
Интернет-компании выбирают и тестируют оборудование для дата-центров не только по номинальным спецификациям, поступившим от производителя, но и с учётом реальных продакшен-задач, которые будут выполняться на этом оборудовании. Затем, когда дата-центр уже спроектирован, построен и запущен, проводятся учения — узлы отключают без ведома сервисов и смотрят, насколько они подготовлены к подобной ситуации. Дело в том, что при такой сложной инфраструктуре невозможно добиться полной отказоустойчивости. В каком-то смысле идеальный дата-центр — это тот, который можно отключить без ущерба для сервисов, например для поиска Яндекса.
Руководитель группы экспертизы runtime поиска Олег Фёдоров был в числе докладчиков на большой поисковой встрече Яндекса, которая прошла в начале августа. Он рассказал обо всех основных аспектах проектирования дата-центров под задачи, связанные с обработкой огромных объёмов данных. Под катом — расшифровка и слайды Олега.
Меня зовут Олег, я работаю в Яндексе уже шесть лет. Начинал менеджером в отделе качества поиска, сейчас больше занимаюсь вопросами, связанными с эксплуатацией наших крупных дата-центров — слежу, чтобы наш поиск работал и т. д.
Давайте попробуем умозрительно спроектировать небольшой дата-центр, машинок на 100 тыс., который сможет отвечать поиском, другими сервисами и т. д. Сделаем это очень просто, умозрительно, по верхам.
Вызовы поискового облака. С чем мы сталкиваемся? Какими принципами руководствуемся, когда строим наши большие системы?

Как любой театр начинается с вешалки, дата-центр можно попробовать начать строить с того, на каком процессоре мы будем проектировать наши сервера, на каком оборудовании все это будет работать, сколько его будет и т. д. Для этого попробуем пройти по трем простым шагам. Мы хотим протестировать наше оборудование. Мы хотим посчитать, сколько нам будет стоить владеть таким оборудованием. Мы хотим как-то выбрать оптимальное решение. Картинка для привлечения внимания:
Чтобы в недалеком будущем построить наш дата-центр, выбрать интересный нам процессор и быть готовыми за год-полтора, нужно заранее получить инженерные образцы. Многие из вас это знают, потому что тестировали оборудование до того, как оно появилось на массовом рынке.
Чем будем тестировать? Возьмем типичные для облака задачи, которые будут работать на наших серверах чаще всего: поиск, кусочек индекса, что нам выдача рисует, еще что-то. Возьмем все эти образцы, поищем аномалии.
Был яркий пример: мы взяли модель процессора одного из производителей и у нас очень сильно просело время отрисовки. Сюрприз. Разобрались: действительно, там была проблема с компилятором, но тем не менее аномалия может возникнуть. Другой пример: производитель заявил новый набор SSE-инструкций, мы немножко переписали наш код – стало существенно быстрее. Это некое конкурентное преимущество нашей модели, все хорошо.
Чуть углубимся. Допустим, мы выбрали некий набор процессоров. Вот мои любимые картинки для привлечения внимания. Это у меня недавно iPhone перегрелся.

Географическое расположение. Все мы знаем, что дата-центр можно строить для российской компании в России или не в России — в разных странах, в разных климатических и географических зонах. Например, на экваторе будет жарковато, но можно использовать солнечную электроэнергию. На севере с электричеством будет все сложнее, но зато с охлаждением все очень неплохо и т. д. Везде есть плюсы и минусы.
Нужно будет обязательно подумать об обслуживании нашего дата-центра. Доставлять комплектующие в какой-то холодный район или в какую-нибудь странную страну с непредсказуемым административным ресурсом может быть сложно. Добыть некоторые комплектующие можно будет только с большим трудом и т. д.
Обязательно надо посчитать для каждого нашего набора процессоров всю остальную инфраструктуру. Если мы берем процессор, который выделяет 160 Вт тепла, наверное, нам надо будет думать об охлаждении, понадобится более мощный радиатор, более мощный сервер.
Куда в этом месте идет индустрия? Мы хотим, как и все, охлаждаться забортным воздухом. Брать с улицы воздух температуры за бортом, продувать через наши серверы, получать охлаждение. Таким образом мы добьемся, чтобы на наши конечные вычисления тратилось как можно больше энергии, а на обслуживающую инфраструктуру — как можно меньше.
Многие знают: есть коэффициент PUE, все стремятся к единичке. Допустим, мы посчитали, сколько процессор готов выполнить стандартных операций и примерно прикинули стоимость владения. Я специально зашифровал названия процессоров, это все некие спекулятивные цифры. Какой общий подход? Как правило, все выглядит так, что процессор максимальной производительности начинает немножко вырываться вперед и его условная стоимость владения решением с производительностью на ядро возрастает по экспоненте. Оптимумы живут где-то по дороге.
Из этого правила всегда есть исключение. Мы хотим для некоторых не массовых приложений, где очень критично latency, получить максимальную производительность на ядро. Либо мы хотим что-то быстро в онлайне собирать, рисовать и т. д — мы можем позволить себе взять несколько процентов исключительного оборудования.
Попробуем посмотреть на другие аспекты. У нас очень сложное многомерное пространство: процессор, память, SSD, диски, сеть, ряд неоткрытых измерений. У нас постоянно все расширяется. Обо всем этом приходится думать. Модель сложная, многомерная, интернет потихоньку меняется, меняются наши подходы к поиску. Все это мы закладываем в модель и обязательно просчитываем.
Вторая картинка для привлечения внимания:
Многие, наверное, узнали распределение в реликтовом излучении — так мы пытаемся компьютерно смоделировать, как выглядит наша Вселенная. Данные выглядят примерно так же. Есть очень горячие участки. Например, сайтик «ВКонтакте» почему-то все ищут — не знаю, почему. Или каких-то котят. Эти данные очень горячие, часто используемые, их очень хочется положить в память куда-нибудь поближе к процессору и т. д. А есть какие-нибудь драйвера. У меня предыдущий ноутбук уже лет 10 лежит, и для него, под старую Ubuntu, нужны были драйвера. Почему-то ни у кого, кроме меня, этот запрос долгое время не возникал. Я пытался по логам поискать – никто не интересуется. Эти данные, наверное, никому не нужны — положу куда-нибудь подальше, на холодные диски с маленькой сложной репликацией и т. д.
К счастью, у нас всё по экспоненте. Самых горячих данных очень мало, их можно попытаться дотянуть до памяти. А самые неинтересные и ненужные корейские спамерские сайты можно положить куда-то на диски и забыть про них.
Картинка о том, какие сложные бывают требования у различных приложений в нашем облаке. Попробуем немного классифицировать приложения, которые у нас бывают. Есть аналогия: я купил пустой аквариум, хочу туда рыбок запустить, но перед этим там надо красоту навести — камушки крупные положить, зaмки, вот это всё. Кроме того, в аквариуме нужен песок и вода. Если я просто налью воды и только потом начну все размещать, у меня будет грязно, камни будет сложно передвигать и т. д.
Подход такой: выберем приложение в нашем облаке, которое требует какого-то специфического железа, например GPU. Понятно, что GPU поставить в каждый сервер — это мечта, но достаточно дорогостоящая. Разместим наши приложения, требующие специфического железа, на тех серверах, где такое железо есть. Это шаг номер один.
Шаг номер два: возьмем и жестко просеем, простандартизируем наш песок и наши основные приложения — узнаем, сколько памяти они будут потреблять, сколько им нужно процессора, в какое время суток, сколько им нужно сети, как они будут доставлять себе данные и т. д. Четко распланируем и поймем, например, что вот эти приложения — массовые, готовы запускаться где угодно, и важно соблюсти их требования.
Дальше, когда мы сделали некое размещение нашего песка, во все свободные участки зальем наши типичные batch-задачи — задачи машинного обучения. Как мы знаем, ночью большая часть людей в России спит. Поэтому запросов в поиск поступает меньше, высвобождается процессор, и его хотелось бы использовать. Ночь – время расцвета батча, ренессанс различных задач, не так сильно связанных с ответом пользователя.
Следующий шаг. Мы наши приложения напланировали в облаке, но как нам избежать интерференции между ними? Как сделать так, чтобы те волки, которые запланировали себе правильные объемы оперативки и процессора, правильно этот объем потребляли? Как сделать так, чтобы им не вредили бедные невинные овечки, которые ничего потреблять не должны, но у которых произошла некая утечка памяти, взрыв количества запросов, и которые начинают заливать процессором соседние задачи? Нам нужны границы, переборки.
