
Здравствуйте, меня зовут Александр Зеленин, и я на дуде игрец веб-разработчик. Полтора года назад я рассказывал о разработке онлайн игры. Так вот, она немного разрослась… Суммарный объём исходного кода превысил «Войну и мир» вдвое. Однако в данной статье я хочу рассказать не о коде, а об организации инфраструктуры проекта.
Оглавление
- Я хочу спать спокойно!
1.1. Планирование стабильной архитектуры
1.2. Выбор сервера/дата-центра
1.3. Балансировка нагрузки
1.4. Мониторинг всего и вся
1.5. Связанный проект — отдельный сервер
1.6. Выбор сервиса службы поддержки - Как перестать беспокоиться и начать разрабатывать
2.1. Где хранить фотографии?
2.2. Настройка домашней сети
2.3. Стратегия резервного копирования и архивации
2.4. Свой dropbox
2.5. Виртуальные машины
2.6. Jira — Confluence — Bitbucket — Bamboo - Что в итоге?
- А что там с игрой?
Оглавление не отражает хронологию, хоть где-то она и будет совпадать. Это не how-to, не мануал и подобное. Это обзорная статья, призванная дать представление о том, что же кроется за небольшим проектом.
Практически каждый из пунктов имеет под собой довольно обширную историю (я намеренно сильно сокращал всё) и тянет на отдельную полноценную статью.
В случае, если данная статья окажется востребованной — постепенно напишу цикл, рассказывающий, как выбирать и настраивать те или иные инструменты.
Читать можно в произвольном порядке.
Важными факторами конечной инфраструктуры были: надежность и стоимость поддержания.
Обеспечение всего этого обходится нам менее чем в 15 тысяч рублей в месяц, большую часть из которых съедает VPC. А если пожертвовать стабильностью самого продукта и использовать более дешевый дата-центр, то можно было бы уложиться в 3 тысячи. Данные цифры учитывают амортизацию и замену неисправных элементов.
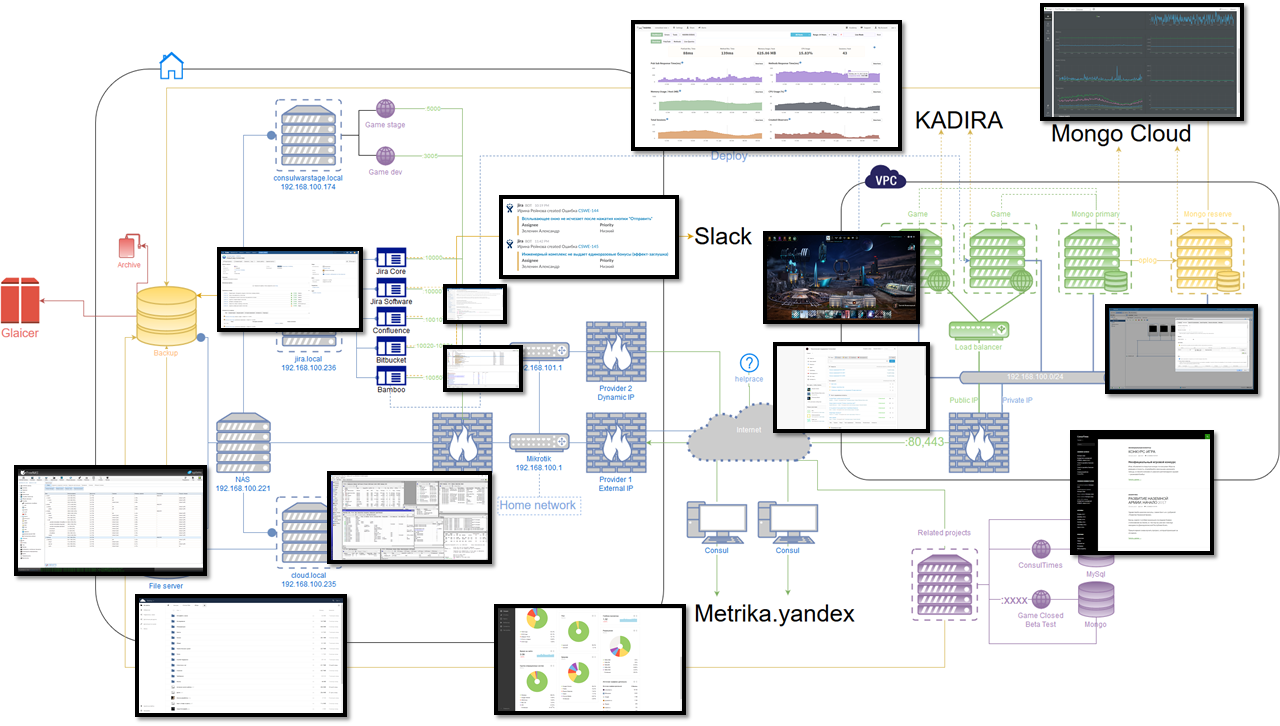
Я хочу спать спокойно
После очередного падения проекта в 2 часа ночи и восстановления работоспособности до утра стало ясно, что продолжаться так больше не может. И это рассказ о правой части схемы.
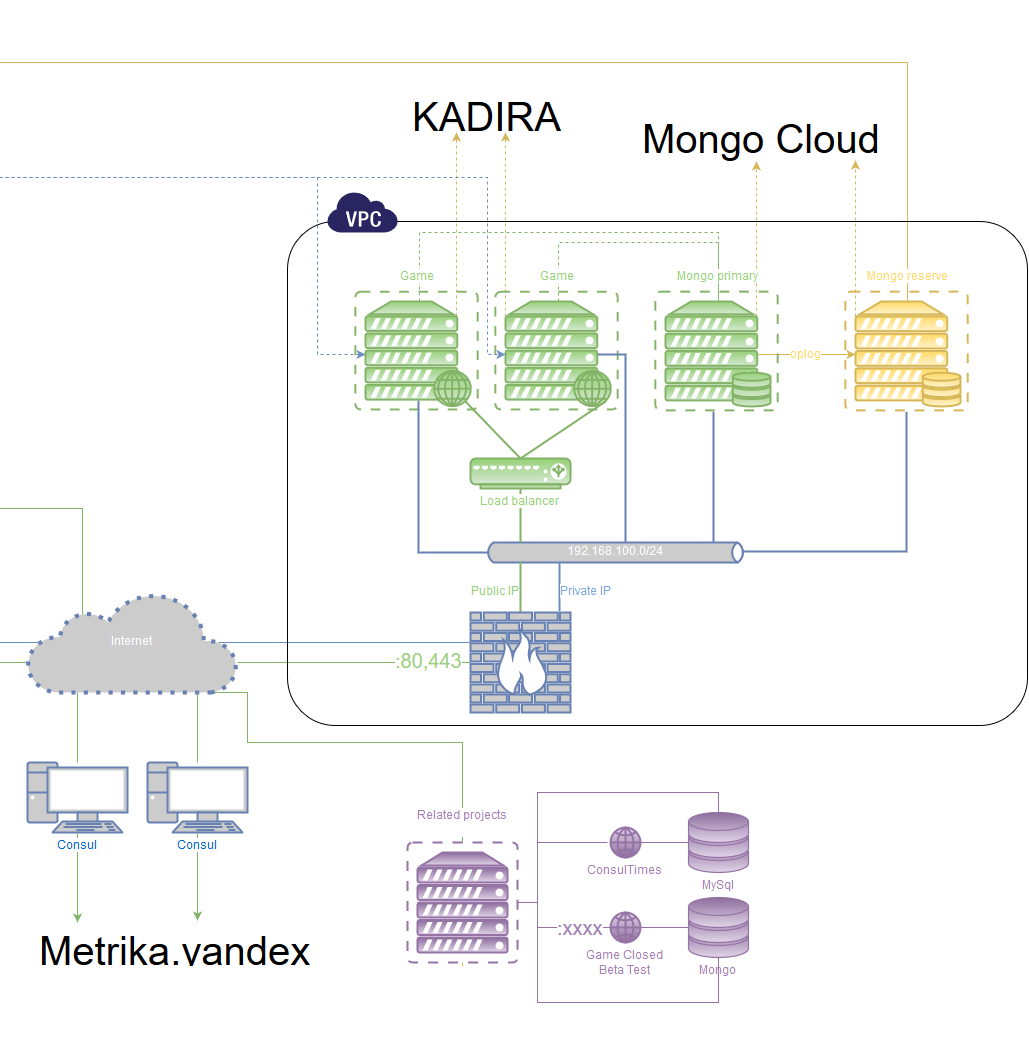
Планирование стабильной архитектуры
Хотелось сделать так, чтобы независимо от того что произойдёт, можно было спокойно спать и не волноваться, что проект вдруг станет недоступен по любой из причин, а потом уже в спокойной обстановке неспешно всё чинить. Попутно хотелось добавить возможность свободного горизонтального масштабирования.
Классический рецепт — это запускать несколько экземпляров приложения на различных серверах и на уровне выше направлять пользователя на работающее. Точкой синхронизации является база данных, так что она должна обладать не меньшей стабильностью, чем само приложение.
1) База данных: MongoDB
Запускается минимум на двух различных физических серверах. Одна является основной, остальные — вторичными.
