
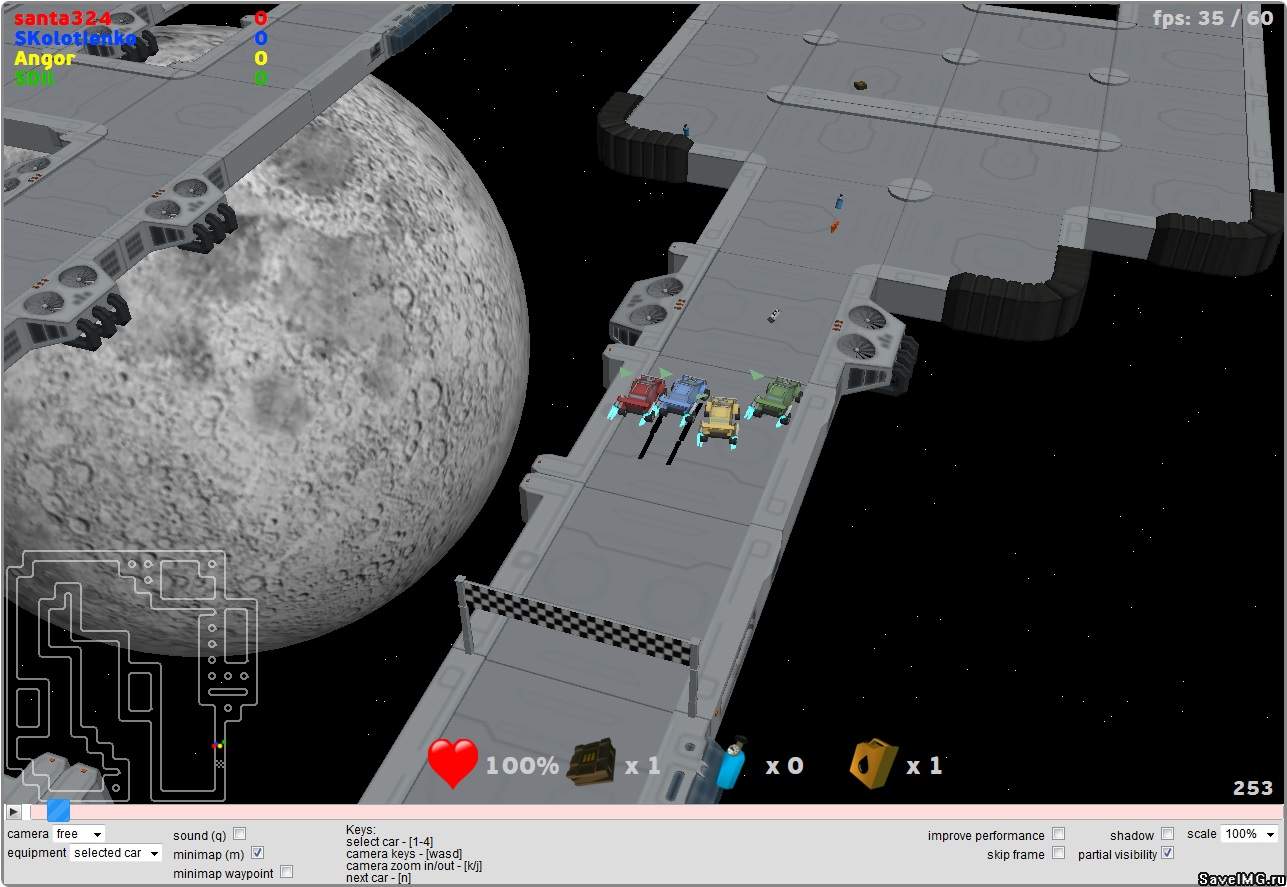
В этом году соревнование было организовано на совершенно новом уровне. Изменения произошли как в масштабности игрового мира, в котором действует ИИ, так и на сайте соревнования. Благодаря трехмерной визуализации, игры смотрелись гораздо увлекательнее. По зрелищности, на мой взгляд, соревнование значительно превзошло прошлогодний хоккей, и «солдатиков» 2013 года.
Участнику предлагалось написать ИИ для управления автомобилем в гонках на выживание. Как и в прошлом году, задача была «с физикой». Но на это раз исходники «физического движка» были открыты. Еще, в отличие от прошлого года, на этот раз все случайные явления в игровом мире были наглядны — случайная карта, случайно расставленные бонусы. Сразу было видно — когда удача на твоей стороне, а когда она от тебя отвернулась. В прошлогоднем хоккее, даже наблюдая за игрой значительно отличающихся по силе противников, было трудно понять произошел выигрыш благодаря случаю или мастерству. Думаю, это положительно сказалось на зрелищности соревнования.
Краткое описание правил
Цель — проехать 2 круга по замкнутой трассе быстрее всех. Точнее надо набрать больше всех очков, но приехать первым — это основной способ заработать очки. Еще очки дают за сбор бонусов по дороге и нанесение урона противникам. Трасса, как конструктор, собирается из квадратных «тайлов», это прямолинейные участки трассы, углы (поворот трассы на 90 градусов), или перекрестки (Т образные и обычные). Нужно ехать по ключевым точкам («тайлам») трассы в определенном порядке – иногда приходится делать петли, иногда вообще ехать назад. Еще у машинок есть возможность разливать за собой лужи мазута, стрелять друг в друга специальными снарядами (шины и шайбы), и использовать особый ускоритель «нитро». Заряды для всех этих приспособлений ограничены, и пополняются подбиранием случайно разбросанных по карте бонусов.
Расскажу, как устроен мой ИИ, и благодаря чему (как я думаю) удалось победить.
