
Даже при наличии качественных входных данных качество предсказаний ML-модели со временем ухудшается. Под катом рассмотрим, как команда Neoflex с помощью мониторинга обнаруживает изменения вовремя и поделимся подборкой open source-библиотек для определения дрифта данных.
Теперь клиенты Selectel могут оптимизировать управление DS/ML-моделями с помощью MLOps-платформы Neoflex Dognauts. Она обеспечивает автоматизацию полного цикла разработки и эксплуатации моделей машинного обучения.
Используйте навигацию, если не хотите читать текст полностью:
→ Почему важен мониторинг дрифта
→ Задачи мониторинга
→ Методы определения дрифта ML-моделей
→ Open source-библиотеки для определения дрифта данных
→ Архитектура решений
→ Заключение
Почему важен мониторинг дрифта
Даже если в модель поступают качественные данные, предсказания со временем могут ухудшаться. Важно вовремя отловить эти изменения и предпринять меры. В этой статье рассмотрим два вида дрифта ML-модели, которые влияют на ее качество.
- Дрифт данных — когда качество предсказания ML-модели изменяется под влиянием статистических свойств входных данных. Объясню на примере. Если распределение возраста и доходов покупателей существенно меняется с течением времени, ML-модель больше не сможет точно предсказывать вероятность покупки.
- Дрифт концепции — когда изменение статистических свойств целевой переменной вызвано изменением концепции того, что мы пытаемся предсказать. Как правило, за это отвечают некоторые глобальные изменения, и примером таких изменений может быть COVID-19.

Ухудшение качества предсказаний при дрифте модели (слева) и предотвращение дрифта при регулярном обновлении модели (справа).
Задачи мониторинга

- Сбор данных, а в случае дрифта концепций еще и объединение с реальными таргетами.
- Детекция дрифта. Здесь происходит расчет метрик входных данных и предсказания ML-моделей. Data Science-специалист задает для них пороговые значения при разработке модели.
- Сохранение (логирование) рассчитанных метрик для дальнейшего анализа и отчетности.
- При превышении пороговых значений — оповещение ML-инженеров или запуск процесса автоматического переобучения модели.
Методы определения дрифта ML-моделей
Если мы говорим о дрифте данных, то каждый столбец рассматриваем по отдельности. В зависимости от его типа — применяем одну из статистических метрик либо алгоритм поиска дрифта. Для числовых полей это будет алгоритм Колмагорова-Смирнова или расстояние Вассерштейна, а для категориальных — Chi-square, Jensen-Shannon или Z-score.
Если мы говорим о дрифте концепций, то здесь иная ситуация. Мы можем либо использовать PSI (Population Stability Index), либо мониторить основные метрики качества работы модели, к примеру, accuracy, f1_score и другие, сравнивая их с пороговыми или эталонными зачениями.
Опишу последовательность действий при поиске дрифта концепций.
- При обучении модели рассчитываем метрики модели на валидационном датасете.
- Определяем пороговые значения для метрик на основе предыдущего пункта.
- Рассчитываем метрики модели на последних данных.
- Сравниваем рассчитанные метрики с пороговыми значениями.
- Фиксируем факты нарушений пороговых значений.
Для расчета метрик вызываем метод mlflow.evaluate, передавая в качестве параметров последние данные и пороговые значения. Полученные результаты анализируем в MLflow UI.
Open source-библиотеки для определения дрифта данных
Data Drift Detector
Эту библиотеку можно назвать наиболее простой из подборки. Data Drift Detector считает основные метрики дрифта и обладает минимальным количеством настроек, но не дает заключения о наличии дрифта в столбцах и датасетах. Библиотека идеально подойдет для домашнего использования или pet-проектов.
Evidently AI
С помощью Evidently AI можно получать как визуализированные отчеты, так и JSON-файлы для дальнейшей обработки. Есть интеграция с Airflow, MLflow, Grafana. На больших датасетах процесс может быть долгим из-за ограничений Pandas, так что для работы с ними советую рассмотреть следующую библиотеку.

