
Коротко: планировали и уже выпускаем «джинна из бутылки».
Теперь вы можете получить облачное решение высочайшего уровня функциональности, включая уникальное распределенное управление гипервизором KVM, резервирование данных, компрессию, дедупликацию и прочее (сотни «фич») на практически любом серверном оборудовании (для тестов я например попробовал на HP G7 DL380 — все работает прекрасно). Бесплатно.
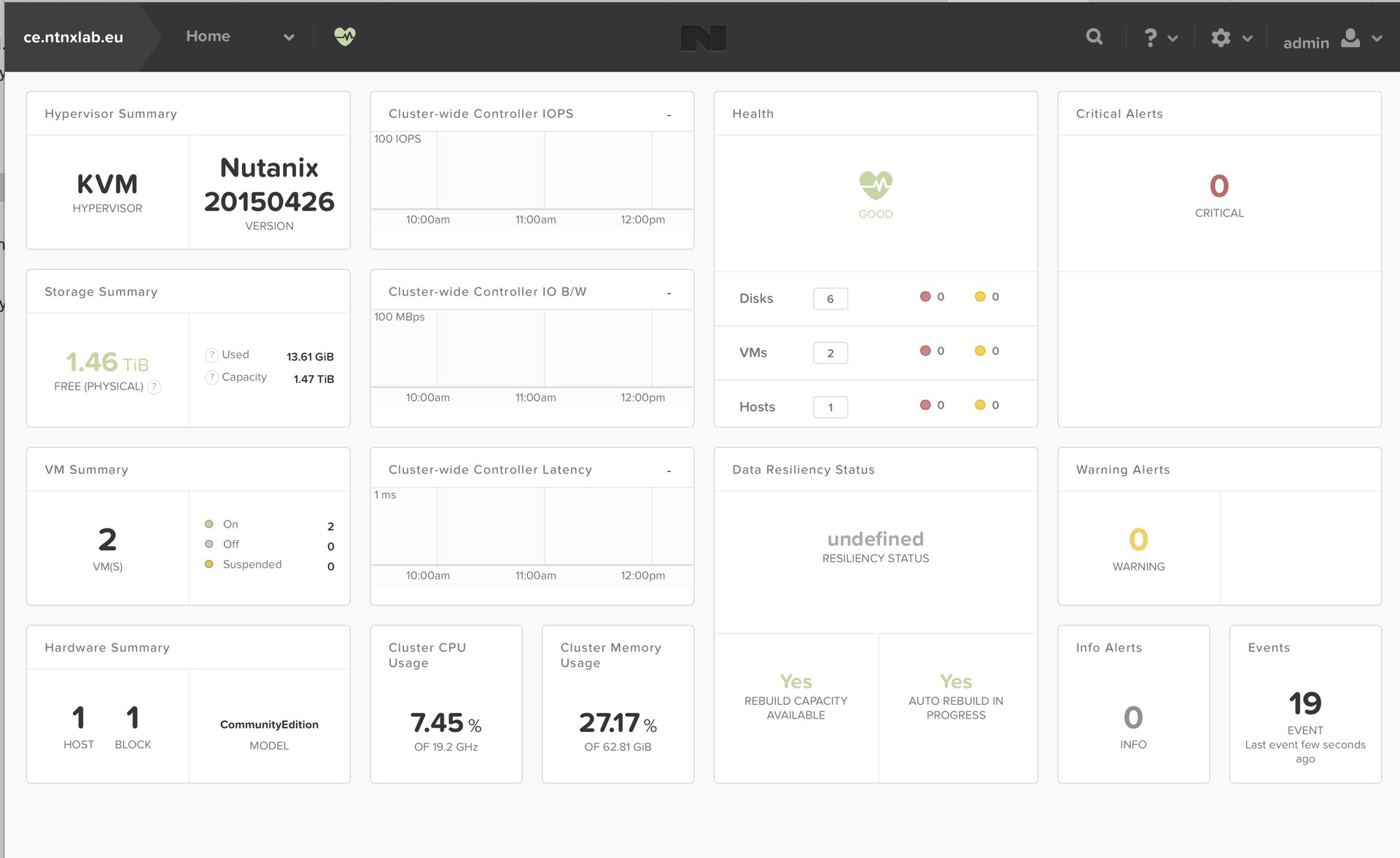
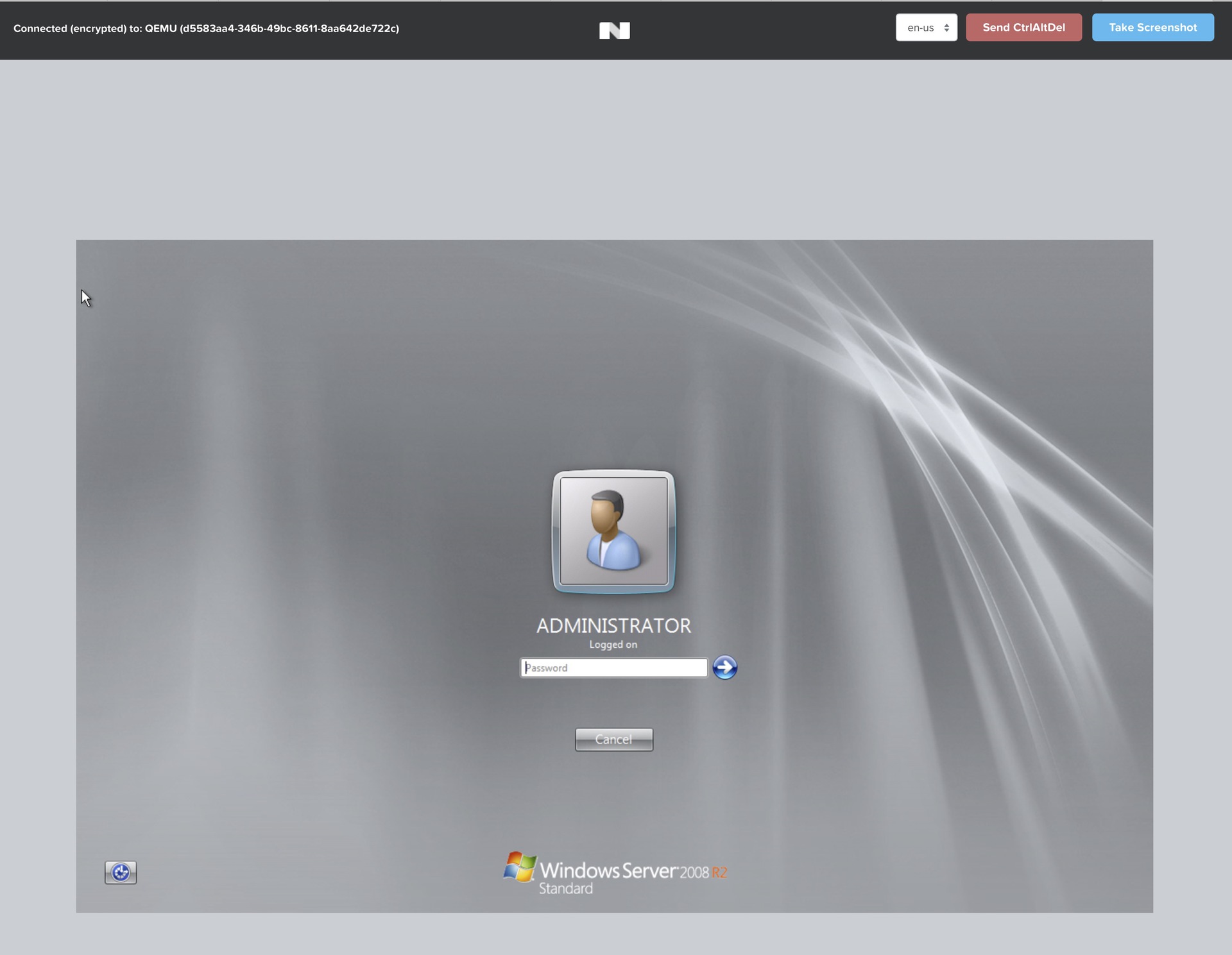
Скриншот — «кластер» из одного нода.
- 1, 3 или 4 (внимание! 2 сервера — не поддерживается) сервера (или «нода») с 4+ ядрами и поддержкой Intel VT-x,
- минимум один SSD диск (можно и all-flash (!)) от 200GB,
- 1 или больше HDD (холодный уровень хранения) от 500GB
- 16+ гигабайт ОЗУ (очевидно, что лучше 64+ если вы планируете запускать серьезные виртуальные машины),
- 1G или 10G сетевая плата (по ряду причин поддерживается только Интел)
Поддерживается фактор репликации 1 (для одного нода, нет защиты данных) или 2 (для 3 или 4 нодов)
CE редакция сделана на базе «боевой» NOS 4.1.3 (т.е. вы будете иметь бесплатно наиболее актуальную версию NOS), но метро кластер, бэкапы на Амазон и Prism Central (мультикластерное управление) пока в комплект не входят.
Все остальное, включая Disaster Recovery — полностью доступно.
Обновления ПО — «одной кнопкой», причем для полноценных кластеров — без остановки сервиса (на лету).
Инсталляция — очень простая, требуется скачать образ CE редакции и записать на USB флеш (от 8 гигабайт), с которого и будет впоследствии происходить загрузка.
Некоторые примеры управления:
Виртуальными машинами
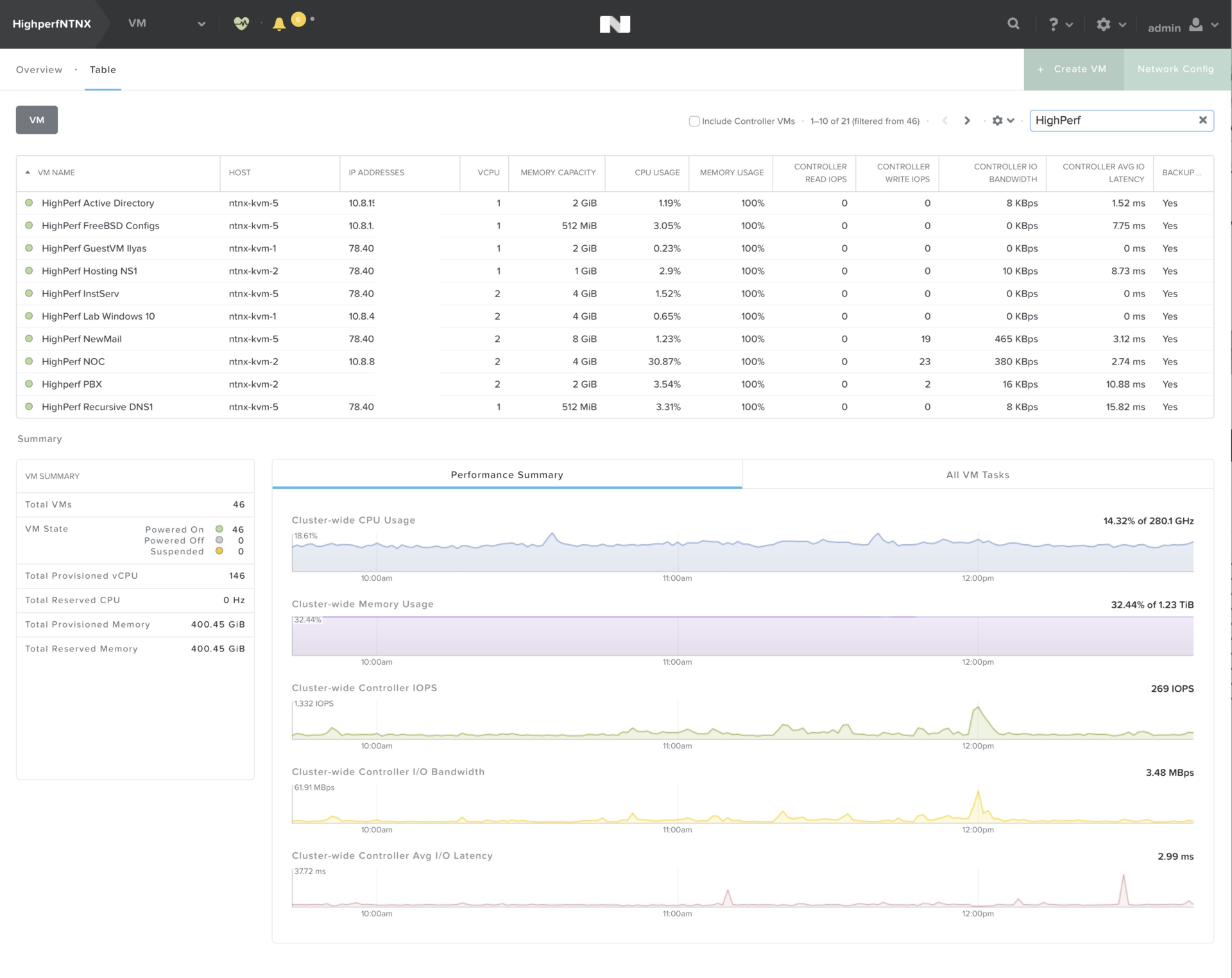
Управление сетями (да-да, включая распределенный коммутатор),

