
2-3 абзаца — привычный размер входного текста для языковых моделей. Больше — тяжело, потому что вычислительная сложность растет квадратичным образом. Поэтому битва за удлинение контекста продолжается и постоянно возникают новые, общие или не очень, подходы. В этом обзоре мы расскажем о двух подходах, связанных с суммаризацией большого текста. Первый — LOCOST — направлен на длинные тексты (статьи и целые книги). Второй — SPECTRUM — на долгие диалоги.
LOCOST
Это архитектура энкодер-декодер, но на базе модели пространства состояний. (немного писали об этом в нашем канале). Вообще само развитие SSM (state space models) в эпоху тотальной доминации трансформеров мотивируется как раз тем, что они способны работать с контекстом на несколько порядков длиннее, а сложность у них при этом линейная. Пока что архитектуры на основе SSM использовали или только декодер, или только энкодер. В первом случае — для безусловной авторегрессионной генерации, во втором — для sequence classification. Генерация условного текста, например, составление саммари с помощью SSM пока не показывает блестящих результатов.
LOCOST (статья) нацелен именно на это. Авторы предлагают архитектуру типа энкодер-декодер на базе SSM для суммаризации текста. Вроде бы получилось составить краткий пересказ целой книги аж в 600 тысяч токенов
Итак, вместо механизма внимания будем использовать модель пространства состояний. Скрытые состояния и выход задаются через систему рекуррентных соотношений. Связь между предыдущим и следующим состоянием линейная, поэтому развернуть всю рекуррентную цепочку до выхода можно одним ходом с помощью свертки. Вообще, обычная свёртка даст ту же квадратичную сложность, что у трансформера ( и те же сложности с длиной входа), и сделает SSM бессмысленным. Но можно применить быстрое преобразование фурье, который даёт сложность LlogL. Следующий важный вопрос — нужно не просто научиться воспринимать длинный контекст, но и не потерять при этом локальные связи. Для этого в LOCOST свёртка идет в двух противоположных направлениях, результаты просто суммируются (на схеме энкодера слева это обозначено как BiSSM).
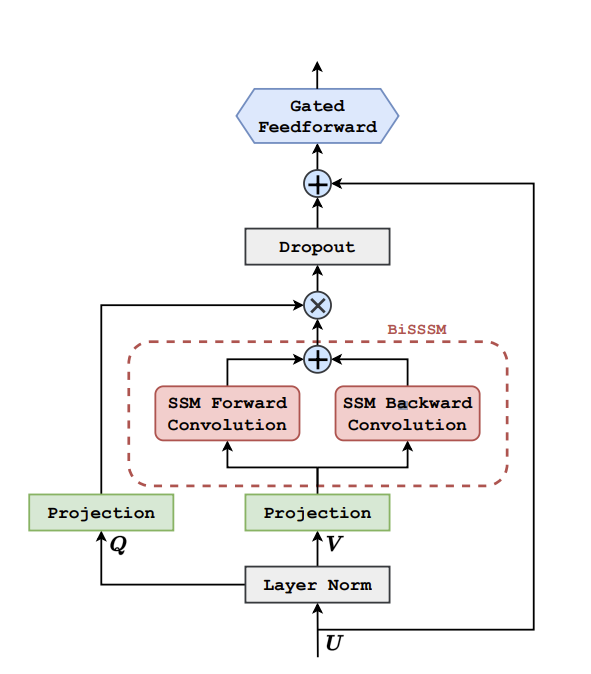
С декодером в LOCOST не стали придумывать ничего нового, так как изначально модель заточена на генерацию маленького текста из большого. Авторы использовали декодер из vanilla transformer.
Модель оценивали метриками ROUGE-1/2/Lsum, а также BERTScore и BLANC. А файнтюнинг проводили на научных статьях из arXiv и PubMed (таргетом были собственно абстракты статей) и на датасетах с пересказами кино, книг и правительственных отчетов США.
Еще один интересный момент — не совсем понятно, как качественно оценить результат, ведь для этого придётся прочитать все эти статьи и книги в полном объёме. GPT это не скормишь, а просить это сделать живых людей слишком дорого. Авторы LOCOST эту проблему не то что бы решили, но оценивали саммари с помощью GPT-3.5 на релевантность и последовательность.

Результаты на входном тексте длиной от тысячи до 500 тысяч токенов примерно соответствуют LongT5 и LED, но вот вычислительные затраты при этом значительно ниже.

учшую модель LOCOST-32K сравнили в задаче суммаризации книги целиком. Она победила LongT5 и BART large, при том что у нее меньше всего параметров. К тому же она единственная смогла прочитать 600 тысяч токенов за один присест без разбиения на части.
