

Одна из проблем, с которыми мне часто доводится сталкиваться в различных софтверных проектов — это сильная связанность кода, при которой в него так сложно вносить даже простые изменения, не провоцируя нежелательных побочных эффектов. Дело в том, что программисты склонны сосредотачиваться на разработке конкретных фич, не задумываясь о том, как база кода станет развиваться в будущем. Также не все учитывают, что применяемые сегодня библиотеки и фреймворки могут постепенно сойти со сцены спустя несколько месяцев или лет.
На старте проекта приходится принимать множество решений. Большинство инженеров при этом рассматривают область применения проекта и решают, при помощи каких инструментов он будет реализовываться. Речь, в частности, о языках программирования, фреймворках, базах данных, внешних API, вариантах развёртывания. Принимая такие решения на самых ранних этапах, они замыкаются на этих инструментах, пронизывают ими всю базу кода, в результате чего её становится сложно менять и поддерживать.
Большинство этих инструментов – это частности, и выбор большинства из них (кроме языка программирования) можно на некоторое время отложить, пока проект не окрепнет. Поэтому на ранних этапах разработки проекта стоит уделить внимание не тому, при помощи каких инструментов пойдёт реализация. Лучше смоделировать предметную область проекта, а к вышеупомянутым инструментам подходить так, как следует — то есть, как к частностям. Разумеется, чтобы проект был реализован, с такими деталями тоже нужно определиться, но они могут оставаться в некоторой отдельной части кода, не относящейся к предметной области — там, где их будет легко менять, удалять или заменять по нашему усмотрению.
Для решения именно таких проблем с сильной связностью кода многоопытные инженеры создали ряд архитектурных паттернов. Таковы, в частности, чистая архитектура Роберта Мартина («дядюшки Боба»), гексагональная архитектура Алистера Кокбёрна и явная архитектура Герберто Грацы.
В данной статье будет показано, как мне удалось выстроить этот блог при помощи концепций, относящихся к этим системам. В основном я придерживался чистой архитектуры, но также заимствовал некоторые концепции и принципы именования из других систем. Весь код написан на языке Go, но разобранные здесь идеи применимы к любому языку.
❯ Слои
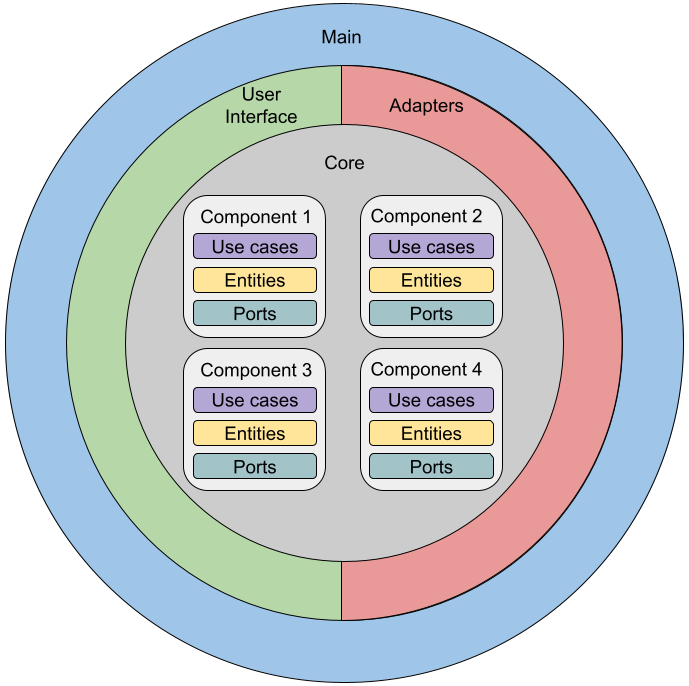
Слои делятся на четыре основные категории: ядро (Core), адаптеры (Adapters), пользовательский интерфейс (User Interface) и главный (Main). Каждый из них объяснён ниже.
Ядро
Это ядро приложения, и в нём содержатся исключительно правила бизнес-логики. У всех компонентов этого слоя нет каких-либо внешних зависимостей. Все тесты проходятся без запуска какого-либо веб-сервера или сервера базы данных.
Слой ядра делится на компоненты ядра. На уровне этих компонентов приложение удобно разделить на независимые части, каждую из которых можно разрабатывать отдельно. В моём проекте есть всего один ядерный компонент, он называется
blog. Примеры других компонентов, также относимых к ядерным — это comment, authentication или authorization.Внутри каждого из ядерных компонентов выделяется 3 вида элементов:
- Юзкейсы – в этих объектах реализуется каждое из действий, совершаемых в системе. Они могут быть инициированы пользователем или выполняться как запланированные задания, либо срабатывать в качестве реакции на событие. В них содержатся только высокоуровневые определения политик, а нужны они для оркестрации элементов другого рода.
