
Кто мы
Мы работаем в российской компании, которая более 10 лет занимается разработкой уникальных программных решений в области анализа данных, прогнозирования, классификации и других областей датамайнинга. Все решения – не абстрактные инструменты, а интегрированные системы для решения конкретных задач заказчиков. Наша ключевая особенность – алгоритмы собственной разработки, заточенные под высокое качество результата.
В нашей компании есть чёткое разделение обязанностей между математиками и программистами. Для наглядной расстановки акцентов добавлю, что команда математиков почти не уступает по размеру команде программистов.
О какой проблеме пойдёт речь
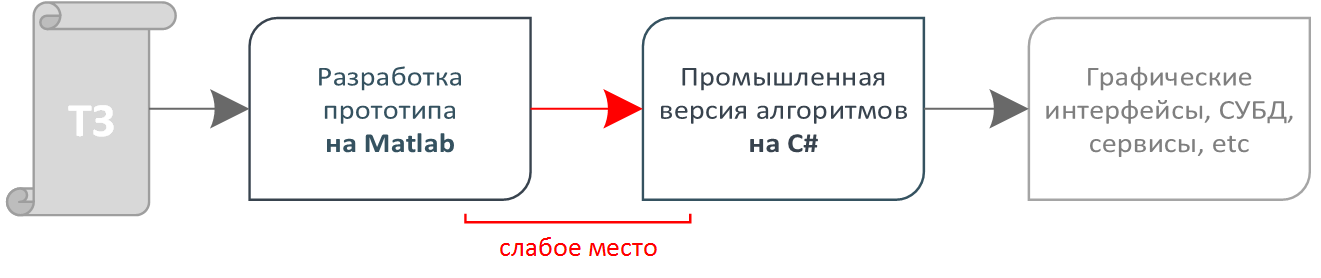
Упрощённо, процесс создания нового решения выглядит так:
После проверки идеи, наши математики разрабатывают полноценную аналитическую систему и реализуют в ней все процессы заказчика. На этой системе как правило происходит демонстрация работы наших алгоритмов в условиях, приближенных к боевым. Наши математики предпочитают работать на Matlab, поэтому их система очень удобна для быстрой проверки гипотез, но по многим причинам не может использоваться в промышленных целях. Нужно заново реализовывать тоже самое в подходящей среде разработки, например, .NET (в нашем случае). Этот момент – слабое звено процесса.
Разработчик промышленного софта имеет перед собой документацию и исходники на Matlab, но не обладает образованием и опытом математика. Однако из-под его пера должен выйти точно такой же алгоритм. Здесь возникает задача: как правильно тестировать промышленную версию алгоритма на соответствие прототипу математика?
В чём сложность этой задачи?
Нужно заметить, что поймать ошибку в математическом алгоритме и, например, в процессе синхронизации двух СУБД – две принципиально разные задачи. С базами данных всё более понятно: количество записей после синхронизации совпадает, контрольные суммы совпадают, значит тест пройдён. Легко понять и сравнительно легко автоматизировать.
Алгоритм прогнозирования принимает на вход и выдаёт на выход десятки или сотни величин — чисел с плавающей точкой. Один алгоритм выводит эти числа на экран в Матлабе, другой, промышленный, записывает в переменную в C#-коде. Как их сравнить? Из-за ограниченной точности вычислений с плавающей точкой, совпадать до последнего знака они не будут. Чем ограничить точность сравнения? В наших условиях падение качества прогнозирования на 2-3% может быть существенно, т.к. иногда это сравнимо с эффектом, который мы даём бизнесу.
Как мы решаем проблему
Процедура тестирования, к которой пришли мы, выглядит так:
- Генерация входных наборов данных – так называемых эталонов. Эту работу заранее делает математик в привычной среде – Matlab.
- Запуск системы тестирования, поглощающей эталоны и превращающей их в тесты. Эта система разработана нами на Matlab, по эталону она понимает какой алгоритм нужно запустить, в каком порядке передавать в него данные и чего ожидать на выход.
- Запуск прототипа на Matlab с эталонами в качестве входных данных. Эта процедура выполяется легко, т.к. и эталоны, и прототип созданы в рамках одной системы – Matlab.
