

Привет! В этой статье я расскажу о двух алгоритмах сортировки: Quick Sort и Merge Sort. Объясню, как они работают, как выглядят примеры кода на Python и Java, а также — как выбрать подходящий алгоритм под ваши задачи. Подробности — под катом.
Используйте навигацию, если не хотите читать текст полностью:
→ Почему сортировка — это не просто перестановка элементов
→ Популярные алгоритмы сортировки
→ Основы алгоритмов сортировки
→ Быстрая сортировка, Quick Sort
→ Сортировка слиянием, Merge Sort
→ Сравнение алгоритмов Quick Sort и Merge Sort
→ Заключение
Почему сортировка — это не просто перестановка элементов
Алгоритмы сортировки — основа программирования, без них невозможно двигаться дальше. Но почему сортировка имеет такое значение? Дело в том, что упорядочивание — это основа для оптимизации других алгоритмов, улучшения производительности и более эффективного управления данными.
Представьте склад огромного интернет-магазина, где миллионы товаров хранятся на стеллажах. Чтобы быстро находить позиции, сотрудники обязаны поддерживать строгий порядок, сортировать товары по категориям и подкатегориям. Теперь представьте, что сортировка нарушилась. Нужный товар придется искать вручную — скорость обслуживания снизится, а расходы магазина возрастут.
В мире разработки ПО, где алгоритмы сортировки играют роль «библиотекарей» для данных, такая ситуация эквивалентна сбою программы или значительному падению производительности системы. При этом, если представить сортировку просто как способ расположить элементы в нужном порядке, мы упустим ее глубокий смысл. Алгоритмы сортировки не просто «переставляют» элементы массива. Они оптимизируют работу приложений, минимизируют потребление памяти и могут работать даже на больших наборах данных
Сортировка — это перестановка заданного массива или списка элементов в соответствии с оператором сравнения элементов. Он используется для определения их нового порядка в соответствующей структуре данных. Сортировка переупорядочивает все элементы либо по возрастанию, либо по убыванию.

Оптимальные алгоритмы позволяют снизить время выполнения программ и обеспечить предсказуемое поведение системы. Без них приложения будут страдать от затяжных задержек или даже сбоев при работе с большими данными.
Сортировка также служит основой для многих других алгоритмов: от поиска до обработки графов и распознавания образов. При решении таких задач важно учитывать не только количество выполняемых операций, но и объем используемой памяти.

Популярные алгоритмы сортировки
Давайте теперь немного отвлечемся от теории и посмотрим, а какие вообще бывают алгоритмы сортировки.
- Пузырьковая сортировка (Bubble Sort). Простейший алгоритм, который сравнивает пары соседних элементов и меняет их местами. Несмотря на свою простоту, это один из наименее эффективных алгоритмов со сложностью O(n2). Подробнее о сложности алгоритмов еще поговорим ниже.
- Сортировка вставками (Insertion Sort). Работает путем вставки каждого нового элемента в уже отсортированный массив. Эффективен для небольших массивов и имеет временную сложность O(n2).
- Сортировка выбором (Selection Sort). На каждом шаге выбирает минимальный элемент из неотсортированной части и помещает его в конец отсортированной. Подходит для массивов, где важна простота реализации. Его эффективность также O(n2).
- Пирамидальная сортировка (Heap Sort). Использует структуру данных «куча» и работает за O(n log n). Отличается предсказуемой производительностью и малыми накладными расходами.
- Быстрая сортировка (Quick Sort). Один из самых эффективных алгоритмов. Как правило, выполняет сортировку быстрее остальных благодаря разделению массива на меньшие подмассивы и последующей рекурсивной сортировке.
- Сортировка слиянием (Merge Sort). Алгоритм, гарантированно обеспечивающий O(n log n) даже в худшем случае. Подходит для больших объемов данных и сохранения стабильности сортировки.