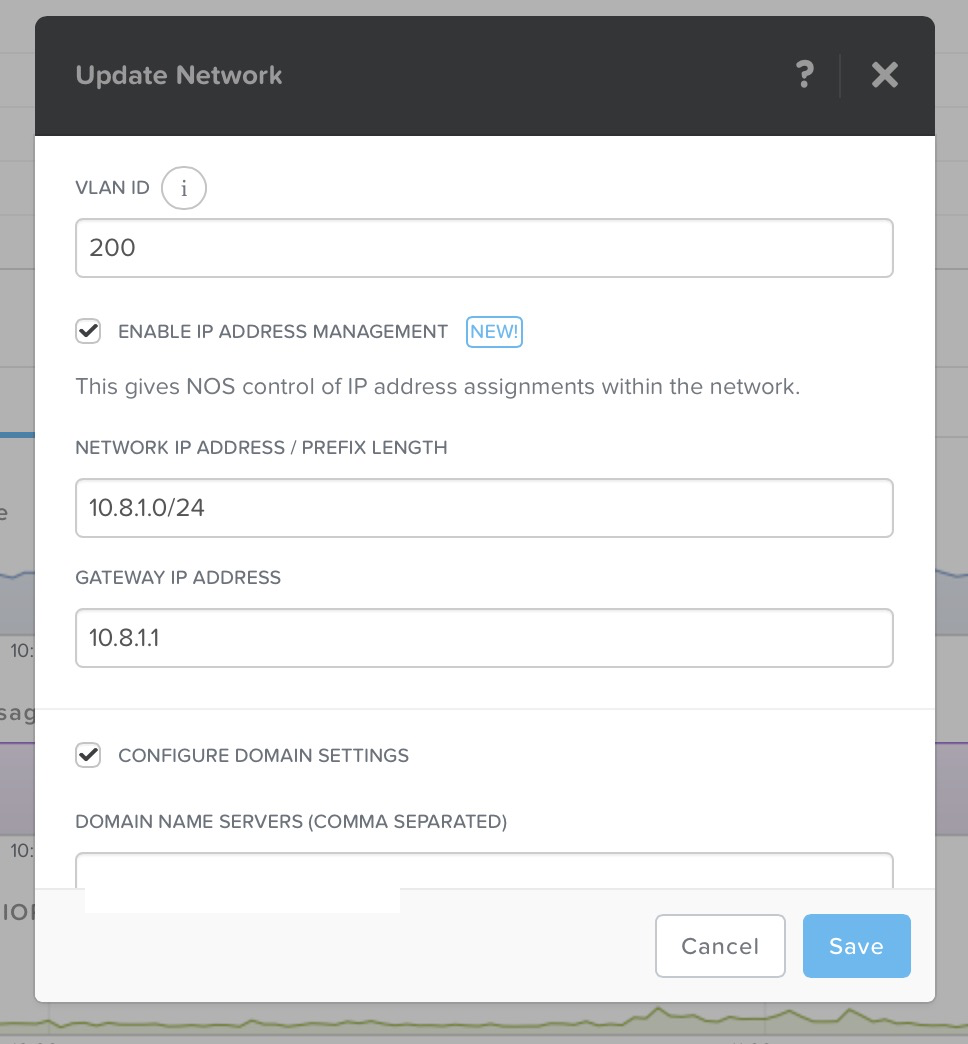
VLAN, DHCP
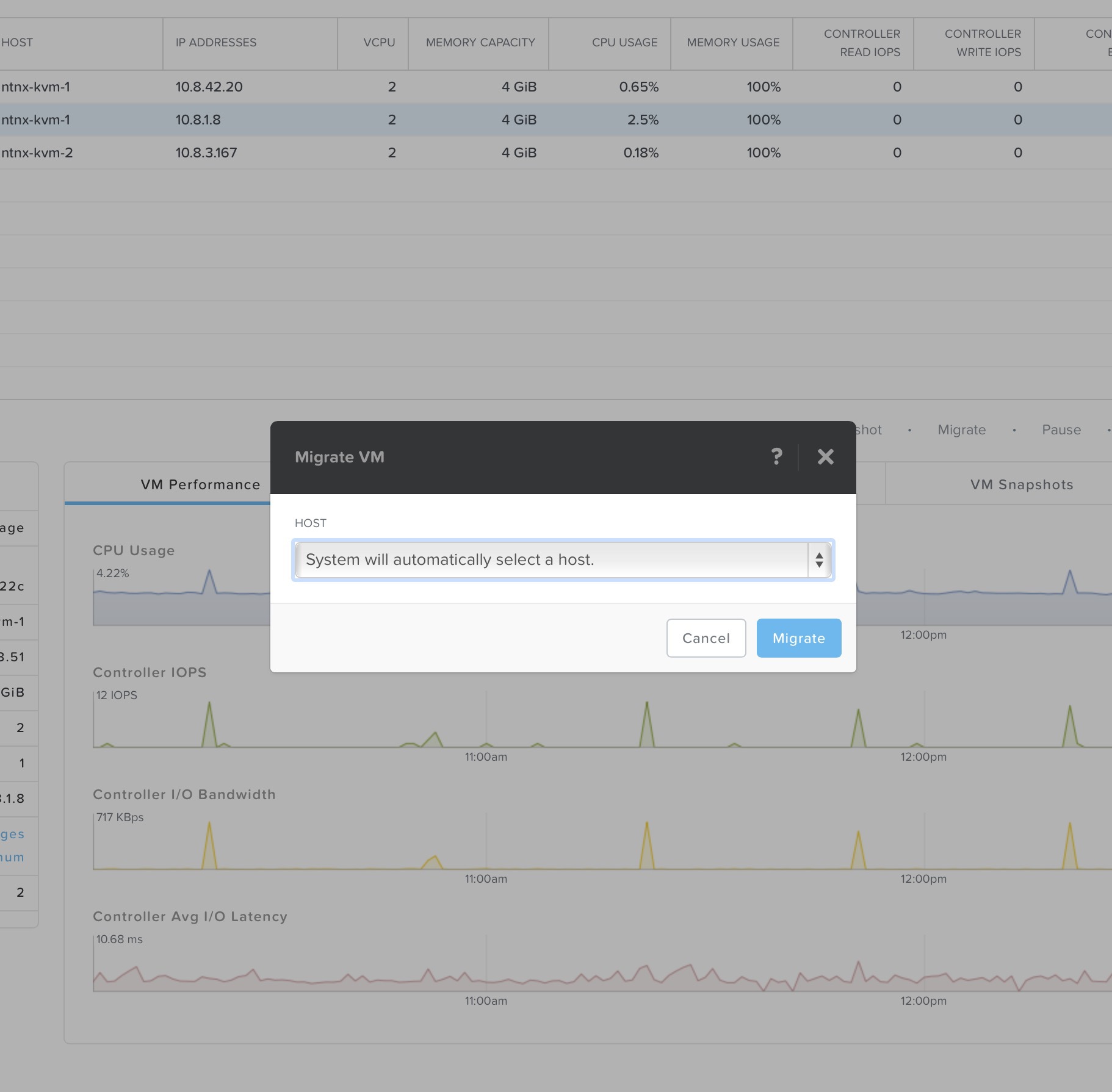
Клонирование, «живая» миграция