- Запуск промышленной .NET-версии, с конвертацией входные и выходные данных из Матлаба в C# и обратно. Перепробовав несколько подходов, для построения такого моста, мы остановились на C#-интерфейсе, реализованном из коробки в последних версиях Матлаб. Он позволяет инстанциировать из Matlab практически любые типы C#-данных, загружать сборки, запускать функции.
- Система получает результаты работы обоих алгоритмов и запускает процедуру сравнения.
- Процедура сравнения выдаёт вердикт: 0 (не совпадает) или 1 (совпадает). Процедуру сравнения требуется разрабатывать вручную под каждый алгоритм, т.к. особенности округления конкретных величин дают разные допуски по значениям. Кроме того, некоторые алгоритмы включают в себя генерацию случайных величин.
- Шаги 2-7 автоматизируются посредством консольного запуска Matlab и запускаются по расписанию.
С учётом необходимости разработки C#-Matlab интерфейса, функции сравнения, а также отладки двух систем, на сведение среднего алгоритма уходит 5-10 дней, что по трудозатратам сравнимо со временем, затрачиваемым на разработку. Это время отражает разницу между алгоритмом, который «в принципе работает и выдаёт что-то нормальное» и алгоритмом, который полностью повторяет задуманное математиком.
Ещё раз, списком, сложности, с которыми мы сталкиваемся:
- Входные данные нужно подавать в Matlab и в C# => нужно разрабатывать конвертации туда и обратно.
- Сравнение и связанные с ним проблемы округления и другие особенности – мешают писать код и вводят в заблуждение при отладке.
- Синхронная отладка: чтобы понять, что не так, часто нужно синхронно запускать два отладчика под двумя системами, это работает, но требует определённого шаманства.
- Генерация исчерпывающего набора эталонов (задача математика). Всевозможные входы перебрать не получится, и веток в алгоритме может быть слишком много для их совместной проверки во всех комбинациях.
- Под каждый алгоритм необходима собственная вручную разработанная функция сравнения результатов.
Особенности кодирования
Разрабатывая промышленный код на C#, мы сразу думаем о том, что его придётся «сводить» с Matlab. Чтобы облегчить себе жизнь, мы используем ряд простых приёмов.
Важно уделить внимание операциям сравнения. Сравнивать на равенство числа с плавающей точкой нельзя (об этом подскажет решарпер). Вместо
a == bMath.Abs(a – b) < epsМенее очевидно, но явно проявляется в математических алгоритмах, что сравнения
<= >= < >if(a <= b) => if(a < b + eps)
if(a < b) => if(a < b - eps)
Также важно вникнуть в детали обработки с псевдовеличинами, такими как NaN (not a number) и Infinity. Например, в Матлабе:
max(0, NaN) = 0Math.Max(0, double.NaN) = NaNДругие пути
Возможные пути облегчения жизни, которыми мы не пошли или идём, но путь пока не пройден:
- Разработка и прототипа и продакшн версии одним человеком. Эта комбинация сильно упрощает жизнь, т.к. снимает задачу понимания этими людьми друг друга. В случаях, когда результат нужен незамедлительно, другого пути вообще нет. Но и людей, способных на такую разноплановую работу, практически не встречается. Ещё меньше людей, которые хотят ей заниматься.
Нормального математика воротит от ограничений и принципов промышленной разработки, а обычный программист – это инженер, отнюдь не математик (да, мы – не яндекс). - Юнит-тестирование продакшн версии (математиком или промышленным разработчиком). Вместо затратной процедуры совместного тестирования Матлаба и C# тестировать только C# на цифрах, которые выгружены из Matlab. В этом случае всё тестирование можно сделать с помощью удобных фреймворков полностью на C#.
Кажется, что это должно сэкономить кучу сил, но мы теряем главное: одновременное сравнение двух алгоритмов. Если в версию на Matlab будут внесены изменения, мы можем не узнать об этом своевременно или не осознать, насколько эти изменения важны (сколько тестов они порушили). - Билдить .NET сборки прямо из Matlab. К сожалению, нормальных (по производительноси и по надёжности) фреймворков для этого нет, и скорее всего никогда не будет. Матлаб – мощнейший инструмент, но создавался для других целей.
