
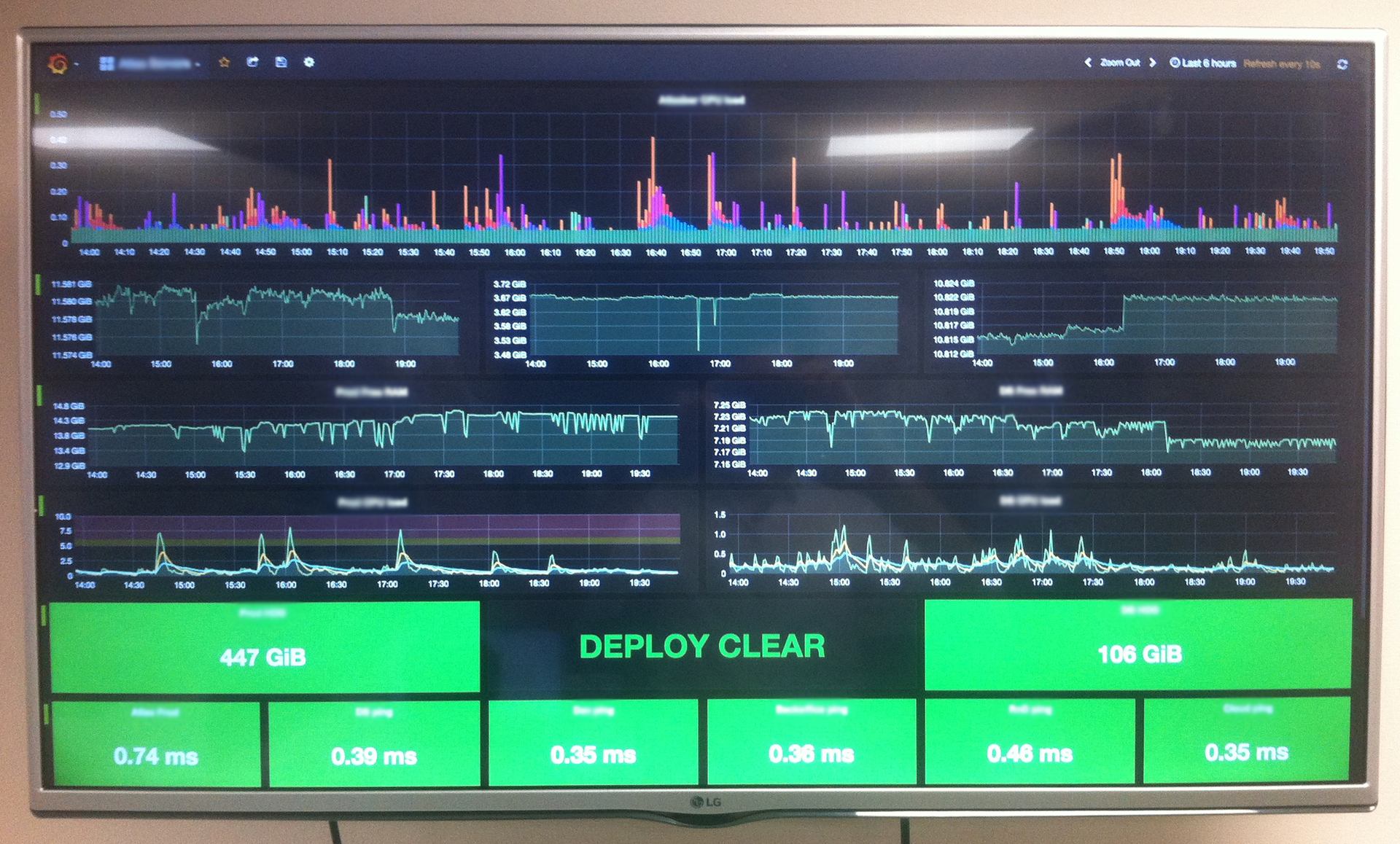
Мы в Атласе любим, когда все находится под контролем. Это касается и всей серверной инфраструктуры, которая, с годами, превратилась в живой организм из многочисленных виртуальных машин, сервисов и служб. Появилась потребность наблюдать за жизненно важными аспектами IT-составляющей нашей деятельности: мониторить боевой сервер, отслеживать изменения системных ресурсов на виртуалках баз данных, следить за ходом бизнес-процессов и тд. Встал вопрос — как же этого добиться и главное какими инструментами? Стали искать какие-то готовые решения. Перепробовали кучу платных/бесплатных сервисов, которые, якобы, предоставляли бы нам "самую ценную" информацию о состоянии нашей системы. Но, в конечном итоге, все сводилось к каким-то непонятных диаграммам, схемам и цифрам, которые, по сути, для нас не имели никакой ценности.