Консоль (примеры Windows 2012r2, 2008r2, FreeBSD, Linux)

Снапшоты / защита данных
Дедупликация / компрессия датасторов
И многое, многое другое.
Фактически, решение, которое используется крупнейшими корпорациями / правительственными службами в мире теперь доступно всем.
Поддержка CE редакции осуществляется средствами сообщества Nutanix Next Community, при устойчивом спросе — сделаем русский раздел.
Из личных рекомендаций — использовать LSI SAS контроллеры, прошитые в IT режим (в интернете доступно множество инструкций как это сделать), ввиду того что практически все аппаратные RAID адаптеры не приносят пользы (Nutanix на программном уровне работает быстрее и надежнее) но приносят проблемы из-за наличия ограниченных по производительности контроллеров / кэшей, также как слабо прогнозируемых задержек (latency).
Официальный анонс и «доступ для всех» — на нашей глобальной конференции Nutanix Next в Майями, где будет выступать множество крайне интересных докладчиков (включая Кондолизу Райс).
Вопросы?
p.s. мы постоянно работаем над улучшением продукта, возможно изменение спецификаций и функциональности.
Комментарии (123)


Meklon
13.05.2015 18:17У меня домашний сервер на Debian 8 со стандартными KVM машинами (i2p, owncloud и прочие). Сейчас использую virt-manager на десктопе для того, чтобы управлять всем этим безобразием. Можно ли удобно прикрутить это в моем варианте? Я понима, что это сильный оверхед, но тут явно удобнее и информативнее интерфейс.

shapa
13.05.2015 18:42+1virt-manager становится не нужным абсолютно, а KVM машины перенести (или VMware) — без проблем, надо будет их забэкапить куда-то и потом заново залить виртуальные диски.

navion
13.05.2015 22:19Хорошая управлялка для KVM даже интересней халявы — этакий AWS в коробке.
shapa
13.05.2015 22:22Она не просто «хорошая», она реально уникальная — конфигурации VM хранятся в NoSQL базе (cassandra жестко доработанная), поэтому сразу (начиная с 3-х нодов) отказоустойчивость в том числе management-plane (сравните с централизованными БД как у всех остальных).
Так что да, «амазон» в коробке. Да еще и REST api открыты все (100% функционала доступно через API)navion
13.05.2015 22:35А Citrix уже пилит под вас свой VDI или пока не было анонсов?
shapa
13.05.2015 22:44Скажем так, технических проблем особо нет.
Citrix на ESXi и HyperV на нас и так работает (официально валидированные конфигурации — мы партнеры, citrixready.citrix.com/ready/en_us/nutanix/nutanix-virtual-computing-platform ),
для KVM — без комментариев, но следите за новостями :D

skobkin
14.05.2015 16:45Для домашнего может быть удобнее и проще Proxmox VE.
shapa
14.05.2015 17:20+1Насчет «удобнее и проще» спорно, ибо UI там мягко говоря на любителя. Но в общем-то да, тоже вариант, особенно если только один хост.
Мы точно никого не принуждаем, это просто разного уровня технологии.skobkin
14.05.2015 18:42-1О том и речь. Я просто не совсем понял, зачем домой для нескольких виртуалок накатывать решение от Nutanix. Ничего против него не имею, но считаю оверкиллом. А PVE в данном случае — то, что настраивается за 10 минут и виртуалки там создаются и управляются в несколько кликов в вебморде.
shapa
14.05.2015 18:52Смею предположить, что CE делалось не для того чтобы пару виртуалок гонять? :D
Тут все просто — кто-то даже домой покупает «профессиональную» технику (например Miele), а кому-то Beko хватит в 5 раз дешевле.
Очевидно, что CE будут использовать инженеры / энтузиасты / разработчики / ВУЗы и прочие.
Мы где-то заявляли что мы сделали супер решение для домашнего использования? В чем суть ваших комментариев вообще?skobkin
14.05.2015 23:01Смею предположить, что CE делалось не для того чтобы пару виртуалок гонять? :D
Ну вот я из слов человека сделал, возможно поспешный, вывод, что у него там не особо огромный парк виртуалок.
Очевидно, что CE будут использовать инженеры / энтузиасты / разработчики / ВУЗы и прочие.
Очевидно. Я даже не знаю, что добавить. Наверное, то, что я нигде не говорил иного? Вообще не понимаю, зачем вы ответили на мой комментарий. Нет, про интерфейс Proxmox понимаю, а вот дальше — уже не особо.
Мы где-то заявляли что мы сделали супер решение для домашнего использования? В чем суть ваших комментариев вообще?
В том, что я отвечал изначально не вам, а человеку, который писал про домашний сервер, наверное?

Darka
14.05.2015 21:14+1Proxmox VE неплохо и на нескольких хостах работает с шаред стораджем.
shapa
14.05.2015 21:35Это прекрасно. А откуда «шаред стораж» возьмете? :) Ceph / GlusterFS? Тут только попутного ветра пожелать.
Я надеюсь вы поняли что ПО Nutanix делает этот самый shared storage, причем одно из лучших решений в мире?
skobkin
14.05.2015 23:06Ну так кто спорит, что как комплексное решение Nutanix рулит? Вот конкретно эта ветка о домашнем сервере.
У меня у самого такой на полке лежит. Там тоже виртуалки и Virt-manager. Туда я CE ставить не буду. А вот если где-то понадобится развернуть на паре-тройке серверов что-то отказоустойчивое — тогда буду смотреть, да.
Meklon
14.05.2015 21:25ProxMox жёстко завязан на свой дистрибутив Debian и обновляется ещё реже. А у меня этот сервер ещё и xbmc/kodi медиаплеер. Я вообще собираюсь на ubuntu LTS мигрировать.
skobkin
14.05.2015 23:09Не знаю, у меня на сервере Proxmox довольно часто обновления получает. Хотя, конечно, в сравнении с десктопом на Gentoo — очень редко :)
А Debian — да. Сама система редко что получает. С другой стороны, если стоит Proxmox VE — скорее всего, весь софт под виртуалками, где уже можно хоть Ubuntu хоть FreeBSD развернуть.Meklon
14.05.2015 23:17Да, но тогда на телевизор фиг изображение нормально вытащишь. А тут при старте kodi запускается без de, а виртуальные машины поднимают отдельные изолированные сервисы.

