
В этой статье я расскажу вам о том, как мы в Ozon оптимизируем базовый поиск: как у нас выстроены процессы, как найти бутылочное горлышко, конкретные рекомендации по написанию горячего кода, реальные примеры значимых оптимизаций и что делать, когда все низко висящие фрукты уже сорваны, а хочется ещё.

Из статьи Сергея Саияна вы можете узнать, что мы в Ozon написали на Java свой поисковый движок на базе Apache Lucene, который пришёл на смену Elasticsearch пару лет назад и используется для обработки пользовательских запросов.
После перехода тайминги поиска упали в три раза. С тех пор мы его ещё существенно оптимизировали, но, к сожалению, можно только гадать, насколько бы он обогнал Elasticsearch сегодня.
Секрет успеха состоит из аккуратного сбора требований, выбора правильной архитектуры, хорошего дизайна, а также в более рутинном процессе оптимизации уже написанного кода. Именно последней теме и посвящена эта статья. Я не буду касаться части системы по сборке и репликации индексов Apache Lucene, так как там другая модель вычислений.
Ключевая идея заключается в том, что мы относимся к производительности как к культурному процессу: расширяем своё понимание и фиксируем результаты в текстах. Как любой эффективный культурный процесс это не только помогает распространять знания внутри команды, но и погружать в контекст новых коллег.
Если новый человек в команде хочет узнать, какая у нас модель вычислений — какие есть стадии обработки запроса, какие ресурсы как потребляются — у нас есть статья об этом. Если новый человек хочет узнать, как лучше писать горячий код — есть статья об этом.
Если новый человек хочет провести нагрузочное тестирование — есть статья об этом.
Если новый человек хочет узнать, почему мы, например, форкнули запрос KnnVectorQuery — есть статья об этом.
Порой люди ленятся фиксировать в статьях полученную информацию, думая, что крутые инженеры и так всё понимают про производительность. И безусловно, вся наша команда состоит из крутых инженеров — и именно поэтому мы фиксируем в статьях не банальности, а действительно интересные результаты.
Сперва я расскажу о том, как мы оформляем задачи на оптимизацию.
Затем — где и как искать узкие места, которые выгодно оптимизировать.
Потом расскажу, как надо писать горячий код и делать микрооптимизации.
И, наконец, что делать, когда ваш код уже работает очень быстро, а упёрлись вы в чужой.
Задача оптимизации как научный эксперимент
Все нетривиальные оптимизации мы стараемся оформлять подобно лабораторным работам по физике.
Гипотезы и метрики
Результатом любого физического эксперимента являются наблюдаемые измеримые величины — в нашем случае это метрики. Без них любая оптимизация превращается в гадание на кофейной гуще.
Перед началом перформанс-тестирования необходимо понять, какие метрики вы хотите улучшить, и сформулировать ряд гипотез о том, как на них повлияют изменения, которые вы планируете реализовать сделать.
Примеры:
Гипотеза: этот метод можно оптимизировать на 10%.
Метрика: доля в CPU-профиле.
или
Гипотеза: в этом методе можно уменьшить аллокации.
Метрики: отчёт профайлера и GC-логи.
или
Гипотеза: эта настройка GC должна уменьшить паузы.
Метрика: GC-логи.
или
Гипотеза: можно уменьшить время считывания файлов с диска.
Метрика: время считывания файлов с диска :)
Если вы хотите оптимизировать код, поведение которого пока не наблюдаемо, вам необходимо сперва навесить на него метрики.
Гипотезы для оптимизации обычно возникают при изучении приложения: его запросов, профилей, разнообразных метрик и, конечно, кода.
Не забудьте оценить сверху, сколько удастся выиграть в случае подтверждения гипотезы, чтобы не экономить на спичках.
Метрики latency
При выборе гипотез надо понимать, что большинство метрик, которые легко собирать, связаны с throughput — это самые «жирные» части на профиле и других усреднённых метриках, а всё, что касается latency, требует целенаправленных действий с вашей стороны.
Например, у вас сильно тормозят специфические запросы, но таких запросов около 1%; таким образом, специфический для этих запросов код на профиле будет заведомо меньше 1%, то есть он практически незаметен — однако его оптимизация срежет тайминги в p99.
Или представьте, что у вас есть какое-то вычисление, которое состоит из двух последовательных операций: А и Б. Для простоты будем считать, что это CPU-bound-задача и синхронизация между потоками пренебрежимо мала.
У вас на руках есть три факта:
1. Сперва до конца исполняется операция А, и только потом — операция Б.
2. Операция А исполняется параллельно в 16 потоков, а операция Б — в один поток.
3. Вы открываете профайлер и видите там, что операция А потребляет 94% CPU, а операция Б — 6% CPU.
Внимание, вопрос: следует ли из этого, что вам надо оптимизировать операцию А, а не операцию Б?
Представьте, что операция А занимает 100 мс и операция Б занимает 100 мс. Очевидно, что их вклад в latency одинаковый. При этом в каждый момент времени профайлер видит, что на 16 потоков, занятых операцией А, есть только один поток, занятый операцией Б. Ну а 16/(16+1)*100% как раз получается 94%.
То есть, хотя для увеличения throughput операция А важнее, но при оптимизации latency они уже одинаково важны. При этом однопоточные вычисления обычно проще оптимизировать, чем многопоточные, так что операция Б оказывается в приоритете.
Отчёт
Из готового отчёта должно быть видно:
1. Отсутствие общей деградации.
2. Наличие эффекта от оптимизации на метриках: подтверждение гипотезы или её опровержение.
Ваша правка может нетривиально повлиять на поведение системы в целом — и важно удостовериться, что, оптимизировав одни кейсы, вы случайно не испортили другие. Поскольку невозможно проверить всё, надо хотя бы проверить общие метрики. Показания стрельб помогают понять, нет ли явной деградации. При этом, если есть подозрения о возможной деградации в конкретных местах, их, конечно, стоит проверить отдельно. Скажем, если вы где-то разменяли вычисления на память, есть риск, что эффект оптимизации будет нивелирован более частыми сборками мусора.
Как я писал выше, нетривиальные результаты следует фиксировать. А поскольку неудачные оптимизации обманывают наши ожидания, они по определению приводят к таким результатам и про них всегда надо писать отчёты. Так, в момент написания этого текста мне нужно написать отчёт об оптимизации, которая прекрасно работала на микробенчмарке, но вообще ничего не дала на стрельбах из-за особенности распределения данных.
Если общая производительность не просела, то надо удостовериться, что оптимизация действительно случилась. Это может быть совсем не просто: нужны достаточно чувствительные метрики.
Например, вы с помощью профайлера выяснили, что какой-то горячий метод потребляет 5% CPU, — и у вас возникла идея, как его оптимизировать. Возможно, плохая идея, а возможно, хорошая. Допустим, вы его оптимизируете на 10%. Это очень хорошо, но это будет 0,5% от всего CPU, на графиках вы такого изменения не увидите — они слишком шумные. Поэтому нужно проверить профайлером код с оптимизацией и удостовериться, что теперь он занимает не 5% CPU, а меньше. Учтите только, что формула не линейная.
Допустим, раньше ваш код на профиле занимал 5% CPU, а теперь — 4%. Насколько он ускорился?
Пусть, оптимизируемый участок кода занимает x единиц работы, а всё остальное — y. Тогда k — доля работы x от общей работы — вычисляется так:
x/(x+y)=k
А после оптимизации — так:
x'/(x'+y)=k'
Если умножить всё на (x+y), а затем выразить x, то получится:
x=kx+ky
x(1-k)=ky
x=yk/(1-k)
Для удобства введём коэффициент g=k/(1-k).
Тогда x=gy и x'=g'y.
Мы хотим оценить (x-x')/x. Подставляем, сокращаем на y, получаем:
(x-x')/x * 100%=(g-g')/g * 100% ~ 21%
Иногда отчёт содержит идеи будущих оптимизаций, которые пришли в голову во время раскопок, но слишком дорогих по времени, чтобы делать их сейчас. Например, у нас есть (пока) небольшой список идей, что мы могли бы улучшить, если бы решились форкнуть Apache Lucene.