Т.к. базы и приложения запускаются на различных серверах и имеется шанс произвольной недоступности, необходимо при восстановлении связи достичь полной корректной синхронизации данных. Для этого у MongoDB есть специальный механизм — для избрания сервера как основного необходима связь как минимум 50% + 1 сервера. Также мы хотим, чтобы в данном голосовании участвовали ещё и сервера с приложениями — вследствие того, что изначально планируется всего 2 сервера под базы (50% + 1 от 2 это те же самые два, т.е. недостаточно для голосования). Для этого у MongoDB есть специальный способ запуска экземпляра БД без самих данных, а только в режиме голосования (Arbiter). На каждый сервер с приложением дополнительно ставится такой Arbiter.
Дополнительный Arbiter запускается на сервере резервного копирования, расположенный вне дата-центра.
Итого имеем 2 сервера БД онлайн, и 5 арбитров (сервер БД тоже им является).
Теперь какой бы экземпляр БД не отвалился — другой становится основным, а отвалившийся переходит в read-only до восстановления связи. После восстановления связи и полной синхронизации он опять становится основным. Если по какой-то причине отваливаются второй сервер и сервер резервного копирования — все базы переходят в режим read-only.
Также необходим мониторинг (слежение за работоспособностью кластера): что он доступен, что данные на месте, что резервная копия в порядке, и так далее.
2) Приложение, Nodejs
Аналогично предыдущему — минимум два различных физических сервера. Все приложения равноправны, т.к. точкой синхронизации являются данные.
Этого удается добиться, т.к. приложения сами по себе не хранят никакие состояния, так что даже если один пользователь присоединится к разным экземплярам, это ни на что не повлияет.
На каждом сервере находятся минимум 2 экземпляра приложения, которые мониторятся и балансируются с помощью pm2 & nginx.
Сверху этого — мониторинг работоспособности.
Выбор сервера/дата-центра
Перед выбором необходимо определить, сколько же ресурсов потребляет наше приложение.
Т.к. я использую Meteor, то выбор тестирования нагрузки пал на MeteorDown. Проверять буду на домашнем сервере, выделив 100% ресурсов под приложение.
Сервер: Intel® Xeon® CPU E5-1620 v2 @ 3.70GHz (6 ядер), 32гб ECC DRR3 памяти.
Тестировать он будет сам себя, т.е. сеть не учитывается. Да, всё это даёт искажения, но приемлемые.
Пишутся сценарии поведения пользователей, генерируются наборы данных. Запуск! Нагрузка постепенно растёт, но при этом время ответа на методы держится стабильным. Тысяча онлайн, две, три, пять, шесть. Постепенно начинает расти время ответа. Семь — время ответа превышает полсекунды. Восемь — время ответа становится неприемлемо большим (10+ секунд). Упёрлись в CPU.
Шесть тысяч — это было в десять раз выше, чем пиковый онлайн. Значит, ориентируемся на в 2-4 раза меньшие параметры, но закладываем масштабирование.
1) Окончание закрытого бета-теста
Во время бета-теста регистрация была ограничена, соответственно, и онлайн тоже. Архитектура, описанная выше, ещё даже не была в проекте, т.к. до этого момента всё было достаточно стабильно. В это время всё приложение работало на одной KVM VPS'ке (4 ядра 2.2GHz, 4гб памяти).
К старту беты было решено переехать (у них же) на «Отказоустойчивый сервер» со стоимостью в два с половиной раза выше за аналогичные характеристики, но вроде как кучей гарантий, что оно всё суперстабильно и круто.
С запуском открытого бета-теста мы начали принимать платежи, так что обязательва наши возросли и простоев нельзя было допускать.
2) ОБТ
Запуск был вполне успешен, и вроде как даже всё работало неплохо. Как вдруг спустя пару недель, днём мне звонит друг и сообщает, что сайт недоступен. Окей, бегу домой. Вижу, что VPS'ка лежит от слова совсем. Пытаюсь перезапустить — безуспешно. Пишу в техподдержку — мне отвечают: крашнулся диск, восстановление через пару часов.
ШТА? В сраном описании «отказоустойчивого сервера» меня уверяли, что у них сервер и СХД располагаются отдельно, там всё супер дублируется и что будет 100% доступность.
Уточняю данные моменты и мне говорят, что компенсируют (та-да-да) 30 рублей! За 6 часов простоя. Отлично.
Окей, предположим, мне реально не повезло и произошло какое-то экстраординарное событие. Уточняю частоту подобных событий и шансы возникновения в будущем — заверяют, что всё будет отлично. Спустя два дня — падение в 4 часа ночи. Крашнулся диск, но в этот раз ещё и с потерей данных :-)
3) Первый переезд
Спасибо бекапам, потеря составила сутки (на тот момент был бекап раз в сутки), а за счёт истории транзакций у партнёра восстановить платежи не составило труда. Экстренно ищу альтернативу. Нахожу, проплачиваю и переезжаю.
Спустя недели три — ситуация практически аналогичная. М-да. Очень нетривиальная ситуация была для меня.
4) Tier 3, DataLine
Изучаю тему глубже: как же взрослые дяди решают такие вопросы? Чувствую, и нам пришло время повзрослеть.
Прорабатываю схему выше, ищу максимально надёжных хостеров и прихожу к тому, что выбор в РФ не такой большой. С маленькими проектами вообще почти никто из крупных игроков работать не заинтересован, кроме DataLine с их упрощённым вариантом CloudLite.
Договариваюсь с поддержкой о тестовом периоде и разворачиваю всё как задумал. Переносим домен.

Фух, вроде работает. Но как-то медленно. Запросы возвращаются около 300мс. Но при этом не было никаких скачков нагрузки, т.е. это было стабильные 300мс.
Решено было оставить так и понаблюдать несколько дней. В общем-то стабильность радовала, но вот заторможенность раздражала.
Начал разбираться в чём дело и сразу стало видно, что узким местом является диск — у нас очень тщательно записывается активность пользователя, и очередь записи была всегда. Оказалось, что в рамках CloudLite предоставляется только VSAN диски и переезд на SSD для устранения проблемы не возможен.
Альтернативой было запустить inmemory версию mongo с репликацией уже на диск, но тут было несколько но: mongo предоставляют полноценную версию in-memory только для энтерпрайз за (па-ба-ба) 15 тысяч долларов в год за один сервер. В моем случае это было совсем неоправданно, особенно в сравнении с альтернативными решениями для текущего уровня (переезд на SSD). Ещё был хитрый вариант с созданием memory раздела в linux и разворачивании БД туда, но я не любитель такого рода хаков, а просчитать возможные проблемы подобного подхода было проблематично.
В общем, надо было переезжать на SSD. У DataLine это доступно только уже с заключением договора и на иной платформе.
На ней мне также предоставили тестовый период. Развернул там всё заново, в этот раз задокументировав все шаги для последующей автоматизации. Повторный перенос домена… Ура! Всё работает быстро и как надо.
Постфактум хочу сказать, что очень рад этому переезду, т.к. ни одного простоя по вине DataLine не было (более 8 месяцев уже).
Был один интересный простой из-за глюка DNS (мастер зону я хостил всё ещё у первого хостера, т.к. там жили всякие другие мелкие проекты), который внезапно откатился на несколько месяцев. Ну т.е. просто стал DNS возвращать адреса старого сервера и всё.
Отловить эту ошибку было очень сложно, т.к. у кого-то работало, а у кого-то нет (у меня изначально работало). Но после сброса кешей DNS на роутере сразу стало всё видно.
В итоге домен тоже был перенесён на DataLine и пока (тьфу-тьфу!) работает без проблем.
Балансировка нагрузки
Итак, теперь у нас несколько серверов и ещё больше экземпляров приложений и надо как-то более-менее равномерно распределять пользователей по ним, чтобы добиться максимальной производительности.
Задача разбивается на два шага — балансировка до сервера и балансировка в пределах сервера.
1) Балансировка до сервера
Решается на уровне дата-центра. Все сервера с приложениями заносятся в пул, выбор же самого сервера идёт по двум параметрам: первое — это cookie, а если их нет, то IP hash. Затея в том, чтобы запросы от одного пользователя шли всегда на один и тот же сервер, так кеширование будет работать более эффективно.

Т.к. все сервера приложения равноправные, то и вес ставится одинаковый. Добавляем проверку доступности 5 секунд.
Готово.
Теперь запросы пользователей достаточно хорошо распределяются на сервера, а в случае, если один из серверов перестаёт быть доступен, то в течении 5 секунд пользователя переводят на другой.
2) Балансировка в пределах сервера
Тут есть несколько вариантов. Т.к. я использую pm2 для запуска nodejs процессов, то возможен вариант запуска необходимого количества экземпляров приложения (по числу ядер) в cluster режиме, который уже будет разруливаться нодой. Минус данного подхода в том, что механизм sticky sessions не работает, но т.к. мы держим socket подключение, то переключение на другой экземпляр приложения возможно только в случае обрыва. В нашем случае это не доставляет проблем.
Второй вариант — это запуск приложений в fork режиме на разных портах и проксирование на них через nginx. Плюсом тут является то, что nginx может ещё и статику раздавать, да SSL сертификат (SSL до сих пор не подключил, кстати, но скоро дойдут руки).
Прописываем в конфиге порты приложений, готово.
3) Проверяем
Проверяю нагрузку на серверах и вижу, что она равномерно распределилась. Отлично!
