
Введение
Вот не люблю я изобретать велосипед и статью я бы эту не написал, но пришлось. Про REST сказано уже довольно много. Многие поставщики веб служб готовы клясться, что их службы являются RESTful. Во время собеседования вы точно услышите хотя бы несколько вопросов про REST, независимо от того это собеседования для бэкенд, мобайл или фронтенд разработчика. Я вот помню как-то во время одного собеседования меня задали такой вопрос: «Вот вы написали в своем резюме, что знайте REST? Ответьте пожалуйста, какой HTTP код вы получите, если при запросе к RESTful сервису ресурс не найден?». Ответ 404 был принят единогласно. Если честно, я так и не понял, как этот вопрос помог понять знаю ли я REST или нет, но одно могу уверенно сказать: REST понимают далеко не все. Вот некоторые вопросы, которые мучали меня долгое время:
- Зачем REST стал таким трендовым? Это архитектура была же предложена еще в 2000 году?
- Что я получу если моя служба будет RESTful?
- Как определить является ли служба RESTful или нет?
- Как правильно должны создаваться URL REST служб?
- Какие http методы и коды должны быть использованы в RESTful службе?
Если вы не можете дать исчерпывающего ответа хотя бы на один из этих вопросов, то продолжайте чтение. Если вы можете однозначно ответить на все эти вопросы, можете привести формат правильного URL, считайте, что GET, POST, PUT, DELETE обязательно должны соответствовать CRUD операциям с ресурсами, то вам обязательно надо продолжать чтение.
Чтобы найти ответы на приведенные вопросы и представить общую картину пришлось прочитать кучу спецификаций, диссертацию Роя Филдинга и книгу Леонарда Ричардсона, поскольку оказалось что есть большая путаница в интернете и в частности в Stack Overflow. Найденная информацию показалось мне довольно полезной вот и решил им с вами поделиться.
Поскольку REST мы рассматриваем с точки зрения веб служб, в статье я попытался изложить все то, что нужно знать для представления общей картины.
Ну что же, начнем путешествие в мир веб-сервисов.
SOA & Web Services
SOA, расширяемая как сервис ориентированная архитектура (Service Oriented Architecture), является парадигмой для организации и использования распределенных систем, которые могут находиться под контролем различных областей собственности [1]. В SOA, под service подразумевается функциональная возможность, которая удовлетворяет следующим критериям [2]?
- Представляет собой функциональность с конкретным результатом.
- Является самодостаточным (self-contained).
- Является черным ящиком для клиентов.
- Может состоять из других услуг.
Service Description – это информация о сервисе, необходимая для взаимодействия со службой (пр. WSDL).
Service Provider – это люди или организации, которые предоставляют сервисы.
Service Consumer – это клиенты, потребители служб.
Web Service, согласно определению [3], является системой, предназначенная для взаимодействия машин/программ по сети. Веб-сервис должен иметь интерфейс, описанной в машинно-обрабатываемом формате (service description). Другие системы должны взаимодействовать с веб-сервисом посредством сообщений.
Взаимосвязь между веб-сервисом и SOA является то, что SOA может быть реализован посредством веб-сервисов.
Если вас заинтересует какие еще методы существуют или существовали для реализации SOA, можете посмотреть COM и CORBA.
Протоколы веб служб
До того, как решить какая служба является RESTful, а какая нет, рассмотрим некоторые реализации, или как по другому их называют, протоколы веб служб. Список общеизвестных протоколов веб служб можно найти в [4].
1. XML-RPC
Протокол XML-RPC (XML Remote Procedure Call) [5] был в первые опубликован в 1999 году. Все сообщение XML-RPC являются HTTP-POST запросами. Для шифрования сообщений используется XML. Параметры процедуры могут быть скалярные значения, числа, строки, даты, массивы и структуры. Ответ веб службы может хранить либо значение, возвращаемой процедурой, либо код и сообщение ошибки.
Host: betty.userland.com
Content-Type: text/xml
Content-length: 181
<?xml version="1.0"?>
<methodCall>
<methodName>examples.getStateName</methodName>
<params>
<param>
<value><i4>41</i4></value>
</param>
</params>
</methodCall>
HTTP/1.1 200 OK
Connection: close
Content-Length: 158
Content-Type: text/xml
Date: Fri, 17 Jul 1998 19:55:08 GMT
Server: UserLand Frontier/5.1.2-WinNT
<?xml version="1.0"?>
<methodResponse>
<params>
<param>
<value><string>South Dakota</string></value>
</param>
</params>
</methodResponse>
В качестве недостатка протокола XML-RPC, приводится большой размер сообщений (4 раза больше, по сравнению с обычным XML) и не существования языка описания веб-сервиса (что-то похожее на WSDL), который мог был бы использоваться для генерации прокси классов на стороне клиента.
2. JSON-RPC
Протокол JSON-RPC [6], опубликованный в 2009 году, по своим принципам работы очень похож на XML-RPC. Главными отличиями являются способ шифрования данных, независимость от транспортного уровня, способность передачи извещений (notification request) и возможность идентификации ответов при отправке нескольких запросов одновременно.
Для шифрования данных в JSON-RPC используется JSON. Кроме имени процедуры и параметров, в запросе указывается также значение id, который используется для идентификации ответа на стороне клиента. Другими словами если вы отправили запрос с id=12345, то ответ этого запроса обязательно должен возвращать сообщение с id=12345.
Извещение – это специальные запросы, на которые сервер может не отвечать. Для отметки запроса, как извещение, значения параметра id указывается = null.
Независимость от транспортного уровня можно обусловить только тем, что в спецификации JSON-RPC [6] HTTP не указывается обязательным протоколом. При использовании JSON-RPC над HTTP, необходимо использовать POST запросы.
--> {"jsonrpc": "2.0", "method": "subtract", "params": [42, 23], "id": 1}
<-- {"jsonrpc": "2.0", "result": 19, "id": 1}
--> {"jsonrpc": "2.0", "method": "subtract", "params": {"subtrahend": 23, "minuend": 42}, "id": 3}
<-- {"jsonrpc": "2.0", "result": 19, "id": 3}
Недостатком JSON-RPC, как и в случае XML-RPC является отсутствие языка описания веб-сервиса (аналог WSDL).
3. SOAP
Протокол SOAP (Simple Object Access Protocol) [7] является наследником XML-RPC. Основными характеристиками SOAP являются:
- Все передаваемые сообщения шифруются с помощью XML (SOAP messages).
- Все SOAP службы имеют описание на языке WSDL, которое тоже является XML-ом. Это позволяет клиентом автоматически сгенерировать прокси классы.
- SOAP поддерживает почти все известные протоколы TCP/IP (TCP, UDP, HTTP, SMTP, FTP и т.д.). Именно по этой причине SOAP является довольно сложным протоколом по сравнению с предыдущими.
- При использовании HTTP, поддерживается как метод GET так и POST. GET допускается использовать только для получения данных, т.е. на стороне сервера нe должно ничего меняться. POST можно использовать для всех случаев. На практике обычно используется только POST.
Главным недостатком SOAP является его сложность по причине гибкости. Другой немало важным недостатком является поддержка шифрование только в XML.
GET /travelcompany.example.org/reservations?code=FT35ZBQ HTTP/1.1
Host: travelcompany.example.org
Accept: text/html;q=0.5, application/soap+xml
HTTP/1.1 200 OK
Content-Type: application/soap+xml; charset="utf-8"
Content-Length: nnnn
<?xml version='1.0' ?>
<env:Envelope xmlns:env="http://www.w3.org/2003/05/soap-envelope">
<env:Header>
<m:reservation xmlns:m="http://travelcompany.example.org/reservation"
env:role="http://www.w3.org/2003/05/soap-envelope/role/next"
env:mustUnderstand="true">
<m:reference>uuid:093a2da1-q345-739r-ba5d-pqff98fe8j7d</m:reference>
<m:dateAndTime>2001-11-30T16:25:00.000-05:00</m:dateAndTime>
</m:reservation>
</env:Header>
<env:Body>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:x="http://travelcompany.example.org/vocab#"
env:encodingStyle="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<x:ReservationRequest
rdf:about="http://travelcompany.example.org/reservations?code=FT35ZBQ">
<x:passenger>Ake Jogvan Oyvind</x:passenger>
<x:outbound>
<x:TravelRequest>
<x:to>LAX</x:to>
<x:from>LGA</x:from>
<x:date>2001-12-14</x:date>
</x:TravelRequest>
</x:outbound>
<x:return>
<x:TravelRequest>
<x:to>JFK</x:to>
<x:from>LAX</x:from>
<x:date>2001-12-20</x:date>
</x:TravelRequest>
</x:return>
</x:ReservationRequest>
</rdf:RDF>
</env:Body>
</env:Envelope>
HTTP POST:
POST /Reservations HTTP/1.1
Host: travelcompany.example.org
Content-Type: application/soap+xml; charset="utf-8"
Content-Length: nnnn
<?xml version='1.0' ?>
<env:Envelope xmlns:env="http://www.w3.org/2003/05/soap-envelope" >
<env:Header>
<t:transaction
xmlns:t="http://thirdparty.example.org/transaction"
env:encodingStyle="http://example.com/encoding"
env:mustUnderstand="true" >5</t:transaction>
</env:Header>
<env:Body>
<m:chargeReservation
env:encodingStyle="http://www.w3.org/2003/05/soap-encoding"
xmlns:m="http://travelcompany.example.org/">
<m:reservation xmlns:m="http://travelcompany.example.org/reservation">
<m:code>FT35ZBQ</m:code>
</m:reservation>
<o:creditCard xmlns:o="http://mycompany.example.com/financial">
<n:name xmlns:n="http://mycompany.example.com/employees">
Ake Jogvan Oyvind
</n:name>
<o:number>123456789099999</o:number>
<o:expiration>2005-02</o:expiration>
</o:creditCard>
</m:chargeReservation
</env:Body>
</env:Envelope>
HTTP/1.1 200 OK
Content-Type: application/soap+xml; charset="utf-8"
Content-Length: nnnn
<?xml version='1.0' ?>
<env:Envelope xmlns:env="http://www.w3.org/2003/05/soap-envelope" >
<env:Header>
...
