

Чтобы понять, как все это работает, давайте начнем с показателей Stack Overflow. Итак, ниже приводится статистика за 12 ноября 2013 и 9 февраля 2016 года:
- 209,420,973 (+61,336,090) HTTP-запросов к нашему балансировщику нагрузки;
- 66,294,789 (+30,199,477) страниц было загружено;
- 1,240,266,346,053 (+406,273,363,426) битов (1.24 TБ) отосланного HTTP-трафика;
- 569,449,470,023 (+282,874,825,991) битов (569 ГБ) всего получено;
- 3,084,303,599,266 (+1,958,311,041,954) битов (3.08 ТБ) всего отослано;
- 504,816,843 (+170,244,740) SQL-запросов (только из HTTP-запросов);
- 5,831,683,114 (+5,418,818,063) обращений к Redis;
- 17,158,874 (not tracked in 2013) поисков в Elastic;
- 3,661,134 (+57,716) запросов Tag Engine;
- 607,073,066 (+48,848,481) мс (168 часов) выполнения SQL-запросов;
- 10,396,073 (-88,950,843) мс (2.8 часов) затрачено на обращение к Redis;
- 147,018,571 (+14,634,512) мс (40.8 часов) затрачено на запросы к Tag Engine;
- 1,609,944,301 (-1,118,232,744) мс (447 часов) затрачено на обработку в ASP.Net;
- 22.71 (-5.29) мс в среднем (19.12 мс в ASP.Net) на формирование каждой из 49,180,275 запрошенных страниц;
- 11.80 (-53.2) мс в среднем (8.81 мс в ASP.Net) на формирование каждой из 6,370,076 домашних страниц.
Вы можете спросить, почему существенно сократилась продолжительность обработки в ASP.Net по сравнению с 2013 годом (когда было 757 часов) несмотря на прибавление 61 миллиона запросов в день. Это произошло как и из-за модернизации оборудования в начале 2015 года, так и из-за некоторого изменения параметров в самих приложениях. Пожалуйста, не забывайте, что производительность – это наша отличительная особенность. Если Вы хотите, чтобы я более подробно рассказал о характеристиках оборудования – без проблем. В следующем посте будут подробные спецификации железа всех серверов, которые обеспечивают работу сайта.
Итак, что изменилось за прошедшие 2 года? Кроме замены некоторых серверов и сетевого оборудования, не очень многое. Вот укрупненный список хардварной части, которая обеспечивает работу ресурса (выделены различия по сравнению с 2013 годом):
- 4 Microsoft SQL Servers (новое железо для 2-х из них);
- 11 Web-серверов IIS (новое оборудование);
- 2 сервера Redis (новое оборудование);
- 3 сервера Tag Engine (новое оборудование для 2-х из 3-х);
- 3 сервера Elasticsearch (те же, старые);
- 4 балансировщика нагрузки HAProxy (добавлено 2 для поддержки CloudFlare);
- 2 брандмауэра Fortinet 800C (вместо Cisco 5525-X ASAs);
- 2 маршрутизатора Cisco ASR-1001 (вместо маршрутизаторов Cisco 3945);
- 2 маршрутизатора Cisco ASR-1001-x (новые!).
Что нам необходимо, чтобы запустить Stack Overflow? Этот процесс не сильно изменился с 2013 года, но из-за оптимизации и нового железа, нам необходим только один web-сервер. Мы этого не хотели, но несколько раз успешно проверили. Вношу ясность: я заявляю, что это работает. Я не утверждаю, что это (запуск SO на единственном web-сервере) — хорошая затея, хотя каждый раз выглядит весьма забавно.
Теперь, когда у нас есть некоторые числа для понятия масштаба, давайте рассмотрим, как мы это делаем. Так как немногие системы работают в полной изоляции (и наша не исключение), часто конкретные архитектурные решения почти не имеют смысла без общей картины того, как эти части взаимодействуют между собой. Цель нашей статьи – охватить эту общую картину. Во многочисленных последующих постах будут подробно рассмотрены отдельные области. Это логистический обзор только основных особенностей нашего «hardware», а уже потом, следующих постах, они будут рассмотрены более детально.
Для того, чтобы Вы поняли, как сегодня выглядит наше оборудование, привожу несколько своих фото рэковой стойки А (в сравнении с ее «сестрой» стойкой B), сделанных во время нашего переоборудования в феврале 2015 года:

И, как не парадоксально, с той недели у меня в альбоме есть еще 255 фотографий (в сумме 256, и да — это не случайное число). Теперь, давайте рассмотрим оборудование. Вот логическая схема взаимодействия главных систем:

Основные правила
Вот некоторые всеобще применяемые правила, поэтому я не буду повторять их для каждой системы:
- Все резервировано.
- Все сервера и сетевые устройства связаны между собой, по крайней мере, 2 x 10 ГБит/с каналами.
- Все сервера имеют 2 входа питания и 2 подвода питания от 2-х ИБП, подключенных к двум генераторам и двум сетевым линиям.
