
В одной из моих предыдущих статей я рассказал о скрипте с названием GentleRebuild, который делал index rebuild в базах, работающих под нагрузкой 24/7, когда нет maintenance window, в Enterprise Edition. Там можно использовать опции ONLINE=ON и даже RESUMABLE=ON, вежливо уступая основной нагрузке базы.
А как же Standard Edition, где этого нет? Каюсь, раньше у меня в скрипте даже стояла проверка, и для Standard Edition скрипт сразу завершался. Но шеф меня попросил заняться и серверами со Standard Edition, и мне пришлось выжать из ситуации максимум.
Человек на мосту

Изображение не случайно.
Итак, у нас все операции непрерываемые. Скрипт по прежнему следит за тем, как он может мешать основной нагрузке на базу. Напомню, что скрипт следит за
слишком высоким CPU
слишком большим объемом заполненности лога (LDF)
слишком большим ростом AlwaysOn queue (репликация лога не успевает за IO)
административными ограничениями (время, объем перестроенных индексов)
кастомными условиями
наличием процессов, блокированных операцией INDEX REBUILD
Если в Enterprise Edition скрипт может для большинства условий временно прервать (throttle) перестройку индекса в середине, то Standard Edition проверяет все те же условия, но только по окончании каждой операции. Большинство из условий не такие жесткие, кроме одного - блокировок. REBUILD большого индекса может занять минуты и часы, и если интерактивный процесс остановится и будет ждать этой операции, то все будет плохо.
Таким образом, наличие блокировки (какой-то процесс или процессы ждут REBUILD) является основанием для прерывания операции. Но в Standard Edition это прерывание вызывает rollback, и откат может занять больше времени, чем достроить индекс до конца! Так и родилась у меня аналогия с задачей про мост.
Вы идете по узкому мосту, а навстречу поезд. Куда бежать - назад или вперед? Вперед, навстречу поезду, бежать лучше, если осталось чуть-чуть. Но как это рассчитать точно и как узнать длину моста? Ведь для операций без RESUMABLE процент выполненной работы не показывается!
Длина моста, или оценка процента выполненной работы
После ряда выполненных экспериментов, я остановился на линейной зависимости между page_count (числа страниц в исходном индексе) и logical_reads из sys.dm_exec_requests:

Для многих таблиц явно проглядывает линейная зависимость. Увы, отношение зависит, видимо, от ряда внутренних факторов, которые я не знаю. В итоге я остановился на формуле:
да, она не абсолютно точна, но это лучше, чем ничего.
Куда бежать? Дождаться конца операции, или делать kill/rollback?
Я написал программу для проведения экспериментов. Начнем с MAXDOP=1:

Оранжевый график - это сколько осталось времени до конца операции в процентах к полному времени выполнения. Очевидно, это прямая. Синяя линия - сколько времени будет идти rollback, если его выполнить в данный момент (время тоже в процентах к полному времени операции)
Как видно, до примерно 75% быстрее сделать rollback, а позже быстрее дождаться окончания rebuild.
Попробуем менять MAXDOP. Сразу скажу, что указание MAXDOP для INDEX REBUILD иногда игнорируется и операция идет в один поток - для некоторых индексов MS SQL иначе не умеет, видимо. Если же он умеет делать работу во много потоков, то образуется MAXDOP+1 запись в sysprocesses - одна управляющая и 'рабочие'. Итак,

При MAXDOP=2 "point of no return" находится уже на 63%. А дальше начинаются чудеса:
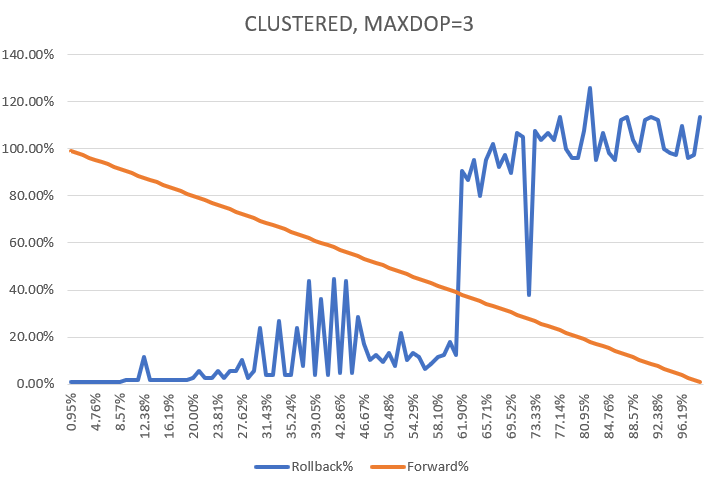
Эффект "гребенки" неслучаен и хорошо воспроизводится. Обратите внимание, что по Y есть точки выше линии 100% - то есть rollback занимает дольше, чем вся операция от начала и до конца. Еще больше это проявляется при дальнейшем повышении MAXDOP:

Тут первая point of no return вообще на 42%. Идем дальше:


Вау! Впрочем, неудивительно - rollback то идет в один поток.
Для NONCLUSTERED индексов графики немного более плавные и имеют немного другие "points of no return".
При MAXDOP>2 систему сильно колбасит, с другой стороны, при увеличении MAXDOP работа будет закончена все быстрее и быстрее:

Здесь время в секундах. Как видно, при увеличении MAXDOP все ускоряется (синяя линия), а красная линия показывает наихудшее время rollback.
Вывод
Лучше использовать MAXDOP=1 или 2, если планируете убивать мешающий основным процессам rebuild. Либо можно перестраивать индекс в режиме кошки, которая прижав уши (будь что будет) перебегает дорогу как можно быстрее. Тогда лучше поставить MAXDOP побольше - чем короче операция, тем меньше вероятности блокировки, и выставить у скрипта параметр killnonresumable=0 - тогда блокировки не будут приводить к kill/rollback.
В обычном режиме (killnonresumable=1), скрипт GentleRebuild при наличии блокировки убивает операцию, только если она не дошла до "point of no return", которая определяется эвристикой (в $maxdop находится число записей в sysprocesses - это MAXDOP+1, либо 1, если MS SQL не послушался вас):
# returns point of no return value
# note that for MAXDOP=n there are typically n+1 threads, so $maxdop=2 should never occur
function PNRheuristic([int]$maxdop, [string]$itype) {
if ($maxdop -gt 9) { return 40. }
if ($itype -eq "CLUSTERED") { $heur = 75., 63., 63., 55., 45., 43., 42., 40., 37. }
else { $heur = 86., 74., 74., 70., 64., 55., 50., 45., 40. }
return $heur[$maxdop-1]
}Сортировка жертв
Но всегда ли блокировка - это повод для паники? Есть процессы, которые могут подождать - UPDATE STATISTICS, разные джобы, которые грузят данные. А есть коннекции от интерактивных процессов, и если они ждут, то пользователь видит замерший экран или ловит таймаут.
Для сортировки жертв блокировки на критичные и не очень администратору предлагается отредактировать функцию, которая изначально выглядит вот так:
function VictimClassifier([string] $conn, [int] $spid) {
# returns:
# cmd - details of the blocked command
# cat - category this connection falls into
# waittime - time this connection already waited, sec
# maxwaitsec - maximum time for this connection allowed to wait
# $waitdescr, $waitcategory, $waited, $waitlimit
$q = @"
declare @cmd nvarchar(max), @job sysname, @chain int
select @job=J.name from msdb.dbo.sysjobs J
inner join (
select
convert(uniqueidentifier, SUBSTRING(p, 07, 2) + SUBSTRING(p, 05, 2) +
SUBSTRING(p, 03, 2) + SUBSTRING(p, 01, 2) + '-' + SUBSTRING(p, 11, 2) + SUBSTRING(p, 09, 2) + '-' +
SUBSTRING(p, 15, 2) + SUBSTRING(p, 13, 2) + '-' + SUBSTRING(p, 17, 4) + '-' + SUBSTRING(p, 21,12)) as j
from (
select substring(program_name,charindex(' 0x',program_name)+3,100) as p
from sysprocesses where program_name like 'SQLAgent - TSQL JobStep%' and spid=$spid) Q) A
on A.j=J.job_id
select @cmd=Event_Info from sys.dm_exec_input_buffer($spid, NULL)
select @chain=count(*) from sysprocesses where blocked=$spid and blocked<>spid
select distinct @cmd as cmd,isnull(@job,'') as job, @chain as chain, waittime/1000 as waittime,open_tran,rtrim(program_name) as program_name
from sysprocesses P where P.spid=$spid
"@
$vinfo = MSSQLscalar $conn $q
$prg = $vinfo.program_name
$cmd = $vinfo.cmd # top level command from INPUTBUFFER
$job = $vinfo.job # job name if it is a job, otherwise ""
$chain = $vinfo.chain # >0 if a process, locked by Rebuild, also locks other processes (chain locks)
$waittime = $vinfo.waittime # already waited
$trn = $vinfo.open_tran # has transaction open
# build category based on info above
$cat = "INTERACTIVE"
if ($cmd -like '*UPDATE*STATISTICS*') { $cat = "STATS" }
elseif ($job -like "*ImportantJob*") { $cat = "CRITJOB" }
elseif ($job -gt "") {
$cat = "JOB"
$cmd = "Job $job"
}
elseif ($prg -like "*Management Studio*") { $cat = "STUDIO" }
elseif ($prg -like "SQLCMD*") { $cat = "SQLCMD" }
if ($chain -gt 0) { $cat = "L-" + $cat } # prefix L- is added when there are chain locks, it is critical
elseif ($trn -gt 0) { $cat = "T-" + $cat } # prefix T- means that locked process is in transaction
$cmd = $prg + " " + $cmd
# allowed wait time before it thrrottles or kills rebuild
$maxwaitsecs = @{
"INTERACTIVE" = 30
"STATS" = 36000
"JOB" = 600
"CRITJOB" = 60
"STUDIO" = 3600
"SQLCMD" = 600
"T-INTERACTIVE" = 30
"T-STATS" = 600
"T-JOB" = 600
"T-CRITJOB" = 30
"T-STUDIO" = 1800
"T-SQLCMD" = 600
"L-INTERACTIVE" = 20
"L-STATS" = 20
"L-JOB" = 20
"L-CRITJOB" = 20
"L-STUDIO" = 20
"L-SQLCMD" = 20
}
return $cmd, $cat, $waittime, $maxwaitsecs[$cat]
}Как вы видите, процедура определяет SQL команду (текст), имя job (если есть), program_name, и на этом основании процесс жертва классифицируется в одну из категорий. Здесь их 6, однако, если процесс жертва в транзации (а значит больше вероятность цепочки блокировок) или такие цепочки уже возникли, то к имени категории дописывается "T-" (в транзакии) и "L-" (цепочка блокировок).
В самом конце на основании категории вычисляется время, которое процесс может подождать (предполагается, что эти параметры может подправить DBA под свою систему).
Итак, мы знаем время, которое процесс УЖЕ ждал ($waittime) и максимальный срок, который он может без последствий ждать. Дальнейшая логика базируется на следующих комбинациях условий:
Мы уже за "point of no return" - увы, как бы ни было плохо, уже лучше подождать окончания операции.
Иначе, если процесс уже ждал больше, чем ему позволено, то придется делать kill/rollback
Иначе сложим время, которое он ждал с "projected time" - ожидаемое время до конца операции, которое скрипт рассчитывает на основе процента выполненной работы (как говорилось выше, эта оценка не совсем точная) и текущей скорости работы. Если wait time + projected time больше позволенного максимума, то мы делаем kill/rollback заранее, потому что до конца операции время ожидания данного процесса "перезреет" и превысит допустимый максимум
Если заблокированных процессов много, то для kill/rollback достаточно условия по любому
Вот как это выглядит на реальной системе:

Вся эта логика отчасти купирует боль, и позволяет пройти много дальше не влияя сильно на рабочие процессы. Однако, могут быть ситуации где мы попали в красную зону. Например, не совсем правильно оцененный процент прогресса. Или заблокированный интерактивный процесс, возникший на позднем этапе.
Опция offlineretries=n заставляет скрипт пытаться повторить операцию после kill/rollback снова и снова после kill/rollback (после окончания попыток он переходит к следующему индексу), и иногда скрипту удается проскочить в окно возможностей даже для больших таблиц. Но будем честны - если у вас есть большая таблица к которой 24/7 идут обращения интерактивных пользователей нон стоп, то на Standard Edition вы не сможете сделать ничего, не влияя на работу.
Некоторые плюшки Standard Edition (для оптимизма)
В OFFLINE INDEX REBUILD есть и хорошие вещи. Например, он не влияет на планы операций. Для RESUMABLE усложнения execution plans может быть проблемой.
RESUMABLE не работает с SORT_IN_TEMPDB. Опция sortintempdb=n добавляет опцию SORT_IN_TEMPDB=ON, если таблица меньше n мегабайт.
Наконец, опция forceoffline=1 "превращает" Enterprise Edition в Standard, если вы не хотите пользоваться ONLINE и RESUMABLE.
Актуальная версия скрипта находится тут: https://github.com/tzimie/GentleRebuild
Сайт проекта: https://www.actionatdistance.com/gentlerebuild
P.S. А как же INDEX REORGANIZE? Stay tuned. Я не хочу включать возможность использования этой операции без оценки прогресса ее выполнения. А это требует отдельного исследования.
echo10
Всегда забавляют эти любители прятать инфу на скринах, когда на статью подготовить хватило выдержки, а сделать информационно нейтральный стенд, который можно скриншотить без черных полосок - нет. Имхо, приятнее реальный вывод видеть без сокращений.