- Разработать на C# фреймворк, который позволит писать код в матлаб-стиле, с привычной обработкой матриц, индексов, условий и др. Такие разработки существуют: numerics.mathdotnet.com, ilnumerics.net, но несовершенны, и мы постепенно делаем свою.
В итоге
Вступая на этот путь, мы не ожидали, что верификация наших алгоритмов выльется в нетривиальный многоходовый процесс. В целом, нас устраивает качество и повторяемость результата, и нам интересно услышать мнение людей, столкнувшихся с похожими задачами.
Комментарии (30)

Zoberg
27.04.2015 12:55Как вариант, для тестирования везде использовать GMP, выставить точность побольше, в матлабе тоже использовать gmp-числа, а сравнивать только первые N разрядов.

Mrrl
27.04.2015 13:12А как потом проверять корректность перевода с кода, использующего GMP, на код на C#, использующий double?
Zoberg
27.04.2015 14:40Да, подразумевался как раз ваш вариант
всю работу придётся вести в классе MyDouble, совместимом по интерфейсу с MyLongDouble
Конечно, идея не претендует на достаточность, скорее похоже на костыль-отсев некоторого количества хороших случаев.


digitaldust Автор
27.04.2015 13:10Спасибо, мысль в копилку идей.
Arbitrary-precision для целых чисел в C# оказывается есть из коробки: msdn.microsoft.com/en-us/library/system.numerics.biginteger%28v=vs.110%29.aspx
Для double, правда, видимо нет.Mrrl
27.04.2015 13:22+1Он не поможет.
Проводить численные расчёты с неограниченной точностью нельзя: длина числителей и знаменателей растёт экспоненциально (за исключением особых случаев вроде вычисления определителя — когда гарантируется, что результат целый, хотя промежуточные числа рациональны).
Если будете считать с ограниченной точностью, то результаты MatLab и библиотеки из C# всё равно начнут расходиться. И если вам не хватило 15 знаков, то где гарантия, что хватит 100?
Да и программист не скажет спасибо, когда код, написанный под длинную арифметику, придётся переводить обратно на double. Особенно, если этого кода много… Ему же всю работу придётся вести в классе MyDouble, совместимом по интерфейсу с MyLongDouble. Стоит ли оно того?

nerudo
27.04.2015 13:42А автогенерацией кода из Матлаба не пробовали пользоваться?
digitaldust Автор
27.04.2015 13:47Когда-то давно, когда в Matlab ещё не было .NET-интерфейса, пробовали C++-генерацию. Она работала не очень, хуже всего было то, что не все функции Matlab поддерживались.
Сейчас есть .NET-генерация, но она требует установки Matlab Redistributable Package.
Здесь два вопроса:
1) производительность такого решения
2) лицензии при установке на сервер клиента
готовых ответов у меня нет.
А вы пробовали?nerudo
27.04.2015 14:58Если говорить про программный код, то сожаление только баловался. Отвечая на второй ваш вопрос — никаких дополнительных лицензий требоваться не должно, лицензия должна быть только у вас как у разработчика на сам Матлаб (с нужными опциями).
Но на самом деле там интереснее Embedded Coder, предлагаемый для встраиваемых решений. Он порождает чистый c/c++ и не должен требовать никаких дополнительных библиотек. Да, там действительно ограниченный набор возможностей, но зато сразу из модели можно получить готовый код без этапа ручного кодирования.

mephistopheies
27.04.2015 15:46+3а можно вопрос оффтоп, не сочтите за тролинг -)
Наша ключевая особенность – алгоритмы собственной разработки, заточенные под высокое качество результата.
что значит заточенность под высокое качество результата? разве кто намеренно и не скрывая ни от кого делает ПО заточенное под низкое качество результата? слабо могу представить компанию, продажник которой приходит к потенциальному заказчику и говорит «привет, наша ключевая особенность — заточенность под низкое качество результата» или «мы не заморачиваемся (не заточенны) над высоким качеством результата», ну или на крайняк «привет заказчик, знаете, мы делаем софт вообще говоря среднего качества, и результат будет сами понимаете каким»digitaldust Автор
27.04.2015 16:16-3Здесь под качеством подразумевается именно качество анализа данных, например, прогнозирования (его сравнительно легко измерить).
