

Бекграунд и подготовка
С марта 2016 года Cofoundit работал в ручном режиме: мы сами подбирали сотрудников и сооснователей в стартапы и изучали потребности пользователей. Собрали требования и в июне приступили к разработке сервиса. Два месяца ушло на создание прототипа и еще месяц на доработку финальной версии. Мы начали работать над продуктом в середине июня, в августе выпустили закрытую бету, в конце сентября — официально запустились и продолжаем работу.
С самого начала в качестве методологии я рассматривал только agile. Первую неделю мы посвятили планированию: разбили задачу на небольшие таски, спланировали спринты, каждый длиной в неделю. Большинство задач укладывалось в один спринт, но поначалу некоторые занимали и два, и три.
Первые спринты были откровенно неудачными — мы задержали релиз на неделю и начали отставать от графика. Но этот опыт помог нам правильно оценить сроки и отказаться от избыточного функционала. Изначально мы хотели сделать сервис с симметричным поиском: чтобы и специалист, и проект могли просматривать анкеты друг друга и начинать общение. В результате в работе осталась только первая часть: кандидат может просматривать и выбирать анкеты стартапов, а проект видит только тех специалистов, которые уже проявили к нему интерес. То есть по сути мы запустили минимальный жизнеспособный продукт.
Управление эффективностью
С помощью «Джиры» и плагина Time in status я постоянно следил за тем, как работает команда, и сколько времени занимает жизненный цикл задачи. Я считал время пяти основных этапов: в разработке (с момента создания таска до отправки на ревью), ревью кода (происходит на стороне команды аутсорса), деплой, тестирование и утверждение (со стороны сервиса, то есть мной).
В таблице указано количество дней, в течение которых задача находилась на каждом этапе разработки. Несмотря на то, что в нашем случае над задачей единовременно работал только один специалист (разработчик, тестировщик или менеджер), эти данные не равны человеко-часам: задача висит в статусе, даже если работа над ней не идет. Я специально не показываю сбор требований, время ожидания релиза и другие этапы, которые никак не отображают скорость работы команды. Статистику по июню толком собрать не удалось, поэтому этих данных нет в таблице.
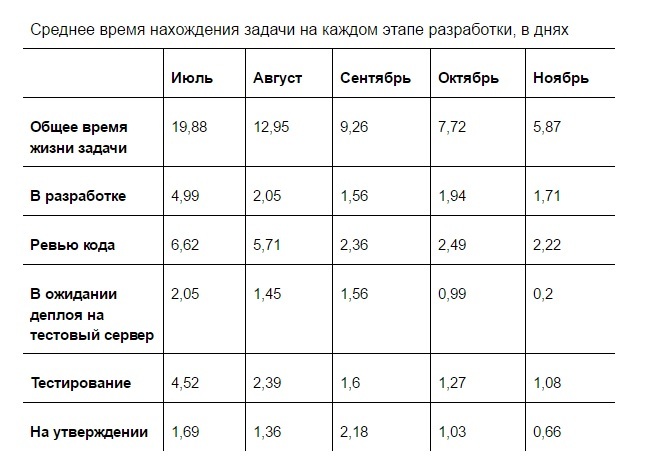
По результатам работы в июле я обратил внимание, что задачи дольше всего находятся в трех статусах: в работе, на тестировании и на ревью. Проще всего было решить проблему долгого тестирования. Тестировщик в нашей команде работал part-time и просто не успевал оперативно тестировать все задачи. Мы поговорили с подрядчиком и перевели его в проект на full-time. Это сократило время тестирования в два раза.
Для основных повторяющихся сценариев мы стали делать автотесты на selenium. Это позволило нашему тестировщику быстрее проводить регрессионное тестирование. Мы сократили время на заполнение анкет, без которого нельзя протестировать новый функционал сервиса. Потом мы продолжали наращивать число автотестов и улучшать показатели эффективности.
Во вторую очередь я начал разбираться с задержками на этапе разработки. При недельных итерациях я не мог позволить задаче висеть в работе пять дней (весь спринт). До финального релиза хотелось как минимум несколько раз посмотреть функционал в работе. Я решил проблему, разделив задачи на более мелкие.
По результатам августа мы отставали по показателю «Время на ревью» со стороны команды аутсорса. Сначала я постоянно напоминал исполнителю, что он должен посмотреть код и дать комментарии. В ноябре я передал эту обязанность тестировщику. С этого момента, как только он заканчивал работу над задачей, он сам оповещал ответственного за ревью. Полностью мы реализовали такой подход только в ноябре, когда деплой на тестовый сервер стал занимать меньше времени.
