

Наверняка почти у каждого есть парочка любимых историй об общении с саппортом компаний, товарами или услугами которых мы пользуемся каждый день. Во многих случаях нас раздражает долгое ожидание ответа и его поверхностное содержание, а проблемы, в свою очередь, редко находят быстрое и действенное решение. Корень этих проблем обычно лежит в организации процессов поддержки.
Бизнес, который предоставляет поддержку и сопровождение своего продукта или сервиса, должен продумать, как это сделать максимально эффективно и удобно. С этой целью многие компании формируют многоуровневую систему саппорта, в которой все общение с клиентом берет на себя технически не сведущий специалист. При этой схеме для любого агента поддержки достаточно минимального набора знаний в технических областях — если потребуется, он сможет перенаправить заявку к нужному “технарю” для продолжения работы по конкретной проблеме (это специфика работы так называемых «колл-центров»). При переходе на другой уровень процесс, как правило, существенно замедляется или даже стопорится. К тому же, дробление поддержки не слишком полезно в плане оптимизации затрат и организационного управления: в общую структуру привносится больше “бюрократии”, качество услуги в целом падает, а затраты возрастают.
Ниже мы расскажем, как с ситуацией справились в Wrike.
Батальоны просят второй фронт
Поддержка компании Wrike, в которой я работаю, первоначально использовала многоуровневую структуру а ля “колл-центр” — более сложные технические запросы передавались прямиком к разработчикам, в то время как обработка всех проблемных моментов и багов ложилась на плечи отдела QA. Тестировщики Wrike обладали необходимыми техническими знаниями и компетенциями, но не могли вступать в диалог с клиентом (всю переписку вели специалисты саппорта), а также не имели представления о том, что происходит на уровне поддержки.
До определенного времени такая организация оправдывала себя, но вскоре масштабы бизнеса компании существенно выросли. Росла клиентская база, а, следовательно, и совокупное количество обращений в поддержку. Помимо этого с развитием продукта увеличились глубина и сложность многих вопросов.
Инженеры-тестировщики перестали справляться с возросшей нагрузкой (в этом случае накладывалась их работа по запуску и тестированию релизов) и не успевали качественно обрабатывать все заявки. Ситуацию усугубляли проблемы с коммуникацией — обе стороны (агенты поддержки и инженеры) временами с трудом находили взаимопонимание, буквально говоря на “разных языках”. Клиенты же, в свою очередь, от этого только страдали — в процессе налаживания внутренней коммуникации их запросы порой кочевали из одной инстанции в другую и обратно, а само решение не двигалось с места. Если представить процесс на упрощенной схеме, все выглядело примерно так:
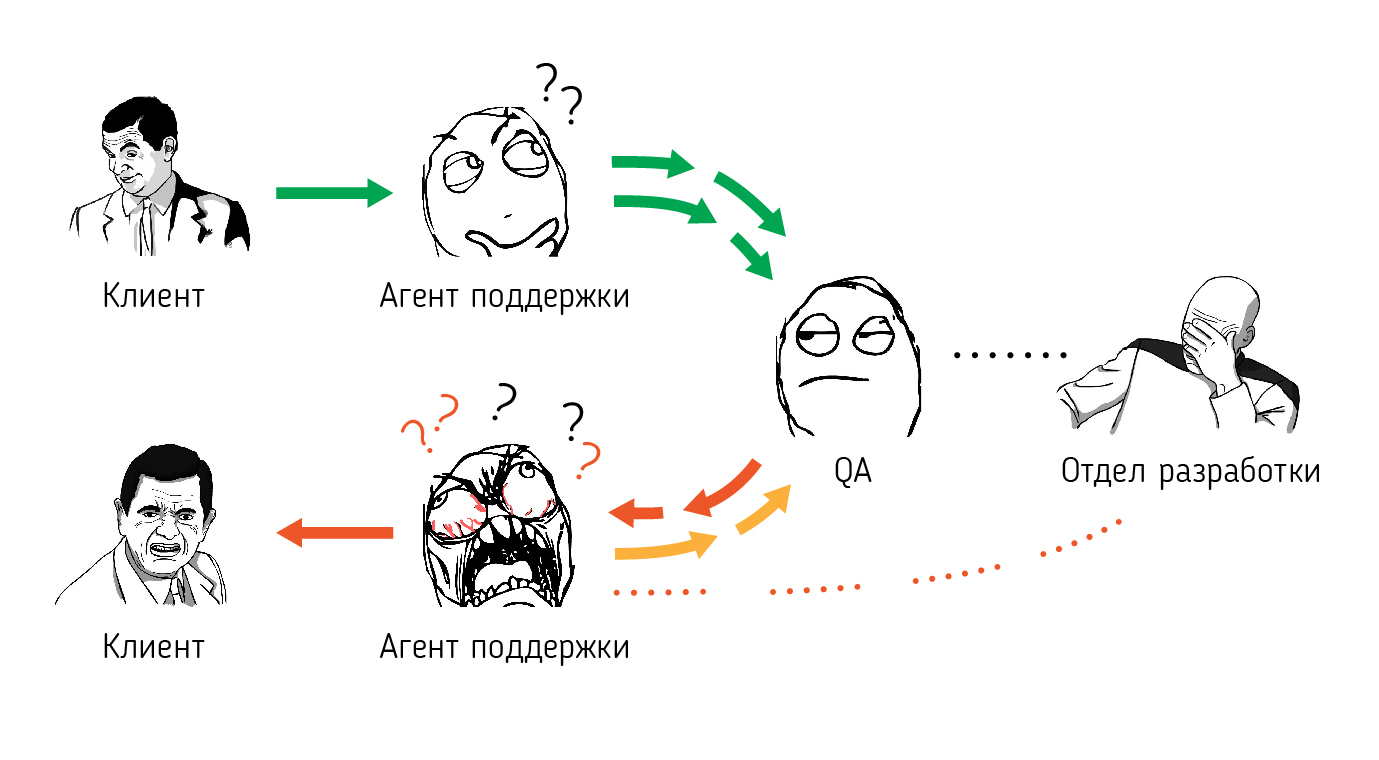
В этот момент перед нами встал вопрос: каким образом модифицировать процесс и структуру обработки технических запросов и, не потеряв ориентации на потребителя, прибавить в качестве и скорости решения проблем?
Tier 2: между саппортом и QA