Запоминайте горячие места в коде
Мы ведём небольшой список горячего кода. Поскольку наше приложение — это не хаотичный набор функций, которые вызывают спагетти-код в произвольном порядке, а структурированный набор функций, уложенный в небольшое число абстракций, то это конечный список методов абстрактных классов и интерфейсов. Так как наше приложение либо считает агрегации по запросу, либо возвращает топ самых релевантных, то основная операция у нас — это проверка одного документа. Поэтому мы считаем горячим такой код, который исполняется на каждый документ-кандидат или чаще. Кандидат, потому что он может не войти в конечный топ, так как его вытеснят более релевантные документы.
У нас были ситуации, когда буквально лишний вызовrequireNonNull в горячем коде привёл к алерту из-за роста таймингов и пришлось откатывать релиз (мой коллега обещал написать об этом подробную статью, так что верим и ждём).
Поэтому оптимизировать горячий код правда важно. Не надо отмахиваться тем, что «это всё Java — она и так тормозит».
К любому рефакторингу в таких местах надо относиться с осторожностью и обязательно его обстреливать. Даже тривиальные правки могут сломать какую-то оптимизацию. К сожалению, поведение оптимизирующих компиляторов крайне хрупкое, и Java-рантайм не является исключением.
Регулярные стрельбы
В Ozon есть общие ночные сайтовые стрельбы, за которыми наблюдают руководители технических команд. Однако на их результаты влияет поведение других сервисов, поэтому результаты получаются слишком хаотичными, чтобы делать выводы об одном конкретном сервисе.
Поэтому у нас есть ещё и изолированные стрельбы. Там зафиксированы патроны и данные, а меняется только код сервиса с релизами. Конечно, время от времени приходится обновлять данные и патроны, но в целом это даёт возможность проследить изменение производительности в течение длительного времени. Более того, мы нарезаем патроны не только по разным ручкам, но и по тяжести запросов: нарезалка патронов делает запросы к реальному индексу и определяет их кардинальность.
Модель вычислений
Оптимизировать код можно в любом месте и по разным метрикам. Времени же при этом не бесконечное количество, и крайне важно понимать, насколько каждая часть системы влияет на производительность, чтобы не тратить время на оптимизацию кода, который не является горячим. Поэтому важно иметь модель вычислений приложения и время от времени её актуализировать.
К тому же поиск потенциально перспективных для оптимизации мест — это во многом поиск подозрительно медленного кода. Но чтобы подозрение вообще могло возникнуть, надо иметь в голове точное представление о том, на что приложение объективно вынуждено тратить много ресурсов, а на что — почти не должно их тратить. Тогда подозрительным покажется расхождение представлений и реального положения дел.
Когда все в команде знают код приложения очень хорошо, это может казаться бессмысленной работой. Но когда мы написали документ с детальным описанием своей модели вычислений, мы сходу завели десяток задач на оптимизацию — и в итоге существенно срезали тайминги.
Ресурсы
Любая модель сложности вычислений строится вокруг потребляемых ресурсов. Скажем, если разбирают алгоритм во внешней памяти, считают операции с диском, а если сетевой алгоритм, то число и размер сообщений. Поэтому надо определиться с ресурсами.
Если ваше приложение и считает, и данные по сети гоняет, и с диском взаимодействует, то может быть совсем не очевидно, какие ресурсы в какие моменты используются активнее всего.
Всё что угодно может стать узким местом, например:
1. Граф вычислений: блокировки, забитые пулы, асимметрия в параллельных задачах и пр.
2. Сам CPU.
3. Шина памяти.
4. Диск
5. Сеть.
У нас в базовом поиске данные загружаются с диска через mmap — и после небольшого прогрева обращений к диску практически нет. Хотя важно следить за метрикой major page fault, так как, когда данные не помещаются в памяти, диск мгновенно становится узким местом. Но мы решаем эту проблему шардированием.
Бизнес-требования вынуждают нас просматривать достаточно много документов при поиске. Например, чтобы не снижать показы у товаров, участвующих в важных акциях, просто потому, что они физически неудачно в индекс легли. Поэтому мы нагружаем до 16 ядер для обработки одного запроса, чтобы уложиться в тайминги. Очевидно, это достаточно тяжёлые запросы, и на одну машину их приходит не много, поэтому сеть не является узким местом: на обработку запросов инстанс нагружает канал на 100 Мбит, но, когда происходит репликация, нагрузка кратковременно увеличивается до 2 Гбит.
Так что мы упираемся в CPU. Но в вашем приложении может быть по-другому.
Организация вычислений
Мы активно пользуемся тулой async-profiler, она поставляется внутри докер-образов наших сервисов и присутствует на каждой машине.
Блокировки
Можно посмотреть на блокировки, которые занимают больше 10 мс, так:
profiler.sh \
-e lock 10ms \
-d 600 \
-o flamegraph=total \
-f /tmp/lock.svg \
<пид вашего java процесса>
Скорее всего, вы увидите много потоков запаркованными в очереди в тред-пулах, особенно если система не находится под пиковой нагрузкой. Поэтому разумно включить режим wall, чтобы увидеть соотношение блокировок и полезной работы.
profiler.sh \
-e wall \
-d 600 \
-o flamegraph=total \
-f /tmp/wall.svg \
<пид вашего java процесса>
Флейм-графы в svg можно скачать здесь.
Мы следим, чтобы никаких проблем с блокировками не было. Что вы и видите на этих флейм-графах: все потоки заняты либо полезной работой, либо ожиданием и epoll, либо запаркованы и ждут задач. На графике блокировок видно, что иногда мы долго ждём внутри кэшей. Но я почти доделал задачу асинхронного кэша, которая полностью исправляет в том числе и эту проблему.
VisualVM и YourKit могут рисовать графики состояния всех потоков, так можно увидеть, как много потоков одновременно выполняют работу, и найти синхронизации, мешающие масштабированию.
Граф вычислений
Если вы тоже занимаетесь бэкендом, скорее всего, у вас SEDA архитектура, то есть обработка запроса разбивается на стадии, которые могут внутри быть параллельными или даже асинхронными, но периодически требуется подождать исполнения всех прошлых стадий, чтобы начать выполнять следующие.
Например, у нас три основные ручки:
1. Search — поиск топа наиболее подходящих документов и выдача их с запрашиваемыми полями.
2. Facet — ручка, благодаря которой мы рисуем фильтры (цена, цвета, производитель) слева на сайте. Она принимает граф из агрегаций и подзапросов, а мы вычисляем его за один проход.
3. Cardinality — возвращает примерное число документов, подходящих под запрос, с учётом параметров склейки.
Все эти ручки выполняют поиск в Apache Lucene. Также у ручки search есть финальная стадия fetch, на которой мы вычитываем запрашиваемые поля для найденного топа документов.
Любой поиск в Apache Lucene состоит из трёх основных стадий, которые выполняются последовательно:
1. Rewrite. API Apache Lucene поддерживает достаточно хитрые запросы, которые необходимо преобразовать к более простым на основе текущей статистики данных.
2. Collect. Одна таблица в Apache Lucene (которую там неудачно называют индексом) состоит из нескольких независимых иммутабельных сегментов. На этой стадии мы обрабатываем каждый соответствующий запросу документ в каждом сегменте независимо от остальных.
3. Reduce. В конце результаты поиска в разных сегментах объединяются.
Поиск по разным сегментам выполняется параллельно, и у нас написано несколько политик такой параллелизации. Остальные стадии в Apache Lucene реализованы однопоточно. Таким образом, время поиска в Lucene не может быть меньше, чем T(rewrite) + max(T(collect))+T(reduce). Хотя сами по себе стадии rewrite и reduce не занимают много CPU, но из-за того, что они не масштабируются, они вносят ощутимый вклад в latency в p99.

