
Всем привет. На связи Артём Гойлик @ArtoLord и Владислав Волох @Chillintano из команды DataSphere в Yandex Cloud. Мы создаём инфраструктуру для ML‑разработчиков. И сегодня расскажем про одну задачу, которая, как и многие другие, начиналась с болей наших пользователей.
Такая боль
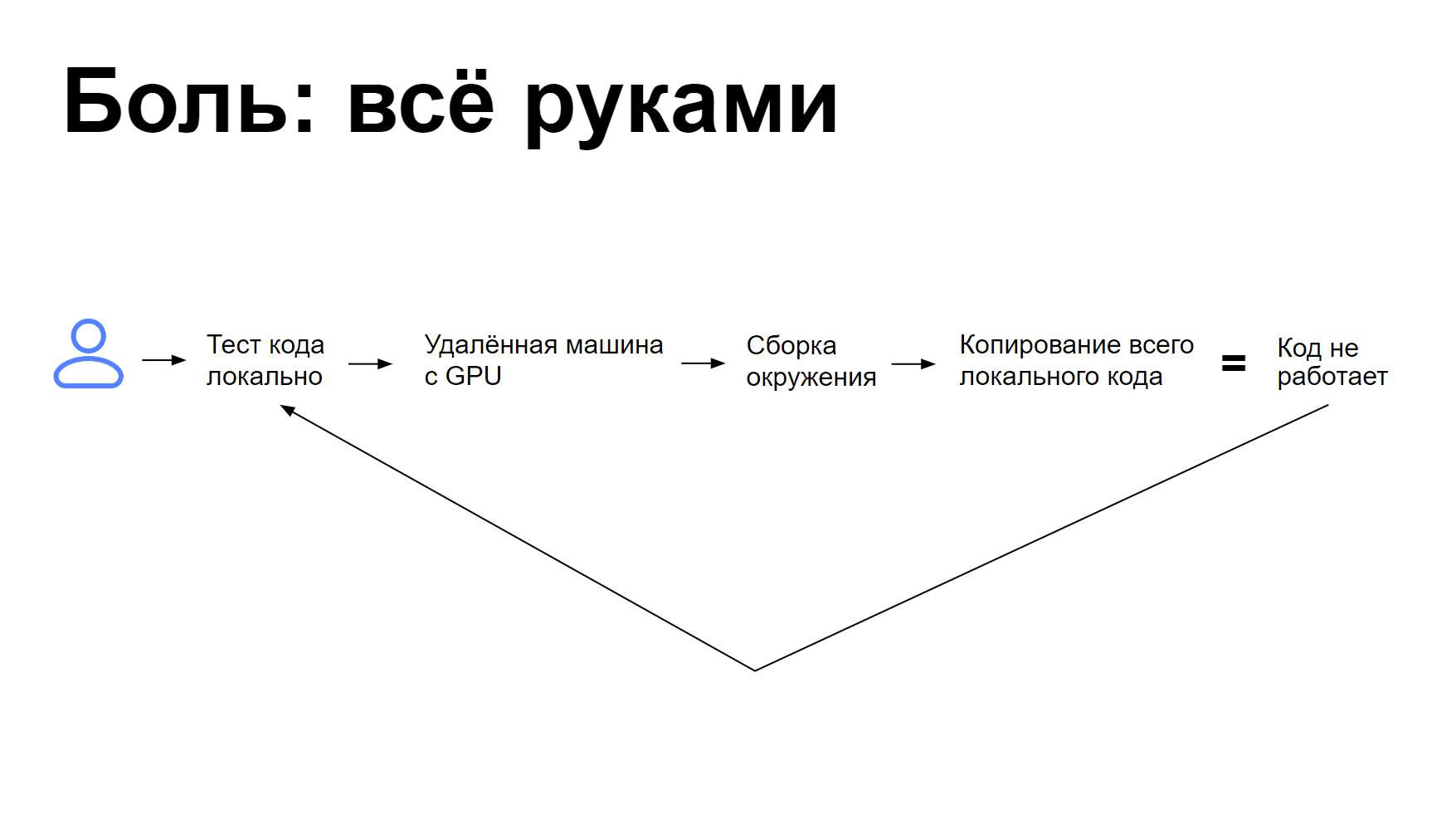
Всё началось с команды, которая обратилась к нам, потому что у неё никак не получались ML‑эксперименты.
Пока её разработчики тестировали код локально, всё шло хорошо. Но как только они переключались на удалённую машину с GPU, чтобы провести тесты на реальных данных, начинались проблемы. Команда вручную переносила окружение на удалённую машину: ставила библиотеки, переносила локальный код. В этот момент что‑то обязательно ломалось, разработчики всё исправляли. А когда после долгих усилий запускали код — он не работал. Приходилось возвращаться к локальной машине и начинать всё заново.
Примерно так:
Мы предложили им переносить окружение, используя Docker. Команда собрала огромный Docker со всеми нужными библиотеками и драйверами и вернулась с новыми проблемами:
Каждому разработчику нужны ещё какие‑то свои библиотеки. Команда бесконтрольно обновляет Docker, доламывая то, что работало.
Обновление базового образа усложняет ситуацию, и кто‑то не обновляет базовые образы, а создаёт новые — получается зоопарк.
Локальный код всё равно нужно копировать руками.
Никто не умеет писать Dockerfile.
Всё очень долго.