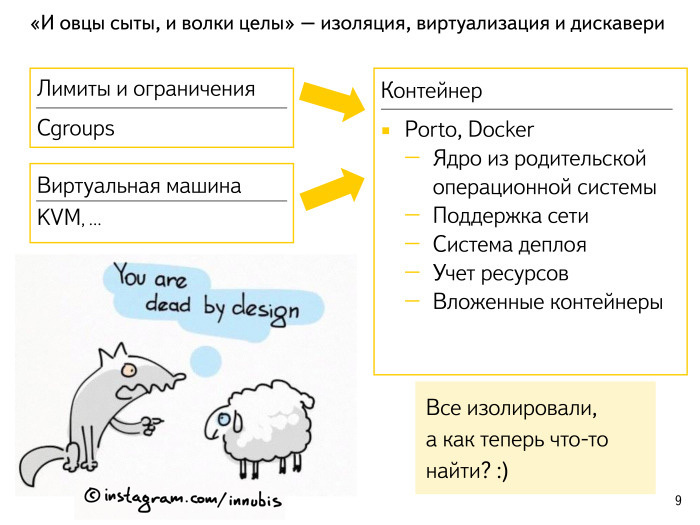
Какие есть подходы в индустрии? Все слышали, а кто-то, у кого ноутбук на Linux, пробовал накрутить, настроить себе cgroups неким образом, чтобы оградить приложение, выставить ему лимиты и чтобы все было более-менее хорошо.
Какой второй распространенный подход? Давайте каждое приложение запустим просто в отдельных виртуалках. Получим накладные расходы, конечно: бесплатно ничего не бывает. Процессора будем потреблять больше, немножко памяти — дело в том, что странички памяти мы иногда будем считать несколько раз. Многие современные решения уже меньше этим болеют, но требуется специфический процессор и т. д.
К чему все приходят? К маленькому тонкому слою — контейнеру, ограждающему приложение.
Когда мы затевали эту историю в нашем облаке, Docker еще не был настолько развит. Его современные обвязки впечатляют — работы было проделано очень много. Мы сделали свою очень похожую штуку. Назвали Porto. Нам хотелось легко управлять сотнями — уже тысячами — приложений: чтобы они друг другу не мешали, чтобы процесс конфигурирования был очень простой и чтобы мы в каком-то смысле описали все лимиты приложения, поняли, как оно будет работать, что ему требуется, где ему нужно хранить данные, какой у этого приложения выделенный IP-адрес. То есть нужно было описать все, что связывает нас с многомерным пространством, запустить этот контейнер и забыть про него.
С другой стороны, с точки зрения самого приложения оно находится практически в виртуальной машине. У него свой маленький chroot, виден не весь процессор и не вся оперативка. Получили плюсы в своей простоте в системе деплоя, получили учет ресурсов. Нам не очень интересно, что приложение делает внутри себя, какие подпрограммы запускает, что делает с данными и т. д. Нам интересно, что происходило вокруг этого приложения, то есть счетчики с контейнера. А в качестве еще одного приятного бонуса мы получили возможность запускать вложенные подконтейнеры. Мы выделили на какую-то задачу или проблему набор ресурсов и дали имя этому контейнеру — всё. Дальше приложение может внутри себя как-то перераспределить пространство и запустить подпрограммы тоже в подконтейнерах, тоже изолированно. В результате получаем нашу прекрасную подводную лодку, где каждый отсек изолирован. Если у кого-то где-то утечка, что-то взорвалось, то оно взорвалось только там — локально.
Итак, мы всё заизолировали, всё напланировали в кластеры. А как находить, где работают инстансы приложения?
Как мы решаем задачу дискавери? Есть несколько подходов. Один наиболее типичный: приложение запускается, стучится куда-то в центральную точку, говорит — я здесь, я буду обслуживать такой-то трафик, я такого-то типа, у меня все хорошо. Наш подход очень похож на этот. У нас интеграция с системой мониторинга. Когда система видит, что на машине запущено приложение определенного рода, она у себя сохраняет его некое мета-описание. Когда другие приложения будут после этого искать для себя список бэкендов, они смогут воспользоваться этим описанием.

Всё у нас прекрасно. Мы на подводной лодке, всё заизолировали и т. д. Но тут у нас всё начинает ломаться. Представим себе, что мы работаем в таксопарке. У нас сто такси. Всегда будет так: у одной машины колесо спустили, другую водить никто не может, руль странный и т. д. Несколько машин всегда будет сломано. Надо привыкнуть к тому, что несколько процентов наших приложений — узлов системы — всегда будут сломаны. Это нужно закладывать на этапах расчета репликаций, нагрузок на каждом узле и т. д.
Что может ломаться? Если мы написали не совсем хорошую версию приложения – она, понятное дело, падает. Обрабатывает определенное количество запросов и падает. На тесте не нашли — в облаке увидели. Ломается ОС. Возьмем новый супер-секьюрити апдейт, ни на что в рантайме не влияющий. Выпустим его — приложения начнут падать, потому что мы что-то задели в ядре. Будет ломаться наш сервер. Он в аптайме работал два года, все было замечательно, но начала теряться оперативка, стали выпадать диски и т. д.
Сервера в дата-центре стоят в стойках. К стойке централизованно подводится питание, локально подводится сеть, несколько жил. Это все может отказать, сломаться. Надо быть готовым к тому, что ломается стойка целиком. Надо критически важные части нашего индекса или приложения, которых не очень много запущено у нас в облаке, не селить в одну стойку, а хранить максимально размазанно.
Стойки, несколько десятков или сотен, объединяются в модули. Образуется некий пожаробезопасный кусочек дата-центра, чтобы в случае неисправности пострадал не весь дата-центр, а можно было модуль заизолировать.
Но и целиком, бывает, ломается дата-центр. Как вы думаете, в какое время года чаще всего по сети отваливаются дата-центры и страдают каналы связи?
— …
— Почему весна? Нет, современная оптика отлично расширяется и сужается. Весна — правильно, но почему? Посевная. Просыпается сельскохозяйственная отрасль, начинает сносить оптику в тех местах, где ее нет. Просыпаются строители и начинают делать ту работу, которую зимой делать не могли. Весной каналы связи страдают и т. д.
Давайте попробуем расклассифицировать проблемы нашей аварии. Вот ребята уронили спутник на пол, беда.

Сломались у нас один-два процента наших узлов, оборудования, чего бы то ни было. Это рутинная задача: в нашем таксопарке одна-две-три машины всегда будут стоять на приколе, надо быть к этому готовыми.
Серьезная проблема — это когда у нас 5-7% узлов вышли из строя. Наверное, какой-нибудь релиз инфраструктурного компонента пошел не так, как мы рассчитывали. Может быть, мы что-то сломали в сети, может, в чем-то другом. В такой проблеме надо разбираться, но она не критическая — наши сервисы продолжают работать, именно в этом фрагменте нашей инфраструктуры все хорошо.
Катастрофа — когда из строя вышли 15-20% узлов. Тут уже явно что-то пошло не так, уже нет смысла релизить программы, что-то выкатывать, переконфигурировать. Надо снимать нагрузку, предпринимать более активные действия. Это не жизнеспособная ситуация. Наверное, многим знаком такой подход.
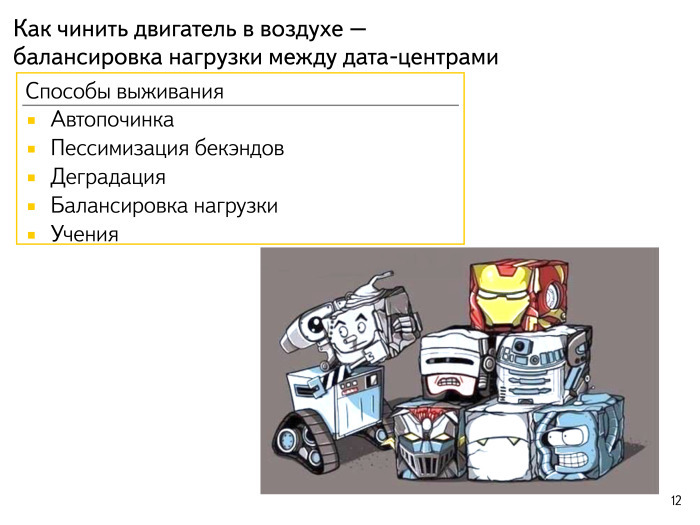
Что в таких случаях можно делать? Начнем с простого. У нас ломаются машинки. Они могут ломаться просто программно. Завис сервер. Надо уметь это детектировать, уметь пробовать общаться с этим сервером по IPMI, чтобы что-то с ним сделать. Мы работу наших систем мониторинга, обнаружения неисправностей и попытки исправить, написать заявку в дата-центре представляем как мультик про робота WALL-E. Такие роботы ездят по кластеру, всё пытаются починить и в некую центральную точку сообщают о том, что у нас происходит. Итак, первый подход — автопочинка.