Поэтому важно измерять тайминги каждой стадии — чтобы понимать, какие части системы выгоднее всего оптимизировать.
Шедулинг задач
Как только вы начнёте распределять задачи по потокам, немедленно возникнет вопрос: является ли это распределение оптимальным? Для начала начните замерять среднее время исполнения одной задачи и время ожидания последней задачи. Если время ожидания относительно среднего маленькое, значит, у вас всё хорошо. Иначе добавьте метрику разницы самой медленной задачи минус среднее время среди всех задач на один запрос. Так вы грубо оцените верхнюю границу времени, которое можно выиграть при оптимизации шедулинга задач.
Учтите, что если задачи имеют значительные перекосы в сложности, то у вас есть предельное число потоков, которые могут давать выигрыш в latency, ведь вычисление не может занимать меньше времени, чем то, которое необходимо на обработку самой сложной задачи. Оценить чисто теоретически этот предел невозможно, поэтому важно иметь возможность легко подкручивать степень параллелизма, чтобы найти оптимум.
Микрооптимизации
Чем более высокоуровневое решение вы принимаете, тем больше оно влияет на производительность.
Пожалуй, на самом верху находится постановка задачи, ведь разные задачи имеют разную минимальную вычислительную сложность решения. Причём даже небольшое изменение задачи может привести к существенному изменению сложности.
В самом же низу находятся микрооптимизации: замена небольшого изолированного участка кода на эквивалентный, но более быстрый. Большого роста производительности от этого ждать не стоит, но это не бесполезная работа.
Дело в том, что, если у вас большой проект, вы наверняка будете время от времени наступать на перформансные грабли нижележащих слоёв. Особенно это актуально для managed-языков, таких как Java. И абсолютно невинный, на первый взгляд, код может начать отъедать заметную долю перфа.
Поэтому важно регулярно мониторить флейм-графы на предмет всяких странностей — и подчищать их.
А заведомо горячий код необходимо сразу писать оптимально.
Поскольку поведение оптимизаций крайне хрупкое, порой бывает так, что незначительная подсказка рантайму и компилятору приводит к каскадному срабатыванию других оптимизаций, — и код заметно ускоряется. Предвидеть это трудно, поэтому проще написать горячий код сразу хорошо, чем исправлять его позже.
Советы по написанию горячего кода
У нас есть небольшой чек-лист для ускорения ревью горячего кода. Основная его идея в том, чтобы писать код как можно беднее и понятнее для компилятора.
Обработка ошибок в горячем коде
Никаких проверок на ошибки, кроме асертов. Это позволит ловить баги при тестировании, но код проверок будет вырезан в проде.
Проверки корректности аргументов должны быть как можно выше по стеку вызовов. Обычно запросы корректны и JVM спекулятивно оптимизирует эти условия, однако если придёт кривой запрос, то проверка сработает и произойдёт деоптимизация кода, которая замедлит другие запросы. Поскольку проверки есть и внутри Apache Lucene, имеет смысл их продублировать на уровне выше. Желательно их делать в коде похолоднее. В нашем случае холодным считается код, который вызывается один раз на сегмент или реже.
Аллокации
Мы стараемся делать так, чтобы число аллокаций на запрос не зависело от его кардинальности, то есть иметь амортизировано ноль аллокаций в куче на документ-кандидат. В идеале аллокаций вообще не должно быть при обработке документов, но для агрегаций это невозможно. К счастью, там суммарное число аллокаций ограничено сверху кардинальностью полей, поэтому амортизированное условие выполняется.
Итерации по коллекциям (даже только при чтении) могут аллоцировать итераторы и генерировать много индирекций, мешая другим оптимизациям. Если в горячем коде вы итерируетесь, лучше делать это по массивам. Скаляризация — это лотерея.
Type pollution
Type pollution — это довольно специфическая проблема Java HotSpot VM. Она стреляет главным образом из-за специфической реализации дженериков, а также тайпкастов внутри самой JVM.
Каждый объект в заголовке содержит ссылку на свой класс. Если вы делаете тайпкаст на объекте, то происходит вот что:
1. Сперва достают точный класс объекта по ссылке в заголовке.
2. Если это класс, к которому мы кастим, то успех.
3. Иначе мы идём в специальный пошаренный между потоками кэш предков — там хранится последний использованный предок (один). Если класс, к которому мы кастим, равен ему, то успех.
4. Иначе идём в список предков и линейно в нём смотрим, а потом обновляем кэш предка.
Ситуация, когда мы кастим какой-то класс к разным его предкам, называется type pollution и приводит к тормозам.
Разумеется, все приличные люди стараются избегать оператора instanceof и явных кастов. Однако касты проникают в программу из-за реализации дженериков. В Java никаких дженериков в рантайме нет: все типы затираются к нижней границе (если границ несколько, то к одной из них), а в нужных местах добавляют касты.
Например, если вы заводите ArrayList<String>, то внутри него создается массив Object[], а когда в коде статически тип известен, то там добавляется на этапе компиляции явный каст к String.
Дженерики рассыпают кучу неявных тайпкастов, чем закладывают под вашу программу бомбу. Представьте, что у вас есть два утильных метода, один из них принимает List<CharSequence>, а другой List<Comparable<?>>. Вы отправляете свой List<String> то туда то сюда и получаете type pollution. А если у вас дженерик с двумя границами, то вы точно получите там type pollution.
Конечно, HotSpot может вырезать лишние тайпкасты, но это тоже лотерея.
Виртуальные вызовы
В горячем коде должно быть как можно меньше виртуальных вызовов, так как они мешают инлайнингу и сами по себе бывают недешёвыми.
В JVM есть много оптимизаций виртуальных вызовов, поэтому производительность зависит от множества условий. Общее правило примерно следующее: если виртуальный вызов не нужен, то он работает быстро, sealed-классы и интерфейсы с небольшим числом наследников тоже работают хорошо, а остальное может тормозить, при этом интерфейсы ведут себя хуже абстрактных классов.
У нас был особенно горячий код примерно следующего вида:
while(this.iterator.hasNext()) {
if (this.set.contains(this.iterator.next())) {
return true;
}
}
return false;Проблема заключается в том, что HotSpot не верит в финальность поля set, поэтому не может вынести из цикла поиск точной реализации метода contains, а мы использовали разные реализации для маленьких и больших множеств.
Соответственно, мы, во-первых, добавили такие строчки в начало метода:
var set = this.set;
var iterator = this.iterator;А во-вторых, сгенерировали с помощью Apache FreeMarker несколько реализаций для разных имплементаций. В большинстве из них код абсолютно одинаковый, просто типы полей указаны точно.
Важно уточнить, что это точечная оптимизация в одном конкретном, очень горячем, месте.
Что делать, когда весь код уже оптимизирован, а хочется ещё
Идеи по оптимизации посещают вас в порядке их очевидности. Вот вы открываете профайлер и оптимизируете свой код, который подозрительно торчит. Затем вы обвешиваетесь метриками, как-то выделяете группы запросов и, вооружившись более тонкими инструментами, начинаете оптимизировать latency. Но в конце концов наступает момент, когда вы уже весь свой код оптимизировали и он нигде не торчит: с какой оптикой ни смотри, вы упираетесь в сторонние библиотеки.
Например, если посмотреть на наш профиль, то видно, что код, написанный нами, практически не потребляет ресурсов. Вся работа происходит в коде Apache Lucene и gRPC.
Вот профили CPU и аллокаций с выделенным regexp-ом:
org\/apache|io\/grpc|com\/google|com\/clearspring|io\/micrometer

