
Существуют различные способы снижения стоимости выполнения SQL-запросов в современных СУБД. Наиболее распространенными подходами являются использование подготовленных запросов и кэширование. Оба метода доступны в YDB.
Кэширование запросов позволяет скомпилировать запрос один раз (проанализировать его, построить оптимальный план запроса, в т.ч. JIT-скомпилировать в машинный код), а затем повторно выполнить его с разными значениями параметров. Это позволяет сократить общее время выполнения запроса на величину времени компиляции запроса. Кроме того, кэширование запросов значительно сокращает объем вычислительных ресурсов, необходимых для выполнения повторяющихся пользовательских запросов, поскольку они компилируются только при первом запросе (и инвалидации кеша). Ниже мы объясняем, почему в самых общих случаях необходима Prepare, какие трудности возникают с этим в случае распределенной СУБД и как кэшировать запросы без Prepare.

Выражения с параметрами
На уроках алгебры в школе нас учили, как найти алгоритм для решения задачи с использованием переменных. Зная это, вы можете использовать разные входные значения для вычисления разных результатов. Алгебраическое решение позволило нам перестать тратить время на переосмысление решения одной и той же проблемы каждый раз, когда у нас появляется новый вариант ее использования.
Чтобы выполнить инструкцию SQL, серверу базы данных необходимо сначала скомпилировать ее, создав план выполнения запроса — серию вызовов внутренних функций, необходимых для выполнения инструкции. Как и любая компиляция, это требует времени и вычислительных ресурсов, а иногда требует доступа к дополнительным данным из базы данных, таким как статистика таблиц, чтобы понять, какой индекс лучше использовать.
Давайте взглянем на это выражение SQL:
SELECT name, age, grade FROM staff WHERE id=12345;Идея этого оператора состоит в том, чтобы получить сведения об одном человеке из таблицы базы данных ‘staff’. Поскольку в таблице ‘staff’ много записей, мы, вероятно, запустим много похожих запросов, которые в конце будут отличаться только числом. Для всех этих запросов в плане выполнения будут одни и те же шаги.
Чтобы сервер базы данных не тратил ресурсы на повторную компиляцию одного и того же плана выполнения, нам нужно переписать запрос таким образом, чтобы сервер мог определить, где находятся переменные.
Как правило, СУБД использования различных видов заполнителей для достижения, что, как :var1, ?, $1, $named_arg. Наш запрос будет выглядеть так:
SELECT name, age, grade FROM staff WHERE id=:var1;Наш запрос больше не содержит фактического значения id для поиска, но содержит ссылку на var1, которая подставляется отдельно через специальный интерфейс.
Использование операторов SQL с переменными помогает вам достичь целого ряда преимуществ:
Сокращение времени синтаксического разбора и нагрузки на железо СУБД.
Prepareявным образом вызывает компиляцию запроса, а последующиеExecuteна подготовленном запросе уже не требуют компиляции.Защита от SQL-инъекций. Вставка вредоносного SQL в качестве аргумента запроса просто не работает, потому что значение не анализируется.
Сокращение кода - меняются только аргументы запроса, но не сам запрос. Не требуется ручная конкатенация строки запроса.
Подготовленные запросы
Исторически у YDB не было другого способа использовать запросы с переменными и использовать кэш запросов, кроме как с помощью Prepare statements (их еще называют подготовленные запросы и связываемые переменные):
// в stmt сохраняется ссылка query_id скомпилированного запроса
stmt, _ := session.Prepare(ctx, `
DECLARE $id as Int32;
SELECT * FROM table WHERE id=$id;
`);
...
// многократно выполняем запрос по query_id
res, _ := stmt.Execute(ctx, table.NewQueryParameters(
table.ValueParam("$id", types.Int32Value(123456)),
)); Может показаться, что Prepare - это серебряная пуля.
Но что не так с Prepare?