Whylogs
Вероятно, если вам нужно работать с большими данными, то Whylogs — это идеальный кандидат. Библиотека обладает функциональностью по профилированию данных, интегрируется со Spark и Dask. В числе прочего есть возможность работы с MLflow для сохранения отчетов.

Alibi Detect
Alibi Detect — это одно из лучших решений для онлайн-мониторинга дрифта. Среди преимуществ библиотеки можно отметить легкое развертывание модели в Seldon и большой арсенал алгоритмов Drift Detection для режимов онлайн и офлайн.

Архитектура решений
Рассмотрим базовую модель Neoflex. Она выдает бинарный ответ на вопрос о том, стоит ли выдавать клиенту кредит. Как мы видим, accuracy на валидационном датасете составляет 88%:
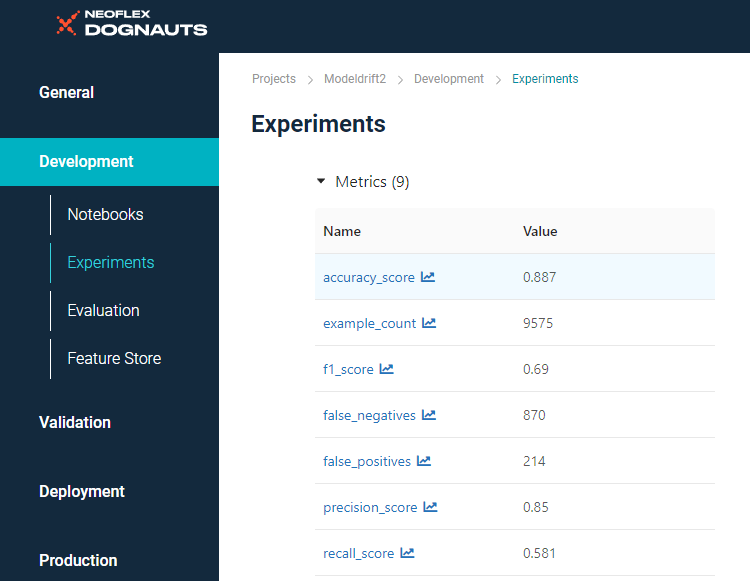
С этой моделью мы залогировали config.json, в котором прописываем путь к эталонному датасету, в нашем случае — датасету Wistia. Также мы определяем категориальные поля и колонки, которые будут участвовать в определении дрифта:
{
"type": "feast_dataset",
"fs_path": ".",
"dataset_path": "loan_approval_baseline",
"categorical_features": [
"person_home_ownership",
"loan_internet",
"state"
],
"cols_to_drop": [
"created _timestamp",
"event_timestamp",
"loan_id",
"zipcode",
"dob_ssn",
"city",
"location_type"
]
}
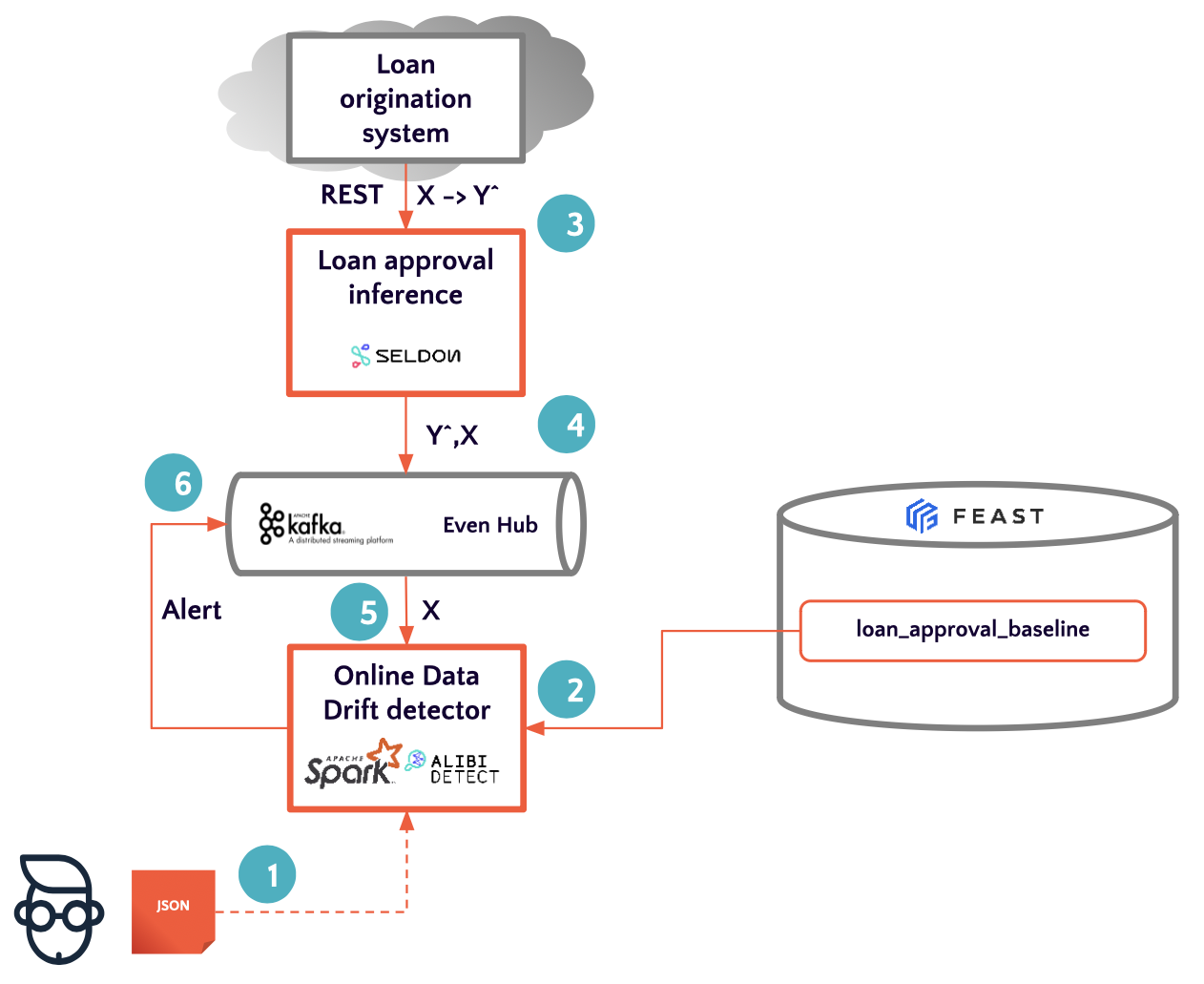
Онлайн-детектирование
Для онлайн-детектирования дрифта мы используем уже упомянутую Alibi Detect, так как она обладает большой совместимостью. Вдобавок наша модель деплоится в Seldon.