...
</env:Header>
<env:Body>
...
...
</env:Body>
</env:Envelope>
REST
REST является на сегодняшний день наверное самым популярным веб-сервис
На самом деле REST вовсе не является протоколом и оно вообще не новое. REST является архитектурой который был предложен в 2000-ие годы Роем Филдингом в его диссертации «Architectural Styles and the Design of Network-based Software Architectures» [8]. До этого REST архитектура была использована в многих проектах в рамках IETF и W3C. В самой диссертации вы не сумейте найти терминов «веб служба» или SOA. REST архитектура была предложена для правильного конструирования распределенных гипермедиа систем, по другим словом того, что на сегодня называется World Wide Web. Чтобы диссертацию Филдинга вы приняли в серьез, скажу, что Рой является архитектором HTTP 1.1, соавтором интернет стандартов для HTTP и URI [10]. В общем мужик он серьезный и известный.
Чтобы распределенная система считалась сконструированной по REST архитектуре, необходимо, чтобы она удовлетворяла следующим критериям:
- Client-Server. Система должна быть разделена на клиентов и на серверов.
- Stateless. Сервер не должен хранить какой-либо информации о клиентах. В запросе должна храниться вся необходимая информация для обработки запроса и если необходимо, идентификации клиента.
- Cache? Каждый ответ должен быть отмечен является ли он кэшируемым или нет.
- Uniform Interface. Универсальный интерфейс между компонентами системы.
Для получения универсального интерфейса вводятся следующие ограничения:
- Identification of resources.
В REST ресурсом является все то, чему можно дать имя. Например, пользователь, HTML документ, изображение, регистрированный пользователь, красная майка, голодная собака, текущая погода и т.д. Каждый ресурс в REST должен быть идентифицирован посредством стабильного идентификатора, который не меняется при изменении состояния ресурса. В нашем случае идентификатором в REST является URI.
- Manipulation of resources through representations.
Представление в REST используется для выполнения действий над ресурсами. Представление ресурса представляет собой текущее или желаемое состояние ресурса. Например, если ресурсом является пользователь, то представлением может является XML или HTML описание этого пользователя.
- Self-descriptive messages.
Под само-описательностью имеется ввиду, что запрос и ответ должны хранить в себе всю необходимую информацию для их обработки. Не должны быть дополнительные сообщения или кэши для обработки одного запроса.
- HATEOAS (hypermedia as the engine of application state).
Данный пункт означает, что гипертекст должен быть использован, для навигации по API [9]. Отмечу, что в случае SOA, для этого используется service description.
Рассмотрим данный пункт более подробно.
В пример ниже на запрос получение баланса, в ответе указан не только баланс, но и действия, которые могут быть выполнены со счетом.GET /account/12345 HTTP/1.1 HTTP/1.1 200 OK <?xml version="1.0"?> <account> <account_number>12345</account_number> <balance currency="usd">100.00</balance> <link rel="deposit" href="/account/12345/deposit" /> <link rel="withdraw" href="/account/12345/withdraw" /> <link rel="transfer" href="/account/12345/transfer" /> <link rel="close" href="/account/12345/close" /> </account>
Рассмотрим этот же пример при негативном балансе:GET /account/12345 HTTP/1.1 HTTP/1.1 200 OK <?xml version="1.0"?> <account> <account_number>12345</account_number> <balance currency="usd">-25.00</balance> <link rel="deposit" href="/account/12345/deposit" /> </account>
Как можно увидеть, в ответе уже нет ссылок на депозит и трансфер, поскольку эти действия для данного счета недоступны.
- Identification of resources.
- Layered System. В REST допускается разделить систему на иерархию слоев но с условием, что каждый компонент может видеть компоненты только непосредственно следующего слоя. Например, если вы вызывайте службу PayPal а он в свою очередь вызывает службу Visa, вы о вызове службы Visa ничего не должны знать.
- Code-On-Demand. В REST позволяется загрузка и выполнение кода или программы на стороне клиента.
И так, если распределенная система удовлетворяет всем шести приведенным пунктам, то можно сказать что она устроена по архитектуре REST, а такая веб служба в этом случае называется RESTful службой.
Как вы уже заметили в этих пунктах ничего не сказано про GET, PUT, POST и DELETE запросы, шифрование JSON, HTTP и т.д.
REST – это просто архитектура, он никак не привязан к каким либо протоколом.
Наверняка вы уже заметили, что в REST архитектуре нет ничего удивительного и нового. Нового было в REST в 2000 году, когда веб только-только начал развиваться. Чтобы еще лучше представить REST и его значимость, представьте, что веб – это распределенная система гипермедиа, где каждый сайт представляет собой гипертекст.
Тогда конечно возникает вопрос — а то, что мы видим и делаем на практике, это что? В интернете можно найти кучу споров про то, как должна выглядеть RESTful служба и как не должна. Какие методы HTTP должны использоваться а какие нет. В общем, как уже понятно, все эти обсуждения не имеют теоритической основы, поскольку нет какой-либо спецификации про RESTful службы. В одном проекте могут решить, что POST будет использоваться для создания новой записи, в дурой для обновления, а в третей для удаления. Эти решения никак не связаны с REST архитектурой.
REST & Richardson Maturity Model
И так, как же связан REST с веб службами? Какие службы можно считать RESTful, а какие нет? Что вы получите, если ваша служба будет удовлетворять всем пунктам Филдинга? Отвечу на эти вопросы по очереди:
- REST архитектура оправдала себя в течении последних 16-и лет на практике веба. Поскольку веб-сервисы являются частью веба, многими компаниями/разработчиками/исследователями было решено и в случае веб-сервисов применить архитектуру REST, что позволит улучшить масштабируемость компонентов, обеспечить безопасность, независимое развертывание и т.д.
- Если веб служба удовлетворяет всем критериям Филдинга, то его можно считать RESTful, независимо от того, используется ли HTTP метод DELETE для удаления записей или нет. Добавлю, что в веб часто используемыми методами являются GET и POST и если веб служба должна быть максимально похожим на веб, то использовать PUT и DELETE тоже как-то не правильно.
- Хотя Филдинг писал про веб и распределенную систем гипертекстов, все равно скопирую часть из его диссертации. По английский звучит более убедительно.
REST provides a set of architectural constraints that, when applied as a whole, emphasizes scalability of component interactions, generality of interfaces, independent deployment of components, and intermediary components to reduce interaction latency, enforce security, and
encapsulate legacy systems.
Звучит конечно все очень круто, но надо ли чтобы ваш веб-сервис был сконструирован по REST или это просто тренд? Давайте рассмотрим модель RMM (Richardson Maturity Model) Леонарда Ричардсона.
После анализа нескольких сотен веб-сервисов [11] был предложен модель RMM для оценки качества, или как Ричардсон назвал это, зрелости веб-сервиса. Модель RMM состоит из 4 уровня. Если ваш сервис соответствует последнему уровню, то можно считать его RESTful. Ниже я приведу примеры и рисунки из [12], которые по словам автора были проверены Аароном Шварцем, Леонардом Ричардсоном и другими известными лицами. Все примеры основаны на следующей истории: Я хочу записаться на прием у врача. От веб службы мне нужно получить свободные часы приема на конкретную дату и после записаться на прием. И так, рассмотрим все эти четыре уровня на данном примере.
Уровень 0: Один URI, один HTTP метод.
Здесь HTTP используется только для взаимодействия компонентов распределенной системы. Из методов используется только один, например POST. Как вы уже догадались, такими веб-сервисами являются протоколы XML-RPC и SOAP.
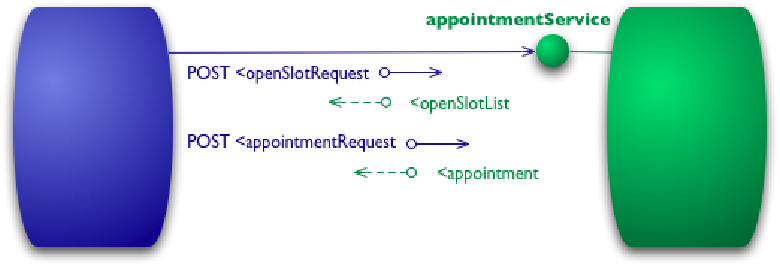
POST /appointmentService HTTP/1.1
[various other headers]
<openSlotRequest date = "2010-01-04" doctor = "mjones"/>
HTTP/1.1 200 OK
[various headers]
<openSlotList>
<slot start = "1400" end = "1450">
<doctor id = "mjones"/>
</slot>
<slot start = "1600" end = "1650">
<doctor id = "mjones"/>
</slot>
</openSlotList>
POST /appointmentService HTTP/1.1
[various other headers]
<appointmentRequest>
<slot doctor = "mjones" start = "1400" end = "1450"/>
<patient id = "jsmith"/>
</appointmentRequest>
HTTP/1.1 200 OK
[various headers]
<appointment>
<slot doctor = "mjones" start = "1400" end = "1450"/>
<patient id = "jsmith"/>
</appointment>
XML используется тут только для примера, в его месте мог был быть JSON, HTML и т.д. Веб-сервис имеет только один URL (относительный URL): /appointmentService. Запрашиваемая функция указывается в теле запроса.
Если ваш сервис соответствует уровню 0, то он еще ребенок.
Теперь рассмотрим этот же пример при работе с веб-сервисом с уровнем 1.
Уровень 1: Несколько URI, один HTTP метод.
Службы этого уровня используют понятие «разделяй и властвуй». В службе вводится понятие ресурсов и для действия с конкретным ресурсом используется URL этого ресурса.
