

Привет, Хабр! Меня зовут Михаил Сапрыкин, я ведущий инженер разработки в Сбере. Наша команда развивает систему антифрода. Раньше мы работали с Apache Ignite, но затем перешли на Platform V DataGrid — распределённую базу данных в оперативной памяти для высокопроизводительных вычислений, которую разрабатывает СберТех.
Расскажу, как и зачем мы это сделали и как это помогло нам справиться с задачей горизонтального масштабирования.
Что такое антифрод и как он работает
Любой финансовой или банковской организации нужно защищать данные клиентов от мошеннических операций. Решать эту задачу помогает антифрод (от англ. anti-fraud) — система по противодействию мошенничеству, которая отслеживает и предотвращает действия злоумышленников. В нашем случае антифрод противодействует мошенничеству с банковскими операциями. Он обеспечивает безопасность и сохранность средств клиентов и таким образом формирует имидж Сбера как финансового партнёра, на которого можно положиться.
Пару слов о том, как работает антифрод в Сбере. Когда в нашу систему приходит транзакция, мы берем из неё некоторые данные и на их основе производим вычисления. Мы называем их фичи (от «feature» — признак). Например, фича — это сумма всех транзакций между двумя пользователями за месяц. Или время между текущей и предыдущей транзакцией. После расчета фич мы передаём их в модели ИИ и на основе полученной информации выносим вердикт: запретить транзакцию, разрешить или отправить на дополнительное подтверждение. Всё это — в режиме реального времени за короткий промежуток до 100-200 мс.
То есть антифрод в Сбере — это высоконагруженная система, для задач которой необходима СУБД для высокопроизводительных вычислений.
Что использовали раньше
Раньше в качестве такой СУБД мы использовали Apache Ignite в составе монолитной схемы. Посмотрим на схему приложения — одной из ключевых частей нашей системы антифрода.

Приложение написано на Java и развёрнуто на машинах с 3 Тб оперативной памяти и 176 ядрами. Внутри приложения мы поднимаем ноду Ignite, которая не является клиентом или частью топологии какого-либо кластера. В кешах этой ноды мы храним исторические фичи, которые были рассчитаны во время обработки предыдущих транзакций. Мы принимаем сообщение, или транзакцию, в виде JSON-схемы. Из этой схемы извлекаем некоторое количество полей, и их значения используем в качестве ключей для кешей, в которых хранится история фич.
Далее мы рассчитываем фичи уже для текущей транзакции, передаём расчёты в модели ИИ, получаем скоринг. Его и определённое множество фич мы возвращаем в вызывающую систему. Под кеши в оперативной памяти выделено 2,7 Тб, это примерно 3,5 млрд записей.
Мощность машин позволяла нам хранить весь объём исторических фич, пока мы масштабировались вертикально. Но со временем система расширяется, добавляются кеши. Мы загружаем в приложение при запуске 3,5 млрд записей из Kafka, на это уходит до 6 часов. В рамках тяжёлых машин масштабироваться стало сложно.
Почему перешли на Platform V DataGrid
Мы решили масштабироваться в рамках более простых машин с помощью продукта Platform V DataGrid — СУБД в оперативной памяти для высокопроизводительных вычислений. Кластер Ignite в Platform V DataGrid доработан и соответствует высоким требованиям в производительности, безопасности и надёжности.
Одно из основных преимуществ перехода на Platform V DataGrid — доступ к функциональности, которая отсутствует в Apache Ignite. Например, сжатие данных в оперативной памяти. Подробно о различиях можно почитать тут.
Обычно пиковая нагрузка на систему составляет 340-350 тыс. транзакций в минуту только в канале дистанционного банковского обслуживания. Совокупно по всем каналам это около 700 тыс. транзакций в минуту. Platform V DataGrid помогает команде работать с постоянно возрастающей нагрузкой сервиса и держать много запросов.
Как подбирали схему решения
Нам нужно было прийти к следующей схеме: сообщение поступает в наше приложение, оно делает запросы в Platform V DataGrid.