Как еще можно бороться с тем, что все все время ломается? Есть пессимизация бэкендов. Предположим, у нас есть приложение А, оно ходит в 10 бэкендов приложений В. Один из бэкендов вдруг начинает отвечать ощутимо медленнее, на 100 мс. Мы можем спокойно запессимизировать этот бэкенд, начать задавать в него сильно гораздо запросов — продолжать задавать, чтобы мониторить его состояние, но перевести запросы на оставшиеся живые-здоровые 9 бэкендов. Ничего не произойдет – все хорошо. Мы учим наши приложения быть аккуратными, уметь понимать, что под нами бэкенд и что у него что-то случилось.
Вот другой подход. Приложение А стало в приложение В слать трафика в разы больше, чем мы рассчитывали. Удобно уметь отключать часть своей функциональности и начинать отвечать, может, еще вполне корректно, но гораздо более низкозатратно с точки зрения CPU. Например, чуть менее глубоко искать, если говорим о поиске. Мы не 1000 документов поднимаем, а 900, потихоньку отодвигаем границу. Это вроде незаметно, но мы существенно увеличиваем свою пропускную способность в тот момент, когда нам это действительно нужно. Это деградация.
Когда серьезная катастрофа уже случилась, понятный шаг — отбалансировать, увести нагрузку. Любой узел, включая весь дата-центр, мы должны уметь изолировать. Может потребоваться увести оттуда трафик и затем увести узел на обслуживание, чтобы что-то с ним сделать.
Как понять, что все наши приложения умеют, работают и спроектированы по этой схеме? Нужно регулярно проводить учения: отключать узлы, отключать большое количество серверов, отключать дата-центры. Это должно происходить неожиданно для команд этих приложений — чтобы не было историй, будто мы манипулируем нагрузкой или еще чем-то. Это должна быть честная нормальная авария, но с возможностью быстро вернуть все в первоначальное состояние. Мы не ждем, когда наступит весна и нам экскаватором переедут один из каналов. Мы его отключим сами и посмотрим, что произойдет. Разрезаем свою инфраструктуру — смотрим, что получается.

Хьюстон, у нас проблема. Мы диагностировали проблему до состояния, когда это уже не рутина, а именно проблема — 5-7% или катастрофа. С этим обязательно надо разбираться. На что смотрят типичные инженеры поиска? Не идет ли сейчас какой-то релиз или запуск? Наверное, если приложение сутками, неделями работало хорошо и все было прекрасно, а сейчас вдруг, в час дня, просело время ответа, то что-то поменялось. Вероятно, состоялся релиз, запуск.
На что мы стараемся смотреть? Для меня наиболее типичной, крупной для поиска показательной частью является количество запросов. Казалось бы, в каждый момент времени в течение дня можно предсказать, сколько запросов нам зададут. Вчера в 8:30 и сегодня в 8:30 количество запросов будет примерно одинаковым. Если же их будет на 20% меньше — наверное, что-то пошло не так.
Время ответа. Мы всегда во всех компонентах обязательно должны писать, сколько заняла поисковая стадия, сколько мы обрабатывали запрос и т. д. Смотрим на все эти аномалии, агрегируем, смотрим на определенные квантили.
Качество поиска. Безусловно, пользователи нам постоянно задают миллионы запросов. Мы сами себе задаем запросы, сами смотрим выдачу, в автоматическом режиме ее разбираем, анализируем и смотрим, насколько она близка к тому, что мы считаем эталоном.
Интересным показателем в последние годы стало распределение по браузерам. Много стало различных браузеров. От истории с Netscape Navigator, когда практически нечем было пользоваться, давно ушли. Появились браузеры в мобильных. Мы смотрим, что у нас происходит в каждом отдельном браузере. Возрастает ли количество запросов? За сколько мы отвечаем? Что интересует пользователей, какие тематики? И т. д.
Вот один из недавних случаев. У мобильного ВКонтакте были технические неполадки и было хорошо видно, как увеличилось количество запросов. Время никак не изменилось, почти не поменялось качество, но было видно, что выросло число запросов в мобильных браузерах. Легко нашли, разобрались и т. д.
Еще пример из недавнего прошлого. 15 июля вечером было крупное новостное событие в Турции, политическая ситуация. Не будем сейчас вдаваться в подробности. Нам интересно, как это на интернете сказалось. Люди начали активно что-то искать. Голубая линия показывает, что происходило в это время неделю назад, а темно-синяя — что происходило в текущий момент времени. Мы видим резкий всплеск интереса — в мире что-то произошло.
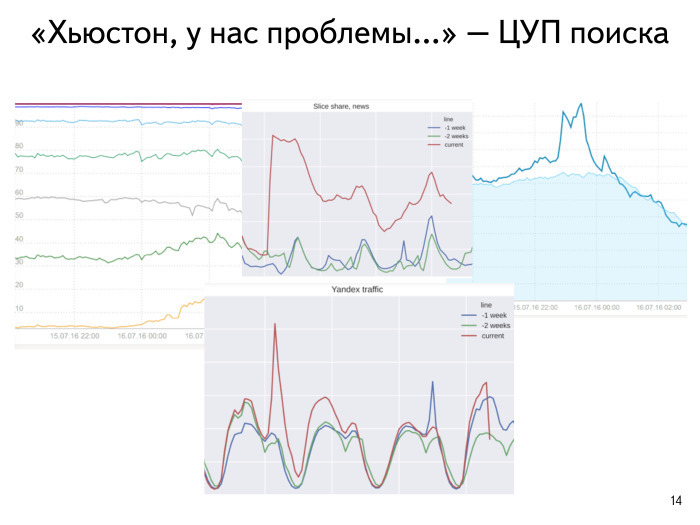
Смотрим наш типичный график времен ответа. Время ответа мы очень любим смотреть квантилями: нарезаем себе разными цветами 100 мс, 200 мс и т. д. Видим, что в смысле времени ответа за указанный промежуток времени ничего не случилось. А вот наша трафик-генерация на масштабе дня. Что было неделю или две назад, мы тоже видим. Простым аналитическим способом мы поняли, что это внешнее событие. Затем, как и все, пошли смотреть новости. Увидели, что происходит.
Я добавил коллег, с которыми работаю каждый день. У нас в поиске есть такая парадигма: мы в любой момент времени можем спрогнозировать, что мы хотим построить такой-то ДЦ, потратить определенное количество денег, купить кучу оборудования, но за короткий промежуток времени клевую, интересную, хорошую команду мы собрать не сможем. Поэтому главная ценность — вот, добавил.
Итак, мы по верхам спроектировали наш дата-центр, заселили его приложениями, разделили их, заизолировали, нашли их все, поняли, что туда должны смотреть люди, поняли, что нам нужен мониторинг и что в этом ключе нужно делать.
Зритель:
— У вас показатели мониторятся автоматизировано или сидят специально обученные люди, которые смотрят за графиками?
Олег:
— Конечно, все автоматизировано. Мы получаем уведомление, после этого можем пойти и посмотреть, проблема это или катастрофа в каком-то смысле.
Андрей Стыскин, руководитель управления поисковых продуктов Яндекса:
— Но сложность задачи там достаточно интересная, много скоррелированных показателей. Если увеличивается температура — возможно, поток запросов вырос, перераспределилась нагрузка. Там сложно быстро узнать и локализовать проблему, в этом некое творчество есть. Но обнаружить, что что-то идет не в стационарном режиме — достаточно простая задача.
Зритель:
— Денис, компания Startup Makers. Два года назад Google выпустила свое open source solution — Kubernetes. Оно очень похоже на Porto. Смотрели на это решение?
Олег:
— Конечно, мы постоянно вдохновляемся тем, что делают коллеги. Смотрим и уже с оглядкой проектируем свои решения. Плюс немножко подумываем тоже что-то в этом ключе может быть когда-нибудь заопенсорсить.
Андрей:
— В перерыве мне задали примерно такой же вопрос, но про несколько другой компонент. Действительно, в Яндексе существует большой синдром NIH — not invented here. Это происходит не потому что мы такие самодуры, а потому что нам приходится находить решения к задачам, которые параллельно решают западные или другие передовые компании. И они пока не успевают выложить свои решения в open source к тому моменту, когда они нам нужны в готовом виде.