Мониторинг всего и вся
Как и во всех задачах сперва пытаемся понять, какие данные мы хотим собирать:
- Данные о работоспособности приложения, нагрузке на него, ошибках и так далее.
- Данные о работоспособности базы данных, размер данных, репликация, лаг и так далее.
- Данные о пользователях, устройства входа, разрешения экрана, источники переходов и прочее.
- Данные о действиях в игре.
1) Kadira.io
Во-первых, хочу отметить, что данный сервис, к сожалению, скоро прекратит своё существование — он оказался нерентабельным. Но разработчик обещал выдать исходные коды и информацию, как развернуть всё это у себя. Так что, видимо, инфраструктура проекта ожидает пополнения.
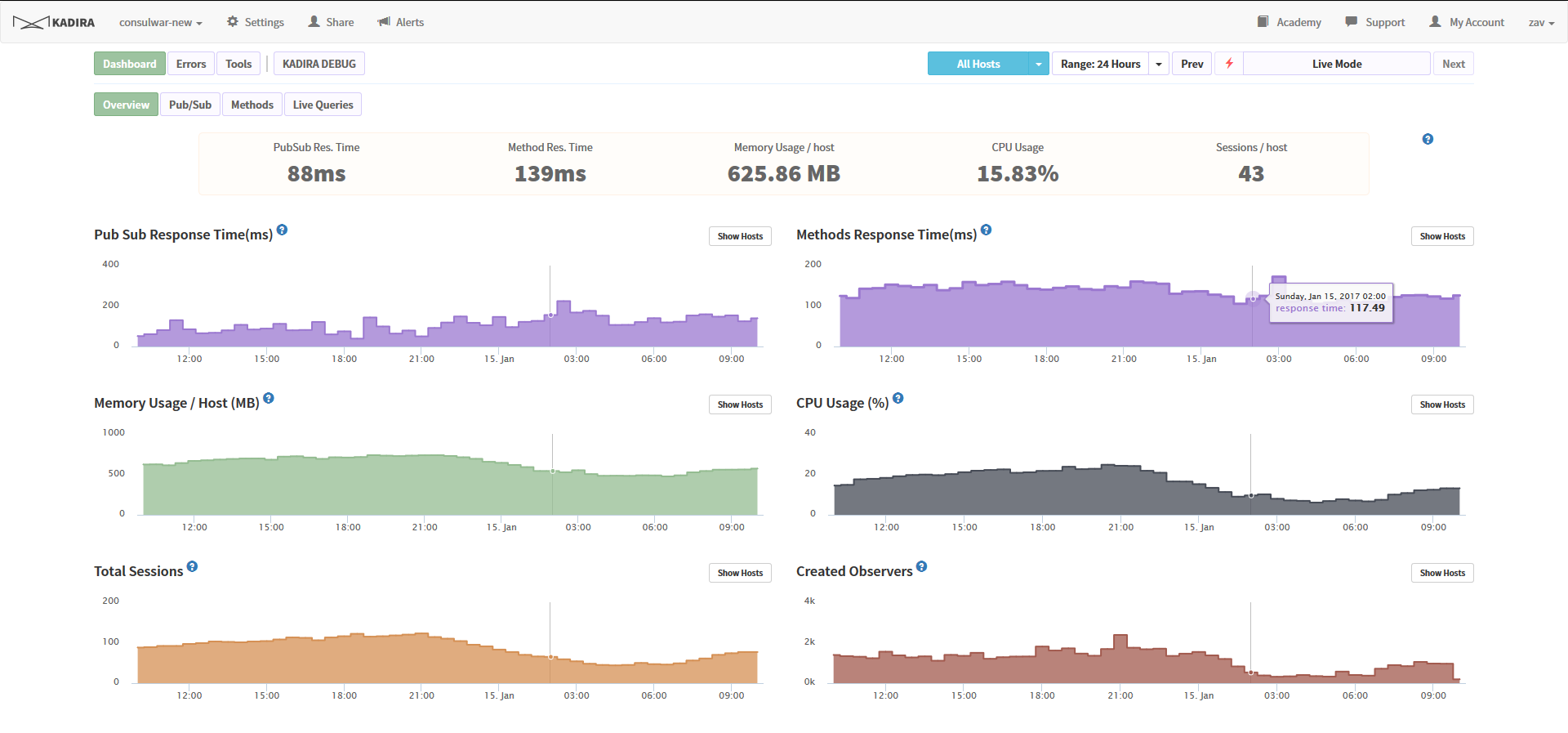
Изобретать велосипед незачем, когда есть замечательные готовые инструменты. Интеграция с приложением представляет из себя всего лишь установку модуля из пакета и прописывание двух строк в конфиге. На выходе получаем мониторинг ресурсов, профилирование тяжёлых запросов, монитор текущей активности, анализатор ошибок и ещё кучу всего.
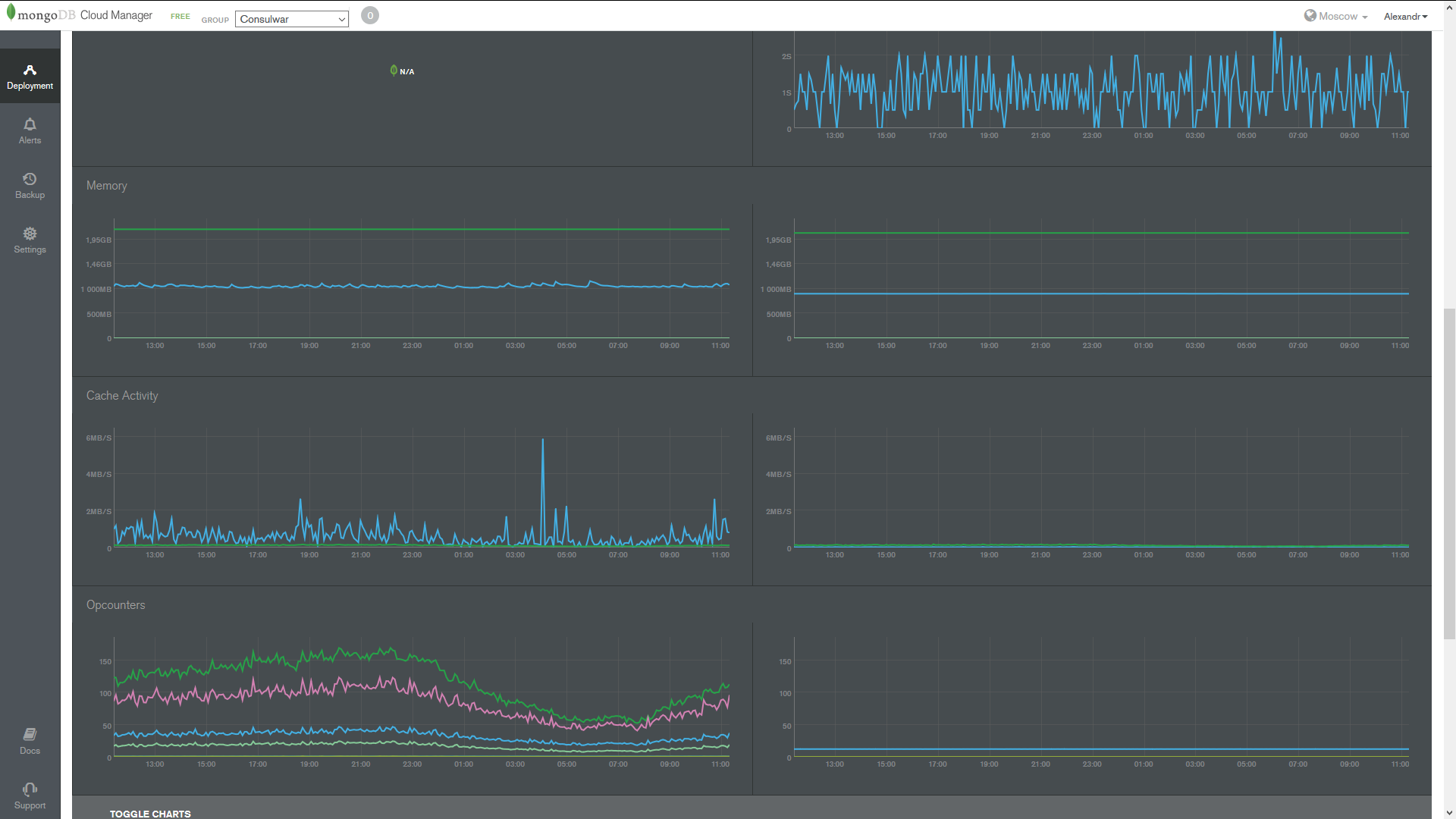
Интеграция не многим сложнее, но ставится на сервера БД, а не приложения, соответственно. Ставим модуль, запускаем watch'еr.
Тут же на месте мониторим ресурсы сервера БД, видим время запросов, лаги репликации, советы обновить БД.
Довольно крутая штука тут — это моментальное информирование в случае недоступности БД на почту.