Первая версия
Я участвую в соревновании не первый раз, каждый год удавалось достигнуть лучших результатов, чем в предыдущем. Из моего опыта, очень большую часть успеха занимает правильно организованная разработка своей стратегии. Так как время сильно ограничено, нужно с самого начала продумать — что и в каком порядке будешь делать. Если придется все выбросить и писать заново, шансов на победу мало.
Не думаю, что в моей стратегии были какие-то «killer feature», скорее множество небольших удачных решений сложились в одно большое преимущество. Рассказ будет довольно длинный с подробным описание всех этих моментов.
По поводу тестирования и отладки. В прошлые годы бывало, что я бился головой о стену пытаясь понять — почему мой алгоритм не дает той выгоды, на которую я рассчитывал. И потратив кучу времени я, вдруг, находил баг в самом сердце своего алгоритма — и все взлетало даже выше, чем я рассчитывал. Даже в этом году я чуть не упустил победу из-за багов, надо было уделять тестам больше времени. На этот раз визуализация стала для меня основным способом отладки. Придумать короткие, но эффективные тесты я не сумел, а тратить много времени на написание длинных тестов, которые потом еще и постоянно переписывать придется, было жалко. Был только тест для физического симулятора, который сравнивал предсказанную траекторию и реальную. Без него отладить физику столкновений было бы вообще невозможно.
Первую версию я решил научить просто проезжать трассу. Но даже этот минимум, если его реализовывать честно, требовал довольно большого объема работы, нужны были: физический симулятор свободного движения машинки, обнаружение столкновения с бортами, поиск пути и планировщик траекторий. Первые три компонента было понятно — как делать, четвертый не очень.
Начал я, как и в прошлые разы, с написания физического симулятора. Тут проблем не возникло — исходники физического движка были доступны. Сразу стало понятно, что если делать 10 итерация на каждый тик как в движке, то с производительностью могут быть проблемы. Припоминая статью прошлогоднего победителя, у меня были сомнения нужна ли абсолютная точность. Решил все же сделать точно, а потом, если нужно будет, переделать на 1 итерацию вместо 10. Это был правильный выбор, как оказалось. Дальше я занялся обнаружением столкновений с ограждениями. Делать обнаружение столкновений как в движке я побоялся, решил, что будет слишком медленно. Обдумав несколько вариантов, я остановился на таком алгоритме:
Каждый «тайл» разбивается квадратной сеткой на 9 секторов. Находясь в каждом секторе, машинка может столкнуться только с определенным видом ограждения находящимся с одной из 4х сторон и, для некоторых видов, с зеркально отображенным ограждением.
Вот эти виды ограждения:
- Прямая стенка справа/снизу/слева/сверху
- Внутренний угол
- Внешний угол
- Окружность
- Стенка, переходящая в окружность с одной стороны за переделами сектора. Тут 4 стороны и для каждой еще зеркальное отображение
- Окружность, переходящая в стенку с одной стороны за пределами сектора. Тут тоже 4 стороны и зеркальное отображение
Эти 6 вариантов покрывают все возможные случаи. Варианты 5 и 6 нужны, так как машинка может находиться в одном «тайле», а углом столкнуться с ограждением в другом «тайле». Дальше строилась таблица для всей карты, где в каждом из 9 секторов для каждого «тайла» лежал объект, который мог проверить — столкнулась ли машинка с его ограждением. Реализация получилась довольно эффективной, потребляла меньше трети времени затрачиваемой на итерацию. Это позволило делать проверку на столкновение на каждой итерации, а не раз в тик без существенной потери в производительности.
Расскажу об еще одной оптимизации. Так как в движении участвовала угловая скорость, то первая реализация вычисляла синусы и косинусы на каждой итерации — это было медленно. Но так как угол поворота колес (влияющий на угловую скорость) менялся только раз в тик, а угловая скорость от столкновения появлялась редко, то обычно на каждой итерации нужно было просто прибавлять к углу ориентации машинки один и тот же постоянный угол. Угол ориентации машинки я хранил вектором и на каждой итерации вращал его на постоянную величину — это 4 умножения и 2 сложения. Синусы и косинусы нужно было считать только раз в тик и, в редких случаях, после столкновений на каждой итерации.
Поиск пути сделал самым простым способом — волновой алгоритм. Хотел потом переписать на алгоритм Дейкстры чтобы как-то учитывать наличие поворотов, бонусов, луж мазута. Но так и не вернулся к этому.
Оставался последний компонент — планировщик траекторий. С ним пришлось повозиться, думаю, в общем счете за все соревнование на него ушла половина времени. Вторая половина на физический симулятор, на все остальное было потрачено минимум времени. Сначала я попытался решить задачу тем же способом что и раньше — перебор траекторий определенного формата. Простейший формат: едем N тиков прямо, потом M тиков крутим руль в какую-нибудь сторону, дальше возвращаем руль в нейтральное положение. Работало, но плохо и очень медленно, просчет всех вариантов на сотню тиков вперед уже не вписывался в ограничения по времени. Машинка не понимала, что ей надо перестроиться в соседний ряд перед поворотом. Провозившись пару дней с этой идеей, я понял, что нужно что-то другое.
