
В мае этого кода Mozilla обновила свой сервис Test Pilot Program. Этот сервис, по мнению разработчиков браузера Firefox, помогает «обкатывать» новые возможности браузера. Любой пользователь, который желает опробовать эти функции, может это сделать, присоединившись к команде «первопроходцев» на соответствующей страничке. Включить или отключить любую тестовую функцию можно в любое время.
Представители компании предупреждают, что новинки, представленные на странице Test Pilot, могут работать не идеально. Но для этого и нужна «обкатка» — компании нужно узнать о проблеме заранее, чтобы ликвидировать ее в финальном релизе. Сейчас на странице Test Pilot появилась информация о Firefox No More 404s. Если включить эту функцию, то браузер покажет не ошибку 404 на месте страницы, пропавшей с сервера, а версию этой страницы из «Архива Интернета». Это сработает только в том случае, если страница вообще когда-либо существовала и если ее копия сохранена «пауками» Wayback Machine.
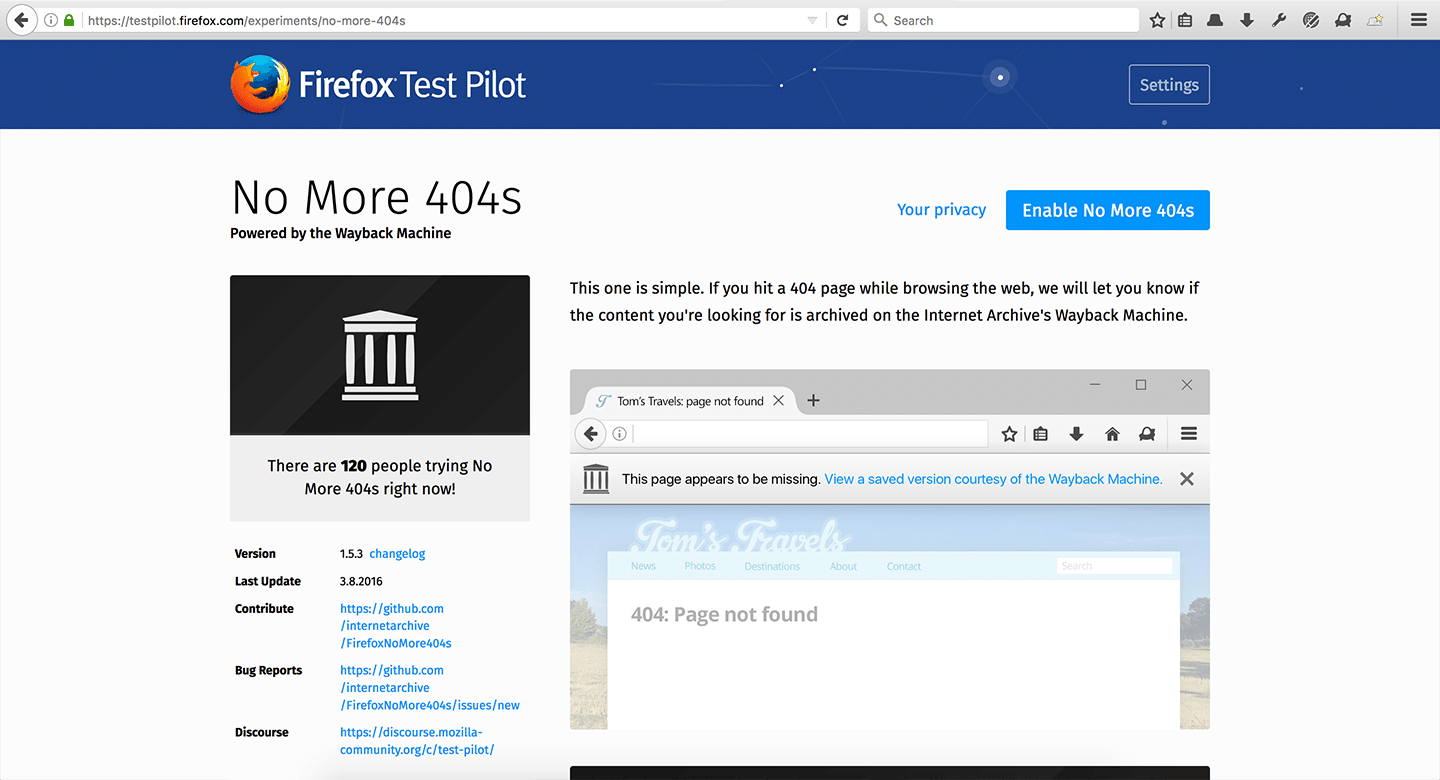
Принцип работы Firefox No More 404s простой. Браузер с включенной функцией анализирует коды ответов для ошибки «404 not found». И если ситуация позволяет, Firefox покажет сохраненную в архиве страничку, которую сервер, на котором размещается искомый сайт, по какой-то причине показать не может. Очень часть ошибка «404 not found» появляется из-за того, что страница просто была удалена. В то же время, удален может быть и весь сайт.