Решение нашлось в создании структурного подразделения в поддержке, отвечающего за технические вопросы и эскалацию проблем к инженерам – Tier 2 – то есть «команды второго уровня» (далее Т2). Идея состояла в том, что опытные агенты поддержки, пройдя через определенный набор тренировок, попробуют выйти на новый уровень в решении технических задач. Иными словами, новая команда должна была стать «спецподразделением» поддержки, которому бы отводилась особая техническая роль. Главным преимуществом этой идеи был уход от дробления сервиса – Tier 2 состоял из опытных агентов «первого уровня», которые по-прежнему были на передовой и активно помогали коллегам с обработкой клиентских запросов, но в то же время большую часть времени посвящали именно запросам и проблемам технического, инженерного характера.
Как при этом видоизменились наша структура и процесс? Если раньше для того, чтобы разобраться в составляющих проблемного обращения клиента и грамотно передать его в разработку могло потребоваться несколько дней (время занимала обработка запроса инженерами QA, почти всегда встречающиеся возвраты в поддержку с уточнениями деталей и т.д.), то теперь весь процесс занимал гораздо меньшее время, на обработку и передачу уходило 1-2 часа. К тому же снижалась нагрузка на обе стороны – поддержку и QA.
Если агент поддержки видел вопрос технического плана, входящий в компетенцию Т2, он выяснял необходимые минимальные детали и передавал их «спецам» из своего отдела. Т2-агенты брали на себя дополнительное общение с клиентом и закрывали кейс, исчерпывающе ответив на вопросы. При этом устанавливался часовой интервал для обработки всех «входящих» запросов. Таким образом, у клиента оставалось чувство удовлетворения от быстрого и качественного обслуживания. В круг технических вопросов входили также наиболее сложные темы – работа с Wrike API, настройка интеграций с такими сервисами как Salesforce и конфигурация SAML SSO.
В случае, если «дело пахло багом» (или вопрос требовал вмешательства инженеров), то Т2-агент помогал своему коллеге на передовой собрать нужную для тестировщиков информацию (или делал это сам), а затем через контакт с QA и передачу нужных деталей убеждался, что задача взята в разработку. Иными словами, Т2 курировал все баги и технические проблемы, приходящие от клиентов, и был в курсе деталей процесса разработки. Кроме того, агенты «второго уровня» получали всю необходимую отладочную информацию напрямую от инженеров, что позволило им приобрести опыт в решении некоторых проблем без эскалации в отдел разработки.
Интересно, что с формальной точки зрения общая структура процесса эскалаций не перестала быть многоуровневой, и скорее только усложнилась – ведь мы добавили еще одно звено в общую цепь. В действительности такой ход как раз позволил упростить систему и настроить ее на максимальную эффективность. Поскольку Т2 агенты работали напрямую с клиентами, большая часть технических вопросов уже не покидала уровень саппорта, а остаточная «проблемная» часть доходила до отдела разработки в «готовом к употреблению» виде. В этом и заключалась фундаментальная разница между структурой Поддержки Wrike «до» и «после» реформирования.
За короткое время нам удалось добиться построения целой системы эскалаций сложных тех вопросов и багов, снизив время обработки новых проблем до 24 ч. Новая схема представлена ниже.