Решил строить дерево траекторий, думаю, к этой идее пришли многие участники. Но, вероятно, представляет интерес то, как я его строил. Думаю, мне удалось победить во многом благодаря удачному алгоритму построения этого дерева. Алгоритм придумывал сам, не основываясь на чем-то известном. Не судите строго, если изобрел велосипед. Строилось дерево таким образом:
Построить несколько начальных траекторий длиной 450 тиков (длина тут и далее измеряется в тиках, на 450 остановился не сразу). Далее много раз (пока не кончится выделенное время) вызывался рекурсивный метод, который в середине какой-либо из ветвей дерева производил «ветвление». При «ветвлении» участок траектории до точки ветвления становился стволом нового поддерева, участок после — одной из ветвей нового поддерева, а также добавлялись новые ветви. Длина всех ветвей выбиралась таким образом, чтобы общая длина пути от корня до любого конечного состояния была постоянна, либо меньше и ветвь оканчивается столкновением. В первой версии для «ветвления» использовалось 4 варианта движения. Газ всегда в пол, а руль крутим в 4 положения: вправо, влево, в нейтральное положение, держим в текущем положении. Позже были добавлены варианты с торможением и ездой задом. Для работы этого алгоритма построения дерева использовались 3 оценочные функции:
- Сделать «ветвление» ствола текущего дерева (всегда в середине), если средняя длина ветвей потомков меньше длины ствола. Иначе перейти к выбору потомка для рекурсивного вызова на нем. Я много тут экспериментировал — это вариант оказался наилучшим.
- Выбрать потомка текущего дерева для рекурсивного вызова на нем. Выбирается потомок с максимальным значением: <средняя длина ветвей в дереве> * <третья оценочная функция> / sqrt(сумма длин всех ветвей дерева). Деление нужно чтобы дерево не вырождалось: чем больше времени потрачено на исследование ветви, тем больше знаменатель и меньше приоритет.
- Основная оценочная функция, на основе которой решалось по какой ветви мы все же поедем (какая ветвь лучше). В первой версии значение этой функции равнялось сумме оценки для ствола и максимальной оценки потомка. Награда давалась за приближение к финишу — «взятие тайла». Позже эта функция сильно изменилась.
Получалось достаточно равномерно ветвящееся дерево с приоритетом ветвления тех ветвей, которые вели к финишу. К сожалению у меня не осталось картинок того дерева, но оно почти не отличалось визуально от последних версий.
Вот так выглядит визуализация последней версии моей стратегии на одной из карт в условиях ограниченной видимости. Это траектории, которые строятся за один тик. Лучшая выбирается из множества таких деревьев, получаемых за много тиков (об этом и других приемах — ниже в статье).
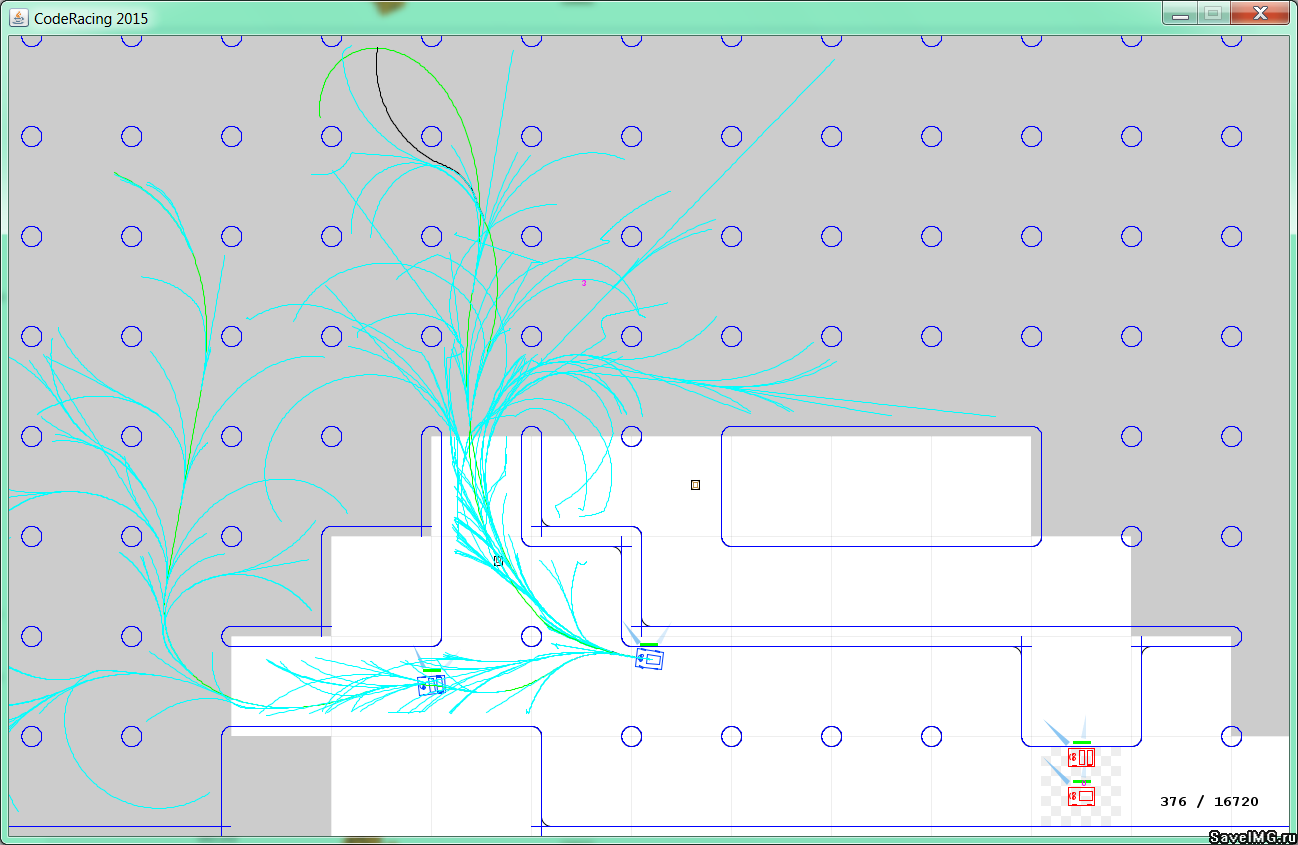
Здесь я хочу поблагодарить организаторов. В этот раз мир, в котором действовал ИИ, получился заметно сложнее, чем в прошлых, и это подтолкнуло участников искать новые алгоритмы и подходы. Такое дерево траекторий, думаю, прекрасно сработало бы и в прошлогоднем хоккее и в танках.
