
 В чем разница между двумя этими определениями инициализированных локальных переменных С/С++?
В чем разница между двумя этими определениями инициализированных локальных переменных С/С++?char buffer[32] = { 0 };
char buffer[32] = {};Одно отличие состоит в том, что первое допустимо в языках С и С++, а второе — только в С++.
Что ж, давайте тогда сосредоточимся на С++. Что означают эти два определения?
Первое гласит: компилятор должен установить значение первого элемента массива в ноль и затем (грубо говоря) инициализировать нулями оставшиеся элементы массива. Второе означает, что компилятор должен инициализировать нулями весь массив.
Эти определения несколько различаются, но по факту результат один — весь массив должен быть инициализирован нулями. Поэтому согласно правилу «as-if» в С++ они одинаковы. То есть любой достаточно современный оптимизатор должен генерировать идентичный код для каждого из этих фрагментов. Верно?
Но иногда различия в этих определениях имеют значение. Если (гипотетически) компилятор примет эти определения в высшей степени буквально, то для первого случая будет сгенерирован такой код:
алгоритм 1: buffer[0] = 0;
memset(buffer + 1, 0, 31);в то время как для второго случая код будет таким:
алгоритм 2: memset(buffer, 0, 32);И если оптимизатор не заметит, что эти два утверждения могут быть совмещены, то компилятор может сгенерировать для первого определения менее эффективный код, чем для второго.
Если компилятор буквально реализовал алгоритм 1, то нулевое значение будет присвоено первому байту данных, затем (если процессор 64-разрядный) будут выполнены три операции записи по 8 байтов. Для заполнения оставшихся семи байтов могут потребоваться еще 3 операции записи: сначала запись 4 байтов, потом 2 и затем еще 1 байта.
Ну, это гипотетически. Именно так и работает VC++. Для 64-разрядных сборок типичный код, сгенерированный для «= {0}», выглядит так:
xor eax, eax
mov BYTE PTR buffer$[rsp+0], 0
mov QWORD PTR buffer$[rsp+1], rax
mov QWORD PTR buffer$[rsp+9], rax
mov QWORD PTR buffer$[rsp+17], rax
mov DWORD PTR buffer$[rsp+25], eax
mov WORD PTR buffer$[rsp+29], ax
mov BYTE PTR buffer$[rsp+31], alГрафически это выглядит так (почти все операции записи не выровнены):

Но если опустить ноль, VC++ сгенерирует следующий код:
xor eax, eax
mov QWORD PTR buffer$[rsp], rax
mov QWORD PTR buffer$[rsp+8], rax
mov QWORD PTR buffer$[rsp+16], rax
mov QWORD PTR buffer$[rsp+24], raxЧто выглядит примерно так:

Вторая последовательность команд короче и выполняется быстрее. Разницу в скорости обычно трудно измерить, но вам в любом случае следует отдавать предпочтение более компактному и быстрому коду. Размер кода влияет на производительность на всех уровнях (сеть, диск, кэш-память), поэтому лишние байты кодов нежелательны.
Это в общем-то не важно, вероятно, это даже не окажет сколько-нибудь заметного влияния на размер реальных программ. Но лично я считаю код, сгенерированный для «= { 0 };», довольно забавным. Равносильным постоянному употреблению «эээ» при публичном выступлении.
Впервые я заметил такое поведение и сообщил о нем шесть лет назад, а недавно обнаружил, что эта проблема всё ещё присутствует в VC++ 2015 Update 3. Мне стало любопытно, и я написал небольшой скрипт на Python, чтобы скомпилировать код, указанный ниже, используя различные размеры массива и разные варианты оптимизации для платформ х86 и х64:
void ZeroArray1()
{
char buffer[BUF_SIZE] = { 0 };
printf(“Не оптимизируйте пустой буфер.%s\n”, buffer);
}
void ZeroArray2()
{
char buffer[BUF_SIZE] = {};
printf(“Не оптимизируйте пустой буфер.%s\n”, buffer);
}Представленный ниже график демонстрирует размер этих двух функций в одной конкретной конфигурации платформы — оптимизация размера для 64-разрядной сборки — в сопоставлении со значениями BUF_SIZE, колеблющимися от 1 до 32 (когда значение BUF_SIZE превышает 32, размеры вариантов кода одинаковы):

