
Отчёт вот. Теперь давайте смотреть, а не читать.

Хорошие мультимодальные способности, чётко считывает указатели, хорошее общее понимание ситуации
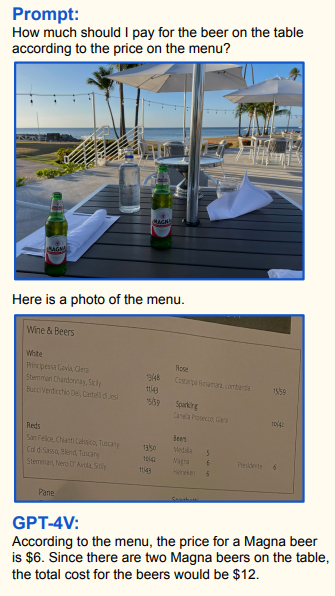
Если вы пьяны, он пересчитает пиво и сверит с чеком:
Собственно, важное:
- Хорошо понимает что за сцена изображена и какие взаимосвязи между объектами на ней.
- Читает текст, ориентируется на местности, опознаёт конкретных людей
- Умеет в абстракции и обратно
- Отлично ищет то, чего не должно быть (отклонения от базовой идеи) — дефекты на деталях, дефекты в людях (в особенности на рентгене) и так далее.
- Плохо считает.
Давайте к деталям.
Можно парсить текст с фото:

Это традиционный навык, но здесь он очень впечатляет. Капче, кажется, хана:

Правда, не всё потеряно для капчи, с математикой, как обычно, не очень:

Таблицы:

Перевод и общее понимание:

Очень, очень хорошая работа с указателями. Можно обводить, показывать корявыми стрелочками, делать системные рамочки, всё очень хорошо фокусирует внимание. Можно хоть делить счёт по фотографии стола:

Хорошо строит взаимосвязи по кадрам, мини-обучение внутри промпта отлично работает (как и на текстовой версии). Здесь пока много ошибок по отчёту, но это одна из самых многообещающих способностей:

Распознаёт людей:

И даже абстракции:

Точно так же он отлично определяет достопримечательности по фото и еду:

Уверенно читает КТ:


Но жертвы будут:

С лёгкими, кстати, традиционно справляется хорошо.
Показывает общее понимание ситуации. Это, пожалуй, одна из самых удивительных вещей, потому что на этом свойстве строится много других сложных навыков. Слишком рано, слишком рано это появилось в нашем мире!

Вот комплексная задача: пересчитать людей и подписать каждого:

Хорошее мультимодальное понимание ситуации:

Но тут надо сказать, что вполне возможно, что по известной картинке он просто знает текстовое описание мема и толкует его.
Аналогичная ситуация, где можно решить и без картинки:

А вот это уже куда интереснее. Здесь нужно просто сделать выводы о том, что в сцене. Похоже, сначала ввод преобразуется в векторную модель (подробное описание в виде вектора, аналог огромного текстового описания от судмедэксперта), а потом по вектору уже применяются логические операции:

И вот:

Прогноз действий в видео(!):

Если вы думаете, что это всё, то нет. Смотрите:

Сочетание с указателями:

Пересказать видео? Не вопрос:

Этой фигнёй вы его не обманете:

Да и вообще не обманите, как он научится воспринимать видео в контексте допроса:

Манипулировать тоже уже умеет:

Невинная игра «найди 5 различий» превращается в поиск дефектов между идеальной векторной моделью объекта и образцом:

Но жертвы будут:

Определение корзины пока страдает без узкой базы того, что есть в магазине (рядом есть примеры с сужением базы, они точнее):

А вот это уже интересно:

Организационный порядок:

И попугай за рулём:

Фильтры, то есть смешение образца с идеей:

Очень, очень хорошие возможности для различной роботизации.
Вот для RPA:


А вот, например, гипотезы поиска холодильника:


Он и вас найдёт, дайте только ему одежду и мотоцикл.
Ещё раз, отчёт вот. Уже видно, кого и сколько можно будет уволить из-за 4V. Это вам не ChatGPT, для работы с которым нужно сильно много думать и формулировать задачу. Этому можно просто показать, и он разберётся.
Ещё раз главное:
- Можно дать на вход текст и картинку (или несколько картинок), это очень гибкое сочетание.
- На выходе тоже можно получить текст и картинку (но генерация пока хуже распознавания).
- Он преобразовывает ввод всё в то же векторное поле, которым пользуется в LLM, то есть, по большому счёту, наследует все способности GPT4, но очень расширяет возможности ввода.
- Хорошо учится по образцам прямо внутри промпта.
- Хорошо распознаёт объекты и их взаимосвязи, предсказывает следующее событие в сцене.
- Уверенно распознаёт медицинские ситуации по изображениям.
- Хороший поиск дефектов.
- Умеет считать объекты, но не хочет. В медленном режиме пошагового счёта считает лучше.
- Умеет обводить объекты и давать их координаты.
- Подписывает части изображения.
- Хорошо объясняет по картинкам, инструкции очень крутые.
- Отлично анализирует сцену в реверсе («представь, что ты детектив, что можешь сказать?»)
- Распознаёт текст и формулы, таблицы, переводит (20 языков), понимает структуру документов.
- Отлично понимает указатели и всё, на что вы тыкаете тем или иным образом.
- Понимает последовательности событий, разбирает видео, умеет строить временные связи между картинками и прогнозы.
- Собирает всякие головоломки типа танграмов и решает задачи на последовательности фигур.
- Определяет эмоции (что пугает в сочетании с анализом видео).
- Предсказывает, как картинка повлияет на аудиторию (самая объективно опасная способность).
- Находит различия, дефекты, оценивает повреждения
- Умеет делать разные задачи в реальной среде: догадываться, что за кнопки и для чего на разных машинах дома, сопоставлять инструкции из базы и станки, ориентироваться без полных данных.
- Хорошо браузит по неполным данным, может купить вам клавиатуру или заказать еду по запросу, причём сам разберётся, где и как это сделать.
Про математику надо пояснить отдельно. Кажется, это общий недостаток всех LLM, потому что они учатся по примерам с решениями и пытаются уловить какие-то ускользающие от нас закономерности, но не сами принципы арифметических операций. И даже если учить модели на детализированных сетах с арифметикой и пошаговым разбором примеров, получится не очень. Вот тут у нас чуть больше деталей про этот китайский опыт. Если что, мы с Milfgard собираем в том числе новости про LLM в этом канале. Называется «Ряды Фурье». Всегда хотел это сказать, вступайте в ряды Фурье!
UPD: и там же второй фломастер — робо-API к физическому миру.
А что касается тендеций LLM, кажется, нам всем хана.
Комментарии (53)



wifage
04.10.2023 07:04+3Ждем аналог в опенсорс и полосу пропускания в миллион токенов. Полгода?

freeExec
04.10.2023 07:04+1Всё ещё упирается в железо, где это крутить

enjoykaz Автор
04.10.2023 07:04+3Я не настоящий сварщик, но "крутить" экстра-больших требований нет.
Обучать - вот тут да.
DJSvist
04.10.2023 07:04+2Даже покрутить что-нибудь вменяемое нужна 4090, либо же вечно смотреть на генерацию на процессоре. Цена этих карт хоть и не сравнится с теслами, но все равно не массовый сегмент.

IvanPetrof
04.10.2023 07:04А никто ещё не организовал выпуск специализированных "асиков" для этой цели? Или видюшки тупо дешевле?

Kristaller486
04.10.2023 07:04+5Буквально на днях появилась LLaVA-RLHF, которая, по метрикам разработчиков достигает точности в 95,6% от GPT-4. А так, "мультимодальные" языковые модели уже давно существуют, просто распознавание картинок там сбоку приклеено, а в GPT-4 вроде как нет.
LLaVA-RLHF
enjoykaz Автор
04.10.2023 07:04Google Bard достаточно прикольно работает с картинками. Но до возможностей заявленных GPT-4v далеко.
Но работает и уже можно тыкать самому.