Примерно за 9 дней до первого раунда первая версия была готова. Она уже нормально ездила и поднялась примерно до 200х-300х мест. Далее это стало каркасом стратегии и принципиально не менялось, только добавлялся новый функционал.
Подготовка к первому раунду
Хотя на тот момент карт было еще мало, и они были простые, машинка часто застревала. Упираясь в стену, так как задом ездить не умела. Переключение на «смартгая» в случае неудачи основного алгоритма было малоэффективно. Писать аварийный эвристический алгоритм я не стал, так как планировал всему научить основной и не хотел зря тратить время. Добавил езду задним ходом в варианты ветвления для корня дерева траекторий. На этом этапе у меня каждый тик строилось дерево траекторий заново. Добавление вариантов ветвления во все ветви сильно снижало ветвистость обычных ветвей (ресурсы ограничены), машинка начинала ездить хуже. Так что новые ветви я старался добавлять только к корню и только в случае крайней необходимости (застряли). Научилась выезжать из простых ситуаций — поражений стало меньше. Рейтинг пополз вверх, добрался до второй сотни.
Тут хочу заметить, что все доработки я старался делать в таком порядке, чтобы в первую очередь решать проблему, причину наибольшего числа поражений. Этот подход себя оправдал, так как некоторые проблемы так и не понадобилось исправлять — что сэкономило время.
Следующее улучшение было очень простым, но очень эффективным. Зачем выбрасывать каждый тик найденную траекторию и искать ее заново на следующий тик? Так как физический симулятор выдавал точность до 10-12 знака после запятой, в течение десятков тиков машина оставалась на выбранной траектории с очень высокой точностью. Тут я понял, что идеально точное предсказание траектории сэкономит мне много вычислительных ресурсов. Каждый тик новое построенное дерево сравнивалось с сохраненным на предыдущем тике и принималось решение оставить старое или заменить новым. Считал что машинка «сошла» с траектории, если предсказанные и реальные координаты или скорость отличались в 7м знаке. Так как дерево было не симметричным, а вытянутым в сторону цели, и длина каждой ветви до 10 и более тиков — найденное дерево «устаревало» довольно медленно.
Таким образом, траектория выбиралась из целого леса деревьев, построенных в течение десятков тиков. Если бы я последовал совету, что абсолютная точность не нужна — этот прием, возможно, было бы сложно применить, пришлось бы контролировать накопленную погрешность. Десять итераций на каждый тик уменьшили скорость вычисления траектории в 10 раз (на самом деле значительно меньше) но дали возможность вычислять ее в десятки раз дольше. Да и трюки вроде разворота ударом об шину затруднительно сделать без абсолютной точности (это к вопросу о достаточной точности).
После предыдущей оптимизации проблемы с производительность отступили: даже снижая в 3-4 раза время на построения дерева, я почти не ослаблял стратегию. Очередная доработка разрешала использовать тормоз. Тут возникли проблемы: множество почти не отличимых друг от друга состояний с торможением уже почти остановившейся машинки расходовали все выделенное время. Решил очень грубо, но сработало: запретил тормозить, если продольная скорость машинки меньше заданной. Постоянные поражения на картах с крутыми поворотами прекратились — рейтинг закрепился в первой сотне.
Дальше я добавил использование нитро. Просто еще несколько вариантов ветвления, но только для корня. Нитро разрешалось использовать, если длина найденного пути с активированным нитро превышала 7 «тайлов». Запланировать использовать нитро через какое-то время алгоритм не мог, я посчитал это не нужным и не делал для экономии ресурсов. Правил баги и добавил несколько «костылей» что бы хот как-то стрелять, ставить лужи.
Следующее что я решил реализовать — это сбор бонусов. К тому времени мало кто их собирал и, приехав последним, легко можно было занять второе место в заезде. Физику столкновения с бонусом я поленился делать и так и не сделал до конца соревнования. Так что добавить сбор бонусов было не сложно, каждый тик в физическом симуляторе проверял пересечение с бонусом. За взятие бонуса награда в 3й оценочной функции. Пока давал большую награду за очки, среднюю за «нитро» и за «ремкомплект», по нулям за остальное (все равно использовать еще не умел). Эта версия участвовала в первом раунде и заняла 14 место, а после раунда закрепилась в «топ20».
Подготовка ко второму раунду
На выходных, пока шел раунд, было время немного отдохнуть и еще раз обдумать общий подход. Кроме того, что я еще не умел стрелять и разливать лужи, наблюдались странности в подбирании бонусов, и машинка стала хуже ездить на скоростных участках.
Решил начать со второй проблемы. Добавление торможения в варианты «ветвления» дерева траекторий, даже с ограничениями, все равно отрицательно сказывалось на езде по скоростным участкам, так как дерево становилось менее ветвистым. Потратив довольно много времени на эксперименты с оценочными функциями дерева, я так ничего и не добился. И тогда решил, что можно строить оба дерева (с торможением и без) и выбирать лучшее. Это была отличная идея, получился композитный алгоритм, который в будущем я еще расширил, добавив в композицию дерево с разрешением коллизий. Однако пришлось снизить количество итераций на каждое дерево в разы, тут очень пригодился запас производительности. Теперь алгоритм совмещал преимущества обеих версий. На приведенном выше изображении дерева траекторий можно увидеть три зеленые линии — это лучшие траектории в каждом из трех различных деревьев. Черная линия — это участок торможения на одной из этих трех траекторий.