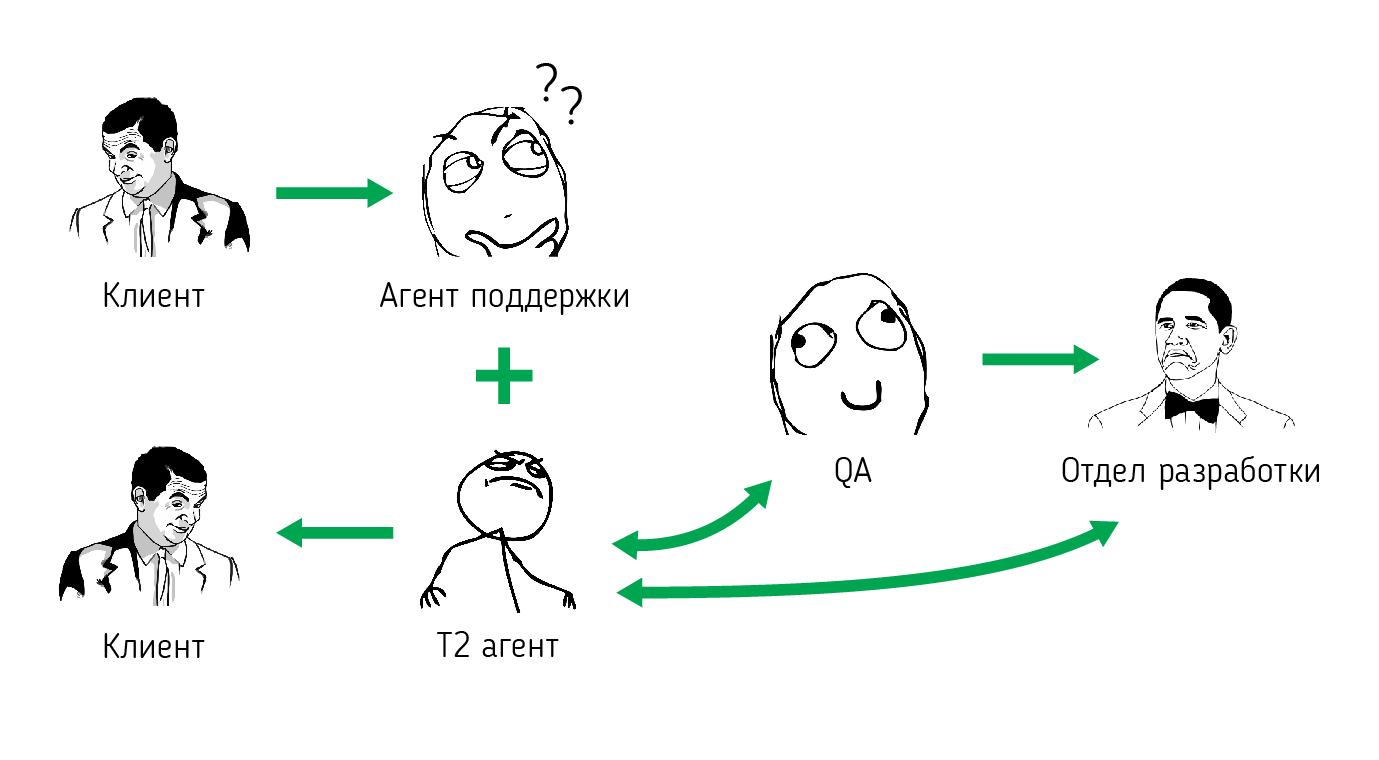
Метрики эффективности
Теперь о главном — как мы поняли, что новая схема успешно работает. Несмотря на то, что никаких жестких метрик изначально не было предусмотрено, ряд факторов свидетельствовал об успехе.
1. Метрика «Количество возвратов» предельно снизилась.
Количество возвратов из Т2 стало ключевой метрикой, которая позволила нам сделать вывод о том, что программа «прижилась» и дала свои плоды в плане качества технического обслуживания. «Возвратом» считалась эскалация в Т2, которая содержала неполные или противоречивые сведения. При старой системе такая эскалация вернулась бы с комментариями от инженеров (как правило, неполными или технически запутанными), и агент Поддержки потерял бы время на ее повторную обработку.
При новой схеме запрос не доходил до инженеров и снабжался подробным комментарием (и, если нужно, пояснением лично) от агента Т2, который позволял агенту первого уровня понять свою ошибку или получить недостающие сведения от клиента, необходимые для решения проблемы. Высокое количество возвратов на начальном этапе говорило о проблемах с качеством обработки технических вопросов и багов. За время адаптации новой структуры Т2-агенты сумели привить «культуру» эскалаций, которые бы не вызывали вопросов у инженеров, о чем свидетельствует падение уровня возвратов почти до нулевого. На графике показана динамика процента возврата обращений (от общего количества эскалаций) из Т2 с момента ввода новой системы. За 7 месяцев существования нового процесса нам удалось снизить средние показатели возвратов с 25% до 2%-3% (см. график ниже).