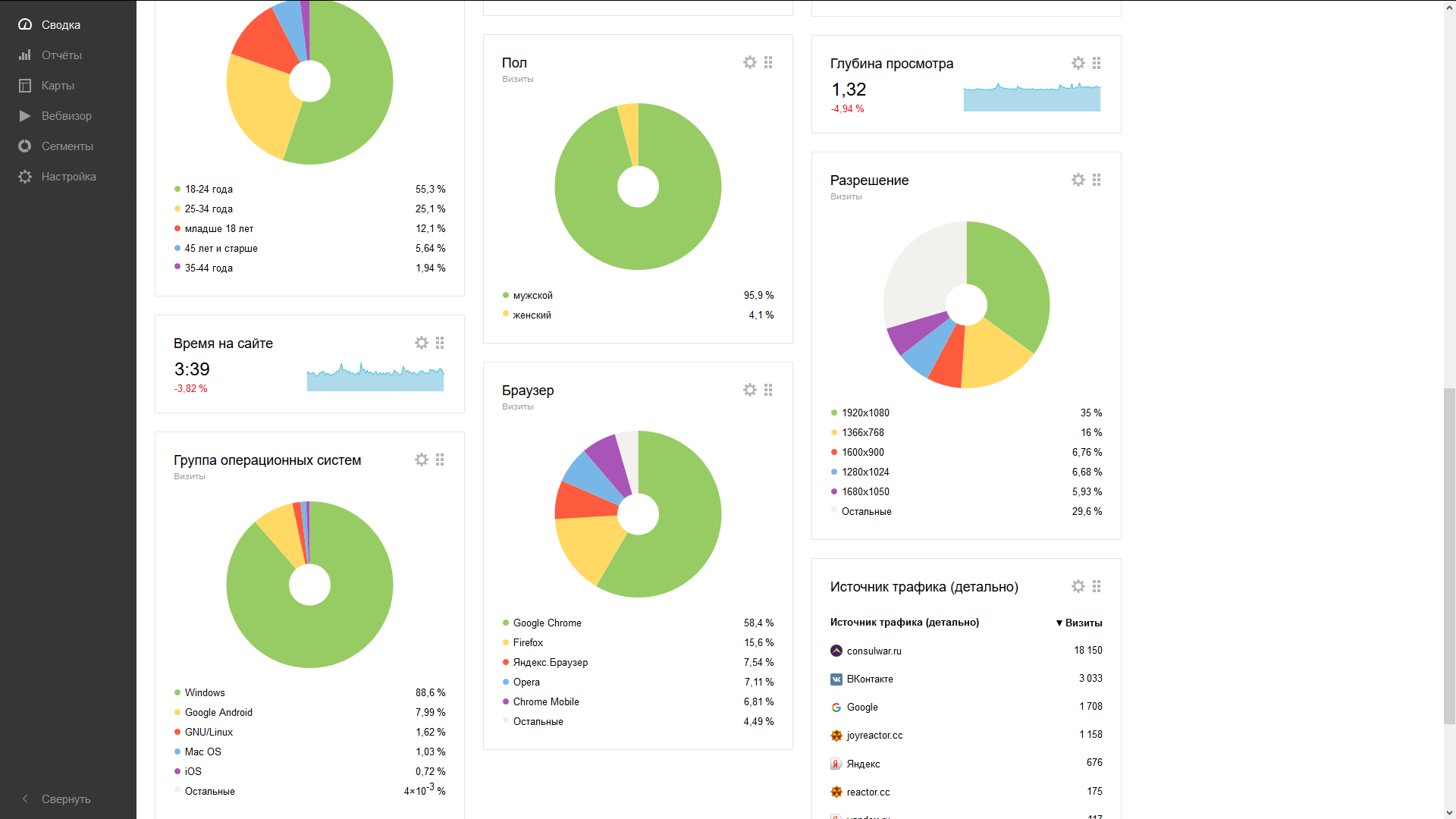
Интеграция чуть сложнее, чем Kadira, т.к. помимо установки модуля необходимо модифицировать приложение, чтобы оно информировало скрипт метрики о переходах по страницам (в SPA не всегда очевидно, какие мониторы надо мониторить, потому сделано так). Добавляем нужный код в роутер, и готово: пол, возраст, переходы, посещения, устройства и так далее. Всё в одном месте. Удобно!
4) Действия в игре
Записываются в базу данных приложения, само собой. Впоследствии можно настроить, чтобы старые данные, необходимые только для анализа, переносились на отдельный сервер. Для подобного у монги тоже есть инструменты.
Связанный проект — отдельный сервер
Со временем проект обрастает различными дополнениями. Например, у нас была газета, которую сделали сами пользователи. Изначально она была создана и размещена где-то у себя одним из игроков, но потом резко закрылась и игрок пропал. Было решено развернуть у себя аналог на wordpress и дать возможность модераторам публиковать там статьи на околоигровые темы.

Само собой, на существующем сервере нельзя запускать подобное хотя бы из соображений безопасности.
Второстепенные сервера было решено размешать у более дешёвого провайдера, т.к. их доступность некритична.
Хотя всё равно был выбран хостер, арендующий мощности в тир 3 дата-центре.
Выбор сервиса службы поддержки
Необходимо также публичное место для сбора информации об ошибках. Оптимальным вариантом виделась возможность сбора предложений от игроков и голосования по ним. Совсем опционально — публикация логов изменений тут же. Очень желательна была возможность бесплатного размещения для маленьких компаний или до какого-либо лимита.
Я перепробовал около трёх десятков систем и в итоге остановился на helprace.
Прямо будто бы под запрос сделана. Вообще, у них есть интеграция с внешним логином, но только в платной версии. Т.к. одной из целей было сэкономить на стоимости содержания, регистрацию у нас система требует отдельно.
Аудитория всегда очень радует — сотни сообщений об ошибках, горы предложений и пожеланий. Иногда даже проскакивает сдержанная похвала игре и разработчикам :-)
Как перестать беспокоиться и начать разрабатывать
А это рассказ о левой части схемы.
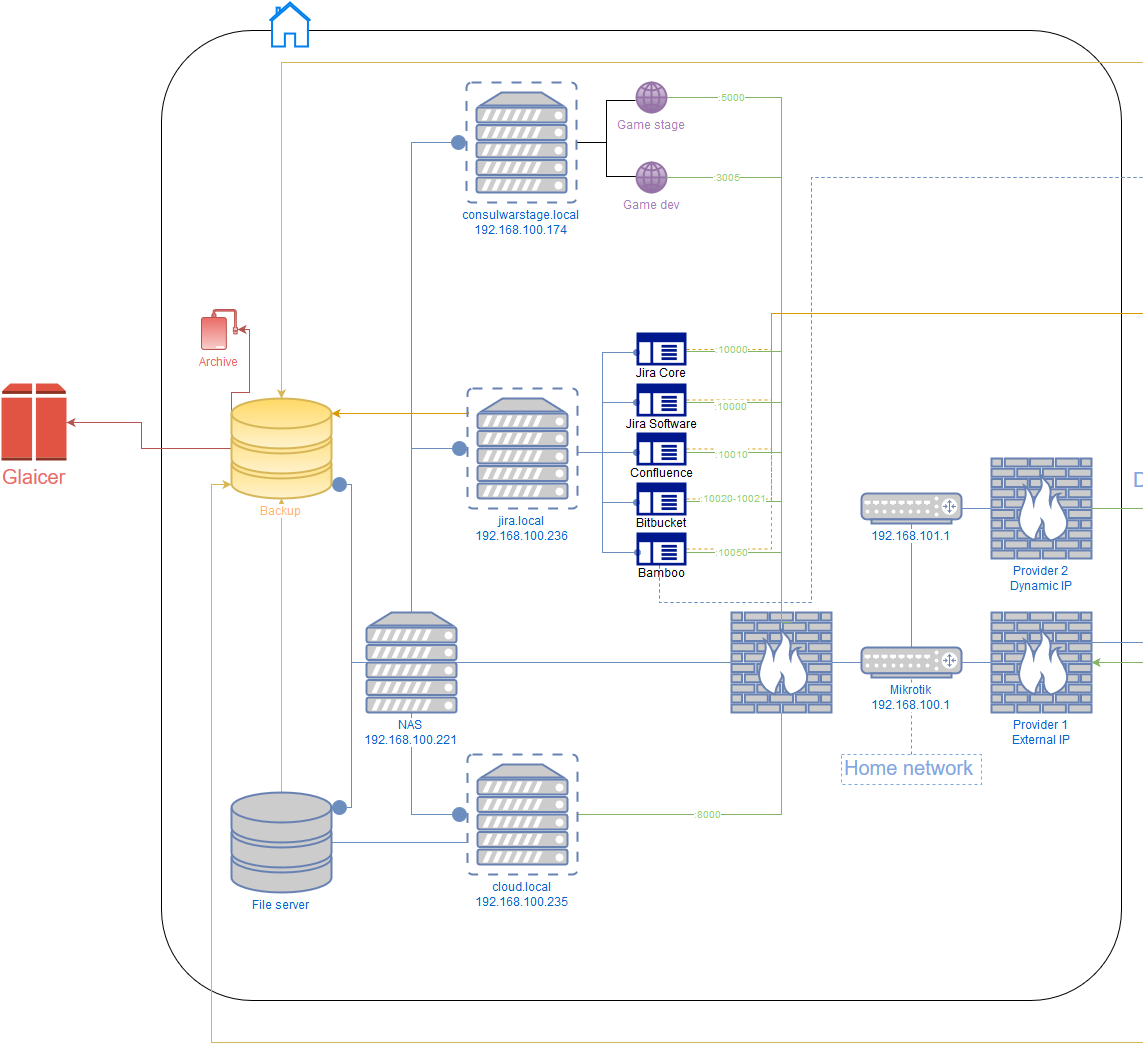
Где хранить фотографии?