- Сущности – это объекты и правила бизнес-логики в наиболее чистом виде. Это могут быть как простые структуры данных, так и более сложные объекты, но в них не заложено никакой информации о персистентности или механизмах доставки. Эти объекты пригодны для совместного использования между другими слоями приложения.
- Порты – это просто интерфейсы, применяемые при работе с юзкейсами. Любая точка сцепления кода с базой данных или с внешней библиотекой — это порт, относящийся к ядерному слою.
Для всех ядер характерно поведение такого рода: юзкейс вызывается из другого слоя, получающего некоторые данные, после чего из долговременного хранилища загружается некоторая сущность, и это делается при помощи порта. После этого код работает с сущностью, генерирующей его новое состояние. В этом процессе могут использоваться другие порты и сущности. В конце концов, сущность вновь долговременно сохраняется в юзкейсе с использованием порта, после чего возвращается ожидаемый результат.
Адаптеры
Каждый адаптер реализует интерфейс порта, используемый ядром. Любая внешняя зависимость, будь то библиотека, фреймворк, внешний API или база данных, проходит через адаптер. Адаптер — это низкоуровневый компонент, управляемый на уровне высокоуровневой политики (юзкейса). Такая структура позволяет предусмотреть множество адаптеров для одного и того же порта. Также можно расширять поведение адаптера, пользуясь такими паттернами проектирования, как Компоновщик (Composite) или Декоратор (Decorator).
Пользовательский интерфейс
Именно в слое UI пользователь взаимодействует с программой. В этом слое может находиться множество инструментов доставки контента, например, сайт (HTML), REST API, GraphQL, gRPC, CLI. Каждый из них — отдельный компонент в слое UI.
Главный слой (приложение)
Именно в «главном» слое (Main) происходят все подключения. Этому слою известно всё о других слоях, в том числе, как инициализировать все компоненты с правильными зависимостями. Поскольку имя пакета
main в Go зарезервировано, в рассматриваемой далее реализации блога этот слой будет называться app.❯ Проект блога
Проект блога устроен следующим образом. Посты пишутся в виде разметки (формат Markdown) и сохраняются в виде текстовых файлов в каталоге
/posts. Всякий раз, когда с веб-сервера запрашивается конкретный пост, загружается файл с этим постом, который затем проходит синтаксический разбор. После этого содержимое разметки преобразуется в HTML, и результат этой операции возвращается пользователю. Формат файла с постом таков:
title: Заголовок поста
author: Имя автора
description: описание поста
image_path: /static/image/sample-image.jpg
time: год-месяц-день часов:минут
--
## Содержимое разметки❯ Реализация
Этот проект реализован по методологии «разработка через тестирование» (Test-Driven Development), но, чтобы не усложнять данную статью, в ней опущены сами тесты, равно как и некоторые фрагменты кода. Полный исходный код к посту выложен в этом репозитории на GitHub.
Далее в этом посте разберём реализацию юзкейса просмотреть пост в разрезе всех слоёв. Другие юзкейсы структурно устроены примерно так же, и весь код по ним выложен в репозитории на GitHub.
Структура каталогов
В данном проекте я придерживаюсь стандартной структуры каталогов, принятой в сообществе Go. Эта структура выложена в репозитории компоновки проекта на GitHub.
Разберём каталоги по отдельности:
- cmd – здесь находится главный файл механизма доставки контента (веб).
- deployment – скрипты развёртывания.
- internal – наиболее важный каталог, здесь содержатся реализации всех слоёв и компонентов.
- pkg – пакеты, не зависящие от проекта. Они нужны для «расширения» языка. Каждый из этих пакетов можно выпустить как самостоятельную библиотеку.
- posts – каталог, специфичный для данного проекта. Здесь хранятся написанные посты, включая разметку для них.
- test – содержит интеграционные тесты и другие ресурсы для тестирования.
- web – материал для представления в Вебе, в частности, шаблоны и статические файлы.