Но Prepare statements также имеют некоторые недостатки, особенно актуальные для распределенных СУБД, таких как YDB. Очень важно понимать их жизненный цикл, и эта часть может быть специфичной для конкретной СУБД. Итак, в YDB:
Prepare statementsпорождаются на сессии и существуют, пока сессия "жива". В случае YDB сессия - это однопоточный актор в распределенной системе. Сессии могут быть инвалидированы в результате серверной балансировки или работ по обслуживанию на стороне YDB. И если сессия неожиданно может исчезнуть - значит и подготовленные на ней запросы (statements) также должны быть инвалидированы (удалены, "забыты", исключены для дальнейшего использования). То есть на пользователя ложится задача разобраться в кодах ошибок YDB и понять когда стоит инвалидировать свой statement, а когда нет. В частности, если в YDB приходит запрос с неизвестным query_id, то возвращается ошибка NotFound.Клиент не может полагаться, что
Prepare statementбудет валидный от старта приложения до завершения его работы. Если по каким-то причинам нода YDB или сессия на ней недоступны (сеть "моргнула", ведутся работы, произошла серверная балансировка сессий), то заранее подготовленныйPrepare statementнепригоден для выполнения запроса здесь и сейчас. То есть на пользователя YDB ложится задача подготовить запрос на другой сессии (и возможно другой ноде YDB).Также следует учитывать, что подготовив запрос через
Prepare, все последующиеExecuteпопадут на один и тот же узел YDB. Это означает, что, вероятно, может возникнуть перекос в нагрузке(некоторые узлы могут быть перегружены, в то время как некоторые могут простаивать).Во всех наших SDK реализована эффективная клиентская балансировка запросов, позволяющая выжать из пропускной способности кластера YDB максимум, а также обеспечивающая равномерность распределения нагрузки по нодам кластера за счет механизмов клиентской балансировки с учетом выставленных политик балансировки (см. пост в блоге о клиентской балансировке в YDB). В случае
Prepare statementклиентская балансировка не работает, потому что подготовленный запрос жестко привязан к сессии и узлу YDB
