
Как-то я посчитал, что 1 минута простоя hh.ru в будни днем затрагивает около 30 000 пользователей. Мы постоянно решаем задачу снижения количества инцидентов и их длительности. Снизить количество проблем мы можем правильной инфраструктурой, архитектурой приложения — это отдельная тема, ее мы пока не будем брать во внимание. Поговорим лучше о том, как быстро понять, что происходит в нашей инфраструктуре. Тут как раз нам и помогает мониторинг.
В этой статье на примере hh.ru я расскажу и покажу, как покрыть мониторингом все слои инфраструктуры:
- client-side метрики
- метрики с фронтендов (логи nginx)
- сеть (что можно добыть из TCP)
- приложение (логи)
- метрики базы данных (postgresql в нашем случае)
- операционная система (cpu usage тоже может пригодиться)
Формулируем задачу
Я для себя сформулировал задачи, которые должен решать мониторинг:
- узнать, что сломалось
- быстро узнать, где сломалось
- увидеть, что починилось
- capacity planning: хватает ли у нас ресурсов на рост
- планирование оптимизаций: выбираем, где нужно оптимизировать, чтобы был эффект
- контроль оптимизаций: если после выпуска оптимизации в produсtion эффекта не видно, то релиз надо откатить, а код выкинуть (или переформулировать задачу)
Сначала несколько слов об архитектуре hh.ru: вся логика распределена между несколькими десятками сервисов на java/python, страницы для пользователей “собираются” нашим сервисом-сборщиком frontik, основная БД — postgresql, на фронтендах и внутренних балансировщиках используется nginx + haproxy.
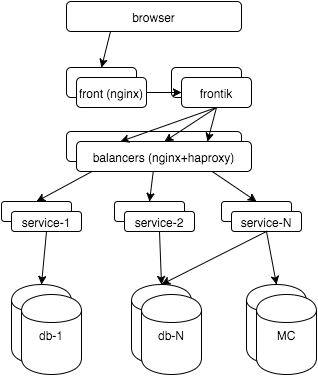
Теперь начнем покрывать мониторингом все слои. В итоге хочется:
- видеть, как работает система с точки зрения пользователя
- видеть, что происходит в каждой подсистеме
- знать, на что уходят ресурсы
- на все это смотреть во времени: как было минуту назад, вчера, в прошлый понедельник
То есть мы будем говорить о графиках. Про алерты, workflow, KPI можно посмотреть мои слайды с RootConf 2015 (нашел так же “экранку”).
Client-side метрики
Самая достоверная информация о том, как пользователь видит сайт, есть в браузере. Её можно получить через Navigation timing API, наш js снипет отстреливает метрики на сервер GET запросом с параметрами, дальше его принимает nginx:
location = /stat {
return 204;
access_log /var/log/nginx/clientstat.access.log;
}
потом мы просто парсим получившийся лог и получаем такой график:
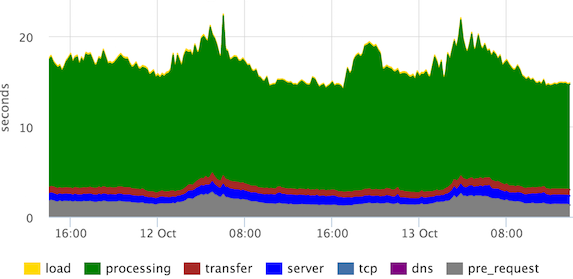
Это стэкированные 95-е персентили времен основных стадий рендеринга страницы. «Processing» можно определять по разному, в данном случае пользователь видит страницу сильно раньше, но наши frontend-разработчики посчитали, что им нужно видеть так.
Мы же видим, что каналы в норме (по стадии «transfer»), выбросов стадий «server», «tcp» нет.
Что снимать с фронтенда
Основной мониторинг у нас построен по метрикам, которые мы снимаем с фронтендов. На этом слое мы хотим выяснить:
- Есть ли ошибки? Сколько?
- Быстро или медленно? У одного пользователя или у всех?
- Сколько запросов? Как обычно/провал/боты?
- Не тупит ли канал до клиентов?