- Все сервера между рэками A и B имеют резервированного партнера (redundant partner).
- Все сервера и сервисы дважды резервированы через другой дата-центр (Колорадо), хотя здесь я буду больше говорить о Нью-Йорке.
- Все резервировано.
В сети Интернет
Сначала Вы должны найти нас – это DNS. Процесс нахождения нас должен быть быстрым, поэтому мы поручаем это CloudFlare (в настоящее время), так как их серверы DNS ближе почти всех остальных DNS мира. Мы обновляем наши записи DNS через API, а они делают «хостинг» DNS. Но поскольку мы «тормозы» с глубоко укоренившимися проблемами доверия (к другим), мы также все еще имеем наши собственные DNS-сервера. Если произойдет апокалипсис (вероятно, вызванный GPL, Punyon или кэшированием), а люди все еще будут хотеть программировать, чтобы не думать о нем, мы переключимся на них.
После того, как Вы найдете наше «секретное убежище», пойдет HTTP-трафик через одного из наших четырех Интернет провайдеров (Level 3, Zayo, Cogent, и Lightower в Нью-Йорке), и через один из наших четырех локальных маршрутизаторов. Для достижения максимальной эффективности, мы вместе с нашими провайдерами используем BGP (довольно стандартный) для управления трафиком и обеспечения нескольких путей его передачи. Маршрутизаторы ASR-1001 и ASR-1001-X объединены в 2 пары, каждая из которых обслуживает 2 провайдера в режиме активный/активный. Таким образом, мы обеспечиваем резервирование. Хотя они подключены все к той же физической сети 10 Гбит/с, внешний трафик проходит по отдельным изолированным внешним VLAN, которые также подключены к балансировщикам нагрузки. После прохождения через маршрутизаторы, трафик направляется к балансировщикам нагрузки.
Я думаю, что самое время упомянуть, что между нашими двумя дата-центрами мы используем линию MPLS на 10 Гбит/с, но это напрямую не связано с обслуживанием сайта. Она служит для дублирования данных и их быстрого восстановления в случаях, когда нам нужна пакетная передача. «Но Ник, это не резервирование!» Да, технически Вы правы (абсолютно правы): это – единственное «пятно» на нашей репутации. Но постойте! Через наших провайдеров мы имеем еще две более отказоустойчивые линии OSPF (по стоимости MPLS — № 1, а это № 2 и 3). Каждое из упомянутых устройств быстрее подключается к соответствующему устройству в Колорадо, и при отказе они распределяют между собой сбалансированный трафик. Мы смогли заставить оба устройства соединяться с обоими устройствами 4-мя способами, но все они и так одинаково хороши.
Идем дальше.
Балансировщики нагрузки (HAProxy)
Балансировщики нагрузки работают на HAProxy 1.5.15 под CentOS 7, предпочтительной у нас разновидности Linux. HAProxy также ограничивает и трафик TLS (SSL). Для поддержки HTTP/2 мы скоро начнем внимательно изучать HAProxy 1.7.
В отличие от всех других серверов с двойным сетевым подключением по LACP 10 Гбит/с, каждый балансировщик нагрузки имеет по 2 пары каналов 10 Гбит/с: одну для внешней сети и одну для DMZ. Для более эффективного управляемого согласования SSL эти «коробки» имеют память 64 ГБ или больше. Когда мы можем кэшировать в памяти больше сессий TLS для повторного использования, тратится меньше времени на образование нового соединения с тем же самым клиентом. Это означает, что мы можем возобновлять сессии и быстрее, и с меньшими затратами. Учитывая, что RAM в переводе на доллары довольно дешевая, это – легкий выбор.
Сами балансировщики нагрузки – довольно простые устройства. Мы создаем иллюзию, что разные сайты «сидят» на различных IP (в основном по вопросам сертификации и управления DNS), и маршрутизируем на различные выходные буфера основываясь, главным образом, на заголовках хоста. Единственными «знаменитыми» вещами, которые мы делаем, является ограничение скорости и некоторые захваты заголовков (отсылаемых с нашего уровня веб-узлов) в сообщение системного журнала HAProxy. Поэтому мы можем делать запись метрик производительности для каждого запроса. Мы также расскажем об этом позднее.