Схем решения было много: я приведу несколько основных и решение, которое сейчас работает в ПРОМе. Для этого напомню, что такое тонкий и толстый клиент Ignite:
Толстый клиент — это полноценная нода, которая входит в топологию кластера и является клиентом, но данные в себе не хранит. У толстого клиента расширенный API по сравнению с тонким клиентом. Толстому клиенту доступна такая функциональность, как Data Streaming.
Тонкий клиент — это легковесный клиент с более простой конфигурацией. Он не является нодой и не входит в топологию кластера.
Сначала мы решили пойти по пути наименьшего сопротивления и просто адаптировать наше изначальное решение под вызовы во внешний кластер, используя возможности тонкого клиента. Для этого мы просто поменяли вызов IgniteCache#get() на ClientCache#get().
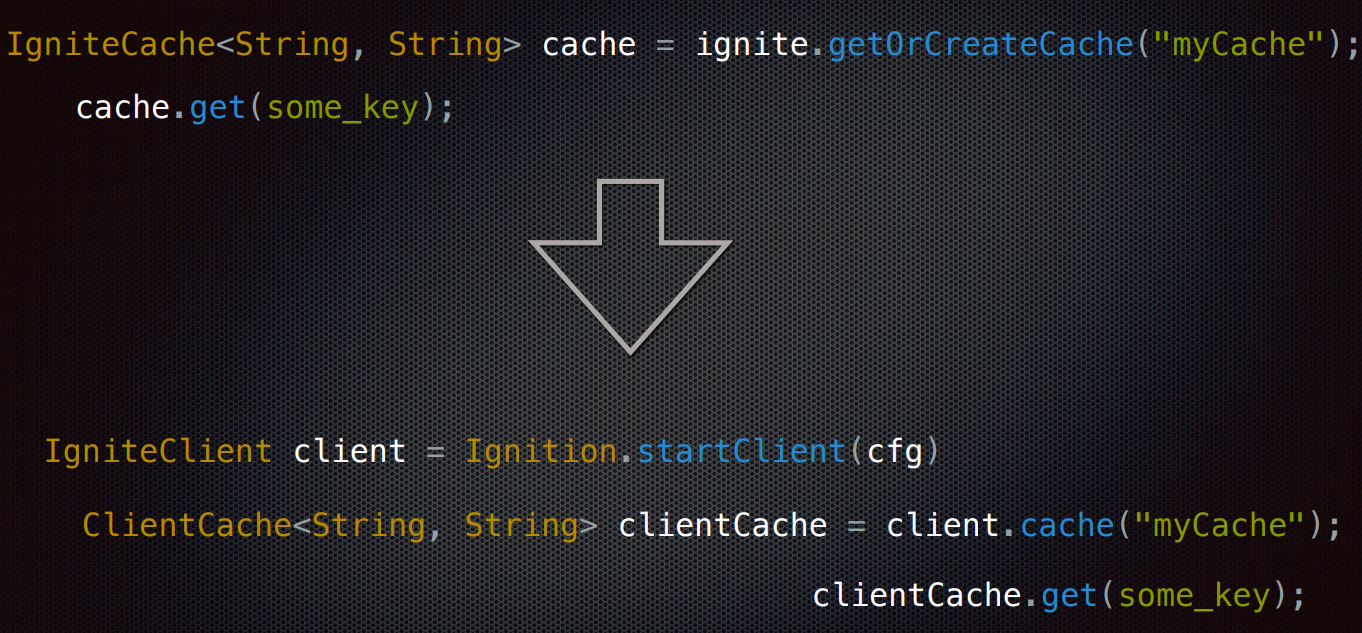
Это не взлетело по очевидным причинам. Когда мы обращаемся в кластер Platform V DataGrid, из-за сетевого взаимодействия получаем от 1 до 4 мс на запрос. Нужно было ускорить процесс. На момент начала работ по переходу на Platform V DataGrid у нас была установлена версия Apache Ignite 2.8.0. Мы обновились до последней на тот момент версии 2.12.0, в котором появился Async API для клиентов, и приступили к созданию асинхронной схемы.
При живой нагрузке входящие сообщения обрабатываются в 150 потоков. На схеме ниже видна разница между синхронной и асинхронной работой клиента в разрезе одного потока. На каждую транзакцию система делает порядка 25 запросов в кеши, одну транзакцию обрабатывает один поток. Для простоты и наглядности на схеме я указал всего три.

Слева мы видим, что при каждом запросе поток блокируется и ждёт ответа. Получается, что общее время выполнения запросов равно сумме выполнения всех запросов.
Справа мы сначала в цикле осуществляем все запросы и складываем полученные future в map. На следующем шаге мы также в цикле жд`м завершения всех полученных future. Таким образом, общее время выполнения всех запросов равно времени выполнения самого долгого запроса.
Мы переписали код под асинхронные вызовы, но один клиент такую нагрузку всё равно не выдерживал.
Создаём пул тонких клиентов
Если одного клиента мало, нужно сделать пул. Во время работы с кластером нам не нужно масштабировать количество клиентов, поскольку время на подключение недопустимо велико. Мы при запуске приложения подключаем все клиенты и храним в списке. Каждый поток, который берёт в работу обработку транзакции, может получить через ThreadLocal свой личный клиент. Количество клиентов равно количеству потоков в пуле обработки. Таким образом, мы получили простой легковесный пул тонких клиентов.