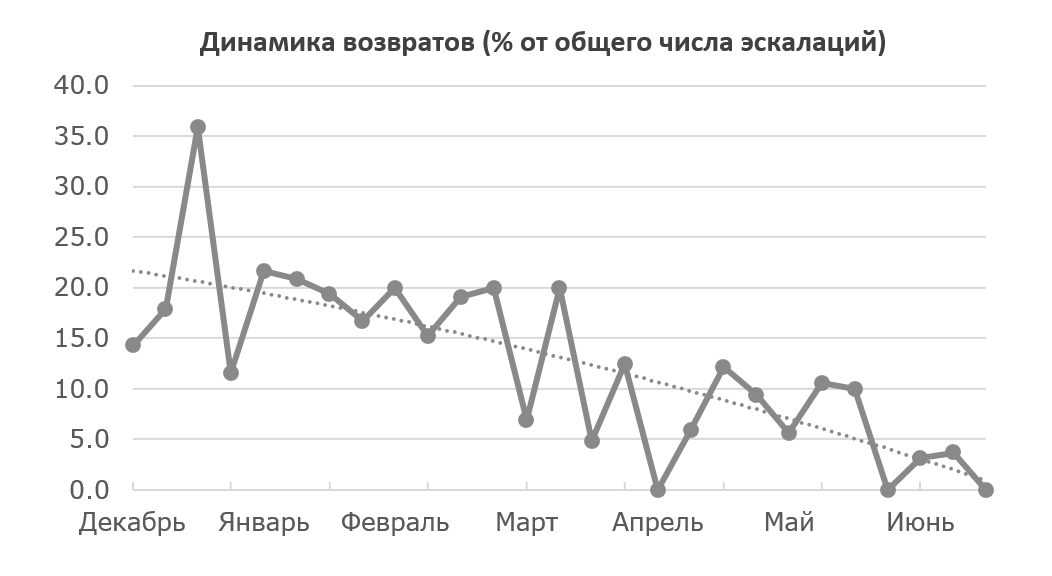
2. Существенно сократилось время на обработку обращений клиентов. Ранее ответ от инженеров занимал 24-48 часов, теперь – 1 час на обработку Т2, рабочий день — на обработку инженерами.
3. Повысилось качество и скорость обслуживания технических вопросов, в частности касающихся работы с API и SSO.
4. QA-отдел разгрузил свой график и смог сосредоточиться на вопросах тестирования.
5. Агенты поддержки получили помощь в решении технических проблем, что позволило им направить больше сил на нетехнические компетенции и повысило скорость обработки обращений.
6. В команде поддержки появился еще один вектор для карьерного роста.
Что потребовалось для введения T2
1. Тренировка пятерых агентов первого уровня по техническим вопросам (обучение на темы API, SSO, Salesforce).
2. Введение необходимых изменений на технической стороне для обеспечения непрерывности процесса эскалации багов и проблем в разработку (этот пункт достоин отдельной статьи).
Подведем итоги
- Введение дополнительной структуры внутри поддержки не привело к ее расслоению и излишней «бюрократизации», а только усилило определенные компетенции, делая команду более технически-ориентированной в целом.
- Это оказалось проще, чем думали.
- Это не потребовало дополнительных затрат (кроме выделения небольшого ресурса на обучение).
Идея с созданием технически-направленного подразделения в поддержке далеко не нова – многие компании с успехом ее реализовывали и до Wrike. В каждом отдельном случае возможны свои комбинации и варианты реализации – все зависит от конкретной структуры и желаемых результатов. Главное в этом деле — понимание необходимости нужных изменений. В случае с такими продуктами, как Wrike желания и отзывы клиентов в конечном итоге определяют внешний вид и суть продукта, поэтому нам очень важно, чтобы связь с потребителем была всегда четко налажена, в особенности на технической стороне. Ну и конечно, важно помнить, что поддержка в целом – это лицо бизнеса, и то, как оно будет выглядеть зависит только от нас.
Комментарии (13)

Shamov
24.10.2016 15:25Замечу кое-что в порядке философского отступления. Почему-то когда люди сами пытаются сделать какую-то полезную работу, они очень быстро приходят к тому, что управляемая многоуровневая иерархия, место в которой определяется опытом и предшествующими заслугами, лучше неуправляемого хаоса демократии, в котором все равны… равны в своей неэффективности. Однако когда те же самые люди взаимодействуют с государственной властью (являясь, по сути, клиентами) они крайне возмущены тем, что у них нет возможности прямой коммуникации с теми, кто реально принимает решения. А если вдруг такая возможность есть — например, прямо в твиттер губернатору можно написать о новой яме на дороге, — то это воспринимается с восторгом… якобы это офигенный прогресс, а вовсе не регресс.