Уровень веб-узлов (IIS 8.5, ASP.Net MVC 5.2.3 и .Net 4.6.1)
Балансировщики нагрузки регулируют трафик 9-ти серверов, которые мы называем «Primary» (01-09), и 2-х web-серверов «Dev/meta» (10-11, среда нашей площадки). Серверы Primary управляют такими вещами, как Stack Overflow, Careers и всеми сайтами Stack Exchange, кроме сайтов meta.stackoverflow.com и meta.stackexchange.com, которые размещены на 2-х последних серверах. Основное приложение Q&A само по себе многопользовательское. Это означает, что одно приложение обслуживает запросы для всех Q&A сайтов. Скажем по-другому – мы можем управлять всей сетью Q&A одним пулом приложений на одном сервере. Другие приложения, такие как Careers, API v2, Mobile API и т.д. размещены отдельно. Вот так выглядят основной и dev-уровни в IIS:
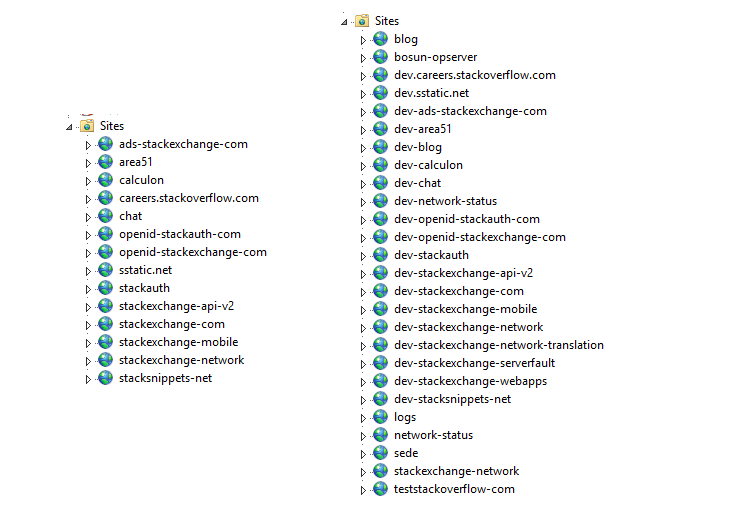
Вот так выглядит распределение Stack Overflow по уровню веб-узлов, напоминая Opserver (наша внутренняя dashboard):
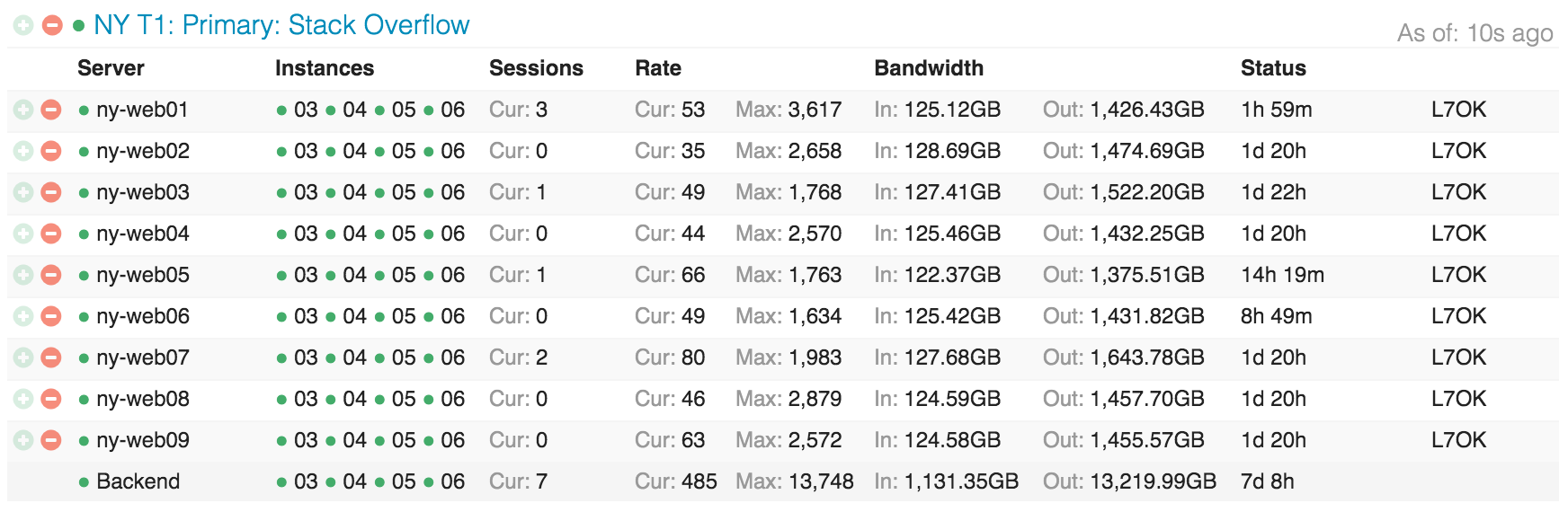
… а вот так выглядят web-серверы с точки зрения нагрузки:
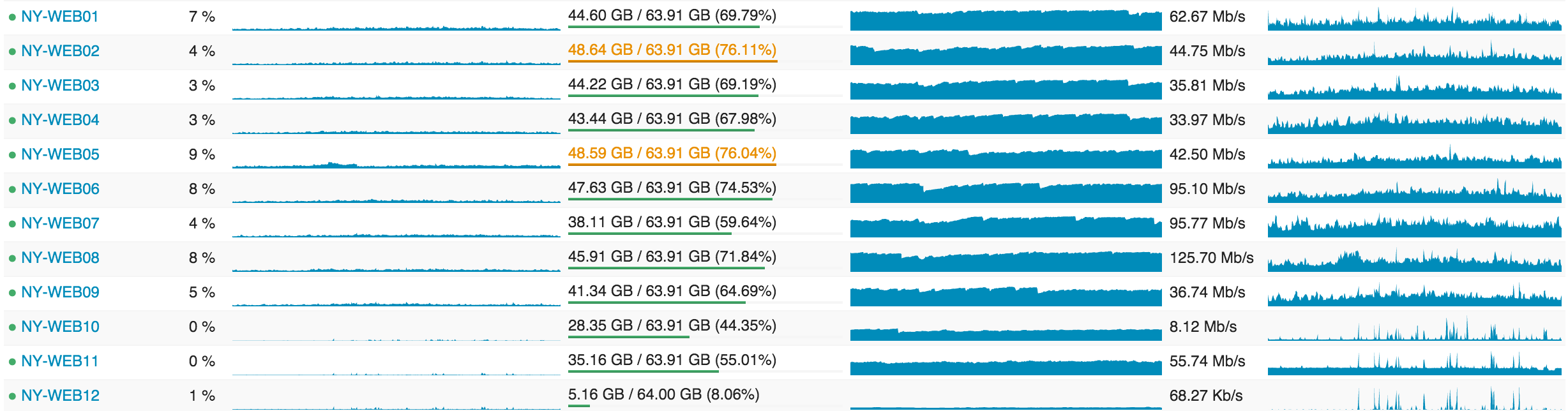
В следующих постах я коснусь того, почему мы так «сверхоснащены», но самыми важными моментами являются: кольцевое построение (rolling builds), операционный резерв и избыточность.
Сервисное звено (IIS, ASP.Net MVC 5.2.3, .Net 4.6.1 и HTTP.SYS)