Porto мы начали разрабатывать и написали под него обширную обвязку — конечно, несовместимую с Docker. Хотя там много чего прикольного сделано.
Зритель:
— Docker сейчас не единственный.
Андрей:
— Да, имеется в виду, что есть очень много крутой обвязки, которую мы хотели бы брать и применять, у себя не писать. Но мы так много сделали, и так много нам нужно было сделать много лет назад, когда ничего еще не было, что у нас теперь хватает собственных проприетарных решений — не совместимых с open source.
Зритель:
— Вопрос не в том, почему не используете Kubernetes. Наоборот, молодцы, и будет здорово, если получится лучше, чем у Google. Service discovery — не совсем раскрыта тема. Когда появляются контейнеры, эти поды, некая группа, некий онлайн — куда они дальше стучатся? Я так понимаю, там не какое-то etcd-хранилище, key value, а что-то свое сделано?
Олег:
— Нам больше нравится подход, когда система мониторинга находит такой контейнер, потому что все равно хочет мониторить там приложение и т. д. И заодно — собирает мета-данные, узнает, что за приложение там запущено, агрегирует и дает другим приложениям возможность находить исходное. Немножко обратный подход — не push, а call.
Зритель:
— Да, по метрикам реверс получается. Сейчас метрик по конкретным контейнерам вроде не так много. Это как-то у вас расширяется? Механизм расширения этого предусмотрен?
Олег:
— По контейнерам сотни метрик. Часто используемых — около десятка. Но в целом это очень кастомизированная система.
Зритель:
— У Kubernetes есть Kube Dash, много решений, которые позволяют легко что-нибудь развернуть у себя. И оно работает. На CoreOS, допустим, поставил. А какие-то UI-решения для облаков, для AWS и прочих, у вас собираются в общество выводить, соединять с комьюнити?
Олег:
— Хороший вопрос, спасибо. Смотрите, чуть в историю. У нас некий аналог закона Мура: вообще за историю Яндекса в прошлом каждый раз, когда количество серверов на порядок возрастает и мы берем новую задачу и понимаем, что нам будет интересно, мы каждый раз начинаем перепроектировать свою систему деплоя и всего остального. Потому что накапливаем существующие минусы.
В UI некий прогресс тоже налицо. Понятно, что, когда у нас есть сто запущенных приложений, очень легко написать UI и следить за ними всеми. А вот когда у нас есть 100 млн запущенных приложений, то уже возникает проблема, как их единоразово показать, сагрегировать, чтобы ничего не тормозило. Это каждый раз меняется.
Относительно планов вывести в люди — боюсь, конкретные сроки не могу назвать.
Андрей:
— Сроки не можем назвать, но спасибо правительству нашей страны. Оно нас подталкивает к таким решениям и говорит: «А давайте вы, все западные компании, будете хоститься в России?» Конечно, у нас есть планы сделать доступные облака в России на нашем железе, на наших дата-центрах, и немного монетизировать остатки мощностей, которые у нас есть.
Зритель:
— Это очень ожидаемо, хотелось бы увидеть.
Андрей:
— В стране самая дешевая в мире ожидаемая электроэнергия. Система, которая занимается деплоем, называется у нас «Няня».
Зритель:
— Данил, выпускник МАИ. Вопрос ближе к риторическому. Вы всегда говорите, что надо быть готовым, что система будет ломаться, и надо быть готовым к починке. У вас есть различные методы для исправления различных поломок. Можно ли и нужно ли стремиться к тому, чтобы ничего не ломалось относительно внутренних причин — не считая внешних?
Олег:
— Конечно, на всех этапах нужно тщательно тестировать оборудование до ввода его в эксплуатацию. Нужно лучше тестировать свои приложения, необходим более тщательный подход с семплами для тестирования и т. д. Конечно, надо улучшать показатели.
Андрей:
— Но ломаться все равно будет.
Олег:
— Из тысячи серверов один сломанный можно починить руками. Из ста тысяч серверов тысячу сломанных будет сложно починить руками и одним инженером. Из миллиона серверов… ну, и т. д.
Зритель:
— То есть в будущем нельзя будет сказать, что от этого можно спокойно защититься?
Олег:
— Можно стараться уменьшать показатели, но рассчитывать на это не нужно.
Зритель:
— Ярослав Нечаев, Фонд Бруно Кесслера. Про Porto. Большой ли overhead у Porto и дорого ли обходятся все эти фичи вроде вложенных контейнеров, изоляции?
Олег:
— В этом ключе Porto очень похож, это в каком-то смысле cgroups на стероидах. Какой пак дают cgroups — столько же примерно дает и Porto.
Зритель:
— Алексей Ушаровскоий, «Сбербанк Технологии». Вы упомянули учения. Можете рассказать подробнее, насколько они эффективны, что они из себя представляют? Я правильно понимаю, что учения — это когда вдруг срабатывает пожарная сирена, весь дата-центр спускается вниз, после чего возвращается к себе на места?
Олег:
— Это скорее как плановая посевная. Мы выбираем независимо себе участок инфраструктуры, который мы будем сами себе ломать, с тем небольшим условием, что мы можем очень быстро вернуть его в рабочее состояние. От реальных поломок учения отличаются только этим.
Дальше мы смотрим, как ведут себя наши приложения, крупные проекты и т. д. У нас есть набор запланированных работ, во время которых мы смотрим, как мы деградируем в случае отказа каких-то частей нашей инфраструктуры.
Андрей:
— Здесь есть интересный и важный момент. Например, когда мы эмулируем перерубание кабеля с дата-центром и происходят учения для всех сервисов — а в данном дата-центре в текущий момент можно поменять диски, еще что-то сделать… Так вот, все это синхронизовано с плановыми работами по апгрейду машинок в дата-центрах и позволяет получить информацию, что, скажем, сервис Яндекс.Музыка не переживает отключение одного дата-центра. После этого в нем надо запланировать инфраструктурные изменения.
Олег:
— Наши коллеги из НОК, операторы сети, очень любят совмещать свои работы с нашими учениями. Потому что некоторые железки, которые работают 24/7/365, очень удобно вывести на какое-то время из эксплуатации. Затем можно произвести какие-то обновления. Это еще один существенный фрагмент сетевой инфраструктуры.
Зритель:
— Владимир Цитис. При анализе диагностики неисправностей Яндекс пользуется исключительно естественным интеллектом или есть какие-то инструменты на базе искусственного интеллекта?
Олег:
— Хороший вопрос. Каждый наш узел мониторится: как приложение, так и мы стараемся мониторить наше железо. Предположим, какой-то показатель вышел за граничные условия, что-то происходит не так. И есть некая умная агрегация: если у нас в какой-то части дата-центра на 90% серверов выросла температура, то, наверное, это не 90% серверов сломалось и у них какой-то перегрев, а что-то не так с охлаждением в этом кусочке. Мы производим такого рода анализ.
Андрей:
— Искусственный интеллект — это термин для маркетологов. В реальности, конечно, существуют процессы, которые занимаются следующим: есть стационарное поведение какой-то компоненты, и можно обучиться на том, что это стационарное поведение, а все, что на него не похоже, — какая-то проблема, о которой нужно сигнализировать. И эта задача — она в каком-то смысле из области машинного обучения. У нас есть компонента, которая называется «разладки». Она умеет эти стационарные процессы предугадывать, обучаться на них. В какой-то мере у нас есть искусственный интеллект, но мы же понимаем, что это всего-то несколько тысяч строк кода.
Олег:
— Вспомнил хардварный случай. Была модель того, как набор приложений, запущенных на сервере, влияет на время жизни SSD этого сервера. Хорошая задачка машинного обучения: предсказать, когда SSD накроется — то есть когда данных запишется больше, чем нужно, — в зависимости от того, что мы туда селим.
Зритель:
— Алексей Старцев, «Релевант Медиа». Примерно какая доля человеческого фактора влияет на все критические ситуации, возникающие в Яндексе?
Олег:
— На моей памяти были интересные истории с человеческим фактором. Но все-таки мы практически во всех местах стараемся сделать так, чтобы действия человека могли привести к катастрофе только в одном отдельно взятом месте — чтобы нельзя было легко и удобно из одной консоли последовательно потрогать все инфраструктуры одного рода. Все это должно происходить очень локально — в одном ДЦ, в одном месте и т. д.