Если вместо «404 not found» определена иная ошибка или сайт редиректит пользователя вместо пропавшей или несуществующей странички в другое место, новая функция не будет работать. Если же No More 404s определила, что отсутствующая страница или сайт присутствуют в архиве, пользователю в окне браузера будет показано следующее сообщение: «Эта страница, похоже, недоступна. Показать сохраненную копию в Wayback Machine». Это сообщение одновременно является ссылкой на искомый ресурс или страничку.
Сейчас функция не всегда срабатывает корректно. В некоторых случаях, несмотря на сообщение с предложением показать архивную страничку, оказывается, что в Wayback Machine ничего нет. Кстати, есть отличный аналог No More 404s в виде расширения Resurrect Pages. Это расширение поддерживает «Архив Интернета», работает с кэшем поисковых систем и другими архивными ресурсами.
Для того, чтобы начать работу с Firefox No More 404s, нужно начала установить расширение Test Pilot. Установка позволит работать и с другими новинками. Это Activity Stream, Teb Center, Universal Search.

Activity Stream делает поиск по журналу посещенных страниц более эффективным, экономя время пользователей. Функция помогает найти сайт, который был посещен, показался пользователю важным, но адрес ресурса был забыт. При открытии новой вкладки пользователю демонстрируется список наиболее часто посещаемых им сайтов и подсказки по журналу посещенных страниц.
Tab Center отображает вкладки вертикально, а не горизонтально. Многим пользователям такой режим отображения вкладок нравится больше традиционного.
Universal Search объединяет историю Awesome Bar с выпадающим меню Firefox Search. Сделано это для того, чтобы пользователь мог быстрее найти нужную ему информацию.
Поделиться с друзьями
Комментарии (16)
Jogger
07.08.2016 22:23-1>Если вместо «404 not found» определена иная ошибка или сайт редиректит пользователя вместо пропавшей или несуществующей странички в другое место, новая функция не будет работать.
Фух, слава богу, а то мне поплохело от идеи что меня вместо штатной страницы будет на заглушку кидать.
А так вообще интересная функция, только вот вопрос — готов ли archive.org к таким дополнительным нагрузкам?

zedalert
08.08.2016 11:55Особенно доставляет сайт Microsoft, который после выхода каждой ОС переделывается, и ничего старого там уже не найти, большинство ссылок из «старых» программ и ОС ведут в никуда.
Darth_Biomech
С тех пор как wayback machine ввели свое дебильнейшее правило о том что наличие в robots.txt записи о непускании их робота на сайт означает «сотрите ВСЮ историю нашего сайта!», из архива были выпилены процентов так 70 сохраненных там ранее сайтов, что сделало его по большей части бесполезным.
roboq6
Думаю это страховка от авторов сайтов которые по каким-то причинам НЕ желают чтобы была создана копия их сайта. Такие случаи уже были, с ними по этому поводу судились.
Что касается самой функции Firefox, то может получиться конфуз в тех странах где власти заблокировали Wayback Machine (благо он может использоваться для обхода цензуры). Пользователь будет думать что у него страница медленно загружается, в то время как браузер будет тщетно пытаться получить доступ к Wayback Machine. И так каждый раз когда в норме сразу последовал бы 404.
Darth_Biomech
Страховка была бы гораздо проще выполнена в стиле фидбековой формы «если вы хотите удалить свой сайт из нашего архива, назовите нам причину».
roboq6
Это всё равно что взять чью-либо вещь без спросу и у себя в квартире повесить плакат «если Вы хотите чтобы я вернул Вашу вещь которую я у Вас спёр, то прямо так и скажите, я верну её A.S.A.P. ». Украв её Вы уже поступили неправильно, и то что Вы готовы возвратить вещь назад по первому требованию владельца возможно в некоторой степени смягчает Вашу вину, но отнюдь не аннулирует. И это при том, что возможно в некоторых случаях владельцам вещей было пофиг что Вы её забрали себе.