В сентябре слабыми показателями были «Утверждение» со стороны команды сервиса и «Ожидание деплоя на тестовый сервер». «Приемку» удалось ускорить просто более пристальным вниманием и быстрым реагированием на задачи. К тому же к этому времени процесс разработки уже вошел в ритм, и уже не так много моего времени уходило на поддержание.
Время деплоя на тестовый сервер в сентябре занимало больше 15% — это было чрезвычайно странно. Выяснилось, что после проведения ревью задачи её выкладывал на тест последний исполнитель. Нужно было мержить ветки, иногда возникали конфликты, исполнитель отвлекался от текущих задач. В октябре мы прикрутили к репозиторию механизм автоматического выкладывания задач, что сильно сократило время деплоя. Потом мы отладили процесс и в итоге за два месяца сократили время на деплой в 8 (восемь!) раз.
Итого, за пять месяцев мы сократили время решения задачи почти в четыре раза. Раньше путь задачи от постановки до утверждения результата занимал в среднем 20 календарных дней. Теперь, когда срок сократился до пяти календарных дней, стало проще контролировать этапы разработки, оценивать итоговые сроки решения задач и планировать загрузку команды.
Прогнозирование сроков
Другая важная задача — точная оценка сроков. По условиям договора с подрядчиком мне в целом было невыгодно попадать в оценку. Если задача делалась быстрее, мы платили только за потраченное на нее время, а если команда не укладывалась в сроки, то мы платили меньше.
Но у меня были другие причины добиваться точной оценки сроков. Например, скорость реализации иногда влияет на выбор функциональностей. Если на внедрение одной фичи уйдет день, а на другую — три дня, то менеджер с большой долей вероятности выберет более быстрый в разработке вариант. При этом «однодневная» фича на практике может занять те же три дня, и если бы это было известно заранее, выбор опций мог быть другим.
Я посчитал процент точности, с которой каждый программист попадает в оценку. В результате я получил коэффициенты, которые помогли точнее планировать сроки. Например, если программист оценил задачу в 10 часов, но его коэффициент ошибки около 40%, то я могу смело считать, что на задачу уйдет 14 часов. Профит.
Сложность состоит в том, что ошибки в оценке сроков бывают несистемными. Одни таски программист может делать в четыре раза медленнее, а другие — в два раза быстрее. Это сильно усложняет расчеты и планирование.
Поэтому я посчитал не только среднее отклонение в оценке сроков для каждого разработчика, но и процент отклонения от среднего. Если он был меньше 20%, я считал это хорошим результатом — такая погрешность в сроках не мешала мне планировать. Но были отклонения и в 30%, и в 50%, и они сильно мешали работе над релизом.
Например, разработчик оценивал сроки выполнения в 10 дней, его стандартное отклонение от сроков 40%, так реальный срок выполнения задачи становится 14 дней. Но если отклонение от среднего составит 50%, то это еще 7 дней работы над задачей. Итого, срок работы составит 21 день вместо обещанных 10 и ожидаемых 14. С такими опозданиями невозможно работать, поэтому я старался найти их причину и исправить.

В «Джире» я проанализировал опоздания и их причины — сделал выводы, что большее отклонение от планового времени приходится на задачи, которые не проходят апрув у меня, и которые тестировщик по несколько раз возвращает после тестирования.
Сначала я исправил ситуацию с задачами из «приёмки». Основная причина возврата заключалась в том, что тестировщик недостаточно анализировал задачу. Во время тестирования он действовал «по обстоятельствам», а иногда и вовсе не понимал, как должна работать функция. Решили, что тестировщик будет готовить Definition of done (DoD) к каждой задаче: не подробные тест-кейсы, а примерное описание того, что и в каком направлении он будет смотреть.
Я же со своей стороны просматривал эти DoD и, в случае ошибочного понимания или недостаточного объема тестирования, сразу указывал на это тестировщику. В итоге количество возвратов из «приемки» сократилось практически до нуля, и оценивать сроки стало проще.
Что касается частого возвращения задач из теста обратно в разработку, выяснилось, что почти треть случаев происходит из-за ошибки при деплое: например, не запущены нужные скрипты. То есть опция совсем не работала, но это можно было понять и без помощи тестировщика.
Решили, что при развертывании задачи на сервер программист будет сам проверять простые сценарии, чтобы убедиться, что все характеристики работают. Только после этого задача уходит в тест. Такая процедура занимает не больше пяти минут, а число возвратов из тестирования сократилось более чем на 30%.