В большинстве случаев специалисты используют Quick Sort и Merge Sort. Далее разберем, с чем это связано.
Основы алгоритмов сортировки
Чтобы понять, почему Quick Sort и Merge Sort считаются лучшими, важно сначала разобраться в основных концепциях: классификации, сложности и стабильности алгоритмов.
Ключевые понятия: временная и пространственная сложность, стабильность
Временная сложность определяет время выполнения алгоритма. Для оценки используется Big O Notation:
- O(n) — линейная сложность, количество операций увеличивается пропорционально размеру входных данных.
- O(n2) — квадратичная сложность, количество операций возрастает квадратично.
- O(n log n) — логарифмическая сложность, оптимальное время для большинства сортировок, включая Quick Sort и Merge Sort.
Пространственная сложность определяет, сколько дополнительной памяти требует алгоритм помимо самого массива. Чем меньше, тем лучше, особенно при работе с большими объемами данных.
Стабильность. Алгоритм сортировки называется стабильным, если он сохраняет относительный порядок одинаковых элементов. Это особенно важно, если в данных есть несколько ключей для сортировки, например, по фамилии и затем по имени.

Классификация алгоритмов сортировки: где стоят Quick Sort и Merge Sort
Алгоритмы сортировки классифицируются по множеству признаков. Основные критерии — это метод выполнения (внутренний или внешний), устойчивость, необходимость дополнительной памяти и методика реализации (разделяй и властвуй, вставки и т. д.).
Внутренние алгоритмы сортировки. Работа выполняется в оперативной памяти. Они отлично справляются с задачами, когда объем данных небольшой и все помещается в ОЗУ. К внутренним алгоритмам относятся:
- пузырьковая сортировка,
- сортировка вставками,
- сортировка выбором,
- быстрая сортировка (Quick Sort),
- сортировка слиянием (Merge Sort).
Внешние алгоритмы сортировки подключают жесткий диск или другие внешние устройства хранения. Используются, когда данных так много, что они не помещаются в оперативной памяти. Например, многопутевая сортировка слиянием разбивает их на несколько файлов, а затем соединяет в один отсортированный массив.
По способу реализации Quick Sort и Merge Sort относят к категории «разделяй и властвуй». Она предполагает, что массив рекурсивно делится на несколько мелких частей, которые затем упорядочиваются и объединяются. При этом каждый алгоритм реализует концепцию по-разному.
Теперь давайте глубже разберем особенности двух алгоритмов.
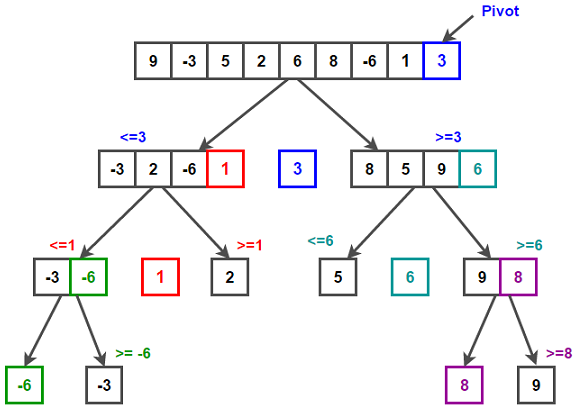
Быстрая сортировка, Quick Sort
Quick Sort отличается быстротой выполнения и эффективностью использования памяти. Это один из самых популярных алгоритмов в мире программирования.
Основная идея базируется на парадигме «разделяй и властвуй». Алгоритм сначала выбирает опорный элемент (pivot). Затем делит массив на два подмассива: в первом элементы меньше или равны pivot, а во втором — больше. После этого каждый подмассив сортируется независимо. Затем процесс рекурсивно повторяется для обоих подмассивов, что позволяет эффективно упорядочить элементы.

Источник.
{kind=link}
Quick Sort показывает одну из лучших производительностей среди алгоритмов сортировки.
- В среднем случае временная сложность составляет O(n log n). Это объясняется тем, что массив делится на две равные части, а операции выполняются для каждой из них рекурсивно.
- В худшем случае сложность может возрасти до O(n2). Это происходит, когда массив разбивается крайне неравномерно, например, если элементы уже упорядочены.
- Пространственная сложность зависит от глубины рекурсии и составляет O(log n), так как хранение дополнительных данных минимально.
Где применять и как оптимизировать
Quick Sort подходит для множества задач — от упорядочивания массивов в простых приложениях до сложных системных решений, где нужно обеспечить эффективную сортировку на месте. Этот алгоритм часто используется в качестве встроенного метода сортировки в популярных библиотеках, например, в C++ и Python.
Чтобы улучшить производительность Quick Sort, можно использовать несколько оптимизаций:
- Выбор опорного элемента (pivot selection). Как уже упоминалось, использование median-of-three или случайного элемента уменьшает вероятность худшего сценария.
- Tail Call Optimization (TCO). Оптимизация рекурсии путем отказа от рекурсивного вызова для одной из частей массива (например, более короткой) позволяет избежать глубоких стеков вызовов и, как следствие, переполнения стека.
- Гибридные алгоритмы. На практике часто используется комбинация Quick Sort и других алгоритмов, таких как Insertion Sort, для небольших подмассивов. Эта техника снижает количество рекурсивных вызовов и уменьшает накладные расходы.
- Параллельная сортировка. Если необходимо работать с большими объемами данных, можно распределить вычисления на несколько ядер процессора или кластеров, реализовав параллельную версию Quick Sort.