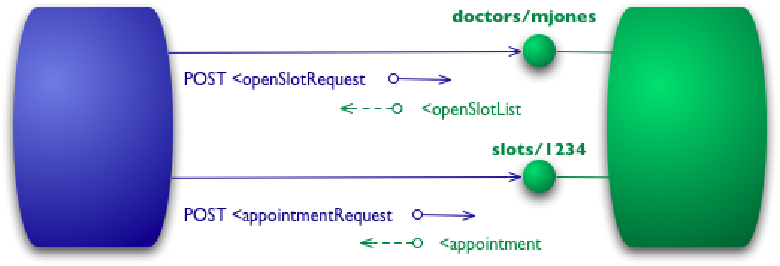
POST /doctors/mjones HTTP/1.1
[various other headers]
<openSlotRequest date = "2010-01-04"/>
HTTP/1.1 200 OK
[various headers]
<openSlotList>
<slot id = "1234" doctor = "mjones" start = "1400" end = "1450"/>
<slot id = "5678" doctor = "mjones" start = "1600" end = "1650"/>
</openSlotList>
POST /slots/1234 HTTP/1.1
[various other headers]
<appointmentRequest>
<patient id = "jsmith"/>
</appointmentRequest>
HTTP/1.1 200 OK
[various headers]
<appointment>
<slot id = "1234" doctor = "mjones" start = "1400" end = "1450"/>
<patient id = "jsmith"/>
</appointment>
И так, если вы хотите выполнить какое-то действие с доктором, то надо использовать относительный URL /doctors, а если ваше действие связано с посещением, то URL /slots. Если сравнить службу первого уровня со службой нулевого уровня, то в последнем случае есть только один ресурс, и этот ресурс сама веб служба.
Если ваш сервис соответствует уровню 1, то он является подростком.
Уровень 2: Несколько URI, каждый поддерживает разные HTTP методы (Правильное использование HTTP).
И так, на уровне 1 все методы веб службы были отделены с помощью ресурсов, но с ресурсом можно выполнить кучу действий. Чтобы эти действия тоже были как-то логически разделены, используется возможность HTTP отправлять и принимать операции с разними методами: GET, HEAD, POST, PUT, DELETE, TRACE, CONECT. Например, если метод является чтением, можно использовать GET, если для создания POST или PUT? В принципе, можно и наоборот, но поскольку в HTTP эти методы имеют какие-то понятия и характеристики, лучше, чтобы эти понятия были те же, что и в веб службе, в противном случае вы можете получить кэшируемый метод создания ресурса. Другими словами, какой метод вы будете использовать для каких операций, уже вопрос правильного использования протокола HTTP?
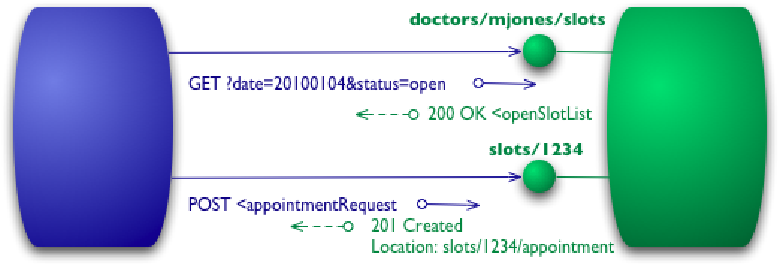
Наверное, пришло время для примеров:
GET /doctors/mjones/slots?date=20100104&status=open HTTP/1.1
Host: royalhope.nhs.uk
HTTP/1.1 200 OK
[various headers]
<openSlotList>
<slot id = "1234" doctor = "mjones" start = "1400" end = "1450"/>
<slot id = "5678" doctor = "mjones" start = "1600" end = "1650"/>
</openSlotList>
POST /slots/1234 HTTP/1.1
[various other headers]
<appointmentRequest>
<patient id = "jsmith"/>
</appointmentRequest>
HTTP/1.1 201 Created
Location: slots/1234/appointment
[various headers]
<appointment>
<slot id = "1234" doctor = "mjones" start = "1400" end = "1450"/>
<patient id = "jsmith"/>
</appointment>
С вводом разных HTTP методов вводится также необходимость возвращения правильных HTTP статус кодов. Например, на запрос создания встречи, если она создана, то должен быть возвращен код 201. Если в течении ваших действий кто-то уже регистрировался на выбранный день и час, должен быть возвращен код 409 conflict и т.д. Опять же, тут дело в правильном использовании протокола HTTP?
Если ваш сервис соответствует уровню 2, то он является уже взрослой мужчиной.
Уровень 3: HATEOAS? Ресурсы сами описывают свои возможности и взаимосвязи.
HATEOAS (Hypertext as the Engine of Application State), требование которое на мой взгляд обязателен для гипермедиа, но насколько это актуален для веб служб — не знаю. Все же, HATEOAS – это характеристика веб-сервиса возвращать действия в виде URL, которые могут быть выполнены с интересующим вам ресурсом.
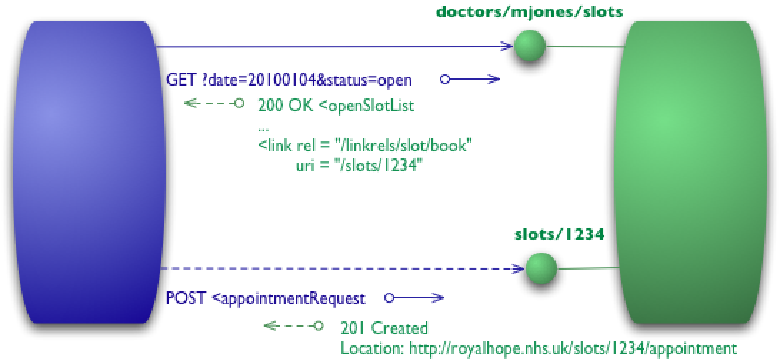
Поскольку HATEOAS был уже рассмотрен выше, тут я приведу только примеры.
GET /doctors/mjones/slots?date=20100104&status=open HTTP/1.1
Host: royalhope.nhs.uk
HTTP/1.1 200 OK
[various headers]
<openSlotList>
<slot id = "1234" doctor = "mjones" start = "1400" end = "1450">
<link rel = "/linkrels/slot/book"
uri = "/slots/1234"/>
</slot>
<slot id = "5678" doctor = "mjones" start = "1600" end = "1650">
<link rel = "/linkrels/slot/book"
uri = "/slots/5678"/>
</slot>
</openSlotList>
Каждый свободный час имеет URL, для выполнения действий над ним, в этом случае регистрация на этот час.
POST /slots/1234 HTTP/1.1
[various other headers]
<appointmentRequest>
<patient id = "jsmith"/>
</appointmentRequest>
HTTP/1.1 201 Created
Location: http://royalhope.nhs.uk/slots/1234/appointment
[various headers]
<appointment>
<slot id = "1234" doctor = "mjones" start = "1400" end = "1450"/>
<patient id = "jsmith"/>
<link rel = "/linkrels/appointment/cancel"
uri = "/slots/1234/appointment"/>
<link rel = "/linkrels/appointment/addTest"
uri = "/slots/1234/appointment/tests"/>
<link rel = "self"
uri = "/slots/1234/appointment"/>
<link rel = "/linkrels/appointment/changeTime"
uri = "/doctors/mjones/slots?date=20100104@status=open"/>
<link rel = "/linkrels/appointment/updateContactInfo"
uri = "/patients/jsmith/contactInfo"/>
<link rel = "/linkrels/help"
uri = "/help/appointment"/>
</appointment>
Преимуществом HATEOAS является то, что оно дает возможность разработчикам веб служб менять URI независимо от клиентов. Кроме этого, веб-сервис сам описывает себя без каких-либо WSDL. Чтобы правильно представить HATEOAS, представьте веб сайт из статических страниц. Вы открывайте главную страницу, а там уже ссылки на все остальное. Чтобы зайти на веб сайт и что-то найти там, нет необходимости прочитать какой-то документ по данному веб сайту, что-то вроде документа по API. Опять же, мое субъективное мнение по необходимости веб-сервиса поддерживать HATEOAS довольно пессимистично.
Если ваш сервис соответствует уровню 3, то его можно уже называть RESTful ну и конечно стариком с хорошим оптом.
Заключение
Если вы читайте эти строки значит либо прочитали всю статью и дошли до заключения, либо по причине недостатка во времени пролистали основную статью и читайте только заключение.
Поскольку второй случай более распространенный чем первый, приведу основные концепции:
- Веб-сервис – это один из методов реализации SOA архитектуры.
- Веб-сервис протоколом называется конкретная реализации веб-сервиса (XML-RPC, SOAP, JSON-RPC, и т.д.).
- REST является архитектурой, который был предложен в 2000 году и применялся для правильного создания компонентов веба и распределенных гипермедиа систем в целом.
- Вопрос чем отличается SOAP от REST, почти то же самое, что спросить, чем отличается бизон от хищника. SOAP-это протокол, у которого есть спецификация, а REST – это архитектура, которую можно применить для создания веб служб с использованием HTTP и URL.
- Richardson Maturity Model – это модель, предложенный Леонардом Ричардсоном для оценки зрелости веб службы. Понятия «ребенок», «подросток», «мужчина» и «старик» я сам ввел, чтобы более хорошо представить слоя модели RMM.
Будет ли веб служба ребенком или стариком – ваш выбор. Если вы или ваша компания разрабатывайте и серверную часть приложения и клиентскую, то думаю нет необходимости, чтобы ваша служба удовлетворяла всем пунктам RMM, особенно HATEOAS. «Мужчина» или «подросток» с этой задачей легко справятся. А если вы разрабатывайте что-то вроде amazon, у вас должны быть несколько тысяч клиентов, о которых вы понятия не имейте, то с этим наверное наилучшим образом справиться «старик». Если же ваша служба имеет очень мало функций, то дайте эту работу «ребенку», он знает, как все слить в одну кучу (в один ресурс).
