
Компаниям нужно где-то хранить большое количество данных, но создавать собственные дата-центры — задача не из легких. На помощь приходит облачное хранилище у провайдеров. Он помогает сэкономить на собственной инфраструктуре и надежно хранить данные разных форматов. Достаточно выбрать подходящий тип хранения: блочный, файловый или объектный. О том, в чем между ними разница, рассказываем в статье. А также делимся инструкцией, как начать работу с объектным хранилищем.
Используйте навигацию, чтобы выбрать интересующий блок:
→ Введение
→ Преимущества облачных хранилищ
→ Для чего используется хранение в облаке
→ Типы облачных хранилищ
→ Заключение: главное преимущество облачного хранилища
Введение
Модель облачного хранилища похожа на «каршеринг СХД». Вместо вложений времени в организацию дата-центра, а позже в регулярное обслуживание, мы обращаемся в компании, у которых уже это есть — к поставщикам облачных хранилищ.
В дата-центрах стоят бесконечные серверные стойки с оборудованием, за которыми следят системы безопасности и профессиональные администраторы. Тем самым поставщик снимает заботы о безопасности информации с клиента.
В модели две стороны: клиент и поставщик услуги (провайдер). Клиент арендует место на серверах провайдера, сохраняет на них документы, приложения, статический контент сайтов, получая доступ к ним удаленно. Поставщик организует хранение, обслуживание, безопасность и доступ к данным. Эта модель имеет несколько преимуществ.
Преимущества облачных хранилищ
Экономия. Для собственной СХД понадобятся: помещение, стойки, серверы, охлаждение, оборудование для инфраструктуры. Потребуется организовать резервное копирование с покупкой ПО и дополнительных накопителей. А еще все это должны обслуживать администраторы, например, проводить периодические профилактические работы с отключениями и обновлениями.
В случае с облачным хранилищем большинство операционных расходов сокращаются, а капитальные отсутствуют.
Надежность. Облачные хранилища обслуживаются инженерами со специализированным опытом в эксплуатации систем такого типа. Администраторы провайдеров регулярно обновляют железо, улучшают ПО, работают над безопасностью.
При этом данные хранятся «с запасом»: для хранения 1 Гб данных клиента поставщик резервирует чаще всего многократно (в нашем облачном хранилище троекратно, то есть вместо 1 Гб резервируется 3 Гб).
Безопасность. Здесь два аспекта: физический доступ и безопасность передачи данных.
- Первый аспект обеспечивается тем, что обычно дата-центр — это режимное, круглосуточно охраняемое здание с видеонаблюдением, системами контроля и учета доступа. Внутри стоят системы охлаждения, пожаротушения и резервного питания, которые задублированы для надежности.
- Второй — настройками прав доступа учетных записей, мониторингом, шифрованием во время загрузки, чтении и хранении данных. Не считая дополнительных услуг поставщиков по защите.
Доступность. Данными можно управлять через графические интерфейсы, консоль или API.
Масштабирование. Объем быстро увеличивается за счет подключения дополнительных серверов и СХД. В физическом варианте это также быстро, но только если заранее позаботится о масштабировании. А еще будет дорого и «vendor lock-in». Это значит, что вы будете привязаны к поставщику (вендору) и его платформе, технологиям, ПО. Когда захотите сменить поставщика, придется строить все заново, потому что все железо и ПО завязано на вендоре.
Управление расходами. Платить нужно ровно столько, сколько потреблять ресурсов. В объектных хранилищах есть классы — стандартное и «холодное». Классы помогают управлять стоимостью хранения. Например, когда к данным нужно часто обращаться, можно платить дороже за хранение, но дешевле за трафик (обращения), Для архивов наоборот — можно платить за извлечение файлов дороже, но за хранение дешевле, потому что к ним редко обращаются.