Так мы пришли к пониманию, что надо собирать что-то самостоятельно. За основу решили взять самую гибкую и продвинутую систему, которую можно настроить для мониторинга чего и как угодно — Nagios. Настроили, поставили, работает — круто! Жаль только интерфейс сего чуда застрял где-то в середине 90-х, а нам хотелось, чтобы еще и визуальная составляющая была на уровне.
Недолгий поиск показал, что лидером среди решений по созданию красивых дашбордов является Grafana. Так и решили выводить весь наш мониторинг из Nagios на мониторах в виде красивых графиков в Grafana. Вопрос остался только в том — как их подружить друг с другом?
Общая цель
Контролировать всю инфраструктуру через Nagios, настроить оповещения о проблемах в системе через Slack, подключить вывод данных о производительности системы в графическую оболочку Grafana для мониторинга в реальном времени.
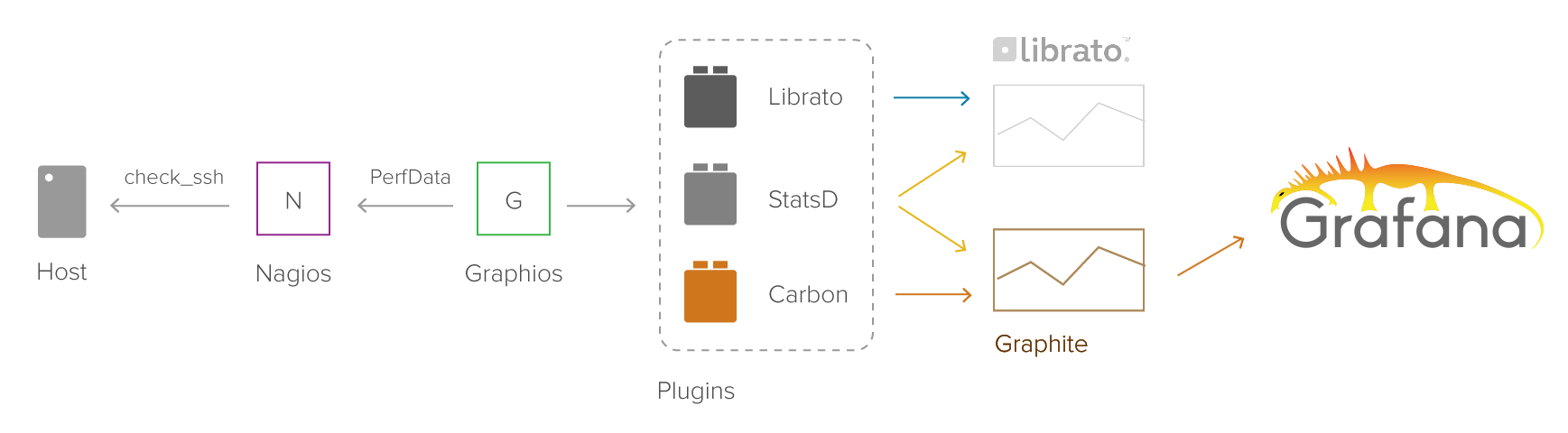
Стэк технологий
- Nagios — центральный узел мониторинга системы
- NRPE — набор плагинов, передающих Nagios информацию о хостах/сервисах
- Graphios — плагин Nagios для сбора данных о производительности системы, необходимых для постоения графиков
- Carbon — back-end прослойка для хранения данных о проиводительности системы в базе данных
- Graphite — модуль обработки стат. данных и построения графиков
- Grafana — графическая оболочка, работающая с данными из Graphite для построения красивых дашбордов с графиками в реальном времени
- Slack Nagios App — модуль для запуска оповещений Nagios через Slack
Короткое описание
Nagios собирает статистические данные со всевозможных виртуалок всей системы. Нам эти данные нужно сохранять в базу в определенном формате и с определенным интервалом, чтобы Grafana смогла их выводить. Grafana работает с несколькими форматами, но самый удобный для нас — Graphite. Graphite — по сути, такая же графическая оболочка, но его интерфейс, видимо, делали те же люди, что и интерфейс Nagios. Под капотом у него лежит база данных, которая хранит стат. данные — Whisper и прослойка для обработки этих данных — Carbon. Напрямую Nagios не умеет общаться с Graphite-ом, поэтому умные люди создали доп. плагин, который берет текущие показания из Nagios и передает их в Carbon — этот плагин называется Graphios. Таким образом, наша задача — связать воедино 6 различных технологий. Поехали!