В случаях когда значение BUF_SIZE равно 4, 8 и 32, экономия памяти впечатляющая — размер кода уменьшается на 23,8%, 17,6% и 20,5% соответственно. Средний объем сэкономленной памяти составляет 5,4%, и это довольно существенно, учитывая, что все эти функции имеют общий код эпилога, пролога и вызов printf.
Здесь я хотел бы порекомендовать всем программистам С++ при инициализации структур и массивов отдавать предпочтение «= {};» вместо = «= { 0 };». На мой взгляд, он лучше с эстетической точки зрения, и, кажется, почти всегда генерирует более короткий код.
Но именно «почти». Результаты, приведенные выше, демонстрируют, что есть несколько случаев, когда «= {0};» генерирует более оптимальный код. Для одно- и двухбайтовых форматов «= { 0 };» немедленно записывает ноль в массив (согласно команде), в то время как «= {};» обнуляет регистр и уже потом создает такую запись. Для 16-байтного формата «= { 0 };» использует регистр SSE, чтобы обнулить все байты одновременно — не знаю, почему в компиляторах этот метод не используется чаще.
Итак, прежде чем что-либо порекомендовать, я счел своим долгом испытать разнообразные настройки оптимизации для 32-разрядной и 64-разрядной систем. Основные результаты:
32-разрядная с /O1/Oy-: Средняя экономия памяти от 1 до 32 составляет 3,125 байта, 5,42%.
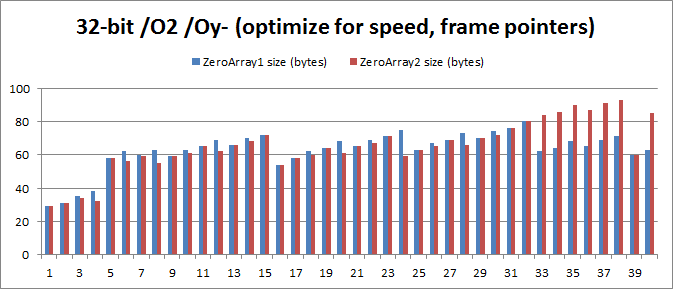
32-разрядная с /О2/Оу-: Средняя экономия памяти от 1 до 40 составляет 2,075 байта, 3,29%.
32-разрядная с /О2: Средняя экономия памяти от 1 до 40 составляет 1,150 байт, 1,79%.
64-разрядная с /О1: Средняя экономия памяти от 1 до 32 составляет 3,844 байта, 5,45%
64-разрядная с /О2: Средняя экономия памяти от 1 до 32 составляет 3,688 байта, 5,21%.
Проблема в том, что результат для 32-разрядной /О2/Оу-, где «= {};» в среднем на 2,075 байта больше, чем при «= { 0 };». Это справедливо для значений от 32 до 40, где код «= {};» обычно на 22 байта больше! Причина в том, что для обнуления массива код «= {};» использует команды «movaps» вместо «movups». Это означает, что ему приходится использовать массу команд только для того, чтобы обеспечить выравнивание стека по 16 байтам. Вот незадача.
Выводы
Я все же рекомендую программистам С++ отдавать предпочтение «= {};», хоть несколько противоречивые результаты и показывают, что предоставляемое этим вариантом преимущество является незначительным.
Было бы неплохо, если бы оптимизатор VC++ генерировал идентичный код для этих двух компонентов, и было бы великолепно, если бы этот код был идеальным всегда. Может быть, когда-нибудь так и будет?
Хотелось бы мне знать, почему оптимизатор VC++ столь непоследователен при принятии решения о том, когда следует использовать 16-байтовые регистры SSE для обнуления памяти. В 64-битных системах этот регистр используется только для 16-байтовых буферов, инициализированных с помощью «= { 0 };», несмотря на то, что с SSE обычно генерируется более компактный код.
Думаю, эти трудности с генерацией кода характерны и для более серьезной проблемы, связанной с тем, что смежные инициализаторы агрегатов не объединяются. Однако я уже достаточно много времени уделил этому вопросу, так что оставлю его на уровне теории.
Здесь я сообщил об этом баге, а скрипт на Python можно найти тут.
Обратите внимание, что представленный ниже код, который также должен быть эквивалентным, в любом случае генерирует даже худший код, чем ZeroArray1 и ZeroArray2.
char buffer[32] = “”;Хотя сам я не проводил тестирование, я слышал, что компиляторы gcc и clang не попались на удочку «= { 0 };».
В более ранних версиях VC++ 2010 проблема была серьезнее. В некоторых случаях использовался вызов memset, и «= { 0 };» при любых обстоятельствах гарантировал неверное выравнивание адреса. В более ранних версиях VC++ 2010 CRT при неверном выравнивании последние 128 байт данных записывались в четыре раза медленнее (команда stosb вместо stosd). Это быстро исправили.
Перевод выполнен ABBYY LS
Комментарии (29)



