
Я и мои коллеги всегда склоняем своих клиентов полностью автоматизировать процесс деплоя. Автоматизация помогает сократить количество конфликтов и задержек, которые возникают в процессе между "завершением" работы над программой и введением в эксплуатацию. Дэйв Фарли (Dave Farley) и Джез Хамбл (Jez Humble) заканчивают книгу "Непрерывная доставка" (Continuous Delivery) на эту тему. Она основывается на множестве идей, которые в целом связаны с непрерывной интеграцией и подталкивают к возможности быстро пустить софт в работу. Глава о сине-зеленом деплое привлекла мое внимание, потому что это один из малоиспользуемых методов, и я решил кратко его осветить.
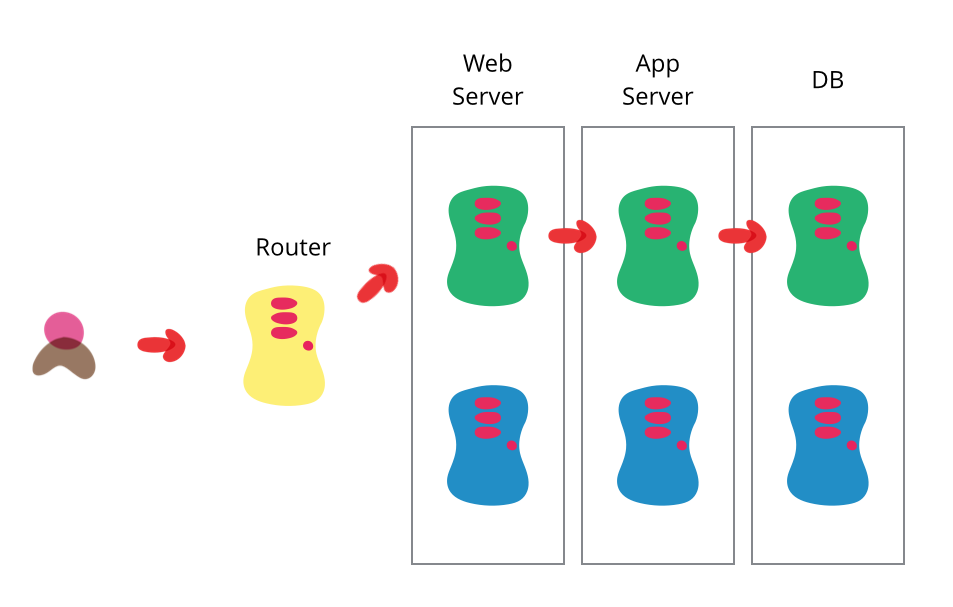
Одна из задач автоматизации деплоя — переход из одного состояния в другое внутри себя же, с переводом софта из финальной стадии тестирования в действующий продакшен. Обычно это нужно сделать быстро, чтобы минимизировать время простоя. При сине-зеленом подходе у вас есть два продакшена, насколько возможно идентичных. В любое время один из них, допустим синий, активен. При подготовке новой версии софта, вы делаете финальное тестирование в зелёном продакшене. Вы убеждаетесь, что программа в этом продакшене работает и настраиваете роутер так, чтобы все входящие запросы шли в зелёную операционную среду — синяя в режиме ожидания.
Сине-зелёный деплой также даёт вам возможность быстро откатиться до старого состояния: если что-то пойдет не так, переключите роутер обратно на синий продакшен. Но вам всё ещё придётся справляться с пропущенными транзакциями, пока зелёный продакшен активен, и, в зависимости от структуры кода, вы сможете направлять транзакции в оба продакшена, чтобы сохранять синий как резервную копию, при активном зелёном. Или можете перевести приложение в read-only режим, перед синхронизацией, запустить его на время в этом режиме, а потом переключить в режим read-write. Этого может оказаться достаточно, чтобы избавиться от многих нерешенных проблем.
Две среды должны быть полностью самостоятельными, но настолько идентичными, насколько возможно. Иногда это могут быть разные компьютеры, иногда просто две виртуальные машины, запущенные одном (или нескольких) компьютерах. Они также могут быть единой операционной средой, разбитой на обособленные зоны с отдельными IP-адресами.
После того, как зелёный продакшен оказывается в работе, и вы довольны его стабильностью, можете использовать синий как staging, чтобы прогнать его через финальные тесты следующего деплоя. Когда вы будете готовы к следующему релизу, сможете переключаться с зеленого на синий так же как переключались с синего на зелёный. В такой конфигурации и зеленый и синий продакшен регулярно проходят через три состояния — действующее приложение, предыдущую версию (для отката) и staging следующей версии.
Преимущество такого подхода в том, что это тот же самый базовый механизм, который нужен для горячего резервирования (hot-standby). Он позволит вам тестировать процедуру аварийного восстановления при каждом релизе. (Надеюсь, что вы релизите чаще, чем у вас происходит аварийное восстановление).
Основная идея в том, чтобы иметь две легко переключаемых среды, а способов изменять детали — множество. Один вариант — делать переключение перезапуском веб-сервера, а не через роутер. Другой — использовать единую базу данных, а сине-зеленые переключения делать для веба и прикладного уровня.
С базами данных при таком подходе часто бывают проблемы, особенно если вам нужно менять их логические структуры для поддержки новой версии софта. Хитрость тут в том, чтобы разделить деплой изменения логических структур и обновление приложения. Для этого сначала нужно применить рефакторинг базы данных, чтобы изменить структуры для поддержки новой и старой версий приложения, задеплоить эти изменения, проверить, что всё хорошо работает, и у вас есть версия предыдущего состояния, и только потом задеплоить новую версию приложения. (А когда обновления уже устаканились, удалить поддержку базы данных для старой версии).
Этот подход существует уже давно, но я не вижу, чтобы его часто использовали. А должны. Название придумали Дан Норс (Dan North) и Джез Хамбл (Jez Humble).
(Перевод Наталии Басс)
Комментарии (12)