Бизнес-процессы упрощаются, когда облачное хранилище доступно для сотрудника, например, из дома на выходных. А еще не забываем о восстановлении данных, когда бизнес-процессы не прерываются форс-мажорами из-за потери документов или репозитория.

Для чего используется хранение в облаке
- Для хранения массивных данных, например, видеозаписей с камер видеонаблюдения.
- В качестве репозиториев контента, например, публичных баз данных, школ дистанционного образования или мультимедиа ресурсов.
- Для хранения массивов данных Big Data, «Интернета вещей» и машинного обучения.
- Крупные СМИ интегрируют облака в цепочки поставки контента, например, для архивации или хранения для последующей аналитики.
- Для хранения данных игровых платформ, вроде Google Stadia.
- Видеохостинги или фотостоки используют хранилища для потоковой раздачи контента.
- В качестве хостинга интернет-магазинов, порталов, блогов и других статических сайтов.
- Для микросервисов: облачные хранилища поддерживают контейнеризацию, изоляцию процессов и совместный доступ.
Но чаще встречается пять сценариев:
Резервное копирование и восстановление. Большинство файловых систем облаков совместимы с базами данных, поэтому хранилища часто используют для резервирования, например, при обновлениях. Резервирование в облаке проще настроить, при этом надежность хранения данных лучше, потому что провайдер услуги распределяет копии по нескольким дата-центрам.
Разработка ПО и тестирование. Часто разработка требует дублирования сред, которые потом нужно удалять, и совместной работы. Использование облачных ресурсов для этого — стандартная практика среди разработчиков ПО. Также, облака интегрируются с разными приложениями без дополнительных «костылей».
Совместный доступ. Например, для команд разработки и тестирования из разных офисов или городов. Если данные хранятся на сервере внутри сети предприятия, часто нужен VPN. Но можно обойтись без этого и перенести часть общих файлов, к которым обычно и нужен доступ, в облачное хранилище.