Немного странный заголовок в рамках данной статьи, но именно этот вопрос повлёк за собой появление домашнего сервера.
Перед поездкой в Индию прямо в последний день дёрнул меня чёрт сходить почистить матрицу на Canon D350 в авторизованный центр. Там «мастер» грязной хреновиной поцарапал матрицу в хлам. До самолёта было менее 8 часов, так что времени на разборки не было, надо что-то решать. По отзывам нашли хорошую точку на вокзале, приехали туда, отдали мастерам (терять-то уже нечего). Ребята покрутили, спросили: «что с матрицей случилось :-)»?.. Почистили как-то хитро и вроде стало даже приемлемо (фотографии из Индии сделаны именно на эту камеру), за что им спасибо.
Но вот по приезду домой снимать я стал мало, т.к. всякие неприятные пятна на фотографиях были и портили даже очень удачные кадры.
Пришло время брать новую камеру, да уж по-серьёзному сразу — FullFrame. Сперва выбор пал на Nikon D800. 37 мегапикселей… Мама дорогая, это же сколько raw весить будет? 50-100 мегабайт! (В итоге, кстати, взял D750 с гораздо более приятным весом raw'ок.)
Мне нравится сохранять архив (удаляя только дубли и совсем неудачные кадры), и со временем стало ясно, что просто домашнего компа мало. При таком весе это 12000 фоток на терабайт. Кажется, что это много, но на самом деле это несколько лет не очень активной съёмки. Для понимания — за прошлые года архив перевалил за 50 тысяч фотографий. И да, иногда для некоторых задач я возвращаюсь к своему фотоархиву, чтобы найти нужную.
Немного погуглив, я понял, что NAS придуманы именно для этого. Потом натолкнулся на ZFS и понял, что он замечательно обнаруживает проблемы, которые у меня уже происходили несколько раз:

(Забавно, что картинку с ошибкой загрузить так и не удалось, пришлось делать скриншот и вырезать.)
Отследить такие проблемы сложно. Они ещё вполне успешно могли улететь в бекап и продублироваться в рейде.
Меня ещё спасло то, что NASы нифига не были доступны в моём городе (Калининград), хотя сейчас ситуация уже немного получше.
После очень долгого анализа (в целом на решение задачи в заголовке ушло более 200 часов) было решено собрать свой сервер и поставить туда FreeNAS.

В общем-то, собирал сразу надолго, и потенциально система расширяется до петабайта хранилищ и половине терабайта оперативки. На текущий момент там всего 12 терабайт места и 32гб памяти. Общая стоимость вышла сравнимо или дешевле готовых NAS решений (от 4 дисков), при этом гибкость и потенциал намного выше.
Настройка домашней сети
Тут же сразу стало очевидно, что старенький dir-300 просто не позволит мне комфортно работать с сервером. Даже если взял и пошёл пофоткать немного, снял 200 кадров и начал сбрасывать (200 * ~75) 15гб, то сам процесс копирования занял бы около 20 минут! Подумаем, какая скорость нам нужна? Судя по тестам, диски в планируемой СХД WD Red выдают 100-150 мегабайт в секунду, значит, гигабитного канала нам хватит при эксклюзивном использовании. А если сразу два пользователя? Например, кто-то из семьи решит фильм в HD 4k посмотреть (с другого физического диска)? Значит, до сервера должно идти минимум 2 канала.
После анализа рынка стало ясно, что надо брать MikroTik. Выбор пал на CRS109-8G-1S-2HnD — восемь гигабитных портов и невероятная возможность конфигурирования.
Непрерывность доступа
Меня очень расстраивало, когда недоступность сети по вине провайдера (Привет, Билайн!) лишала меня возможности работать. (Ну да, есть ещё мобильный интернет, но это вообще даже близко не комфортная работа, особенно при том, что он тут нифига не ловит и тоже требует отдельного решения в виде внешней антенны.)

В нашем подъезде работают два провайдера — Билайн и Ростелеком. Сперва необходимо было настроить их отдельно, с чего я и начал.
Ох уж эти пляски подключения Билайна на роутерах микротик! С бубном и плясками удалось подключить, но нервов и времени скушало много. Плюс таки требуется иногда ручная донастройка, т.к. решения с постоянно запущенным скриптом на роутере мне не нравилась от слова совсем. Билайн в подъезде, кстати, тоже с микротика всё раздаёт, что было вдвойне удивительно.
А Ростелеком тянет оптоволокно до квартиры (Вилы этому маркетологу!), так что без дополнительного роутера не обойтись. Ну а роутер связать с микротиком вообще проблем не составило, т.к., по сути, это просто сеть.
У Билайна за дополнительную плату был приобретён (ещё давно) внешний IP, который я всегда использовал в качестве одного из средств авторизации и для доступа ко внутренним ресурсам.
А вот для того, чтобы это всё заработало вместе и одновременно, пришлось подтянуть знание сетей и пакетов. Для более-менее простой настройки и понимания, что происходит, советую ознакомиться с презентацией Bandwidth-based load-balancing with failover. The easy way.
Публичный доступ к внутренним ресурсам
На сервере будут некие ресурсы, доступные из внешней сети. Как этого добиться? Как упоминал выше, у меня есть внешний IP. На внешний IP ссылается универсальный поддомен вида *.home.domain
Есть несколько вариантов разруливания: layer 7 или по порту.
Изначально я настраивал его с использованием layer 7 на роутере, проверяя что же там за звёздочкой и направляя куда надо, но быстро выяснилось, что подобное использование очень сильно нагружает процессор роутера. С учетом того, что ресурсы будут использоваться только небольшим кругом лиц, решено было использовать более дешёвую адресацию по портам.
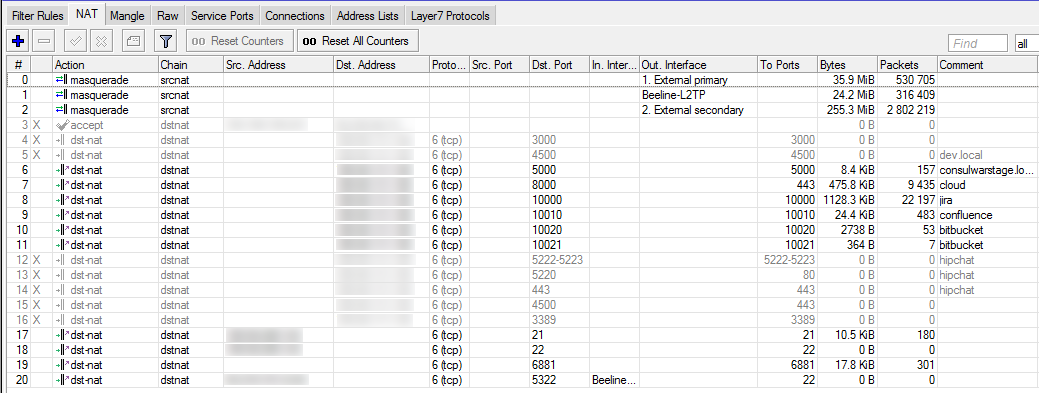
Прописываем правило в фаерволе, разрешающее подключение на определённые порты на внешний IP, добавляем в NAT правило-связь с внутренним ip и портом… Работает! (Кстати, при работе двух подключений необходимо, чтобы ответ шёл через того же провайдера, на который пришёл запрос. Это называется sticky connections и описано в той же презентации.)
Полный доступ
Допустим, что мы уезжаем на какое-то время в другую страну. Как получить полный доступ, как будто я нахожусь внутри сети? Конечно же, нужен VPN.
На роутере запускаем VPN сервер, добавляем его в bridge, создаем пользователя — готово. Без какого-либо дополнительного ПО создаётся подключение.
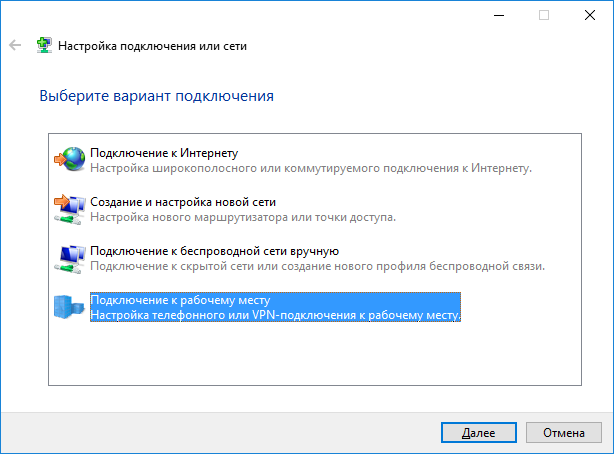
Стратегия резервного копирования и архивации
Начнём с разделения ценности хранимой информации. Выделим три градации:
1) Легко восстанавливаемая информация (музыка, фильмы).
2) Некритичная, но неприятно терять (фотографии).
3) Важная, невосполнимая информация (рабочие файлы, резервные копии).
Изначально я брал 4 диска как раз под различные типы: часто используемая информация (media), фото (photo), рабочие файлы (work), бекап (backup).
Первый слой:
Настраиваем создание ежедневных снимков для разделов work и некоторых подразделов media.
Создаем задания репликации снимков на раздел backup в отдельные подразделы.