На этом этапе мы поняли, что без разработки решения не обойтись, и написали для страдающей команды простенькую утилиту.
Велосипед MVP. По нашему плану, эта утилита:
1. Локально соберёт окружение через pip freeze и перенесёт его на удалённую машину.
2. Запакует и скопирует локальный код.
3. Развернёт данные из пунктов 1 и 2 поверх базового образа.
В теории после этого всё должно было заработать. На деле оказалось, что в окружении ML‑разработчиков очень много пакетов: они переносятся и ставятся целую вечность. Pip freeze при этом не помогает, потому что выдаёт все версии пакетов, которые могут быть несовместимы друг с другом. Потестив это всё, мы поняли, что нам нужен новый план.
Уточнённые условия задачи
Мы поговорили с пользователями и сформулировали требования к пайплайну:

Чаще всего команда тестировала код локально, прежде чем запустить его на удалённой машине. Но иногда пропускала тестирование на локалке и переходила сразу к большим данным. Если что‑то ломалось, цикл повторялся. А потом всё ехало в деплой. Но деплой — уже не наша забота, от нас требовалось сделать быстрый перенос окружения. Идеальное решение:
кросс‑платформенное: не зависит от ноутбуков и дистрибутивов;
обладает низким порогом входа: не требует дополнительного обучения;
воспроизводимо между запусками.
Новое решение
Мы выбрали следующий алгоритм:
Динамическая сборка окружения в рантайме + возможность использовать кастомный базовый образ
Сначала запустим import в коде программ и посмотрим, от каких пакетов он действительно зависит: едва ли в рантайме нужны абсолютно все пакеты, установленные в системе. А дальше — оставим возможность задавать базовый образ, где можно установить то, что не удастся перенести.
Плюсы такого подхода:
Находит только нужные модули.
Видит локальные модули.
Различает типы модулей.
В корнер‑кейсах можно использовать кастомный Docker‑образ.
Минимальный порог входа.
Есть и минусы:
Нужно запускать импорты локально.
Не всегда работает (об этих корнер‑кейсах мы расскажем дальше).
Шаг 1 из 3. Ищем модули для переноса
Первый шаг — найти только те пакеты и модули, от которых зависит рантайм, и сделать это как можно быстрее.
Для этого начнём с теории: что такое неймспейсы в Python.
Неймспейсы — это словари, в которых хранятся все объекты, которые есть в рантайме в Python:
Глобальный неймспейс — словарь, где есть все объекты текущего модуля: импортированные модули, функции, классы, глобальные переменные и прочее. Такой неймспейс есть у каждого модуля.
Локальный неймспейс — словарь, который создаётся во время исполнения функции и содержит все локальные переменные. Удаляется после окончания исполнения.
Как их обойти? Построим граф, где каждое ребро соединяет два зависящих друг от друга модуля:
import functools
a = 42
def foo():
pass
print(globals())
# {
# '__name__': '__main__’,
# ...,
# 'functools': <module 'functools'>,
# 'a': 42,
# 'foo': <function foo at ...>
# }Определим, что такое зависимость. Зависимость — это:
модули в неймспейсе других модулей;
модули объектов в неймспейсе других модулей.
Всё бы было хорошо, но в Python всегда есть всякие подводные камни.
Корнер-кейсы
Во-первых, некоторые пакеты (например, pkg_resources) импортируют внутри вообще все установленные модули. Их нужно пропускать, чтобы не обходить всё-всё-всё, что есть в системе.
Во-вторых, локальные неймспейсы. Как мы уже обсудили, они существуют только внутри функций. Но проблема в том, что внутри функции можно сделать import, и мы его не увидим, потому что не запускаем функции. Это, конечно, антипаттерн, так никому не надо делать, но такие случаи встречаются. Сейчас мы их не поддерживаем, но в будущем можно будет просто составлять функции АСТ-дерева и смотреть, что импортируется на самом деле.
Мы написали такую штуку: первый раз она находит все нужные модули за полсекунды, дальше работает сильно быстрее. И находит вот для такого окружения две с чем-то тысячи модулей:
import torch
import catboost
import pandas
import numpy
timeit(lambda: get_dependencies(globals()), number=1)
# >> 0.49449617799999857
len(get_dependencies(globals()))
# >> 2293На первый взгляд выглядит очень страшно. Но на самом деле эти модули принадлежат одним пакетам: на следующем шаге мы их объединим.
Шаг 2 из 3. Переносим модули
Итак, мы нашли тысячи нужных модулей. Теперь требуется объединить их по пакетам, классифицировать и собрать артефакты для переноса.
И снова нам нужно немного теории: напомню, что такое distribution.
Distribution — архив, где хранится информация обо всех пакетах и модулях, которые есть на диске: версии пакетов, их местоположение на диске, откуда их установили и так далее.
Информация доступна только для пакетов, установленных с помощью pip. Её предоставляет библиотека importlib-metadata:
import importlib_metadata
dist = importlib_metadata.distribution("torch”)
dist.version
# '1.13.1’
dist.files
# [
# PackagePath('../../../bin/convert-caffe2 to-onnx’),
# PackagePath('functorch/.dylibs/libiomp5.dylib’),
# PackagePath('functorch/_C.cpython-39.so’),
# PackagePath('functorch/__init__.py’),
# ...
# ]Именно metadata поможет нам собрать все возможные артефакты.
Теперь классифицируем модули:

Чтобы отнести модуль к одной из трёх групп, нужно проверить наличие (или отсутствие) distribution и откуда он установлен: из Pypi или нет.
Модули, которые есть в Pypi, перевозим с помощью списка в conda.yaml вместе с версией Python. Локальные и editable‑модули — архивами через s3.
Ну а бинарные локальные модули — не перевозим, выводим на экран пользователя предупреждения: например, просим их вставить проблемные модули в базовый Docker‑образ, который позже поднимем на удалённой машине.
Корнер‑кейсы
1. Namespace modules
Namespace modules — модули, которые состоят из нескольких пакетов. Например:
files_to_dist["<>/google/api/annotations.proto"]\
.name
# 'googleapis-common-protos’
files_to_dist["<>/google/rpc/status.proto"].name
# 'pylzy'Для работы с namespace modules нужна специальная логика: кроме того, что найти внутренние модули будет сложнее обычного, такой модуль может состоять наполовину из локального модуля, наполовину — из модуля Pypi.
2. Editable‑установка, которую conda делает плохо
Это такой вид установки пакетов в Python, когда мы не копируем все файлики в директорию с питонячьими модулями, а указываем путь на реальные файлы на диске: создаём ссылку на то, что лежит где‑то в другом месте.
Проблема в том, что conda устанавливает так вообще все свои пакеты: вместо пути в реальной файловой системе она указывает какие‑то свои метаданные, которые никуда не ведут.
И снова, чтобы распознать всё это, понадобится отдельная логика.
3. Файлы одного пакета в разных местах, как в Jupyter
На первый взгляд, нет ничего страшного в том, что файлы одного пакета могут лежать в разных местах. Но пакеты могут класть свои файлы, например, в системные директории. Такие файлы перенести не получится: мы не можем гарантировать, что они заведутся на удалённой машине.
4. Разные схемы Pypi (и то, что он иногда лежит)
Pypi, по идее, должен работать у всех. На деле оказалось, что у многих есть локальные версии Pypi, которые отличаются от стандартной. А сам стандартный Pypi постоянно лежит и возвращает странные коды.
Приготовьтесь обложиться ретраями, чтобы всё это починить.
Итак, нам удалось преодолеть все трудности и не споткнуться о корнер‑кейсы: теперь можно собрать окружение.
timeit(lambda: classify(all_deps), number=1)
# 2.6664085060001526
len(classify(all_deps))
# 27
classify(all_deps)
# [
# PypiDistribution(name='numpy', version='1.24.1’),
# PypiDistribution(name='torch', version='1.13.1’),
# …
# ]Всё работает довольно быстро: две с половиной секунды, большую часть которых занимают походы в Pypi. Можно сделать быстрее, оптимизировав код: наш пример совсем простой, мы идём в Pypi за каждым пакетом.
Из 2000+ модулей мы получили всего 27 пакетов, объединили их и перенесли на удалённую машину.
Шаг 3 из 3. Разворачиваем окружение
Остался последний шаг: удалённо развернуть все элементы окружения, которые мы перенесли.
Это совсем просто: запускаем базовый образ, через conda устанавливаем conda yaml и распаковываем локальные модули в этом же образе (так их можно будет получить из кода).