Миграция данных в облако облегчает обслуживание своей инфраструктуры, но это серьезная задача, требующего многолетнего опыта у системного администратора. Однако есть сервисы, облегчающие этот процесс.
Big Data и IoT. Например, для Big Data массив данных в 100 Терабайт не так уж много, но держать на локальных серверах такой объем дорого, поэтому для этого часто используют облака. Хранить в облаке массивы удобно: в облачных сервисах обычно высокая пропускная способность, низкие задержки, и возможность настроить запросы не извлекая данные.
Типы облачных хранилищ
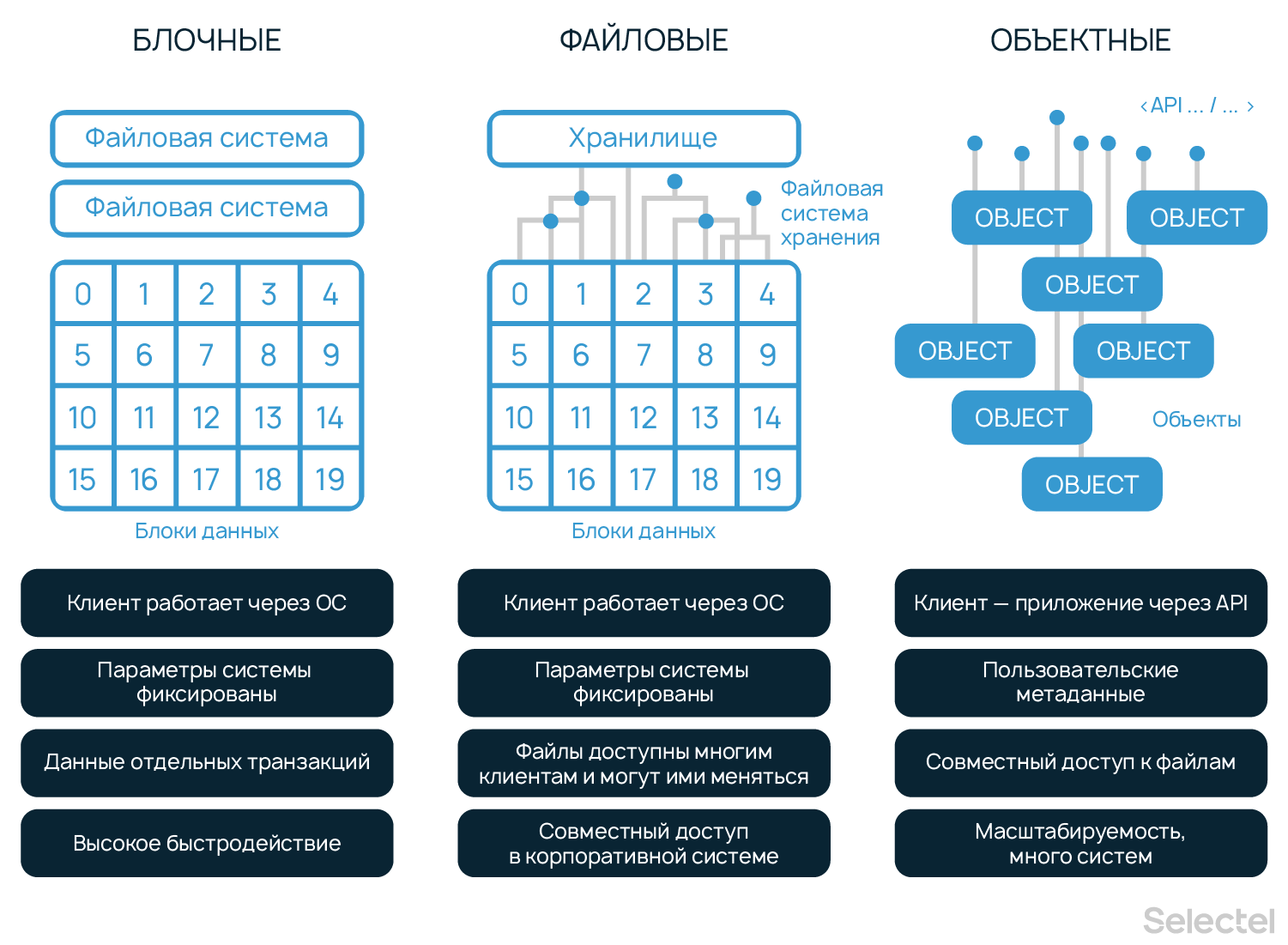
Хранить массив данных для Big Data и архив корпоративных документов вместе нецелесообразно. Под каждую задачу требуется свой тип облачного хранения: объектное, блочное или файловое.
Блочное хранилище

В этом типе файлы делятся на одинаковые части — блоки (chunk). У каждого блока есть свой идентификатор (location ID), по которому система хранения быстро собирает блоки обратно в файлы.
Преимущества. У блочных хранилищ данные пользовательские среды разделены. Это позволяет распределять данные по нескольким средам и давать к ним отдельные доступы.
Низкие задержки. Все ОС видят блочные СХД как диски и могут подключаться к ним через Fiber Channel или iSCSI.
Как используют. Часто интегрируют с корпоративными базами данных. Например, Oracle используют блочные системы.
- Когда скорость ввода-вывода (IO) данных и низкая задержка (через SAN), критичны.
- Когда заранее неизвестен объем данных. Вместо жесткого диска к серверу подключают блочное хранилище, чтобы СУБД писала данные на него. Когда заканчивается место — докупается еще и сервер БД увеличивает емкость без переездов и настроек.
Недостатки. Отсутствие метаданных ограничивает управление данными. Дополнительная информация о блоках нагружает базу данных. Даже без этого настройка блочного хранилища создает дополнительную работу: выбор файловой системы, разрешения, управление версиями, резервное копирование.
Также этот тип один из самых дорогих, потому что нужно платить за все выделенное пространство, даже если оно пустует.