SPECTRUM
Привычный человеческий диалог — очень интересная цель для суммаризации, возможно даже интереснее чем просто большой односвязный текст статьи или книги. Дело во внутренней структуре диалога, при которой чередуются реплики участников и в формальной особенности. Люди могут долго не терять общую нить разговора, при этом в явном виде о ней не упоминать. И именно в диалоге как нигде важно следить за глобальным контекстом, который может полностью поменять локальный смысл.
Модели же воспринимают долгие диалоги, как обычный текст. Сама структура при этом теряется.
SPECTRUM (статья) модифицирует процесс переобучения трансформеров так, чтобы сохранялась информация о спикере и внутренняя структура диалога. Обучение идет по двум направлением — предсказания чья очередь говорить и маскированное языковое моделирование. Первое добавляет понимание самого диалога в целом, а второе помогает проследить контекст.
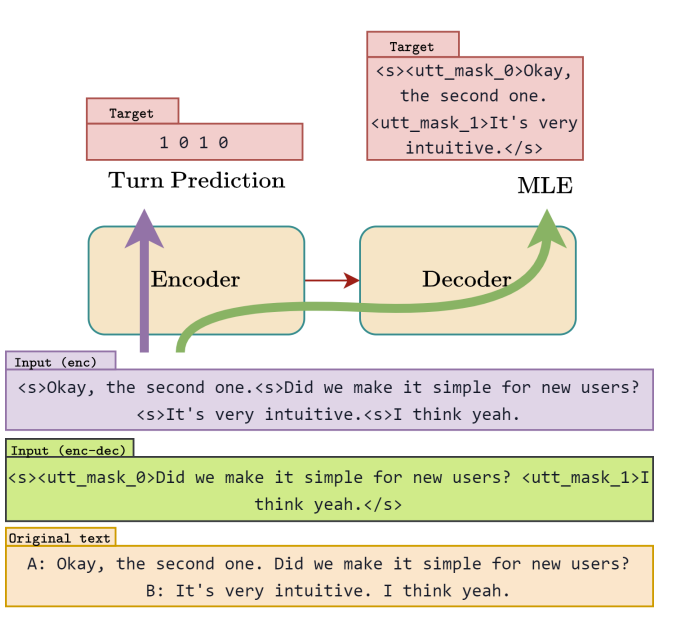
Сама методика обучения тоже разделяется на два пути. Один обновляет только энкодер, а второй — энкодер и декодер. Первый нужен для прогнозирования очередного спикера. Для этого в начало каждого предложения добавляться токен <s> и после энкодера получается последовательность нулей и единиц, обозначающая меняется ли спикер после этого предложения или нет.
Второй путь, маскированное моделирование, идет на уровне предложений (авторы экспериментировали и с уровнем слов, но этот вариант оказался лучшим). Случайным образом выбранные предложения заменяются масками и в таком виде пропускаются полностью через трансформер.
Авторы взяли датасеты с расшифровками интервью, диалогами из книг и дополнили собственным датасет из реальных диалогов — их взяли из кино и сериалов. Туда же добавили диалоги пользователей с GPT-3.5 (датасет Soda). Максимальная длина контекста — 4096 токенов.
Сравнивали результаты примерно с теми же с моделями, что и в случае с LOCOST на той же метрике Rouge .
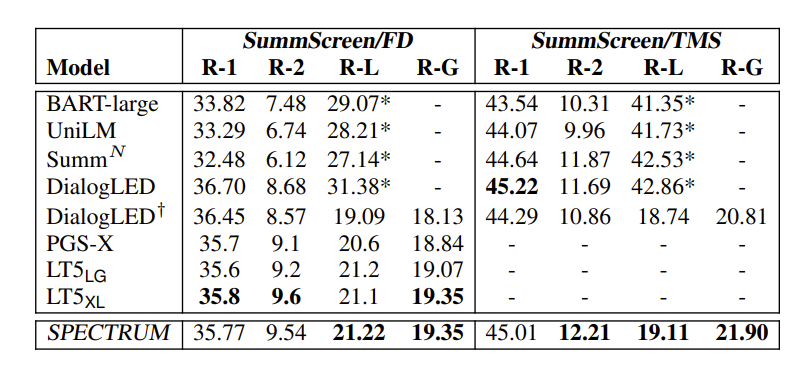
Не безупречно убедительно, но всё же SPECTRUM кое-где превзошел LongT5 и LED, и BART large
Больше наших обзоров AI‑статей на канале Pro AI.