Ядро
К реализации любой фичи я всегда приступаю с разработки юзкейса. Юзкейсы закладываются на уровне ядра, внутри тех компонентов, к которым относятся. Поскольку наше приложение достаточно маленькое, здесь всего один такой компонент —
blog.Юзкейс всегда реализует высокоуровневую политику, описывающую работу с фичей, а низкоуровневые детали остаются на долю адаптеров, подключённых к портам. Каждый юзкейс представлен в формате структуры (класса) с методом
Run. В структуре содержатся зависимости, а аргументы запроса передаются непосредственно в метод Run. Вот реализация blog.ViewPostUseCase:// internal/blog/view_post_use_case.go
package blog
type ViewPostUseCase struct {
postRepo PostRepo
renderer Renderer
}
func NewViewPostUseCase(postRepo PostRepo, renderer Renderer) *ViewPostUseCase {
return &ViewPostUseCase{postRepo: postRepo, renderer: renderer}
}
func (u *ViewPostUseCase) Run(path string) (RenderedPost, error) {
post, err := u.postRepo.GetPostByPath(path)
if err != nil {
return RenderedPost{}, err
}
return u.renderPost(post)
}
func (u *ViewPostUseCase) renderPost(post Post) (RenderedPost, error) {
renderedContent, err := u.renderer.Render(post.Markdown)
if err != nil {
return RenderedPost{}, err
}
return RenderedPost{
Post: post,
HTML: renderedContent,
}, nil
}Метод
Run получает в качестве аргумента путь к посту. На основе этого пути он загружает Post (сущность) из PostRepo (порт). Если такой пост найден, он отображает разметку этого поста при помощи Renderer (порт). Наконец, он собирает и возвращает RenderedPost (сущность).Post — это простая структура данных, в которой содержится информация поста, возвращённая PostRepo. Есть и другая структура данных RenderedPost, построенная внутри юзкейса. В ней содержится оригинал поста и отображённый HTML в таком виде, в котором он должен быть подан в UI.Порты
PostRepo и Renderer — это интерфейсы, к которым можно подключать адаптеры. Теперь можно собрать весь юзкейс целиком.Вот как реализуются порты и сущности:
// internal/blog/entities.go
package blog
import "time"
type Post struct {
Title string
Author string
Time time.Time
Path string
Description string
ImagePath string
Markdown string
}
type RenderedPost struct {
Post Post
HTML string
}
// internal/blog/ports.go
package blog
import "errors"
type PostRepo interface {
GetPostByPath(path string) (Post, error)
}
var ErrPostNotFound = errors.New("post not found")
type Renderer interface {
Render(content string) (string, error)
}Адаптеры
Адаптеры — это низкоуровневые детали, управление которыми идёт из юзкейсов. Они хранятся в следующей структуре каталогов:
internal/adapters/PORT/ADAPTER_TYPE, где PORT — это имя порта, реализуемого адаптером, а ADAPTER_TYPE — это тип адаптера для данного порта. В данном случае имеем адаптер FileSystem для порта PostRepo и адаптер Goldmark для порта Renderer, причём, последний назван по той библиотеке Markdown, которую он «адаптирует». Начиная с
PostRepo, реализация такова:// internal/adapters/postrepo/filesystem/post_repo.go
package filesystem
import (
"io/ioutil"
"path/filepath"
"github.com/geisonbiazus/blog/internal/core/blog"
)
type PostRepo struct {
BasePath string
}
func NewPostRepo(basePath string) *PostRepo {
return &PostRepo{BasePath: basePath}
}
func (r *PostRepo) GetPostByPath(path string) (blog.Post, error) {
content, err := ioutil.ReadFile(filepath.Join(r.BasePath, path+".md"))
if err != nil {
return blog.Post{}, blog.ErrPostNotFound
}
post, err := ParseFileContent(string(content))
post.Path = path
return post, err
}В
filesystem.PostRepo реализуется интерфейс blog.PostRepo. GetPostByPath получает путь, фактически, идентификатор поста в системе, далее читает файл, который находит в конструкторе репозитория, проследовав по этому пути, а затем разбирает синтаксис этого файла. Это делается при помощи функции ParseFileContent, генерирующей сущность blog.Post.Для простоты я не привожу здесь реализацию функции
ParseFileContent. С её реализацией, а также с соответствующими ей тестами можете познакомиться на GitHub.Второй адаптер, используемый в
ViewPostUseCase — это Renderer (см. реализацию ниже): // internal/adapters/renderer/goldmark/renderer.go
package goldmark
import (
"bytes"
"github.com/alecthomas/chroma/formatters/html"
"github.com/yuin/goldmark"
highlighting "github.com/yuin/goldmark-highlighting"
)
type Renderer struct{}
func NewRenderer() *Renderer {
return &Renderer{}
}
func (r *Renderer) Render(content string) (string, error) {
var buf bytes.Buffer