Первые хорошие результаты — на графике. Сверху мы видим нагрузку до 130 000 tps на кластер Platform V DataGrid. Снизу — график времени обработки сообщения в нашем приложении от входа до ответа:

У зелёного графика есть выбросы, от которых хотелось избавиться. Для этого мы понижали нагрузку и искали точку возникновения выбросов. При минимально необходимой нагрузке выбросы оставались, и мы решили отложить работу с пулом тонких клиентов.
Толстый клиент. Выполнение на кластере
Мы решили посмотреть, как себя покажет толстый клиент. Вариантов было несколько, я покажу самый перспективный для нашей системы и, как мне кажется, самый интересный.
API Distributed Computing — мощный инструмент, который позволяет использовать кластер Ignite в Platform V DataGrid не только как хранилище, но и как кластер для вычислений (Compute Grid). В нём есть механизм Executing tasks, который помогает развёртывать свой код в кластере, а тот будет его исполнять. Для этого нужно определить один из интерфейсов IgniteRunnable, IgniteCallable или IgniteClosure, у которых есть соответствующие методы run(), call() и apply(). Аннотация @IgniteInstanceResource позволяет получить в кластере экземпляр Ignite для работы с данными. Мы использовали IgniteCallable, потому что в качестве ответа нам нужны были данные из кешей. Получилась следующая схема:

MyCallableTask развёртывается в кластере с помощью механизма Peer Class Loading. В методе call() итерируемся по keysToCaches и используем предоставленный экземпляр Ignite для обращения в каждый кеш по ключу. Собираем данные из кешей в результирующую map, которая будет возвращена клиенту как ответ.

Сам вызов происходит следующим образом: когда транзакция приходит в обработку, мы извлекаем из нее ключи для кешей, складываем в map напротив имён кешей, формируем задачу, передаем в неё эту map и отправляем для выполнения в кластер. В ответ получаем map с ключами напротив данных по этим ключам.

Толстый клиент работает при такой нагрузке довольно стабильно. Но это половина от того, что нам требуется. Если добавить нагрузку, схема быстро деградирует.
Возвращаемся к тонкому клиенту
Так мы решили попробовать доработать тонкий клиент для достижения целевого результата. Для этого мы стали смотреть, что происходит с пулами потоков в приложении. Приложение можно условно разделить на два пайплайна:
Процессинговый — вход сообщения, получение фич, скоринг моделей, формирование ответа.
Постпроцессинговый — формирование и сохранение данных для транзакционной истории и истории фич.
На тот момент в процессинговый пайплайн был установлен ForkJoinPool#commonPool. Выяснилось, что помимо обработки сообщения он также участвовал в постпроцессинге. И это ещё не всё. Оказалось, что ForkJoinPool#commonPool установлен по умолчанию для выполнения континуаций — операций, которые можно производить над результатом, полученным в процессе асинхронной операции.
Как видно из примера, переданный в thenAccept() System.out.println() будет обработан в asyncContinuationExecutor.

Получается, commonPool не мог обеспечить сбалансированную работу с тонкими клиентами, вследствие чего мы и наблюдали выбросы.
Для решения этой проблемы мы установили на процессинговый пайплайн FixedThreadPool с количеством потоков, равным количеству тонких клиентов. Для asyncContinuationExecutor в конфигурации клиента мы установили ещё один FixedThreadPool с таким же количеством потоков. Таким образом мы сбалансировали нагрузку на тонкие клиенты и получили долгожданный результат.

На графике сверху мы видим нагрузку на Platform V DataGrid порядка 130 000 запросов в секунду. При этом график времени обработки сообщений довольно ровный и не превышает 50 мс, выбросов не наблюдается. SLA y нас — 200 мс.
Пазл сложился — асинхронный вызов пулом тонких клиентов с балансировкой по пулам потоков дал рабочий результат.
В ПРОМе приложение работает для отказоустойчивости на четырёх машинах. Каждая в пике генерирует около 2,3 миллиона запросов в минуту в Platform V DataGrid. Все четыре машины — 9,2 миллиона в минуту, что в переводе на секунды даёт более 150 000 tps.

Подводим итоги
Мы проиллюстрировали на реальном примере, как распределённая база данных Platform V DataGrid помогает поддерживать работу и масштабировать такие высоконагруженные системы, как наша. Это решение отлично подходит для быстрых масштабных операций, с которыми работает в том числе и наша система антифрода. Благодаря этому мы способны обеспечить высокий уровень безопасности данных наших клиентов и надёжно хранить их средства.
За рамками статьи осталось то, как мы используем толстый клиент Ignite (Data Streamers) в нашем отдельном приложении для загрузки кластера данными из Kafka. А также то, как мы пишем экспериментальный код для оптимизации уже рабочих решений. Но об этом — уже в следующих материалах.
Спасибо за внимание!
alpha_Dog
О, приятно было почитать. Году в 2017 приложил руку к созданию mvp этой системы. Как раз туда и был заложен Ignite.