Проблема с бонусами носила более фундаментальный характер. Изучая поведение машинки, было видно, что она проезжает мимо некоторых очень простых бонусов. Причина оказалась в том, что впереди было 2 бонуса (поближе и подальше). Стратегия не успевала просчитать траекторию, на которой могла бы взять оба бонуса и выбирала второй, так как при этом чуть лучше держала трассу. Хотя взяв ближний, она бы легко нашла способ взять и дальний. Чтобы мотивировать брать в первую очередь ближние бонусы — в 3ю оценочную функцию добавил экспоненциальное затухание награды за любые события. Наилучший результат дало довольно медленное затухание 0.99 за тик (в 2 раза примерно за 70 тиков). Думаю, этот прием положительно сказался и на езде машинки, и на стрельбе в будущем, хотя наверняка сказать сложно.
Дальше анализ игр показал, что много поражений из-за наезда на лужи мазута. Добавил штраф за наезд на лужу мазута. Потом решил что этого мало, очень уж боялся довольно безобидных луж. Добавил в симулятор падение коэффициента трения при контакте с лужей. Поковырялся в «локал ранере», нашел формулу — как меняется угловая скорость при первом контакте с лужей мазута. Оказалось «рандом» там дает всего 2 варианта: закручиваемся вправо или влево, а скорость закручивания можно рассчитать точно. Сделал «вероятностную» ветвь в своем дереве траекторий, имеющую эти 2 варианта в своих потомках и усредняющую оценку по ним. Лужи стал прекрасно объезжать, а иногда даже использовать в свою пользу.
Приближался второй раунд, пора было осваивать шины. Тут принципиально нового я ничего не делал. Добавил в физический симулятор шины, их столкновения с бортами и с машинкой. На это ушло много времени, пришлось разобраться с физикой коллизий в движке, все протестировать. За получение повреждений давал штраф в оценочной функции, а за смерть очень большой штраф. После этого я уже умел уклоняться от шин и даже использовать столкновение с ними себе на пользу, но еще не умел стрелять. Теперь добавление стрельбы стало совсем тривиальной задачей. Нужно было представить, что я противник и попытаться уклониться от моей шины. Если это не получалось или получалось но ценой врезания в стену — значит надо стрелять. Я подставлял противника в свой алгоритм поиска наилучшей траектории и если общая оценка траектории (учитывающая все: движение, урон, бонусы) при моем выстреле сильно снижалась, тогда стреляю.
Для противника траектории рассчитывались на 150 тиков, и времени выделялось в 10-20 раз меньше чем на поиск своей траектории. Трюки с разворотом ударом об собственную шину получились сами собой — стратегия симулировала выстрел по противнику и видела что собственная траектория, которая пересчитывалась с учетом летящей своей шины, хуже не становится, и разрешала выстрел. Постановка луж была добавлена аналогичным образом, уже не помню до или после стрельбы. Было много промахов из-за малого объема вычислений, но я и так закончил второй раунд на первом месте с большим отрывом. Пока шел второй раунд, я учил стрелять багги. Сделал я это точно так же как и стрельбу шинами. Сначала научился уклоняться от шайб, потом добавил стрельбу.
Подготовка к Финалу
Пришло время готовиться к особенностям финала. Организаторы обещали неизвестные карты и ограниченную видимость. Что будет иметь решающее значение в таких условиях — было непонятно. С ездой в условиях ограниченной видимости у меня были проблемы, этим и решил заняться.
Наверно, как и все участники финала, я просто считал неизвестные «тайлы» перекрестками. Доработал визуализацию — рисовал «туман войны», все известные мне «тайлы». Вместо неизвестных рисовал перекрестки, теперь я видел мир глазами своей машинки. Первый же просмотр заезда выявил проблему. Машинка находила лучшую траекторию через неизвестные «тайлы» которые считала перекрестками, но после их раскрытия не сбрасывала ее, хотя теперь ехала прямиком в стену. Написал небольшой алгоритм, который «подрезал» сохраненное дерево траекторий каждый тик по мере получения новой информации. Если ветвь проходила через неизвестный «тайл», а после его «раскрытия» он оказывался не того типа, который предполагался — эта ветвь отсекалась от дерева. Надо было так же сделать обработку и других событий (появление луж, снарядов, бонусов) но не успел, для них сбрасывалось все дерево.
Была еще одна проблема, которую выявила визуализация. Некоторые «тайлы» считались «проходимыми» (не пустыми), хотя по соседним «тайлам» было видно, что это не так. Немного модифицированный волновой алгоритм (повторно проходивший по «тайлам» для которых обнаружены новые данные о наличии стенок) исправил эту ситуация. Теперь целые области карты могли резко «схлопнуться» в большую пустую область, как только становилось ясно по косвенным данным, что там дороги быть не может. Не знаю, дало ли это какой-то прирост силы игры, но смотреться стало в визуализации гораздо приятнее.
Что еще сильно ослабляло стратегию в условиях ограниченной видимости? Неожиданные повороты создавали много проблем, панически боясь коснуться стены, стратегия теряла много времени. Либо сильно тормозила на поворотах, либо, чуть коснувшись стенки, даже под небольшим углом — переходила на задний ход. Решил, наконец, заняться разрешение коллизий машинки со стенками. Тут тоже особо рассказывать нечего — много времени на копирование логики и тестирование, попытки сделать все это не очень медленным. Были и принципиальные проблемы. Если до этого траектория обрывалась, коснувшись стенки, то теперь появились длинные (в тиках) траектории толкания у стенки. Машинка практически не двигалась, упершись в стенку, и дерево траекторий опять вырождалось на этих почти не отличимых состояниях.
