
o1-previewЗа последние 24 часа мы получили доступ к недавно выпущенным моделям OpenAI, o1-miniспециально обученным для эмуляции рассуждений. Этим моделям дается дополнительное время для генерации и уточнения токенов рассуждений перед тем, как дать окончательный ответ.
Сотни людей спрашивали, как o1 выглядит на ARC Prize. Поэтому мы протестировали его, используя ту же базовую тестовую систему, которую мы использовали для оценки Claude 3.5 Sonnet, GPT-4o и Gemini 1.5. Вот результаты:

Является ли o1 новой парадигмой по отношению к AGI? Будет ли она масштабироваться? Чем объясняется огромная разница между производительностью o1 на IOI, AIME и многими другими впечатляющими результатами тестов по сравнению с лишь скромными результатами на ARC-AGI?
Нам есть о чем поговорить.
Цепочка мыслей
o1 полностью реализует парадигму цепочки мыслей (CoT) «давайте подумаем шаг за шагом», применяя ее как во время обучения, так и во время тестирования.

На практике o1 значительно реже допускает ошибки при выполнении задач, последовательность промежуточных шагов которых хорошо представлена в синтетических данных обучения CoT.
В OpenAI заявляют, что на этапе обучения они создали новый алгоритм обучения с подкреплением (RL) и высокоэффективный процесс обработки данных, использующий CoT.
Подразумевается, что основополагающим источником обучения o1 по-прежнему является фиксированный набор данных предварительной подготовки. Но OpenAI также может генерировать тонны синтетических CoT, которые эмулируют человеческое мышление для дальнейшего обучения модели с помощью RL. Остается нерешенным вопрос, как OpenAI выбирает, на каких сгенерированных CoT обучаться?
Хотя у нас мало подробностей, сигналы вознаграждения за обучение с подкреплением, вероятно, достигались с помощью проверки (в формальных областях, таких как математика и кодирование) и человеческой маркировки (в неформальных областях, таких как разбивка задач и планирование).
Во время вывода OpenAI говорит, что они используют RL, чтобы позволить o1 отточить свой CoT и усовершенствовать используемые им стратегии. Мы можем предположить, что сигналом вознаграждения здесь является некая система актер + критик, похожая на те, которые OpenAI опубликовала ранее . И что они применяют поиск или возврат к сгенерированным токенам рассуждений во время вывода.
Тест-время вычислений
Самым важным аспектом o1 является то, что он демонстрирует рабочий пример применения поиска рассуждений CoT к неформальному языку, а не к формальным языкам, таким как математика, кодирование или Lean.
Хотя добавленное масштабирование времени обучения с использованием CoT заслуживает внимания, большой новинкой является масштабирование времени тестирования.
Мы считаем, что итеративный CoT действительно разблокирует большее обобщение. Автоматическое итеративное повторное подсказывание позволяет модели лучше адаптироваться к новизне, аналогично тонкой настройке во время тестирования, используемой командой MindsAI.
Если мы делаем только один вывод, мы ограничены повторным применением запомненных программ. Но, генерируя промежуточные выходные CoT, или программы, для каждой задачи, мы открываем возможность составлять компоненты изученных программ, достигая адаптации. Эта техника является одним из способов преодоления проблемы № 1 обобщения большой языковой модели: способности адаптироваться к новизне. Хотя, как и тонкая настройка во время тестирования, она в конечном итоге остается ограниченной.