Conda медленная, но именно благодаря ей мы можем вообще не думать про версию Python. Нельзя поддержать все текущие минорные версии языка — они часто бывают несовместимы друг с другом, даже если речь идёт о подверсиях минорной версии, мы такое ловили. Conda умеет самостоятельно ставить нужную версию: ту, которая была локально.
Если нужно ускорить решение, можно кешировать локальные модули по хешу в s3 между исполнениями кода, чтобы сохранять запущенный образ с уже установленным окружением и устанавливать только те модули, которых ещё нет.
Новый инструмент для распределённого исполнения кода, который автоматически собирает окружение, мы назвали Lzy и выпустили его в опенсорс. Приходите ставить звёздочки и контрибьютить.
Но если вы не хотите самостоятельно собирать окружение и переносить его либо модифицировать свой код, чтобы использовать Lzy, попробуйте DataSphere Jobs.
DataSphere Jobs

Мы уже вкратце рассказывали, как это работает:
Вы запускаете команду у себя в консоли.
Консольная утилита собирает ваше окружение и вместе с входными данными загружает его в Object Storage.
Мы выделяем вам виртуальную машину с нужной конфигурацией. Если у вас уже есть ресурсы в DataSphere (например, s3 или датасеты), то мы можем подключить их к этой виртуальной машине.
Мы исполняем ваш код. Следите за процессом: логи попадают к вам в консоль.
После исполнения кода мы выгрузим выходные данные в Object Storage и отправим вам ссылку на скачивание.
Но давайте проверим на примере: превратим фотографии котиков в смешной стикерпак.
План такой: находим на фото кошачьи мордочки, вырезаем их, а затем обрабатываем нейросетью, чтобы перерисовать их в мультяшном стиле. Вот такие прекрасные котики:

И вот такой код:

Выделение объектов работает очень быстро даже на процессоре ноутбука: исполнение этого кода заняло всего пару минут.

И вот такие прекрасные мордочки получились:

Угадайте, какой из этих котов принадлежит одному из авторов статьи?
Следующий шаг — обработать мордочки моделью, которая перегенерирует их в стиле рисунков. Когда мы запустили локальное окружение с этой моделью, обнаружили, что одно изображение будет генерироваться около часа. И решили ускорить этот процесс:

Можно воспользоваться облачными ресурсами: получить доступ к машине с более мощной видеокартой. Для этого мы написали простой конфигурационный файл: описал, как запустить мой скрипт, какие у него входные и выходные данные:

Также мы немного переписали скрипт генерации, чтобы он принимал и отдавал архивы: упростил конфигурационный файл и скачивание данных. В самом конце файла указали конфигурацию вычислительных ресурсов.

Запустили этот скрипт командой DataSphere: около пяти минут ушло на загрузку окружения и входных данных, а затем исполнение запустилось и логи исполнения начали отображаться прямо в консоли. Генерация одного изображения, как видите, стала занимать порядка полутора‑двух минут.
Через десять минут после запуска скрипта мы получили ссылку на скачивание результатов. А повторные запуски будут и того быстрее, мы закешируем окружение.

Как вы узнали из примера, можно заниматься локальной разработкой в любимой IDE и пользоваться облачными мощностями, как только вам перестаёт хватать ресурсов на исполнение кода.
DataSphere Jobs — удобный способ батчевого инференса для тяжёлых моделей. Поскольку запуск исполнения происходит из консоли, у конфигурационного файла простая и чёткая структура, с которой легко автоматизировать исполнение кода.
Спасибо, что дошли до конца. Приходите обсудить наши решения в комментариях.