Литература
1. www.oasis-open.org/committees/download.php/19679/soa-rm-cs.pdf
2. www.opengroup.org/standards/soa
3. www.w3.org/TR/ws-arch/#whatis
4. en.wikipedia.org/wiki/List_of_web_service_protocols
5. xmlrpc.scripting.com/spec.html
6. www.jsonrpc.org/specification
7. www.w3.org/TR/soap
8. www.ics.uci.edu/~fielding/pubs/dissertation/fielding_dissertation.pdf
9. restcookbook.com/Basics/hateoas
10. roy.gbiv.com/untangled/about
11. www.crummy.com/writing/speaking/2008-QCon/act3.html
12. martinfowler.com/articles/richardsonMaturityModel.html
Комментарии (124)

kafeman
20.01.2017 10:54Я вот помню как-то во время одного собеседования меня задали такой вопрос: «Вот вы написали в своем резюме, что знайте REST? Ответьте пожалуйста, какой HTTP код вы получите, если при запросе к RESTful сервису ресурс не найден?».
Возможно, от вас хотели, чтобы вы объяснили разницу между 404 и 410.

lair
20.01.2017 12:04+3Что-то нелогично выходит.
Чтобы распределенная система считалась сконструированной по REST архитектуре, необходимо, чтобы она удовлетворяла следующим критериям [...] Как вы уже заметили в этих пунктах ничего не сказано про GET, PUT, POST и DELETE запросы, шифрование JSON, HTTP и т.д.
Далее:
Давайте рассмотрим модель RMM (Richardson Maturity Model) Леонарда Ричардсона.
Уровень 0: Один URI, один HTTP метод.Откуда вообще взялся HTTP? Мы же выяснили, что HTTP не обязателен для REST… или нет?
Как вы уже догадались, такими веб-сервисами являются протоколы XML-RPC и SOAP.
Эмм. SOAP, знаете ли, не REST. Так зачем оценивать SOAP-сервис по REST-классификации?
Другими словами, какой метод вы будете использовать для каких операций, уже вопрос правильного использования протокола HTTP?
С вводом разных HTTP методов вводится также необходимость возвращения правильных HTTP статус кодов. Например, на запрос создания встречи, если она создана, то должен быть возвращен код 201. Если в течении ваших действий кто-то уже регистрировался на выбранный день и час, должен быть возвращен код 409 conflict и т.д. Опять же, тут дело в правильном использовании протокола HTTP?… и как определить, какое использование "правильное"?
HATEOAS (Hypertext as the Engine of Application State), требование которое на мой взгляд обязателен для гипермедиа, но насколько это актуален для веб служб — не знаю.
Вы не знаете, насколько это требование актуально для веб-служб, но все равно утверждаете (позже), что именно этот уровень говорит о том, что сервис — RESTful. Хм...
А если вы разрабатывайте что-то вроде amazon, у вас должны быть несколько тысяч клиентов, о которых вы понятия не имейте, то с этим наверное наилучшим образом справиться «старик».
А вот теперь — хороший вопрос: какой же уровень RMM у амазоновских сервисов?
Ну и самое главное.
REST является архитектурой который был предложен в 2000-ие годы Роем Филдингом в его диссертации «Architectural Styles and the Design of Network-based Software Architectures»
Нет. Диссертация Филдинга описывает архитектурный стиль, а не архитектуру.
REST is a hybrid style derived from several of the network-based architectural styles described in Chapter 3 and combined with additional constraints that define a uniform connector interface. [Chapter 5]
An architectural style is a coordinated set of architectural constraints that restricts the roles/features of architectural elements and the allowed relationships among those elements within any architecture that conforms to that style. [Chapter 1]
TipTep
20.01.2017 22:14Попытаюсь ответить на все вопросы/замечания:
Q. Откуда вообще взялся HTTP? Мы же выяснили, что HTTP не обязателен для REST… или нет?
A. Если речь идет про REST, то да, HTTP не обязателен. Но если речь идет про модел RMM, то тут HTTP уже обязателен.
RMM — это модель, который строен на основе RESTЯ. Я могу сам создать какой-то модель,
который будет удовлетворять всем пунктам REST и назвать его моделю Шурика. Если веб сервис будет удовлетворять этой модели, то он тоже будет RESTfull.
Единственное отличное будет, что про модель Шурика буду знать только я, а RMM является общепринятым.
Q. Эмм. SOAP, знаете ли, не REST. Так зачем оценивать SOAP-сервис по REST-классификации?
A. Поскольку SOAP — это реализация веб сервиса, а REST — это архитектурный стил.
Вы же можете взять любой класс и сказать является ли он синглтон или нет? Почти тоже самое тут.
Q. … и как определить, какое использование «правильное»?
A. Тут нет спецификации, нет конкретного определения, что так правильно, а так нет.
Нужно просто, чтобы бизнес логика соответствовала описанию статус кодов, вот например:
201 Created
The request has been fulfilled, resulting in the creation of a new resource.
Если этот код будет возвращен при удалении записи, будет неправильно.
Q. Вы не знаете, насколько это требование актуально для веб-служб, но все равно утверждаете (позже), что именно этот уровень говорит о том, что сервис — RESTful. Хм…
A. По модели RMM, если ваш сервис не поддерживает HATEOAS, то его можно считать только частично RESTful.
На счет актуальности — это мое субьективное мнение. Инымы словами, я не знаю насколько актуально иметь полноценню RESTfull службу.
А HATEOAS — это обязательное ограничение для REST.
Q. А вот теперь — хороший вопрос: какой же уровень RMM у амазоновских сервисов?
A. Надо проверить. Что-то мне кажется, что HATEOAS они не поддерживают.
Q. Нет. Диссертация Филдинга описывает архитектурный стиль, а не архитектуру.
A. Согласен. Правильнее будет «Архитектурный стиль».lair
20.01.2017 22:24Если речь идет про REST, то да, HTTP не обязателен. Но если речь идет про модел RMM, то тут HTTP уже обязателен.
А какой нам интерес в модели, которая налагает более строгие ограничения, хотя раньше вы несколько раз говорили, что вас удивляет, когда спрашивают про эти ограничения?
RMM является общепринятым.
Является ли?
Вы же можете взять любой класс и сказать является ли он синглтон или нет?
Конечно, не могу — если, например, единственность его экземпляра обеспечивается другими средствами.
Но вопрос не в том, могу ли, а зачем.
Тут нет спецификации, нет конкретного определения, что так правильно, а так нет.
Нужно просто, чтобы бизнес логика соответствовала описанию статус кодов, вот например:
201 Created
The request has been fulfilled, resulting in the creation of a new resource.
Если этот код будет возвращен при удалении записи, будет неправильно.Если нет конкретного определения, что "правильно", то откуда вы берете "неправильно".
И, что характерно, больше половины виденных мной дебатов вокруг REST как раз сводились к "как же правильно имплементировать HTTP".
А HATEOAS — это обязательное ограничение для REST.
Дело за малым — найти способ формально определить, поддерживает ли тот или иное приложение HATEOAS.

DigitalSmile
20.01.2017 12:33Спасибо за исследование и мнение.
Помимо того что REST это не стандарт, а принципы построения архитектуры, в отличие от веб-сервисов, для меня видится ключевым отсутствие хранения состояния. Именно это я и спрашиваю на собеседовании при приеме к нам на работу. Если есть понимание, что REST это строго отсутствие состояния, а веб-сервисы нет (или не всегда), то на вопрос ответили правильно (хинт для тех кто пойдет к нам трудоустраиваться :) )lair
20.01.2017 12:43-1для меня видится ключевым отсутствие хранения состояния
Отсутствие хранения какого состояния?
DigitalSmile
20.01.2017 12:57-1Состояние объекта разумеется. Если есть на сервере объект, то мы никогда не храним его состояние (изначальное или измененное) в «неразделяемых» условиях. Для примера можно взять объект «сессия». По REST подходу его нельзя хранить в in-memory на машине, а нужно передавать на «разделяемый» ресурс (БД, к примеру).
Если пойти дальше, то и взаимодействие с БД можно тоже сделать restful и вообще избавится от сессий, заменив их, к примеру, на токены.
Вообще тема скользкая, в моей логике тоже есть изъяны и всегда можно найти контрпример :) Я считаю REST подход может масштабироваться и переходить на разные уровни (необязательно речь про веб).lair
20.01.2017 13:01Состояние объекта разумеется. Если есть на сервере объект, то мы никогда не храним его состояние (изначальное или измененное) в «неразделяемых» условиях. Для примера можно взять объект «сессия». По REST подходу его нельзя хранить в in-memory на машине, а нужно передавать на «разделяемый» ресурс (БД, к примеру).
Эмм. С точки зрения REST нет никакого разделения на "сервер" и "БД", поэтому "состояние объекта" в вашем примере хранится "на сервере" (в противовес "на клиенте"). Поэтому ваш вопрос (по крайней мере, в такой трактовке) неправилен.
DigitalSmile
20.01.2017 13:06-1На «сервер» и «БД» нет, есть сервер и есть клиент (один из них «сервер», другой «БД»). И таки REST строится на клиент-серверной архитектуре, поэтому разделение есть.
Не вижу ничего неправильного в вопросе, можете поподробнее?lair
20.01.2017 13:11Ох, давайте начнем сначала.
Когда вы говорите, что в REST нет состояния, что конкретно вы имеете в виду? Нет состояния чего? Нет где (напомню, наше "где" ограничивается только клиентом или сервером)?
Вот на этом, скажем, примере:
PUT /clients/1 { "name": "Client 1" } < 201 CREATED GET /clients/1 < 200 OK < { < "name": "Client 1" < }DigitalSmile
20.01.2017 13:22Давайте.
Когда вы говорите, что в REST нет состояния, что конкретно вы имеете в виду?
для меня видится ключевым отсутствие хранения состояния.
Я не утверждал, что состояния нет. Я лишь сказал, что мы его не храним на неразделяемых ресурсах. Или выражаясь другим языком, подсказанным f0rk, сессисонно (или per-request или по-запросно, как хотите).
В этом примере, мы создали/отредактировали объект «Client 1». Если нам этот объект опять понадобится мы запросим его с сервера и будем с ним работать, а не с тем объектом который мы создали. Если мы говорим о веб сервисах, то в них не описано (протоколом точно, в договоренностях не всегда) как нам поступить в этом случае — работать с созданным или запросить новый.