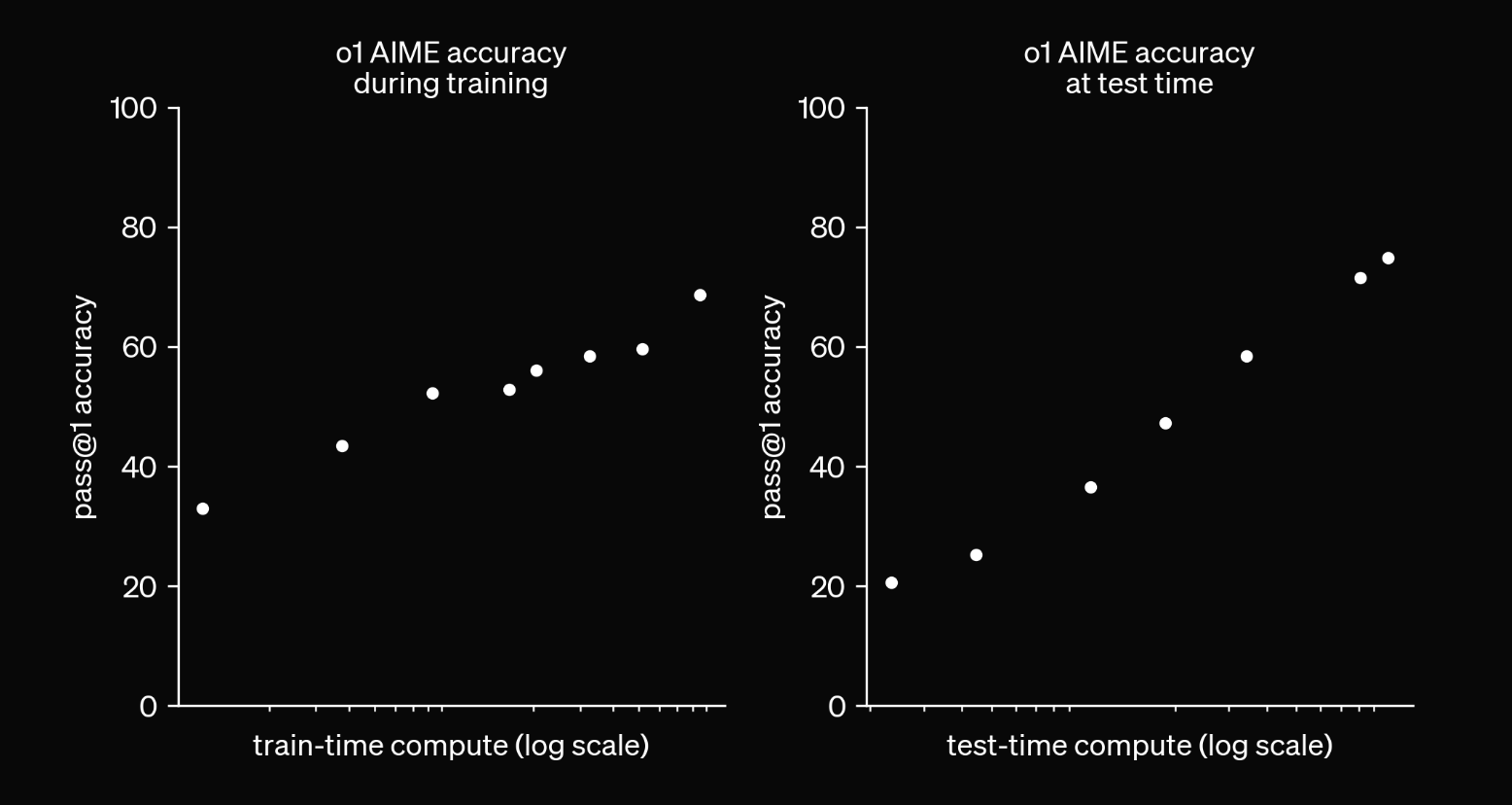
Когда системам ИИ разрешено переменное количество вычислений во время теста (например, количество токенов рассуждений или время поиска), нет объективного способа сообщить единую оценку бенчмарка, потому что она соотносится с разрешенными вычислениями. Это то, что показывает эта диаграмма .
Больше вычислений — больше точности.
Когда OpenAI выпустил o1, они могли бы позволить разработчикам указывать объем вычислений или время, отведенное для уточнения CoT во время тестирования. Вместо этого они «жестко закодировали» точку вдоль континуума вычислений во время тестирования и скрыли эту деталь реализации от разработчиков.
{kind=link}
С изменяющимися вычислительными возможностями во время тестирования мы больше не можем просто сравнивать выходные данные между двумя различными системами ИИ для оценки относительного интеллекта. Нам также необходимо сравнивать эффективность вычислений .
Хотя в своем заявлении OpenAI не поделился цифрами эффективности, волнительно, что мы вступаем в период, когда эффективность будет в центре внимания. Эффективность имеет решающее значение для определения AGI, и именно поэтому ARC Prize устанавливает предел эффективности для победивших решений.
Наш прогноз : в будущем мы увидим гораздо больше графиков тестов, сравнивающих точность и время выполнения тестов.
Базовые линии модели ARC-AGI-Pub
OpenAI o1-previewи o1-miniоба превосходят GPT-4oобщедоступный набор данных оценки ARC-AGI. o1-previewПо точности он примерно соответствует Claude 3.5 Sonnet от Anthropic, но для достижения результатов, аналогичных Sonnet, ему требуется примерно в 10 раз больше времени.

Чтобы получить базовые баллы модели в таблице лидеров ARC-AGI-Pub, мы используем тот же базовый запрос, который мы использовали для тестирования GPT-4o. Когда мы тестируем и сообщаем результаты на чистых моделях, таких как o1, мы намерены получить измерение производительности базовой модели, насколько это возможно, без наложения какой-либо оптимизации.
В будущем другие могут найти более эффективные способы создания моделей в стиле CoT, и мы с радостью добавим их в таблицу лидеров, если они будут проверены.
Рост производительности o1 сопровождался затратами времени. На 400 публичных задач ушло 70 часов по сравнению с 30 минутами для GPT-4oand Claude 3.5 Sonnet.