c0ntr0ller
25.10.2016 09:47Мы в своей фирме сделали почти так же — ввели должности разработчиков отдела поддержки, то есть разделили отдел разработки и отдали его часть в управление отдела поддержки. Правда эта возможность связана со структурой продукта, который состоит из множества модулей, каждый из которых имеет свои настройки, БД и скрипты для каждого клиента. В итоге резко снизилось количество и увеличилось качество проработки задач для основных разработчиков, что позволило сосредоточиться на выпуске новых версий. Плюс увеличилась скорость обработки запросов клиентов на мелкие изменения, которые можно осуществить «на лету», и исправление или купирование ошибок. Престижность этого отдела невысокая, но он является отличной «кузницей кадров», человек переходит в основной отдел разработки с хорошим багажом знаний продукта и знанием реальных проблем клиентов

pavel_mal
25.10.2016 09:58Спасибо за комментарий — интересный опыт! В вашей ситуации отдел «разработчиков поддержки» действительно видится хорошей разгонной площадкой для новых разработчиков. Быть может, такой отдел на самом деле видится престижным для определенной категории сотрудников с интересом к техническим темам и разработке, не имеющих большого опыта в этой среде. К тому же взращенные у себя кадры всегда ценнее в плане уникальных знаний и приспособленности под конкретную работу. Еще главный плюс в таком подходе в том, что порой инженерам как раз не хватает понимания проблем и чаяний клиентов — а так выходит, что человек уже и с этой стороны подготовлен.

DenisGaravsky
26.10.2016 23:34Спасибо за статью, Павел – было очень интересно узнать о вашем опыте, так как уже давно занят в данной области — мы правда продаем и обслуживаем инструменты/компоненты для других разработчиков бизнес приложений. Хотел бы задать несколько вопросов:
1. Расскажите, сколько в среднем инцидентов (всего, простых L1 и сложных L2) отвечает рядовой сотрудник супорта и Т2 агент, если это не секретная информация?
2. Как у вас распределяются задачи в работу из очередей (новые и реактивированные инциденты)? В частности, имеет ли каждый супортер всегда в разработке в любой момент времени только одну задачу, которую потом оставляет на себе (AssignedTo)? Берет ли он следующую из общего пула только когда закончит с предыдущей или возможна ситуация, когда на одного сотрудника приходится несколько задач сразу, так как он с ними уже сильно и много разбирался до последней реактивации (ну т.е. личная ответственность vs групповая)?
3. Интересно, возможно ли в вашей системе прогнозирование доступности ресурсов «на будущее», т.е. предсказание ждущим клиентам в очередях типа «При текущей загрузке специалистов вам ответят примерно через 1ч.30», если в вашем бизнесе такое вообще требуется.
4. Как у вас происходит передача запросов и проблем клиентов к разработчикам и другим членам команды? В частности, нет ли с таким T2 подходом проблем с утаиванием/потерей важной информации до тех, кто написал исходный код продукта?
5. Расскажите, пожалуйста, какой еще проактивной работой помимо улучшения качества базы знаний, документации, самого продукта занимаются ваши сотрудники техподдержки.
В заключение, хотелось бы поделиться опытом нашей компании (live chat я брать не буду, пока только расскажу кратко про online help desk с тикетами или почтой). У нас в 2016 году есть те же L1 и L2, но на них практически работают одни и те же сотрудники техподдержки (aka support developers), которые находятся физически рядом с ответственными разработчиками и др. членами команды. Например, мой текущий трайб XAF и в нем есть сквады WinForms, ASP.NET, Mobile, Core, Security, Analytics, которые имеют разработчиков, супортеров, техписателей, дизайнеров (последние два шарятся на трайб ввиду дефицита данных ресурсов). Отдельных тестеров или отдела QA у нас нет — автоматическое юнит, функциональное и ручное тестирование производится силами всей команды. Специалист супорта в трайбе у нас универсален и может ответить на любой вопрос по продукту/направлению, но в то же время он также старается больше фокусироваться на теме своего сквада, например, Core (эта специализация касается как поддержки так и разработки/тестирования новых фич). В тоже время есть небольшое число очень опытных и мега универсальных спецов. Ответы стараемся давать в течение бизнес дня или в большинстве случаев раньше (<24ч), основной язык общения — английский (по-русски тоже можно пообщаться в приватных тикетах при большой необходимости), есть вторая смена (15.00-00.00) для охвата западного побережья, priority line для некоторых подписок типа Universal, эскалация на руководство. Как и думаю везде, стараемся чтобы на L1 не залеживалось тикетов старше нескольких часов (1-2 в идеальном мире), на L2 попадают сложные