Что делать в такой ситуации? Начинать контрибьютить в Apache Lucene и Protobuf? Делать форки? Докупать железо? Смириться?
Когда всё уже и так оптимизированно, каждое следующее существенное ускорение — это всегда какой-то неожиданный ход, проявление смекалочки. Давайте пройдёмся от простых приёмов к трудоемким.
Оптимизируйте использование своего сервиса
Как известно, не так важен уровень производительности, как умение с ним обращаться. Оптимизация того, как клиенты пользуются вашим сервисом, подразумевает не только ряд обязательных шагов, но и постоянную работу по поиску проблем.
Rate Limiter
Любая система массового обслуживания склонна стремительно деградировать под нагрузкой выше определённого порога. На практике это выглядит как забивание пулов потоков задачами. Поэтому у вас должны быть на них метрики, в том числе и на реджекты.
Потом вы должны нащупать этот порог экспериментально — и установить на него rate limiter, чтобы система никогда не переходила в состояние перегрузки, так как из него довольно сложно выйти, даже когда нагрузка уйдет: пулы уже забиты задачами, но ресурсов их разобрать ещё нет. Поэтому лучше заранее начать отдавать 429 для HTTP или RESOURCE_EXHAUSTED для gRPC.
Поскольку лимит RPS — это параметр, который используется системой под нагрузкой, нужно иметь возможность динамически менять его значение без перезагрузки сервиса.
Мы используем Resilience4j.
Деградация
В рекомендательных системах и поиске можно плавно ослаблять точность ответов, сокращая вычисления. Такой приём называется деградацией. Сервис либо сам может решить деградировать из-за нехватки ресурсов, например с помощью PID-контроллера, пытающегося сбалансировать число задач в очереди, либо параметр деградации может приходить в запросе.
В Ozon механизм деградации внешний, так как она существенно влияет на прибыль, и включается человеком только в случае проблем. Впрочем, мы не пользуемся этим механизмом с тех пор, как пересели с Elasticsearch на свой движок. Но всё ещё держим рубильник деградации под подушкой — на всякий случай.
Расширение API
Рано или поздно пользователи вашего сервиса начнут использовать его странно. Например, делать тяжёлые запросы, чтобы по результатам посчитать что-то маленькое, но то, что напрямую через API достать невозможно. Или, наоборот, делать несколько последовательных запросов — и на своей стороне объединять результаты. Очевидно, вы можете расширить API, предоставив возможность считать это эффективнее, снизив нагрузку на сервис и срезав тайминги для пользователей.
Самое сложное — это найти такие кейсы, поскольку часто пользователи не осознают, что делают что-то не так. И хотя необходимо иметь канал обратной связи, чтобы пользователи могли поинтересоваться, не делают ли они чего-то странного, часто этот вопрос даже не приходит им в голову, а потому придётся искать странное самостоятельно.
Если в запросе есть потенциально опасные параметры, скажем, какие-то неограниченные списки или лимиты, надо добавить для них метрики и сохранять куда-то потенциально тяжёлые запросы. Например, можно отправлять их в Kafka и настроить процесс сохранения этих запросов в HDFS — а позже их аналитически мурыжить.
Оптимизируйте использование чужого кода
После того как вы помогли своим пользователям, самое время вспомнить, что для разработчиков языков программирования и библиотек пользователи — это вы. И мы тоже склонны неэффективно использовать нижележащие слои.
Обновляйтесь
На момент написания этой статьи мы запускаем свои сервисы на JDK 20. Так как я иногда хожу по собеседованиям, то знаю, что многие сидят на JDK 11 или даже 8. На вопрос о том, почему они не обновляются, обычно отвечают: «Ну там ничего особенно важного не добавляли».
Каждый раз это очень грустно слышать, потому что вообще-то, обновив JDK с 11 до 17, вы, скорее всего, получите 10% перфа в подарок. Помимо этого, sealed-классы реально позволяют срезать виртуальные вызовы в простых случаях. А record-ы фиксят очень неприятную проблему: JVM не верит в финальность полей у классов (и у неё есть на то причины), из-за чего отваливаются многие оптимизации. В коде JDK вы можете увидеть кучу мест, где поля класса копируются в локальные переменные в начале метода, — ровно из-за этого.
Обновлять свой билд-тулчейн полезно и на других языках.
Есть и ещё одно соображение, почему обновляться — это хорошо, которое я почерпнул в этом докладе: если ваш проект станет успешным и просуществует достаточно долго, он по определению превратится в legacy, поэтому, регулярно обновляясь, вы поможете будущим поколениям разработчиков его поддерживать и немного уменьшите сумму страданий всех живых существ во вселенной.
Изучайте то, что используете
У нас в команде любой разработчик может потратить час рабочего времени в день на изучение кода Apache Lucene. без каких-либо особых причин. Единственное, мы просим коллег написать о том, какие интересные вещи они узнали в результате долгих раскопок.
Конечно, у нас особый случай, поскольку одна библиотека для нас намного важнее остальных. Но если вы упираетесь в чужой код, то надо тратить время на его изучение: возможно, там есть какой-то малоизвестное API, которое сможет вам помочь.
У нас было несколько таких случаев, но все они слишком Lucene-специфичны, чтобы подробно описывать их здесь.
Точечный вендоринг
Когда вся простая, но обязательная работа сделана можно начинать точечно вендорить используемые библиотеки. Сразу скажу, что проталкивать изменения в open-source-проекты очень сложно. Вы можете потратить несколько месяцев на добавление одной тривиальной строчки кода.
Конечно, проекты бывают разными, но всё равно они, особенно старые заслуженные и популярные, развиваются крайне медленно по сравнению с закрытыми, и авторы очень консервативно относятся к добавлению изменений: им потом придётся их поддерживать, а вы в любой момент уйдете в закат, даже без двух недель передать все дела не будет. К тому же у них есть свои планы относительно изменений. Например, сейчас можно оптимизировать какой-то код с помощью Unsafe. Альтернативно можно подождать несколько лет, пока релизнут Foreign Function and Memory API релизнут и оптимизировать код уже с его помощью. Для закрытого проекта вполне подходит первый вариант, а для открытой популярной библиотеки второй вариант намного лучше, тем более что Unsafe реализацию в будущем придётся выпиливать.
Поэтому идеальное решение — найти отдельный тормозящий класс, написать альтернативную реализацию и заменить на неё. Конечно, для этого библиотека должна поддерживать расширение в таком месте. Обычно большие и популярные библиотеки это умеют. В любом случае пропихнуть возможности расширения, как правило, проще, чем существенное изменение.
А теперь расскажу вам несколько историй успеха и поделюсь нашими планами на будущее.
Кэши
У Apache Lucene есть реализация кэша LRUQueryCache. В целом это обычный LRU кэш, но с дополнительной фильтрацией запросов на кэширование. Логика такая: если запрос считается очень быстрым, он не кэшируется; иначе кэшируется в том случае, если достаточно часто встречается. Из-за этого кэш заполняется запросами достаточно медленно, но зато они действительно популярные.
К сожалению, этот кэш довольно небрежно реализован. Например, подсчет частоты запроса каждый раз берёт глобальную синхронизацию на весь кэш. Мы заменили это на использование оптимистичной блокировки через StampedLock.
Другая интересная особенность реализации кэша в том, что когда для модификации кэша берут блокировку, вызывают tryLock, и если взять лок не удалось, то вычисляют запрос напрямую. Из-за этого на высоком контеншене резко падает hit rate.
Также, когда подзапрос кешируется, он энергично и синхронно вычисляется на всём сегменте, что может негативно повлиять на тайминги, поскольку обычно подзапросы вычисляются лениво и никогда не проходят по всему индексу, так как есть другие подзапросы, которые тоже двигают итераторы.
А ещё есть вот такое подозрительное место в BooleanWeight:
if (query.clauses().size() > TermInSetQuery.BOOLEAN_REWRITE_TERM_COUNT_THRESHOLD) {
// Disallow caching large boolean queries to not encourage users
// to build large boolean queries as a workaround to the fact that
// we disallow caching large TermInSetQueries.
return false;
}Причём BOOLEAN_REWRITE_TERM_COUNT_THRESHOLD равен всего 16. Поправить это, к сожалению, не так просто, поскольку BooleanWeight — это final-класс, который много где используется: придётся завендорить всю логику с boolean-кверями.
Сейчас мы разрабатываем новый асинхронный кэш, который избавит нас от проблем с блокировками и синхронными вычислениями.
Когда вы решите добавить кэш в свой проект, помните, что он должен быть хорошо настроен и затюнен и максимально учитывать особенности ваших вычислений. Не могу не посоветовать библиотеку Caffeine, когда есть повод.
ANN и Panama
В новых версиях Apache Lucene появились ANN-запросы — и у бизнеса тут же возникла идея добавить их в поиск.
К сожалению, реализация там из рук вон плохая. Проблемы две: чудовищно медленная индексация и чудовищно медленные запросы. При этом для индексации векторов используется алгоритм HNSW, который вообще так плохо не должен работать.
Сам запрос KnnVectorQuery имеет ряд параметров. В частности, для него можно задать подзапрос — и тогда топ документов будет считаться по этому подзапросу.
1. Сперва KnnVectorQuery исполняет подзапрос (который хранится в поле org.apache.lucene.search.KnnVectorQuery#filter) для ВСЕХ сегментов и получает битсет подходящих документов.
2. Затем исполняет на каждом сегменте HNSW-алгоритм, чтобы найти топ документов, либо линейно ищет их, если в битсете меньше, чем org.apache.lucene.search.KnnVectorQuery#k, документов.
3. Это делается последовательно в org.apache.lucene.search.KnnVectorQuery#rewrite для каждого сегмента.
4. Хотя rewrite возвращает Query, в данном случае он возвращает просто закэшированные значения DocId и SegmentId топа документов.
Реализация абсолютно чудовищная. Поэтому мы, во-первых, у себя на уровне API запретили использовать подзапросы, так как энергичная фильтрация всех документов во всех сегментах — это безумие, а во-вторых, в своей реализации передаём executor, чтобы обрабатывать сегменты параллельно. Запрос всё ещё очень тяжёлый, но с таким уже можно жить.
С индексацией дела обстоят ещё хуже. Реализация в целом нормальная, и, если сравнивать её с другими реализациями HNSW на Java, имеет схожую производительность. Но с ней просто невозможно жить с нашими объёмами. Однако оказалось, что, если собрать свежую Hnswlib свежим компилятором под конкретные процессоры, то она работает в несколько раз быстрее любых реализаций на Java. Что неудивительно — в Hnswlib куча SIMD-кода.
Поэтому вот что мы сделали. Перевели проекты с JDK 17 на JDK 20, написали Сишные биндинги к Hnswlib (она написана на плюсах), потом для них сделали Java-биндинги через jextract. А дальше провернули такой финт: написали свой кодек, который собирает HNSW-индекс через биндинги с помощью Hnswlib, а потом через Foreign Function and Memory API сохраняет граф из нативной памяти в том же формате, в котором Apache Lucene сохраняет свой граф. Соответственно, код чтения остался прежним.
Это дало двукратное ускорение сборки индексов с векторными полями, поскольку есть и другие поля, помимо векторных.
Оптимизация базовых операций
В приложении за множеством слоёв абстракций всегда находится то полезное вычисление, ради которого мы изначально запускали программу. Те операции, из которых оно состоит, можно считать базовыми, и, когда их вызовы оптимизированы, не остаётся ничего другого, кроме как оптимизировать сами эти операции. Это то, чем мы занимаемся сейчас.
Например, существенная часть профиля занята тем, что отфильтровывает товары, которые не доставляются по адресу пользователя. При этом большинство запросов идёт из крупных городов, где, конечно, почти все товары доставляются. У нас есть статистика, что в 70% вызовов мы находим пересечение в первой же локации. У распределения довольно длинный хвост, но тем не менее здесь практически нечего верхнеуровнево не выиграть. Нужно оптимизировать саму операцию чтения значений.
Unsafe mmap
В Apache Lucene есть класс Directory, который инкапсулирует логику работы с файлами на диске. И есть стандартная имплементация MMapDirectory, которую мы использовали раньше. Она загружает файлы через mmap. Однако в Java пока нет стабильного способа читать данные произвольного размера напрямую из памяти, поэтому эта реализация использует несколько ByteBuffer-ов. Из-за особенностей реализации один буфер не может быть больше 2 Гб, так как длина массива должна умещаться в int (в действительности Apache Lucene ограничивается 1 Гб, поскольку на самом деле массив в 2 Гб создать нельзя — можно только чуть-чуть меньше). Поэтому при доступе возникает дополнительная индирекция.
Можно написать реализацию через Unsafe, а можно — через FFM API, который находится в превью на JDK 20. По результатам наших замеров, Unsafe-версия работает быстрее, так что мы написали реализацию с использованием Unsafe и библиотеки one-nio. При этом в комьюнити Apache Lucene идёт работа по созданию реализации поверх FFM API, так что, когда их производительность сравняется с нашей, или Unsafe кончательно задеприкейтят, нам будет на что перейти.
Разработка своего кодека
Apache Lucene достаточно агрессивно сжимает данные, которые хранит колоночно (в так называемых DocValues). В общем случае это разумный выбор, потому что сжатие позволяет быстрее поднимать данные с диска, а также больше их положить в RAM. Плюс чтение из этих полей обычно происходит, когда мы вычитываем дополнительные поля у найденного топа документов, то есть таких чтений совсем не много. Однако есть несколько полей, по которым мы активно фильтруем, и было бы лучше их положить без сжатия, чтобы выиграть на чтении.
Пока работа над этим проектом находится в самом начале, поэтому подводить какие-то итоги рано. Но это всё равно поучительная история: может быть сложно придумать общее решение лучше того, которое есть в используемой библиотеке, но вполне возможно, что разработчики упустили скучный и крайне простой частный случай, — а вы его заметите и на нём выиграете.