Все это есть в логе nginx, нужно только немного расширить его дефолтный формат:
- $request_time — время с получения первого байта запроса до записи последнего байта ответа в сокет (можно считать, что учитываем передачу по сети ответа)
- $upstream_response_time — сколько думал бэкенд
- Опционально: $upstream_addr, $upstream_status, $upstream_cache_status
Для визуализации всего потока запросов хорошо подходит гистограмма.
Мы заранее опредилили, что такое быстрый запрос (до 500ms), средний (500ms-1s), медленный (1s+).
Рисуем по оси Y запросы в секунду, время ответа отражаем цветом, так же добавили ошибки (HTTP-5xx).
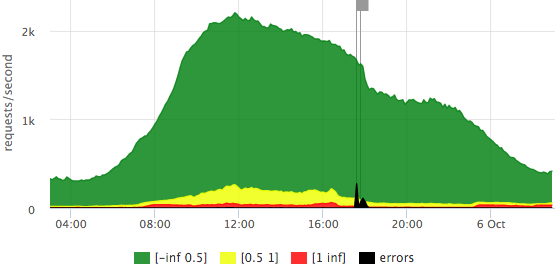
Вот пример нашего “светофора” на основе $request_time:
Мы видим, что у нас в пике чуть больше 2krps, большинство запросов быстрые (точная легенда есть в тултипе), в этот день было 2 выброса ошибок, затрагивающие 10-15% запросов.
Посмотрим как отличается график, если за основу взять $upstream_response_time:

Видно, что до бэкендов долетает уже меньше запросов (часть отдается из кэша nginx), “медленных” запросов почти нет, то есть, на предыдущем графике красное — это в основном вклад передачи по сети до пользователя, а не ожидание ответа бэкенда.
На любом из графиков можно подробнее рассмотреть масштаб количества ошибок:
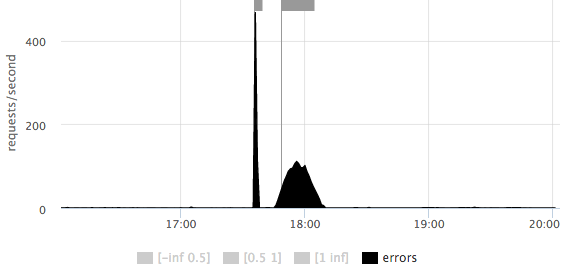
Сразу понятно, что было 2 выброса: первый короткий ~500rps, второй более продолжительный ~100rps.
Ошибки иногда нужно разложить по урлам:
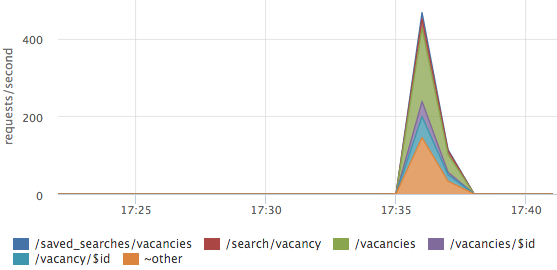
В данном случае ошибки не на каком-то одном урле, а распределены по всем основным страницам.
На основном дашборде у нас так же есть график с HTTP-4xx ошибками, мы отдельно смотрим на количество HTTP-429 (мы отдаем этот статус, если превышен лимит на количество запросов с одного IP).
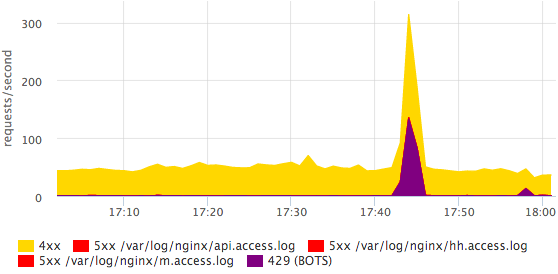
Здесь видно, что приходил какой-то бот. Более детальную информацию по ботам проще посмотреть в логе глазами, в мониторинге нам достаточно просто факта того, что что-то изменилось. Все ошибки можно разбить по конкретным статусам, это делается достаточно просто и быстро.
Иногда бывает полезно посмотреть на структуру трафика, какие урлы сколько трафика генерируют.