Файловое хранилище

Организация хранения в файловых хранилищах знакома:
- информация хранится в файлах;
- файлы в папках;
- а папки объединены в подкаталоги и каталоги.
Хранение организовано иерархически. Чтобы найти файл, нужно знать полный путь: к каталогу, подкаталогу, папке и к файлу. К файловому хранилищу могут иметь доступ как серверы, так и ПК.
Преимущества. Данные организованы в иерархическое дерево каталогов, как в других ОС, например, в Windows, и работа с файлами интуитивно понятна. Файлы в облако загружают через веб-интерфейс или отдельную локальную папку.
Как используют. Для совместной (и одновременной) работы, потому что:
- легко ориентироваться;
- администратор может настроить доступ и права доступа к файлам и деревьям.
Системы хранения файлов подходят для больших объемов структурированных данных. Например, для компаний, которые разрабатывают ПО или анализируют данные, когда требуется, чтобы несколько серверов одновременно получали доступ и изменяли несколько файлов.
Недостатки. Такой тип хранения плохо масштабируется. С ростом объема данных, иерархия и разрешения усложняются настолько, что мешают ориентироваться и замедляется работа самой системы. Поэтому такой тип редко используют в дата-центрах.
Объектное хранилище
Относительно новый и универсальный способ хранения данных. Подходит для любых данных: логи, бухгалтерская отчетность, фильмы, презентации, фотографии, программы или статические сайты.
Универсальность достигается за счет того, что файлы хранятся как объекты с набором свойств. Свойства хранят идентификатор и метаданные:
- Идентификатор (один) — 128-битное число. Обычно называется универсально (UUID) или глобально (GUID) уникальным идентификатором.
- Метаданные: имя, координаты, размер, имя автора и другая информация для идентификации объекта.
Преимущества. Благодаря идентификаторам структура плоская — нет иерархии, что позволяет масштабироваться до сотен Петабайт. При этом метаданные можно настроить под конкретные требования приложения: уточнить, переписать, расширить.
К данным удобно обращаться приложениям — поддерживается параллельный доступ через разные протоколы, а также API. Все это достаточно безопасно — у современных объектных хранилищ высокий уровень надежности и низкая удельная стоимость хранения.
Как используют:
- Для хранения больших наборов данных, например, резервных логов.
- Для бэкапов, архивирования, например, видеозаписей видеопродакшн-студии за 10 лет.
- Для хранения и раздачи контента мобильных и веб-приложений: изображений, образов, обновлений ПО. Например, в объектных хранилищах с поддержкой S3 можно использовать плагины, расширения и библиотеки и CDN для ускорения раздачи обновлений.
- E-commerce, чтобы хранить статический контент интернет-магазинов, например.
Недостатки. 128-битный идентификатор добавляет сложности с именованием объектов. Например, поэтому существует Digital Asset Managers (DAM), как ПО, которое накладывает организационную схему поверх хранилища объектов. Такое дополнительное ПО придется использовать для компаний, что производят, например, видеоконтент.
Другой недостаток — нельзя записать файл в объектное хранилище, перетащив из папки в папку. Для взаимодействия используется программный интерфейс — API. Но у некоторых облачных провайдеров, кроме API, реализованы графические интерфейсы для загрузки и управления (перетаскивания) файлами. Например, в Selectel есть панель OpenStack Swift, которая устраняет этот недостаток. Рассмотрим, как это работает.
В панели управления объединили проекты Облачной платформы и Объектного хранилища. Чтобы начать использовать контейнеры, перенесите их в проект. Подробнее — в документации.
После регистрации и подтверждения почты, зайдем в личный кабинет. Дальше в раздел Объектное хранилище — Контейнеры.

Без группировки трудно управлять большим количеством объектов. Один из способов обойти это ограничение — контейнеры. Они логично связываются, например, с отдельным проектом. Создаем контейнер.