В этом мое понимание этого принципа. У вас есть контрпример или свое видение?lair
20.01.2017 13:26Если нам этот объект опять понадобится мы запросим его с сервера и будем с ним работать, а не с тем объектом который мы создали.
Кто "мы"? Клиент? Тогда это совершенно точно не так, REST нигде не накладывает таких ограничений.
Более того, механизм конфликтов на основе
If-Not-Modified-Sinceнамекает нам на то, что в голове держали строго обратный сценарий. И это логично, потому что каждый раз перезапрашивать объект, особенно в условиях пропадающего соединения, очень дорого.DigitalSmile
20.01.2017 13:30Во-первых, накладывает именно словом stateless. Причем и на сервер и на клиент, раз иного не упомянуто.
Во-вторых, при чему тут If-Not-Modified-Since и в целом HTTP? Транспорт может быть любой.
Ну и в-третьих, так и не увидел ответа на свой вопрос. Пока вижу кучу нападок на мое мнение, без контраргументов.lair
20.01.2017 13:44+2Причем и на сервер и на клиент, раз иного не упомянуто.
Вообще-то у Филдинга явно сказано: "We next add a constraint to the client-server interaction: communication must be stateless in nature, as in the client-stateless-server style of Section 3.4.3". Так что ограничение stateless накладывается только на сервер, а не на клиент. Дальше, идем в 3.4.3: "The client-stateless-server style derives from client-server with the additional constraint that no session state is allowed on the server component."
Таким образом, диссертация Филдинга, если мы ее берем за основу, накладывает на REST только одно ограничение по хранению состояния: сервер не должен хранить сессионное состояние.
(обсуждение, является ли кэш сессионным состоянием, смотрите ниже)
Ну и в-третьих, так и не увидел ответа на свой вопрос. Пока вижу кучу нападок на мое мнение, без контраргументов.
Вы просто пропускаете контраргументы.
(1) ничто не запрещает клиенту хранить любое состояние (более того, Филдинг явно пишет "Session state is kept entirely on the client"). Здравый смысл подсказывает нам, что нет никаких проблем с тем, чтобы хранить созданный бизнес-объект на клиенте, там его обновлять, и высылать обновления на сервер (получая в ответ уведомления о конфликтах, если такие случились).
(2) ничто не запрещает серверу хранить бизнес-состояние (сущностей ли, процессов ли), потому что иначе эти сервера будут (в основном) бессмысленны. Рассуждения "мы храним состояние не на веб-сервере, а в БД" находятся строго за пределами REST, потому что для REST есть только пара "клиент-сервер" (где, в данном случае, "сервером" выступает "веб-сервер"), и где именно сервер хранит состояние, значения не имеет.
Так что обсуждение, какое же именно состояние в REST допустимо, а какое нет, — тема для длинного вдумчивого обсуждения.
(
Традиционный пример здесь, на самом деле, это какой-нибудь пейджинг. Пример с состоянием-на-сервере — этоPOST /search/nextPage, в то время как REST-совместимый пример — этоPOST /search?page=2(с поисковым запросом в теле)
)DigitalSmile
20.01.2017 14:02Если уж делать трактовку оригинала, то я бы сказал что ключевая фраза здесь вот эта:
communication must be stateless in nature
То бишь, где они расположены неважно, сам процесс взаимодействия между сервером и клиентом должен быть stateless. Ваши референсы далее касаются хранения сессии, а не состояния объектов.
По вашим аргументам:
1) Действительно ничто, потому что REST это принципы, а не четкий протокол. Вы можете делать так, а можете не делать, руководствуясь, в т.ч. «здравым смыслом». В моем понимании stateless должен быть на всех этапах выполнения бизнес-процесса.
2) Мое мнение, эти принципы масштабируемы под разные уровни. Браузер <-> веб-сервер <-> БД, почему нет? На каждом из звеньев можно соблюдать эти принципы. Где именно хранит важно для соблюдения stateless.
Так что обсуждение, какое же именно состояние в REST допустимо, а какое нет, — тема для длинного вдумчивого обсуждения.
Да, как я упомянул выше, тема очень скользкая и немало копий сломано :) Будет интересно где-нибудь обсудить.
lair
20.01.2017 14:08+1Ваши референсы далее касаются хранения сессии, а не состояния объектов.
А про состояние объектов не сказано ни слова. Значит, к ним эти ограничения не относятся.
В моем понимании stateless должен быть на всех этапах выполнения бизнес-процесса.
Это невозможно, потому что бизнес-процесс и характеризуется состоянием.
На каждом из звеньев можно соблюдать эти принципы.
Stateless (в вашем понимании) БД? Невозможно.
Где именно хранит важно для соблюдения stateless.
Вы сейчас явно противоречите тексту Филдинга о том, что сервер — черный ящик.
Jermes
24.01.2017 02:53Добавлю еще, что нужно понимать зачем наложено stateless ограничение на коммуникацию, чтоб потом не возникало непоняток, можно ли и где хранить состояние. А наложено оно в целях реализации масшатибруемости и кеширования. Если ваши запросы будут удовлетворять возможности масштабируемости и кещирования, то можно хранить состояние, хоть на сервере хоть на клиенте.
Jermes
24.01.2017 03:33Например, pages/nextPage не REST, потому что такой запрос нельзя закешировать. А page/nextPage?sessionId=Vasya вполне себе REST.
lair
24.01.2017 11:38-1А что, ваш второй пример можно закэшировать? Почему он масштабируется лучше, чем первый?
Jermes
24.01.2017 13:10Это не самый лучший пример того, чтобы делать так. Скорей как не делать. Но в зависимости от реализации — можно, если переход по такому URL не подразумевает изменения текущей страницы для пользователя. Понятней был бы пример с current page: pages/current?sessionId=Vasya. Тогда на переход на next page сервер бы менял last modified date для current, а пока next page не вызван, current-ответ может быть возвращен из кеша. Ну а масшабируется, потому что ?sessionId=Vasya и ?sessionId=Petya могут быть перенаправлены на обработку разными серверами или закешированы разными прокси.
lair
24.01.2017 13:16Но в зависимости от реализации — можно, если переход по такому URL не подразумевает изменения текущей страницы для пользователя.
… но он-то подразумевает, это nextPage.
Ну а масшабируется, потому что ?sessionId=Vasya и ?sessionId=Petya могут быть перенаправлены на обработку разными серверами или закешированы разными прокси.
… и чем это отличается от куки, на которых те же сессии делаются обычно?
Jermes
24.01.2017 15:16… но он-то подразумевает, это nextPage.
Зависит от реализации. Это просто может быть указатель на следующую страницу без изменения состояния текущей. Или по-другому — next page может быть точкой отсчета, а current = next-1.
… и чем это отличается от куки, на которых те же сессии делаются обычно?
Тем, что запросы с куками не кешируется и не масштабируется инфраструктурой web, теми же прокси-кэш серверами, например.lair
24.01.2017 15:23Это просто может быть указатель на следующую страницу без изменения состояния текущей.
Следующую относительно чего?
Тем, что запросы с куками не кешируется и не масштабируется инфраструктурой web, теми же прокси-кэш серверами, например.
Хм, точно ли?
(скажем, ARR по кукам как раз делает sticky session)
Jermes
24.01.2017 15:36Следующую относительно чего?
Относительно текущей.
Хм, точно ли?
(скажем, ARR по кукам как раз делает sticky session)
В данной нам реализации web ресурс идентифицируется по URL, а не по кукам и URL. Поэтому запрос не кешируется правильно.
ARR? IIS Application Request Routing? Так это приблуда IIS, какое отношение оно имеет к инфраструктуре web?lair
24.01.2017 15:41Относительно текущей.
А текущая как определяется?
В данной нам реализации web ресурс идентифицируется по URL, а не по кукам и URL. Поэтому запрос не кешируется правильно.
Одно дело — как он идентифицируется, другое — как он кэшируется. Скажем, достаточно очевидно, что нельзя в ответ на запросы к одному и тому же URL отдавать закэшированные ответы с разным
Content-Type, нет? Вот и с куками то же самое.
Vary: Cookie, да.
ARR? IIS Application Request Routing? Так это приблуда IIS, какое отношение оно имеет к инфраструктуре web?
Такое же, как и другие проксирующие/кэширующие маршрутизаторы.
Jermes
24.01.2017 16:32А текущая как определяется?
По sessionID
Vary: Cookie, да.
Спасибо про vary header. Да, с этим хедером запросы будут нормально кешироваться. Значит, проблемы с куками не в кешировании и масштабировании, как я предполагал. Филдинг указывает на другие проблемы с куками, связанные с mis-communication между сервером и клиентом и нарушением приватности из-за того, что они аттачатся к любому запросу (6.3.4.2 Cookies). Решением предлагает использовании context-setting URI. То есть pages/current?sessionId=Vasya будет все-таки REST-ful.lair
24.01.2017 16:55По sessionID
То есть хранится на сервере, может быть изменено другим запросом и так далее. Не, разницы нет никакой — это то же самое сессионное состояние, о котором пишет Филдинг.
То есть pages/current?sessionId=Vasya будет все-таки REST-ful.
Сессионное состояние на сервере противоречит требованию stateless как оно описано в диссертации. Применима ли эта диссертация сейчас — вопрос другой, но пока мы вроде как условились считать ее за исходный камень.
Jermes
24.01.2017 17:31То есть хранится на сервере, может быть изменено другим запросом и так далее.
Чем состояние сессии отличается от любого другого состояния, хранящегося на сервере? Состояние сессии может трактоваться так же как и любой другой ресурс? Как насчет этого:
PUT /session/Vasya
< 201 CREATED
GET /session/Vasya
< 200 OK
< {
< «current-page»: "/session/Vasya/current-page"
< }
POST /session/Vasya/current-page
+1
<200 OK
Не, разницы нет никакой — это то же самое сессионное состояние, о котором пишет Филдинг.