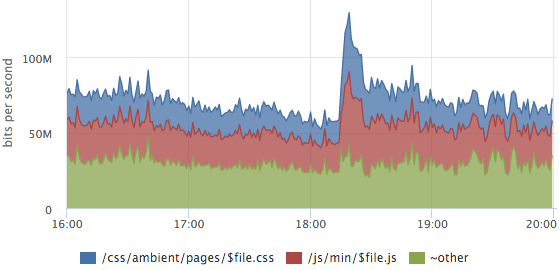
На этом графике раскладка трафика статического контента, выброс — это выход нового релиза, у пользоваетелей проинвалидировались кэши css и js.
Про разбивку метрик по урлам стоит упомянуть отдельно:
- ручные правила для парсинга основных урлов устаревают
- можно попробовать как-то нормализовывать урлы:
выкинуть аргументы запроса, id и прочие параметры в самом урле
/vacancy/123?arg=value -> /vacancy/$id - после всех нормализаций хорошо работает динамический top урлов (по rps или сумме $upstream_response_time), вы детализируете только самые значимые запросы, для остальных считаются суммарные метрики
- можно так же сделать отдельный top по ошибкам, но с отсечкой снизу, чтобы не было мусора
Логи у нас парсятся на каждом сервере, на графиках мы обычно смотрим итоговую картину, но можно посмотреть в разрезе серверов тоже. Например, это удобно для оценки балансировки:
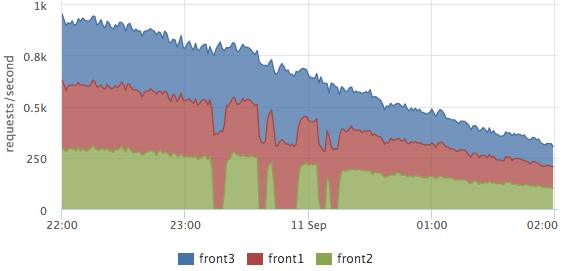
Тут хорошо видно, как выводили из кластера front2, в это время запросы обрабатывали 2 соседних сервера. Общее количество запросов не просело, то есть пользователей эти работы не затронули.
Подобные графики на основе метрик из лога nginx позволяют хорошо видеть, как работает наш сайт, но причину проблем они не показывают.
Слой сборщика
Мгновенный мониторинг любой программы дает ответ на вопрос: где сейчас находится управление (вычисления, ожидание данных от других подсистем, работа с диском, памятью)? Если рассматривать эту задачу во времени, нам нужно понимать, на какие стадии (действия) уходило время.
В нашем сервисе-сборщике логируются все значимые стадии каждого запроса, например:
2015-10-14 15:12:00,904 INFO: timings for xhh.pages.vacancy.Page: prepare=0.83 session=4.99 page=123.84 xsl=36.63 postprocess=13.21 finish=0.23 flush=0.49 total=180.21 code=200В процессе обработки страницы вакансии (handler=”xhh.pages.vacancy.Page”) мы потратили:
- ~5ms на обработку пользовательской сессии
- ~124ms на ожидание всех запросов к сервисам за данными страницы
- ~37ms на шаблонизацию
- ~13ms на локализацию
Из этого лога мы берем 95-ю персентиль для каждой стадии каждого обработчика (как мы парсим логи я расскажу на более наглядном примере чуть ниже), получаем графики для всех страниц, например для страницы вакансии:
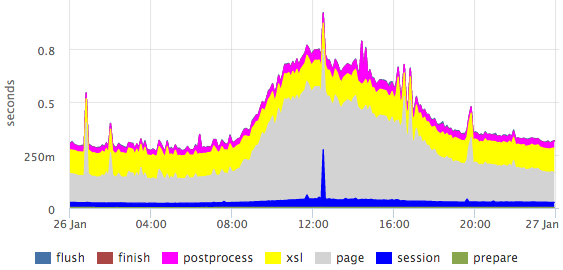
Здесь хорошо видно выбросы в пределах конкретных стадий.
Персентили обладают рядом недостатков (например, сложно объединить данные из нескольких замеров: серверов/файлов/итд), но в данном случае картина получается гораздо нагляднее гистограммы.
