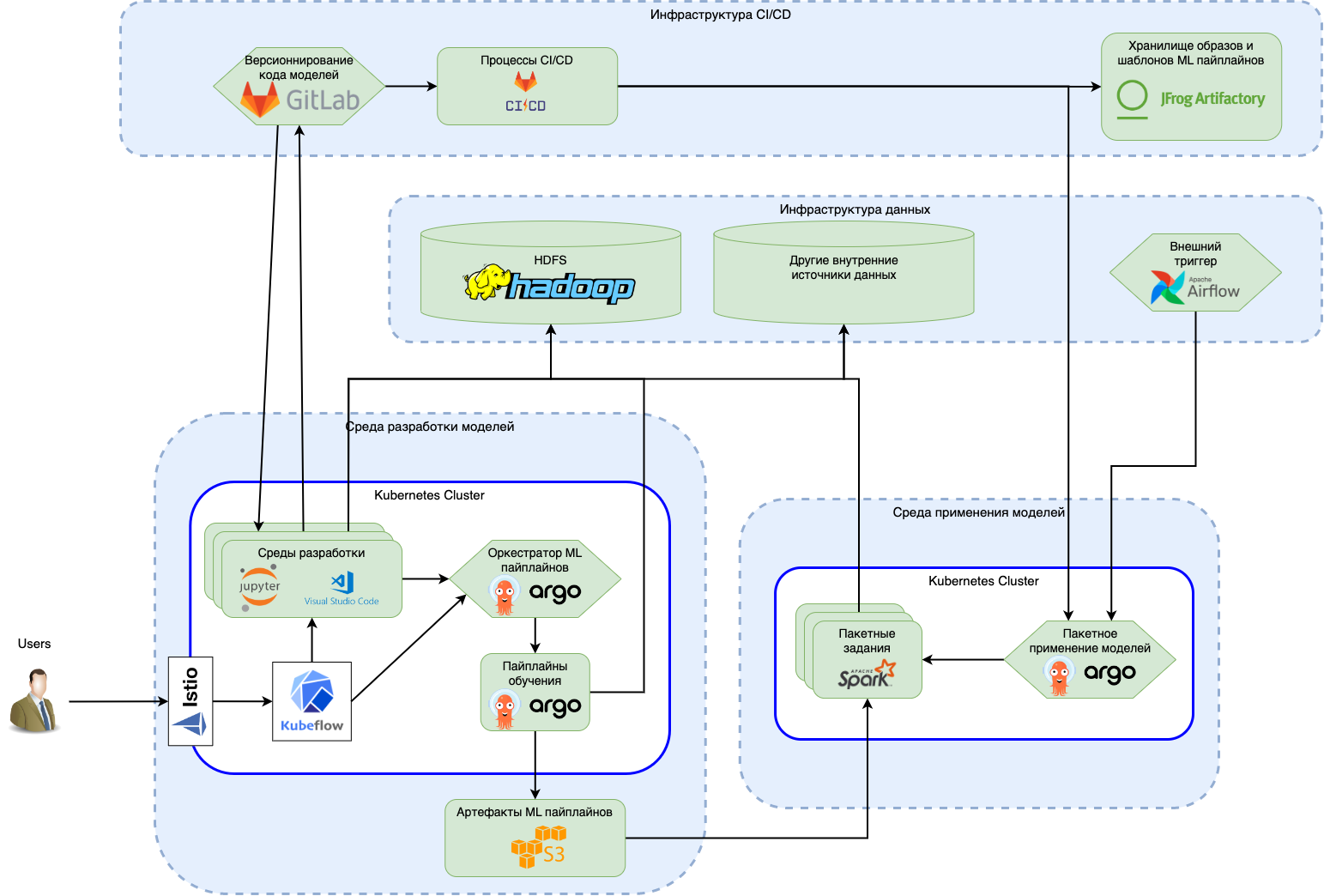
По результатам обкатки данной платформы были проанализированы плюсы и минусы её реализации относительно предыдущего проекта и сделаны следующие выводы:
Kubeflow в принципе более цельный как платформа, предоставляя одновременно инструменты разработки ML моделей, их применения в онлайн и пакетном режимах, инструменты подбора и тюнинга гиперпараметров, хранения и отслеживания созданных артефактов, их происхождения, а также централизованную аутентификацию и авторизацию;
Kubeflow работает на уровне нескольких нэймспэйсов Kubernetes, позволяя разделять рабочее пространство групп дата-сайентистов и выделенные для них ресурсы;
Управление средами разработки сделано в Kubeflow более гибко – в рамках каждого пространства имён может быть создано множество экземпляров IDE серверов, поддерживается три типа серверов «из коробки» (JupyterLab, RStudio и VSCode), и для каждого сервера может быть указано необходимое количество ресурсов (CPU, GPU, RAM, Disk), а также смонтированы заранее подготовленные конфигурации (сущности Secret и ConfigMap с заранее заданными путями монтирования). Но при этом ноутбуки не персонализированы и разделяются между всеми пользователями, имеющими доступ к пространству имён;
В части отслеживания экспериментов и сравнения метрик подход имеет свою специфику, этакую «пайплайноцентричность»: эксперименты представляют собой пайплайн обработки данных, привязанный к конкретному пространству имён Kubernetes, который регистрируется в Kubeflow и может быть запущен с определённым набором входных параметров. Каждый шаг такого пайплайна позволяет сохранить результаты в S3, а также залогировать связанные с ним метрики и артефакты, которые будут привязаны к конкретному запуску пайплайна. Полученные числовые результаты могут быть сравнены в интерфейсе в виде таблицы. Также поддерживается сравнение сохранённых артефактов, например, графиков или HTML файлов. Но при этом API более сложное для сохранения, нежели в MLflow и имеет несколько версий (каждая со своими ограничениями) и не позволяет просто сохранить файлы и метрики в запуск и затем посмотреть их через UI. Вопросы также вызвал интерфейс для отслеживания артефактов и их происхождения, отображающий артефакты и связи между ними для всего кластера без разделения по пространствам имён, а также ограничения доступа и в целом имеющий очень ограниченную функциональность;
Реестр моделей в Kubeflow отсутствует в принципе – на вкладке Models отображаются модели, запущенные в режиме онлайн применения с помощью одного из поддерживаемых аддонов. Красивого способа получить доступ к сохранённым артефактам нет, с другой стороны – никто не запрещает использовать для этого сторонние технологии, например, тот же MLflow;