Пришлось вернуться к старой идее, с которой я много экспериментировал, пытаясь решить аналогичную проблему при торможении. Смысл ее был в замене «длины в тиках» на настоящую длину. Хотя это портило обычные траектории, для траекторий со столкновениями это лучшее что смог придумать. Добавил этот вариант езды в свой «композитный» алгоритм поиска траектории. Это усилило практически все стороны стратегии. Неожиданные перекрестки перестали быть проблемой, объезд луж и уклонение от шин стали гораздо увереннее (ловко ударившись о шину, потом о стенку «как будто случайно» удавалось продолжить движение без большой потери времени). Стрельба шинами и постановка луж тоже стали опаснее, возможности уклонится, чуть чиркнув об стену, оставлял гораздо меньше. А еще в процессе переписывания логики обработки столкновения со стенками я нашел баг (неправильно определялось столкновение с углом), исправление которого усилило стратегию чуть ли не сильнее чем все остальное.
На имеющихся картах стратегия стала играть довольно хорошо, единственной явной проблемой было столкновение машин друг с другом и стрельба по своим. Хотя происходило это редко, но могло все испортить. Стрельбу по своим исправил так: если собрался стрелять, проверим, не «испортит» ли это оценку лучшей траектории одной из своих машин больше чем на заданную величину. Теперь нужно было научить машинки друг с другом не сталкиваться. Так как у меня есть сохраненная траектория для каждой машинки, по которой она собирается ехать, можно было просто добавить штраф за пересечение машин. Так я и сделал, штраф был пропорционален квадрату относительной скорости машин, так как на больших скоростях столкновения опасней. Сработало на удивление хорошо, теперь машинки со свистом проносились мимо друг друга на перекрестках, аккуратно ехали колонной, и вежливо пропускали друг друга.
Я ожидал сюрпризов от неизвестных карт финала. Обдумывая, что может быть неожиданного и очень неприятного в новых картах, напрашивался вывод, что пока нигде не нужна была езда задом, только развороты после столкновений. Нужно было это предусмотреть, начал эксперименты с ездой задом. Тут я нашел в своей оценочной функции «баг», который потом оказался «фичей». Если давать награду за приближение к финишу и штраф за отдаление — машинка не разворачивалась, очень боялась отдалиться от финиша, даже ненадолго. По этому, награду я давал только за первое «взятие тайла», если потом отъезжаем назад и снова приближаемся – награду не давал, за отдаление не штрафовал. В этой логике был баг, для ветвей дерева награда за повторное «взятие тайла» все же давалась. Из-за этого при езде задом машинка застревала между «тайлов» и дергалась туда-сюда, многократно получая
Последнее что я сделал перед финалом, вечером в пятницу, была система контроля времени. Она должна была не допустить сюрпризов с «таймлимитами», но все получилось наоборот, исправил только в перерыве. Исправленный вариант беспечно тратит процессорное время пока его много, а по мере исчерпания — экспоненциально сокращается количество итерация на все симуляции. Когда падает ниже предельного минимума — отключается все, кроме самого универсального варианта построения дерева траекторий (с торможением, без коллизий, на минимальном количестве итераций), чтобы хот как-то доехать до финиша. Начальный темп расходования процессорного времени выбирал так, чтобы хватало без выхода на аварийный режим на большинстве карт.
Заключение
Победа чуть не ускользнула из моих рук из-за нескольких серьезных ошибок. Этому нужно было уделить больше внимания и с самого начала разработать методику тестирования и отладки. В остальном, думаю, подход был выбран удачный.
Исходный код стратегии доступен тут.
Комментарии (40)



TimsTims
22.12.2015 12:48+1А будет ссылка на видео, где можно посмотреть, кто как себя вёл?
Как было в прошлом году с хоккеями, было интересно наблюдать, как ИИ играет — один ошибается, второй обыгрывает, а первый потом снова востанавливается и одерживает интеллектуальную победу :)

Stepanow
22.12.2015 13:12+1Написано интересно, не ожидал такого количества сложных моментов. Реквестирую игру, где игрок мог бы управлять машинкой, соревнуясь с машинками, управляемыми вашей стратегией, чтобы на собственной шкуре оценить, насколько силён ИИ.

SKolotienko
22.12.2015 13:54+1В принципе, это можно сделать локально с помощью russianaicup.ru/p/localrunner и исходников любой стратегии

gli
23.12.2015 09:38Выиграть ИИ вообще нереально. У меня стратегия была на 400+ месте, и я не мог с ней соревноваться. Если сравнивать себя с победителями — они и на круг могут успеть обогнать.
ruspartisan
23.12.2015 09:41Как тут уже написали, можно скачать исходники, собрать и localrunner с нужными настройками, но, возможно, придётся потвикать стратегию для улучшения производительности, иначе вы играть не сможете из-за 10-30 фпс.

splav_asv
22.12.2015 13:39Нда, если в 2013 году можно было выкарабкаться на python, то дальше с каждым годом все хуже. Хорошо хоть в этом году numpy и scipy разрешили использовать, а то было совсем печально. Дерево вариентов я пробоввл сделать, но тупо не вписывался по времени. Только с одной итерацией на шаг и то еле-еле, а это оценка хороша только на 20-30 тиков как максимум. В следующем году надеюсь будут еще языки компилируемые добавлены. Rust например…
JustAMan
22.12.2015 19:42В этом году в финале 2 питониста, в сотне — четверо. По итогам заездов понятно, что выиграть питонячья стратегия не могла, но побороться за двадцатку — вполне.