Если нам нужно, например, получить более-менее точное соотношение каких-либо стадий, то можно смотреть на сумму времен. Cуммируя времена ответа с разбивкой по обработчикам, можно оценить, чем занять весь наш кластер.
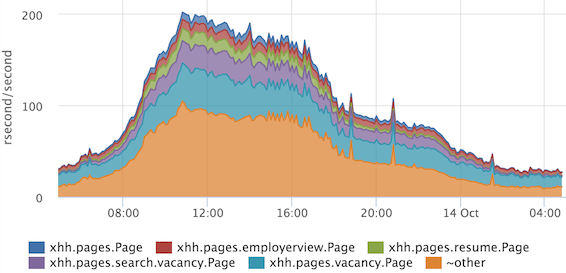
По оси Y у нас так называемые “ресурсные” секунды, потраченные в секунду. Очень удобно, что соотношение сразу учитывает частоту запросов, и если у нас один очень тяжелый обработчик вызывается редко, то он в топ не попадет. Если не брать во внимание распараллеливание обработки некоторых стадий, то можно считать, что в пике мы на все запросы тратим 200 процессорных ядер.
Мы применили этот прием еще и для задачи профилирования шаблонизации.
Сборщик логирует, какой шаблон сколько рендерился для каждого запроса:
2015-10-14 15:12:00,865 INFO: applied XSL ambient/pages/vacancy/view.xsl in 22.50msАгент сервиса мониторинга, который мы используем, умеет парсить логи, нам для этого нужно написать примерно такой конфиг:
plugin: logparser
config:
file: /var/log/hh-xhh.log
regex: '(?P<datetime>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}),\d+ [^:]+: applied XSL (?P<xsl_file>\S+) in (?P<xsl_time>\d+\.\d+)ms'
time_field: datetime
time_field_format: 2006-01-02 15:04:05
metrics:
- type: rate
name: xhh.xsl.calls.rate
labels:
xsl_file: =xsl_file
- type: rate
name: xhh.xsl.cpu_time.rate
value: ms2sec:xsl_time
labels:
xsl_file: =xsl_file
- type: percentiles
name: xhh.xsl.time.percentiles
value: ms2sec:xsl_time
args: [50, 75, 95, 99]
labels:
xsl_file: =xsl_file
Из полученных метрик рисуем график:

Если вдруг при релизе у нас вырастет время наложения одного шаблона (или всех сразу), то мы это увидим. Так же мы можем выбрать, что именно имеет смысл оптимизировать…
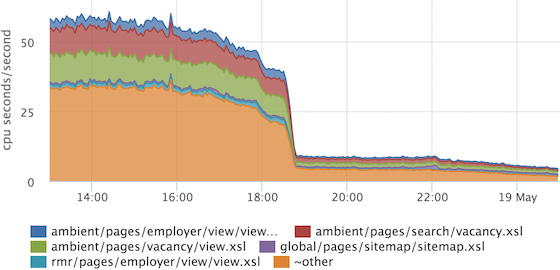
… и проконтролировать, что оптимизация принесла результат. В этом примере оптимизировался общий кусок, который включен во все остальные шаблоны.
Что происходит на сборщиках, мы теперь понимаем достаточно хорошо, двигаемся дальше.
Внутренний балансировщик
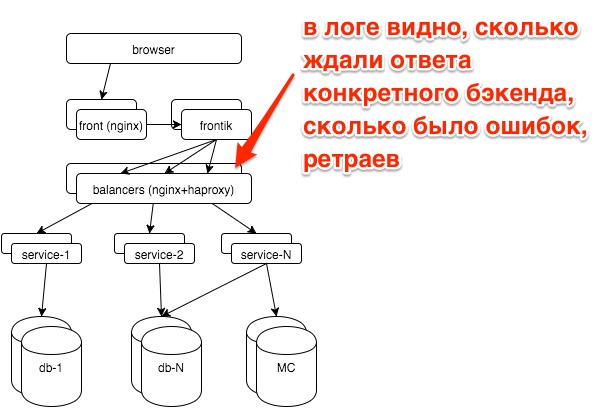
При поломках у нас, как правило, возникает вопрос: сломался какой-то конкретный сервис (если да, то какой) или все сразу (например при проблемах с базами, другими хранилищами, сетью). Каждый сервис стоит за балансировщиками с nginx, логи для каждого сервиса пишутся в отдельный access log.