Сразу небольшой дисклеймер:
- Текущая конфигурация собиралась под Debian, но общая логика сборки одинакова под всё семейство.
- В данной статье я не буду рассказывать об установке и настройке самого Nagios-а, так как в сети полно мануалов (о том, как качественно настроить Nagios — напишу отдельно). Речь пойдет именно о связке серии технологий между собой — никакой лирики, чистый кардкор.
Carbon
Ставим и настраиваем Carbon:
apt-get install graphite-carbon
sudo nano /etc/default/graphite-carbonПроставляем значение параметра в true:
CARBON_CACHE_ENABLED=trueСохраняем, выходим.
Редактируем файл схем
sudo nano /etc/carbon/storage-schemas.confВ этом файле представлены директивы, в которых указаны параметры хранения стат. данных: как часто сохраняются и как долго хранятся. Для себя мы используем приблизительно следующую директиву:
[atlas]
pattern = .*
retentions = 60s:1yЭто означает, что данные будут поступать в базу каждую минуту и храниться на протяжении года. Поправьте значения под свои нужды.
Также, важно понимать, что частота сохранения данных в базе не должна превышать частоту отдачи данных самим Nagios-ом — иначе мы будем складывать в базу дубликаты значений. Из коробки Nagios прослушивает все сервисы и хосты раз в 10 минут, так что если хочется добиться максимального real-time-а — нужно также изменить интервалы обработки на стороне Nagios-а.
Подключаем последний конфиг и стартуем Carbon:
sudo cp /usr/share/doc/graphite-carbon/examples/storage-aggregation.conf.example /etc/carbon/storage-aggregation.conf
sudo service carbon-cache startDatabase
Подготавливаем базу для всех дальнейших программ. Мы предпочитаем PostgreSQL, но Graphite поддерживает разные базы.
apt-get install postgresql libpq-dev python-psycopg2
sudo -u postgres psqlНастраиваем нового пользователя и базу:
CREATE USER graphite WITH PASSWORD 'password';
CREATE DATABASE graphite WITH OWNER graphite;
\qПароль от БД нужно сохранить — он нам еще пригодится.
Graphios
Устанавливаем Python, Django и далее — сам graphios:
apt-get install -y python2.6 python-pip python-cairo python-django python-django-tagging
pip install graphiosРедактируем файл /etc/graphios/graphios.cfg:
debug = False
enable_carbon = TrueСоздаем папку для хранения статистических выгрузок:
mkdir /var/spool/nagios/graphios/
chown -R nagios:nagios /var/spool/nagiosТестирование:
Добавляем тестовую строку в определение сервиса Nagios:
define service {
use generic-service
host_name DB
service_description PING
check_command check_ping!100.0,20%!500.0,60%
_graphiteprefix monitoring.nagios01.pingto
}Вызываем Graphios в тестовом режиме:
/usr/local/bin/graphios.py --spool-directory /var/spool/nagios/graphios --log-file /tmp/graphios.log --backend carbon --server 127.0.0.1:2004 --testНа выходе должны появляться записи типа:
monitoring.nagios01.pingto.DB.rta 0.248000 1461427743
monitoring.nagios01.pingto.DB.pl 0 1461427743Если все в норме — запускаем демона graphios:
service graphios startGraphite
Graphite нужно ставить строго после установки Carbon, иначе Nagios/Graphios не смогут правильно отправлять данные
Устанавливаем основные зависимости
apt-get install -y libapache2-mod-wsgi python-twisted python-memcache python-pysqlite2 python-simplejson
pip install whisper
pip install carbon
pip install graphite-web
pip install pytz
pip install pyparsing
wget https://raw.github.com/tmm1/graphite/master/examples/example-graphite-vhost.conf -O /etc/apache2/sites-available/graphiteДалее, нужно немного поправить новый конфиг Apache2:
nano /etc/apache2/sites-available/graphiteМеняем "WSGISocketPrefix /etc/httpd/wsgi/" на:
WSGISocketPrefix /var/run/apache2/wsgiДобавляем еще один алиас после строчки "Alias /content/ /opt/graphite/webapp/content/":
Alias /static/ "/opt/graphite/static/"Сохраняем, выходим.