Для сложных задач мы приняли решение проводить созвон с разработчиком, тимлидом и тестировщиком. Я комментировал документацию и подробно рассказывал, что именно и как я хочу, чтобы было реализовано. Если команда разработки видела какие-то недочеты на этом этапе, мы сразу вносили изменения в документацию. В таких случаях оценкой сроков занималось минимум два человека — разработчик и тимлид.
За четыре месяца средняя ошибка при планировании уменьшилась в 1,4 раза. Количество отклонений более 50% от средней ошибки сократилось с 9% до 1%.
Сбор и анализ статистики помог мне вовремя увидеть слабые места и исправить ошибки управления командой. Какие-то из них могли произойти и у «домашних» разработчиков, какие-то — особенность работы с аутсорсом. Надеюсь, принципы работы с внутренней статистикой пригодятся и вам.
Комментарии (21)

Lofer
20.12.2016 15:26Первые спринты были откровенно неудачными — мы задержали релиз на неделю и начали отставать от графика.
Тут нет причин считать их «неудачные». Первые пару спринтов и предназначены для уточнения методов оценок.
Я специально не показываю сбор требований, время ожидания релиза и другие этапы, которые никак не отображают скорость работы команды
…
Я считал время пяти основных этапов
По идее заказчика интересует время через которую он получит свою «хотелку»
Что бы собрать требования, это же тоже работа какой-то команды и соответственно ее эффективность.
Почему вы их «выкинули»?
Время деплоя на тестовый сервер в сентябре занимало больше 15% — это было чрезвычайно странно. Выяснилось, что после проведения ревью задачи её выкладывал на тест последний исполнитель. Нужно было мержить ветки, иногда возникали конфликты, исполнитель отвлекался от текущих задач.
Это типовые проблемы и по идее должны были быть учтены сразу. Странно что это стало новостью «в процессе»
nondead
20.12.2016 15:381. Разработку начали до моего прихода и оценка спринтов уже велась, так что считать первые спринты при мне удачными — нельзя. Хотя вы и правы они как раз и нужны для уточнения методов оценки.
2. Этот вопрос решался в моем взаимодействии с заказчиком и слабо связан с работой с аутсорс команды, поэтому он и не описан тут. Если интересует могу предоставить статистику с учетом всех этапов.
3. Опять же согласен с вами. Но разработку начинали до меня на базе уже сложившихся процессов. Поэтому этим аспектом занялись только когда он начал «гореть».Lofer
20.12.2016 16:03Если интересует ...
Очень интересуют:) Давно собираю метрики со всех доступных проектов :))) Можно в личку
Критерии приемки сразу с новымии «хотелками» продумываете или потом qa придумывает DoD на свой вкус?nondead
20.12.2016 16:24Чуть позже отправлю метрики.
DoD пишет тестировщик и я его проверяю.
Есть мнение, что если буду писать DoD сам, то тестироваться задачи будут только по моим DoD и никак иначе, что увеличит вероятность попадания ошибки на прод.
Для больших задач я при созвоне рассказываю как пользователи будут это использовать, но это не является исчерпывающим критерием приемки.
nondead
20.12.2016 17:30Остальная метрика. Она не очень показательна, как мне кажется.

Появляются зачастую задачи, которые надо решать не в ближайшую неделю. Или после оценки принимается решение о снижении приоритета. Что увеличивает время в столбце — До начала разработки.
Также время в ожидании релиза не показательно к примеру:
а) программист может быстро успеть решить все таски в текущем спринте и приступить к следующему, что приведет что часть его задач будет долго ждать релиза.
б) программист может сильно затянуть с решением своих задач, которые критически выкатить в ближайший релиз, что может привести к увеличению срока всех остальных задач в ожидании релиза на 1 день.
И оба результата будут иметь одинаковый эффект в столбце — Ждет релиза.
Тут более показательны запланированные и фактические сроки релиза, но к сожалению таких данных у меня под рукой нет.Lofer
21.12.2016 00:39а) программист может быстро успеть решить все таски в текущем спринте и приступить к следующему, что приведет что часть его задач будет долго ждать релиза.
По идее если программист закроет свои таски в спринте, то маскимум, что он может сделать, это взять чужие таски из этого спринта. Если он бежит впереди паровоза, то это странная штука… честно говоря, не помню такого ни в одном фреймвоке.