Простой график top-5 сервисов по количеству ошибок сильно упростил нам жизнь:
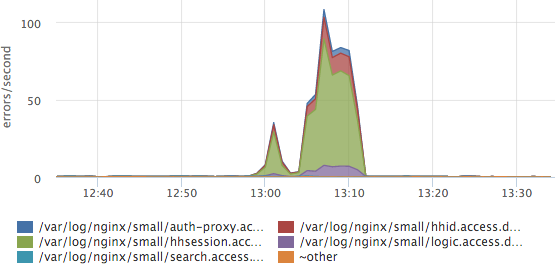
Здесь видно, что больше всего ошибок приходится на лог сервиса сессий. Если у нас появится новый сервис/лог, то он распарсится автоматически и новые данные будут сразу учитываться в этом топе. У нас есть так же гистограммы времени ответа по всем сервисам, но чаще всего мы смотрим на этот график.
Сервисы
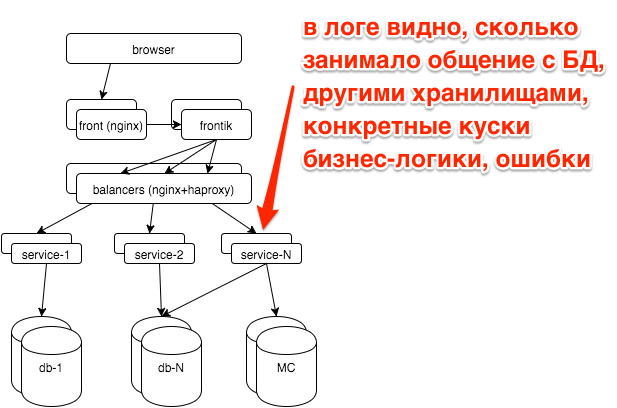
В логах сервисов у нас так же стадии обработки запросов:
2015-10-21 10:47:10.532 [Grizzly-worker(14)] INFO r.hh.health.monitoring.TimingsLogger: response: 200; context: GET /hh-session/full; total time 10 ms; jersey#beforeHandle=+0; HHid#BeforeClient=+0; HHid#Client=+6; DB#getHhSession=+3; pbMappers=+0; makeHeaderSession=+1; currentSessionInBothBodyAndHeader=+0; jersey#afterHandle=+0;Визуализируем:
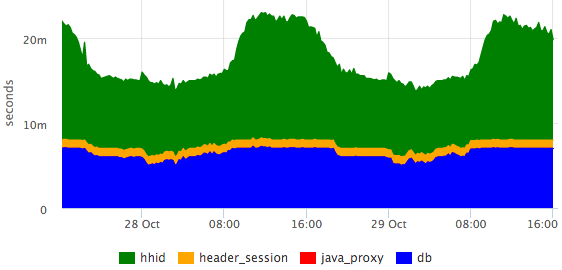
Видно, что БД отвечает за константное время, а сервис hhid в пики посещаемости немного замедляется.
База данных
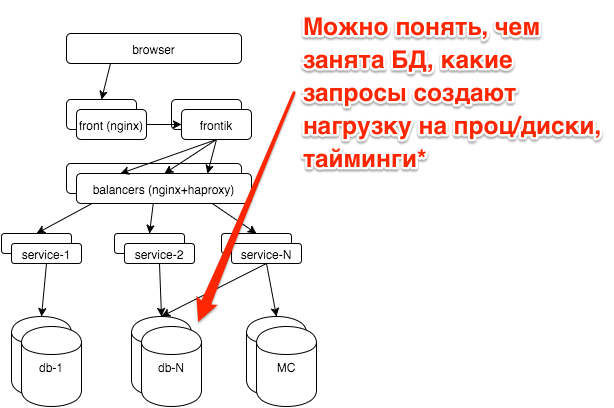
Все основные БД у нас работают на postgresql. Администрирование базы данных мы аутсорсим в postgresql-consulting, но нам самим тоже важно понимать, что происходит с БД, так как дергать DBA при всех проблемах не целесообразно.