RaveNoX
15.05.2015 01:49Посмотрите в сторону OpenNebula прекрасно работает и в схеме с одним хостом. Просто ставится на основные дистрибутивы и имеет кучу фич.
shapa
15.05.2015 02:54Ну, рекомендовать ставить ISasS решение для дома — это еще из большей пушки стрелять чем Nutanix CE :))
Можно еще OpenStack порекомендовать поднять или vCloud ;)RaveNoX
15.05.2015 03:08OpenStack и vCloud какраз я не рекомендую по той причине, что это монстры, которые для поддержания только своей работоспособности требуют немалых ресурсов. OpenNebula же лично у меня прекрасно работает дома, на «сервере», собранном из десктопного железа, который кроме этого является роутером, файл помойкой и торрент качалкой. При этом никакой ощутимой нагрузки она не создаёт ибо представляет из себя посути 2 c++ демона, набор bash/ruby скриптов и web на руби ( остальные компоненты ставятся по желанию ), в отличие от того же OpenStack, состоящего из приличного количества компонентов, в Небуле даже бд по-умолчанию SQLite. Но при этом она даёт возможность комфортного управления виртуалками и всем, что с ними связано, за исключением бэкапов, которые делаются методом snapshot + rsync.

SemperFi
13.05.2015 18:33это хорошо, когда строишь что то с нуля.
а если есть унаследованная архитектура, которая стоит немало, у меня, например, фулл-флеш NetApp — как к ним можно прикрутить NX?
или не стоит пробовать так делать, а просто использовать NX для виртуальных сред, а на фулл-флеш массив положить СУБД, и подключить физ. сервера?
можете что то посоветовать?shapa
13.05.2015 18:44Никто не мешает подключить NetApp как внешнюю хранилку — iSCSI,NFS, SMB и тд — например напрямую в виртуальные машины которым это нужно.
Многие клиенты наши так делают для защиты инвестиций (ну не выкидывать же старое оборудование?)
СУБД, даже большие, прекрасно работают на Нутаниксе.SemperFi
13.05.2015 18:51ммм, а что нить типа бэст практис или референсной архитектуры, в картинках, есть для ознакомления?
гуглил, посмотрел по сайту — не нашел, в основном описание различных решений для VDI.shapa
13.05.2015 19:00Я думаю просто не заметили :)
У нас есть BP почти на любую задачу — включая Oracle, MS SQL и тд
Все открыто лежит на сайте.
www.nutanix.com/solutions/enterprise-applications/oracle-db
«Oracle Databases on Nutanix
Best Practices Guide»
www.nutanix.com/solutions/enterprise-applications/sql-server
«Virtualizing Microsoft SQL Server on Nutanix
Best Practices Guide»
И тд.
Даже Cisco UCS, Avaya, MS Exchange на 1.3 миллиона ящиков. Скоро на сотни уже пойдет счет «лучших практик».SemperFi
13.05.2015 19:23спасибо
то есть я правильно понимаю, что ВМ на нодах NX можно отдать дополнительно какой то шустрый объем с быстрого standalone массива? а подключать как как лучше? FC HBA, я так понимаю, нет в нодах? соответственно, блочной хранилке нужен файловый контроллер? подключение 10 GbE, а протоколы? NFS?shapa
13.05.2015 19:34Ноды у нас есть разные, есть такие в которые можно воткнуть FC карты (мы это официально не поддерживаем но и не сопротивляемся).
Но конечно NAS3/4 лучше и проще всего, тем более что почти все СХД вендоры умеют это (NFS / iSCSI)
Во многих проектах делаем как раз решения когда нужны ультра-большие объемы СХД (на десятки петабайт), например в РФ / СНГ часто ставятся сторонние NAS (такие как ArgoTech, сделанный на базе бывшего Coraid)shapa
13.05.2015 20:20Пардон, NFS 3/4 :)
SemperFi
14.05.2015 11:56почитал, получается, что создать гибрид в целом можно — тут поставим не-х86 сервера с СХД, и там крутим СУБД (Oracle+SPARC), а здесь на NX крутим виртуальные машины.
в процессе размышлений возник вопрос — а как бэкапить?
я понимаю, что DR типа встроен, но в силу определенных документов мне нужно записывать на ленту. вопрос, собственно в чем? я понимаю, что я могу понаставить агентов в ВМ, и их бэкапить, а к NOS есть какие то агенты, которые нативно могут работать с Симантеком или там Акронисом? этого на сайте не нашел, заранее прошу прощения, если оно там есть, тогда просьба направить по правильному пути =)shapa
14.05.2015 12:00Насчет бэкапа я чуть ниже отвечал.
Суть такая — что сейчас будут очень крупные анонсы по интеграции больших «бэкапных» вендоров с Nutanix (нативными снапшотами).
Подождите .next, это уже совсем скоро :)
Прямо сейчас — любым способом (NFS / SCP / Rsync) выгружать снапшоты наружу (они доступны в виде обычных файлов) и заливать на ленту. Можно настроить даже Bacula или Amanda это делать (если нравится идея открытых технологий).
И да, любое решение с агентами будет работать без проблем.
SemperFi
14.05.2015 12:19а снэпшот в виде какого файла? какой то внутренний для NOS или можно обычный vmdk записывать?
shapa
14.05.2015 13:20Ну это raw формат де-факто — так что да, можно восстановить VM из него (причем не только на Nutanix).
Агалогично flat VMDK
SemperFi
20.05.2015 17:20+1прошу прощения, не могу найти момент — видел ссылку на сайт HP, с описанием, по какой неустранимой причине не возможно использовать сервера HP под NX.
гуглил, перекопал комментарии на хабре, посты, блог =(
нет случайно под рукой, я сохранил бы себе.
SemperFi
20.05.2015 17:25нашел =)
еще раз извиняюсь.
h20565.www2.hp.com/hpsc/doc/public/display?ac.admitted=1415791140275.876444892.492883150&docId=c03835455shapa
20.05.2015 17:33Да. На всех железках HP (G6, G7, G8 — как минимум) жестко сломан механизм проброса PCI. Это аппаратная проблема судя по всему. Воркэраунд в 5.5u4 сделан, но это именно что затыкание дырок паклей.
G9 возможно (?) починили.
Кстати, CE редакция будет на HP работать без проблем, она не использует проброс PCI но маппит диски (поэтому конечно производительность ниже будет, хотя и остается очень высокой). Сделано это как раз потому что очень много серверов / вендоров у которых эта функциональность не работает корректно.

ranzhe
13.05.2015 18:55+11, 3 или 4 (внимание! 2 сервера — не поддерживается) сервера (или «нода») с 4 ядрами и поддержкой Intel VT-x
4 физических сервера — это максимум? Будет ли поддержка большего количества нод?shapa
13.05.2015 18:57Для CE — не думаю, мы все-же не благотворительная компания :) Хотя и максимально открыты.
Но на достаточно мощном «оборудовании» это уже означает что вы можете сотни виртуальных машин крутить, с производительностью распределенной дисковой системы более 70 тысяч IOPS.
Стандартная-же версия Nutanix вообще не имеет ограничений на размер кластера.
n1nj4p0w3r
14.05.2015 16:03В случае если организация вырастет и упрется в эти четыре несчастные ноды на супермикрах, как им быть дальше?
Могут ли ноды CE стать частью кластера «настоящего» нутаникса?shapa
14.05.2015 16:07«несчастные 4 ноды» — это сотни виртуальных машин на современном железе (для VDI например — до 700 рабочих мест мы на Haswell новых платформах получали).
Кто вышел на такие объемы — явно пора будет подумать о коммерческий версии.
Мы не предусматриваем использование совместно в кластере CE и стандартных редакций, это принципиальный момент, ввиду того что невозможно поддерживать только часть кластера — это работает как единое целое.
Эксплуатировать два разных кластера — никто не запретит.n1nj4p0w3r
14.05.2015 16:28+1Тогда другой вопрос, насколько проблематично переехать с CE на чистокровную платформу?
Ну и не забывайте, что не у всех есть деньги на топовый hasswell до отказа забитый озу, вопрос как раз к тому, насколько «среднему» бизнесу будет разумно садиться на CEshapa
14.05.2015 16:40Ivy Bridge — спокойно 300-400 VDI крутится
Переезд на «взрослую» версию очень просто — простым копированием VM. ОЗУ забивать не надо, для начала 128G на нод более чем хватит. DDR3 нынче очень недорогая.
Я уверен что кто-то из коммьюнити сделает скрипт для этого, это в общем-то максимум несколько часов работы.