Для запуска ML пайплайнов обучения и пакетного применения моделей Kubeflow использует один из доступных движков (по умолчанию Argo Workflows, но также можно настроить Tekton). Поскольку оба оперируют ресурсами Kubernetes и предполагают публикацию шаблонов рабочих процессов в виде YAML файлов, а дата-сайентисты и дата-инженеры привыкли работать с использованием Python, то для разработки таких пайплайнов в Kubeflow есть Python SDK, позволяющий описать рабочий процесс в виде Python кода, а затем скомпилировать и опубликовать его в Kubeflow как YAML манифест. Такой подход имеет как плюсы, так и минусы. Среди плюсов можно выделить нативную работу в Kubernetes за счёт первоначально ориентированных на работу в подобной среде движков, чёткое разделение оркестрации шагов от деталей их реализации, практически полную независимость пайплайнов от настроек Workflowдвижка и лёгкую переносимость скомпилированных пайплайнов между средами. Один из важнейших минусов – из-за компиляции пайплайнов в YAML файлы в сравнении с Airflow теряется гибкость, достигаемая за счёт описания этих пайплайнов в виде Python кода (API Kubeflow в этой части довольно ограничен, хоть и поддерживает многие стандартные варианты использования и ветвления), а также усложняется их параметризация. Скомпилированные YAMLфайлы громоздки и сложны в поддержке, особенно если создавать его шаги из Python кода. Помимо этого, само API для описания шагов ограничено и не расширяемо: например, нет возможности как в Airflow задать соединение с базой данных и использовать его в шаге для подключения;
Онлайн применение моделей в Kubeflow на тот момент было представлено на базе KFServing (который затем трансформировался в самостоятельный проект KServe) и сделано очень достойно в части базовой визуализации состояния развёрнутых моделей. Есть поддержка вывода метрик, логов и описания моделей, но не так хорошо как при использовании Seldon Core (который мы пилотировали параллельно с данным проектом) в части развёртывания комплексных графов применения моделей и операций второго дня – развёртывания моделей в режиме A/Bтестирования, трассировки, бизнес логирования работы моделей, а также отслеживания принятых решений (хотя большинство из этого добавили в более свежих версиях). Надо сказать, что часть из этих возможностей также была доступна и в KFServing, но его API на тот момент в целом выглядело гораздо менее зрело, а возможности были недостаточно документированы.