Заключение
Напоследок хочу сказать вам, что, хотя внедрение культурных практик в команду может казаться непростой задачей, помните, что более продвинутая культура всегда побеждает примитивную. Причём культура развивается при написании текстов. Поэтому исследуйте код, рантаймы и тулчейны, пишите отчёты об интересных результатах — и люди к вам потянутся. А более развитая культура команды обязательно принесёт свои плоды и на продуктовых на метриках.
Комментарии (65)

Vcoderlab
30.11.2023 15:26+52Пользуясь случаем, хочу задать вопрос о поиске на "озоне".
Например я хочу найти микроконтроллер CH32V307 либо отладочную плату с ним. Ввожу в поиск "CH32V307". Результат на скриншоте:

Поиск на "озоне". Первая страница результатов поиска. Как видим, нужный нам товар, в названии которого есть указанное в поиске обозначение, появился только на третьей строке. Всего в первых трёх строках только один релевантный для меня результат.
Поясните пожалуйста, по каким параметрам приведённые на скриншоте пылесборники и масляный фильтр оказались более релевантными с точки зрения озоновского поиска? В их названиях нет искомого обозначения.

aol-nnov
30.11.2023 15:26+13стоит предположить очевидный вариант - "деньги не пахнут", а содержимое нерелевантной выдачи проплачено продавцами )
(списывают у старшего брата, в общем https://habr.com/ru/companies/first/articles/776960/)

sergey-sw
30.11.2023 15:26+22Мы облажались с текстовым анализатором, будем исправлять.

jackcrane
30.11.2023 15:26+15а можете сделать секретный метод поиска ? например если аргумент в тройных кавычках
'''CH32V307'''
это значит "искать точное совпадение, проплаченый мусор из промо не напихивать, если ничего не найдено - показать что ничего не найдено".

ti_zh_vrach
30.11.2023 15:26+6У вас хотя бы нашлось. А я как-то искал по критериям: hdd 2,5" sata3 1тб. Мне пару штук надо было. Хотел посмотреть, что есть, по каким ценам. Я даже даже фильтры всякие включил. Где-то через час мне надоело вылавливать карточки нужных товаров среди ssd разных объёмов, всяческих внешних дисков, разноцветных корпусов, переходников, кабелей и чёрт знает какого мусора (как у вас). Пошёл на сайт оранжевого магазина, за 10 минут всё посмотрел, купил нужное. Летом дело было.
jackcrane
30.11.2023 15:26Пошёл на сайт оранжевого магазина
у них иерархический каталог есть. это большое преимущество.

Femistoklov
30.11.2023 15:26"Почти 4000 инженеров" не могут сделать подсветку поисковой строки в результатах поиска? Серьёзно?