celebrate
13.05.2015 20:32Скажите, данная платформа имеет какое-либо отношение к вашей NDFS?
shapa
13.05.2015 20:35Данная «платформа» полностью базируется на NDFS, мало того это ровно такая-же версия ПО как и (например) используется в критически-важных инфраструктурах заказчиков. Не изменено ни байта.
Фактически, мы бесплатно раздаем ПО которое стоит сотни тысяч долларов, причем на каждый блок.shapa
13.05.2015 20:43+2Если спросите «где подвох» — то его нет.
Ограничения:
1) До 4-х нодов максимум
2) Только KVM
3) Техподдержка — только общественная, коммерческая недоступна.
Прекрасно подходит для энтузиастов, университетов, небольших компаний и тд.
Серьезные бизнесы / применения — коммерческий Nutanix.Meklon
13.05.2015 20:45+1Звучит крайне вкусно, да. Давно хотелось поиграться с чем-то сурово-энтерпрайзным в своих целях. У меня в основном пачка виртуальных машин для насилия над ними и экспериментов, плюс сервисы. Но все равно очень жду, когда можно будет попробовать. Прям обидно, что анонс прошел, а потрогать пока нельзя. Ну и может в рамках нашей лаборатории разверну.
shapa
13.05.2015 20:50«сурово-энтерпрайзным» — отличный термин, запомним :)
Как раз про нас.
Да, функционал CE редакции — уровня (или превосходит) HighEnd решений других вендоров, причем зачастую за миллионы долларов (например — подсчитайте просто хотя-бы сколько стоит 4-х контроллерная Hybrid-Flash или AllFlash СХД)
Насчет «пощупать» — вот-вот будет, просто шквал регистраций (десятки или уже сотни тысяч запросов, буквально), коллеги активно обрабатывают.Meklon
13.05.2015 21:22Спасибо. Хорошо бы фильтр по почтовым ещё снять. У меня есть домен, но поднимать ради регистрации почтовый сервер не хочется. Тем более принимает 10minuteMail, что в корне ломает концепцию фильтра, если уж компания нацелилась на сбор корпоративных ящиков.
shapa
13.05.2015 22:27Снимут, снимут. Сейчас это просто некий фильтр чтобы совсем уж не засыпаться :)


dyasny
13.05.2015 22:37+1Интересная штука, были бы у вас удаленки или офис в Монреале, я бы CV забросил на какую нибудь техническую позицию, или на PM/TPM
shapa
13.05.2015 22:41У нас народ по всему миру раскидан, разработчики есть даже в Европе. Так что закидывать точно никто не мешает, набор практически постоянный (за год AFAIR тысячу человек наняли).
dyasny
13.05.2015 22:50Ну, на сайте я особо ничего не нашел, особенно насчет (T)PM. A вообще тема классная, как раз то что я люблю — между KVM и продвинутым стореджем. Сейчас приходится заниматся опенстаком, и эта гадость меня не особо радует, энтерпрайзный софт намного интереснее. Если есть конкретные идеи или контакты, я заинтересован. Да и вам наверное бонус обломится.
Профиль тут: ca.linkedin.com/in/dyasny
… все, больше тут не пишу :)shapa
13.05.2015 23:20Бонус мне точно «не обломится» — у нас нет программы мотивации за поиск, ибо сами обычно засыпают компанию резюме.
Вакансии тут обычно регулярно:
www.nutanix.com/company/current-openings
navion
13.05.2015 22:58Кстати, а с него можно делать бекапы?
Для AIX, RHEL и Solaris у меня есть TSM, но он не умеет KVM и Nutanix.shapa
13.05.2015 23:18Можно конечно.
Нативные NDFS снапшоты (у нас они вообще не влияют на производительность), просто по NFS / SCP / rsync вытаскиваете куда угодно и чем угодно (любое решение которое поддерживает NFS / scp например).
Интеграция со стороны вендоров бэкап-решений крупных — опять-же, подождите .next. Будет много анонсов.
ncuxez
14.05.2015 02:50+1В статье написано «с 4 ядрами», а на сайте «4 cores minimum». Не могли бы вы уточнить, десктопные процессоры с 6+ ядрами эта редакция поддерживает? Или только <=4 ядер?
shapa
14.05.2015 10:51В статье минимальные требования.
Минимум 4 ядра, а так можете использовать например 12-ядерные процессоры два сокета (24 ядра на хост).

trueadmin
14.05.2015 11:03«минимум один SSD диск» — это обязательное требование, без SSD не поставится?
shapa
14.05.2015 11:15Нутаникс изначально рассчитан на работу с flash / SSD (с момента создания в 2009 году).
Без SSD — не имеет смысла.
Безусловно, можно «обмануть» инсталлятор (подправить детект оборудования), но смысла реально в этом очень мало — разве что посмотреть на UI.
trueadmin
14.05.2015 11:19Почему же только на UI? На миграцию, отказоустойчивость и т.д.
shapa
14.05.2015 11:22Это будет чрезвычайно плохо все работать, IOPS обычного SATA диска — в районе 100, SSD диска — в районе десятков тысяч. Мы храним метаданные ФС / конфигурацию VM / прочее в NoSQL базе которая лежит на SSD, плюс oplog (некий аналог журнала файловой системы) там-же.
Учитывая стоимость SSD дисков сегодня (200G за 70$ можно купить), смысла реально практически нет.trueadmin
14.05.2015 12:19Вот, что значит «сурово-энтерпрайзный» подход. Просто купите 3 SSD диска. Шучу)
По существу: «чрезвычайно плохо» — просто будет тормозить или реально не сможет работать? Мне не нужны десятки тысяч IOPS чтобы покрутить одну-две виртуалки.shapa
14.05.2015 12:36Работать формально будет, мало того теоритически это даже можно все поднять под гипервизором другим (который умеет пробрасывать VT-x в VM — например ESXi с 9+ версией VM)

gotch
14.05.2015 11:26Подскажите пожалуйста, где можно ознакомиться с лицензионным соглашение? Какие остались ключевые ограничения на использование — по виду деятельности организации, объему хранения?
shapa
14.05.2015 11:34Мы не ограничиваем объем (формально — можете воткнуть 8TB диски например 5 штук в каждый сервер и SSD на 1.6TB — получите Nutanix на 100+ терабайт RAW)
По виду организации тоже не ограничиваем, но безусловно традиционные запреты (нельзя использовать для создания оружия массового поражения и тд)
При инсталляции есть EULA, там все детально описаноskobkin
14.05.2015 16:56+2нельзя использовать для создания оружия массового поражения
Чёрт, а так хотелось…
navion
15.05.2015 16:05Приглашения хоть кому-нибудь уже пришли?
ncuxez
26.05.2015 23:42нет, в почте тишина.
Meklon
26.05.2015 23:46До сих пор? ( обидно. Ждём…
navion
27.05.2015 14:19Похоже, маркетинг просто собилар контакты:
forum.ixbt.com/topic.cgi?id=66:11064-4#154
shapa
27.05.2015 15:11+18 июня числа стартует раздача массовая, ввиду решения сделать глобальный / красивый анонс на нашей конференции в Майями.
Так что осталось недолго.