В основе этих web-серверов лежит очень похожее «сервисное звено». Оно также работает на IIS 8.5 под Windows 2012R2 и отвечает за внутренние службы, поддерживая вычислительный уровень веб-узлов и другие внутренние системы. Здесь два крупных «игрока»: «Stack Server», который управляет Tag Engine и основан на http.sys (не под IIS), и Providence API (работает на IIS). Забавный факт: я должен настроить маску соответствия для каждого из этих 2-х процессов, чтобы прописать их на разных процессорах, потому что Stack Server «забивает» кэши L2 и L3 при обновлении списка вопросов каждые 2 минуты.
Эти сервисные «коробки» выполняют ответственную работу по поднятию Tag Engine и внутренних API, где нам нужна избыточность, но не 9-ти кратная. Например, загрузка из базы данных (в настоящее время 2-х) всех постов и их тэгов, которые изменяются каждую n-ную минуту, не очень «дешевая». Мы не хотим загружать все это 9 раз на уровень веб-узлов; достаточно 3 раза и это обеспечивает нам достаточную «безопасность». Кроме того, на уровне оборудования мы конфигурируем эти «коробки» по-разному, чтобы они были более оптимизированы под различные характеристики вычислительной нагрузки Tag Engine и гибкого индексирования (которое также здесь работает). Сам по себе «Tag Engine» является относительно сложной темой и ему будет посвящен отдельный пост. Основной момент: когда Вы заходите на /questions/tagged/java, вы нагружаете Tag Engine, чтобы определить соответствующие запросы. Он делает все наше сопоставление тэгов вне процесса поиска, поэтому новая навигация и все прочее используют эти сервисы для обработки данных.