Wallhead
30.11.2023 15:26-2Мне ниже ответили, что это трейд офф, чтобы поиск работал лучше, надо чтобы он работал хуже)



igor_suhorukov
30.11.2023 15:26+2Однако в Java пока нет стабильного способа читать данные произвольного
размера напрямую из памяти, поэтому эта реализация использует несколько
ByteBuffer-ов.Года 3 назад удобно работал в Java программе с непрерывным регионом памяти на сотни гигабайт через VirtualMemory обертку из QuestDb. mmap и никаких ByteBuffer.
В этом проекте много полезных примитивов для джавистов было написано с нуля. Проект не использует внешние зависимсти.

SharplEr Автор
30.11.2023 15:26А там так же через Unsafe всё делается. У нас по сути так же.
igor_suhorukov
30.11.2023 15:26Для тех кто не в ozon и решает подобные задачи эти классы могут пригодиться. Проект с десятками тысяч звезд на гитхабе, входящий в Y Combinator и существующий почти десятилетие дает надежду что эти классы будут поддерживаться и переноситься на новые стандарты платформы с выходом каждой новой версии JDK.





ShadowMaster
30.11.2023 15:26Почему Java 20, а не 21? Все-таки 21 - LTS. Потому что Java 21 слишком свежая и не успели перейти?

Sherman81
30.11.2023 15:26+2Когда переходили на 20, 21-ой еще не было в GA. Сейчас переходим на 21. Дело в том, что как раз с 20 версии уже нормально заработала panama, которую мы используем (проект ANN поиска упоминается в статье).

Ayahuaska
30.11.2023 15:26+4Культурный феномен — это антифрод Озона, который заблокировал мне учётку на ровном месте.

ivorrus
30.11.2023 15:26О, не я один такой! Мне, правда, учётку не блокировали, но антифрод несколько раз срабатывал, я пожал плечами и ушёл искать нужную мне камеру для тюбинга на другие маркетплейсы
Ayahuaska
30.11.2023 15:26Мне полностью заблокировали учётку, при попытке входа с использованием номера телефона появляется сообщение в духе "Мы не можем отправить смс на этот номер", предлагается обратиться в службу поддержки.
Служба поддержки мне каждый раз предлагает заполнить форму для восстановления доступа, результат всегда один и тот же: "Нам не удалось удостовериться, что вы являетесь владельцем аккаунта".
В последний раз я обратился к их сервису по работе с персональными данными (как я понял) с просьбой удалить аккаунт. В удалении было отказано со ссылкой на то, что аккаунт был заблокирован по причинам, которые они в соответствии с их правилами, которые я принял при регистрации, могут не указывать, а потому аккаунт нельзя удалить. Именно поэтому я решил, что это антифрод.

andreyiq
30.11.2023 15:26+4Меня больше всего подбешивает, что когда открываешь сайт на телефоне, тыкаешь в поиск, набираешь текст, а он либо часть символов не пропечатывает, либо оказывается надо ещё раз на поиск нажать чтобы он заработал и появились подсказки. Такое ощущение, что страница не успевает полностью прогрузится. И этим страдают многие сайты

antohabio
30.11.2023 15:26Похоже так и задумано. Нажимаешь на поле поиска, вводишь текст, нажимаешь поиск и перекидывает на страницу поиска, где поле уже пустое и снова нужно вводить запрос.

Levin7
30.11.2023 15:26+1В olx такая херня подбешивает. Что поиск при вводе глючный, что подгружаемость сделана так что когда ты хочешь быстро в нужные кнопки сайта попасть, оно устроено так что в этот момент догрузит остальные потроха и намеренно сдвинет экран и попадёшь ты не туда куда тебе нужно, а им






polos75
30.11.2023 15:26+6С удовольствием прочитаю статью о поиске, когда будет рабочий поиск. Хотя бы кавычки включите - уже хорошо.

Panzerschrek
30.11.2023 15:26Если стоят столь строгие требования к производительности, то почему Java, а не что-то более для этого подходящее (C++, Rust)? В этих языках нету многих упомянутых тут проблем Java, вроде излишних аллокаций, виртуальности вызовов там где не надо, затрат на дженерики и т. д.
Или были куда более веские причины использовать Java, скажем, доступность конкретных библиотек под неё или наличие знаний в команде?SharplEr Автор
30.11.2023 15:26-1В статье Сергея написано детально о причинах, но всё таки на C++ надежный проект поддерживать сложно, а растоманов у нас тогда почти не было. Плюс можно было переиспользовать куски кода эластика скажем касательно мультиматч запросов, что бы переход для клиентов сделать плавнее. Сегодня, наверное, если начинать новый проект действительно может быть лучше взять tantivy и делать вокруг него на Rust.
Sherman81
30.11.2023 15:26+1Lucene как библиотека все еще очень хороший выбор. Написать свой поисковый движок с ноля возможно, но это примерно 1-2 года для команды из людей, которые уже точно знают что надо делать (уже работали с поиском, разбираются в SoTA поисковых технологиях и так далее).
У нас есть немалая экспертиза в java/JVM, но тогда, не было супер экспертизы в поиске, поэтому для нас Apache Lucene был вполне логичен.

Forvad
30.11.2023 15:26+4А Вы сами свом поиском пробовали пользоватся?
Задаешь любое - скажем "графин стеклянный 2 литра".. Нашло. Меняешь сортировку - и всё. Там всякая бяка

rPman
30.11.2023 15:26+5Тот самый случай, когда маркетологи правят балом, какие бы крутые решения программисты не реализовывали, все это ломается о правило - мы завалим вас мусором чтобы бизнес платил бабки за то чтобы быть сверху мусорной ямы.

Komrus
30.11.2023 15:26+8Читаешь статью - красота! Продвинутые технологии, умные программисты, интересные технические решения!
Заходишь на сайт, пишешь некий набор параметров - и получаешь в результатах поиска пачку ну вот СААВСЭМ нерелеватного мусора :(((
И где все эти продвинутые технологии и технические решения?
Wallhead
30.11.2023 15:26+4Запрос айфон 13
Сортировка самый дешевый