Реализация на Python:
def quick_sort(arr):
if len(arr) <= 1:
return arr # Базовый случай: массив из 0 или 1 элемента уже отсортирован
pivot = arr[len(arr) // 2] # Выбираем середину в качестве опорного элемента
left = [x for x in arr if x < pivot] # Массив элементов меньше опорного
middle = [x for x in arr if x == pivot] # Массив элементов, равных опорному
right = [x for x in arr if x > pivot] # Массив элементов больше опорного
# Рекурсивно сортируем левую и правую части, объединяем все вместе
return quick_sort(left) + middle + quick_sort(right)
# Пример использования
array = [10, 7, 8, 9, 1, 5]
sorted_array = quick_sort(array)
print("Отсортированный массив:", sorted_array)
Реализация на Java:
public class QuickSort {
public static void quickSort(int[] arr, int low, int high) {
if (low < high) {
int pivotIndex = partition(arr, low, high);
quickSort(arr, low, pivotIndex - 1);
quickSort(arr, pivotIndex + 1, high);
}
}
private static int partition(int[] arr, int low, int high) {
int pivot = arr[low];
int left = low + 1;
int right = high;
while (true) {
while (left <= right && arr[left] <= pivot) {
left++;
}
while (right >= left && arr[right] >= pivot) {
right--;
}
if (right < left) {
break;
} else {
int temp = arr[left];
arr[left] = arr[right];
arr[right] = temp;
}
}
int temp = arr[low];
arr[low] = arr[right];
arr[right] = temp;
return right;
}
public static void main(String[] args) {
int[] array = {10, 7, 8, 9, 1, 5};
quickSort(array, 0, array.length - 1);
System.out.println("Отсортированный массив: ");
for (int num : array) {
System.out.print(num + " ");
}
}
}
Quick Sort — это только один из инструментов в арсенале разработчика. На практике часто приходится комбинировать его с другими алгоритмами, такими как Merge Sort, чтобы достичь максимальной производительности и эффективности.
Сортировка слиянием, Merge Sort
Сортировка слиянием (Merge Sort) — классический алгоритм, часто упоминаемый в связке с Quick Sort. Он также использует подход «разделяй и властвуй», но с акцентом на объединение (слияние) отсортированных подмассивов в итоговую структуру.
Алгоритм делит массив на две части, рекурсивно сортирует каждую из них, а затем объединяет их в один отсортированный массив.

Источник.
{kind=link}
Как выглядит алгоритм:
- Делим массив на две равные части, пока каждая не станет одноэлементной.
- Сравниваем элементы каждой пары и сливаем их в один отсортированный подмассив.
- Повторяем шаг 2, пока не получим один полностью отсортированный массив.