При работе с онлайн-дрифтом сценарий работы состоит из нескольких действий.
- Определяем пороговые значения для метрик дрифта нашего алгоритма.
- Инициализируем и обучаем алгоритм.
- Разворачиваем модель как REST-сервис.
- Логируем входы и выходы модели.
- Полученные данные прогоняем через детектор.
- Рассылаем оповещение при наличии дрифтов.
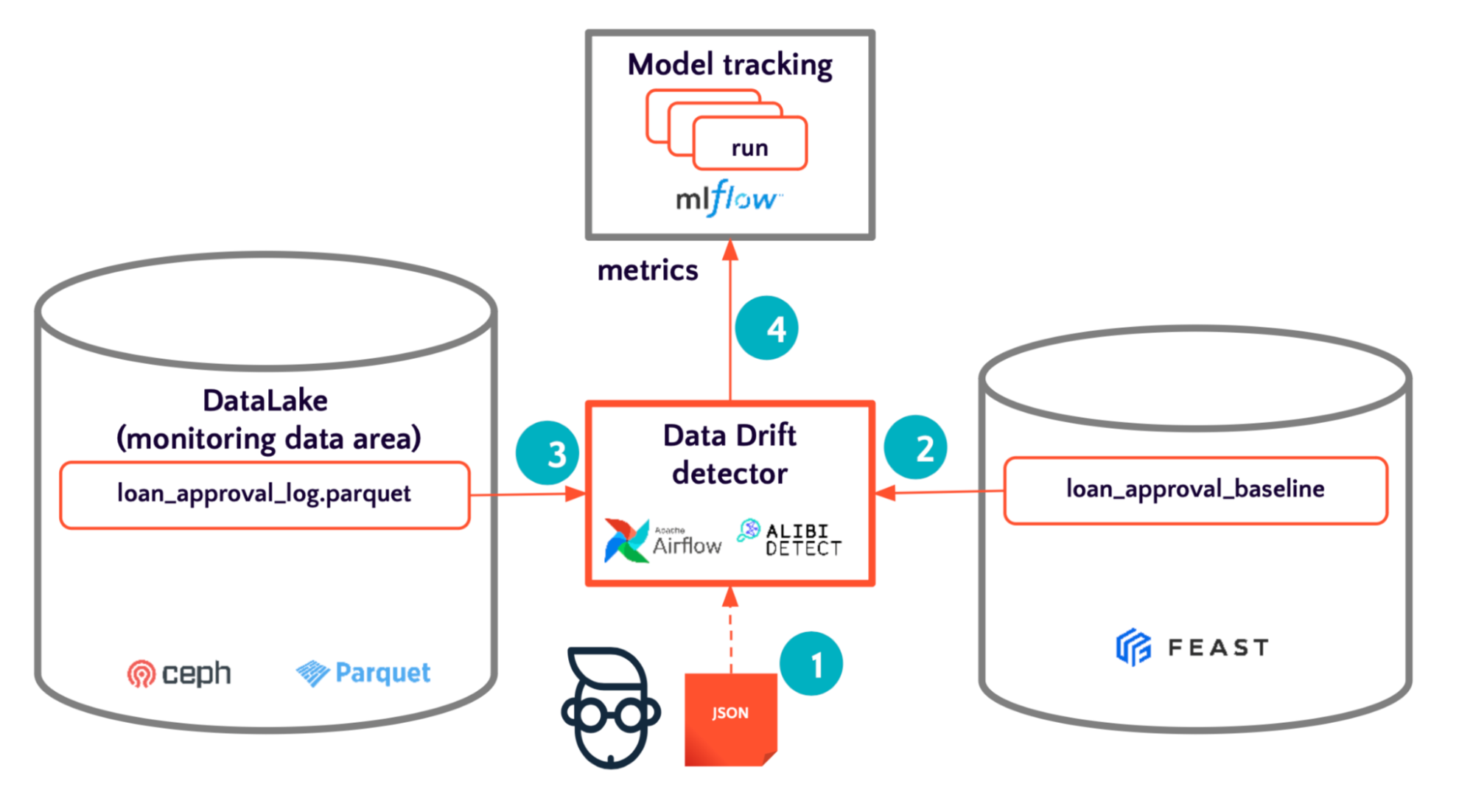
Оффлайн-детектирование
Алгоритм действий для оффлайн-детектирования дрифта.
- Определяем пороговые значения для метрик дрифта нашего алгоритма.
- Инициализируем и обучаем алгоритм.
- Применяем алгоритм поиска дрифта до последних данных.
- Сохраняем результаты.
Все пороговые значения наших метрик описываем в thresholds.json:
{
"data_drift": [
{
"metric_name": "min_chi_square",
"threshold": 0.05,
"higher_is_better": true
},
{
"metric_name": "mean_chi_square",
"threshold": 0.05,
"higher_is_better": true
},
{
"metric_name": "min_ks_test",
"threshold": 0.05,
"higher_is_better": true
},
{
"metric_name": "mean_ks_test",
"threshold": 0.05,
"higher_is_better": true
}
],
"concept_drift": [
{
"metric_name": "accuracy_score",
"threshold": 0.8,
"higher_is_better": true
}
]
}
Замечу, что мы ограничиваем минимальные и средние значения для Chi-square и теста Колмагорова-Смирнова на значении 0,05, что является общей практикой.
Далее, чтобы применить наш метод, щпереписали функцию evaluate под собственные нужды.
class BasicDriftEvaluator(ModelEvaluator):
def_evaluate(self, categorical_columns=None):