Вы можете использовать наш открытый исходный код Kaggle notebook в качестве базовой тестовой обвязки или отправной точки для вашего собственного подхода. Подача SOTA в общедоступную таблицу лидеров является результатом умных методов в дополнение к передовым моделям.
Возможно, вы сможете придумать, как использовать o1 в качестве основополагающего компонента для достижения более высокого результата аналогичным образом!
Есть ли здесь AGI?
На этой диаграмме OpenAI показывает логарифмически линейную зависимость между точностью и временем тестирования вычислений на AIME. Другими словами, с экспоненциальным ростом вычислений точность растет линейно.
Многие задаются новым вопросом: насколько масштабно это может быть?
Единственным концептуальным ограничением подхода является разрешимость проблемы, поставленной перед ИИ. Пока процесс поиска имеет внешний верификатор, который содержит ответ, вы увидите, что точность логарифмически увеличивается с вычислением.
Фактически, представленные результаты чрезвычайно похожи на один из лучших подходов ARC Prize Райана Гринблатта. Он достиг результата 43%, сгенерировав GPT-4ok=2048 программ решений для каждой задачи и детерминировано проверив их с помощью демонстраций задач.
Затем он оценил, как меняется точность при разных значениях k.

Райан обнаружил идентичную логарифмически-линейную зависимость между точностью и временем тестирования вычислений на ARC-AGI.
Означает ли все это, что AGI уже здесь, если мы просто масштабируем вычисления во время тестирования? Не совсем.
Вы можете увидеть похожие экспоненциальные кривые масштабирования, посмотрев на любой поиск методом грубой силы, который является O(x^n). Фактически, мы знаем, что по крайней мере 50% ARC-AGI можно решить методом грубой силы и нулевым ИИ.
Чтобы превзойти ARC-AGI таким образом, вам нужно будет сгенерировать более 100 миллионов программ решения для каждой задачи. Одна только практичность исключает поиск O(x^n) для масштабируемых систем ИИ.
Более того, мы знаем, что люди не так справляются с задачами ARC. Люди не генерируют тысячи потенциальных решений, вместо этого мы используем сеть восприятия в нашем мозге, чтобы «увидеть» несколько потенциальных решений и детерминированно проверить их с помощью мышления в стиле системы 2.
Мы можем стать умнее.
Нужны новые идеи
Интеллект можно измерить, посмотрев, насколько хорошо система преобразует информацию в действие в пространстве ситуаций. Это коэффициент преобразования, и поэтому он приближается к пределу. Как только у вас будет идеальный интеллект, единственный способ прогрессировать — это собирать новую информацию.
Есть несколько способов, которыми менее интеллектуальная система может казаться более разумной, не будучи на самом деле более разумной.
Один из способов — это система, которая просто запоминает лучшее действие. Такая система была бы очень хрупкой, кажущейся разумной в одной области, но легко падающей в другой.
Другой способ — пробы и ошибки. Система может казаться интеллектуальной, если она в конечном итоге даст правильный ответ, но не если для этого ей нужно 100 попыток.
Следует ожидать, что будущие исследования вычислений во время тестирования позволят изучить, как эффективнее масштабировать поиск и уточнение, возможно, используя глубокое обучение для управления процессом поиска.
Тем не менее, мы не считаем, что это само по себе объясняет большой разрыв между результатами o1 на ARC-AGI и другими объективно сложными тестами, такими как IOI или AIME.
Более убедительным способом объяснить это является то, что o1 по-прежнему работает в основном в пределах распределения своих предварительных обучающих данных, но теперь включает все вновь созданные синтетические CoT.
Дополнительные синтетические данные CoT усиливают фокусировку на распределении CoT, а не только на распределении ответов (больше вычислений тратится на то, как получить ответ, а не на то, что является ответом). Мы ожидаем, что такие системы, как o1, покажут лучшие результаты в тестах, включающих повторное использование известных эмулированных шаблонов рассуждений (программ), но им все равно будет трудно решать проблемы, требующие синтеза совершенно новых рассуждений на лету.
Тестовое уточнение на CoT пока может только исправить ошибки рассуждений. Это также объясняет, почему o1 так впечатляет в определенных областях. Тестовое уточнение на CoT получает дополнительный импульс, когда базовая модель предварительно обучена аналогичным образом.
Ни один из подходов в отдельности не даст вам большого скачка.
Подводя итог, можно сказать, что o1 представляет собой смену парадигмы от «запоминания ответов» к «запоминанию рассуждений», но не является отходом от более широкой парадигмы подгонки кривой к распределению с целью повышения производительности за счет размещения всего внутри распределения.
Есть ли у вас идеи, как продвинуть эти новые идеи дальше? Что насчет CoT с мультимодальностью, CoT с генерацией кода или объединения поиска программ с CoT?
Напоминаю, что каждый может следить за новостями в мире ИИ в моем канале