Сортировка самый дорогой

Сортировка высокий рейтинг
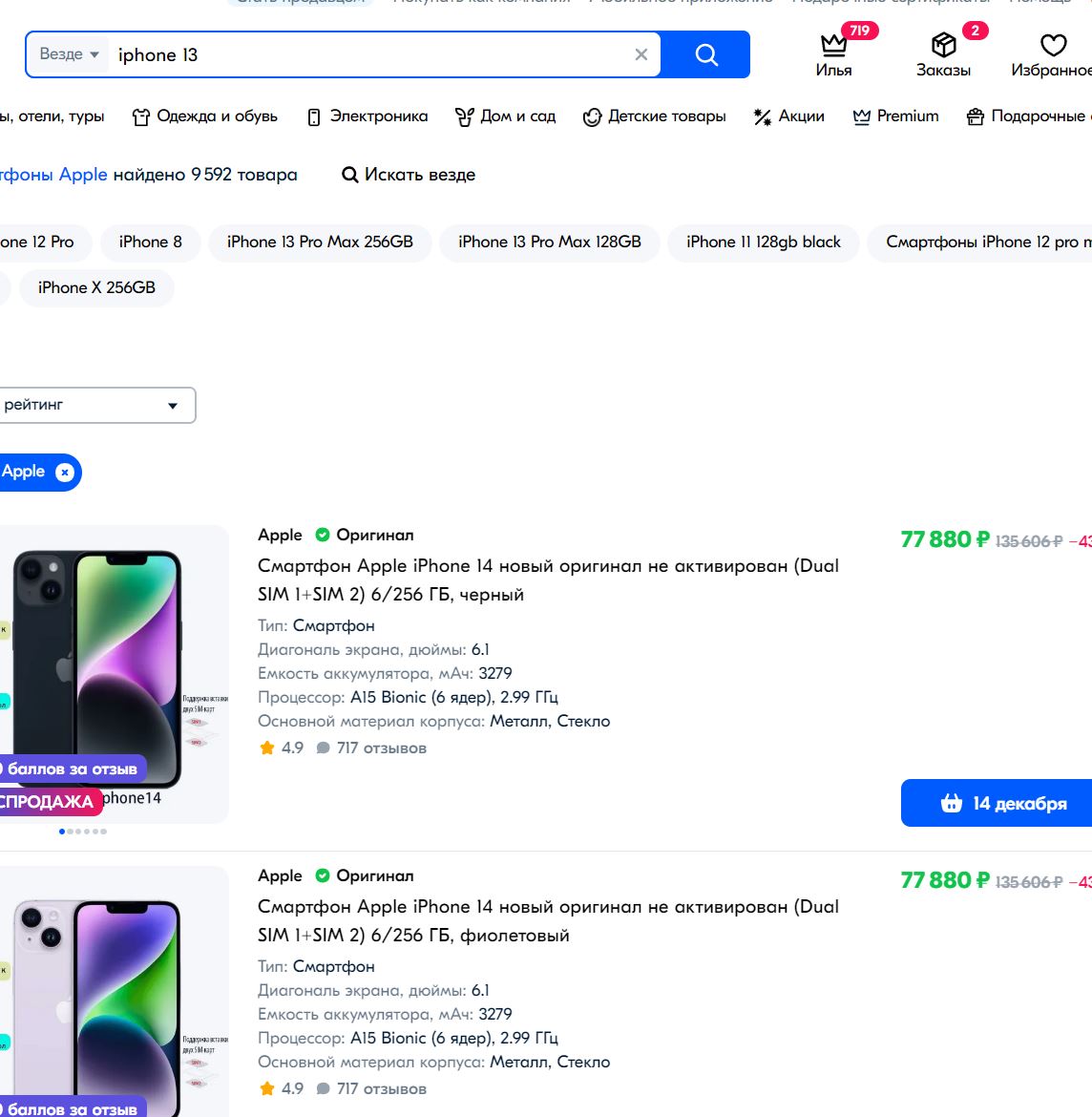
Ни в одной сортировке нет 13го) каеф. Причем, если искать через гугл на озоне, то потом все норм сортирует. Может вам все вот, что вы наделали удалить и прост гуглу платить?
Sherman81
30.11.2023 15:26-3Если вы зажмете конкретную модель слева, то результат будет именно тот, которвый вам нужен.
Разнообразие и сужение выдачи, это всегде некоторый trade off. Так не только у нас.
Мы даем вам инструмент суждения выдачи через фильтры, если он вам нужен.
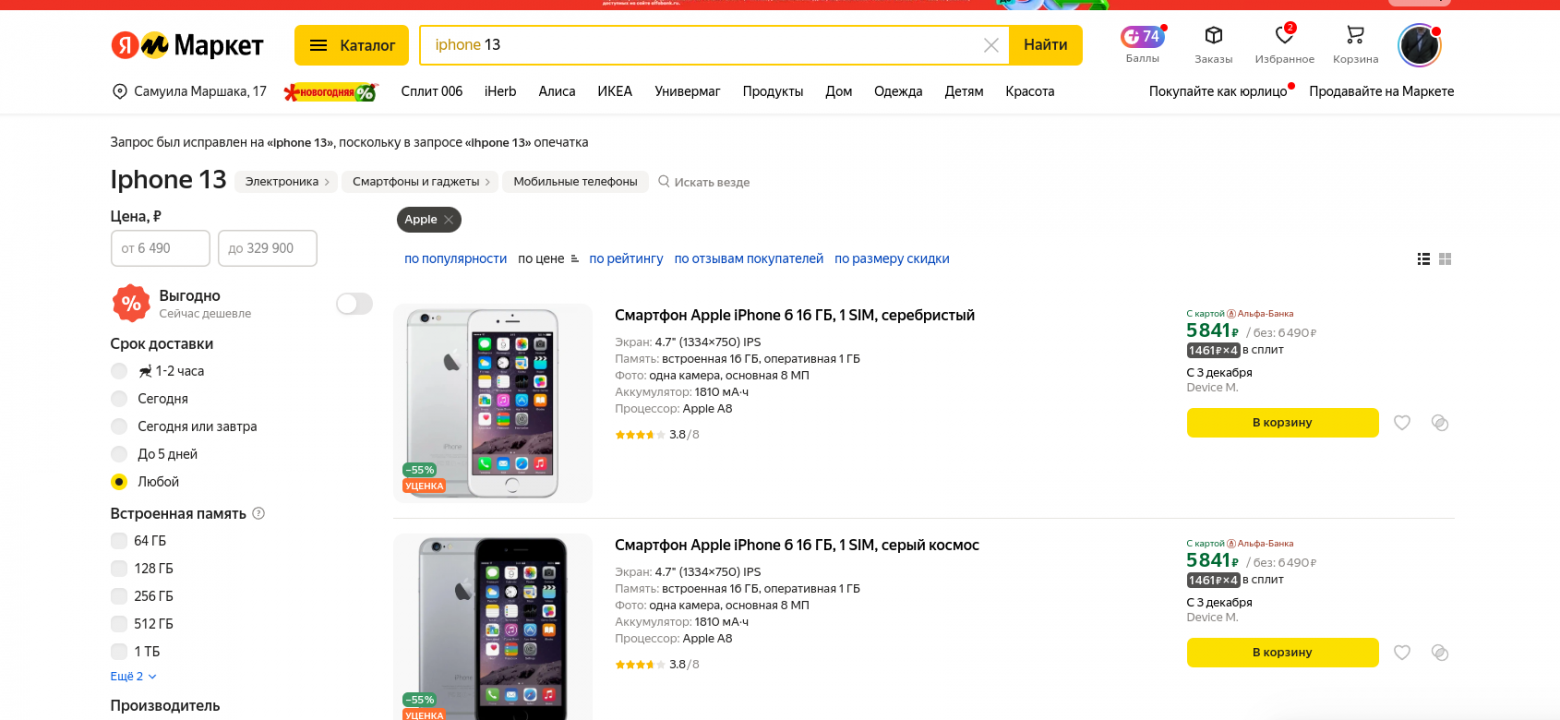
Wallhead
30.11.2023 15:26+7я бы понял сужение выдачи только для 13х айфонов, но не для всех айфонов вообще. Я же ввел цифру 13 для чего? чтобы мне выдавало все остальные с 7 по 15? Если я ввожу просто айфон показывайте все вариации, но если есть конкретика зачем мне все остальное? Для айфонов у вас есть подфильтр, но я уверен, что есть много товаров для которых подфильтров нет и как мне сужать вашу выдачу для них?