Выбираем тип, класс хранения и добавляем название. Контейнер видно на вкладке Объектное хранилище в Контейнеры.

Чтобы добавить файлы, нажимаем на название контейнера. Добавляем файл — Выберите файлы… (также можно перетащить). На вкладке показываются загруженные файлы. Ограничений объема у них нет, но этот параметр, как и другие, можно указать в настройках контейнера.

Кроме панели, с файлами возможно работать, например, через S3cmd — интерфейс командной строки для работы с сервисами, поддерживающими HTTP API Amazon S3. Инструкции, как установить S3cmd и загружать файлы, подробнее описаны в базе знаний.
Заключение: главное преимущество облачного хранилища
Это снижение операционных расходов. «Самодельные» решения (и дешевые, и дорогие), нужно администрировать, бэкапить, обновлять, когда выходят уязвимости. Это отдельная работа, которой должен заниматься отдельный человек. Содержать для этого системного администратора в долгосрочной перспективе, иногда выходит дороже, чем единоразово купить все оборудование (капитальные затраты) для хранения. Облако — альтернатива собственным СХД для хранения в корпоративной системе, которое снимает большой пласт проблем и операционных расходов.
Готовы показать свои знания в IT? Примите участие в IT-кроссворде Selectel, выиграйте 10 000 рублей на аренду серверов и эксклюзивный мерч Selectel.
Интересные материалы по теме
Комментарии (9)

kkuznetzov
03.11.2023 13:14+2Главное что бы облако находилось в отдельном здании от бэкапа. На случай пожара.
adeshere
А можно ли здесь вместо обсуждения статьи задать вопрос про выбор облачного хранилища? Дело в том, что мы начали использовать для определенных задач Яндекс-диск, но он не обеспечивает некоторые наши потребности (впрочем, не факт, что их вообще можно обеспечить каким-то "дешевым" способом). Чтобы не мешать обсуждению статьи (если такой вопрос тут все же офтопик)
сам длинный-предлинный вопрос убран под кат
Ситуация следующая. У нас есть самодельная программа, работающая с временными рядами. Она была написана очень давно, и в силу исторических причин представляет собой конгломерат из
СУБД временных рядов и пакета процедур анализа рядов данных, обернутых в проблемно-ориентированный интерфейс
Если интересны подробности, ТЗ можно найти здесь, а описание самой программы - вот здесь (а полные тексты этих статей выложены вот тут). А саму программу можно скачать вот здесь: exe-шники и исходники.
Причем, кардинально в ней что-то менять у нас нет ни возможности, ни потребности, так как со своими функциями система справляется, а реализовать их на базе какой-то современной среды не так-то просто ввиду очень большого количества специфических опций. Да и не факт, что эта среда не вымрет через несколько лет, и нам не придется все заново переписывать. А фортран, хотя и неудобен в некоторых отношениях, но весьма эффективен в вычислительном плане и, по сравнению с большинством других сред, практически вечен ;-)
Изначально встроенная СУБД временных рядов была однопользовательской, так как все работало на самых первых персональных компьютерах, а о таких штуках, как будущий интернет, большинство советских программистов попросту еще не догадывалось (хотя сеть NSFNet в тот момент уже появилась).
Спустя некоторое время в наших институтах появились локальные сети. После чего авторы программы с удивлением обнаружили, что эту нашу персональную базу данных можно записать на один компьютер, а подключаться к ней совсем из другого места. Так как с точки зрения программы, она просто открывает файл на каком-то диске, и при этом совершенно не важно - локальный он или же сетевой.
Чтобы предотвратить конфликты, в БД был добавлен флаг "база занята", который проверяется/устанавливается при подключении юзера и снимается при его отключении. Сама база при этом по сути осталась однопользовательской, но работе это совсем не мешало, так как из-за специфики задач количество пользователей у каждой БД не превышало (и не превышает) нескольких человек, а непосредственный доступ к базе им нужен достаточно редко: только при обновлении/модификации данных либо при их загрузке в личное рабочее пространство (где и идут все расчеты).