owniumo
10.06.2015 12:10Пришло такое письмо 9-го июня:
SUBJ:Hello from Nutanix!
FROM: Nutanix <success@nutanix.com>
Hello from Nutanix!
We make IT uncompromisingly simple so you can focus on running your business.
blah-blah,
Let’s keep in touch! Follow us on Twitter or check out some of the resources below.
(твиттер, лерн моар, blah)
Take 15 minutes with one of our solution consultants and learn how you can optimize your datacenter with hyper-converged infrastructure.
1-(855)-NUTANIX
sales@nutanix.com
Никакого приглашения, видать на этом этапе email валидировали и отпечаток мэйлсервера брали.navion
11.06.2015 12:51Нас развёл маркетинг, сегодня появилась интересная новость про них — оказывается нельзя публиковать результаты бенчмарков без разрешения Nutanix, которого они не дают:
www.vmgu.ru/news/vmware-virtual-san-vs-nutanix
ximik13
11.06.2015 13:06На самом деле похоже, что это стандартные формулировки для EULA почти у любого вендора. Но все равно забавно.
navion
11.06.2015 13:23Это их не украшает, Microsoft не запрещает публиковать независимые тесты, но там и маркетинг не такой упоротый.
shapa
11.06.2015 16:04Майкрософт не запрещает? :)) Да вы что?
Поищите фразу (и ее аналоги) «That you may not disclose to anyone, without our prior written permission, the results of any performance tests on the Software.»navion
11.06.2015 16:13Не нашел запретов, в EULA есть только условия тестирования .NET Framework. Вполне адекватные, между прочим.
shapa
11.06.2015 14:12Это называется «слышал звон, да не знает где он» :)
История простая.
VMware начала _у себя_ в лаборатории делать какие-то там тесты. Очевидно что публиковать они будут только тесты выгодные им, причем без подгонки конечно-же не обойдется — уж больно нервные они (тем более что мы уже всему миру показали апгрейд с ESXi на Acropolis KVM нажатием одной кнопки, буквально — автоматически конвертируем виртуальные машины, инсталлируем драйвера и тд)
Мы предложили сделать тесты в независимой (и от нас, и от vmware) лаборатории, но VMware — отказались (!!!).
После этого не оставалось ничего, кроме как внести стандартное для индустрии ограничение в EULA.
Это кстати не означает полного запрета, но означает что надо обратиться к нам за авторизацией.
ximik13
27.05.2015 13:37+2Написал вопросы для пользователя shapa тут, что бы не замусоривать ими статью про другого вендора.
Список вопросов:
1. Какой размер дисковой емкости получает пользователь под свои данные (виртуалки)? SSD? SATA? Например в полностью набитом одном боксе на 4 сервера.
2. Какие CPU используются в серверах? Самые мощные? Самые слабые? Или они во всех моделях одинаковые?
3. Как построена архитектура NDFS? Одна виртуальная машина работающая на конкретном сервере физически может быть «размазана» по дисковой емкости нескольких серверов кластера (размер блока которым при этом оперирует FS?) или данные будут стремится находиться на том же физическом сервере, где запущена VM?
4. Если мы говорим о двухкратном дублировании данных, то вторая копия данных этой виртуалки будет так же «размазываться» по дискам нескольких серверов?
5. Если есть возможность, то можно ли привести хотя бы схематично алгоритм или принцип распределения данных по физическим серверам?
6. Для тестовых или не очень важных виртуалок есть возможность отключать дублирование данных в пределах кластера для экономии дискового пространства?
7. Для миграции данных с медленных дисков на быстрые и обратно каким блоком (по размеру) оперирует NDFS? Ну и соответственно на блок какого размера собирается статистика производительности?
8. Миграция данных между SSD и SATA осуществляется по расписанию или постоянно в фоне?
9. Какие типы SSD дисков используются?
10. Где-то в метаданных CRC считается? Или какие есть механизмы для защиты от сбойных блоков на физических дисках?
11. Где и по какому принципу хранятся метаданные в NDFS?
12. Требуется ли отдельная настройка 1G/10G коммутаторов для соединения боксов Nutanix? VLAN-ы, транки, QoS, Jambo Frame и etc.? Особенно в том разрезе: должен ли человек, разворачивающий или администрирующий кластер, обладать достаточными знаниями в сетевых технологиях, а не только в виртуализации?
13. Срок гарантийной поддержки, который идет с новой системой «по умолчанию»?
14. Стоимость продления поддержки на один год после окончания первоначальной поддержки? Например на один полный бокс на 4 сервера?
15. Есть ли описания условий этой поддержки/гарантии для заказчика на русском? Или по другому, что заказчик получает/приобретает, покупая поддержку?
16. В случае возникновения неисправности куда заказчик обращается в первую очередь и какие данные обязан предоставить?
17. Есть ли механизмы и какие для автоматизации заведения кейсов у вендора в случае неисправности оборудования или проблем с софтом? Если да, то как будут обрабатываться подобные кейсы? Кто будет помогать заказчику на месте в случае такой необходимости или запросе из Глобал Сапппорта вендора?
18. Какой срок жизни предполагается для одного семейства продуктов до полного окончания поддержки и невозможности ее продления?
19. Миграция на новое поколения будет прозрачной без остановки сервисов?
20. Какой цикл обновления железной платформы предполагается в годах? Н-р: раз в три года, раз в пять лет.
21. Какие запчасти меняются в Nutanix при выходе из строя? Все ли запчасти меняются на горячую?
22. Где можно найти описание сервисных процедур для замены запчастей?
23. Какие запчасти заказчик может менять самостоятельно?
24. Если для замены запчасти потребуется выезд инженера, то кто поедет и за чей счет? Например в Екатеринбург?
25. Где находятся сервисные склады с запчастями для Nutanix?
26. Какова процедура заказа запчасти? Кто принимает решение о необходимости замены? Кто инициирует и отслеживает сам процесс доставки и замены запчасти?
27. Каков средний срок доставки запчасти до заказчика например в Екатеринбург? За чей счет будет доставляться запчасть?
28. Если необходимо неисправную запчасть возвращать производителю, то за чей счет это будет производиться?
29. Каким образом изолируется служебный трафик между контроллерными VM Nutanix, между контроллерными VM и гипервизором?
30. Требуется ли ручная настройка маршрутизации между контроллерными VM?
31. Какое количество и каких железных компонентов должно выйти из строя в кластере, что бы привести к недоступности данных? К потере данных?
32. Сжатие данных включается на каком уровне? На конкретном физическом сервере? На конкретной VM? На весь кластер сразу?
33. Какой процент производительности теряется, если теряется при работе со сжатыми данными?
34. Репликация виртуалок между датацентрами может выполняться в синхронном режиме? Если да, то какие критерии по предельному расстоянию между ДЦ и времени задержки на канале, минимальная ширина канала?
35. Есть ли разумные ограничения по характеристикам канала между ДЦ для репликации в асинхронном режиме?
36. Какова минимальная (по времени н-р: 5 сек. или 5 мин.) гранулярность снапшотов VM при репликации между ДЦ.
37. Что имеется в виду при репликации между ДЦ под «Защита данных» => Восстановление приложений? Например если у меня MS SQL внутри виртуалки упадет, то он будет «поднят» в другом ДЦ автоматически? Для этого требуется установка агентов Nutanix в виртуалку? Или имелось в виду что то совершенно иное?
38. Для Disaster recovery используется софт и функционал, предоставляемый производителями гипервизоров? Или у Nutanix есть свои инструменты для этого?
39. Ну и почти риторический вопрос. Nutanix не подойдет, как я понимаю, для сервисов, выходящих по производительности за пределы одного сервера Nutanix?shapa
27.05.2015 15:10Ух :)
Столько вопросов и все по делу. Очень интересно.
1) Сколько дадите, столько и будет. Размер виртуального диска не ограничен локальными ресурсами, и SSD и SATA уровни могут работать по сети. У нас есть так называемые capacity nodes (60TB RAW на 2U), которые вообще не предназначены для запуска пользовательских VM.
2) На сайте есть спецификации.
www.nutanix.com/products/hardware-platforms
Если коротко — у нас уже configure to order конфигурации, и процессоры есть практически любые из ходовых, включая Haswell.
3) VM не только может, но обязана быть «размазана» по дискам кластера. Локализация I/O делается для hot уровня (ssd), задержки (latency) sata выше чем сеть поэтому локализовывать смысла нет.
4) Да, всегда размазывается по серверам. RAIN архитектура.
5) Это показано очень детально в библии Nutanix ( www.nutanix.ru ), логически распределение идет по кольцу кассандры
6) RF1 ранее был неофициально, сейчас отказались — клиенты начинают использовать, не понимая что отказ любого диска / нода означает потерю данных. Минимальный RF сейчас 2.
7) Экстент группа — 4 мегабайта, при включенной дедупликации — 1 мегабайт.
8) Постоянно
9) Intel EMLC (S3700 и другие)
10) Конечно считаются.
11) В значительно доработанной NoSQL БД Cassandra, 3 или 5 копий в зависимости от RF
12) Нет, не требуется — будет работать даже в access режиме. Очевидно, для разделения гостевого и служебного трафика рекомендуется использовать VLAN
13) При покупке оборудования приобретается техподдержка (по принципу «все включено») минимум на год
14) Зависит от многих факторов, если очень утрированно — 10% от стоимости решения в год
15) На русском есть, но так как сайт еще не локализован — можно выслать на емейл. Условия во всем мире идентичны.
16) Обращается в нашу техподдержку напрямую. Данные — требуется или включить удаленный туннель или предоставить результаты диагностики (по email).
17) Да, у нас есть служба Nutanix Pulse — полностью автоматический мониторинг систем и проактивная реакция.
18) Мы гарантируем срок жизни платформы 5 лет, в течении которых на конкретном оборудовании будет работать все новое ПО
19) Да, миграция прозрачная, но есть нюансы которые от нас не зависят — например EVC режим ESXi — если нужна live миграция на новое железо, на нем надо понижать уровень EVC до совместимого со старым.
20) В среднем раз в два года выходят новые платформы, но последнее время мы разогнались.
21) Диски / БП / ноды — горячая замена. Логически, если от 3-х блоков оборудования в кластере, даже замена блока целиком (со всеми нодами) не ведет к остановке сервиса (у нас есть Block Awareness)
22) Все доступно в документации официальной (клиентам и партнерам)
23) Диски / БП / ноды. Все что внутри ноды (сервера) мы обычно меняем сами, но в сущности зависит от типа операции — например поменять модули памяти очень просто, а процессоры или SATA-DOM уже выше квалификация.
24) Это входит в поддержку / наша головная боль.
25) Для РФ — Мск / Питер / Екатеринбург
26) Решение принимает наша техподдержка
27) NBD (Next Business Day)
28) Возврат за наш счет
29) VLAN
30) Нет, они обязаны быть в пределах одной L2 сети (рутинг в данном случае будет узким местом, трафики десятки гигабит)
31) Для RF3 + BA может выйти из строя или любых 2 компонента кластера (диски / ноды / и тд) или целиком один блок (4 нода например для 1000/3000) + еще один компонент (если RF3).
32) На уровне виртуального датастора (контейнера). Технически можно и per VM.
33) Для отложенного сжатия — потерь нет, с точностью до наоборот — производительность только растет (меньше физических данных поднимать с дисков).
Для inline — зависит от типа нагрузки, во многих случаях (тяжелые БД) производительность тоже растет (виртуально больше флеша становится)
34) Per VM — пока нет, но ждите новостей. Metro Cluster / Репликация датасторов (контейнеров) — да, до 5 миллисекунд между кластерами реплицируемыми. Минимальная ширина канала не лимитируется, зависит от количества реплицируемых данных и может отличаться на порядок.
35) Асинхронная репликация крайне нетребовательна, есть клиенты которые реплицируют данные на 4000км
36) Официально — один час, возможно 15 минут для ряда нагрузок (VDI например). Скоро будет 15 минут для любых типов нагрузок.
37) Да, будет поднята виртуалка автоматически, причем если это был MS SQL и ESXi / HyperV — то снапшоты консистентные (мы поддерживаем VSS).
Для KVM идет работа (там сложнее консистентные делать).
38) У нас полностью своя имплементация DR, тобишь будет работать на базовой версии (например ESXi standard) ПО. Большинство клиентов считает наш DR одним из наиболее эффективных / быстрых / удобных решений на рынке.
39) Если подразумевается память / CPU — да, больше чем есть в физическом сервере не получить ввиду особенностей X86.
Если I/O + дисковое место — то оно горизонтально масштабируемое.
shapa
27.05.2015 15:31«5. Если есть возможность, то можно ли привести хотя бы схематично алгоритм или принцип распределения данных по физическим серверам? „
nutanix.ru/#12