Самый главный вопрос, который нас волновал: все ли хорошо сейчас с БД? На основе pg_stat_statements мы рисуем график среднего времени выполенения запросов:
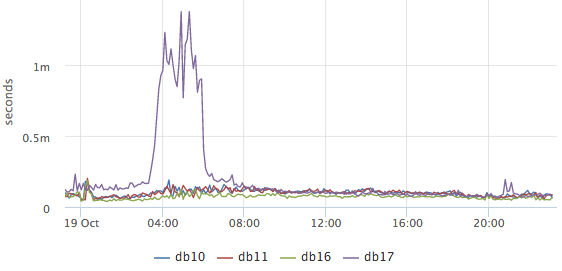
По нему понятно, происходит ли в БД сейчас что-то необычное или нет (к сожалению ничего кроме среднего на имеющихся данных сделать нельзя). Дальше мы хотим узнать, чем занята база в данный момент, при этом нас прежде всего интересует, какие запросы грузят CPU и диски:

Это top-2 запросов по использованию CPU (снимаем мы top50+other). Тут хорошо видно выброс конкретного запроса к базе hh_tests. При необходимости его можно полностью скопировать и рассмотреть.
В postgresql так же есть статистика про то, сколько запросы ждут операций с диском. Например, мы хотим узнать, что вызвало этот выброс на /dev/sdc1:
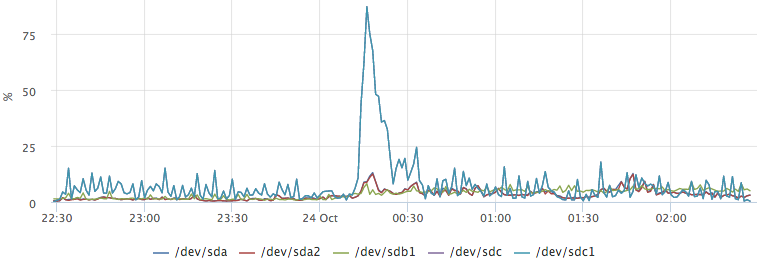
Построив график top запросов по io, мы легко получаем ответ на наш вопрос:
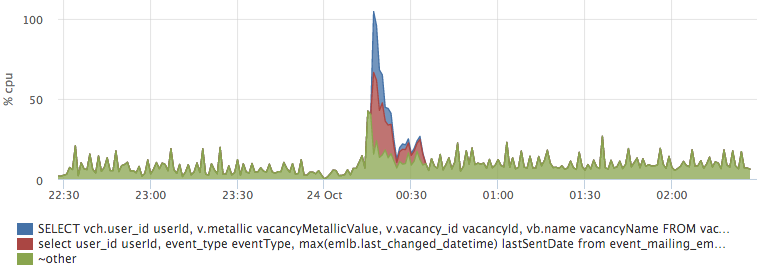
Сеть
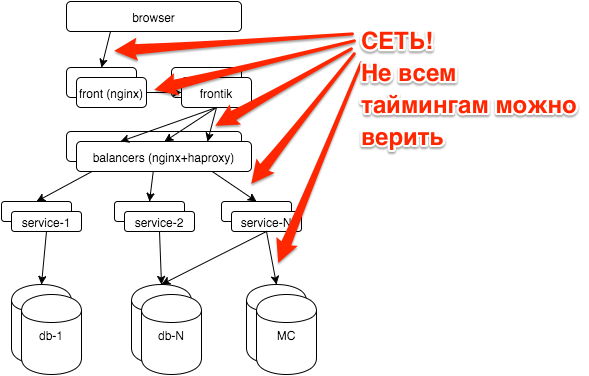
Сеть — достаточно нестабильная среда. Часто, когда мы не понимаем, что происходит, можно списать тормоза сервисов на проблемы с сетью. Например:
- сервис hhsession ждал ответа от hhid 150ms
- сервис hhid считает, что он ответил на этот запрос за 5ms (у нас все запросы имеют идентификатор $request_id, мы умеем по логам узнавать конкретные запросы)
- между ними только сеть
Результатов ping за вчера между этими хостами у вас нет. Как исключить сеть?