Настраиваем local_settings.py
cd /opt/graphite/webapp/graphite
cp local_settings.py.example local_settings.py
nano local_settings.pyВ открывшемся файле включаем строки и проставляем значения:
SECRET_KEY нужно придумать, а значения для директивы DATABASE берем из ранее созданной базы.
Значение WHISPER_DIR можно найти через команду "locate whisper".
Значения директивы CARBONLINK_HOSTS нужно проставить в соответствии с выводом команды "lsof -i -P | grep carbon".
SECRET_KEY = 'some_secret_key'
TIME_ZONE = 'Europe/Moscow'
WHISPER_DIR = '/var/lib/graphite/whisper'
USE_REMOTE_USER_AUTHENTICATION = True
DATABASES = {
'default': {
'NAME': 'graphite',
'ENGINE': 'django.db.backends.postgresql_psycopg2',
'USER': 'graphite',
'PASSWORD': 'password',
'HOST': '127.0.0.1',
'PORT': ''
}
}
CARBONLINK_HOSTS = ["127.0.0.1:2003","127.0.0.1:2004","127.0.0.1:7002"]Настраиваем Graphite
В процессе конфигурации, система попросит завести супер-пользователя. Нужно проставить новые значения и запомнить их.
cd /opt/graphite/conf/
cp graphite.wsgi.example graphite.wsgi
cd /opt/graphite/webapp/graphite
python manage.py syncdb
chown -R www-data:www-data /opt/graphite/storage/
a2enmod wsgi
a2ensite graphite
python manage.py collectstatic --pythonpath=/opt/graphite/webapp
chown -R www-data:www-data /opt/graphite/static
/etc/init.d/apache2 restartGrafana
Самая простая часть — если Graphite/Carbon настроены правильно — достаточно будет подключить новый ресурс типа Graphite и настроить дашборд для вывода данных — Grafana сама сделает все остальное!
wget https://grafanarel.s3.amazonaws.com/builds/grafana_3.0.0-beta51460725904_amd64.deb
sudo apt-get install -y adduser libfontconfig
sudo dpkg -i grafana_3.0.0-beta51460725904_amd64.deb
sudo service grafana-server start
sudo update-rc.d grafana-server defaults 95 10Интерфейс будет доступен на 3000 порту. Дефолтные логин/пароль — admin.
Бонус: Slack Nagios App
Как альтернатива прямой визуализации и пассивным письмам — подключим также вывод оповещений из Nagios в Slack.
1) Создаем новый канал в Slack, например #alerts
2) Идем на страницу приложений Slack-а

3) Находим приложение Nagios

4) Следуем инструкциям по загрузке конфига
wget https://raw.github.com/tinyspeck/services-examples/master/nagios.pl
cp nagios.pl /usr/local/bin/slack_nagios.pl
chmod 755 /usr/local/bin/slack_nagios.pl5) Копируем токен и домен Slack и вставляем их в новый конфиг /usr/local/bin/slack_nagios.pl

6) Копируем директивы Nagios и вставляем в соответствующие места (команды и новый контакт)
define contactgroup {
contactgroup_name admins
alias Nagios Administrators
members root,slack
}
define contact {
contact_name slack
alias Slack
service_notification_period 24x7
host_notification_period 24x7
service_notification_options w,u,c,r
host_notification_options d,r
service_notification_commands notify-service-by-slack
host_notification_commands notify-host-by-slack
}
define command {
command_name notify-service-by-slack
command_line /usr/local/bin/slack_nagios.pl -field slack_channel=#alerts -field HOSTALIAS="$HOSTADDRESS$" -field SERVICEDESC="$SERVICEDESC$" -field SERVICESTATE="$SERVICESTATE$" -field SERVICEOUTPUT="$SERVICEOUTPUT$ ($LONGDATETIME$)" -field NOTIFICATIONTYPE="$NOTIFICATIONTYPE$"
}
define command {
command_name notify-host-by-slack
command_line /usr/local/bin/slack_nagios.pl -field slack_channel=#alerts -field HOSTALIAS="$HOSTADDRESS$" -field HOSTSTATE="$HOSTSTATE$" -field HOSTOUTPUT="$HOSTOUTPUT$ ($LONGDATETIME$)" -field NOTIFICATIONTYPE="$NOTIFICATIONTYPE$"
}7) Сохраняем, перегружаем Nagios, проверяем.