Также необходимо уметь инвалидировать на уровне клиентского кода подготовленные запросы в зависимости от кодов возвращаемых ошибок. И вообще этот микро-менеджмент statement'ов ложится на пользователя YDB, что усложняет его код и требует аккуратности и большей квалификации программиста. Легко допустить ошибку, сохранив для последующего использования "испорченный" подготовленный запрос. Кажется слишком сложным, не так ли?
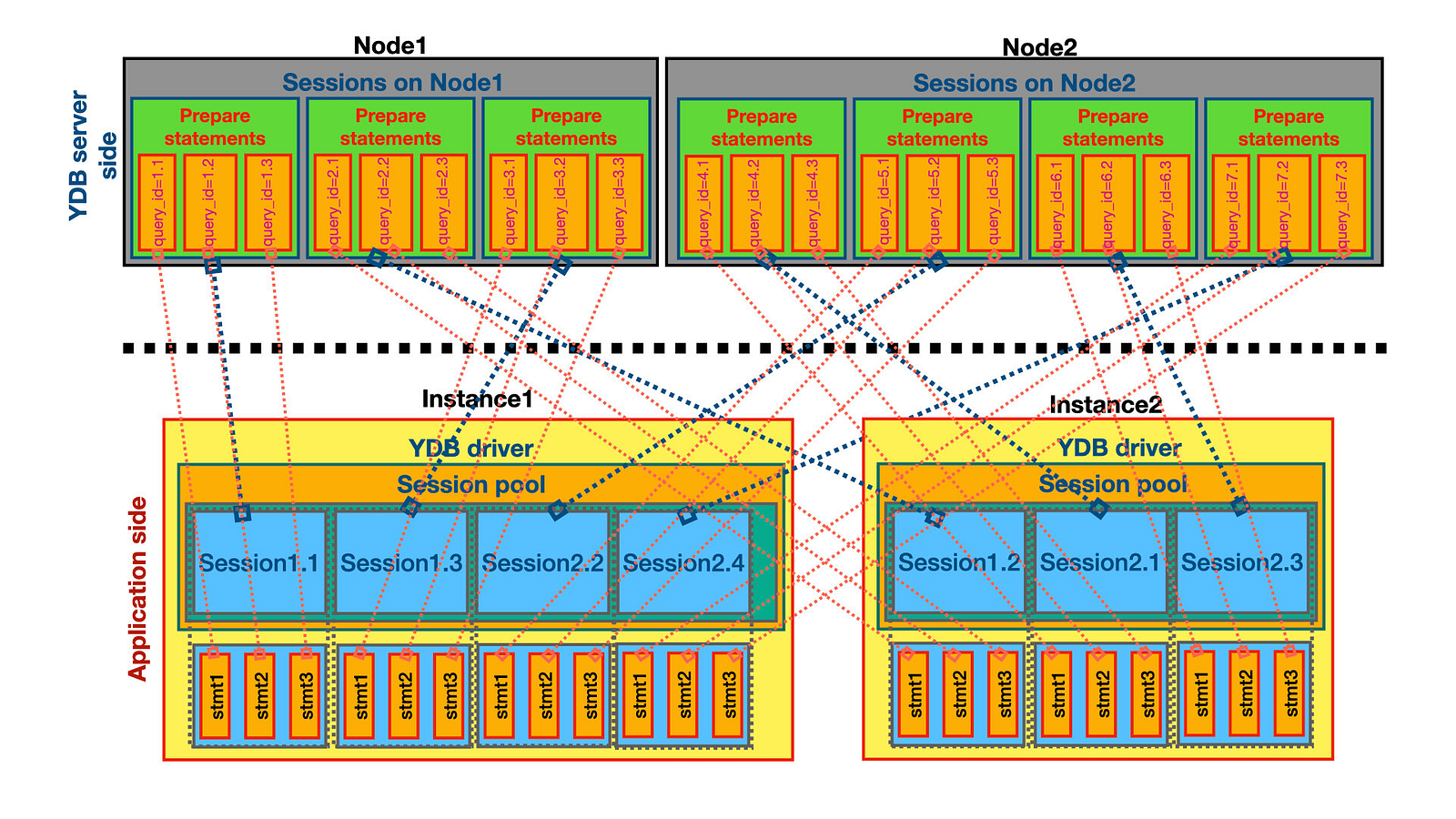
Опасно использовать Prepare statements , когда statement является внешней переменной относительно ретраера.
// Какой-то ретраер (из sdk или свой)
func queryRetry(stmt, args) (res, err) {
for i := 0; i < 10; i++ {
// stmt может быть инвалидирован на одной из прошлых попыток,
// а мы продолжаем на нем ретраить
res, err = stmt.Execute(args)
if err == nil {
return res, nil
}
}
return nil, err
}
...
// здесь кроется опасность - stmt сохранен для последующего использования
// и его статус никак не отслеживается
stmt := sessionPool.Get().Prepare(query)
...
err := queryRetry(stmt, args)Если Prepare вызывается внутри ретраера, то риск сохранить statement для последующего использования устраняется, но требуется лишний запрос на сервер в каждой итерации ретраера.
// Какой-то ретраер (из sdk или свой)
func queryRetry(sessionPool, query, args) (res, err) {
for i := 0; i < 10; i++ {
session := sessionPool.Get()
// если на сессии уже был подготовлен такой запрос, то это будет быстрый хоп.
// в противном случае будет честная компиляция запроса
stmt := session.Prepare(query)
res, err = stmt.Execute(args)
if err == nil {
return res, nil
}
}
return nil, err
}А как тогда эффективно кэшировать запросы?
На данный момент мы не рекомендуем использовать Prepare statements для кэширования запросов. У YDB есть более эффективный способ заставить запрос скомпилироваться один раз и выполнить несколько последующих запросов с использованием результатов компиляции. Мы предлагаем использовать параметризованный вызов Execute в сеансе с установленным флагом KeepInCache. В этом случае первый запрос к узлу YDB приводит к компиляции запроса, а результат компиляции кэшируется на узле YDB (на узле, а не в сеансе). В YDB кэш запросов (LRU cache) имеет ограничение по умолчанию 1000. Для большинства клиентских приложений этого ограничения достаточно.