б) программист может сильно затянуть с решением своих задач, которые критически выкатить в ближайший релиз, что может привести к увеличению срока всех остальных задач
По идее спринт не может начаться, если все не согласятся со сроками преварительно обсудив методы решения. Своеобразная перекрестная проверка. Если не уложился, то фичу можно просто перенести в следующий спринт.
Спринт то планируется так, что бы объем задач в спринте не более чем доступно ресурсов на спринт. Меньше — можно. А у вас как-то два правила трактуются своеобразно.nondead
21.12.2016 10:55Про своеобразность — согласен.
Но давайте приведу примеры:
У нас есть фронтэнд разработчик, который совсем ничего не может делать в бекэнд части.
У него в спринте 3 задачи по фронтэнд и ещё есть 10 задач по бэкенд.
Он молодец и сделал все свои 3 задачи раньше срока. Что ему делать дальше? Добавлять задачи в спринт? Плохая идея, может не выдержать тестировщик. Брать задачи бэкендера? Как я говорил таких компетенций у него нет. Помогать тестировать? Лучше и дешевле это сделает тестировщик.
В итоге остается только брать задачи, которые позже попадут в следующие спринты.
- Все со сроками согласились, оценку провели и всё хорошо. Но потом всплыла задача которая была ошибочно оценена. При этом задача это самая важная для бизнес-заказчика в этом спринте. И у меня есть 2 варианта действий (все мотивации и давайте поработаем ночью испробованы и не помогают успеть решить её в срок):
а) Подойти к бизнес-заказчику и сказать давай релиз отодвинем на 1-2 дня?
б) Подойти к бизнес-заказчику и сказать, вот сегодня мы выкатим не особо нужные тебе фичи, но вот через неделю выкатим то что тебе реально надо.
И я выбираю 1-ый путь, что не согласовывается с чистым скрамом, но я нигде и не говорил что мы живем по этой методологии.
Lofer
21.12.2016 12:28С точки зрения итеративной разработки такая упреждающая разработка провоцирует кучу ненужных проблем, и с кодом в том числе. У вас, по идее, провоцируется осознанно риск реализация не подтвержденных задач, поскольку Клиент еще не принял текущую итерацию и, дополнительно, может перепланировать следующую. Например отказать от уже сделанной «заранее задачи». Это провоцирует бизнес-риск: за работу заплачено, но она не продана.
Если я верно понимаю, обработка этого риска будет Вашей заботой?
При такой проблеме, предпочитаю дать людям книжку — пусть учаться на смежном :) через пару итераций — начнет окупаться.
Но потом всплыла задача которая была ошибочно оценена.
Рискну предположить, что это проистекает из:
DoD пишет тестировщик и я его проверяю.
Есть мнение, что если буду писать DoD сам, то тестироваться задачи будут только по моим DoD и никак иначе, что увеличит вероятность попадания ошибки на прод.
Честно говоря, не видел такой проблемы. Правильные методологии тестирования не пропускают такие ошибки. Обычно QA от 3 лет опыта знает их.
Для больших задач я при созвоне рассказываю как пользователи будут это использовать, но это не является исчерпывающим критерием приемки.
Нет формализованных критерием приемки от Заказчика и каскадом проблемы аналитика->планирование->реализация->тестирование-> показ/приемка.
Было бы интересно узнать пару эмпирических метрик: сколько в среднем стоит час ошибки или «экономии» в аналике и архитектуре?
«Экономия» — это изначально не сделанная работа, но которую потом все равно пришлось делать.
Цена — сколько работы было сделано «не корректно» по всей цепочке.
Я не рассматриваю ваш процесс как Scrum.nondead
21.12.2016 13:30- У нас так устроен процесс, что релизы мы делаем в среду, а примерный список задач на спринт я согласовываю в понедельник (потом в среду мы его конечно уточняем). Что позволяет избежать риска несогласованных задач. И риск этот риск — да, моя забота.
- Ошибочная оценка задачи связана далеко не только с QA и его работой. Плохие оценки случаются, и надо как-то на это реагировать.
Но да, писать свои критерии приемки я не стал именно из-за QA, до того как он начал писать DoD с моим ревью задачи после тестирования часто имели много ошибок, иногда очевидных. - Не совсем понял вопрос последний.
Аналитика моя или разработчиков?
Очевидно коэффициент зависит от объема и сложности задач.
Думаю для крупных аналитика/архитектура разработчика ко всему процессу у нас имеет коэффициент x5, может больше, но точно меньше x10.