Полезные материалы:
» How To Configure StatsD to Collect Arbitrary Stats for Graphite on Ubuntu 14.04
» How To Install and Use Graphite on an Ubuntu 14.04 Server
» https://github.com/shawn-sterling/graphios
» http://grafana.org/features/#graphite
Комментарии (24)

zim32
29.08.2016 16:38Не сравнивали со связкой Logstash -> Elasticsearch -> Kibana?
Там вроде намного меньше технологий пересекается, должо быть проще в настройке.
SirEdvin
29.08.2016 17:07Как я понимаю, такой набор технологий не для сбора метрик. Например, Whisper для этого подходит куда лучше + автоматическая чистка данных.
zim32
29.08.2016 17:25Да вроде даже крупные игроки (Netflix) если не ошибаюсь используют этот стек. Счетчики пишуться на Go. Данные удаляются дропаньем индекса. Есть механизм алертов (сам не использовал)
SirEdvin
29.08.2016 17:36Данные удаляются дропаньем индекса
Если не ошибаюсь, Whisper позволяет чистить данные не полностью, а скажем, после того, как данным стали старше 6 месяцев, их сжимать.
Слабой стороной этой штуки может быть отсутствие нативных алертов и проблемы с кластеризацией.

Undiabler
29.08.2016 22:33увы-увы, лично мой опыт работы с данной связкой крайне печален
все отлично работает пока каждое по одной копии и/или на одном сервере
для масштабирования связка крайне неудобоварима, кибана с еластиком требуют ежедневного администрования, постоянно то индексы на одном из кластеров побились то кибана отвалилась
могу посоветовать посмотреть в сторону telegraf -> influx -> chronograf
связка намного проще и в настройки и в обслуживании
Sovigod
29.08.2016 23:01+1telegraf -> influx(с использованием CQ) -> grafana -> kapacitor — вот реально шикарно. И практически не кушает ресурсов даже на очень больших объемах данных для мониторинга.

xunder
29.08.2016 22:47+2Я верю, что каждый инструмент хорош для выполнения своего спектра задач. Для наших задач текущий стэк подходит лучше всего: мы контролируем все железо, каждый отдельный сервис, получаем качественные оповещения с минимумом false-positive, имеем возможность в обход Nagios-а слать кастомные стат. данные из любых мест нашей платформы напрямую в Whisper и отслеживать всю эту прелесть со скоростью ее изменений на больших экранах.
К тому же, я лично за подход «убился — разобрался — работает как часы», чем за «проще в настройке — поставил — должно работать». Разве не для того мы тут все статьи пишем, чтобы как раз делиться опытом настройки сложных вещей?
commanderxo
30.08.2016 13:05+1У ELK-стека другой предназначение, он хорош для логов, которые содержат текстовые сообщения, структурированные или не очень. Так что это не альтернатива, а дополнение к описанным выше технологиям.
Метрики это числа, их можно естественным образом агрегировать и сжимать по времени. Данные за сегодня храним с разрешением в одну секунду, метрики за прошлый месяц усредняем поминутно, а для сравнения нынешнего года с предыдущим достаточно знать старые метрики с разрешением в час. Данные никогда полностью не удаляются, просто становятся менее подробными по мере устаревания.
Elasticsearch такого не может, да и бессмысленно это, усреднять текстовые данные. Зато хорошо помогает в поиске и устранении ошибок. Ограниченное время хранения (дни, недели) — не помеха, всё равно крайне редко интересует stack-trace исключения годичной давности. Баги обычно нужно фиксить здесь и сейчас. Декорирование записей тэгами также очень удобно, например у нас микросервисы вызывают друг-друга и каждый пишет в логи общий для всей цепочки correlation-id. Когда сервис в глубине системы рушится, в Кибане можно в пару кликов вывести всю цепочку вызовов приведшую к проблеме.
Понятно, что Kibana имеет простенькие средства агрегирования и примтивную математику по цифровым полям, так что при большом желании можно использовать её и для показа метрик, но остаются проблемы с историческими данными, плюс на средства визуализации невозможно смотреть без слёз. Например есть бессмысленный pie-chart, но нет горизонтального bar-chart. Хорошо хоть у Elasticsearch есть простой и понятный REST-API, так что легко приделать собственный интерфейс. Мы писали собственные плагины к AtlasBoard, которые тянут данные из ElasticSearch и показывают JavaScript-ом в браузере, благо графических JS-библиотек есть немерено, на любой вкус и цвет.