413x
04.10.2023 07:04+2Был бы еще гайд как её стартануть, для не особо продвинутых в этой теме. Звучит очень интересно.

TheRikipm
04.10.2023 07:04+5по метрикам разработчиков достигает точности в 95,6% от GPT-4
Я каждую неделю на r/LocalLLaMa вижу новые модели которые по метрикам разработчиков достигают точности в 100500% от GPT-4.

FreeNickname
04.10.2023 07:04Скажите, пожалуйста, а запускать её только "вручную" через код, как они тут пишут, или есть какие-то удобные решения с GUI "для чайников" вроде меня?



huaw
04.10.2023 07:04+1Это же уже можно считать AGI, разве нет?
ps. Может он прикалывается, что не умеет в арифметику? Возможности просто сверхчеловеческие o_O
IvanPetrof
04.10.2023 07:04+5Как говорится - "Я не боюсь компьютера, который пройдёт тест Тьюринга. Я боюсь компьютера, который его намеренно завалит."))

acc0unt
04.10.2023 07:04Одно ясно: это точно уже не классический однозадачный "narrow AI". Мы потихоньку перешли от "пара-тройка вжаренных в ИИ при обучении задач" к "вжаренная в ИИ при обучении модель мира и пара-тройка вжаренных модальностей". Эпоха "narrow AI" заканчивается, и чем дальше, тем больше "general" будет в наших "AI".
Как скоро мы дойдём до того, что ИИ сможет и достраивать собственную модель мира, и модальности впиливать в себя сам?
Вполне возможно отнести текущий GPT-4V в область "subhuman AGI". У него всё ещё есть много ограничений и много областей, где он уступает людям - но много и сильных сторон, где люди с ним просто неспособны соревноваться. Это не ужасающий сверхчеловеческий разум, про который часто думают при упоминании AGI. Но это точно шаг в том направлении.


JArik
04.10.2023 07:04+4Мы тут недавно в домино играли, и я свою гпт4 подписку и эту бету решил проверить. Сфоткал доминошки и попросил посчитать точки на них(count the dots on the domino), так он 420 насчитал, потом пытался исправиться и 290 выдал. А было всего 22 точки. Так что хз, с такими сложными вещами вроде справляется, а с элементарщиной не может.


sophist
04.10.2023 07:04+4А если ему объяснить, что понимается под точками? А то, может, он все пятнышки пересчитал?




sophist
04.10.2023 07:04+1
Ну, так ведь и напрашивается: "…on their heads" :)

andreishe
04.10.2023 07:04+6Переноска в руках - это «carry», а не «wear».
sophist
04.10.2023 07:04+1Для этого нужно знать, что каска в руках не выполняет своей функции.
Вообще, в подобных случаях возникает острое желание дообучить модель, передать ей свои знания. Говорят, диалоговый формат промптинга самый эффективный. Но всё наработанное качество утрачивается со сменой контекста.
Интересно, кто-нибудь работает в направлении создания модели, способной приобретать новые знания в процессе диалога?
Предвижу возражения, что человек в таком диалоге может сам ошибаться и даже намеренно вводить модель в заблуждение. Это значит, что такая модель должна будет различать знания, полученные от разных людей и оценивать их достоверность, сравнивая со своими априорными знаниями и друг с другом. Что-то вроде theory of mind.
А ещё такая модель начнёт сама задавать вопросы – как с уточняющей целью (в диалоге), так, вероятно, и по собственной инициативе (тут может пригодиться уже существующая концепция любопытства).
В общем, размечтался я что-то… :)

Moog_Prodigy
04.10.2023 07:04Подозреваю, что можно и так. Только маленькое "но" : обучение очень тяжелая задача для серверов. Вы вот подсказки модели набили в промпт, отправили, и теперь ждите пару месяцев, пока тысячи а100 прожуют ваш промпт и уложат его в нейронные связи. С такой скоростью это совершенно не эффективно и чудовищно дорого.



andreishe
04.10.2023 07:04+11Хорошее мультимодальное понимание ситуации:
Эээ… там же все мимо. Просто носорога, рисующий картинки с очень большой натяжкой можно назвать смешным. Вся суть в том, что он рисует и это полностью упущено.