Lofer
21.12.2016 15:28Теперь, когда срок сократился до пяти календарных дней,
…
коэффициент x5, может больше, но точно меньше x10
Т.е час работы аналитика ВА (при созвоне рассказываю + писать DoD с моим ревью задачи + ...) порождает примерно 5..10 часов разработки +ревью +QA?
А можно табличку «В таблице указано количество дней, в течение которых задача находилась на каждом этапе разработки. » не в днях, а человеко-часах глянуть?
В проектах что я видел, в случае проблем, выяснялось, что «экономия» часа работы BA порождало проблемы на ~8...16 часов в лучшем случае. Худшее пока что я видел — это порядка 80 часов.
Прочие метрики — нормальные «здоровые» :)nondead
21.12.2016 15:40Очень больная тема эта метрика, к сожалению не могу её снять сейчас.
Для этого планирую немного изменить процесс работы в jira (а это возможно только после нового контракта с командой разработки) и начать снимать её в феврале.

smbody
20.12.2016 16:13Все это напоминает сферического коня в вакууме. Мне кажется, что такая почти идеальная сходимость возможна только в команде аутсорсеров, которая не делает продукт, а ляпает заплатки на существующие решения.
Кто принимает решение об использовании тех или иных технологий? Кто определяет архитектуру системы? Как Вы объясняете Заказчику, что на самом начальном этапе на стадии проектирования были допущены ошибки и приняты неверные решение и что теперь наращивание функционала системы делать все труднее и труднее и времени на это уходит больше? Как Вы доказываете Заказчику, что нужно вернуться к разработанному ранее решению и провести рефакторинг?
Как Вы все это учитывает в своих планах?nondead
20.12.2016 16:38Хотелось бы узнать у вас в какую сходимость вы не верите? Во время в каждом статусе или в качество оценки?
Давайте буду отвечать по частям.
1. Кто принимает решение об использовании тех или иных технологий?
Основной набор технологий был сформирован ещё до моего прихода и даже до текущий команды разработки. Есть 2 пути добавления/изменения технологий у нас в проекте:
а. Я хочу что-то поменять, доношу свои потребности до команды и они мне предлагают варианты технологий/средств применимых для этого.
б. Команда сама приходит к мысли что им проще жилось бы с какой-то технологией/средством, они мне об этом говорят и обосновывают свою позицию. Если убеждают (обычно убеждают), то мы начинаем её использовать.
2. Кто определяет архитектуру системы?
Глобально архитектуру системы определяет команда разработки, но если я считаю что кусок встраивается довольно большой, то я принимаю участие при обсуждении архитектуры.
3. Как Вы объясняете Заказчику, что на самом начальном этапе на стадии проектирования были допущены ошибки и приняты неверные решение и что теперь наращивание функционала системы делать все труднее и труднее и времени на это уходит больше?
Для команды разработки заказчик — я. Моё взаимодействие с бизнес заказчиком на команде отражается в минимальном объеме.
Если то что они хотят поменять укладывается условно в 1 день, то я просто принимаю это решение.
Если же надо к примеру на неделю остановить процесс и всё переписать, то тут я более подробно анализирую что именно это нам даст и иду с этими данными к бизнес заказчику.
Был довольно свежий пример, раньше на внесения изменений в одну часть анкеты кандидата мы тратили 2-3 дня, но после того как потратили меньше недели на рефакторинг смогли ускорить этот процесс и начать тратить менее 1 дня. В итоге счастлива и команда разработки (я верю что программистам приятно работать в «красивом» проекте) и заказчик (его потребности решаются быстрее и это вложении окупилось менее чем за месяц).
4. Как Вы объясняете Заказчику, что на самом начальном этапе на стадии проектирования были допущены ошибки и приняты неверные решение и что теперь наращивание функционала системы делать все труднее и труднее и времени на это уходит больше?
См. пункт 3.
Но что скрывать, бывают моменты, когда надо выкатить какую-то задачу в срок и тянуть больше нельзя. Тогда я принимаю решение выкатить «костыльное» решение. Но сразу договариваюсь с разработчиком что вернемся к этой части кода в течение определенного срока (не более 2 недель) и уже дальше общаясь с бизнес заказчиком объясняя ему что рефакторинг необходим, иначе через пару недель проект у нас завалится и мы потратим огромное время его восстановление.smbody
21.12.2016 12:57Ваши ответы многое прояснили. Вы не просто менеджер, Вы скорее выполняете функции тимлида.