Однако жизнь - штука непредсказуемая. И спустя еще какое-то время в дополнение к локальным сетям появились облачные сервисы. После чего авторы программы с удивлением обнаружили, что если эту персональную базу данных записать на Я-диск, то подключаться к ней можно будет с
любого компьютера в мире
Например, я живу в Подмосковье, и использую некоторые БД совместно с коллегами на Камчатке.
Так как с точки зрения программы, она просто открывает файл на каком-то диске, и при этом совершенно не важно - локальный он или же облачный.
И все было бы хорошо, если бы
бензопила в этот момент не сказала "КРЯК"не задержки синхронизации. Де-факто во время работы с "облаком" программа открывает не файл в облачном хранилище Я-диска, а его локальную копию. Которая можетобновляться с задержкой
Флаг, естественно, ставится не в файлах с данными, а в специальном заголовочном файле небольшого размера. Обычно там 10-20Кб. Т.е. он вроде бы должен синхронизироваться мгновенно. Но по факту иногда это может занимать даже не секунды, а чуть ли не минуту. Делать такую паузу при каждом подключении к БД невозможно: это уже не работа...
Поэтому вполне возможна ситуация, когда два юзера на своих компах открывают свою локальную копию базы одновременно. А в ней факт подключения второго юзера еще не отражен (флаг "занято" не установлен). После чего начинается синхронизация... облако обнаруживает, что файл изменен двумя клиентами сразу, в результате у каждого из них появляются сразу две версии открытого файла с пометкой (1), (2) и т.д.
Да, наша программа это почти сразу же замечает и спрашивает "Парни, че делать-то будем?". Даже пытается как-то этот конфликт разрешить. Но это борьба со следствиями, а не с причинами.
На самом деле, все, что мне нужно - это возможность задать вопрос облаку:
А не идет ли в данный момент синхронизация вот этого файла с каким-то другим юзером?
После чего я готов подождать ровно столько времени, сколько нужно облачному хранилищу для проверки этого факта. То есть, при получении моего запроса облако должно проставить у облачной (а не моей локальной) копии файла ключ блокировки (если он еще не стоит), а затем вернуть мне ответ: файл твой, работай!
Как правило, связь хорошая, поэтому есть надежда, что облако ответит быстро (незаметно для юзера). Если же со связью проблемы, то можно и подождать - это лучше, чем разбираться потом с дубликатами файла.
Да, в этом случае остается вопрос про компы, которые не в сети, или где синхронизация с облаком временно выключена. Там ведь никто (кроме моей программы) не может запретить юзеру редактировать тот же файл в автономном режиме. Но это уже будет не проблема облака, а моя.
Но насколько я понял, сейчас задать такой вопрос облаку Я-диска нельзя.
Или все-таки можно?
Или для этого нужны другие сервисы, а не Яндекс-диск?
Для меня тут критично, что с точки зрения моей программы,
она должна просто открывать файл
точно так же, как если бы он лежал на локальном диске. Чтобы не делать какую-то особую систему для работы с облачными БД, а просто работать со всеми базами через одинаковый интерфейс. Я же основную часть времени не программированием занимаюсь, а работаю с данными. Поэтому на поддержку и развитие программы ресурс времени ограничен...
Или я вообще какую-то ерунду спрашиваю, и на самом деле все делается совсем по-другому? Честно скажу, что я с многопользовательскими СУБД никогда не работал. Вполне возможно, что я поэтому в каких-то азбучных истинах плаваю, и вообще мне хочется странного...