Да, в основном ошибаются люди, а не роботы, известный факт. Доля — скажем, 50% внешних факторов, природных или посевных, и, может, 50% внутренних действий.
Руководитель группы экспертизы runtime поиска Олег Фёдоров был в числе докладчиков на большой поисковой встрече Яндекса, которая прошла в начале августа. Он рассказал обо всех основных аспектах проектирования дата-центров под задачи, связанные с обработкой огромных объёмов данных. Под катом — расшифровка и слайды Олега.
Меня зовут Олег, я работаю в Яндексе уже шесть лет. Начинал менеджером в отделе качества поиска, сейчас больше занимаюсь вопросами, связанными с эксплуатацией наших крупных дата-центров — слежу, чтобы наш поиск работал и т. д.
Давайте попробуем умозрительно спроектировать небольшой дата-центр, машинок на 100 тыс., который сможет отвечать поиском, другими сервисами и т. д. Сделаем это очень просто, умозрительно, по верхам.
Вызовы поискового облака. С чем мы сталкиваемся? Какими принципами руководствуемся, когда строим наши большие системы?
Как любой театр начинается с вешалки, дата-центр можно попробовать начать строить с того, на каком процессоре мы будем проектировать наши сервера, на каком оборудовании все это будет работать, сколько его будет и т. д. Для этого попробуем пройти по трем простым шагам. Мы хотим протестировать наше оборудование. Мы хотим посчитать, сколько нам будет стоить владеть таким оборудованием. Мы хотим как-то выбрать оптимальное решение. Картинка для привлечения внимания:
Чтобы в недалеком будущем построить наш дата-центр, выбрать интересный нам процессор и быть готовыми за год-полтора, нужно заранее получить инженерные образцы. Многие из вас это знают, потому что тестировали оборудование до того, как оно появилось на массовом рынке.
Чем будем тестировать? Возьмем типичные для облака задачи, которые будут работать на наших серверах чаще всего: поиск, кусочек индекса, что нам выдача рисует, еще что-то. Возьмем все эти образцы, поищем аномалии.
Был яркий пример: мы взяли модель процессора одного из производителей и у нас очень сильно просело время отрисовки. Сюрприз. Разобрались: действительно, там была проблема с компилятором, но тем не менее аномалия может возникнуть. Другой пример: производитель заявил новый набор SSE-инструкций, мы немножко переписали наш код – стало существенно быстрее. Это некое конкурентное преимущество нашей модели, все хорошо.
Чуть углубимся. Допустим, мы выбрали некий набор процессоров. Вот мои любимые картинки для привлечения внимания. Это у меня недавно iPhone перегрелся.
Географическое расположение. Все мы знаем, что дата-центр можно строить для российской компании в России или не в России — в разных странах, в разных климатических и географических зонах. Например, на экваторе будет жарковато, но можно использовать солнечную электроэнергию. На севере с электричеством будет все сложнее, но зато с охлаждением все очень неплохо и т. д. Везде есть плюсы и минусы.
Нужно будет обязательно подумать об обслуживании нашего дата-центра. Доставлять комплектующие в какой-то холодный район или в какую-нибудь странную страну с непредсказуемым административным ресурсом может быть сложно. Добыть некоторые комплектующие можно будет только с большим трудом и т. д.
Обязательно надо посчитать для каждого нашего набора процессоров всю остальную инфраструктуру. Если мы берем процессор, который выделяет 160 Вт тепла, наверное, нам надо будет думать об охлаждении, понадобится более мощный радиатор, более мощный сервер.
Куда в этом месте идет индустрия? Мы хотим, как и все, охлаждаться забортным воздухом. Брать с улицы воздух температуры за бортом, продувать через наши серверы, получать охлаждение. Таким образом мы добьемся, чтобы на наши конечные вычисления тратилось как можно больше энергии, а на обслуживающую инфраструктуру — как можно меньше.
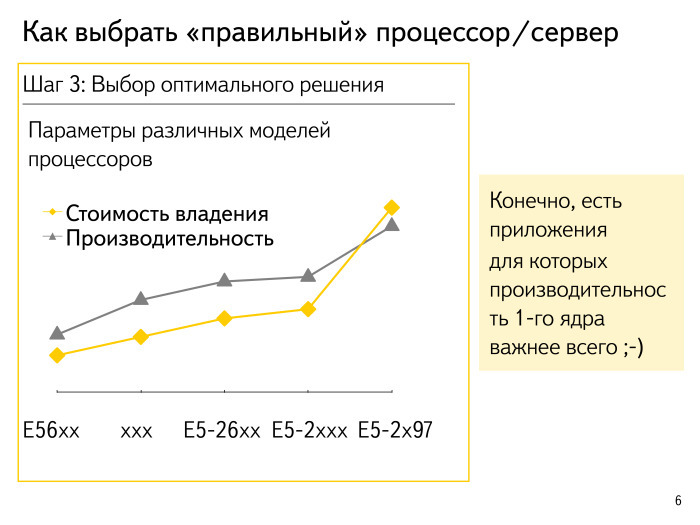
Многие знают: есть коэффициент PUE, все стремятся к единичке. Допустим, мы посчитали, сколько процессор готов выполнить стандартных операций и примерно прикинули стоимость владения. Я специально зашифровал названия процессоров, это все некие спекулятивные цифры. Какой общий подход? Как правило, все выглядит так, что процессор максимальной производительности начинает немножко вырываться вперед и его условная стоимость владения решением с производительностью на ядро возрастает по экспоненте. Оптимумы живут где-то по дороге.
Из этого правила всегда есть исключение. Мы хотим для некоторых не массовых приложений, где очень критично latency, получить максимальную производительность на ядро. Либо мы хотим что-то быстро в онлайне собирать, рисовать и т. д — мы можем позволить себе взять несколько процентов исключительного оборудования.
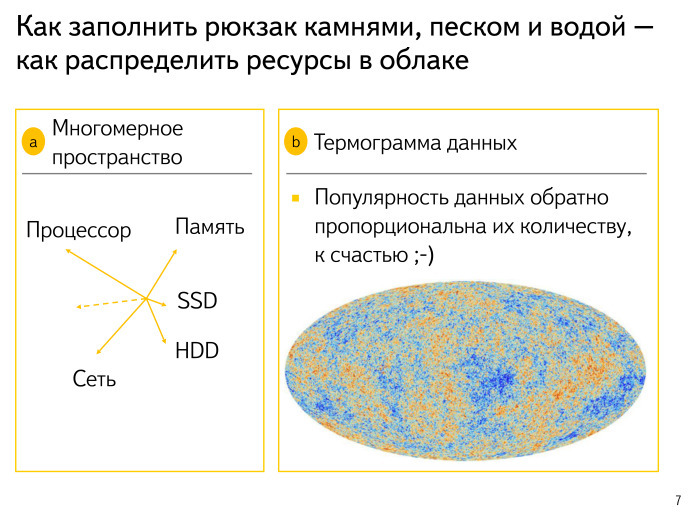
Попробуем посмотреть на другие аспекты. У нас очень сложное многомерное пространство: процессор, память, SSD, диски, сеть, ряд неоткрытых измерений. У нас постоянно все расширяется. Обо всем этом приходится думать. Модель сложная, многомерная, интернет потихоньку меняется, меняются наши подходы к поиску. Все это мы закладываем в модель и обязательно просчитываем.
Вторая картинка для привлечения внимания:
Многие, наверное, узнали распределение в реликтовом излучении — так мы пытаемся компьютерно смоделировать, как выглядит наша Вселенная. Данные выглядят примерно так же. Есть очень горячие участки. Например, сайтик «ВКонтакте» почему-то все ищут — не знаю, почему. Или каких-то котят. Эти данные очень горячие, часто используемые, их очень хочется положить в память куда-нибудь поближе к процессору и т. д. А есть какие-нибудь драйвера. У меня предыдущий ноутбук уже лет 10 лежит, и для него, под старую Ubuntu, нужны были драйвера. Почему-то ни у кого, кроме меня, этот запрос долгое время не возникал. Я пытался по логам поискать – никто не интересуется. Эти данные, наверное, никому не нужны — положу куда-нибудь подальше, на холодные диски с маленькой сложной репликацией и т. д.
К счастью, у нас всё по экспоненте. Самых горячих данных очень мало, их можно попытаться дотянуть до памяти. А самые неинтересные и ненужные корейские спамерские сайты можно положить куда-то на диски и забыть про них.