Кэш и Pub/Sub (Redis)
Здесь мы используем Redis для нескольких вещей и они вряд ли будут сильно изменяться. Несмотря на выполнение примерно 160 миллиардов операций в месяц, в каждый момент загрузка центрального процессора менее 2%. Обычно намного ниже:
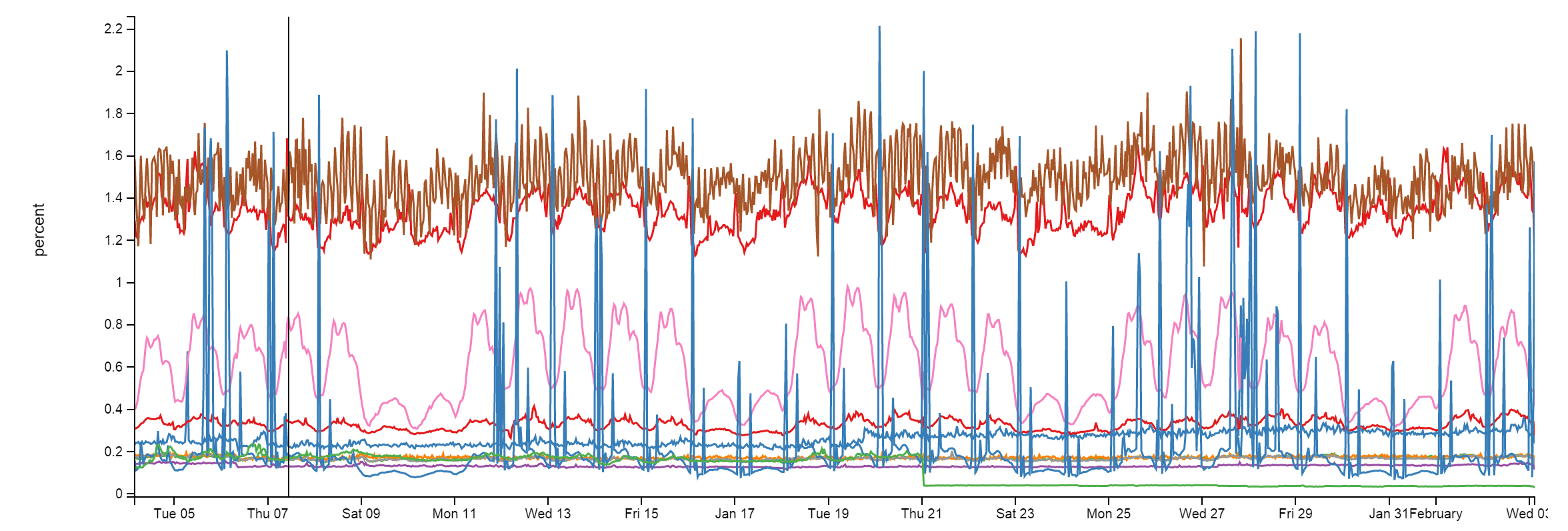
С Redis мы имеем систему кэшей L1/L2. «L1» – это кэш HTTP на web-серверах или каком-либо работающем приложении. «L2» обращается к Redis за выборкой значений. Наши значения сохраняются в формате Protobuf через protobuf-dot-net от Марка Грэвелла (Marc Gravell). Для клиента мы используем StackExchange.Redis – open source проект. Когда один web-сервер получает «промах кэша» (cache miss) L1, либо L2, он берет выборку из источника (запрос к базе данных, вызов API и т.д.) и помещает результат и в местный кэш, и в Redis. Следующий сервер, нуждающийся в выборке, может получить «промах кэша» L1, но найдет ее в L2/Redis, экономя на запросе к базе данных или вызове API.
Также у нас работает много Q&A сайтов, поэтому у каждого сайта есть свое собственное кэширование L1/L2: по ключевому префиксу в L1 и по ID базы данных в L2/Redis. Более подробно этот вопрос мы рассмотрим в следующих постах.
Вместе с 2-мя основными серверами Redis (мастер/ведомый), которые управляют всеми запросами к сайтам, у нас также есть система машинного обучения, работающая на 2-х более специализированных серверах (из-за памяти). Она используется для отображения рекомендованных запросов на домашней странице, улучшения выдачи и т.д. Эта платформа, называемая Providence, у нас обслуживается Кевином Монтроузом (Kevin Montrose).
Основные серверы Redis имеют по 256 ГБ RAM (используется около 90 ГБ), а в серверах Providence установлено по 384 ГБ RAM (используется около 125 ГБ).
Redis используется не только для работы с кэшем – он также имеет алгоритм «publish & subscriber» (публикация и подписка), работающий так, что один сервер может разослать сообщение, а все другие «подписчики» получат его – включая нижерасположенных клиентов на ведомых серверах Redis. Мы используем этот алгоритм для очистки кэша L1 на других серверах, когда один web-сервер делает удаление для сохранения согласованности. Но есть и другое важное применение: websockets.
Websocket’ы (NetGain)
Мы используем websocket’ы для отправки пользователям в реальном времени обновлений, таких как уведомления, подсчет голосов, новое навигационное исчисление, новые ответы и комментарии и т.п.
Сами сокет-серверы используют необработанные сокеты, выполняемые на уровне веб-узлов. Это — очень маленькое приложение на вершине нашей открытой библиотеки: StackExchange.NetGain. Во время пиковой нагрузки у нас одновременно открыто около 500,000 параллельных каналов websocket. Это — множество браузеров. Забавный факт: некоторые из этих страниц были открыты более 18 месяцев назад. Мы не знаем почему. Кто-то должен проверить, живы ли еще эти разработчики.