Буду благодарен за любые советы. Даже если в моей ситуации реализовать их заведомо нереально, то хотя бы пойму, что к чему...
darkxanter
Можете попробовать подключить сетевой диск по протоколу WebDAV, но Яндекс как-то ограничил этот протокол и возможно с Яндекс-диском не получится. Как альтернативу можете сделать собственный сервер с Nextcloud который поддерживает WebDAV.
adeshere
...попробовать подключить сетевой диск по протоколу WebDAV
Спасибо за наводку! Но к сожалению, я никогда про такой протокол не слышал, и вообще с сетями "на Вы". Поэтому из беглого чтения вики и еще пары сайтов не смог понять, как это может работать на практике. Мы ведь не работаем с облачными файлами через браузер. Никто не копирует файлы вручную в облако и обратно. Удобство работы заключается именно в том, что слой интерфейса к облачному хранилищу полностью прозрачен как для прикладной программы, так и для юзера.
Для нас это выглядит так:
- на локальном компе установлен клиент Я-диска. Он создает на локальном компе точную копию облачной папки с данными.
- прикладная программа фактически и работает с этой локальной папкой (= копией облачной папки). Для программы-клиента эта папка ничем не отличается от других папок на компьютере. Для нее это просто обычные файлы.
- Я-клиент "на лету" синхронизирует локальные файлы с облаком
А как на практике может выглядеть использование протокола WebDAV в этой схеме?
В идеале, я бы хотел послать Я-диску запрос на блокировку облачного файла (локальную копию которого открывает прикладная программа) перед его открытием, и запрос на разблокировку после того, как работа с файлом и его синхронизация закончена.
Но я подозреваю, что исполнение такого запроса - это все равно компетенция облака. Ведь ему одновременно надо проверять статус синхронизации файла?
Я правильно понял, что Я-диск умеет выполнять такие запросы, но обычный яндекс-клиент не поддерживает их отправку? И что поэтому нужно установить какой-то альтернативный клиент (надстройку над Я-клиентом?), который будет работать с облачным хранилищем Я-диска по протоколу WebDAV?
darkxanter
В диалоге подключения сетевого диска указываете
https://webdav.yandex.ruСкриншот
Далее будет запрос логина и пароля, в качестве пароля надо будет использовать "пароль приложения", он создается в разделе безопасности с типом "WebDav Файлы".
В итоге вы получаете сетевой диск средствами системы. В этом случае по идее изменения сразу должны будут сохраняться на сетевой диск.
acyp
Сталкивался в своей деятельности с WebDav от Яндекса.
Могли и поменять, но тогда этот интерфейс внезапно стал платным, доступным только на коммерчесских тарифах с совершенно непонятной моделью оплаты. Думаю сейчас, с появлением Яндекс360 это устаканилось в понятные расценки, но это только предположение. Не проверял, но отказались даже не поэтому, а п.2
Многие программы, имеющие конрни из 90х и ранее в упор не видят веб-диски, в т.ч. от яндекса. Т.е. надо перепиливать клиента в современные реалии. Но если я правильно понял @adeshere, то у них эдакий монолит из прошлого без разделения на клиентскую и серверную части, что и вызывает огневой эпизод.
foxb
Если исходные файлы централизованы и не обновляются пользователями, вы можете использовать простой веб-хостинг для хранения файлов.
Если ваши файлы обновляются пользователями, можно использовать какой-то вид системы контроля версий (например, git).
adeshere
Если ваши файлы обновляются пользователями, можно использовать какой-то вид системы контроля версий (например, git).
Файлы обновляются при каждом сеансе работы. Контроль версий не поможет, так как задача в том, чтобы вообще избежать проблемы слияния веток (когда файл правили два пользователя сразу, и затем надо сохранить и те, и другие правки. А они могут быть взаимоисключающими).
В общем, нужен не контроль версий, а гарантия поочередного доступа к файлу.
unclegluk
Все изначально неправильно сделано, но учитывая ограничения того времени, вариантов не было. Все это надо переделать, причем вчера. Да, оно вымрет и придется переписывать. Лучше уже сейчас начать.