Alex_ME
18.08.2016 09:29Может это на случая, если по какой-то ну очень важной причине программист напишет так:
char buffer[32] = { 1 };
и хочет получить
1 0 0 0 0 ...
Хотя я не знаю, зачем это может понадобиться.

Evengard
18.08.2016 09:49+7Честно говоря, первый раз, когда-то давным давно, написав
char buffer[32] = { 1 };
Я ожидал получить в результате то же самое, что и
memset(buffer, 1, 32);
Эх, старые добрые времена… Хотя если честно мне такой вариант до сих пор кажется логичней.

maaGames
18.08.2016 09:50+2Как я понял, проблема актуальна только для типов, размер которых меньше чем sizeof(void*)? Т.е. для массива double всей этой свистопляски с выравниванием не будет в принципе и будет одна лишняя операция, если компилятор не догадается всё в один memset впихнуть?
DistortNeo
18.08.2016 15:18SSE регистры имеют размер 16 байт, AVX — 32 байта. Их запись также должна быть выровнена.
maaGames
18.08.2016 15:20SSE регистры не имеют никакого отношения к функции memset.
DistortNeo
18.08.2016 17:49SSE регистры имеют прямое отношение к memset, т.к. компиляторы бывают умные и могут его соптимизировать до пары ассемблерных инструкций, не используя библиотечные вызовы. И даже просто выкинуть обнуление, если после инициализации присваиваются другие значения.
maaGames
18.08.2016 17:53В статье речь о memset, а не про то, как компилятор может оптимизировать SSE инструкции. В контексте SSE память должна быть выровнена на 16 байт, с массивами вообще веселуха получается с «лишними» байтами в начале массива. Думаю, про такие специфичные случаи можно вообще не говорить.
DistortNeo
18.08.2016 19:02Один movups, не требующий выравнивания, но работающий медленнее, часто выходит быстрее обычных операций. В моих проектах (обработка изображений) это, кстати, довольно частый случай.

CTAPOBEP
18.08.2016 16:13+3Собственно, с выходом стандарта C++11 не осталось ни единой причины для использования «сырых» массивов и оператора new[].
KennyGin
18.08.2016 18:21+2Не осталось, если не считать следующие две:
1) Когда критично быстродействие и размер использованной памяти.
2) Когда массивы живут не только «внутри» чистого C++, где мы можем обмазываться контейнерами сколько угодно, но и активно куда-то передаются или откуда-то получаются. Я имею в виду связки C++ с высокоуровневыми ЯП, а также различные прикладные расширения C++ типа Cuda.
DarkEld3r
19.08.2016 15:211) Когда критично быстродействие и размер использованной памяти.
И какой оверхед std::array привносит?
DarkEld3r
19.08.2016 15:20std::array ведь не умеет выводить размер из списка инициализации?..
CTAPOBEP
19.08.2016 18:22Насколько я понимаю — нет, но в 99.99% случаев прекрасно работает vector. Допускаю, что в каких-то случаях использование array может оказаться критичным, но сталкиваться с такой ситуацией (а это лет за 15 уже) ни разу не приходилось.