SquareRootOfZero
04.10.2023 07:04+3Да, чего-то автор его перехвалил там — саму шутку, ради которой картинка нарисована, оно совершенно не вдуплило. Вдобавок, второй пункт ("the rhinoceros is painting a picture of itself") попросту фактически неверен.

Vsevo10d
04.10.2023 07:04Выше - комментаторы Хабра. Дай краткую характеристику каждому на основе его активности на ресурсе.



Apokalepsis
04.10.2023 07:04+1Я же правильно понимаю, что это только отчет и в живую потрогать нельзя?

AlexEx70
04.10.2023 07:04Можно, раскатили уже сегодня. Дейсвительно впечатляет, основа для робототехники очень неплохая уже, а это только первая версия.
acc0unt
04.10.2023 07:04Когда Илон Маск анонсировал в 2021 году Tesla Bot, над ним посмеивались. А теперь у нас чуть ли не в руках есть первые ИИ, способные "видеть" и "понимать" окружающий мир и решать простые проблемы в трёхмерном пространстве.
Именно в отсутствии подходящего ИИ была основная проблема таких гуманоидных роботов. "Железо" сделать можно было ещё 20 лет назад, но без "мозгов" оно было малополезно.
Вот и думай о том, что с этим всем будет дальше.


Dagnir
04.10.2023 07:04+6Жду момента, когда ему можно будет скармливать средневековые немецкие рукописные тексты и на выходе получать перевод на нужный язык. Историкам бы это облегчило работу очень знатно.


Dron007
04.10.2023 07:04Была новость, что используют для чтения всяких древностей, которых много ещё неразобранных.



Dron007
04.10.2023 07:04Мультимодальность это суперперспективная штука, ведь человек тоже не думает словами, в слова ухе потом формулируются какие-то внутренние ощущения, я бы их назвал теми самыми эмбеддингами. Думаю, это требования к будущему AGI: мыслить эмбеддингами и работать со всеми модальностями, постоянно обучаться, постоянно получать данные для формирования ощущения времени и самоосознания, иметь такие цели как любопытство, желание обучаться, иметь возможность активного получения информации - поиск в сети, подвижный робот с камерой. Самое сложное тут, по-моему, архитектура с постоянным обучением и не на миллионах примеров, а как-то более эффективно.

Vindicar
04.10.2023 07:04Очень напомнило суарезовский Kill Decision. Там одним из компонентов боевого дрона был алгоритм, в реальном времени преобразующий видео в текстовое описание событий, пригодное для последующего анализа...


RomanSkrypin
04.10.2023 07:04+1Благодаря популяризации AutoGPT, мне кажется обучение происходит с большим опережением графиков. Тонны распарсеного интернета льются в OpenAI.
Страшно то, что возможно из-за разных закручиваний гаек в виде запрета на обучение на своих работах и других юридических и технических преград, OpenAI вырастут до такого монополиста, что догонять придется десятилетиями. Они обучились пока никто не запрещал, а теперь уже каждый датасет достаётся кровью и потом.
Milfgard
Если что, enjoykaz — это человек, который в каждом промпте добавляет "пожалуйста". Без этой черты его образ не будет полным )
enjoykaz Автор
спасибо за камингаут
Gutt
MashkovIlya
О, а я думал я один такой. И вежливость и страховка на будущее :)
deseven
Была пару-тройку месяцев назад статья, в которой показывалась корреляция между вежливостью запросов и качеством результатов. Авторы предположили, что дело тут в данных, использованных для обучения - люди склонны давать более подробные и развернутые ответы там, где исходный вопрос задан вежливо.