После The client-stateless-server style derives from client-server with the additional constraint that no session state is allowed on the server component. он пишет уточнение Each request from client to server must contain all of the information necessary to understand the request. Тут под session state имеется ввиду, некое неявное из запроса состояние, которое образуется на сервере в результате серии запросов от одного и тоже клиента. В результате чего отдельно взятый запрос из этой серии будет непонятен серверу. Но что непонятного для сервера в запросе session/vasya/current-page или pages/current?sessionId=Vasya?lair
24.01.2017 18:18Чем состояние сессии отличается от любого другого состояния, хранящегося на сервере?
Семантикой, вестимо. И именно в этом месте и начинаются драки за то, что считать stateless, а что — нет.
Тут под session state имеется ввиду, некое неявное из запроса состояние, которое образуется на сервере в результате серии запросов от одного и тоже клиента.
Проблема в том, что вы здесь додумываете, что же именно имеет в виду Филдинг. Вы можете додумать одно, я могу додумать другое, а никакого формального определения нет. Отсюда и дискуссии (включая, собственно, всю эту).
В результате чего отдельно взятый запрос из этой серии будет непонятен серверу.
Что непонятного в запросе?
GET current-page Session: vasyaJermes
24.01.2017 18:54Проблема в том, что вы здесь додумываете, что же именно имеет в виду Филдинг. Вы можете додумать одно, я могу додумать другое, а никакого формального определения нет.
Там явно сказано, что имеется ввиду: Each request from client to server must contain all of the information necessary to understand the request..
Что непонятного в запросе?
Все понятно. И это будет REST-ful, если только session header не будет цепляться к каждому запросу без необходимости, как это делают куки, и добавить Vary:Session. Филдинг описывает проблему с куками ни как-то, что они связаны с user-сессией, а именно: The problem is that a cookie is defined as being attached to any future requests for a given set of resource identifiers, usually encompassing an entire site, rather than being associated with the particular application state (the set of currently rendered representations) on the browser.lair
24.01.2017 19:04там явно сказано, что имеется ввиду: Each request from client to server must contain all of the information necessary to understand the request..
Это не определение сессионного состояния, это определение того, что должен содержать клиентский запрос. И оно нестрогое, потому что формально любой запрос с куками ему соответствует.
Все понятно.
Ну вот видите. Значит, у нас нет никакого формального критерия для различения сессионного состояния.
И это будет REST-ful, если только session header не будет цепляться к каждому запросу без необходимости
Из какого пункта описания REST architectural style это следует?
Jermes
24.01.2017 19:28Это не определение сессионного состояния, это определение того, что должен содержать клиентский запрос.
Это единственное ограничение, указанное Филдингом. Значит, все остальное — позволяется.
И оно нестрогое, потому что формально любой запрос с куками ему соответствует.
Соответствует. Проблема кук не в state.
Из какого пункта описания REST architectural style это следует?
Ни из какого. REST тут не нарушается. Мой fail.
oxidmod
24.01.2017 20:33Что непонятного в запросе?
то, что его результат зависит от предыдущего. Что делать, если установка current-page не была произведена?
Jermes
24.01.2017 20:45Что делать, если установка current-page не была произведена?
404oxidmod
24.01.2017 21:23и это неверный ответ в рамках REST.
потому как current-page роде как иеднтификатор ресурса, но он зависит от предыдущих запросов. и может каждый раз указывать на другой ресурсJermes
24.01.2017 21:53и это неверный ответ в рамках REST.
потому как current-page роде как иеднтификатор ресурса, но он зависит от предыдущих запросов. и может каждый раз указывать на другой ресурс
Я пожалуй соглашусь, что:
GET current-page
Session: vasya
все-таки не REST (как и с куками), но не потому что:
он зависит от предыдущих запросов. и может каждый раз указывать на другой ресурс
Этот момент уже обсуждался выше.
А потому что неуверен, что так будет правильно:
PUT current-page
Session: vasya
PUT current-page
Session:petya
Также нарушено HATEOAS.
То есть наличие session-id в URL только REST-ful.
lair
24.01.2017 21:23то, что его результат зависит от предыдущего
Формально, не от предыдущего, а от набора предыдущих операций с сервером:
POST search POST search/nextPage GET item/10 GET item/11 PUT item/11 GET item/12 DELETE item/12 GET item/13 GET item/14 GET search/currentPage
А в этом смысле уже почти любой запрос "непонятен":
GET item/1 < 404 PUT item/1 < 201 GET item/1 < 200 PUT item/1 < 409 DELETE item/1 < 204 GET item/1 < 404
Тут ведь тоже результат запроса зависит от предыдущего, не так ли?
Что делать, если установка current-page не была произведена?
Определяется бизнес-правилами, очевидно — точно так же, как и "что делать, если обновляют ресурс, которого не существует" и так далее.
oxidmod
24.01.2017 21:34Когда вы создаете ресурс, то в ответ получаете 201 и линку на ресурс с уникальным идентификтором. И делается это както так так:
`
POST /item
{value:1}
< 201 Location: /item/1
GET /item/1
< 200
< {value:1}
DELETE /item/1
< 204
POST /item
{value: 1}
< 201 Location: /item/2
GET /item/1
< 404
GET /item/2
< 200
< {value:1}
`
А вот current-page не идентификатор и однозначно не мапится на ресурс, потому это нифига не REST
lair
24.01.2017 21:37Когда вы создаете ресурс, то в ответ получаете 201 и линку на ресурс с уникальным идентификтором.
В диссертации Филдинга прямо так и написано?
А вот current-page не идентификатор и однозначно не мапится на ресурс, потому это нифига не REST
А в
POST searchчто ресурс? А вPOST /builds/15/enqueue?
Даже более занятный вопрос: что ресурс в
GET /queuedEmails?oxidmod
24.01.2017 21:56Ну я без понятия где вы набрали таких запросов. Теоретически
POST /searchдолжен содержать атрибуты ресурса в теле запроса, который требуется создать. Ну а в ответ получить201 Location: /search/<identifier>.
И теперь мы будем получать 200 и представление этого ресурса как результат GET запроса до тех пор пока его не удалим.
Суть в том, что друому пользователю не нужно повторять создание ресурса, чтобы получить 200 при запросе того же идентификатора.
По поводу Филдинга, ознакомьтесь с Section 5.2
lair
24.01.2017 22:02Ну я без понятия где вы набрали таких запросов. Теоретически
POST /search должен содержать атрибуты ресурса в теле запроса, который требуется создать.Почему это? "The action performed by the POST method might not result in a resource that can be identified by a URI" (RFC 2616, 9.5) И позже: "The URI in a POST request identifies the resource that will handle the enclosed entity. That resource might be a data-accepting process, a gateway to some other protocol, or a separate entity that accepts annotations."
По поводу Филдинга, ознакомьтесь с Section 5.2
Там нет ни слова про обязательные коды ответов HTTP.
oxidmod
24.01.2017 23:26там есть о ресурсах и идентификаторах. Филдинг не предлагал реализацию. Он предложил архитектуру, которая покоитьс на некоторых базовых китах-понятиях. Ресурсы и их идентификация — один из этих китов.
lair
24.01.2017 23:30Я уже процитировал высказывание о ресурсах из той же диссертации. Совершенно не понятно, из какого именно тезиса в диссертации вы делаете вывод, что
/search— не ресурс (или чтоPOSTна него обязан создавать новую сущность).
(BTW, не архитектуру, а архитектурный стиль)
oxidmod
25.01.2017 10:49Еще раз, я не говорю, что /search не ресурс. Но если это ресурс, то любой клиент запросив /search должен получить ровно тоже самое, без предварительных плясок с цепочокой запросов, приводящие серч в нужное состояние.
POST не обязан создавать новый ресурс, это уже вопрос реализации. Но както так вышло, что обычно постом создают ресурсы, а гетом читают.
lair
25.01.2017 11:26+1любой клиент запросив /search должен получить ровно тоже самое
Это, как мы понимаем, противоречит здравому смыслу, причем не важно,
/searchу вас или/books.
Но както так вышло, что обычно постом создают ресурсы, а гетом читают.
Это если у вас ресурсы имеют CRUD-семантику (да и то не обязательно). Но ей же дело не ограничивается.
oxidmod
25.01.2017 11:36окай, я погорячился с "тоже самое". Да тут вылазят вопросы с авторизацией/правами и прочее. Но условно, если есть 2 юзера с правом чтения этого ресурса, то оба должны получать этот ресурс при одинаковом запросе до тех пор, пока ресурс не будет удален. При этом второму юзеру не нужно повторять всю цепочку запросов, которая привела ресурс в определнное состояние, чтобы это сосотояние в итоге увидеть. Именно этот ресурс. Если ресурс был удален, а потом создан новый с таким же содержимым — это всеравно уже другой ресурс, и у него должен быть свой уникальный идентификатор.
lair
25.01.2017 11:40Но условно, если есть 2 юзера с правом чтения этого ресурса, то оба должны получать этот ресурс при одинаковом запросе до тех пор, пока ресурс не будет удален. При этом второму юзеру не нужно повторять всю цепочку запросов, которая привела ресурс в определнное состояние, чтобы это сосотояние в итоге увидеть.
Ну так и
/searchведет себя так же — все юзеры, которые имеют право на эту операцию, получают некий ответ. То, что этот ответ зависит от пользователя — так это технически ничем не отличается от разграничения по правам.
Соответственно, все это обсуждение скатывается к семантике, которая у Филдинга (естественно), не формализована.
Если ресурс был удален, а потом создан новый с таким же содержимым — это всеравно уже другой ресурс, и у него должен быть свой уникальный идентификатор.
Это, кстати, неверно. Цитату про идентификаторы и семантику я уже приводил.
oxidmod
25.01.2017 11:48Я умываю руки… Как можно не понимать, что не должно быть зависимости от цепочки предыдущих запросов???
lair
25.01.2017 11:49+1Как можно не понимать, что не должно быть зависимости от цепочки предыдущих запросов?