Большинство наших конкурентов внедряют и настраивают продукты зарубежных вендоров, а не делают свой BI-софт. При внедрении они делают упор на качество настройки процессов, а собственно прогнозирование имеет более низкий приоритет.
Прежде всего это происходит по причине отсутствия экспертизы, которые могут дать люди, одновременно разбирающиеся в математике и бизнесе (такие люди, особенно русскоговорящие — редкость). Ещё одна причина — недостатки инструментов во внедряемом софте.
Поскольку у нас есть специалисты, и свой софт, в BI-продуктах мы делаем упор на качество [прогнозирования/анализа данных], и по этому критерию били на пресейлах, например, Oracle.mephistopheies
27.04.2015 16:26ох уж этот маркетинг имаркетологи
но мне вот все равно не понятно, у компании стоит цель допустим прогнозирование тренда в цене на нефть, к ним приходит ваш конурент и говорит: "господа, наша ключевая особенность — алгоритмы собственной разработки (или чужой, заказчику не так это важно, важен таки результат же), заточенные под отказоустойчивость/юзабилити/биг дата/скорость", у него спрашивают, а как у вас с качеством прогнозирования, а он такой "да средненькое оно у нас, но ведь это не важно, главное качество софта, у нас же трехступенчатое тестирование ПО"
При внедрении они делают упор на качество настройки процессов, а собственно прогнозирование имеет более низкий приоритет.
а можете назвать хоть одного вашего конкурента, который позиционирует себя как софт для анализа данных, и они не говорят, что делают прогноз качественно, но говорят что остальное у них лучше все?
ну и второй вопрос, у вас получается более низкий приоритет на качество настройки процессов?digitaldust Автор
27.04.2015 16:38а можете назвать хоть одного вашего конкурента, который позиционирует себя как софт для анализа данных, и они не говорят, что делают прогноз качественно, но говорят что остальное у них лучше все?
Все конечно говорят, что всё самое лучшее, но внутри приоритеты расставляются по-разному. Мы бьёмся за качество, а кто-то нет, и этот кто-то не обязательно хуже в совокупности.
ну и второй вопрос, у вас получается более низкий приоритет на качество настройки процессов?
Просто по этому параметру сложнее стать лучше конкурентов.mephistopheies
27.04.2015 16:53Все конечно говорят, что всё самое лучшее, но внутри приоритеты расставляются по-разному. Мы бьёмся за качество, а кто-то нет, и этот кто-то не обязательно хуже в совокупности.
вот вы так как бы намекаете, что среди продуктов по анализу данных (а из названия класса продуктов следует что анализ данных — это ключевой параметр этого класса ПО), есть продукты которые на самом то деле плохие, по ключевому показателю, а вы вот как бы нет
так если вы обладаете информацией о том, что кто то обманывает своих клиентов, говоря, что они крутые в аланиле данных, а вы знаете что внутри то на самом деле там все не так, так почему бы не помочь всем потенциально обманутым клиентам ваших конкурентов и не выложить в чем же там и у кого косяки?
и как вы оцениваете, что ваш продукт по качеству анализа, как вы говорите, лучше других?
давайте я приведу пример как это делается в мире, так, что бы ни у кого не возникало вопросов
вот компания baidu, а вот ее главный по науке Andrew Ng, а вот его выступление на gtc 2015, а вот его слайд про их новую собственную разработку, которая лучше всех в мире распознает лица на общедоступном бенчмарк датасете, и вот он прямо говорит, что все остальные хуже них, приводя названия компаний
слайд
digitaldust Автор
27.04.2015 16:58Поскольку пост о другом, не хочется углубляться в оффтоп.
Давайте дальше в личке, если вы не против.

bya
28.04.2015 08:53-1SciPy + Cython для повышения производительности. Быстрая и качественная разработка+легкая оптимизация без сильного переписывания кода. PySide для интерфейса. Если Вы считаете. что лучше использовать монстры Matlab и .NET., то это Ваши проблемы.