TCP RTT
TCP Round-Trip Time — время от отправки пакета до получения ACK. Мониторинговый агент на каждом сервере снимает rtt для всех текущих соединений. Для ip из нашей сети мы агрегируем времена отдельно, получаем примерно такие метрики:
{
"name": "netstat.connections.inbound.rtt",
"plugin": "netstat",
"source_hostname": "db17",
"listen_ip": "0.0.0.0",
"listen_port": "6503",
"remote_ip: "192.168.1.48",
"percentile": "95",
}
На основе таких метрик можно задним числом посмотреть, как работала сеть между любыми двумя хостами в сети.
Но значения TCP RTT даже близко не совпадают с ICMP RTT (то, что показывает ping). Дело в том, что протокол TCP достаточно сложный, в нем применяется много различных оптимизаций (SACK итд), это хорошо иллюстрирует картинка из этой презентации:
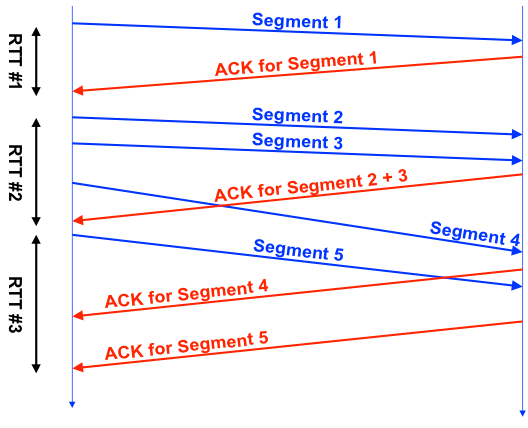
Каждое TCP соединение имеет один счетчик RTT, видно что RTT#1 более-менее честный, во втором же случае за время замера мы отправили 3 сегмента, в третьем — отправили 1 сегмент, получили несколько ACK.
На практике TCP RTT достаточно стабилен между выбранными хостами.
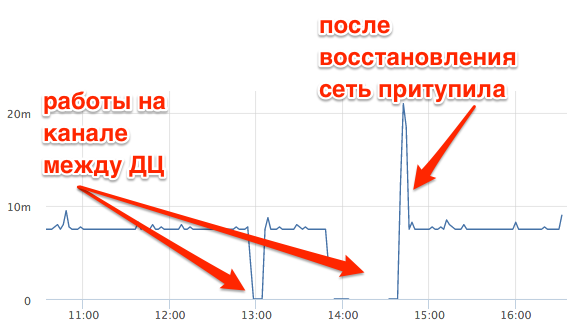
Это TCP RTT между мастер-БД и репликой в другом датацентре. Хорошо видно, как пропадала связь во время работ на канале, как притормаживала сеть после восстановления. При этом TCP RTT ~7ms при ping ~ 0.8ms.
Метрики OS
Мы, как и все, смотрим на использование CPU, памяти, дисков, утилизацию дисков по IO, трафик на сетевых интерфейсах, packet rate, использование swap. Отдельно нужно упомянуть swap i/o — очень полезная метрика, позволяет понять, использовался ли реально swap или в нем просто лежат неиспользуемые страницы.
Но этих метрик бывает недостаточно, если хочется задним числом понять, что происходило на сервере. Например, посмотрим на график CPU на мастер-сервера БД:

Что это было?