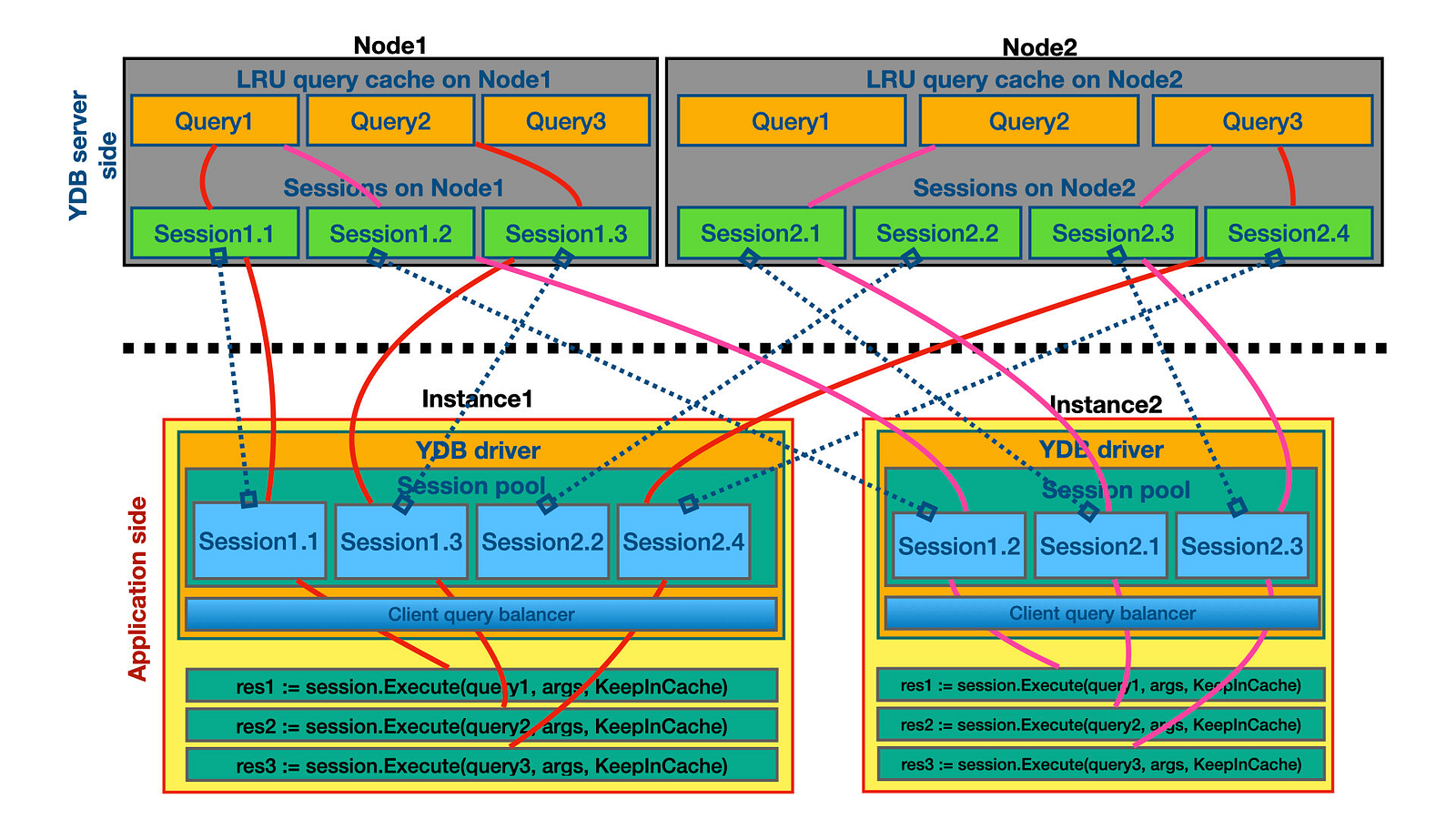
Мы можем упростить наш пример — заменить два последовательных вызова <Prepare+Execute> одним Execute с флагом KeepInCache:
with Prepare |
with KeepInCache |
|
|
С помощью Execute+KeepInCache мы получаем преимущества клиентской балансировки: запросы равномерно распределяются по узлам YDB и компилируются по первому Execute запросу на каждом новом узле, поэтому кэш запросов также дублируется на узлах YDB. И мы не беспокоимся о сложности обслуживания подготовленных запросов на стороне клиента с помощью распределенной СУБД.
У этого подхода, конечно, тоже есть недостатки. Если у вас много уникальных запросов, то есть риск инвалидации конкретных запросов в LRU-кэше на узле YDB. Например, это может происходить, когда клиентская программа автоматически интерполирует параметры запроса в текст запроса.
Строго говоря, кэширование запросов с помощью вызова Prepare помещает запрос в тот же самый LRU-кэш на узле с единственной разницей: доступ к этому кэшу осуществляется через query_id, который приходит в ответ на Prepare. И этот query_id становится недействительным вместе с сеансом.
