
Статья взята из источника Daily Dose of Data Science.
Оговорюсь сразу: Я новичок в Data Scince и в оформлении статей. Пишу лишь сюда для своих заметок ну и может быть будет кому-то полезно. Прошу сильно не судить!)
Случайный лес - это довольно мощная и надежная модель, представляющая собой комбинацию множества различных деревьев принятия решений.
Но самая большая проблема заключается в том, что всякий раз, когда мы используем случайный лес, мы всегда создаем гораздо больше базовых деревьев решений, чем требуется.
Конечно, это можно настроить с помощью гиперпараметров, но для этого требуется обучение множеству различных моделей случайных лесов, что занимает много .
И в этой статье делюсь одним из самых невероятных приемов, которые я недавно нашел для себя:
Повышаем точность модели случайного леса.
Уменьшаем размер модели RandomForestClassifier.
-
Коренным образом сокращаем время на предсказание.
И все это без необходимости повторного обучения модели.
Логика
Мы знаем, что модель случайного леса представляет собой совокупность множества различных деревьев принятия решений:
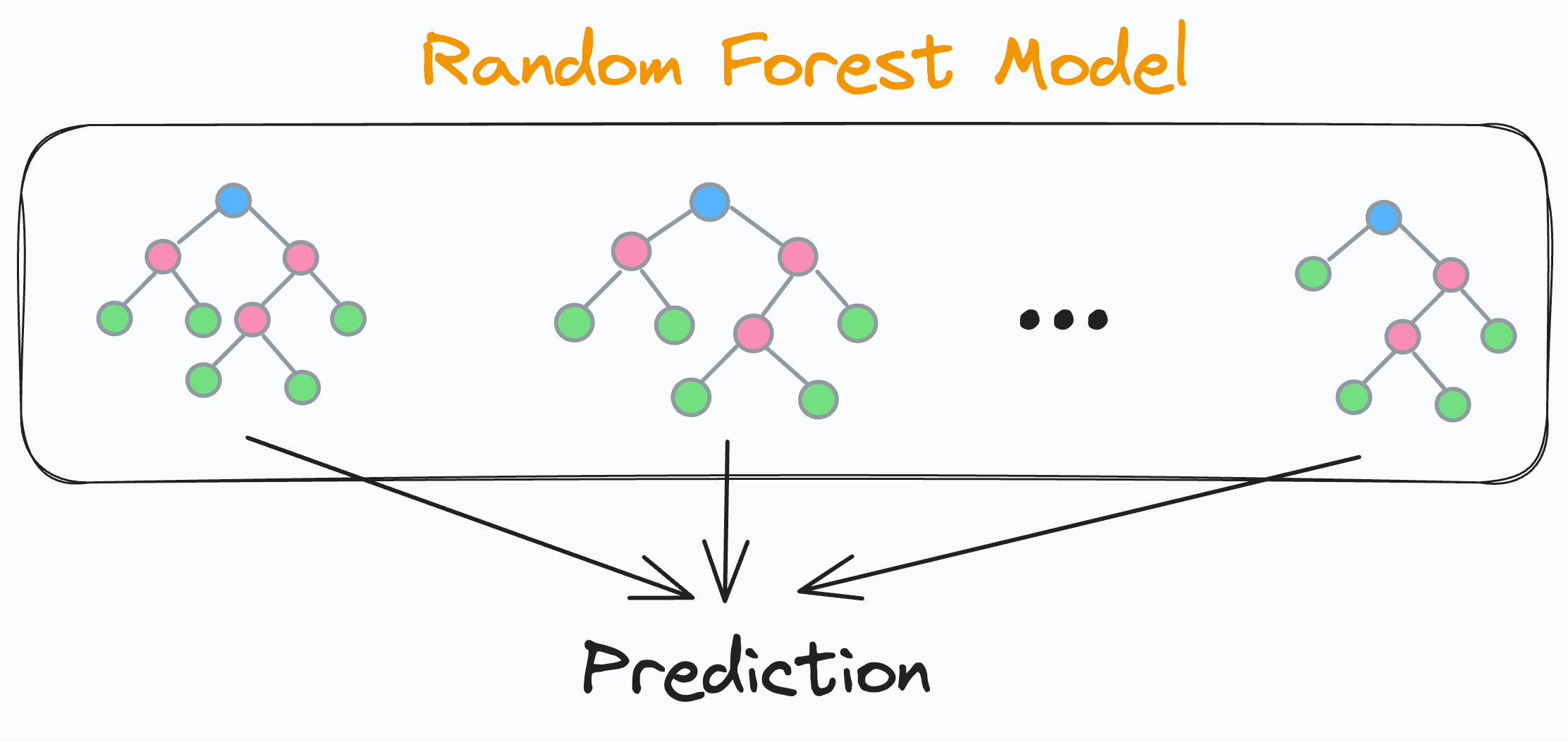
Финальное предсказание генерируется путем объединения предсказаний от каждого отдельного и независимого дерева решений. Поскольку каждое дерево решений в случайном лесу является независимым, это означает, что каждое дерево решений будет иметь свою собственную точность на тестовых данных, верно?