markdown := goldmark.New(
goldmark.WithExtensions(
highlighting.NewHighlighting(
highlighting.WithStyle("monokai"),
highlighting.WithFormatOptions(
html.TabWidth(2),
),
),
),
)
err := markdown.Convert([]byte(content), &buf)
if err != nil {
return "", err
}
return buf.String(), nil
}Как и в случае с репозиторием постов, структура
goldmark.Renderer реализует интерфейс blog.Renderer. С её помощью мы абстрагируем от юзкейса то, как именно разметка преобразуется в HTML. Для этого применяется библиотека goldmark.Обратите внимание: в этом и только в этом файле используется и вообще упоминается библиотека
goldmark. Поэтому становится проще расширять поведение этой библиотеки или вообще заменить её в процессе развития проекта. Вот в чём по-настоящему полезны адаптеры.Пользовательский интерфейс
Для доставки контента в этом блоге используются технологии HTTP и HTML. Поэтому назову этот компонент с «веб-сайтом»
web. В этот пакет попадает всё, что касается работы в вебе, в частности, сервер, маршрутизатор и обработчики (в других языках и фреймворках их могут называть «контроллерами»).Начнём с обработчика. Каждый обработчик, чтобы получить результат, первым делом вызывает юзкейс из слоя ядра. Ради упрощения тестируемости каждый юзкейс представлен как порт в пакете
web, примерно так, как представлены адаптеры в пакете ядра. Здесь реализация юзкейса — это «адаптер» данного порта в слое UI. Порт юзкейса определяется следующим образом:// internal/ui/web/ports.go
package web
import "github.com/geisonbiazus/blog/internal/core/blog"
type ViewPostUseCase interface {
Run(path string) (blog.RenderedPost, error)
}В других языках, например, в Java или C#, где требуется явно упоминать реализуемый интерфейс, этот порт определялся бы внутри слоя ядра. Так они получаются работоспособными, ничего не зная о внешних слоях. Так мы не создаём циклических зависимостей. Но, поскольку в Go интерфейсы реализуются неявно, можно держать интерфейс поближе к тому месту, где он используется, не вызывая при этом сильной связности.
Обустроив порт для юзкейса, переходим к реализации обработчика, которая делается вот так:
// internal/ui/web/view_post_handler.go
package web
import (
"fmt"
"html/template"
"net/http"
"path"
"github.com/geisonbiazus/blog/internal/core/blog"
)
type ViewPostHandler struct {
usecase ViewPostUseCase
template *TemplateRenderer
}
func NewViewPostHandler(
usecase ViewPostUseCase, templateRenderer *TemplateRenderer,
) *ViewPostHandler {
return &ViewPostHandler{
usecase: usecase,
template: templateRenderer,
}
}
func (h *ViewPostHandler) ServeHTTP(
res http.ResponseWriter, req *http.Request,
) {
path := path.Base(req.URL.Path)
renderedPost, err := h.usecase.Run(path)
switch err {
case nil:
res.WriteHeader(http.StatusOK)
h.template.Render(res, "view_post.html", h.toViewModel(renderedPost))
case blog.ErrPostNotFound:
res.WriteHeader(http.StatusNotFound)
h.template.Render(res, "404.html", nil)
default:
res.WriteHeader(http.StatusInternalServerError)
h.template.Render(res, "500.html", nil)
}
}
func (h *ViewPostHandler) toViewModel(p blog.RenderedPost) postViewModel {
return postViewModel{
Title: p.Post.Title,
Author: p.Post.Author,
Description: p.Post.Description,
ImagePath: p.Post.ImagePath,
Path: fmt.Sprintf("/posts/%s", p.Post.Path),
Date: p.Post.Time.Format(DateFormat),
Content: template.HTML(p.HTML),
}
}
type postViewModel struct {
Title string
Author string
Date string
Description string
ImagePath string
Path string
Content template.HTML
}Структура
web.ViewPostHandler реализует внутренний интерфейс Go http.Handler, который по умолчанию используется для обработки HTTP-запросов при помощи стандартной библиотеки. Метод ServeHTTP извлекает из запроса путь к посту, а затем выполняет юзкейс и при этом получает blog.RenderedPost и возможный результат ошибки. В зависимости от результата ошибки устанавливается соответствующий код состояния, а далее при помощи модуля web.TemplateRenderer отображается шаблон.В случае успеха генерируется
postViewModel. В этой модели представления содержится вся информация о посте в правильно отформатированном виде, готовая к отображению в пользовательском интерфейсе. После этого модель представления передаётся обработчику шаблонов (template renderer), который просто сгенерирует итоговый HTML и выведет его пользователю. Обработчик шаблонов, роутер и сервер также входят в состав пакета web, но рассказ об их реализации выходит за рамки этого поста. Их код можно посмотреть на GitHub.