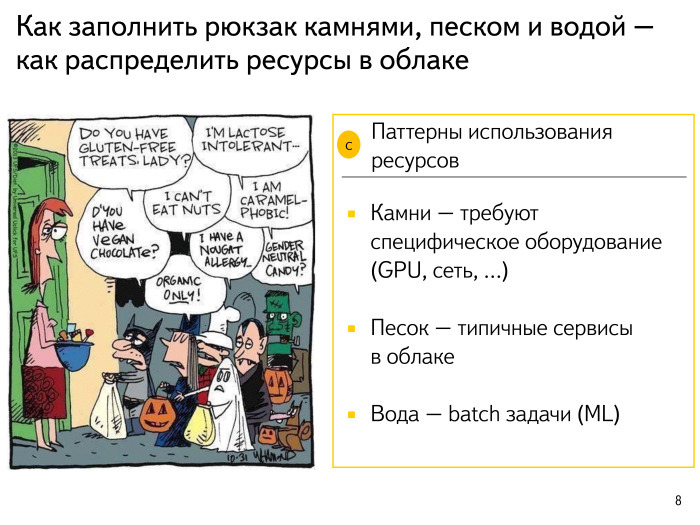
Картинка о том, какие сложные бывают требования у различных приложений в нашем облаке. Попробуем немного классифицировать приложения, которые у нас бывают. Есть аналогия: я купил пустой аквариум, хочу туда рыбок запустить, но перед этим там надо красоту навести — камушки крупные положить, зaмки, вот это всё. Кроме того, в аквариуме нужен песок и вода. Если я просто налью воды и только потом начну все размещать, у меня будет грязно, камни будет сложно передвигать и т. д.
Подход такой: выберем приложение в нашем облаке, которое требует какого-то специфического железа, например GPU. Понятно, что GPU поставить в каждый сервер — это мечта, но достаточно дорогостоящая. Разместим наши приложения, требующие специфического железа, на тех серверах, где такое железо есть. Это шаг номер один.
Шаг номер два: возьмем и жестко просеем, простандартизируем наш песок и наши основные приложения — узнаем, сколько памяти они будут потреблять, сколько им нужно процессора, в какое время суток, сколько им нужно сети, как они будут доставлять себе данные и т. д. Четко распланируем и поймем, например, что вот эти приложения — массовые, готовы запускаться где угодно, и важно соблюсти их требования.
Дальше, когда мы сделали некое размещение нашего песка, во все свободные участки зальем наши типичные batch-задачи — задачи машинного обучения. Как мы знаем, ночью большая часть людей в России спит. Поэтому запросов в поиск поступает меньше, высвобождается процессор, и его хотелось бы использовать. Ночь – время расцвета батча, ренессанс различных задач, не так сильно связанных с ответом пользователя.
Следующий шаг. Мы наши приложения напланировали в облаке, но как нам избежать интерференции между ними? Как сделать так, чтобы те волки, которые запланировали себе правильные объемы оперативки и процессора, правильно этот объем потребляли? Как сделать так, чтобы им не вредили бедные невинные овечки, которые ничего потреблять не должны, но у которых произошла некая утечка памяти, взрыв количества запросов, и которые начинают заливать процессором соседние задачи? Нам нужны границы, переборки.
Какие есть подходы в индустрии? Все слышали, а кто-то, у кого ноутбук на Linux, пробовал накрутить, настроить себе cgroups неким образом, чтобы оградить приложение, выставить ему лимиты и чтобы все было более-менее хорошо.
Какой второй распространенный подход? Давайте каждое приложение запустим просто в отдельных виртуалках. Получим накладные расходы, конечно: бесплатно ничего не бывает. Процессора будем потреблять больше, немножко памяти — дело в том, что странички памяти мы иногда будем считать несколько раз. Многие современные решения уже меньше этим болеют, но требуется специфический процессор и т. д.
К чему все приходят? К маленькому тонкому слою — контейнеру, ограждающему приложение.
Когда мы затевали эту историю в нашем облаке, Docker еще не был настолько развит. Его современные обвязки впечатляют — работы было проделано очень много. Мы сделали свою очень похожую штуку. Назвали Porto. Нам хотелось легко управлять сотнями — уже тысячами — приложений: чтобы они друг другу не мешали, чтобы процесс конфигурирования был очень простой и чтобы мы в каком-то смысле описали все лимиты приложения, поняли, как оно будет работать, что ему требуется, где ему нужно хранить данные, какой у этого приложения выделенный IP-адрес. То есть нужно было описать все, что связывает нас с многомерным пространством, запустить этот контейнер и забыть про него.
С другой стороны, с точки зрения самого приложения оно находится практически в виртуальной машине. У него свой маленький chroot, виден не весь процессор и не вся оперативка. Получили плюсы в своей простоте в системе деплоя, получили учет ресурсов. Нам не очень интересно, что приложение делает внутри себя, какие подпрограммы запускает, что делает с данными и т. д. Нам интересно, что происходило вокруг этого приложения, то есть счетчики с контейнера. А в качестве еще одного приятного бонуса мы получили возможность запускать вложенные подконтейнеры. Мы выделили на какую-то задачу или проблему набор ресурсов и дали имя этому контейнеру — всё. Дальше приложение может внутри себя как-то перераспределить пространство и запустить подпрограммы тоже в подконтейнерах, тоже изолированно. В результате получаем нашу прекрасную подводную лодку, где каждый отсек изолирован. Если у кого-то где-то утечка, что-то взорвалось, то оно взорвалось только там — локально.
Итак, мы всё заизолировали, всё напланировали в кластеры. А как находить, где работают инстансы приложения?
Как мы решаем задачу дискавери? Есть несколько подходов. Один наиболее типичный: приложение запускается, стучится куда-то в центральную точку, говорит — я здесь, я буду обслуживать такой-то трафик, я такого-то типа, у меня все хорошо. Наш подход очень похож на этот. У нас интеграция с системой мониторинга. Когда система видит, что на машине запущено приложение определенного рода, она у себя сохраняет его некое мета-описание. Когда другие приложения будут после этого искать для себя список бэкендов, они смогут воспользоваться этим описанием.
Всё у нас прекрасно. Мы на подводной лодке, всё заизолировали и т. д. Но тут у нас всё начинает ломаться. Представим себе, что мы работаем в таксопарке. У нас сто такси. Всегда будет так: у одной машины колесо спустили, другую водить никто не может, руль странный и т. д. Несколько машин всегда будет сломано. Надо привыкнуть к тому, что несколько процентов наших приложений — узлов системы — всегда будут сломаны. Это нужно закладывать на этапах расчета репликаций, нагрузок на каждом узле и т. д.
Что может ломаться? Если мы написали не совсем хорошую версию приложения – она, понятное дело, падает. Обрабатывает определенное количество запросов и падает. На тесте не нашли — в облаке увидели. Ломается ОС. Возьмем новый супер-секьюрити апдейт, ни на что в рантайме не влияющий. Выпустим его — приложения начнут падать, потому что мы что-то задели в ядре. Будет ломаться наш сервер. Он в аптайме работал два года, все было замечательно, но начала теряться оперативка, стали выпадать диски и т. д.
Сервера в дата-центре стоят в стойках. К стойке централизованно подводится питание, локально подводится сеть, несколько жил. Это все может отказать, сломаться. Надо быть готовым к тому, что ломается стойка целиком. Надо критически важные части нашего индекса или приложения, которых не очень много запущено у нас в облаке, не селить в одну стойку, а хранить максимально размазанно.
Стойки, несколько десятков или сотен, объединяются в модули. Образуется некий пожаробезопасный кусочек дата-центра, чтобы в случае неисправности пострадал не весь дата-центр, а можно было модуль заизолировать.
Но и целиком, бывает, ломается дата-центр. Как вы думаете, в какое время года чаще всего по сети отваливаются дата-центры и страдают каналы связи?
— …
— Почему весна? Нет, современная оптика отлично расширяется и сужается. Весна — правильно, но почему? Посевная. Просыпается сельскохозяйственная отрасль, начинает сносить оптику в тех местах, где ее нет. Просыпаются строители и начинают делать ту работу, которую зимой делать не могли. Весной каналы связи страдают и т. д.
Давайте попробуем расклассифицировать проблемы нашей аварии. Вот ребята уронили спутник на пол, беда.
Сломались у нас один-два процента наших узлов, оборудования, чего бы то ни было. Это рутинная задача: в нашем таксопарке одна-две-три машины всегда будут стоять на приколе, надо быть к этому готовыми.