navion
28.05.2015 19:29Офигеть, в вашем CE нет вообще никакого HA?
shapa
28.05.2015 22:38Это откуда у вас такие бурные фантазии? :D
RF2 — от 3-х нодов. Отказ одного сервера со всеми дисками — без проблем.
Если про HA на уровне гипервизора — оно тоже есть.navion
28.05.2015 22:40В вашем вебкасте сегодня сказали, для виртуалок может быть потом «что-то прикрутят».
shapa
28.05.2015 22:42Это ошибка, HA уже сейчас можно включить. Оно в бете до 4.1.3, но вполне хорошо работает.
Кто и когда делал вебкаст? Это наш официальный?
Я скажу свое «фи» маркетологам.
nutanix@NTNX-15SZXXXD1-A-CVM:10.18.1.71:~$ acli
ha.setup_ha 1
SetupHA: complete
help
Namespaces:
core
dr
ha
host
net
snapshot
task
vm
Aliases:
quit
exit
help
help ha
Commands:
setup_ha
navion
28.05.2015 22:46Ваш, пару часов назад его провёл какой-то Адам и девочка из маркетинга.
shapa
28.05.2015 22:53При слове «маркетинг» глаз дергается ;)
Шутка, но всегда есть доля.
В общем не стоит волноваться, учитывая что мы наняли сотни людей только за последний месяц — еще не все в курсе всего.

nekufa
28.05.2015 21:04А если во все требования машинка укладывается, но диск ssd всего 125 гб?
Работать не будет никак или просто неудобно использовать будет?
Хочу дома попробовать завести, а там уже можно на работу тащить если понравится.
Покупать новый ссд большего размера как-то не хочется, если честно.shapa
28.05.2015 22:41+1Мы проверяем размер SSD.
К сожалению, все алгоритмы заточены под нормальный размер flash, а для CE версии мы используем (это принципиальный подход) «боевое» ПО.
nekufa
28.05.2015 23:17Спасибо, вкусная штука должна быть, конечно.
Пока ссылка не пришла, но как придёт пойду за новым ссд :)
shapa
09.06.2015 23:48-1Как и обещали, раздача началась.
Делитесь впечатлениями ;)Meklon
10.06.2015 10:50Возможность использовать e-mail от google появилась? Вообще лучше через неделю новый пост с обзором новый запилить.