Приложение
Когда готовы реализации всех этих слоёв и компонентов, остаётся всего лишь собрать всё вместе. Эти связи прокладываются именно в слое app. Этому компоненту известно обо всех других компонентах, он понимает, какие зависимости связаны с каждым из компонентов. Вот реализация:
// internal/app/context.go
package app
import (
"log"
"net/http"
"os"
"path/filepath"
"github.com/geisonbiazus/blog/internal/adapters/postrepo/filesystem"
"github.com/geisonbiazus/blog/internal/adapters/renderer/goldmark"
"github.com/geisonbiazus/blog/internal/core/blog"
"github.com/geisonbiazus/blog/internal/ui/web"
"github.com/geisonbiazus/blog/pkg/env"
)
type Context struct {
Port int
TemplatePath string
StaticPath string
PostPath string
BaseURL string
}
func NewContext() *Context {
return &Context{
Port: env.GetInt("PORT", 3000),
TemplatePath: env.GetString("TEMPLATE_PATH", filepath.Join("web", "template")),
StaticPath: env.GetString("STATIC_PATH", filepath.Join("web", "static")),
PostPath: env.GetString("POST_PATH", filepath.Join("posts")),
BaseURL: env.GetString("BASE_URL", "http://localhost:3000"),
}
}
func (c *Context) WebServer() *web.Server {
return web.NewServer(c.Port, c.Router(), c.Logger())
}
func (c *Context) Router() http.Handler {
return web.NewRouter(c.TemplatePath, c.StaticPath, c.UseCases(), c.BaseURL)
}
func (c *Context) UseCases() *web.UseCases {
return &web.UseCases{
ViewPost: c.ViewPostUseCase(),
}
}
func (c *Context) ViewPostUseCase() *blog.ViewPostUseCase {
return blog.NewViewPostUseCase(c.PostRepo(), c.Renderer())
}
func (c *Context) PostRepo() *filesystem.PostRepo {
return filesystem.NewPostRepo(c.PostPath)
}
func (c *Context) Renderer() *goldmark.Renderer {
return goldmark.NewRenderer()
}
func (c *Context) Logger() *log.Logger {
return log.New(os.Stdout, "web: ", log.Ldate|log.Ltime|log.LUTC)
}Модуль
app.Context действует в качестве контейнера для внедрения зависимостей. Например, если у него будет запрошен веб-сервер, он сможет правильно собрать все зависимости из всех слоёв, чтобы веб-сервер работал. То же касается любого другого компонента приложения.Главный файл
Перейдём, например, к главному файлу. Реализация довольно простая, ведь это всего лишь точка входа для приложения:
// cmd/web/main.go
package main
import (
"log"
"github.com/geisonbiazus/blog/internal/app"
)
func main() {
c := app.NewContext()
log.Fatal(c.WebServer().Start())
}Функция
main просто создаёт app.Context, получает веб-сервер и запускает его.❯ Заключение
По словам Роберта Мартина, в хорошей архитектуре доводится до максимума количество таких решений, которые не приходится принимать. В этом и суть. Если все до одной низкоуровневые детали вашего приложения реализованы как адаптеры, то на вас не давит необходимость принимать верное решение в самом начале. Ведь в реальности верное решение всегда зависит от того, когда именно делается реализация.
Вероятно, какой-то компонент, который работает сегодня, через несколько месяцев или лет будет уже не лучшим вариантом. Иногда ради соблюдения дедлайнов мы срезаем углы и сознательно идём на увеличение технического долга. Вот почему в хорошей архитектуре совершенно необходимо контролировать этот аспект.
Концепции чистой архитектуры значительно упрощают разработку и поддерживаемость софта. Не приходится тратить время на то, чтобы на самом раннем этапе решать, какова будет ваша инфраструктура. Если требуется что-то изменить, то (при условии, что правила бизнес-логики не изменятся), достаточно всего лишь реализовать новый адаптер. Если требуется изменить правило бизнес-логики, то для этого вносятся минимальные изменения в адаптеры, иногда никаких изменений вообще не требуется.
Вот почему этот подход так хорош. Всё легко менять, легко тестировать, в базе кода всё на своих местах.

ghostiam
Спасибо за статью.
Но разве UseCase должен преобразовать Markdown в HTML?
Что если нам понадобится, в будущем, REST API для блога или мы захотим читать блог через терминал с диска со специальным форматированием для него?
Думаю таким должен заниматься UI слой, получая только модель с данными.