В наших SDK мы стараемся иметь комфортное для пользователя и максимально ожидаемое поведение по-умолчанию. В том числе касательно серверного кэша. Ниже приведены примеры явного управления серверным кэшем скомпилированных запросов из наших SDK:
in ydb-go-sdk:
Флаг KeepInCache устанавливается автоматически (если передан хотя бы один аргумент запроса), чтобы явно отключить серверное кэширование запроса, мы можем передать опцию с Keepincache(false):
err = db.Table().Do(ctx, func(ctx context.Context, s table.Session) (err error) {
_, res, err = s.Execute(ctx, table.DefaultTxControl(), query,
table.NewQueryParameters(params...),
// uncomment if need to disable query caching
// options.WithKeepInCache(false),
)
return err
})in ydb-java-sdk:
Флаг KeepInCache по умолчанию установлен в значение true в объекте класса ExecuteDataQuerySettings. При необходимости флаг KeepInCache можно отключить:
CompletableFuture<Result<DataQueryResult>> result = session.executeDataQuery(
query,
txControl,
params,
new ExecuteDataQuerySettings()
// uncomment if need to disable query caching
// .disableQueryCache()
);in ydb-jdbc-driver:
Cерверное кеширование задается через параметр строки подключения &keepInQueryCache=true&alwaysPrepareDataQuery=false параметрами строки подключения JDBC.
in ydb-cpp-sdk:
Чтобы поместить запрос в кэш, используйте метод KeepInQueryCache объекта класса TExecDataQuerySettings.
NYdb::NTable::TExecDataQuerySettings execSettings;
// uncomment if need to disable query caching
// execSettings.KeepInQueryCache(true);
auto result = session.ExecuteDataQuery(
query, TTxControl::BeginTx().CommitTx(), execSettings
)in ydb-python-sdk:
Флаг KeepInCache устанавливается автоматически, если передается хотя бы один аргумент запроса. Это поведение нельзя переопределить. Если кэш запросов на стороне сервера не требуется, рекомендуется использовать Prepare явно.
in ydb-dotnet-sdk:
Флаг KeepInQueryCache по умолчанию установлен в значение true в объекте класса ExecuteDataQuerySettings. При необходимости флаг KeepInQueryCache можно отменить:
var response = await tableClient.SessionExec(async session =>
await session.ExecuteDataQuery(
query: query,
txControl: txControl,
settings: new ExecuteDataQuerySettings { KeepInQueryCache = false }
));in ydb-rs-sdk:
В Rust нет отдельного метода для компиляции запроса, серверный кэш также пока не используется, но будет.
in ydb-php-sdk:
Флаг keepInCache по умолчанию установлен в значение true в объекте класса query. При необходимости флаг keepInCache можно отменить:
$table->retryTransaction(function(Session $session){
$query = $session->newQuery($yql);
$query->parameters($params);
$query->keepInCache(false);
return $query->execute();
}, $idempotent);in ydb-nodejs-sdk:
4-й аргумент метода session.ExecuteQuery() является необязательным объектом настроек типа ExecuteQuerySettings, он имеет флаг keepInCache, по умолчанию он имеет значение false. Вы можете установить для него значение true следующим образом:
const settings = new ExecuteQuerySettings();
settings.withKeepInCache(true);
await session.executeQuery(..., settings);Заключение
Мы рекомендуем запускать параметризованные запросы с флагом KeepInCache для эффективного кэширования результатов компиляции запросов, чтобы повысить производительность выполнения запросов к YDB и снизить сложность кода и, следовательно, стоимость разработки и обслуживания конечного приложения. Важно отметить, что мы не отказываемся Prepare, это все еще продолжает работать. В статье дается только рекомендация о том, как использовать кэш запросов YDB более простым и надежным способом.
Если у вас возникнут какие-либо трудности или вопросы, пожалуйста, не стесняйтесь обращаться к нам через:
FanatPHP
Очень странная терминология. Обычно употребляют термин prepared statement, то есть "подготовленное выражение". А не "подготовка выражение", как это почему-то используется в статье. Если же имеется в виду сама команда prepare, то почему бы тогда так и не написать по-русски, "О команде Prepare, серверном кэше скомпилированных запросов или как эффективно кэшировать запросы в YDB"?