winger
25.08.2016 02:35Как минимум, локальные «сырые» массивы выделяются на стеке, а не в хипе, что намного быстрее.
robert_ayrapetyan
Подтверждаю — не смог заставить clang сгенерировать похожий код. На O2 задействуется SSE, без оптимизации — просто вызов memset. Так что это какая-то проблема VС.
masai
Кстати, GCC 6.1 что с оптимизациями, что без использует
rep stosq, который быстрееmovaps, выдаваемого clang.robert_ayrapetyan
Хм, по ссылке что вы дали, movaps на некоторых процах отрабатывает быстрее…
ion2
Это если movaps не потребует переключения контекста SSE. Или его теперь принудительно меняют при переключении на другой процесс?
DistortNeo
Переключение режимов SSE-AVX занимает около 70 тактов. При обнулении малого массива и переключении SSE-AVX на каждой итерации разница во времени выполнения будет отличаться в разы, чего не наблюдается.
ion2
Переключение контекста при исключении #NM выполняет операционная система. Это не 70 тактов.
TrueMaker
Я боюсь спросить, что вы такое делаете, что знаете подробности таких деталей?
ion2
Я один из разработчиков ОС Колибри и как раз делал переключение контекста fpu/sse. Поэтому знаю как всё работает. Обычно применяют отложенное переключение контекста. При установленном в 1 бите TS регистра cr0 первая команда сопроцессора вызывает исключение 7(#NM). Ядро сбрасывает бит TS и производит переключение контекста сопроцессора. Поэтому сложно сказать сколько тактов на самом деле займёт команда. На мой взгляд применять simd нет смысла, если объём данных меньше пары килобайт. С учётом длинных регистров avx планка ещё выше. В принципе ядро может отслеживать количество исключений для каждого процесса, и если сопроцессор активно используется переключать контекст сразу. Не знаю, используется такая схема или нет.
DistortNeo
Подождите. Речь не о FPU/SSE, а о SSE/AVX, при переключении которого не происходит никаких исключений. Просто fallback YMM->XMM реализован довольно костыльно, и требует теневого копирования регистров при смене набора команд. На это и уходит около 70 тактов — точное количество зависит от реального числа «физических» регистров.
ion2
А при чём здесь AVX? Первоначально речь шла о movaps которая к AVX не относится. Это команда SSE. А внутренняя кухня процессора при использовании разных наборов команд дело тёмное. Откуда эта информация про теневое копирование? И для чего? Регистры ymm удваивают xmm и совпадают по формату. Это же не альяс fpu/mmx.
DistortNeo
При том, что пользовательский код может содержать инструкции AVX, а тут опа — обнуление переменной через SSE. Эта ситуация не такая уж и редкая, на первый взгляд. Вот здесь чуть подробнее:
https://software.intel.com/en-us/articles/intel-avx-state-transitions-migrating-sse-code-to-avx
Информация про теневое копирование следует из технических спецификаций. Причина этому — аппаратная реализация регистров (маппинг), операций с ним на низком уровне и упрощение архитектуры процессора (реализация AVX команд через существующие блоки SSE и отказ от блоков копирования) за счёт потери некоторой функциональности.
ion2
Ага. Уже разобрался. Это особенность двух близких микроархитектур Sandy Bridge и Ivy Bridge в отличие от исключения при установленном бите cr0.ts, которое всегда работает. Кроме того компиляторы стараются защитить программистов от выстрела в ногу и не генерируют sse и avx код в одном объектном файле.
DistortNeo
Компилятор генерирует адекватный код ровно до того момента, как программист начинает эти инструкции использовать. Самая неприятная для компилятора ситуация — это когда программист начинает вручную использовать avx и делать в коде две ветки: legacy и avx.
Решение простое: просто генерить два комплекта бинарников, чтобы не допустить смешения инструкций.