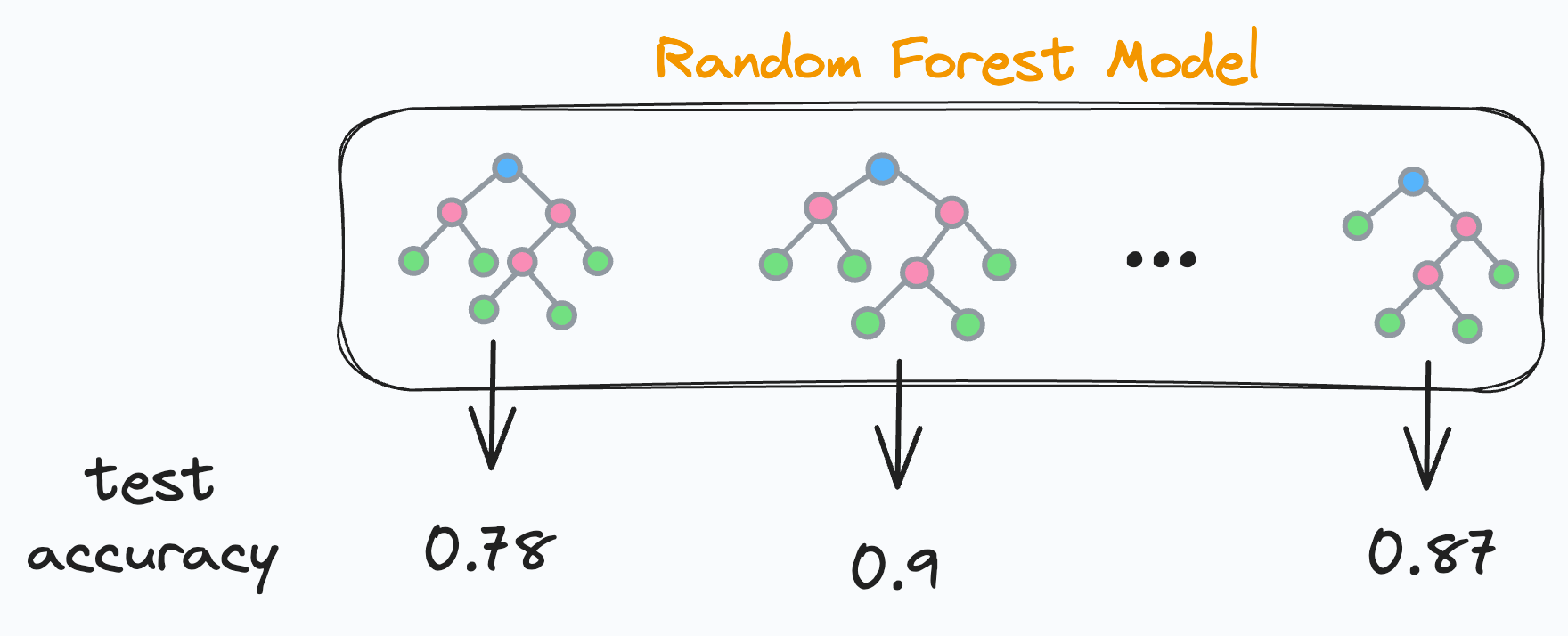
Но это также означает, некоторая часть деревьев решений показывают худшие результаты и часть лучшие результаты. Верно?
Итак, что если мы сделаем следующее:
Мы найдем точность на тестовых данных для каждого дерева решений.
Мы отсортируем точности в порядке убывания.
Мы оставим только «k» наилучших деревьев решений и удалим остальные.
После этого в нашем случайном лесу останутся только деревья решений с лучшими результатами, оцененными на тестовом наборе данных. Круто, не так ли?
Теперь, как определить “к” наилучших деревьев?
Это просто.
Мы можем построить график кумулятивной точности.
Это будет линейный график, отображающий точность случайного леса:
Рассматривая только первые два дерева решений.
Рассматривая только первые три дерева принятия решений.
Рассматривая только первые четыре дерева принятия решений.
И так далее.
Ожидается, что точность сначала будет увеличиваться с увеличением числа деревьев решений, а затем уменьшаться.
Глядя на этот график, мы можем найти наиболее оптимальное “k” деревьев решений.
Реализация
Давайте посмотрим на его реализацию.
Сначала мы тренируем наш случайный лес, как обычно:
Далее мы должны вычислить точность каждой модели дерева решений.
В sklearn доступ к отдельным деревьям можно получить с помощью атрибута model.estimators_.
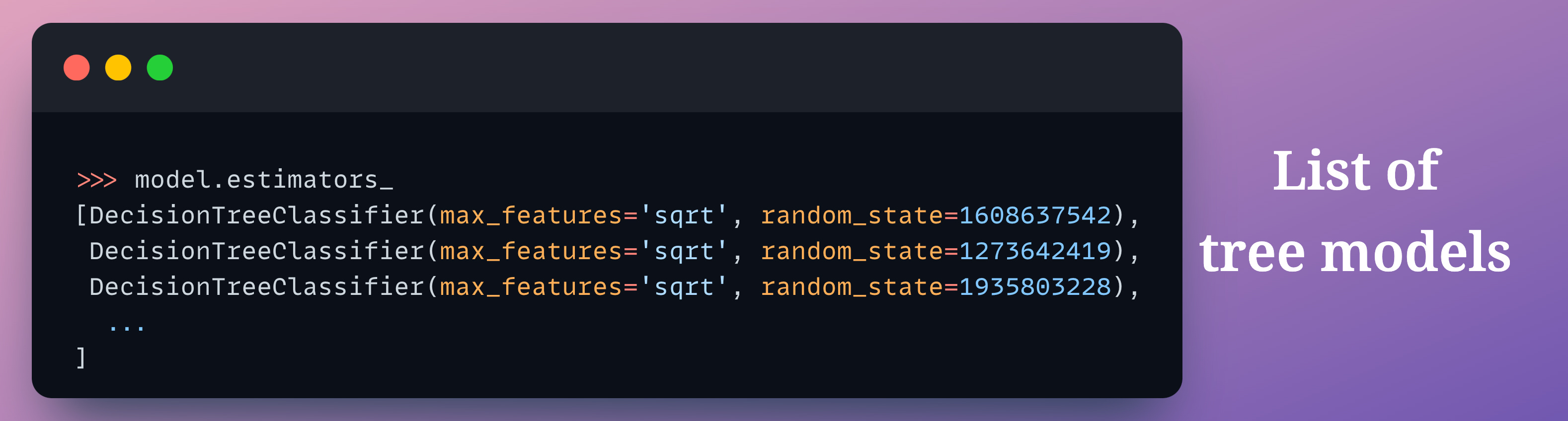
Таким образом, мы перебираем все деревья и вычисляем их точность тестирования:

model_accs - это массив NumPy, который хранит идентификатор дерева и его точность тестирования:
>>> model_accs
array([[ 0. , 0.815], # [tree id, test accuracy]
[ 1. , 0.77 ],
[ 2. , 0.795],
...Теперь мы должны переставить модели дерева решений в списке model.estimators_ в порядке убывания точности тестирования:
# sort on second column in reverse order to obtain sorting order
>>> sorted_indices = np.argsort(model_accs[:, 1])[::-1]
# obtain list of model ids according to sorted model accuracies
>>> model_ids = model_accs[sorted_indices][:,0].astype(int)
array([65, 97, 18, 24, 38, 11,...Этот список сообщает нам, что 65-я индексированная модель является самой производительной, за ней следует 97-я индексированная и так далее ....
Теперь давайте переставим модели деревьев в списке model.estimators_ в порядке model_ids:
# create numpy array, rearrange the models and convert back to list
model.estimators_ = np.array(model.estimators_)[model_ids].tolist()Сделано!
Наконец, мы создаем сюжет, о котором говорилось ранее.
Это будет линейный график, отображающий точность случайного леса:
Рассматривая только первые два дерева принятия решений.
Рассматривая только первые три дерева принятия решений.
Рассматривая только первые четыре дерева принятия решений.
и так далее.
Ниже показан код для вычисления совокупной точности:

В приведенном выше коде:
Мы создаем копию базовой модели с именем small_model.
На каждой итерации мы устанавливаем деревья small_model на первые “k” деревьев базовой модели.
Наконец, мы оцениваем small_model только с помощью “k” деревьев.
Построив график совокупного результата точности, мы получим следующий график:

На графике видно, что максимальная точность теста достигается при рассмотрении только 10 деревьев, что означает десятикратное сокращение количества деревьев.
Сравнивая их точность и время выполнения, мы получаем:

Мы получаем повышение точности на 3%.
время выполнения на предсказание в 6,5 раза быстрее.
Обратите внимание что:
Мы не проводили повторное обучение и подбор гиперпараметров
Отобрав наилучшие деревья мы сократили время на обучение
И это круто!
Вы можете скачать этот блокнот здесь: Jupyter Notebook.
На этом все! Спасибо за прочтение! Статья взята из источника Daily Dose of Data Science.
А какие есть еще решения? Пишите комментарии!
Комментарии (6)

mostodont32
16.10.2023 11:07+2Мне показалось или отбор моделей и замер качества проводятся на одном и том же датасете?
Вам стоит почитать что-то про множественное тестирование гипотез.

kkalmutskiy
16.10.2023 11:07Вся суть бэггинга в построении множества различных слабых классификаторов, не нужно потом отбирать лучшие классификаторы, которые, к тому же, являются лучшими только на тестовых данных.
Более того, это даже вредно для итогового ансамбля, потому что сильно увеличивается риск переобучения. И это не говоря о том, что нет никакого смысла ускорять Random Forest, работающий и так быстрее подавляющего большинства моделей.

andrej_ilin7 Автор
16.10.2023 11:07Друзья, спасибо за советы и ценное для меня ваше мнение. К сожалению в наше время слишком много разной информации и мне как новичку ее пока трудно отфильтровать. Мне показалось эта статья интересной и я решил ее перевести и опубликовать! Я обязательно обдумаю все и даже попробую разбирать на train, test и valid. И про решающие деревья я помню - вспоминаю эксперимент Френсиса Гальтона "Сколько весит бык" .

Angriff07
16.10.2023 11:07+1К сожалению, но ваш подход в корне не верный. Вы настраиваете гиперпараметры своей модели на тестовом множестве... То есть переобучаетесь...
Понятно, что так вы получите лучшие результаты. С таким же успехом можете оставить только 1 самую лучшую модель из ансамбля.
Предлагаю, для эксперимента сделать 2 тестовых датасета. На первом настроить параметры, как вы указали в статье... На втором только в самом конце посмотреть на метрики и сравнить... Вы удивитесь :)

Mirual
16.10.2023 11:07+1Вы можете попробовать сделать кросс-валидацию (хотя бы 80 на 20) на вашем датасете при обучении деревьев и для каждого фолда выбирать топ деревьев, по вашему критерию "лучших результатов". А в конце сравнить какие номера деревьев после 1 фолда были в топе, и после последнего. Если они совпадут, то возможно тут и подойдёт ваш метод.
zartdinov
Если правильно помню, то сильную модель можно получить на основе результатов слабых моделей, поэтому не был бы так категоричен отдавая приоритет только наиболее сильным из них.