cd = TabularDrift(self.df_prior-values, p_val=drift_threshold, categories_per_feature=categories_per_feature)
preds = cd.predict(self.df_post.values)
labels = ['No!', 'Yes!']
result = {}
chi_arr = []
ks_arr = []
for f in range(cd.n_features):
stat = 'Chi2' if f in list(categories_per_feature.keys()) else 'K-S'
chi_arr.append(preds['data']['p_val'][f]) if f in list(categories_per_feature.keys()) else ks_arr.append(preds['data']['p_val'][f])
fname = feature_names[f]
stat_val, p_val = preds['data']['distance'][f], preds['data']['p_val'][f]
col_res = {
'Drifted': 1 if p_val < drift_ threshold else 0,
stat: round(stat_val.item(), 3),
'p_value': round (p_val.item(), 3),
}
result.update({
fname: dict(col_res),
})
json_name = 'drift_result'
{
"type": "feast_dataset",
"fs_path": ".",
"dataset_path": "loan_approval_baseline",
"categorical_features": [
"person_home_ownership",
"loan_intent",
"state"
],
"cols_to_drop": [
"created_timestamp",
"event_timestamp",
"loan_id",
"zipcode",
"dob_ssn",
"city",
"location_type"
]
}
Под капотом функция использует алгоритм Tabular Drift из библиотеки Alibi Detect. Из config.json собираем данные, с которыми будем сравнивать входящие. Далее — определяем категориальные переменные и удаляем колонки, которые не будут участвовать в детекции дрифта. Упомянутый evaluator возвращает отчет о каждом столбце и наличии дрифта.
Для перемещения данных у нас есть DAG в Airflow, который принимает имя датасета как параметр, а затем подставляет его в функцию evaluate для сравнения с эталонным показателем.