phprus
10.06.2015 12:18> Делитесь впечатлениями ;)
Вчера пришло письмо с текстом:
Hello from Nutanix!
We make IT uncompromisingly simple so you can focus on running your business.
Our customers love us because our converged infrastructure allows enterprises to run any app at any scale with peak efficiency and lowest total cost of ownership.
Let’s keep in touch! Follow us on Twitter or check out some of the resources below.
…
Let’s talk!
Take 15 minutes with one of our solution consultants and learn how you can optimize your datacenter with hyper-converged infrastructure.
1-(855)-NUTANIX
sales@nutanix.com
и все. Ссылок на скачивание/регистрацию и приглашений в письме нет :((
email был указан на своем домене (без сайта) со своим почтовым сервером.
blind_oracle
О, как раз ScaleIO собрались бесплатно выкладывать, и вы тут как тут :) Респект и уважуха.
За Intel-only сетевухи незачёт, у меня, к примеру, много серверов Supermicro с 10G Broadcom :(
shapa
К сожалению, много проблем выплывает при высоких нагрузках — при всем уважении к этому вендору, мы вполне обоснованно пришли к такому решению.
В общем-то никто не мешает поставить сетевые карты дополнительно.
Про scaleio «бесплатный» ESXi — то бесплатно вам никто не выдаст. Да и функциональность как-бы «чуть-чуть» отличается.
А тенденция хорошая, да.
phprus
А с сетевыми картами Mellanox Вы не сталкивались?
shapa
Сталкивались, но пока большого смысла не видим. Хотя конечно индустрия активно идет на 25G ( 25gethernet.org )
Например Intel 520 или 540 работают очень хорошо и надежно.
navion
Там есть RDMA, который очень помогает при Hyper-V.
shapa
C одной стороны да, с другой — HyperV на нас очень хорошо работает и без дополнительных ухищрений.
Не зря Microsoft нас активно поддерживает и есть референсы для множества различных задач.
В сущности, проблем использовать другие адаптеры нет — если они стабильно и хорошо работают. Мелланокс, откровенно, в свое время было много проблем. Сейчас вполне возможно все сильно лучше.
navion
У вас оно всё равно не будет работать, так что невелика потеря.
shapa
Логично :)
ximik13
Простите, не уловил связи между бесплатным ScaleIO и ESXi. Можно с этого момента поподробнее?
shapa
Конечно.
Для получения гиперконвергентного решения требуется несколько ключевых компонентов:
Оборудование (сервера c дисками, памятью, процессорами, интерфейсами ввода-вывода)
Гипервизор, причем работающий в кластерном режиме (=> бесплатная версия ESXi «отметается» мгновенно)
Поверх этого SDS-решение (например ScaleIO или Nutanix NDFS, в CE варианте работающая поверх доработанного KVM)
SDN-решение (коммутатор сетевой встроенный в ESXi — в бесплатной крайне ограниченный, или в Nutanix KVM — распределенный коммутатор бесплатно)
Как итог, даже для «бесплатной» версии ПО от EMC (scaleio) потребуется коммерческая версия гипервизора (ESXi) от компании VMware, которая целиком принадлежит EMC (наиболее частый сценарий), или HyperV, или KVM.
К которым потребуется система управления кластером (которые имеют классические архитектурные проблемы — использование централизованных баз данных для хранения конфигураций кластера — VCenter, System Managemenet Center, RHEV, Proxmox (который хранит просто копии конфигов на каждом ноде), OpenStack и тд).
В нормальном режиме (в виде гостевой машины, аналогично Nutanix) ScaleIO сделан только для ESXi, для остальных случаев идет интеграция на уровень ядра гипервизора, что крайне опасный и кривой подход.
Итого серьезно можно рассматривать ScaleIO только поверх ESXi, что совершенно логично с точки зрения бизнеса EMC.
KVM Managagement Tool (Acroplis) от Nutanix не имеет этих проблем фундаментально, ввиду использования NoSQL БД (безлимитно масштабируемой) для хранения конфигурации VM в кластере. Насколько я в курсе, пока что это единственное решение подобного рода на рынке.
Учитывая что KVM от Nutanix имеет встроенный асинхронный DR (многие им заменяют SRM), распределенный коммутатор (с поддержкой LACP) и множество другого функционала — клиенты начинают сравнивать (мы запретить не можем ;)) стоимость ESXi в Enterprise Plus редакции + SRM (около 15-20$k на каждый сервер?) и 100% бесплатный Nutanix CE.
Сухой итог: даже если будет в «подарок» ScaleIO, ситуации это никоим образом не меняет, ввиду того что требуется иметь кластер гипервизоров и управлять оным.
navion
Неужели нет других гипервизоров? Для Hyper-V ничего докупать не нужно, а консоли Hyper-V Manager и Failover Clustering работают без зависимостей.
Там основное различие в автоматическом копировании конфигурации, остальное мелочь и не влияет на работу.
Уже нет и это хорошо. Проксирование дисков в ВМ — страшный костыль для экономии на разработке.
С бесплатным CE на 4 ноды? В небольших внедрениях важнее экосистема, которой нет у Nutanix.
shapa
«Для Hyper-V ничего докупать не нужно, а консоли Hyper-V Manager и Failover Clustering работают без зависимостей.»
Проблемы Scaleio + hyperV я описал.
1) ScaleIO не сделана в виде VM для HyperV, но интегрируется на уровень гипервизора. Очень опасный / кривой подход.
«ScalelO supports two methods of deployment for VSI. Both methods result in a fully functional ScalelO solution. For non-VMware environments including Citrix XenServer,
Linux KVM, and Microsoft Hyper-V, ScalelO is deployed as a hypervisor component. „
2) HyperV, при том что очень неплохой гипервизор, несет за собой legacy в виде централизованных систем управления облаком — использование SQL серверов (со всеми вытекающими).
“Уже нет и это хорошо.» — тобишь уже и для ESXi на уровень гипервизора интеграция? Понятно, через VM работать нормально так и не научили.
Ничему не учатся многие компании. Fault Domain Isolation видимо слово крайне незнакомое разработчикам ScaleIO.
Cбой кода ФС -> сбой гипервизора. Апргейд гипервизора (массовые изменения) — вероятность отказа ФС.
Недаром для EVO:RAIL до сих пор старый VSAN (5-й) поставляют, VSAN6 будет доступен только к осени (наверное).
" Проксирование дисков в ВМ — страшный костыль" — для ScaleIO видимо да, Nutanix же работает намного умнее (KVM и ESXi) — пробрасывается в виртуальный контроллер PCI адаптер и работа с дисками идет на нативной скорости. Для HyperV, который пока не умеет PCI pass-through, работает прямой маппинг дисков. Тоже отлично по производительности.
3) «Там основное различие в автоматическом копировании конфигурации,»
Так-же как отсутствие LACP. Ну и да, в 2015 году ручками / скриптами наколенными копировать конфиги — как-то уже некомильфо.
Если так хочется «ручками» — то тогда уж KVM + Ceph.
4) Почему же только с бесплатным?
Подсчитайте кластер на коммерческой версии Nutanix, тоже практически всегда значительно выгоднее.
Про экономику решений есть множество публикаций в интернете, включая мы выкладывали здесь.
ximik13
Очень много текста :). И итог очень уж сухой.
ScaleIO, насколько понимаю, позиционируется в первую очередь как SDS (Software-defined storage). О чем вы собственно написали сами. Т.е. не как гиперконвергентное решение, а как возможная часть такого решения. Так давайте рассматривать его именно в этом ракурсе :). Отсюда, как использовать ScaleIO в своей среде решает пользователь. Вы описали только один возможный сценарий, а он далеко не единственный. Cудя по описанию на сайте вендора, ScaleIO может работать и не в среде виртуализации. Кроме того поддерживает смешанные кластеры хранения, когда данные распараллеливаются по различным OS (Microsoft Windows, RedHat Enterprise Linux, CentOS, SUSE) и/или гипервизорам (VMware vSphere, Citrix XenServer, Microsoft Hyper-V, Linux KVM) в пределах одного кластера. Опять же есть гибкость в том, что ноды можно разделить по ролям: Server — отдает часть локальной емкости под хранение данных и Client — использует дисковые емкости серверов. Или можно использовать одни и те же ноды и как сервер, и как клиент. Минимальные требования к серверу, для включения его в кластер ScaleIO, по нашим временам достаточно скромные: 2CPU, 1.5 Gb RAM, 100GB дискового пространства.
Никаких специальных ограничений на «бесплатный» ScaleIO EMC так и не озвучила. Т.е. будет доступен бесплатно с 29 мая 2015г. полный функционал решения. А за деньги только тех.поддержка от производителя, если она вам нужна.
Есть и недостатки. Насколько знаю, первична для управления ScaleIO CLI. А GUI только визуализирует конфигурацию кластера и обладает далеко не полным функционалом для управления этим кластером. Возможно (и даже скорее всего) в будущем это изменится. Но я думаю что для «начинающих» такое положение дел пока будет скорее отталкивающим фактором.
P.s. У всех решений и продуктов есть как минусы, так и плюсы. Все зависит от конкретной ситуации и конкретных задач. По этому у меня всегда вызывает улыбку попытка выставить на показ только «плохие» черты конкурентов и только «хорошие» собственные. Ну не живем мы в черно-белом мире в конце-то концов! :)
P.s. P.s. EMC вроде как не владеет VMware целиком (на 100%), по всем последним и не очень новостям звучит цифра 80% :). Кроме того, VMware так и не стала «частью» EMC, как многие другие удачные приобретения. Т.е. VMware живет и развивается достаточно самостоятельно :).
shapa
«ScaleIO, насколько понимаю, позиционируется в первую очередь как SDS (Software-defined storage). О чем вы собственно написали сами. „
Само по себе SDS сейчас мало кому нужно. Требуется решать бизнес-задачи, тобишь полный стек.
Ну и само EMC не согласно с вами :)
twitter.com/emcscaleio/status/565139122193698816
“All roads lead to hyperconvergence»
«Кроме того поддерживает смешанные кластеры хранения, когда данные распараллеливаются по различным OS » — Nutanix поддерживает это, мало того — новые Capacity ноды идут под KVM-only, но могут расширять место например на кластерах ESXi.
…
«Т.е. VMware живет и развивается достаточно самостоятельно :).» и сидят в одном офисе (на беговой) в Мск например :) Причем не в одном здании, а именно что едином офисе.
ximik13
При таком раскладе и Nutanix, и все гипервизоры, и все что окружает эти решения — это плод тупиковой ветви развития эволюции. Нужно сразу заниматься виртуализацией приложений, к чему все эти прослойки в виде эмуляции виртуального железа? :)
. ScaleIO — может быть частью гиперконвергентного решения, как SDS. В чем противоречие?
— Я не пытался сравнивать Nutanix и ScaleIO. Но если так уж хочется, то Nutanix поддерживает только популярные гипервизоры тчк. Про остальные OS даже речи нет. Что логично с той точки зрения, как позиционируется Nutanix. Но не всегда логично точки зрения конечного заказчика.
— распространенное мнение :). Но вроде как не в одном офисе, а на одном этаже. В Екб офис EMC на одном этаже с Microsoft, насколько знаю. Давайте тоже делать выводы :).
shapa
«Если смотреть в таком разрезе, то и у Nutanix стек не полный. „
Интересное мнение. “как минимум потребуется приобретение коммерческих OS или поддержки на них.» — это не так, берите Centos например. Который фактически полный клон RHEL. Бесплатно, и все свежие апдейты.
«ScaleIO — может быть частью гиперконвергентного решения, как SDS. В чем противоречие?»
Никаких противоречий, все укладывается в бизнес-логику EMC. ScaleIO сделано с ориентацией на HyperConvergent. Так как EMC этот рынок активно «проморгала», сейчас пытаются вскочить на поезд. Тем интереснее видится будущее.
Проблема ScaleIO SDS — оно начинает конфликтовать как с «аппаратными» решениями EMC, так еще и в пределах «холдинга» EMC и VMware — scaleio vs VSAN.
Правая рука борется с левой :)
«Но не всегда логично точки зрения конечного заказчика.»
Согласен, поддерживаются основные гипервизоры. Поверх гипервизора крутите хоть QNX, хоть MSDOS. Технически, ввиду того что Нутаникс сделан в виде VM, работать может практически на любом гипервизоре, но коммерческого спроса нет.
В целом-же — «платиновой пули» (одно решение для любого типа задач) не бывает. Nutanix может быть для части задач (например Bare Metal конфигурации) неприменим.
"— распространенное мнение :)." — я там бывал, и неоднократно. Там даже ресепшен в офисе единая.
shapa
Кстати, забавный момент.
«CentOS (abbreviated from Community Enterprise Operating System) is a Linux distribution that attempts to provide a free, enterprise-class, community-supported computing platform which aims to be functionally compatible with its upstream source, Red Hat Enterprise Linux (RHEL).[5][6] In January 2014, CentOS announced the official joining with Red Hat while staying independent from RHEL,[7] under a new CentOS governing board.[8]
»