И главное, если у вас проблема с плавающий точкой, не забывайте, что арифметические операции +, * коммутативны, но не ассоциативны. В этом весь корень проблем.
Mrrl
28.04.2015 12:24+2Сегодня обнаружил у себя очередную ошибку в алгоритме, написанном несколько лет назад. В алгоритме оптимизации методом наименьших квадратов при вычислении градиента пара координат вычислялась неправильно. Несмотря на это, всё работало, и после исправления лучше не стало. А вы говорите «ошибки вещественной арифметики»… Математические алгоритмы обладают громадной устойчивостью к ошибкам, их даже неправильным индексом или перепутанным знаком не собьёшь :)

gbg
О сравнении чисел с плавающей запятой тут не писал только ленивый. Замечу, что (коль скоро у вас есть математики в штате) такое сравнение нужно делать на основании того, как представлено сравнение в числовых множествах, с которыми работает задача. Да, чаще всего это модуль разности (абсолютная разность), но иногда предлагают комбинацию абсолютной и относительной разности, как в этом топике.
Странно, что ничего не сказано о «настоящем» тестировании математических алгоритмов (триада «аппроксимация — устойчивость — сходимость»)
Mrrl
Про устойчивость как раз сказано. Если ошибки, вызванные ограниченной разрядностью вещественных чисел, существенно влияют на результат — то о какой устойчивости можно говорить? Алгоритмы явно работают в зоне хаотического поведения.
gbg
Устойчивость, как правило, нужно доказывать чисто математически, например анализируя спектры операторов, входящих в задачу. Если критерий устойчивости не работает, алгоритм и при ста знаках точности насосет погрешность.
Здесь же нам привели «студенческие» проблемы. В эту копилку можно добавить «всю задачу считали в double, но один параметр посчитали во float, теперь удивляемся» и «в матлабе был красивый график, а у программы получился забор».
Mrrl
То, что алгоритм «насосёт погрешность», не всегда страшно. Правильный результат не обязан быть единственным — главное, чтобы он с нужной точностью удовлетворял заданным условиям. Особенно, когда расчёты идут с элементами случайности — и анализируется статистика нужных характеристик исходов. Правда, не представляю, как такое можно тестировать. Впрочем, и «генерация наборов входных данных» мне кажется чем-то нереальным. Когда анализируется сигнал в реальном времени, например, что можно генерировать? Синтетический гигабайт входного потока? Но, конечно, всё зависит от задачи…
Про спектр — спасибо, что напомнили. У меня уже несколько лет в промышленном коде используется решение почти вырожденной системы (отношение собственных значений — порядка 10^25), но ничего, как-то работает. Всё руки не доходят сделать ситуацию более регулярной.
digitaldust Автор
Проблемы скорее не «студенческие», а «инженерные».
Было бы интересно перевести дискуссию в более инженерное русло.
Пытался ли кто-нибудь на работе доказывать устойчивость эвристического алгоритма прогнозирования, который он придумал для прогнозирования продаж молока?
Как понять, когда нужно этим заниматься, когда нет?
gbg
Если с позиции математики подходить — нужно доказывать всегда, это просто один из этапов работы добросовестного математика.
Если с позиции бизнеса подходить — если кривая работа этого решения приносит убытка больше, чем стоимость исследования ошибки. Именно исследования, потому что потом еще есть этап исправления, который по отдельному прайсу.
Если с позиции инженера: «Работает — не трогай!»
digitaldust Автор
Не совсем.
В реальных данных из реальной жизни часто встречаются «круглые» значения.
После произведения математических операций над ними производные значения тоже часто получаются «круглыми».
Затем это производное значение сравнивается, например, с нулём: больше нуля или нет. В этой ситуации при прямом сравнении на "> 0" результат заранее не известен. Приходится сравнивать на "> 0 — eps".
Результат такого сравнения скорее всего существенно не влияет на результат по качеству. Но получившиеся на выходе алгоритма цифры будут другими и программиста скорее всего заставят искать ошибку там, где её нет.