DATASET _NAME = Variable.get("data_drift_dataset")
with DAG(
dag_id = "data _drift_detect",
default_args=default_args,
# schedule_interval='0 0 * * *',
schedule_interval='@once',
dagrun_timeout=timedelta(minutes=60),
description='detect model data drift',
start_date = airflow.utils.dates.days_ago(1),
catchup=False
) as dag:
В настройках evaluator указываем кастомный evaluator и прописываем пороговые значения. Так мы получаем отчеты о валидации.
try:
result = mlflow.evaluate(
baseline_uri,
data=eval_data,
targets=target,
model_type="classifier",
evaluators=["basic_drift_evaluator"],
validation_thresholds=thresholds,
)
except ModelValidationFailedException as e:
with open("evaluate.log", "w") as text_file:
text_file.write(str(e))
mlflow. log_artifact("evaluate.log", artifact_path="logs")
run_id = current_run.info.run_id
print(run_id)
Мы прогнали детектор по двум месяцам с клиентскими данными (заявками на кредит). По показателям за первый месяц можем заметить, что к нам пришли те же клиенты, что и раньше. Дрифт не был обнаружен, средние и минимальные значения в пределах нормы:
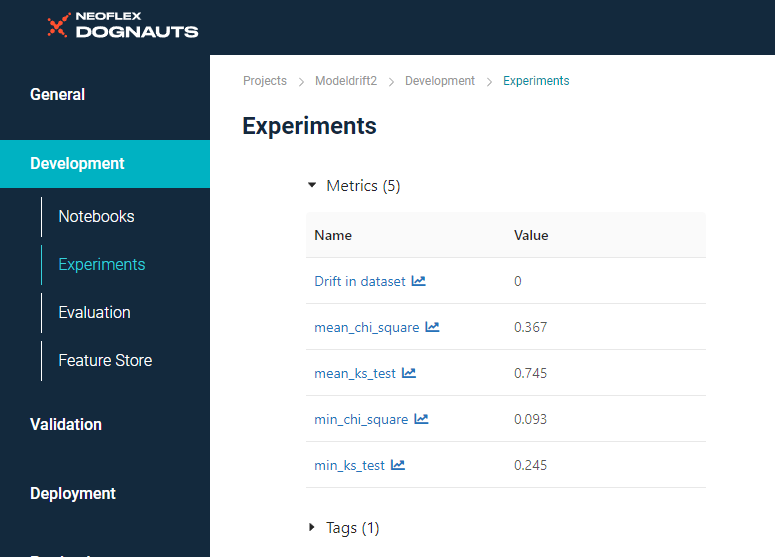
Показатели за первый месяц.
Со вторым месяцем ситуация обратная. Дрифт был обнаружен, а минимальные значения значительно ниже пороговых:

Показатели за второй месяц.
В артефактах MLflow видим сообщения о том, что метрики не прошли валидацию (сравнение с пороговыми значениями):

Здесь же можем ознакомиться с отчетом по каждому столбцу:

По данным за второй месяц у клиентов изменились доходы и возраст, из-за чего модель может давать неверные результаты.
Дрифт концепций
Напомню, что дрифт концепций — это изменение статистических свойств целевой переменной, вызванное изменением концепции того, что мы пытаемся предсказать. Рассмотрим алгоритм действий при работе с этим типом дрифта.
- Соединяем данные с реальными таргетами.
- Определяем пороговые значения для метрик.
- Сравниваем метрики между собой.
- Сохраняем результаты оценки.

У нас есть данные по кредитным заявкам за третий и четвертый квартал — это датасеты в Feast, уже обогащенные реальными таргетами.

Так как на валидационном датасете получили 88% качества, поставим ограничение для метрики accuracy в 80%:
{
"data_drift": [
{
"metric_name": "min_chi_square",
"threshold": 0.05,
"higher_is_better": true
},
{
"metric_name": "mean_chi_square",
"threshold": 0.05,
"higher_is_better": true
},
{
"metric_name": "min_ks_test",
"threshold": 0.05,
"higher_is_better": true
},
{
"metric_name": "mean_ks_test",
"threshold": 0.05,
"higher_is_better": true
}
],
"concept_drift": [
{
"metric_name": "accuracy_score",
"threshold": 0.8,
"higher_is_better": true
}
]
}
Также у нас есть DAG, который принимает имя датасета как параметр. Прогоняем два квартала через него. Полученные результаты удобно сравнивать в MLflow с помощью функции compare:

Результаты работы базовой модели на валидационном тесте, третьем и четвертом квартале.
За четвертый квартал значительно упало качество работы модели, а за третий все показатели в норме. Отчет о валидации, которую модель не прошла, доступен в артефактах MLflow. Таким образом мы можем мониторить дрифт концепций:

Если вам интересна тема статьи, присоединяйтесь к сообществу «MLечный путь» в Telegram. Там мы вместе обсуждаем проблемы и лучшие практики организации production ML-сервисов, а также делимся собственным опытом. А еще там раз в неделю выходят дайджесты по DataOps и MLOps.
Заключение
Если вы только находитесь в поиске инструментов для работы с дрифтом данных, то советую ориентироваться на функциональность, которая у вас уже есть, и на те продукты, которые вы используете.
В случае с нашей платформой, причины выбора инструментов вполне прозаичны. MLflow уже стоял на платформе и подходил по функциональности, что сэкономило время на поиск подходящего фреймворка. Для онлайн-мониторинга дрифта мы используем библиотеку Alibi Detect, так как она хорошо работает с Seldon.
С демонстрацией работы модели от Neoflex и другими докладами на тему ML вы можете ознакомиться на YouTube:
Автор доклада «Определение дрифта ML-моделей»: Анастасия Коткова, ML-инженер в Neoflex.
Читайте также:
→ Вызволяем увлажнитель из сетей Xiaomi
→ И снова дискеты: американская система управления поездами в Сан-Франциско полностью зависит от флоппи-дисков
→ Fairphone: не только модульный телефон, но и беспроводные наушники со сменным аккумулятором