Эта структура делает алгоритм понятным и легко реализуемым, особенно в языках с поддержкой рекурсии: Python и Java. Однако операции требуют дополнительной памяти для хранения временных подмассивов. Это один из основных недостатков Merge Sort.
Реализация на Python:
def merge_sort(arr):
if len(arr) <= 1:
return arr # Базовый случай: массив из 0 или 1 элемента уже отсортирован
# Делим массив на две части
mid = len(arr) // 2
left = merge_sort(arr[:mid])
right = merge_sort(arr[mid:])
return merge(left, right)
def merge(left, right):
sorted_list = []
i = j = 0
# Сравниваем элементы левой и правой части и сливаем их в один массив
while i < len(left) and j < len(right):
if left[i] < right[j]:
sorted_list.append(left[i])
i += 1
else:
sorted_list.append(right[j])
j += 1
sorted_list.extend(left[i:])
sorted_list.extend(right[j:])
return sorted_list
# Пример использования
array = [12, 11, 13, 5, 6, 7]
sorted_array = merge_sort(array)
print("Отсортированный массив:", sorted_array)
Реализация на Java:
public class MergeSort {
public static void mergeSort(int[] arr, int left, int right) {
if (left < right) {
int mid = (left + right) / 2;
mergeSort(arr, left, mid);
mergeSort(arr, mid + 1, right);
merge(arr, left, mid, right);
}
}
private static void merge(int[] arr, int left, int mid, int right) {
int n1 = mid - left + 1;
int n2 = right - mid;
int[] L = new int[n1];
int[] R = new int[n2];
System.arraycopy(arr, left, L, 0, n1);
System.arraycopy(arr, mid + 1, R, 0, n2);
int i = 0, j = 0;
int k = left;
while (i < n1 && j < n2) {
if (L[i] <= R[j]) {
arr[k] = L[i];
i++;
} else {
arr[k] = R[j];
j++;
}
k++;
}
while (i < n1) {
arr[k] = L[i];
i++;
k++;
}
while (j < n2) {
arr[k] = R[j];
j++;
k++;
}
}
public static void main(String[] args) {
int[] array = {12, 11, 13, 5, 6, 7};
mergeSort(array, 0, array.length - 1);
System.out.println("Отсортированный массив: ");
for (int num : array) {
System.out.print(num + " ");
}
}
}
Merge Sort — один из немногих алгоритмов, которые гарантируют временную сложность O(n log n) в худшем, среднем и лучшем случаях. Все это — благодаря рекурсивному делению массива и упорядочиванию уже отсортированных подмассивов.
Пространственная сложность Merge Sort составляет O(n). Требуется дополнительная память для хранения временных массивов, используемых на каждом этапе рекурсии.
Таким образом, в ситуациях, где важна постоянная скорость выполнения независимо от распределения данных, лучше выбирать Merge Sort. Quick Sort может страдать от квадратичной сложности в худших случаях.
Примеры и сравнение с другими алгоритмами
Несмотря на большие требования к памяти, Merge Sort находит свое применение в разных сценариях. Вот некоторые из них.
Внешняя сортировка. При сортировке данных, которые не помещаются в оперативную память, алгоритм может обрабатывать их по частям, сохраняя промежуточные результаты на диске.
Сортировка связанных списков. Благодаря своей способности легко работать с рекурсивными структурами, Merge Sort подходит для сортировки связанных списков, где вставка и удаление элементов из середины могут быть выполнены за константное время.
Оптимизация в многоядерных системах. Процесс рекурсивного деления массива на подмассивы можно распараллелить, что делает Merge Sort хорошим выбором для многопоточных систем и обработки данных на кластерах.
Сравнение алгоритмов Quick Sort и Merge Sort
Когда мы говорим о сравнении алгоритмов сортировки, важно рассмотреть, как они проявляют себя на практике и в каких случаях стоит использовать каждый из них.
Временная и пространственная сложность
Quick Sort показывает отличную производительность в среднем, с временной сложностью O(n log n), но в худшем случае падает до O(n2). Это делает его менее предсказуемым. Однако из-за того, что алгоритм работает «на месте», его пространственная сложность — O(log n), что минимизирует расход памяти и обеспечивает отличную работу с кэшем.
Merge Sort сохраняет стабильную сложность O(n log n) независимо от входных данных. Это делает его хорошим выбором для задач, где важна предсказуемость, но его пространственная сложность O(n) требует больше памяти, так как нужно дополнительное хранилище для слияния.
Практическая эффективность
Quick Sort благодаря меньшему числу операций и интуитивной работе с кэш-памятью показывает высокую производительность на большинстве реальных данных. Он хорошо работает с массивами в оперативной памяти. В стандартных библиотеках, таких как C++ STL или Java Collections, используется именно этот алгоритм.
Merge Sort применяется в сценариях, где данные не помещаются в оперативную память, например, для внешней сортировки на жестких дисках. Это объясняет его применение в файловых системах и базах данных.
Стабильность и адаптивность
Merge Sort — устойчивый алгоритм, он сохраняет порядок одинаковых элементов. Такая способность делает его предпочтительным для работы с данными, где это важно, например при сортировке транзакций. Quick Sort в базовой реализации такой стабильностью не обладает.
Что выбрать
Выбирайте Quick Sort, когда работаете с массивами в оперативной памяти и хотите оптимизировать работу программы за счет низкой пространственной сложности и хорошей работы с кэшем. Merge Sort оставьте для задач, связанных с внешней сортировкой или если важна стабильность алгоритма.