Затронув тему Seldon Core, хотелось рассказать ещё об одном проекте внедрения MLOps- платформы, который наша компания выполняла параллельно с предыдущим. На этот раз при проектировании системы фокус был на эксплуатации моделей машинного обучения, оставляя процесс их разработки за рамками скоупа. Архитектуру системы, разработанной в рамках данного проекта, можно представить следующим образом:
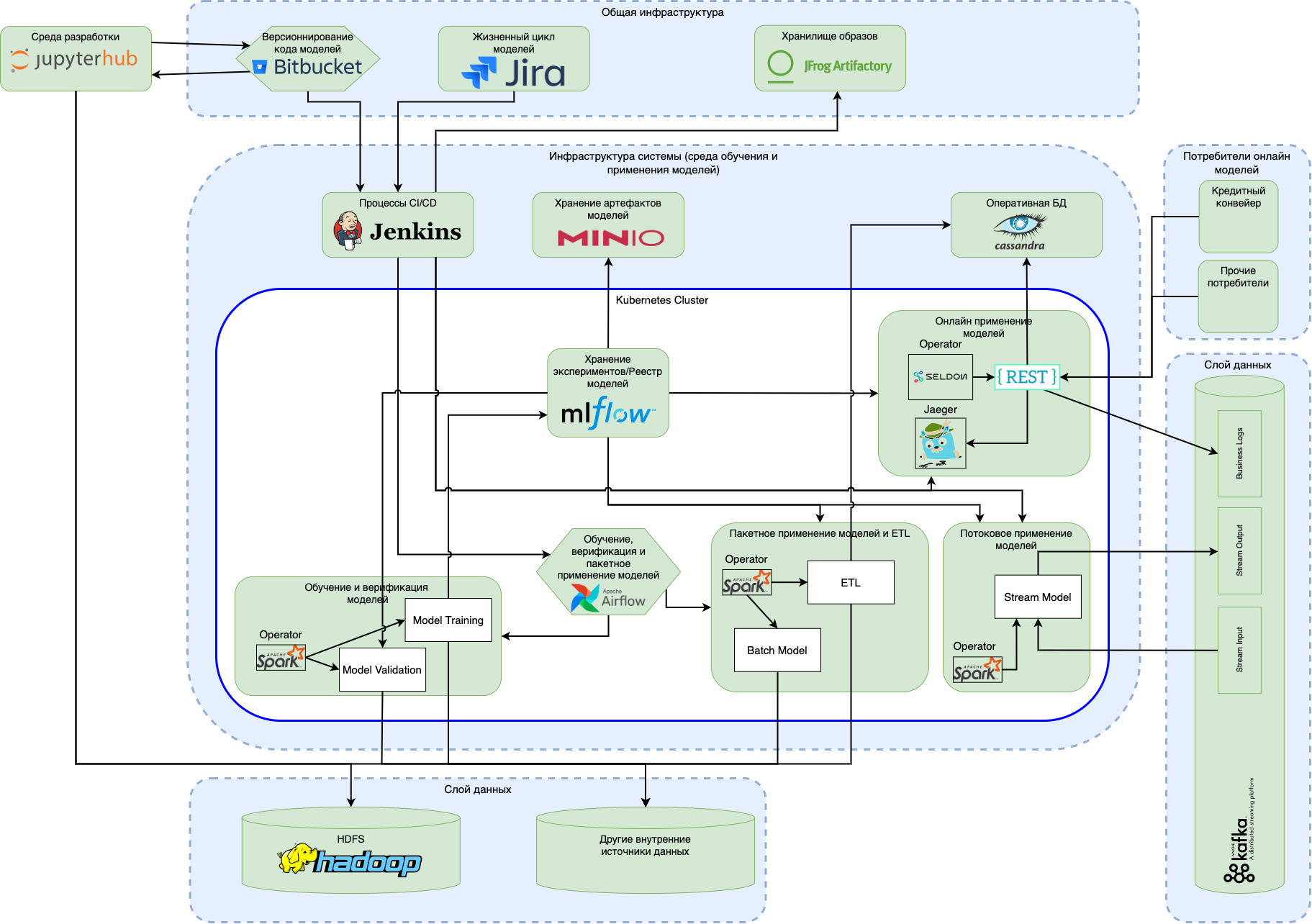
В связи с наличием соответствующих требований информационной безопасности в части доступа к данным, описанный выше состав компонентов присутствовал на каждой из сред и обеспечивал единые процессы разработки, тестирования и применения ML моделей. С её помощью дата-сайентисты и дата-инженеры могли в автоматизированном режиме обучать и верифицировать модели, подготавливать данные для онлайн применения моделей (для их получения в системе использовалась оперативная база данных) и развёртывать любую из обученных моделей в одном из трёх режимов – онлайн, пакетном и потоковом.