Для раздела photo временно используем схожую стратегию, пока диск backup заполнен менее чем на 50%. После заполнения диска стратегия будет пересмотрена в пользу переноса только полноразмерных jpg для экономии места. В этом случае фотографии как минимум остаются, но теряется возможность полноценной постобработки.
Для большей части media резервное копирование не настраивается, т.к. всё восстанавливается из открытых источников.
Второй слой:
Создаём jail, даём ему read-only доступ к разделу backup. Настраиваем программу для копирования в Amazon Glaicer на сохранение снимков work и других важных, а также на сохранение jpg'ов фотографий раз в неделю.
Третий слой:
Раз в месяц делается полное копирование на внешний жесткий диск, после чего последний кладётся на полку в дальней от сервера комнате квартиры. Всего таких диска два — они чередуются. Т.е. в архиве я храню только два последних месяца. Архив, в данном случае, используется только в случае потери информации.
Что имеем в итоге? Чтобы потерять важный данные, надо очень постараться. Файлы хранятся минимум в 5 экземплярах: оригинал, бекап, глейсер и два архива.
При этом фактически занимается места не много, т.к. мы грамотно выбрали, что именно хранить.
Свой dropbox
Собрав такую махину, было бы упущением не предоставить доступ близким и друзьям для безопасного складирования файлов. Само собой, одно из применений — это работа с коллегами над проектом. Owncloud — наше решение.
Создаем jail и устанавливаем по инструкции. Пробрасываем в jail внешний раздел для хранения файлов и резервной копии мета-информации. Настраиваем резервное копирование owncloud в проброшенный раздел.
Добавляем правила в роутер для доступа извне. Создаем пользователей. Сохранность файлов гарантируем схемой выше.
Виртуальные машины
Нужна возможность легко разворачивать тестовые окружения, рабочие пространства, различные инструменты.
Virtualbox — простой и знакомый всем инструмент отлично подходит. А ещё устанавливается в пару кликов, т.к. готовый шаблон для jail phpvirtualbox уже вшит во FreeNAS.
Пробрасываем несколько рабочих разделов в virtualbox так, чтобы нам они были доступны как сетевой ресурс от freenas, а не от машин по отдельности, для удобства работы.
Создаем первую машину, на которую устанавливаем ту же самую ОС, что и будет на боевом сервере, стараясь сконфигурировать максимально похоже. Ставим туда git, nodejs и прочее, что необходимо для функционирования проекта. Разворачиваем проект, запускаем, проверяем работу. Всё ок? Останавливаем машину, создаем образ — теперь мы можем его использовать, чтобы быстро создавать дополнительные тестовые окружения для нас или сотрудников в один клик.
Тут можно рассказать про замечательный Docker, но у меня как-то исторически сложился сугубо негативный опыт работы с ним. Сам ни разу не настраивал, но каждый раз, когда приходил в проект и говорили: «У нас тут Docker, развернуть окружение — дело получаса», в итоге всё затягивалось в лучшем случае дня на три, а потом и сами разработчики признавались, что докер у них никогда не работал. Повторюсь — вероятно мне просто не везло в этом плане, и рано или поздно кто-нибудь меня таки впечатлит его использованием, но пока что у меня и так реально развертка в 1 клик :-)
Jira — Confluence — Bitbucket — Bamboo
Изначально для планирования и простого взаимодействия мы использовали RealtimeBoard, но он довольно быстро разросся. Необходима была платформа для постановки и ведения задач.
Сперва у нас появился GitLab, в котором есть возможность ведения задач. Через какое-то время стало ясно, что банально состояний задачи недостаточно для удобной асинхронной работы и взаимодействия друг с другом без постоянного дёрганья.
Я всегда думал, что Jira и весь пакет стоит каких-то там тысяч долларов, и затрачивать подобные суммы для ещё незапущенного проекта в мои планы никак не входило. Но абсолютно случайно наткнулся на то, что для команд до 10 человек каждый из продуктов стоит всего 10$. В итоге всего за 60$ был взят полный комплект инструментов.
Jira
И в этот момент я понял, что не зря в крупных компаниях есть отдельная должность — «жировод».
Для конфигурации запроса необходимо прописать хренову кучу параметров на более чем 20 экранах.
Запрос — это когда вы жмёте «Создать задачу». И вот для типа, например, «Ошибка»:

1) Создаем бизнес-процесс, называем его «Ошибка».
2) Создаем 6 статусов внутри: Открыт, В процессе, Не воспроизводится, Проверка кода, Ожидает вливания в мастер (попадание в мастер у нас означает выкатку на продакшен), Готово.
3) Каждому статусу проставляется одна из категорий: Сделать, В процессе, Выполнено.
4) Создаются необходимые переходы между статусами. Переход может иметь: отдельный экран (появляется, когда инициируем его вручную), свойства, триггеры, условия, валидаторы, post-функции. В данном примере 10 переходов.
5) Большинство переходов имеют свой экран: при создании задачи заполняется информация о самой задаче, когда задача берётся в работу, можно проставить оценку времени и дополнить информацией, если не удалось воспроизвести — поясняются условия или причина (например, уже исправлено в другом месте).
6) На некоторые переходы настраиваются права, чтобы только тимлид проекта мог их делать (например, влить в мастер).
7) Некоторые переходы только автоматические. Например, «вмерджено в dev» инициируется через триггер от bitbucket, когда ветка, в которой был коммит с тегом текущей задачи, вмерджена в dev. Для перехода в статус «проверка кода» необходимо создание pull request'а в bitbucket'е из ветки с нужным коммитом.
8) Создается тип запроса — «Ошибка».
9) Тип запроса «Ошибка» помещается в схему типов запроса.
10) Создаётся схема бизнес-процесса, например, «Разработка ПО».
11) Бизнес-процесс «Ошибка» помещается в схему бизнес-процесса со связью с типом запроса «Ошибка».
12)…
13) ???
999) Profit!
Я написал только часть этапов. На деле их гораздо больше :-) Хотя результат, в итоге, того стоит. Коректная система прав, автоматические переходы и экономия времени.
Confluence
Вот тут всё ощутимо попроще. Единственное, что приложение надо было связать с основным сервером Jira, чтобы оттуда и управлять всеми правами.
В целом это довольно уютный текстовый редактор, интегрированный с Jira. Множество действий вызывает автоматическое создание страниц в нём с кучей информации. Например, при закрытии спринта в Jira автоматом создается ретроспектива с информацией по закрытым задачам и затраченным ресурсам. Удобно!
Также используется для ведения документации проекта.
Bitbucket
Git репозиторий, Код ревью и всё в таком духе.
Устанавливаем, интегрируем с Jira, связываем с соответствующим проектом.
Настраиваем protected ветки master и dev. Запрещаем force в них, запрещаем влив без проверки кода минимум 1 участником проекта. Вливать в мастер может только владелец проекта. Влитие запрещено, если не пройдены тесты.
Bamboo
После Gitlab CI ощущение было примерно такое же, как при переходе на Jira — будто бы сел в звездолёт.
Куча ненужных, на первый взгляд, настроек, но, по факту, после настройки этот инструмент становится ультимативным.
Например, теперь с помощью него я могу с нуля развернуть ещё один инстанс приложения или базы данных в 1 клик, только указав логин и пароль от целевого сервера.
Настраиваем необходимые триггеры: на пуш любой ветки запускаем тестирование кода, на пуш в dev запускаем дополнительно деплой на stage сервер и прогоняем дополнительные тесты, при пуше в master запускаем деплой в продакшен, тесты, проверяем, что деплой успешен, а в случае провала откатываем до предыдущей версии. Доволен :)
Интеграция со Slack
Мы в команде используем Slack для общения по рабочим вопросам, т.к. он вполне удобен для подобных задач и предоставляет много различных удобных инструментов.
Одной из его фишек является интеграция со сторонними сервисами. Хочется, чтобы важная информация лилась в отдельный канал, информация по билдам — ещё в один. Нотификацию в каналах отключаем, чтобы не отвлекало зазря. Запушили код, глянули в слак > видим результаты тестов. Удобно. Откомментили твою задачу? Слакбот уже стучится к тебе.
Конечно же, вся важная информация приходит и на почту, но возможность посмотреть всё комплексно за день в одном месте экономит какое-то время.
Что в итоге?
В итоге можно спокойно спать, т.к. в случае различных непредвиденных ситуаций все важные системы продолжают работать, а уж если что-то совсем непонятное произойдет, то как минимум всегда есть возможность восстановить все утерянные данные.
У нас есть надёжное сетевое хранилище. Пользователи довольны стабильностью и скоростью работы. Мы знаем, что происходит на всех узлах системы, и можем их независимо улучшать.
В случае необходимости мы можем быстро наращивать мощности, просто добавляя сервера в пару кликов.
Мы можем обслуживать запросы пользователей (ошибки, идеи, предложения, вопросы), и быть уверенными, что ничего не будет потеряно или забыто. Мы видим темп нашей работы и можем корректно её планировать. Процесс разработки устроен так, что код проверяется несколько раз, в том числе и живым человеком.
Мы можем вводить новых членов команды и быть спокойны — их действия ничего не сломают.
А что там с игрой?
А игра всё ещё в стадии открытой беты, и сам геймплей пока далёк от текущих планов, но мы к ним двигаемся. То, что выходит, нам очень нравится. Надеемся, что и игрокам тоже :) Сейчас идёт активный редизайн, отчего некоторые экраны немного поехали, зато другие сильно лучше того, что было раньше.