Sherman81
30.11.2023 15:26+1У WB точно также.
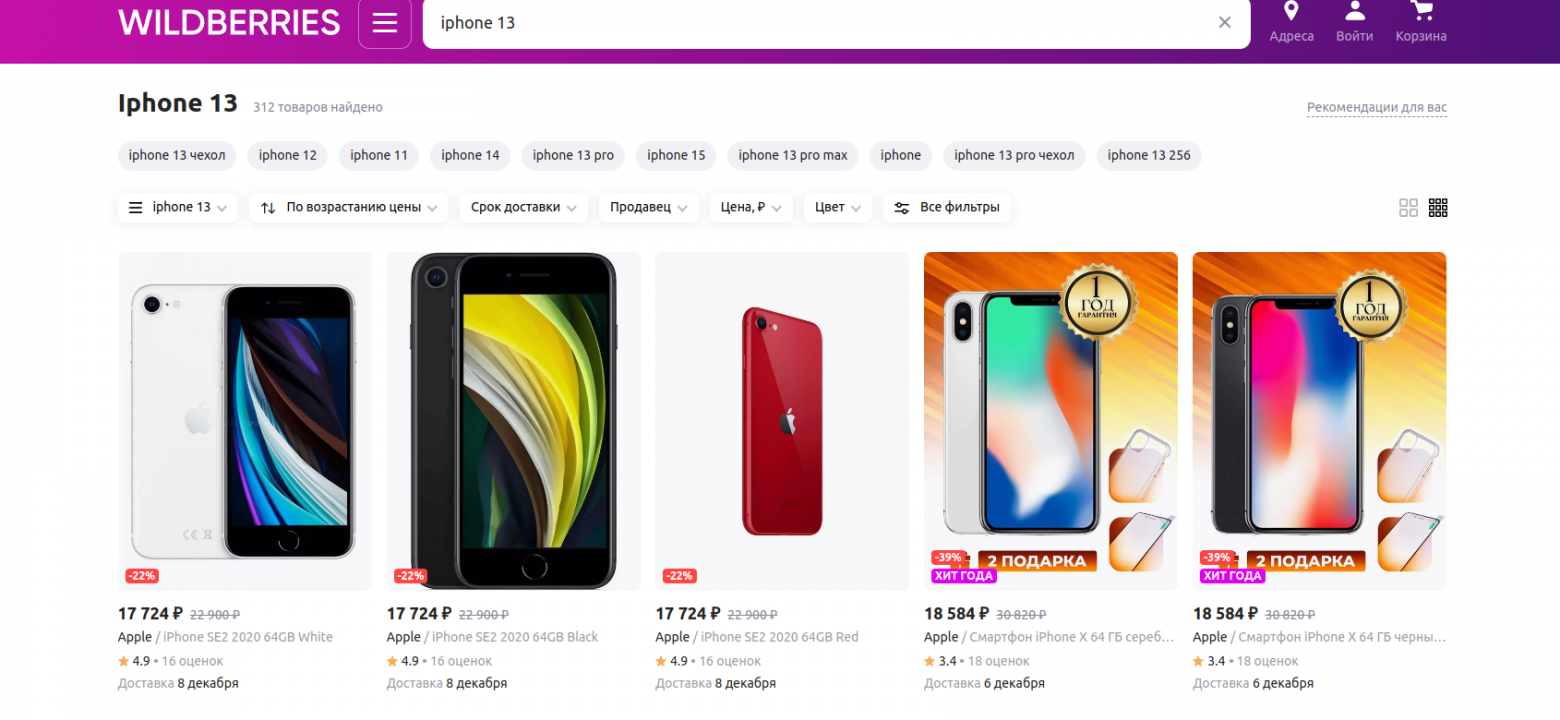
Wallhead
30.11.2023 15:26+4Если у других так же это не значит, что это хорошо. Это все равно, что вы в ресторане закажете шампанское, а вам скажут "может по пивку, а?"
Sherman81
30.11.2023 15:26-2Ну вы не передергивайте, да. Это довольно сомнительный прием в дискуссии. Я привел здесь примеры из других поисков, чтобы показать тот факт, что это довольно распрастенная практика. И вовсе не согласен с тем, что она плохая, даже если вы счиаете иначе :-)
Wallhead
30.11.2023 15:26+7Зачем мне, примеры других поисков, если мы обсуждаем ваш, если вы прочитаете комментарии, то увидите, что многим поиск не нравится, а не только мне. Поиск по факту не ищет то, что нужно и разбавляет его какими-то левыми вещами. Сделайте голосовалку, нравится людям ваш поиск или нет.
Sherman81
30.11.2023 15:26-1Для того чтобы учтонить запрос, есть прекрасный инструмент фильтрации. Вы почему-то игнорируете его, при этом написали уже множество комментариев (совершенно не по теме статьи, кстати) о том, что вы считаете всех вокруг дураками, потому что они по вашему, выдают "не те результаты".
То что вы считаете другие модели iphone "левыми вещами" при запросе "iphone 13" с сортировкой по цене, это ваше право, но это не значит, что выше мнение является здесь экспертным или даже может быть обощено каким-то образом на большую группу людей.
Wallhead
30.11.2023 15:26+3Ну так сделайте голосовалку, где спросите устраивает ли людей ваш поиск. Вы ее никогда не сделаете, потому что знаете ответ. Тут уже были разрабы с he али, которые тоже говорили, что поиск у них норм.

rombell
30.11.2023 15:26+1Кстати да. Меня попросили написать на мыло, что мне кажется неудачным. Я написал 14 пунктов с картинками и подробными описаниями. Через пару писем они просто слились. Больше года прошло, стало ещё хуже.

GDragon
30.11.2023 15:26+4А я уже давно не пользуюсь поиском ни на озоне, ни на вб, ни на яндексе, потому что их выдача - абсолютно нерелевантный мусор.
И большинство моих знакомых и коллег (в том числе женщин которые постоянно чем то закупаются) делают так же.
Потому что "ой там поиск такой дурацкий, никогда ничего не находит!".
Вы уверены что вы именно этого хотели добиться?
Ну отдавайте первую полосу под строго релевантные результаты а дальше пихайте промо, маркетинг и продвижение, это ещё как то понять можно.
А когда в поиске есть всё кроме того что ищешь - остаётся незабываемое ощущение наступания в говно.Sherman81
30.11.2023 15:26+1Возможно, вам больше подходит более строгая модель "каталога", вместо поиска. То есть вы попадаете в каталог с определенными товарами в конкретной категории и потом просто уточняете запрос, пока вам не будет достаточно.
У всех маркетплейсов каталоги + фильтры плюс/минус есть.
Поиск это немного другая штука. Понятие релевантности не так просто оценивается разными людьми, как кажется, на первый взгляд. Безусловно, бывают явные промахи (типа показали стул, а искали тарелку), и с ними идет постоянная борьба.А в говно лучше не наступать ;-)
rombell
30.11.2023 15:26+2Ваши каталоги имеют мало релевантных фильтров. Мне обычно наплевать (или я просто не знаю) производителя, и совершенно точно наплевать на продавца. Мне товар купить, а не шашечки.
Но когда приходится листать десяток страниц, пока найдёшь хотя бы одно предложение (третья строка? ха! Восьмая страница! Поищите "цепь для пилы 8 дюймов" - вся выдача забита от произвольного размера цепей до цепей 3/8")
Sherman81
30.11.2023 15:26Я в цепях ничего не понимаю, но может быть вы покажите (на каком-то сервисе), как должна была бы выглядеть эталонная выдача по этому запросу?
rombell
30.11.2023 15:26+1Я не могу показать на сервисе, поскольку все сервисы подсовывают по принципу "покажем побольше, авось прокатит".
Но я могу сказать, что если у меня в запросе аккумуляторная цепная пила 8", мне точно не надо показывать бензиновые пилы на 14"
А если у меня в запросе цепь для пилы 8 дюймов , я ещё могу понять логику показа цепей с шагом 3/8 (поэтому крайне хотелось бы указывать, чего НЕ должно быть в ответе), но зачем мне цепи на 6" и на 14"?Ну вот
Яндекс

Али

Озон

И вроде бы не совсем плохо, но посортируем по цене

0!

ganzmavag
30.11.2023 15:26Это та же практика, по которой в супермаркетах через какой-то период берут и меняют местами все полки. Или в торговых центрах не дают с эскалатора спуститься дальше сразу на следующем, а заставляют пройти до него по всему этажу.






vtal007
30.11.2023 15:26+1Культурный феномен это то, что поиск не работает. От слова вообще
В запросе: Велосипед городской. В фильтре - велосипеды городские
Показывает что? показывает горные велосипеды
Подскажите, это какая-то внеземная технология сравнить заголовок товара и поисковый запрос?
Ссылка на урл поиска

Wallhead
30.11.2023 15:26Самый смак, что по ссылке, он включает категории автоматом и правильно показывает городские хД, но если её сбросить(категорию) , то да будут все велосипеды. И топик стартер утверждает, что это вершина поиска, выдавать, то что не в запросе)


vvzvlad
30.11.2023 15:26+3Очень крутая статья, и очень грустно, что поиск в озоне поломан настолько, что я постоянно ищу в гугле, просто забиваю что мне нужно, и где-нибудь в первых пяти результатах — ссылка на озон. Если забивать на самом озоне, ничего найти невозможно, куча мусора в результатах. WB таким не страдает, поэтому в основном пользуюсь им.

av-86
30.11.2023 15:26-1Вот да. Неужели вы серьезно каким-то образом верите, что ваш поиск хоть как-то полезен людям? Вы лучше напишите, как анализируете изменение продаж, меняя разный мусор в выдаче по конкретному запросу. Хоть честно будет.
odilovoybek
Вот честно, с удовольствием читаю ваши статьи) Спасибо.
SharplEr Автор
Пожалуйста :)