Мое субъективное мнение, что точная оценка времени выполнения задач бессмысленная трата того самого времени дорогостоящего специалиста. Вас или разработчика. Единственное чего Вы добились — оценка сроков реализации стала отвечать Вашим ожиданиям. А эффект дало совсем другое — наведение порядка в работе.nondead
21.12.2016 13:15Я в детали кода не лезу, ревью не провожу, экспертом по технологиям не являюсь и т.д.
Так что назвать меня тимлидом довольно сложно.
Как я писал мне не нужна точная оценка времени. Для меня (в силу контрактных особенностей) даже выгодно если программисты будут ошибаться в оценке. Но мне надо чтобы ожидания бизнес-заказчика оправдывались, поэтому ошибка пусть будет, но она будет предсказуемой.
И в силу контрактных особенностей разработчикам всё равно надо проводить оценку своих задач.
Если чуть-чуть пояснить эти особенности, то мы платим им за время затраченное на задачу, если время затраченное сильно превысило оцененное, то к сумме будет применяться коэффициент вплоть до коэффициента 0,1.
smbody
21.12.2016 18:50Понятно. Тогда Вы очень рискуете.
Такой порядок работы с Заказчиком ставит Вас в полную зависимость от него. Если Ваша оценка времени не будет совпадать уже с его ожиданиями Вас очень легко «наказать» установив нужные ему коэффициенты. Причем не столько за невыполнение текущих задач, сколько за то, что Вы что-то сделали не так в предыдущих. Иными словами все взаимодействие с Заказчиком строится на личном доверии к Вам. Малейшее сомнение тут же Вашу красиво работающую систему разрушит. И сейчас как Вы сами говорите «выгодно если программисты будут ошибаться», значит эта система не для оценки качества их труда, а чтобы отчитаться перед Заказчиком.
Как многие наши коллеги советуют Заказчик должен платить за выполненную работу. И тогда в Ваших интересах будет сделать ее как можно быстрее. При этом итерации «согласование — работа — оплата» должны быть как можно короче.
Lofer
21.12.2016 00:57Команда сама приходит к мысли что им проще жилось бы с какой-то технологией/средством, они мне об этом говорят и обосновывают свою позицию. Если убеждают (обычно убеждают), то мы начинаем её использовать.
По идее это сугубо дело команды, а не кого-то со стороны. Хотя с точки зрения бизнес-рисков это имеет смысл.
Если то что они хотят поменять укладывается условно в 1 день, то я просто принимаю это решение.
…
Если же надо к примеру на неделю остановить процесс и всё переписать, то тут я более подробно анализирую что именно это нам даст и иду с этими данными к бизнес заказчику.
Странно. А заказчику эти подробности зачем? И почему остановить процесс? просто задачи помещаются в спринт и процесс идет дальше своим ходом.
По идее вмешиваться в спринт — не лучшая идея.Максимум что рекомендуется делать, это выкинуть задачу из спринта.
Если уж настолько и срочно меняется в течении спринта набор задач, то разумнее остановить спринт и начать заново, но предпочтительней — завершить текущий.nondead
21.12.2016 10:44- Из-за особенностей контрактования у нас команда работает над проектом 1 год, потом происходит тендер и его выиграть может та же компания или другая. Поэтому это дело не сугубо команды.
- Под остановить процесс я имел ввиду перестать на неделю к примеру реализовывать новые таски. А бизнес-заказчик по проекту Cofoundit очень часто тестирует гипотезы и т.д. И у меня (в проекте Cofoundit) нет полномочий самостоятельно принимать такие решение.
- О спринтах тут ничего не говорились. Если появилась задача на рефакторинг на 1 день это не значит что её начали в тот же день, это значит что она займет 1 день когда решим её взять (вероятно в следующем спринте)

Askofen
21.12.2016 19:22На мой взгляд, статья не про аджайл (который тут выглядит, как нечто «пришитое» сбоку), а:
- про декомпозицию (фичи нужно разбивать на подфичи, а технические задачи — на подзадачи);
- про контроль качества и выработку критериев приемки;
- про ревью (кода, декомпозиции, оценки).
theRavel
Вы вцелом молодец! Теперь после тюнинга процессов можно посмотреть на технические аспекты: я так понимаю деплой делается вручную? Пишутся ли модульные тесты?
nondead
Деплой на тестовые сервера как написано в статье автоматизировали. Деплой на прод делаем в ручном режиме, с учетом того что делаем это не чаще 2 раз в неделю с затратой около 1 часа времени не вижу смысла сейчас автоматизировать и этот процесс.
Модульные тесты пишутся, но покрывают далеко не весь код, а только наиболее важные и сложные модули.