Mrrl
Если сравнение с нулём влияет на логику выполнения алгоритма, то есть несколько вариантов.
A. От знака f(x) действительно зависит результат. Например, если f(x) > 0, то критерий пройден, в противном случае нет. Тогда ситуация, где f(x) близко к нулю, является пограничной, и оба результата выполнения допустимы. Сравнивать с 0-eps здесь смысла нет.
B. В зависимости от знака получаются разные промежуточные результаты, или даже разные результаты работы алгоритма, но на то, что увидит пользователь, они не повлияют. Например, какую диагональ 4-угольника провести при триангуляции выпуклой оболочки. Формально разные диагонали дадут разные результаты, но фактически тело (и его изображение) будет одним и тем же. Здесь тоже возиться с eps незачем — может оказаться только хуже.
C. Самый неприятный случай — когда логика программы меняется при f(x)=0. Например, когда при решении какого-нибудь дифф.уравнения мы переходим от функции 10001*exp(-x)-10000*exp(-1.0001*x) к exp(-x)*(1+x). Здесь от eps уже не отмахнёшься — если f(x) достаточно близко к нулю, то в представлении функции могут получиться слишком большие коэффициенты, и нужно искать либо баланс — когда замена eps на 0 даст меньшую ошибку, чем потеря точности — либо более регулярную модель.
В случае, если тестовый пример привёл к ситуации А, то математик сам дурак — нечего давать тесты с неустойчивым результатом.
В случае С явное сравнение с eps будет и в коде математика, и в коде программиста. И возникнет более серьёзная проблема — как быть с тестами, в которых f(x) близко к eps. Такие тесты должны быть, чтобы удостовериться в достаточно одинаковом поведении по обеим сторонам границы. Как написать сравнение, чтобы C# и MatLab давали одинаковый результат, уже непонятно. Ответ — не давать таких тестов, а предложить f(x)=eps/2 и f(x)=2*eps.
Возможно, проблема будет в случае B. По-хорошему, написать f(x) < eps надо и в MatLab, и в C# — тогда появится шанс, что на пограничном тесте логика будет одинаковой. Но ведь кроме этого потребуется, чтобы был, например, одинаковый порядок перебора коллекций — ведь выбор первого элемента множества тоже может повлиять на логику. И хуже всего в этом подходе — что если число eps/2 вы объявите отрицательным, то модель может стать противоречивой, и уже не в тестовом, а в рабочем режиме. Честное слово, я бы оставил f(x) < 0. И пусть этот пример программист разбирает вместе с математиком, чтобы быть уверенным, что разное поведение это не ошибка.
EndUser
Я думаю, что математики знаю определение и устойчивости, и сходимости, включая неточное представление чисел — они не зря численные методы в приложении к диплому имеют, которые созданы именно для вычтеха.
Достаточно попросить их доказать вам, что они решили именно запрошенную задачу, а не что либо другое случайно или злонамеренно. Такой аппарат у них есть.
digitaldust Автор
Ценное замечание! Позволю себе перетащить в топик формулу:
и ссылку: realtimecollisiondetection.net/blog/?p=89Касательно «аппроксимация — устойчивость — сходимость» — этот пост по другой тематике. Но раз уж вопрос прозвучал: вы знаете хорошую статью/автора по этой теме? Применительно к IT?
gbg
Любой учебник по численным методам, лучше импортный (наши написаны дичайшим канцеляритом и их месседж «смотрите, какой я академический академик и какие рулезные термины я знаю»). Патанкар (Численные методы для задач теплообмена и динамики жидкости), например, написан вполне человеческим языком — его можно студентам давать для самостоятельного просвещения. Из IT там правда исходники в конце книги на последней странице (Фортран-77 конечно же), но подружиться с вычислительной математикой он поможет.
digitaldust Автор
Оговорюсь, что я инженер, а не математик, и поднятый вопрос интересует меня прежде всего с позиции облегчения моих инженерных проблем.
Отсюда интерес к тому, как эту теорию используют в IT для бизнес-задач.
Хотя вспомнить математику для мозгов никогда не вредно.
gbg
Тот учебник как раз на инженеров рассчитан, как будущих, так и состоявшихся.