Очень просто: нет определения "зависимости". Результат следующего запроса зависит от предыдущих проведенных? Так это нормальное поведение нормальной бизнес-системы.
oxidmod
25.01.2017 12:37-1Результат следующего запроса зависит от предыдущих проведенных? Так это нормальное поведение нормальной бизнес-системы.
Ну да. Бухгалтер чтобы посмотреть в 1С-ке ваши зарплаты за период должен сначала по новому их вам начислить… каждый раз. А вам нужно каждый раз выполнить теже задания в той же последовательности, чтобы глянуть сколько ж вам зп пришло за прошлый месяц
lair
25.01.2017 12:42Аналогии с подменой — некрасиво.
Результат запроса "покажи начисления за последний месяц" будет зависеть от того, какие начисления были проведены в последнем месяце (=какие запросы "сделай начисление" были выполнены)?
oxidmod
25.01.2017 13:08Вы меня тролите? Да, естественно что
Результат запроса "покажи начисления за последний месяц" будет зависеть от того, какие начисления были проведены в последнем месяце
Но не естесвенно, что другому бухгалтеру, чтобы увидеть точно такой же отчет по запросу "покажи начисления за последний месяц" нужно предварительно повторить все эти начисления.
После того как период был закрыт, любой бухгалтер просто запросив отчет за этот период увидит точно такую же картинку.
Вот если бы в вашем примере с currentPage было, что Петя устанавливает currentPage, а Вася запрашивая currentPage увидит то, что установил Петя (ему не надо по новому начислять зп, чтобы увидеть такой же отчет как у Пети), то вопросов нет.
lair
25.01.2017 13:25-1Вот если бы в вашем примере с currentPage было, что Петя устанавливает currentPage, а Вася запрашивая currentPage увидит то, что установил Петя
Ну нет. Мы же уже выясняли, что один и тот же ресурс может иметь разные представления для разных пользователей. Авторизация, бизнес-ограничения, вот это все. Поэтому максимум, которого вы можете ожидать — это то, что когда Вася установил currentPage, Вася потом его и увидит… но ведь это так и есть.
oxidmod
25.01.2017 13:35Окей, только тот бухгалтер, который зп вам нащитал сможет для вас сформировать отчет. А другой не сможет. А когда именно этот помрет — вы вообще потеряете возможность смотреть отчеты, потому что кто установил тот и смотрит.
Вопросы авторизации/прав ортогональны существованию ресурсов. От того что у вас нет прав их смотреть не значит что их не существует. Просто вы получите ответ в виде: "доступ запрещен, обратитесь к администратору". Суслик же есть
lair
25.01.2017 13:39+1Окей, только тот бухгалтер, который зп вам нащитал сможет для вас сформировать отчет. А другой не сможет.
Так иногда бывает, вы не поверите.
Вопросы авторизации/прав ортогональны существованию ресурсов.
Да, ортогональны. Но они влияют на то, как ресурс отображается конечному клиенту, поэтому игнорировать их нельзя (иначе получаются ошибки вида "Вася увидит то же, что и Петя").
Просто вы получите ответ в виде: "доступ запрещен, обратитесь к администратору".
… или, если используется соответствующая политика безопасности, "ресурс не найден". Потому что раскрытие информации о существовании ресурса — потенциальная уязвимость.
lair
24.01.2017 21:56Ну да, к разговору о "не ресурс":
The definition of resource in REST is based on a simple premise: identifiers should change as infrequently as possible. Because the Web uses embedded identifiers rather than link servers, authors need an identifier that closely matches the semantics they intend by a hypermedia reference, allowing the reference to remain static even though the result of accessing that reference may change over time. REST accomplishes this by defining a
resource to be the semantics of what the author intends to identify, rather than the value corresponding to those semantics at the time the reference is created. It is then left to the author to ensure that the identifier chosen for a reference does indeed identify the intended semantics.
Johanga
20.01.2017 22:29+1ИМХО ключевая фраза в 5.1.3 Stateless
each request from client to server must contain all of the information necessary to understand the request, and cannot take advantage of any stored context on the server.
Т.е. пример с nextPage правильно описывает stateless.

f0rk
20.01.2017 13:24На сервере нет дополнительной информации (отсутствующей в запросе), которая позволила бы ответить на этот запрос как-то иначе.
lair
20.01.2017 13:27На сервере нет дополнительной информации (отсутствующей в запросе), которая позволила бы ответить на этот запрос как-то иначе.
Это неправда. Если бы на сервере уже существовал ресурс с адресом
/clients/1, ответ был бы200 OK/204 No Content(ну или отказ в модификации, если она запрещена).f0rk
20.01.2017 13:29Если бы на сервере уже существовал ресурс с адресом /clients/1, ответ был бы 200 OK/204 No Content (ну или отказ в модификации, если она запрещена).
Этот факт никак не связан с содержимым запроса, не нужно путать идемпотентность и statless
lair
20.01.2017 13:32Подождите-подождите. Мы говорим не о содержимом запроса, а о состоянии. Вы только что утверждали, что
На сервере нет дополнительной информации (отсутствующей в запросе), которая позволила бы ответить на этот запрос как-то иначе.
При этом мы уверенно наблюдаем, что отсутствующая в запросе информация "на сервере этот объект есть/нет" влияет на ответ сервера.
Не согласуется.
f0rk
20.01.2017 13:44Подождите-подождите. Мы говорим не о содержимом запроса, а о состоянии.
Мы говорим о понятии stateless в контексте REST.
отсутствующая в запросе информация "на сервере этот объект есть/нет"
Эта информация не имеет никакого отношения к сессии, любому клиенту с таким запросом при отсутствии объекта вернется 201, а при наличии 200
lair
20.01.2017 13:47Мы говорим о понятии stateless в контексте REST.
… которое определено как именно?
Эта информация не имеет никакого отношения к сессии, любому клиенту с таким запросом при отсутствии объекта вернется 201, а при наличии 200
Вооот. То есть не "на сервере нет дополнительной информации (отсутствующей в запросе), которая позволила бы ответить на этот запрос как-то иначе", а "на сервере нет сессионной информации, которая позволила бы ответить на этот запрос как-то иначе".
(заметим, в случае кэша это тоже не вполне верно, но кэш мы пока обсуждать не будем)
f0rk
20.01.2017 13:50на сервере нет сессионной информации
Мой первый коммент в этой ветке:
Сессионного вестимо
Хорошо бы уметь держать контекст обсуждения в голове во время спора (конечно не в том случае когда хочется потроллить :))
kafeman
20.01.2017 13:35Если ресурс уже существует, то значит все клиенты получат одинаковый ответ. Если ресурс нельзя модифицировать, то либо также все клиенты получат ошибку, либо только вы, но для этого в запросе есть некая информация для валидации (например, access token).
lair
20.01.2017 13:45А какая разница, все ли клиенты получат одинаковый ответ, или кто-то получит разный?
С моей точки зрения, намного интереснее то, что один и тот же клиент в ответ на две последовательные идентичные операции получит разный ответ. Это как бы явно говорит нам о наличии состояния.
kafeman
20.01.2017 14:04+1Вы спросили f0rk, что есть stateless, он вам ответил:
На сервере нет дополнительной информации (отсутствующей в запросе), которая позволила бы ответить на этот запрос как-то иначе.
Вы начали приводить пример с разграничением прав доступа и т.д., а я вам ответил, что это никак не противоречит цитате выше. Либо в запросе действительно нет никакого идентификатора сессии и т.д., но тогда и нет основания ответить на него как-то иначе, либо она есть, но тогда за сохранение состояния между двумя запросами отвечает клиент, а не сервер. Более того, один физический клиент может иметь сразу несколько сессий, но все-равно именно он отвечает за то, какую сессию использовать.
Возможно, стоит тут подойти с другой стороны. Например, как выглядит statefull API?
glClearColor(0.0, 0.0, 0.0, 0.0); glClear(GL_COLOR_BUFFER_BIT);
В данном случае, OpenGL явно хранит некоторое внутреннее состояние, которое зависит от ранее вызванных процедур.lair
20.01.2017 14:09-2Вы начали приводить пример с разграничением прав доступа и т.д
Нет, никакого разграничения прав доступа в моем основном примере не было, только разница между созданием и обновлением.
VolCh
20.01.2017 20:45В REST stateless означает отсутствие состояния у соединений между клиентами и серверами, а не у каких-то там объектов. Работа с состоянием в подавляющем большинстве случаев — это цель создания сервера. Не запрещено и на клиенте хранить сколько угодно сложные состояния. stateless означает, что одна атомарная бизнес-операция должна осуществлять за один запрос к серверу, вся информация, необходимая для его осуществления должна содержаться в запросе. Нельзя, например, описывать взаимодействие так:
1. клиент посылает запрос на аутентификацию
2. сервер проверяет кредсы и сохраняет в сессии идентификатор пользователя, возвращает (например в куки) какой-то токен, идентифицирующий сессию
3. клиент посылает запрос на создание ресурса, с указанием токена, но без указания своего единтификатора
4. сервер по идентификатору сессии достаёт идентификатор пользователя, добавляет его к данным запроса и записывает в базу
По REST на втором шаге сервер должен возвратить клиенту идентификатор пользователя, на третьем клиент передать его серверу, на четвертом сервер должен для изменения состояния использовать его, а не сохраненное в сессии.VolCh
21.01.2017 11:25Если ответ не зависит от того прогрет кэш или нет — функционально rest. Если клиенту нужно учитывать, что первый ответ будет долгим, а другие быстрыми — то не rest по неофункциональным критериям.
f0rk
20.01.2017 13:08Сессионного вестимо
lair
20.01.2017 13:13То есть сервис, который внутри себя создает сессию-на-пользователя и кэширует в ней объекты для ускорения доступа — не REST?
f0rk
20.01.2017 13:21Если кеширует — это не проблема, если изменяет из-за факта наличия сессии — то не REST
lair
20.01.2017 13:23Но сессионный кеш — это все равно сессионное состояние. Получается, что какое-то сессионное состояние можно, а какое-то нельзя. Так?