Для ответа на подобные вопросы у нас есть метрики по всем запущенным процессам:
- CPU per process+user
- Memory per process+user
- Disk I/O per process+user
- Swap per process+user
- Swap I/O per process+user
- FD usage per process+user
Примерно в таком интерфейсе мы можем “играться” с метриками в реальном времени:
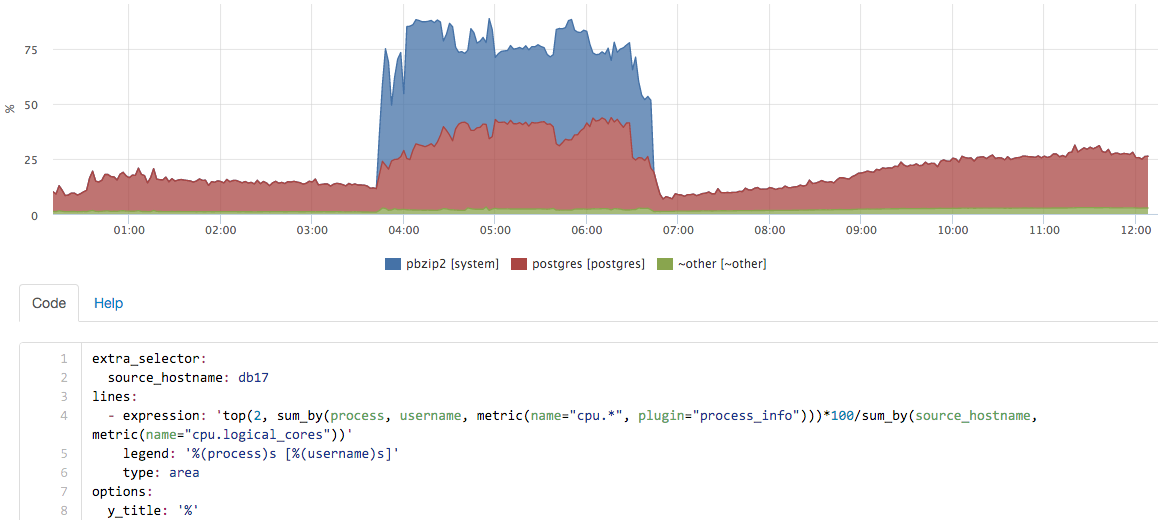
В данном случае на сервере у нас запускался бэкап, сам pg_dump проц практически не использовал, а вот вклад pbzip2 хорошо виден.
Резюмируем
Под мониторингом можно понимать много разных инструментов. Например можно внешним сервисом проверять доступность главной страницы раз в минуту, таким образом вы можете узнать об основных сбоях. Нам этого было мало, мы хотели научиться видеть полную картину качества работы сайта. С текущим решением мы видим все значимые оклонения от обычной картины.
Вторая часть задачи — сократить длительность инцидентов. Здесь нам сильно помогло “ковровое” покрытие мониторингом всех компонентов. Отдельно пришлось заморочиться с простой визуализацией большого количества метрик, но после того, как мы сделали хорошие дашборды, жизнь сильно упростилась.
—
Статья написана по мотивам моего доклада на Highload++ 2015, слайды доступны тут.
Не могу не упомянуть сервис мониторинга okmeter.io, которым мы пользуемся уже больше года.
Комментарии (11)


zapimir
08.12.2015 16:17Спасибо за интересную статью, не хватает еще скриншота общего дашбоарда для полной картины.

NikolaySivko
08.12.2015 16:25+3основной выглядит как-то так (он на плазмах в офисе крутится)
дальше уже отдельные по сервисам/базам итд
{kind=link}

ArjLover
12.12.2015 00:28Второй график действительно напрягает. 18 секунд до отрисовки страницы? Тут что-то определенно не так. Но другой отметки на графики нет. Какой-то рендеринг после tranfer-а должен быть…
NikolaySivko
14.12.2015 20:42+1Ну в данном вопросе мы просто сделали, как просили фронтендеры. Конечно рендерится все раньше 18 секунд. Детальнее раскрыть этот вопрос не могу, я тут не силен.
Scf
15.12.2015 10:48Какой софт используете для визуализации данных?
andshorin
15.12.2015 12:27+1«Не могу не упомянуть сервис мониторинга okmeter.io, которым мы пользуемся уже больше года.»

alekciy
16.12.2015 10:27А что с поддежкой браузерами Navigation Timing? Как я понимаю, сейчас только IE да Chrome его реализовали. Т.е. по сути метрики снимаются только у части посетителей.
mcleod095
А чем снимаются показания TCP RTT? Свой софт или используете открытый?
NikolaySivko
По нашей просьбе доработали агента (мы используем saas), код не наш. Снимать можно либо через ss из iproute2 (достаточно дешево), либо напрямую через netlink
Мы все снимаем раз в минуту, если 2 машины постоянно общаются — этого достаточно.