Вот так изменялось на этой неделе число одновременно открытых websocket:
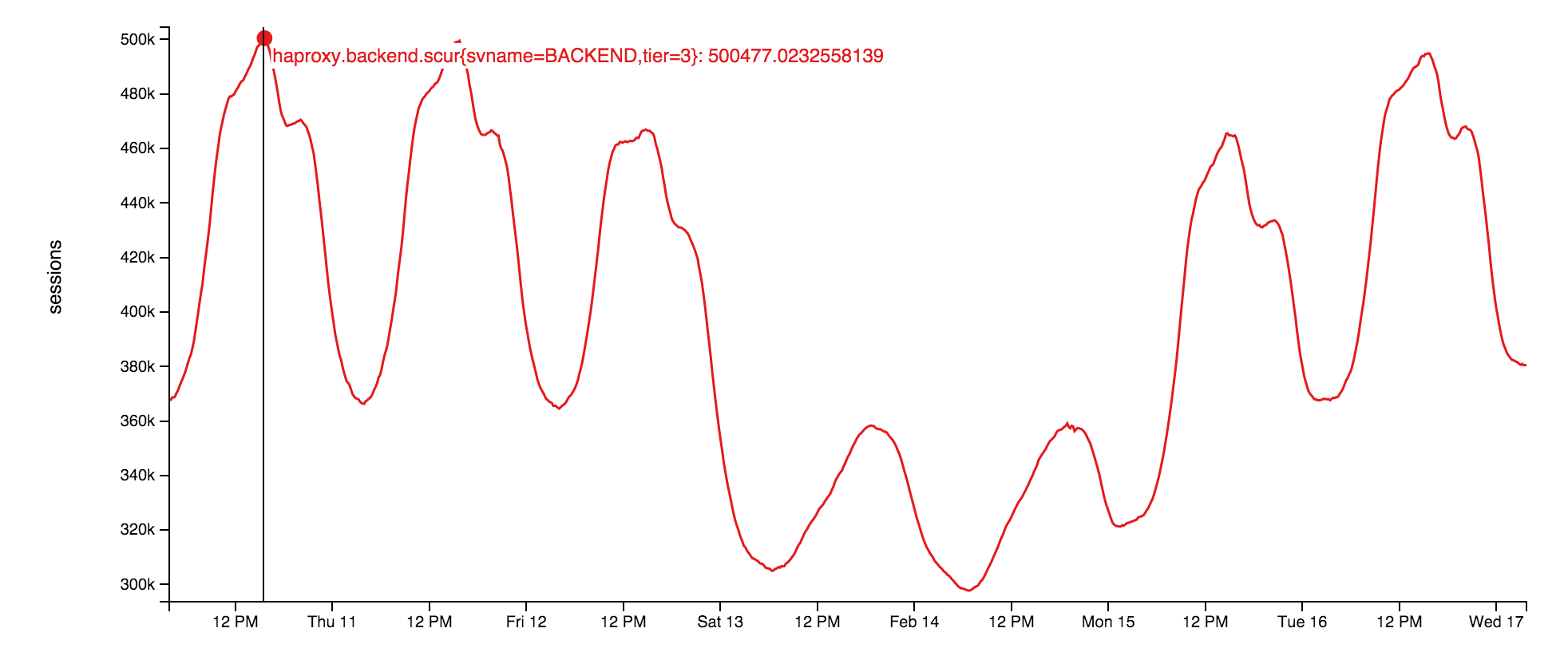
Почему websocket? При нашем масштабе они намного более эффективны, чем опрос. Просто таким способом мы можем передать пользователю больше данных при меньшем количестве используемых ресурсов, к тому же более быстро. Но у них тоже есть проблемы, хотя временный порт и полный перебор всех дескрипторов файлов на балансировщике нагрузки – несерьезные проблемы. Мы расскажем о них позже.
Поиск (Elasticsearch)
Спойлер: это не то, от чего можно прийти в восторг.
Уровень веб-узлов выполняет солидную поисковую работу по сравнению с Elasticsearch 1.4, который использует очень тонкий высокоэффективный клиент StackExchange.Elastic. В отличие от большинства других средств, мы не планируем выкладывать его в открытый доступ просто потому, что он отражает только очень небольшое подмножество API, которые мы используем. Я убежден, что его выпуск «в свет» принесет больше вреда, чем пользы из-за путаницы среди разработчиков. Мы используем Elastic для поиска, вычисления связанных запросов и советов, как формировать вопрос.
Каждый кластер Elastic (по одному такому есть в каждом дата-центре) имеет 3 узла, а каждый сайт имеет свой собственный индекс. Careers имеет несколько дополнительных индексов. Это делает нашу систему немного нестандартной: наши 3 серверных кластера немного больше «накачаны» всеми этими хранилищами SSD, памятью в 192 ГБ и двойной сетью по 10 Гбит/с на каждый канал.
Те же самые прикладные домены (да, мы здесь тронуты на .Net Core …) в Stack Server, на котором установлен Tag Engine, также непрерывно индексируют элементы в Elasticsearch. Здесь мы применяем некоторые уловки, такие как ROWVERSION в SQL Server (источник данных), сравниваемый с документом «последней позиции» в Elastic. Так как он ведет себя как последовательность, мы можем просто использовать и индексировать любые элементы, которые изменились с момента последнего прохода.
Главной причиной того, что мы остановились на Elasticsearch вместо чего-то подобного полнотекстовому поиску SQL, является масштабируемость и лучшее распределение денег. SQL CPU достаточно дорогие, Elastic же дешевый и сегодня имеет намного лучшие характеристики. Почему не Solr? Мы хотим искать по всей сети (сразу много индексов), но это не поддерживалось Solr во время принятия решения. Причиной того, что мы еще не перешли на 2.x, является солидная доля «types», из-за которых нам надо будет все переиндексировать для обновления. У меня просто нет достаточно времени, чтобы когда-нибудь составить план и сделать необходимые для перехода изменения.