RomanVPro
13.09.2016 13:02Трюк с использованием одной базы данных для двух серверов с разными версиями приложения заключается в том, что в новых версиях можно только добавлять новые сущности (колонки, таблицы и т.д.). А удалять старые можно только после того, как все серверы мигрируют на новую версию. При этом ничего не мешает делать это из самого приложения (обновление БД при запуске приложения — Liquibase и т.д.). Недостаток: миграция БД занимает несколько версий приложения.
А вот использование разных баз данных обязательно приведет к вопросу их синхронизации между собой, что опять-таки должно выполняться автоматически. Первый вариант (одна БД — много серверов) выглядит проще и надежнее.

shushu
13.09.2016 14:34Основная идея в том, чтобы иметь две легко переключаемых среды
А что если если серверов много? Достаточно дорогое решение. Ко всему этому 50% мощности всегда простаивает.shushu
13.09.2016 14:51Да и необходимость переводить приложение в read-only режим во время деплоя тоже не очень красивое решение.

osigida
14.09.2016 11:51Большие дядьки, когда серверов много, заменяют по одному контролируя кто из пользователей переключен на новый сервис. canary release называется, опять же у Фаулера почитать можно: http://martinfowler.com/bliki/CanaryRelease.html
что в общем то частный случай blue-green deployemnt-а
Переключать в read-only не нужно и даже вредно, но нужно соблюдать правила backward/forward compatibity.
и снова Фаулер к чтению: http://martinfowler.com/articles/consumerDrivenContracts.html

onyxmaster
14.09.2016 11:51Здесь вам на помощь придёт уменьшение уровня изоляции — виртуальные машины, контейнеры или даже просто изолированные среды исполнения (отдельные application pool в IIS, pool в php-fpm и т.д.).
Например у нас более-менее стандартная схема nginx->haproxy->backend, где в качестве бэкендов выступают IIS, где на каждом сервере есть b/g apppool. Основная нагрузка обрабатывается только одним экземпляром, второй через минуту (в нашем случае) просто выгружается, потому что haproxy не передаёт на него новых запросов. А запас по памяти на бэкенде организовать обычно не проблема.
Maur
13.09.2016 17:22+3Прежде всего хочу сказать спасибо моей жене Клэр, которая сподвигла меня написать это комментарий. Моим друзям Дэну и Стивену что поддерживали меня когда я читал текст перевода. Хочу поблагодарить Натали Басс за оказаный перевод, и особую благодарность Дэйву Фарли (Dave Farley) и Джезу Хамбл (Jez Humble) за незаконченную книгу «Непрерывная доставка», автору неизвестного рисунка с амебами, так же благодарен за то что открыл для меня новый вид технической схемы.
После того как мы пересели на Сине-Зеленый деплой мы увеличили продажи. Вначале мы были настроены скептически, но когда мы собравшись на совещании, Кен (наш ведущий аналитик) неожиданно сказал: «Почему бы нам не попробувать сине-зеленый деплой»? И тут же с жестикуляцией начал объяснять нам, что это то, что нам нужно. Никогда наши совещания не были столь увлекательные. Мы избежали сразу же проблемы с базами данных с маржинколами и перчерсордерами, фьючерсы начали общатся на одном языке с контентменеджерами, а фолоапы почти исчезли.
Спасибо автор за проделаный вами труд. Побольше бы таких статей на хабре!
PS: Спасибо фаулеру за новый паттерн!
kossmak
Кто бы сомневался)
Печаль в том, что со временем все привыкают бояться задорого менять имеющиеся и закостеневшие сущности в БД, без страха только приносят новые.