Серьезная проблема — это когда у нас 5-7% узлов вышли из строя. Наверное, какой-нибудь релиз инфраструктурного компонента пошел не так, как мы рассчитывали. Может быть, мы что-то сломали в сети, может, в чем-то другом. В такой проблеме надо разбираться, но она не критическая — наши сервисы продолжают работать, именно в этом фрагменте нашей инфраструктуры все хорошо.
Катастрофа — когда из строя вышли 15-20% узлов. Тут уже явно что-то пошло не так, уже нет смысла релизить программы, что-то выкатывать, переконфигурировать. Надо снимать нагрузку, предпринимать более активные действия. Это не жизнеспособная ситуация. Наверное, многим знаком такой подход.
Что в таких случаях можно делать? Начнем с простого. У нас ломаются машинки. Они могут ломаться просто программно. Завис сервер. Надо уметь это детектировать, уметь пробовать общаться с этим сервером по IPMI, чтобы что-то с ним сделать. Мы работу наших систем мониторинга, обнаружения неисправностей и попытки исправить, написать заявку в дата-центре представляем как мультик про робота WALL-E. Такие роботы ездят по кластеру, всё пытаются починить и в некую центральную точку сообщают о том, что у нас происходит. Итак, первый подход — автопочинка.
Как еще можно бороться с тем, что все все время ломается? Есть пессимизация бэкендов. Предположим, у нас есть приложение А, оно ходит в 10 бэкендов приложений В. Один из бэкендов вдруг начинает отвечать ощутимо медленнее, на 100 мс. Мы можем спокойно запессимизировать этот бэкенд, начать задавать в него сильно гораздо запросов — продолжать задавать, чтобы мониторить его состояние, но перевести запросы на оставшиеся живые-здоровые 9 бэкендов. Ничего не произойдет – все хорошо. Мы учим наши приложения быть аккуратными, уметь понимать, что под нами бэкенд и что у него что-то случилось.
Вот другой подход. Приложение А стало в приложение В слать трафика в разы больше, чем мы рассчитывали. Удобно уметь отключать часть своей функциональности и начинать отвечать, может, еще вполне корректно, но гораздо более низкозатратно с точки зрения CPU. Например, чуть менее глубоко искать, если говорим о поиске. Мы не 1000 документов поднимаем, а 900, потихоньку отодвигаем границу. Это вроде незаметно, но мы существенно увеличиваем свою пропускную способность в тот момент, когда нам это действительно нужно. Это деградация.
Когда серьезная катастрофа уже случилась, понятный шаг — отбалансировать, увести нагрузку. Любой узел, включая весь дата-центр, мы должны уметь изолировать. Может потребоваться увести оттуда трафик и затем увести узел на обслуживание, чтобы что-то с ним сделать.
Как понять, что все наши приложения умеют, работают и спроектированы по этой схеме? Нужно регулярно проводить учения: отключать узлы, отключать большое количество серверов, отключать дата-центры. Это должно происходить неожиданно для команд этих приложений — чтобы не было историй, будто мы манипулируем нагрузкой или еще чем-то. Это должна быть честная нормальная авария, но с возможностью быстро вернуть все в первоначальное состояние. Мы не ждем, когда наступит весна и нам экскаватором переедут один из каналов. Мы его отключим сами и посмотрим, что произойдет. Разрезаем свою инфраструктуру — смотрим, что получается.
Хьюстон, у нас проблема. Мы диагностировали проблему до состояния, когда это уже не рутина, а именно проблема — 5-7% или катастрофа. С этим обязательно надо разбираться. На что смотрят типичные инженеры поиска? Не идет ли сейчас какой-то релиз или запуск? Наверное, если приложение сутками, неделями работало хорошо и все было прекрасно, а сейчас вдруг, в час дня, просело время ответа, то что-то поменялось. Вероятно, состоялся релиз, запуск.
На что мы стараемся смотреть? Для меня наиболее типичной, крупной для поиска показательной частью является количество запросов. Казалось бы, в каждый момент времени в течение дня можно предсказать, сколько запросов нам зададут. Вчера в 8:30 и сегодня в 8:30 количество запросов будет примерно одинаковым. Если же их будет на 20% меньше — наверное, что-то пошло не так.
Время ответа. Мы всегда во всех компонентах обязательно должны писать, сколько заняла поисковая стадия, сколько мы обрабатывали запрос и т. д. Смотрим на все эти аномалии, агрегируем, смотрим на определенные квантили.
Качество поиска. Безусловно, пользователи нам постоянно задают миллионы запросов. Мы сами себе задаем запросы, сами смотрим выдачу, в автоматическом режиме ее разбираем, анализируем и смотрим, насколько она близка к тому, что мы считаем эталоном.
Интересным показателем в последние годы стало распределение по браузерам. Много стало различных браузеров. От истории с Netscape Navigator, когда практически нечем было пользоваться, давно ушли. Появились браузеры в мобильных. Мы смотрим, что у нас происходит в каждом отдельном браузере. Возрастает ли количество запросов? За сколько мы отвечаем? Что интересует пользователей, какие тематики? И т. д.
Вот один из недавних случаев. У мобильного ВКонтакте были технические неполадки и было хорошо видно, как увеличилось количество запросов. Время никак не изменилось, почти не поменялось качество, но было видно, что выросло число запросов в мобильных браузерах. Легко нашли, разобрались и т. д.
Еще пример из недавнего прошлого. 15 июля вечером было крупное новостное событие в Турции, политическая ситуация. Не будем сейчас вдаваться в подробности. Нам интересно, как это на интернете сказалось. Люди начали активно что-то искать. Голубая линия показывает, что происходило в это время неделю назад, а темно-синяя — что происходило в текущий момент времени. Мы видим резкий всплеск интереса — в мире что-то произошло.
Смотрим наш типичный график времен ответа. Время ответа мы очень любим смотреть квантилями: нарезаем себе разными цветами 100 мс, 200 мс и т. д. Видим, что в смысле времени ответа за указанный промежуток времени ничего не случилось. А вот наша трафик-генерация на масштабе дня. Что было неделю или две назад, мы тоже видим. Простым аналитическим способом мы поняли, что это внешнее событие. Затем, как и все, пошли смотреть новости. Увидели, что происходит.
Я добавил коллег, с которыми работаю каждый день. У нас в поиске есть такая парадигма: мы в любой момент времени можем спрогнозировать, что мы хотим построить такой-то ДЦ, потратить определенное количество денег, купить кучу оборудования, но за короткий промежуток времени клевую, интересную, хорошую команду мы собрать не сможем. Поэтому главная ценность — вот, добавил.
Итак, мы по верхам спроектировали наш дата-центр, заселили его приложениями, разделили их, заизолировали, нашли их все, поняли, что туда должны смотреть люди, поняли, что нам нужен мониторинг и что в этом ключе нужно делать.
Зритель:
— У вас показатели мониторятся автоматизировано или сидят специально обученные люди, которые смотрят за графиками?
Олег:
— Конечно, все автоматизировано. Мы получаем уведомление, после этого можем пойти и посмотреть, проблема это или катастрофа в каком-то смысле.
Андрей Стыскин, руководитель управления поисковых продуктов Яндекса:
— Но сложность задачи там достаточно интересная, много скоррелированных показателей. Если увеличивается температура — возможно, поток запросов вырос, перераспределилась нагрузка. Там сложно быстро узнать и локализовать проблему, в этом некое творчество есть. Но обнаружить, что что-то идет не в стационарном режиме — достаточно простая задача.
Зритель:
— Денис, компания Startup Makers. Два года назад Google выпустила свое open source solution — Kubernetes. Оно очень похоже на Porto. Смотрели на это решение?
Олег:
— Конечно, мы постоянно вдохновляемся тем, что делают коллеги. Смотрим и уже с оглядкой проектируем свои решения. Плюс немножко подумываем тоже что-то в этом ключе может быть когда-нибудь заопенсорсить.
Андрей:
— В перерыве мне задали примерно такой же вопрос, но про несколько другой компонент. Действительно, в Яндексе существует большой синдром NIH — not invented here. Это происходит не потому что мы такие самодуры, а потому что нам приходится находить решения к задачам, которые параллельно решают западные или другие передовые компании. И они пока не успевают выложить свои решения в open source к тому моменту, когда они нам нужны в готовом виде.
Porto мы начали разрабатывать и написали под него обширную обвязку — конечно, несовместимую с Docker. Хотя там много чего прикольного сделано.
Зритель:
— Docker сейчас не единственный.