Базы данных (SQL-сервер)
Мы используем SQL Server как наш единственный источник достоверной информации. Все данные Elastic и Redis получают от SQL-сервера. У нас работают 2 кластера SQL-серверов под AlwaysOn Availability Groups. У каждого из этих кластеров есть один мастер (выполняющий почти всю нагрузку) и одна реплика в Нью-Йорке. Кроме этого, еще есть одна реплика в Колорадо (наш дата-центр с динамическим копированием). Все реплики асинхронные.
Первый кластер – набор серверов Dell R720xd, у каждого 384 ГБ RAM, 4 TB PCIe SSD и 2 x 12 ядер. На нем установлены Stack Overflow, Sites (имеет дурную славу, я объясню позже), PRIZM и базы данных Mobile.
Второй кластер – это набор серверов Dell R730xd, у каждого 768 ГБ RAM, 6 TB PCIe SSD и 2 x 8 ядер. На этом кластере стоит все остальное. Список «всего остального» включает Careers, Open ID, Chat, наш Exception log и некоторые Q&A сайты (например, Super User, Server Fault и т.д.).
Использование CPU на уровне баз данных – это то, чего мы предпочитаем избегать, но, фактически, в данный момент оно немного повысилось из-за некоторых проблем с кэшем, которые мы сейчас решаем. Сейчас NY-SQL02 и 04 назначены мастерами, 01 и 03 – репликами, которые мы сегодня перезагрузили после обновления SSD. Вот как выглядят прошедшие 24 часа:

Мы используем SQL довольно просто. Ведь просто – это быстро. Хотя некоторые запросы могут быть безумными, наше взаимодействие с SQL само по себе – просто классика. У нас есть одна «древняя» Linq2Sql, но все новые разработки используют Dapper – наш выложенный в открытый доступ Micro-ORM, использующий POCOs. Позвольте сказать по-другому: Stack Overflow имеет только 1 хранимую в базе данных процедуру, и я намереваюсь перевести тот последний кусок в код.
Библиотеки
Хорошо, позвольте нам переключиться на что-то, что может непосредственно помочь Вам. Некоторые из этих вещей я упомянул выше. Здесь я предоставлю список большинства открытых .Net-библиотек, которые мы поддерживаем для использования во всем мире. Мы выкладываем их в открытый доступ, поскольку они не имеют никакой ключевой ценности для бизнеса, но могут помочь миру разработчиков. Я надеюсь, что Вы их сочтете полезными:
- Dapper (.Net Core) — высокопроизводительный Micro-ORM для ADO.Net;
- StackExchange.Redis – высокопроизводительный клиент Redis;
- MiniProfiler – малообъемный профайлер, который мы используем на каждой странице (поддерживает только Ruby, Go и Node);
- Exceptional – регистратор ошибок для SQL, JSON, MySQL, и т.п;
- Jil — высокопроизводительный (де) сериализатор JSON ;
- Sigil – помощник генерации .Net CIL (когда C# не достаточно быстрый);
- NetGain — высокопроизводительный сервер websocket ;
- Opserver — контрольная приборная панель, опрашивающая напрямую большинство систем и также получающая данные от Orion, Bosun или WMI;
- Bosun – система мониторинга серверных СУБД, написанная на Go.
Далее последует подробный список имеющегося железа, на котором работает наш софт. Затем мы пойдем дальше. Оставайтесь с нами.
Комментарии (29)

gotch
02.03.2016 18:54+20Ну вот, на горе хейтерам с аргументацией уровня "На вашей винде можно только кривой sharepoint запустить, и то, сколько не настраивай, все равно будет падать каждые 10 секунд". :-)
Профессионалы они и есть профессионалы, спасибо за перевод.
vba
03.03.2016 11:45+2Ну винда там мало влияет на производительность, это скорее вопрос железа и организации. А то что можно эффективно использовать и винду, то это не для кого не секрет. Ведь не зря и MS копает в том же направлении, тут вам и сервера с минимальным GUI и автоматизация за счет PS. Хотя до полного счастья далековато, но прогресс на лицо.



polarnik
02.03.2016 19:01Подскажите по HAProxy.
В описанном проекте HAProxy балансирует, делает SSL offloading. Кеширование ответов на запросы реализовано программно, Redis используется в качестве кеша.
HAProxy может кешировать ответы?
Почему спрашиваю. Есть проект, где работает связка HAProxy + Oracle WebLogic (аналог текущей связки HAProxy + IIS). Получил отказ на предложение добавить nginx для кеширования и разгрузки Oracle WebLogic, аргумент для отказа — уже есть HAProxy.