Честно говоря, я думал, что это будет совершенно небольшая обзорная статья, а вышло вот оно как.
Повторюсь — абсолютно каждый из пунктов достоин статьи (или даже цикла) аналогичного объёма.
Как только появится время и подходящее настроение — всё оформлю. Прошу простить за некоторые неточности — многие вещи писались по памяти, а времени прошло уже много. При подготовке подробных статей уже будут точности :)
Ну и, если дочитали до конца, то вы — молодец. Спасибо за это.
Комментарии (46)
Gorniv
16.01.2017 14:15+3Всегда интересно прочитать про внутреннюю инфраструктуру работающих приложений\сервисов\компаний, особенно без больших бюджетов и с описанием, почему именно так(на какие грабли наступали). Надуюсь на цикл статей.

Zav
16.01.2017 14:22Спасибо.
На самом деле почти всегда есть варианты «чем платить» — деньгами или временем.
В случае если есть много опыта, то затраты времени сокращаются и могут перекрывать финансовый вариант :-)

Latnok
16.01.2017 15:16Однозначно полезная публикация. Очень хочется подробностей про развертывание (pm2, bamboo и т.д.). Заранее благодарю.
Zav
16.01.2017 15:18Сама по себе развёртка приложений не представляет сложности — манулы достаточно подробны.
А вот дальнейшая настройка сложна. Если по этим моментам будут статьи, то уже больше по использованию.
Там есть специфика при развертывании на крупные компании, когда тысячи сотрудников. Вот в таком случае там это не так тривиально. Но подобного опыта у меня нет.
kernel72
16.01.2017 15:50Очень интересная статья, спасибо!
Не совсем понял, про Mongo. Вы используете Sharding или просто репликацию или sharding с репликацией?Zav
16.01.2017 15:51Вам спасибо :-)
На текущий момент используется исключительно репликация.
Шардинг будет использоваться когда объемы данных будут влиять на скорость хоть сколько то значимо, для выноса «архивной» части. Пока такой необходимости нет.
lehnh
16.01.2017 18:30Роутер надо было брать 3011, он на 20$ дороже, но в несколько раз производительнее.
Zav
16.01.2017 18:32Производительности данного роутера достаточно что бы решить поставленные задачи и иметь ещё пласт мощности сверху. При куче правил, условий и прочего нагрузка на роутер не увеличивается более чем на 10%. Т.е. у меня ещё 90% неиспользуемой мощности :-)
lehnh
16.01.2017 19:53Хм, у меня одна только раздача торрентов мегабит на 200-300 прогружает роутер на ~20% плюс всякие ipsec к виртуалкам, впн для доступа в домашнюю сетку и тд. Запас производительности еще большой, но предыдущей платформы на 2011, которая даже чуть-чуть быстрее Вашей, мне уже не хватало, 600 мбит для нее потолок при 30-40 правилах. Хотя об объема трафика и количества конектов конечно зависит)
Zav
16.01.2017 20:07Предполагаю что у вас всё организовано через bridge, а не через мастер-порт.
По сути ощутимые затраты идут только на установление соединения, а сами данные очень быстро бегают и правила не проверяются каждый пакет.lehnh
17.01.2017 12:20Конечно через мастер порт, все соединения с не-туннельными шлюзами через fast track. Я внимательно читаю документацию и по роду занятий хорошо понимаю, как оно устроено внутри :) Проблема в том, что даже с фасттрэком ~700МГц мипс не может переваривать больше 600 мбит трафика с натом.
Именно по этому у микротика все не сохо модельки масштабируются с помощью увеличения количества ядер и частот.Zav
17.01.2017 12:38Я через внешний канал, через NAT то бишь, не гонял такие объемы и не планирую пока что.
Спасибо за пояснения, в случае необходимости теперь буду знать :-)

RouR
16.01.2017 19:36Slack.
Откомментили твою задачу? Слакбот уже стучится к тебе.
Стучится в личку или в свой канал пишет?
У нас тоже слэк, но так и не получилось найти бота, который бы писал в личку что «вот эта задача назначена на тебя». Остановились на том что весь поток событий льётся в канал, который никто не читает, т.к. нет персонификации.
Если эту проблему решили, то прошу рассказать детали.Zav
16.01.2017 20:01+1У меня несколько проще задача, т.к. он пишет в личку только мне :-)
С ходу нашел несколько вариантов решения. Вот один, в лоб:
на каждого пользователя создается дополнительная slack конфигурация, которая шлёт то что надо, и указывается конкретный пользователь. По сути эту операцию можно делать при найме сотрудника и она совсем не трудоёмка, особенно если как-то автоматизировать.
Возможно, есть решения лучше :-)

thunderspb
17.01.2017 17:07Может я чего не понимаю, но для того, чтобы в канал написал используется #channelname, для лички someusername?
Также можно в сообщении упомянуть ользователя, тогда ему подругому нотификация в трее придет.
зыж ботами не пользовался, через curl все работает как часы.lehnh
17.01.2017 17:54Если мне не изменяет память, не все так просто. Сначала надо зайти на общий канал, получить список всех пользователей, а потом уже из списка получить id нужного пользователя, и ему писать сообщение.
thunderspb
17.01.2017 18:06ну естественно, что нужно знать имя пользователя. тут уж зависит от реализации… самое простое заводить в слаке пользователя с таким же логином, что в <вашсписокпользователей>ю Сложнее и, видимо, дороже — сделать авторизацию в слаке через вашу систему.
lehnh
17.01.2017 18:51Я про то, что обратиться напрямую по имени/логину/емейлу — нельзя (хотя могу и ошибаться, точно не помню). А только из общего списка по емейлу (допустим) получить id и уже через него писать личное сообщение.
thunderspb
17.01.2017 19:04Смутился, только что проверил — все работает
curl -X POST --data-urlencode 'payload={"channel": "@myusername", "username": "HostWatcher", "text": "This is posted to DM and comes from a bot named HostWatcher.", "icon_emoji": ":ghost:"}' https://hooks.slack.com/services/YOURTOKEN
Правда пришло в канал slackbot'a, но сдается мне, что это фича :)
Zav
17.01.2017 17:56Да тут много тем же.
Банально надо что бы какой-то механизм соотнёс имя в слаке с тем что в жире.
Можно делать как выше написал или бота своего писать или ещё что-то. Но из коробки реально универсального решения не нашел с ходу.thunderspb
18.01.2017 15:37ну без внедрения авторизации, например, через okta или каких-то иных SSO систем только если создавать в лаке пользователей с такими же именами, что и в жире.

Caravus
16.01.2017 23:46Интересно, спасибо. Надо будет почитать внимательно (а не после рабочего дня), но в любом случае — пишите ещё!
P.S.: С докером может быть помочь чем? Пользуюсь год, разворачиваю на kubernetes на локалке (для разработки) и в GCE. Всего полтора велосипеда написал под это дело…Zav
17.01.2017 07:00+1Вот это, кстати, небольшой парадокс — индивидуально с докером проблем нет почти ни у кого.
Я даже одно время приложение разворачивал как докер (но была просадка около 10% из-за некоторых особенностей).
Но вот когда дело доходит до корпоративных решений — когда подготавливается образ и все настройки не индивидуально, а, хотя бы для полста человек — почему то волшебным образом начинаются проблемы.Caravus
17.01.2017 07:59Ну на самом деле всё объясняется просто. Дла того чтоб разобраться с какой-то технологией — надо посидеть, подумать, почитать документацию, поэксперементировать… При условии того что мы знаем как в наших компаниях происходит работа (давай, быстрей, нужен релиз, сейчас!!!11) — ничего удивительного что не получается внедрить толком что-то новое. Я этим всем спокойно занимался в перерывах между работами в компаниях, изучил, попробовал, применил на своих проектах, набил шишек и написал пару скриптов. Так же стоит отметить проблему с документацией что у докера что у кубурнетес, нужно реально захотеть в этом разобраться чтоб чего-то добиться, ну и навык гугления должен быть минимум 4 уровня :). Вспомнить хотя бы этот новомодный миникуб, которым заменили кубернетес разворачиваемый в докере, который разворачивает кубернетес в виртуалке и куда не подключить hostPath без танцев с бубном, но в документации уже всё выпилили.
Сейчас пришёл в новую компанию, увидел что они всё ещё деплоят прям на железо (причём у разработчика стоял nginx, а на проде apache) и ужаснулся. Достал свои скрипты, допилил под нужды командной разработки и обучил разработчиков. У меня конечно не «полста человек», а всего лишь 4 разработчика, но судя по тому с какой лёгкостью мы подключаем новых людей — не должно быть проблем с расширением, просто будем постепенно допиливать решение (скрипты).
Минусы и неудобство перекрываютс плюсами с головой, по крайней мере с точки зрения людей которые работают с конечным сетапом. Разработка вернулась на локальный комп и при этом — окружение идентичное тесту/проду, этож просто чудо какое-то…Zav
17.01.2017 08:13+1При условии того что мы знаем как в наших компаниях происходит работа (давай, быстрей, нужен релиз, сейчас!!!11)
К сожалению, моя речь касалась совершенно не наших компаний :-)
всё ещё деплоят прям на железо
Ну это тоже из крайности в крайность. Я предпочитаю использовать виртуальные машины хоть в каких то проявлениях. Но даже это не всегда спасает.