По моему мнению, Nagios+Grafana хорошо подходят для мониторинга железа, и «больших технологий» общих для всех, например «мы хостим веб-сайт». ELK хорош, если важна специфика работы конкретного приложения и требуются ответы на вопросы типа «пользователи жалуются, что проверка правильности почтового адреса часто рушится, если в названии города есть буква 'ё', проверь пожалуйста, так ли это».zim32
30.08.2016 13:15Спасибо за развернутый ответ. Я так понял если подытожить, то ELK — для хипстеров )
commanderxo
30.08.2016 13:52+1Врач начинает осмотр с измерения температуры и давления. Да, есть сотни разных болезней и других причин для повышенной температуры, и это крайне неточная метрика, но она проста в измерении и позволяет быстро определить кому из пациентов нужно уделить больше внимания. Больному с жаром назначают дополнительные, более точные, анализы.
Grafana хороша чтоб с одного взгляда на необычную загрузку процессора, памяти или долгое время отклика определить, что пора вызывать программистов. А вот они для вылавливания багов полезут в хранящиеся в Elasticsearch логи, потому как «средняя температура по больнице» недостаточно точный инструмент.
Кибана в роли Dashboard это действительно «для хипстеров». Она хороша как интерактивный инструмент, а для висящего под потолком телевизора подходит плохо.xunder
30.08.2016 14:53Grafana хороша чтоб с одного взгляда на необычную загрузку процессора, памяти или долгое время отклика определить, что пора вызывать программистов. А вот они для вылавливания багов полезут в хранящиеся в Elasticsearch логи, потому как «средняя температура по больнице» недостаточно точный инструмент.
В точку!

ArjLover
30.08.2016 03:34+2А сам nagios настраивается по старинке в текстовых конфигах?
Можно посмотреть еще примеров красивых экранов?

Ar0x13
30.08.2016 11:38-1Почему решили использовать Nagios — допустим тот же Zabbix отрисовывает отличнейшие графики и достаточно гибок.
SirEdvin
31.08.2016 17:54"допустим тот же Zabbix отрисовывает отличнейшие графики и достаточно гибок."
Немного на эту тему: https://habrahabr.ru/post/275737/
Графики в Zabbix — это боль и ничего, кроме боли.
xref
30.08.2016 11:38+1В последней версии Grafana таки допилили алертинг, в частности со Slack. На скриншоте выглядит достойно )
https://github.com/grafana/grafana/issues/2209#issuecomment-236842179

DenisIzmaylov
30.08.2016 14:49Алекс, спасибо за статью. Всё здорово. Мы сами используем Grafana для мониторинга Kubernetes-кластера и в целом довольны. Вопрос не совсем по теме, но понравилась, как схема нарисована. Что использовали, если не секрет? В чём рисовали?
xunder
30.08.2016 15:02Часть схемы нашел где-то на просторах и дорисовал под свои нужды в Ps. Такие вещи делаются на раз-два в том же Ps или Ai — по сути, просто набор из прямоугольников, линий и текста.
jazzl0ver
30.08.2016 15:34+1Не смотрели в сторону Centreon? Умеет и нагиос из GUI настраивать (правда, там сейчас они свой брокер пилят, но это не большая проблема) и графики понятные строить…
xunder
30.08.2016 17:16Centreon взял за основу ядро Nagios и, как это принято, решил создать новый, единый стандарт. Проблема заключается в том, что когда пытаешься делать все и сразу — хорошо получается ничего) Поэтому, да, это уже не Nagios, но еще и не Grafana. Так что я предпочитаю пользоваться инструментами, которые прекрасны в своей узкой и конкретной специфике, а потом связывать эти инструменты друг с другом.
Это как учитель младших классов — знает все и про все и детям кажется что это самый умный человек на земле. А потом детишки взрослеют и наступает пора отдельно учиться математике с математиком, языкам с лингвистами и тд.
Несомненно, Centreon для многих может стать отличной альтернативой. Вопрос только в подходе к своим задачам. Какие задачи, такие и инструменты.jazzl0ver
30.08.2016 17:28Спасибо за ответ. Несомненно Grafana строит /более/ красивые графики. Но по трудозатратам на внедрение системы мониторинга (а затем ее поддержки), имхо, как-то несопоставимо: поставить один готовый продукт, который умеет практически все «из коробки», или взаимоувязывать 5 различных продуктов.
Про «делать все и сразу» и «все плохо» я как-то не понял. Что Центреон делает плохо?
Smithson
У вас, кажется, ошибка:
60, наверное?
xunder
Поправил, благодарю!