Scratch
02.03.2016 19:18+1Лучше для такого использовать какой-нибудь varnish. Мы как раз его прикручиваем к haproxy сейчас перед IIS
polarnik
03.03.2016 10:38Спасибо.
Перечитал статью, для кеширования статики StackOverflow, видимо, используют CloudFlare — про кеширование DNS в статье написано, про кеширование статики — предположил. А Redis кеширует работу с базой данных и сервисами. И поэтому у них нет ни varnish ни nginx.

lostpassword
02.03.2016 21:19+5Я верно понял, что весь StackOverflow, со всеми его дочерними площадками, данными и т. д. умещается на 33 серверах?!

justmara
02.03.2016 22:36+7- вообще-то 27 (остальное — не серверы ;)
- всё это имеет боевую нагрузку в районе 5-9% для веб, 6 и 13% для master-серверов SQL и 0-1% для slave. т.е. эти 27 серверов ещё имеют запас эдак на порядок.

Razaz
02.03.2016 22:43+5С вашего позволения дополню вас :)
Что нам необходимо, чтобы запустить Stack Overflow? Этот процесс не сильно изменился с 2013 года, но из-за оптимизации и нового железа, нам необходим только один web-сервер. Мы этого не хотели, но несколько раз успешно проверили. Вношу ясность: я заявляю, что это работает.
sergeylanz
03.03.2016 02:25+4у них сервера мощные очень 10 core/ 20 Threads
"The new web tier has dual Intel 2687W v3 processors and 64GB of DDR4 memory".
это вам не амазон с с3.xlarge 4 coregotch
03.03.2016 12:33+2Мощные, но, опять же, любопытно, не самые мощные. Intel 2699, 18 ядер. Такой еще бы и в 4-х сокетный сервер, вот это получится самолет. :)
С Microsoft SQL Server Enterprise, правда, такие шутки тяжело проходят. Там лицензии поядерные, и весьма дорогие.
AlanDenton
03.03.2016 12:57+1Просто дополню Ваш комментарий. Лицензии на ядра добавили начиная с 2012 версии. StackOverflow долгое время крутился на SQL Server 2008. Сейчас они используют SQL Server 2014 (мигрировали на него еще в 2013 когда был доступен CTP).
SantyagoSeaman
08.03.2016 11:50+1Справедливости ради замечу, что есть m4.10xlarge на 40 ядер. Но дорого :)
sergeylanz
08.03.2016 12:37+1но вот как раз для людей который любят говорить у нас все можно на один сервер поставить


Holms
02.03.2016 22:20было бы очень интересно прочитать а может посмотреть на реализацию L1, L2 cache на базе Redis, и как они находят и оповещают что надо обновить в кэше.
justmara
02.03.2016 22:27там же всё написано
Redis isn’t just for cache though, it also has a publish & subscriber mechanism where one server can publish a message and all other subscribers receive it—including downstream clients on Redis slaves. We use this mechanism to clear L1 caches on other servers when one web server does a removal for consistency
Собственно redis pub/sub

ZOXEXIVO
02.03.2016 23:31Интересно, как они используют JSON-сериализатор Jil?
Тоже в свое время перескакивал на альтернативные фреймворки (Jil, fastJSON, NetJSON), но появилось столько проблем, начиная с невозможностью сделать camelCase (Pascal на клиенте выглядит слишком странно) и заканчивая просто ошибками сериализации простых! объектов (Jil) + кучи Issues на GitHub по каждому из проектов, которые долго не закрываются…

ruslanys
03.03.2016 01:11О, теперь я знаю, что Stackoverflow написан на ASP.NET!
Спасибо!
igrishaev
03.03.2016 10:09Они этого никогда не скрывали. Джоэль Спольски вышел из рядов Микрософта.
IvaYan
03.03.2016 14:09Я, кстати, слышал, что Спольски ни за что не хотел использовать МС-стек при запуске проекта, но его уговорили, что ASP.NET будет лучше [чем то решение, которое он хотел выбрать]. Но сейчас почему-то не могу найти, где видел. Я это к тому, что то, что он вышел из МС в какой-то мере могло бы сыграть против ASP.NET
w1ld
03.03.2016 10:55Забавный факт: некоторые из этих страниц были открыты более 18 месяцев назад. Мы не знаем почему. Кто-то должен проверить, живы ли еще эти разработчики.
Как такое возможно? Может быть какой-нибудь бот держит эти вебсокеты
teleavtomatika
03.03.2016 14:26+1Легко. Я могу подключится на один из серверов, открыть там браузер, в нем — stack overflow, после чего отключится и не появляться там месяцок. Видать не один я такой.
ragequit
Как всегда, обо всех ошибках и прочих огрехах перевода прошу сообщать в ЛС или через контакты, указанные в профиле. Спасибо, приятного чтения.
AlanDenton
Спасибо за статью. К слову хотел скинуть ссылку на бекап базы StackOverflow. Данные там не все, но для тестирование 65Гб информации очень пригодилось.