кейсы, которые нельзя/быстро сразу ответить (например, какой-то сложный проект для долгой отладки) либо с полной инфой после всех уточнений, чтобы любому можно было сразу взять без усилий и начать разбираться. Например, если прислали проект, надо убедиться, что он собирается и запускается, есть шаги и др. необходимые данные. Супорт должен хорошо разбираться в поддерживаемом продукте с технической стороны, отлаживать проекты клиентов, грамотно и вежливо передавать им решения и др. информацию, искать и оформлять баги со всеми шагами (все баги должны предварительно заверяться вместе с разработчиками), анализировать код и запросы клиентов, быть передатчиком клиентской боли и запросов в команду, взаимодействовать со всеми коллегами, чтобы планировать будущие релизы и улучшать сам продукт, базу знаний и онлайн документацию. «Идеальный» супортер у нас — эдакий чтец, жнец и на дуде игрец, разве что баги сам не фиксит и фичи с тестами не пишет (хотя есть и такие исключения)?. Конечно, создание такого «швейцарского ножа» требует долгой и серьезной подготовки, но плюсы очевидны и также легче сохранять мотивацию таких специалистов на высоком уровне за счет большого разнообразия задач. Конечно, это все было бы невозможно или сложно, если бы под боком не было друзей-разработчиков, которые вместе с нами слушают customer pain/suggestions (мы стараемся следовать принципу Put everyone on the front lines как в Rework от 37 signals и доводить эту инфу до авторов напрямую), планируют изменения и помогают в сложных случаях или делятся знаниями. Иногда, в случае больших завалов или на праздники, сами разработчики напрямую привлекаются для ответов на тикеты (конечно, каждый предварительно проходит тренинг, чтобы соответствовать стандартам техподдержки компании по вежливости, грамотности, стилю и др.). Вкратце вроде все описал:-)
P.S.
Пользуемся вашим продуктом для некоторых marketing задач, спасибо!pavel_mal
27.10.2016 18:16Денис, спасибо за вопросы и за то, что поделились собственным опытом! Также рады услышать, что пользуетесь Wrike :)
Постараюсь ответить на всё так же максимально развернуто:
1. Если я правильно понял ваш вопрос, интересно количество «простых» инцидентов и «сложных». Мы не ведем отдельный подсчет для каждого агента, но чтобы вы получили представление о масштабах:
— в среднем в неделю нагрузка по всем каналам на всех агентов > 2k тикетов
— как правило 10% процентов от общего числа тикетов составляют различного рода проблемные инциденты (категория product issue, по вашей классификации можем назвать их L2 инцидентами)
— большинство вопросов по продукту невольно затрагивают некую «проблему», которую клиент не может решить (в нашей статистике такие вопросы обозначаются как product question). Их доля ок. 40% от общего числа запросов.
В Т2 эскалируется в среднем 40-50 проблем в неделю, равномерно распределенная нагрузка на каждого агента при этом получается 6-7 проблем, хотя, конечно все работаю по-разному. Интересно, что с нашей новой системой все эти проблемы уже как правило валидные случаи для дальнейшей эскалации или же вопросы, на которые только Т2 сможет ответить (API, интеграции), т.к. Т2 работает напрямую с агентами первого уровня и консультирует уже «на подходе».
2. Каждый суппортер обязан разбирать новые тикеты из очереди по мере поступления, при этом ответ на них приоритетнее работы над «реактивированными», открытыми тикетами. Плюс в нагрузку даются чаты и звонки (в зависимости от роли агента). У нас действует «ассайн» новых тикетов, соотв. каждый имеет некое портфолио открытых, с которыми он ведет переписку. В итоге, по «реактивированным» тикетам ответственность личная, а по новым запросам – групповая.
3. У нас на самом деле по live каналам (чат, телефон) нет очередей, поэтому такое прогнозирование не ведется :) Вообще мы пользуемся эффективной SLA метрикой, которая устанавливает следующие целевые показатели: 90% чатов должны быть взяты за 30 секунд, 90% звонков за 20 с, 90% email тикетов получить первый ответ в течение часа.
4. Интересно, что вы имеете в виду под «утаиванием»? Передача проблем осуществляется через задачу в Wrike, в ней же хранятся технические записи для dev (в кач-ве подзадачи). Т2 агент составляет подробное и четкое описание, прилагает скриншоты, видео, логи и т.д. К тому же у нас прямая коммуникация ведется, всегда можно что-то уточнить лично.
5. Т2 выполняет функцию мостика между саппортом и другими отделами, не только инженерами. Мы пытаемся доводить до команды любые новости по развитию продукта и изменениям в нем, часто работаем с PM-ами (предоставляем фидбэк), присутствуем на митингах различных команд разработки. Knowledge-sharing через личный контакт также неотъемлемая часть работы – мы проводим тренинги, обучаем новичков процессам напрямую.