Например, jail, это те же самые контейнера, на самом деле. У меня в jail стоит virtualbox. Даже при такой, казалось бы, изоляции, у меня несколько раз мастер-машина падала из за проблем на одной из виртуальных в virtualbox. Там очень специфичные ошибки были, но факт был что они сначала вырывались и из virtualbox, а потом и из jail, уводя машину в кернел паник.
всего лишь 4 разработчика, но судя по тому с какой лёгкостью мы подключаем новых людей
Вот в этом и есть разница. Мало сделать решение — его надо ещё поддерживать. Своевременно обновлять и так далее. Зачастую изначальные контейнера готовятся вот такой командой, а когда она расширяется, и когда кодовая база сильно больше, и требований в целом больше — забывают актуализировать и искренне считают что это ты тут дурак, не смог разобраться как их уюненький докер поставить в 1 команду :-)
Окей, мы можем проблему вынести в другую плоскость — «любое решение требует поддержки» — но это вопрос для отдельной статьи :-) Я думаю так или иначе мы поняли позиции друг друга.Caravus
17.01.2017 08:28К сожалению, моя речь касалась совершенно не наших компаний :-)
Тогда почему «К сожалению»? :) На самом деле под «нашими» я подразумевал «компании в которых мы работаем». Я работал много где (и много кем) но «война… война никогда не меняется». Везде есть «эффективные менеджеры», которыми самими надо управлять для достижения результатов…
Я предпочитаю использовать виртуальные машины хоть в каких то проявлениях. Но даже это не всегда спасает.
Например, jail, это те же самые контейнера, на самом деле. У меня в jail стоит virtualbox.
Я подумал что у меня подводит память (jail и freebsd в частности пользовался последний раз лет 5 назад), но оказалось что нет:
В основу FreeBSD Jail вошёл системный вызов chroot(2), при котором для текущего процесса и всех его потомков, корневой каталог переносится в определённое место на файловой системе
К контейнеризации это относится слабо, вы просто говорите процессу что «вот эта папка — корень системы и выше ничего нет», то есть вы засунули виртуалку в папку и сказали ей «сиди тут». В контейнере же у вас полноценная ОСь, окукленная в оперативке, по сути. Если не накосячить с подключением чего-либо с хост-машины (например — монтирование папок в контейнер) то очень сложно вообще что-либо сломать. Но если прям происходит какая-то жесть — в дело вступает система оркестрации, например kubernetes, которая быстро, решительно объясняет контейнеру или даже целому поду что они не правы. Такой сетап используется гуглом уже лет 15, я думаю они могли бы в своё время просто заюзать jail и не париться, но похоже что это не одно и то же…
Мало сделать решение — его надо ещё поддерживать. Своевременно обновлять и так далее
Окей, мы можем проблему вынести в другую плоскость — «любое решение требует поддержки»
Если не поддерживать — совершенно всё равно какие технологии и в каком кол-ве применять. Рано или поздно всё нужно обновлять и переделывать.
А я бы кстати не против был бы что-то обсудить в этой плоскости, может быть — это не плохая тема для вашей следующей статьи? :) Буду ждать, удачи!Zav
17.01.2017 08:40К контейнеризации это относится слабо
Да ладно, Jail вполне соотносится идеологически с контейнерами.
Более того можно собрать linux джейл, и проксировать linux-команды.
У них много общего, на самом деле.
Вот дальше:
Однако FreeBSD Jail также имеет поддержку на уровне ядра, что позволяет ограничивать доступ к сети, общей памяти, переменным ядра sysctl и ограничивать видимость процессов вне jail.
Процесс, заключённый в Jail, может иметь доступ только к определённым IP-адресам операционной системы и использовать определённый hostname. Такой процесс называется «изолированный процесс» или «Jailed-процесс».
Таким образом, создаётся безопасная «клетка», внутри которой можно исполнять даже потенциально опасное программное обеспечение, которое не сможет никак повредить основной системе или другим таким же «клеткам».
это не плохая тема для вашей следующей статьи
Точно не следующей — слишком мало у меня материала.
Например, вот эта статья была написана за один присест. Прям реально — сел и написал, отрывался только что бы чая ещё сдлать.
Но вот материал мариновался в голове полтора года :-)Caravus
17.01.2017 10:10Да ладно, Jail вполне соотносится идеологически с контейнерами.
Из цитаты:
позволяет ограничивать доступ к сети, общей памяти, переменным ядра sysctl и ограничивать видимость процессов вне jail.
И в этом (на мой взгляд) изначальное различие: в контейнерах по умолчанию «всё запрещено что не разрешено». Разрешили контейнеру доступ в сеть — есть сеть, нет — значит идёт лесом. Сложно (сложнее) сломать хост-систему если софт понятия не имеет что есть какая-то хост-система.
Точно не следующей — слишком мало у меня материала.
Как вы сами пишите — надо просто взять кусочки того что есть и не обрезать:
Практически каждый из пунктов имеет под собой довольно обширную историю (я намеренно сильно сокращал всё) и тянет на отдельную полноценную статью.
Zav
17.01.2017 10:23Тьфу, я думал вы хотите статью про докер :-)
Про виртуализацию в целом это можно, но, тем не менее, не следующей точно.
Не цепляйтесь к словам, пожалуйста. Это уже детали. Мы можем создавать Jail'ы с большим количеством ограничений сразу, что для большинства пользователей является достаточным.
Я это к тому что задачу они решают кране схожую — лёгкий слой изоляции с минимальными издержками. Я не говорю что это одно и тоже, но сравнивать вполне можно.
Несмотря на этот пост я не считаю себя крутым сетевиком или системным администратором, и не претендую на то, что данные решения самые лучшие и корректные из возможных — более того, вероятно, это совсем не так. Но они позволили решить поставленные задачи на должном уровне и гарантировать большое количество свобод.
Мне нравится правило 100 часов, и в ряде отдельно взятых навыков у меня именно схожий опыт. Ну может не 100, а скажем 200-500.Caravus
17.01.2017 10:28Тьфу, я думал вы хотите статью про докер :-)
Про докер я тоже хочу! :)
Я это к тому что задачу они решают кране схожую — лёгкий слой изоляции с минимальными издержками.
Так я же и не против, просто предположил что некоторых проблем можно было бы избежать используя, например, докер.
Но они позволили решить поставленные задачи
И это — самое главное.
lehnh
17.01.2017 12:33> В контейнере же у вас полноценная ОСь, окукленная в оперативке, по сути.
Это не так. Полноценная ось — только в виртуальной машине. Контейнер это лишь огораживание окружения средствами ядра, в линуксе это cgroups и namespaces, в бсд что-то аналогичное. Но и у гостевой и у хост ос общее ядро, адресное пространство, ресурсы и тд. Дело лишь в ограничении доступа к ресурсам для процессов, которые крутятся в контейнере.Caravus
17.01.2017 12:38Ну как верно сказал автор — не цепляйтесь к словам, а то мы дойдём до того что «полноценная ось у нас только на железе», т.к. виртуалка это тоже только эмуляция :) Я же не про это писал.
lehnh
17.01.2017 14:03Дело в том, что общее ядро накладывает определенные ограничения. Мало того, что нельзя запустить ос, отличную от хост ос, так еще и существует софт, требующий интеграции юзерспейса и кернелспейса. Самый простой пример (и актуальный на сегодняшний момент) — поднятие собственного openvpn сервера на удаленной площадке для обхода блокировок. Он тупо не заработает в контейнере, т.к. требует подгрузки модуля в ядро. Это же относится и к файловым системам, крутящимся в юзерспейсе и тд.
Zav
17.01.2017 14:13Да, есть такое. Это одна из причин, почему пришлось virtualbox использовать.
Некоторый софт под linux не очень себя чувствовал в jail'ах. Например PLEX (хотя я от него всё равно потом отказался).
AbstractGaze
17.01.2017 08:15Если не секрет, сколько сейчас человек в команде? Было бы интересно узнать с чего начинался проекта, и как и по какой причине разрасталась команда.
Zav
17.01.2017 08:18Возможно, ответ будет в виде отдельной статьи.
Можно сказать что сейчас над проектом трудятся 5 человек: я, гейм-дизайнер/дизайнер, иллюстратор, копирайтер и музыкант.
Предвосхищая вопрос: для одного разработчика некоторые шаги действительно инфраструктуры избыточны.AbstractGaze
17.01.2017 13:32Было бы очень замечательно. Многие хотят создавать соло все сами и не понимают зачем нужна команда. А так реальный пример от инди. Таких статей мало, точнее я даже не помню чтобы находил на русском языке.

nikitasius
17.01.2017 10:48Спасибо за статью!
Если в общем: отличная экономия времени для тех, кто имеет проблемы, с которыми вы сталкивались или ищет похожие технические решения.
vdeneko
17.01.2017 11:14Можете в DTLN обратиться на тему теста S3 стораджа для хранения своих фотографий и замены owncloud
Zav
17.01.2017 11:17Так просадка будет по скорости локальная — я это тоже отметил в статье. Дома гигабитная сеть, а внешний канал ~80 мегабит.
Онлайн хранилище использую исключительно для резервирования на случай потери.
SkyHunter
«Спасибо» не нажимается ;)