Для компенсации такого неравенства можно попробовать разрешить присылать гибридные стратегии (т.е. питоновые исходники + C extension), в Джаве разрешить JNI. Только я сомневаюсь, что организаторы на это пойдут.SKolotienko
23.12.2015 14:05Или, как вариант, если в мире есть «точная физика» — сделать API по её расчёту.

Nashev
30.12.2015 11:11Или уйти из реального времени
JustAMan
30.12.2015 19:52Это не поможет, пока остаётся ограничение на процессорное время.
Если его убрать — то это приведёт только к развязыванию рук всем писателям перебора, в текущем варианте это хотя бы сильно ограничено, и надо искать нетривиальные подходы, например, как у автора статьи.
SKolotienko
22.12.2015 13:44+1Поздравляю с победой! Я считаю, что победу дал именно алгоритм поиска траекторий с помощью таких «деревьев». Я до такого не додумался :) Да и вообще думал, что это нереально считать «хорошие» траектории, особенно с точностью в 10 подтиков, на глубину 450 тиков.
А можно попросить снять видео с визуализацией того, как порождаются такие деревья в самом начале?
PS. Я могу вкратце описать тут в комментариях, как был устроен мой алгоритм. Надо?santa324
22.12.2015 15:29+6Спасибо. Сделал небольшое видео, извиняюсь за плохое качество, не было времени разбираться:
youtu.be/dJ37tF_QwYYSKolotienko
22.12.2015 21:52Очень круто. До сих пор не верю, что можно симулировать столько траекторий и укладываться во времени. Особенно с точностью 10 подтиков.
santa324
23.12.2015 10:53+1У меня за последний год была возможность попрактиковаться в выжимании из кода предельной производительности, тут это оказалось не лишним. Хотя «красота» кода из-за этого сильно пострадала, много дублирования кода. Писать быстрый и красивый код одновременно — это, видимо, навык следующего уровня…
JustAMan
30.12.2015 19:53По-моему, одновременно быстрого и красивого не бывает.
Бывает красивый и не слишком медленный, а когда начинаются микрооптимизации — тут красотой уже приходится жертвовать.

VoidEx
22.12.2015 16:06+1PS. Я могу вкратце описать тут в комментариях, как был устроен мой алгоритм. Надо?
Да, интересно

Iceg
22.12.2015 16:27Конечно, надо! И остальные ТОПеры если напишут, будет здорово.
SKolotienko
22.12.2015 20:31del
SKolotienko
22.12.2015 21:46+5Писал комментарий, который вырос во что-то огромное и, в общем, решил всё-таки написать отдельную тему: habrahabr.ru/post/273745

vip_delete
22.12.2015 16:41Первый круг машины едут не пойми куда — оно и понятно, но почему на втором-то круге они опять делают какие-то петли и заезжают в те же тупики — правильный путь известен же!
SKolotienko
22.12.2015 17:24+3Возможно потому, что так были расставлены вейпоинты, которые нужно проезжать в определённом порядке.

MichaelBorisov
22.12.2015 23:08-2Расчет оптимальной траектории — это же задача на теорию оптимального управления! Тут бы вам матан применить. Начать можно хотя бы с вариационного исчисления — его проще освоить, а потом перейти к принципу максимума Понтрягина. Придется, правда, решать краевые задачи на дифуры, что тоже вычислительно затратно, но зато имеется прочный математический фундамент. Может быть, удастся и сэкономить время расчета за счет упрощений или если удастся получить аналитическое решение для участков траекторий.
gli
23.12.2015 09:58Да, это именно то, что очень хочется применить! :)
К сожалению, «идеально» решить систему не хватает времени. На весь конкурс отведено полтора месяца, при этом не все узнают о начале «до начала». А нужно много кодировать, тестировать и т.п.
При этом, я не уверен, что здесь вообще удастся аналитические решения найти, вся система очень дискретна, при этом есть много внешних факторов случайной или псевдослучайной природы.MichaelBorisov
26.12.2015 13:52ТОУ применима и к дискретным системам, просто непрерывный случай более лаконично описывается на языке математики, поэтому его легче понять. К тому же, при достаточной гладкости траекторий дикретные решения будут стремиться к непрерывным. Случайные погрешности также могут быть учтены при рассмотрении в рамках ТОУ, эти вещи в нее изначально закладывались, ведь теория разрабатывалась главным образом для расчета систем управления ракет.
Мне кажется, главный барьер здесь — понимание ТОУ, сложность математического аппарата. Я вон уже больше года ломаю голову над учебником, и до сих пор не достиг полного просветления.
santa324
23.12.2015 10:00+2Игровой «движок» дискретный, простая симуляция обычно работает гораздо быстрее чем аналитическое решение. Я пытался что-то подобное применить в первом соревновании (танках)- ничего хорошего не получилось.
И на трассе есть противники, которые активно противодействуют — это не очень вписывается в теорию оптимального управления.MichaelBorisov
26.12.2015 13:57простая симуляция обычно работает гораздо быстрее чем аналитическое решение
Простая симуляция по сути дела есть численное решение дифференциальных или разностных уравнений. В этой связи нет особой разницы, решаете ли вы уравнения движения системы, или уравнения ТОУ. Однако последние могут за меньшее число итераций привести вас к оптимальному решению.
И на трассе есть противники, которые активно противодействуют — это не очень вписывается в теорию оптимального управления.