P.S. У нас есть свежее видео с выступления менеджеров, где рассказывается о базовых организационных вещах по работе Саппорта в целом, если вам интересно, можете глянуть: https://www.youtube.com/watch?v=YY5Bm3kDw-M
К вам также возникли вопросы:
1. Как в вашем случае все-таки различаются L1 и L2 уровни саппорта? Если работают одни и те же сотрудники, это лишь формальное деление по сложности задач?
2. Очень интересен опыт ответов разработчиков на тикеты, вовлечения их в «customer-facing» роль – насколько сложно это было воплотить в жизнь и есть ли какие-то хитрости в «приобщении»? Все-таки тяжело «технических» людей привлечь к клиентской работе.DenisGaravsky
27.10.2016 23:55Спасибо за развернутые ответы, Павел!
По п.4 смотрю у меня там опечатки, простите. Имел ввиду возможные потери пользовательского фидбека (как хорошего, так и плохого) или недонесение его до разработчиков за счет прослойки между клиентов. Уточнял это отдельно, так как мы с этим сталкивались в некоторых командах и эта проблема также описывается в сообществе. Хорошо, что у вас все хорошо:-) и п.5 лишний раз это подтверждает.
Мои ответы на ваши вопросы:
1. Да, линии по сути просто сортируют работу на день: все что можно простое — отвечаем сразу, сложные кейсы просто требуют доп. исследований и времени.
2. Да, сложностей куча, начиная от элементарного владения деловым английским языком и заканчивая чисто мотивационными «не барское это дело» или «я пишу код, а донести у вас все равно лучше получится», а также желанием соблюсти баланс между супортом и разработкой (фичи писать и тесты поднимать тоже ведь надо). В компании у нас огромное внимание уделяется сервису клиентов, и поэтому одним из принципов является «поддержка клиентов — это ответственность ВСЕЙ команды». Поэтому считаю немаловажным, чтобы разработчики и остальные понимали эту ценность на уровне подкорки. Когда будет понимание, тогда и не будет отношения к процессу поддержки как к повинности. Конечно, как писал выше, также необходим базовый тренинг aka «неделя в супорте», который длится у все по разному в зависимости от исходных данных. Во время него разработчик работает в паре с опытным супортистом и делает обычный разбор линий, пишет сам ответы, получает корректировки по ходу дела и знакомится со всеми остальными секретами данного дела. Дальше плотный контроль потихоньку ослабевает. Если все хорошо, то разработчик идет уже сам в бой и со временем присмотр вообще становится не нужен. Некоторым ребятам вообще очень нравится отвечать тикеты так как приятно все таки общаться с живыми пользователями твоей фичи, получать благодарности, что даже просят иногда «подкиньте посупортить, а то давно не было»:-) — так что это вполне может быть дополнительной мотивацией к работе, тем более полезно менять сферу деятельности. Есть также вообще уникальные команды, где поддержку оказывают целиком дежурные разработчики (как писали выше в коментах), но это скорее исключение. В среднем по больнице, привлекать разработчиков мы стараемся только по реальной необходимости, такой как перегрузы или праздники (по договоренности/желанию разработчики могут выйти в праздники вместо коллег супортистов). Для этого координатор группы супорта продукта в начале дня (чтобы ребята могли лучше спланировать свой день и не переключаться лишний раз) выделяет тикеты на спец линию Developers Queue или «девку» — сей процесс мы даже шутливо называем «разогрев девки»:-)
Так как английский язык очень важен для нашего бизнеса (не только для супорта, но и тупо метод в классе нормально назвать, сделать ревию новой статьи в документации или понять о чем говорили на вебинаре с маркетингом), компания всячески мотивирует сотрудников на улучшение этого навыка (это даже упоминается в оценке уровней) и создает условия для его изучения (компенсации или курсы на базе офиса, причем супорту курсы вообще бесплатно и за счет рабочего времени). В своей команде я лично всегда ставлю поднятие уровня языка на ревию уровней молодым или проблемным ребятам. И это вроде действует — после осознания многие стали ходить на курсы/наняли репетиторов и прокачивают этот навык сами. Дай бог скоро совсем не будет переменных «needRepit» и шуток про «Минаков-стайл»:-)
Конечно, для ответов на тикеты для всех в компании есть специально обученные знатоки языка aka «корректоры» (местные и нативные), которые помогают с грамматикой, стилями и правильными коннотациями, перед тем как ответ уйдет клиенту.