Андрей:
— Да, имеется в виду, что есть очень много крутой обвязки, которую мы хотели бы брать и применять, у себя не писать. Но мы так много сделали, и так много нам нужно было сделать много лет назад, когда ничего еще не было, что у нас теперь хватает собственных проприетарных решений — не совместимых с open source.
Зритель:
— Вопрос не в том, почему не используете Kubernetes. Наоборот, молодцы, и будет здорово, если получится лучше, чем у Google. Service discovery — не совсем раскрыта тема. Когда появляются контейнеры, эти поды, некая группа, некий онлайн — куда они дальше стучатся? Я так понимаю, там не какое-то etcd-хранилище, key value, а что-то свое сделано?
Олег:
— Нам больше нравится подход, когда система мониторинга находит такой контейнер, потому что все равно хочет мониторить там приложение и т. д. И заодно — собирает мета-данные, узнает, что за приложение там запущено, агрегирует и дает другим приложениям возможность находить исходное. Немножко обратный подход — не push, а call.
Зритель:
— Да, по метрикам реверс получается. Сейчас метрик по конкретным контейнерам вроде не так много. Это как-то у вас расширяется? Механизм расширения этого предусмотрен?
Олег:
— По контейнерам сотни метрик. Часто используемых — около десятка. Но в целом это очень кастомизированная система.
Зритель:
— У Kubernetes есть Kube Dash, много решений, которые позволяют легко что-нибудь развернуть у себя. И оно работает. На CoreOS, допустим, поставил. А какие-то UI-решения для облаков, для AWS и прочих, у вас собираются в общество выводить, соединять с комьюнити?
Олег:
— Хороший вопрос, спасибо. Смотрите, чуть в историю. У нас некий аналог закона Мура: вообще за историю Яндекса в прошлом каждый раз, когда количество серверов на порядок возрастает и мы берем новую задачу и понимаем, что нам будет интересно, мы каждый раз начинаем перепроектировать свою систему деплоя и всего остального. Потому что накапливаем существующие минусы.
В UI некий прогресс тоже налицо. Понятно, что, когда у нас есть сто запущенных приложений, очень легко написать UI и следить за ними всеми. А вот когда у нас есть 100 млн запущенных приложений, то уже возникает проблема, как их единоразово показать, сагрегировать, чтобы ничего не тормозило. Это каждый раз меняется.
Относительно планов вывести в люди — боюсь, конкретные сроки не могу назвать.
Андрей:
— Сроки не можем назвать, но спасибо правительству нашей страны. Оно нас подталкивает к таким решениям и говорит: «А давайте вы, все западные компании, будете хоститься в России?» Конечно, у нас есть планы сделать доступные облака в России на нашем железе, на наших дата-центрах, и немного монетизировать остатки мощностей, которые у нас есть.
Зритель:
— Это очень ожидаемо, хотелось бы увидеть.
Андрей:
— В стране самая дешевая в мире ожидаемая электроэнергия. Система, которая занимается деплоем, называется у нас «Няня».
Зритель:
— Данил, выпускник МАИ. Вопрос ближе к риторическому. Вы всегда говорите, что надо быть готовым, что система будет ломаться, и надо быть готовым к починке. У вас есть различные методы для исправления различных поломок. Можно ли и нужно ли стремиться к тому, чтобы ничего не ломалось относительно внутренних причин — не считая внешних?
Олег:
— Конечно, на всех этапах нужно тщательно тестировать оборудование до ввода его в эксплуатацию. Нужно лучше тестировать свои приложения, необходим более тщательный подход с семплами для тестирования и т. д. Конечно, надо улучшать показатели.
Андрей:
— Но ломаться все равно будет.
Олег:
— Из тысячи серверов один сломанный можно починить руками. Из ста тысяч серверов тысячу сломанных будет сложно починить руками и одним инженером. Из миллиона серверов… ну, и т. д.
Зритель:
— То есть в будущем нельзя будет сказать, что от этого можно спокойно защититься?
Олег:
— Можно стараться уменьшать показатели, но рассчитывать на это не нужно.
Зритель:
— Ярослав Нечаев, Фонд Бруно Кесслера. Про Porto. Большой ли overhead у Porto и дорого ли обходятся все эти фичи вроде вложенных контейнеров, изоляции?
Олег:
— В этом ключе Porto очень похож, это в каком-то смысле cgroups на стероидах. Какой пак дают cgroups — столько же примерно дает и Porto.
Зритель:
— Алексей Ушаровскоий, «Сбербанк Технологии». Вы упомянули учения. Можете рассказать подробнее, насколько они эффективны, что они из себя представляют? Я правильно понимаю, что учения — это когда вдруг срабатывает пожарная сирена, весь дата-центр спускается вниз, после чего возвращается к себе на места?
Олег:
— Это скорее как плановая посевная. Мы выбираем независимо себе участок инфраструктуры, который мы будем сами себе ломать, с тем небольшим условием, что мы можем очень быстро вернуть его в рабочее состояние. От реальных поломок учения отличаются только этим.
Дальше мы смотрим, как ведут себя наши приложения, крупные проекты и т. д. У нас есть набор запланированных работ, во время которых мы смотрим, как мы деградируем в случае отказа каких-то частей нашей инфраструктуры.
Андрей:
— Здесь есть интересный и важный момент. Например, когда мы эмулируем перерубание кабеля с дата-центром и происходят учения для всех сервисов — а в данном дата-центре в текущий момент можно поменять диски, еще что-то сделать… Так вот, все это синхронизовано с плановыми работами по апгрейду машинок в дата-центрах и позволяет получить информацию, что, скажем, сервис Яндекс.Музыка не переживает отключение одного дата-центра. После этого в нем надо запланировать инфраструктурные изменения.
Олег:
— Наши коллеги из НОК, операторы сети, очень любят совмещать свои работы с нашими учениями. Потому что некоторые железки, которые работают 24/7/365, очень удобно вывести на какое-то время из эксплуатации. Затем можно произвести какие-то обновления. Это еще один существенный фрагмент сетевой инфраструктуры.
Зритель:
— Владимир Цитис. При анализе диагностики неисправностей Яндекс пользуется исключительно естественным интеллектом или есть какие-то инструменты на базе искусственного интеллекта?
Олег:
— Хороший вопрос. Каждый наш узел мониторится: как приложение, так и мы стараемся мониторить наше железо. Предположим, какой-то показатель вышел за граничные условия, что-то происходит не так. И есть некая умная агрегация: если у нас в какой-то части дата-центра на 90% серверов выросла температура, то, наверное, это не 90% серверов сломалось и у них какой-то перегрев, а что-то не так с охлаждением в этом кусочке. Мы производим такого рода анализ.
Андрей:
— Искусственный интеллект — это термин для маркетологов. В реальности, конечно, существуют процессы, которые занимаются следующим: есть стационарное поведение какой-то компоненты, и можно обучиться на том, что это стационарное поведение, а все, что на него не похоже, — какая-то проблема, о которой нужно сигнализировать. И эта задача — она в каком-то смысле из области машинного обучения. У нас есть компонента, которая называется «разладки». Она умеет эти стационарные процессы предугадывать, обучаться на них. В какой-то мере у нас есть искусственный интеллект, но мы же понимаем, что это всего-то несколько тысяч строк кода.
Олег:
— Вспомнил хардварный случай. Была модель того, как набор приложений, запущенных на сервере, влияет на время жизни SSD этого сервера. Хорошая задачка машинного обучения: предсказать, когда SSD накроется — то есть когда данных запишется больше, чем нужно, — в зависимости от того, что мы туда селим.
Зритель:
— Алексей Старцев, «Релевант Медиа». Примерно какая доля человеческого фактора влияет на все критические ситуации, возникающие в Яндексе?
Олег:
— На моей памяти были интересные истории с человеческим фактором. Но все-таки мы практически во всех местах стараемся сделать так, чтобы действия человека могли привести к катастрофе только в одном отдельно взятом месте — чтобы нельзя было легко и удобно из одной консоли последовательно потрогать все инфраструктуры одного рода. Все это должно происходить очень локально — в одном ДЦ, в одном месте и т. д.
Да, в основном ошибаются люди, а не роботы, известный факт. Доля — скажем, 50% внешних факторов, природных или посевных, и, может, 50% внутренних действий.
Поделиться с друзьями


azsx
При поиске в yandex, при просмотре исходного кода страницы есть sas. Например, _!-- sas1-5628 -->
Подскажите, пожалуйста, что зашифровано в этой строке?
Aingis
Вероятно, это какая-то информация, имеющая отношение к известному ДЦ Яндекса в Сасово.