Расскажем о технических деталях проекта:
В части отслеживания экспериментов и ведения реестра моделей вновь использовался MLflow. Здесь активно использовался реестр моделей: зарегистрированная версия модели в зависимости от стэйджа попадала на верификацию, либо исполнение, API которого использовался в рамках CI/CD конвейера для автоматизации получения артефактов соответствующей версии;
Airflow выступал основной движущей силой решения – с его помощью публиковались и запускались DAG’и для обучения моделей, их верификации и пакетного применения. Если же разрабатывалась онлайн модель, для вызова которой вызывающая система не имела полного набора данных и для полноценной работы требовалось обогащения входного запроса, то с помощью Airflow также публиковался и запускался ETL процесс загрузки данных из исторического хранилища в оперативное.
Для обеспечения быстрой обработки большого количества данных, необходимых для описанных выше процессов, в решении использовался Spark on K8S Operator, упрощающий запуск заданий Spark на кластере Kubernetes. Для интеграции с ним в Airflow использовался соответствующий оператор от CNCF. С его помощью также происходило развёртывание моделей в потоковом режиме, при котором модель загружается в виде Spark UDF функции и применяется на потоке данных из Apache Kafka (например, совершая предсказания на основе кликстрима);
Выше я уже писал про Seldon Core и в этом проекте он использовался для онлайн применения ML моделей. С его помощью осуществлялась публикация моделей в виде REST сервисов, для успешной эксплуатации которых был задействован ряд имеющихся в нём интеграций. Для отслеживания корректности работы моделей требовалось осуществлять бизнес логирование входящих запросов и ответов, которые с помощью Seldon Core могут быть заданы декларативно (поддерживается отправка запросов в HTTP и Kafka эндпоинты). В ряде моделей использовалась возможность Seldon Core по построению ансамблей и комплексных графов применения, в рамках которых различные узлы выполняли разные функции. Например, в одном узле выполнялось обогащение входящего запроса данными из оперативной базы, а в другом – вызов модели для получения предсказания. Если требовалось оценить производительность отдельных узлов графа, то на помощь приходила интеграция с Jaeger, предоставляющая TraceView вызовов, также задаваемая декларативно. Помимо этого, используемый в Seldon Core микросервис предоставляет SwaggerUI, с помощью которого можно получить состав имеющихся в нём методов, схемы входного и выходного запроса, а также осуществить вызов модели непосредственно из браузера для тестирования её работы.
Выбранный стек показал свою эффективность, но всё ещё оставались незакрытые вопросы: например, касающиеся разделения прав доступа в MLflow для работников, занимающихся разными проектами или работающими в разных отделах. В процессе работы над последним проектом в компании было принято решение о создании акселератора, который позволит реализовывать подобные проекты быстрее, качественнее и более эффективно консолидировать полученную экспертизу. Так начался процесс создания продукта, который в последствии получил название Dognauts (образовано от Dogs Astronauts). О его создании речь и пойдёт в следующей статье.