Вроде все из основного — почти на статью получилось… Спрашивайте, если что интересует еще!
pavel_mal
30.10.2016 20:43Действительно интересно, спасибо за то, что поделились ценным опытом привлечения dev к процессу контактов с клиентом — нам крайне интересна такая тема, т.к. иногда чувствуется необходимость «сблизить» клиентскую и инженерную стороны сервиса. Идея с «разогревом девки» и привлечением к работе в саппорте разработчиков очень понравилась :)
Ваши действительно достойны отдельной статьи, тема это всегда актуальна для ориентированных на клиента IT компаний, на мой взгляд.
Наверное, если разработка и саппорт у вас в компании так близки, не возникает особых сложностей в понимании нужд клиента и их адаптации в продукте. Всегда интересовал вопрос, каким образом лучше донести клиентские жалобы до ушей разработки — любой фидбэк из саппорта все же обычно воспринимается не слишком «близко к сердцу», но когда сам творец оказывается на передовой, то наверное и ответственность ощущается лучше.DenisGaravsky
01.11.2016 10:37Павел, сложности есть всегда, и многое зависит от самих людей. По мне основной секрет успеха — это прививка ценности на уровне компании — люди должны понимать где и для чего они работают (опять же в «Put everyone on the front lines» главе из Rework от 37 signals неплохо расписано). Помимо передачи «кастомер-боли»/сценариев использования разработчикам, у нас само руководство, например, читает каждый отзыв в «Uninstall Feedback» письмах, налажена передача информации напрямую либо через мыл-листы и др. каналы, чтобы все были в курсе интересных вещей/серьезных проблем и могли формировать понимание, принимать решения. OKR опять же — тоже неплохой фреймворк в помощь для лучшего следования ценностям компании/трайба.
К разработчикам опять, есть такое неплохое летучее выражение: «Пиши код так, как будто в дальнейшем его будет поддерживать сумасшедший психопат-убийца, который знает, где ты живешь». На практике его пробовали реализовывать для некоторых особо важных новых фич даже путем технической поддержки самими разработчиками на протяжении нескольких месяцев после релиза. Так авторы еще лучше могут «прочувствовать» слабые места и оперативно выпускать обновления.
Удачи!
pavel_mal
01.11.2016 12:28Спасибо, Денис, за обмен опытом, вам тоже удачи и успешной реализации планов! :)
Misiam
Добрый день, хотелось бы задать несколько вопросов:
Спасибо
pavel_mal
Михаил, добрый день!
1. Обучение Т2 проходило постепенно, по ходу работы: некоторое время мы провели в изучении правил эскалаций, знакомстве с основными инструментами и рабочими ситуациями (т.е. изучали сам процесс); параллельно с этим запускали обучающие сессии по конкретным техническим темам (несколько итераций, от простого к сложному) — обучние работе с API, плагинам, интеграциям Wrike.
Что касается общего «траблшутинга», никакого особого тренинга наши агенты не получали — здесь, скорее, многое родилось само в процессе контактов с QA и dev и из опыта решения разного рода проблемных ситуаций. Мы также запустили свою внутреннию документацию для саппорта на основе этих знаний.
Насчет требований: во главу угла для Tier 2 агентов мы поставили навыки локализации и анализа проблемы (аналитические способности, умение отделить важное от второстепенного, умение грамотно и четко донести суть). Отдельно выделили важность коммуникативной составляющей — умение наладить общение как с людьми инженерного скалада ума, так и с клиентами. Ко всему прочему Т2 агент должен был стать опорой для товарищей из поддержки — здесь пригодится наличие менторских качеств, а также стремление помогать и объяснять (такой 'support for support' прицнип практикуется в поддержке Wrike и на уровне менеджмента).
2. Нашему Т2 процессу чуть больше года на данный момент, за это время мы расширили состав Т2 только единожды (+2 человека для прикрытия ночной смены, т.к. поддержка у нас 24/7) — никаких специальных тестов не проводили, но, безусловно, был важен опыт на первом уровне, интерес к технчиеским знаниям и аналитический склад ума. Я бы еще сравнил отбор в Т2 с собеседованием на роль помощника Шерлока Холмса — есть в процессе исследований клиентских проблем и багов что-то детективное :) И требования соответствующие.
3. Спасибо за ссылку, по этой статье Т2 относится скорее к Уровню-Линии 2 («аналитические методы решения», «оказание помощи первой линии» говорят прямо в его пользу).
В то же время в характеристике Уровня 3 указна ответственность «за исследования и развитие решений для новых, появляющихся, неизвестных ранее проблем» — все-таки в нашем случае Т2 иногда может взять на себя и эту функцию. Часто бывает, что Т2 агент сам находит проблему, выявляет ее источник, стабильный способ воспроизведения и передает напрямую разработчикам для фикса (QA остается только лишь официально подтрведить баг). В общем и целом, наши инженеры квалифицируются как Tier 3 в общей системе эскалаций, т.к. за ними всегда фикс любых багов, что, к сожалению, не в компетенции Tier 2 спецов.