Оптимизация с использованием специфических реализаций или адаптаций алгоритмов
Оба алгоритма можно дополнительно оптимизировать под конкретные требования. Quick Sort можно адаптировать, комбинируя его с Insertion Sort для небольших подмассивов, чтобы улучшить производительность на мелких данных. Merge Sort может быть реализован с многопоточностью для более эффективного распределения нагрузки при сортировке на многопроцессорных системах.

Примеры применения алгоритмов сортировки, с которыми вы точно сталкивались.
Google, YouTube, Netflix и другие медиакомпании используют Quick Sort, чтобы систематизировать контент перед тем, как предложить его пользователям. Этот алгоритм зачастую лежит в основе формирования ленты рекомендаций.
PostgreSQL использует Merge Sort при выполнении внешней сортировки. Это позволяет обрабатывать большие таблицы данных. А Bloomberg Terminal с помощью этого же алгоритма сортирует временные ряды и анализирует финансовые данные в реальном времени.
Заключение
И напоследок пару слов об искусственном интеллекте (куда же без него). Недавние прорывы в этой области привели к открытию новых алгоритмов сортировки, которые были интегрированы в устоявшиеся библиотеки, такие как libc++ LLVM. Эти достижения могут улучшить производительность до 70% для коротких последовательностей и приблизительно до 1,7% для больших наборов данных, превышающих 250 000 элементов.
Но даже с такими инновациями классические алгоритмы Quick Sort и Merge Sort все еще используются. Интеграция ИИ в классические подходы открывает новые горизонты для оптимизации, позволяя, например, более эффективно выбирать опорные элементы и прогнозировать оптимальные точки разбиения.
Так что, если вам кажется, что мир сортировок — это давно пройденный этап, попробуйте реализовать собственный алгоритм, когда у вас будет массив размером в несколько миллиардов записей. Уверяю, эта задача изменит ваше отношение к, казалось бы, давно решенной проблеме.
А что думаете по этому поводу вы? Пишите мнение в комментариях.
Комментарии (6)

lexus6666
17.10.2024 08:38А почему в примере реализации quicksort на питоне используются дополнительные массивы вместо in place варианта?

nickolaym
17.10.2024 08:38А потому что халява сэр. Ещё бы на хаскелле написали, там синтаксического шума примерно в пять раз меньше будет.
Сделать inplace quicksort на питоне - примерно столько же кода, как на яве, ну вдвое меньше строк за счёт фигурных скобок.
Akina
Господи, кто вам это начитывал? Это называется "устойчивая", а вовсе даже не "стабильная".
Да вряд ли. Есть поразрядная и подсчётом - они побыстрее будут.
PS. Жаль, что в рассмотрение не включена сортировка кучей (Heap Sort). У неё единственный минус по сравнению с рассмотренными методами (точнее, только с одним из двух) - отсутствие устойчивости. Зато всё остальное - плюсы.
postgrez4ik
А ещё пирамидальная сортировка не паралелится и не работает на списках последовательного доступа. По сути - улучшенный пузырьковый алгоритм. Любую "кучу" данных захочется сначала упорядочить или проиндексировать.
nickolaym
На списках - сам бог велел слиянием сортировать. Это даёт гарантии на логлинейное время.
nickolaym
Настоящий квиксорт на массиве - тоже неустойчивый.
Минус пирамидальной сортировки - в том, что она в лучшем случае вдвое медленнее быстрой (элементы сравниваются и перемещаются дважды - при сборке и разборке кучи).
А вот плюс - в том, что она гарантирует логлинейное время.
Промышленные методы сортировки - это сплав быстрой, вставок и пирамиды.
если массив маленький, то вставками он сортируется быстрее, просто потому, что два цикла быстрее, чем рекурсии
если глубина рекурсии превысила порог, кратный логарифму длины массива, это признак того, что набор плохой для квиксорта, и надо валить оттуда, пока мы до квадрата не доигрались, - запускают пирамиду