если изменяет из-за факта наличия сессии — то не REST
Изменяет что?
f0rk
20.01.2017 13:26Изменяет что?
объекты
Но сессионный кеш — это все равно сессионное состояние. Получается, что какое-то сессионное состояние можно, а какое-то нельзя. Так?
Так, это вопрос терминологии и понятия stateless в контексте REST
lair
20.01.2017 13:29Так, это вопрос терминологии и понятия stateless в контексте REST
Вот и выходит, что простое "отсутствие состояния" недостаточно для понимания REST, потому что мы вот уже с десяток комментариев пытаемся выяснить, какого же состояния быть не может, а какое — может.

Cykooz
20.01.2017 13:47+7Всё на самом деле просто. Сервер, между отдельными запросами, не хранит какого либо контекста (состояния) в котором находится клиент и какие запросы до этого он выполнял.
Примером системы, которая хранит состояние может быть например «помощник» с голосовым интерфейсом (Google Now например). Для такой системы нет ничего необычного в такой последовательности запросов:
1. Какая температура в Москве?
2. А в Самаре?
Тут видно, что «сервер» должен для выполнения второго запроса помнить, что перед этим клиент спрашивал про температуру.
В случае же REST запросы должны быть такими:
1. Какая температура в Москве?
2. Какая температура в Самаре?
Тут сервер ничего не помнит про предыдущие запросы и каждый новый запрос выполнят без оглядки на предыдущие, т.к. все необходимые для выполнения данные находятся в текущем запросе. Такой подход позволяет легче масштабировать систему, т.к. нет необходимости, что бы все запросы клиента обрабатывались только одним или несколькими серверами, у которых есть доступ к хранилищу «состоянию» клиента.
lair
20.01.2017 13:53-2Сервер, между отдельными запросами, не хранит какого либо контекста (состояния) в котором находится клиент и какие запросы до этого он выполнял.
Если быть совсем точным, клиент не ожидает от сервера, что тот хранит такой контекст, и поэтому постоянно его шлет. Что при этом хранит сервер — его личное дело, до тех пор, пока оно не противоречит ожидаемому клиентом поведению.
plartem
20.01.2017 22:17Тогда какой смысл в применении стандарта JSON-RPC, а именно части с id?
kafeman
20.01.2017 23:08Чтобы понять, ответ на какой запрос мы получили.
plartem
21.01.2017 01:37Разве при отправке запроса клиент не ожидает ответа на этот же запрос? Ведь если так, то становится очевидно, на какой запрос пришел ответ.
kafeman
21.01.2017 08:01При отправке одного запроса — да, ожидает. А если сделать два запроса, притом второй успеет отработать быстрее, чем первый?
VolCh
21.01.2017 13:57Запросы бывают асинхронными, отправляемые без ожидания ответа на предыдущий, ответы бывают приходят не в порядке отправления.

ivanych
20.01.2017 14:40Я это формулирую так — сервер не хранит состояние клиента. Уточнение про сессионное состояние клиента — излишнее, потому что у клиента, на самом деле, нет никакого другого состояния.
Каждый запрос от клиента сервер воспринимает как «первый раз в жизни вижу этого чувака». Логинился клиент раньше или нет, передавал какие-то данные или нет — пофигу.
Соответственно, чего бы клиент ни хотел от сервера — все необходимые для этого данные он должен передать в запросе.lair
20.01.2017 14:43Уточнение про сессионное состояние клиента — излишнее, потому что у клиента, на самом деле, нет никакого другого состояния.
Эмм, почему у клиента нет другого состояния?
В остальном, впрочем, я склонен с вами согласиться. И это, кстати, совпадает с тезисом из Филдинга: "Each request from client to server must contain all of the information necessary to understand the request, and cannot take advantage of any stored context on the server"
ivanych
20.01.2017 14:47-1> Эмм, почему у клиента нет другого состояния?
А потому что слово «состояние» уже подразумевает некий «текущий момент», т.е. это и есть сессионное состояние. Тавтология, в общем.lair
20.01.2017 14:48-1Ну а как же состояние, скажем, бизнес-процесса?
ivanych
20.01.2017 14:53Ээ… бизнес-процесса? Не понял. Я про клиента же. Клиент — это программа, её состояние сервер не хранит. А бизнес-процесс — это какая-то абстракция не из rest-a, это про что-то другое.
lair
20.01.2017 14:54Когда клиент (программа) хранит (в памяти или локально) список заказов, сделанных пользователем — это состояние клиента или нет?
ivanych
20.01.2017 14:58Так список заказов хранит не клиент, в смысле не тот клиент, который клиент rest-а. Список хранит программа, часть которой является клиентом rest-a. Но тут, пожалуй, уже метафизика начинается:)
lair
20.01.2017 14:59Эмм, почему эта программа не клиент REST-а?
ivanych
20.01.2017 15:23А если список хранит не программа, а покупатель в голове? Шастает по сайту и хранит в голове. А потом вписывает разом покупки в заказ.
Хранит ли такая система состояние?
Является ли такая система клиентом rest-а?
Кто в этой системе хранит состояние? Клиент?
Кого тут вообще считать клиентом?
lair
20.01.2017 15:25-1Спасибо, но, пожалуй, не интересно.
ivanych
20.01.2017 15:31Впрочем, даже если считать всю систему программа-пользователь черным ящиком и весь этот ящик называть клиентом, так это всё-равно ничего не меняет.
В паре клиент-сервер у этого клиента с точки зрения сервера есть только одно состояние — «какой-то новый клиент, никогда его раньше не видел». Что там себе клиент внутри хранит — вообще без разницы.VolCh
20.01.2017 17:20А в рамках системы целиком состояние есть у клиента (хоть с пользователем, хоть без) и у сервера. А ещё есть коммуникационный прикладной канал между ними. Имеет канал состояние — система не rest. Не имеет — rest, незаисимо от того есть ли состояние у сервера и есть ли у клиента.
VolCh
20.01.2017 12:35На каком-то уровне восприятия у меня есть понимание разницы между архитектурой распределенного приложения в стиле REST и конкретным сервисом, использующем в качестве прикладного протокола HTTP с JSON согласно семантики HTTP из спецификации и HTTP over TCP в качестве транспорта. Но как в разговорной речи на русском кратко различать не знаю. Есть варианты?



funca
24.01.2017 01:27+1Основные вопросы, которые должен был решить REST, связаны с Hypermedia. Поэтому главный упор при выборе компромиссов в данном архитектурном стиле был сделан на решение проблем, касающихся представления.
Что же касается выполнения транзакций, то этот действительно важный и сложный вопрос в REST затронут только чуть (по сложившейся традиции затрагивать действительно важные и сложные вопросы с тем самым с умным видом, как будто и так все понятно).
По теме коммуникации в стиле REST/HTTP есть классная картинка на сайте Webmachine, как вариант описания единичной транзакции с помощью диаграммы — не к столу будет сказано — состояний.
Некоторая часть моментов, с которыми обычно сталкиваются разработчики RESTful приложений на концептуальном уровне, при решении простых задач, метафорически описана в How to GET a Cup of Coffee (ага, «нельзя просто так взять и взять»). Задачи конкуретного обновления (что, в принципе, не такая уж и экзотика для распределенных приложений), с большой вероятностью могут привести к двух- (трех-, рекурсивно-) фазным коммитам. Каково это в реализации для не очень сложного кейса про дебет с кредитом можно посмотреть, например здесь (не совсем REST, но очень близко по составу операций, буквально точностью до синтаксиса).
Конечно, в реальности, так ни кто не делает — это ни в какой бюджет. Всегда есть возможность отойти от канонов, в пользу каких-то упрощений. Как следствие, с момента изобретения, для индустрии вся эта веселуха вокруг RESTful архитектур вылилась в хренову гору человеко-часов, потраченных на разработку «подходящих» имплементаций REST-style со стороны тех кто старался что-то сделать, и гигабайты срачей в комментах со стороны тех кто пытался что-то понять.

Leoon
25.01.2017 21:21Мне кажется опечатка в склонении, или мне кажется.
Модель RMM состоит из 4 уровня

onekit
25.01.2017 21:21Кто любит Symfony2, я по ReST пример на open-source выложил:
https://github.com/onekit/rest-tutorial
Начинающим самое оно, а pull-request-ы всегда welcome.
grossws
25.01.2017 23:51Copyright © 2004-2016 Fabien Potencier
Выложили на github, видимо, положив на принятые в open source вещи типа ссылки на оригинального автора, который, судя по сайту https://symfony.com/doc/master/contributing/code/license.html и является реальным автором кода, на котором базируется ваш.
onekit
26.01.2017 00:00+1В коде по данной ссылке нет ни одного файла написанного Фабьеном Патенсьером, это Вы подгрузите в зависимостях с остальными библиотеками и увидите его копирайт внутри его библиотеки.
Ну и уж если заниматься буквоедством, то Symfony2 является фреймворком, написанным огромным комьюнити контрибутеров. Не уместно ставить копирайт на одного Фабьена. Загляните в composer.json, там кроме Symfony2 много других зависимостей, например PHP, значит и копирайт создателя PHP следует поставить. А если уж его, то тогда и создателя С/C++, который в свою очередь использовал Ассемблер.

illiakailli
29.01.2017 03:22Кроме этого, веб-сервис сам описывает себя без каких-либо WSDL.
Это немного не так, скорее, он пытается сам себя описать, но у него ничего толком не получается.
Советую посмотреть на Swagger, там эту проблему решают по-взрослому.
kafeman
Deosis
Скорее всего через гугл-транслейт
VolCh
Скорее всего, везде шифрование надо читать как кодирование.
RomanPyr
Или «сериализация» (что тоже самое, но звучит ближе к оригиналу).
SemmZemm
Видимо, имелся в виду формат данных (кодирование?)
andrey_grunyov
Сериализация
TipTep
Да, похоже термин не подходящий подобрал. Имел ввиду data encoding.
grossws
encoding != encryption