(Только не надо интерпретировать мой пример как знак равенства между кражей и незаконным копированием данных, тут речь об другом.)
sumanai
> Только не надо интерпретировать мой пример как знак равенства между кражей и незаконным копированием данных, тут речь об другом
Конечно не нужно, ибо копирование тут совершенно законное. Всё, что было выставлено в открытый доступ, может быть сохранено.
roboq6
Ой ли? Вот например есть сайт Slon.ru, у него написано «Любое использование материалов допускается только с согласия редакции». То есть просто взять и скопировать статью, пусть даже указав источник, нельзя. Нужно написать редакции письмо и спросить её согласие. Насколько понимаю, паук Wayback Machine не настолько продвинут чтобы запрашивать у владельцев сайтов согласие.
Плюс раз владелец сайта запретил в ROBOTS.TXT паука Wayback Machine, значит он запретил конкретно Wayback Machine копировать контент своего сайта (хотя с таким настроем он скорее всего другим запретил тоже).
sumanai
> Насколько понимаю, паук Wayback Machine не настолько продвинут чтобы запрашивать у владельцев сайтов согласие.
Для этого и был сделан robots.
> Плюс раз владелец сайта запретил в ROBOTS.TXT паука Wayback Machine, значит он запретил конкретно Wayback Machine копировать контент своего сайта (хотя с таким настроем он скорее всего другим запретил тоже).
Почему по вашему запрет на данный момент должен распространятся на все прошлые копии, сделанные в отсутствие запрета?
roboq6
>Для этого и был сделан robots.
А Вы уверены что судья с Вами согласится? Например на том же Slon.ru robots.txt вполне допускает доступ к разделу /posts где находятся платные и бесплатные статьи, однако как я уже сказал, на сайте написано «Любое использование материалов допускается только с согласия редакции.» У меня нет уверенности, но думаю вполне может быть и так, что словесная формулировка будет иметь приоритет над содержимым robots.txt с юридической точки зрения.
>Почему по вашему запрет на данный момент должен распространятся на все прошлые копии, сделанные в отсутствие запрета?
А, ну если так. Я-то думал речь идёт об прошлых копиях в которых этот запрет тоже был. Но и тогда тут не всё так ясно и однозначно. Автор ведь всегда может изменить режим доступа к своему контенту задним числом. Скажем я могу написать Open Source программу под лицензией GPL 3 и выложить её вместе с исходниками. Но потом я могу передумать и сменить лицензию на проприетарную EULA. Или я мог опубликовать в своём блоге текст своего романа. Но потом моим романом заинтересовалось издательство, предложило мне заманчивый контракт и я быстренько удалил этот текст. Вопрос, может быть в этих случаях ранее скаченный/скопированный исходный код программы/тексты романа будут задним числом незаконным?
sumanai
> А Вы уверены что судья с Вами согласится?
Я не собираюсь ни с кем судиться.
> Вопрос, может быть в этих случаях ранее скаченный/скопированный исходный код программы/тексты романа будут задним числом незаконным?
В нормальных странах закон обратной силы не имеет.
TotalAMD
Сайт был ранее предоставлен на всеобщее обозрение, следовательно, автор намеревался сделать его доступным для неограниченного круга лиц.
Darth_Biomech
Нет, это все равно что сфотографировать какую-либо вещь в месте с публичным доступом, повесить эту фоторафию у себя дома с плакатом «если Вы хотите чтобы я убрал эту фотографию вещи которую вы добровольно выставили на всеобщее обозрение, то прямо так и скажите, я уберу её A.S.A.P. » IWM не лазит в скрытые, запароленные или платные участки сайтов (впрочем, как и любой другой веб-бот), где аналогия с кражей была бы уместна, поскольку контент НЕ в свободном доступе.
andreymal
Проверить прям щас не на чем, но у меня иногда прокатывало открытие страницы как ифрейма или как (внезапно) картинки, то есть если вместо
https://web.archive.org/web/ГГГГММДДЧЧММСС/http://example.org/
написать
https://web.archive.org/web/ГГГГММДДЧЧММССif_/http://example.org/
или
https://web.archive.org/web/ГГГГММДДЧЧММССim_/http://example.org/
, то веб-архив может показать страницу, игнорируя все эти robots.txt
daihatsu
Владельцы сайтов имеют на это право.
Darth_Biomech
Владелец имеет право сказать чтобы за ним перестали следить, но что это влечет за собой подтирание истории — это если по запросу человека о том чтобы о нем не писали больше, редакторы начнут ходить по домам и забеливать прошлые опубликованные материалы о этом человеке из всех книг, газет и прочего.