Прекрасно вписываются, только это относится уже к углубленным разделам теории, которые сложнее понять и применить. Все эти задачи в свое время ставились и решались для военной техники, например, рассмотрения поединка самолета и противовоздушной ракеты. См. по ключевым словам "дифференциальные игры".santa324
26.12.2015 17:26При свободно движущихся объектах, вроде ракеты и самолета, найти аналитическое решение ещё возможно. Но в данном соревновании действия происходят в узких коридорах. Столкновения с ограждениями, столкновения с шинами, столкновения машин между собой. Каким образом Вы будете писать для них уравнения движениями, тем более, решать их численно быстрее чем простой симуляцией?
Я не вижу способа применить аналитическое решение даже небольшого участка траектории. Как я уже писал, я пытался, в первом соревновании (танках). Я по образованию физик, и это было даже естественнее для меня. Но потом все пришлось выкинуть и переписать на симуляцию.
Не будьте голословны, приведите пример того, как это можно применить.
santa324
26.12.2015 17:42Например, в танках я нашёл аналитическое решение уравнения движения танка. Пытался применить его для нахождения кратчайшего пути к бонусу, но учесть размеры и формы танка и бонуса (подобрать можно чиркнув углом) в уравнении движения практически невозможно. Я уже не говорю про столкновения. И даже если получится, уравнения будут столь сложными, что их численное решение будет намного медленнее симуляции с обработкой столкновений. А ещё точность будет хуже, так как «движок» дискретный.
MichaelBorisov
28.12.2015 23:26Каким образом Вы будете писать для них уравнения движениями, тем более, решать их численно быстрее чем простой симуляцией?
Начнем с того, что «простая симуляция» есть численное решение системы разностных уравнений, которые в случае дискретной системы являются «истинными» уравнениями движения, а в случае непрерывной системы — приближением к «истинным» дифурам, которые описывают систему.
Нужно ли решать эти уравнения аналитически? Все зависит от рассматриваемой задачи. Например, когда имеют место столкновения, то можно рассматривать аналитические решения от столкновения к столкновению, если их удастся найти. Иногда бывает, что хоть аналитическое решение найти не удается, но можно применить другой (не «в лоб», как при простой симуляции) численный метод их решения. Так, если уравнения линейные — то большой прирост скорости дают методы, основанные на преобразовании Фурье.
Но я вел речь не о решении уравнений движения. Понятно, что так или иначе их решить можно (хотя бы численно). Но вот, если перед вами стоит следующая задача:
1) Заданы уравнения движения («простой симуляции») вида x(t) = f(x(t-1), u(t-1), t), где x — вектор переменных состояния системы в зависимости от времени, u — вектор управляющих воздействий, f — векторная функция. Например, x — это могут быть координаты и скорости машины, u — вектор, в который входит положение руля, педалей газа и тормоза и т.д.
2) Требуется найти векторную функцию u(t), такую, чтобы x(t0) = x0, x(t1)=t1 (т.е. чтобы автомобиль в начальный и конечный момент времени имел заданные координаты и скорость)
3) Среди всех функций u(t), удовлетворяющих условию 2), требуется найти такую, чтобы функционал I(x(t), u(t), t)) принимал наименьшее значение. Это условие оптимальности решения — функционал является оценкой решения по выбранным вами критериям.
Эту задачу уже нельзя решить с помощью «простой симуляции». Вы можете симулировать систему множество раз, перебирая различные варианты для u(t), но если делать это вслепую — то понятное дело, что не всегда даже удастся так подобрать u(t), чтобы автомобиль приехал куда надо, не говоря уже об оптимальности решения — слишком велико пространство для перебора.
Рассмотренная задача — это задача на оптимальное программное управление, и в ТОУ разработан ряд методов для ее решения.
Если вам нужны более конкретные примеры — обратитесь, приведу парочку.
Вряд ли есть смысл искать оптимальное программное управление сразу для всей трассы, т.к. на ней появляются случайные бонусы, противники совершают непредсказуемые маневры и т.д. Но можно попытаться применить теорию для поиска оптимальных траекторий прохождения поворотов или взятия бонусов.santa324
29.12.2015 10:53+1Наверно не зря это теория «оптимального» управления. Если вы решаете задачу управления роботом на конвейере на заводе — это одно. Ваши вычислительные ресурсы и время жестко не ограничены, можно попытаться найти оптимальное решение. Тут же за отведенные временные рамки (ограничение процессорного времени) найти оптимальное решение не представляется возможным. Нужно найти хотя бы просто хорошее решение. Преобразование Фурье и подобные вещи не такие уж легкие в этом плане.
По поводу того чтобы искать аналитическое решение от столкновения к столкновению: столкновения очень важная часть оценочной функции, на основании которой выбирается траектория. Если рассматривать участок траектории только между столкновениями — то практически не остается критериев по которым выбирать.
Основная проблема применимости этой математики в подобном соревновании — то что критерии оптимальности не известны. Единственный точно известный критерий — надо набрать больше всего очков в гонке. Какой функционал должен принимать максимальное значение не известно. И какой смысл искать абсолютный максимум некоторого выдуманного функционала — если вы даже не уверены он ли вам нужен?
Подход с перебором траекторий в этом плане очень удобен, можно менять критерии выбора очень легко, ничего не переделывая.
ruspartisan
А вы не пробовали на большой глубине уменьшать точность симуляции переходом к 5 или даже 1 итреации физики на тик? Особенно если там UNKNOWN_TILE. Или, например, для соперников менее точно считать?
santa324
Для себя не хотел снижать точность, чтобы машинка максимально долго не сходила с траектории. Для противников, наверно, имело смысл. Но пришлось бы корректировать симулятор чтобы он оба варианта поддерживал, времени на все не хватало.