

Второй такой задачей является прогнозирование временных рядов с заданной точностью. Сети прямого распространения с сигмоидальной активационной функцией не дают возможности предсказать ошибку по количеству скрытых нейронов. Для того чтобы можно было предсказать эту ошибку стоит использовать какой-нибудь ряд для скорости сходимости которого есть расчетные формулы. В качестве такого ряда был выбран ряд Фурье.
Ряд Фурье
Комплексный ряд Фурье от одной переменной.

Но нейронные сети зачастую работают с функциями многих переменных. Предлагаю рассмотреть ряд Фурье от двух независимых переменных. [2]
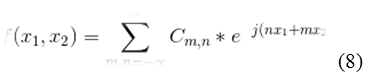
В общем случае следует использовать ряд Фурье для функций от «k» переменных.
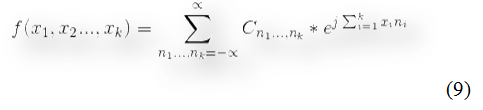
Архитектура
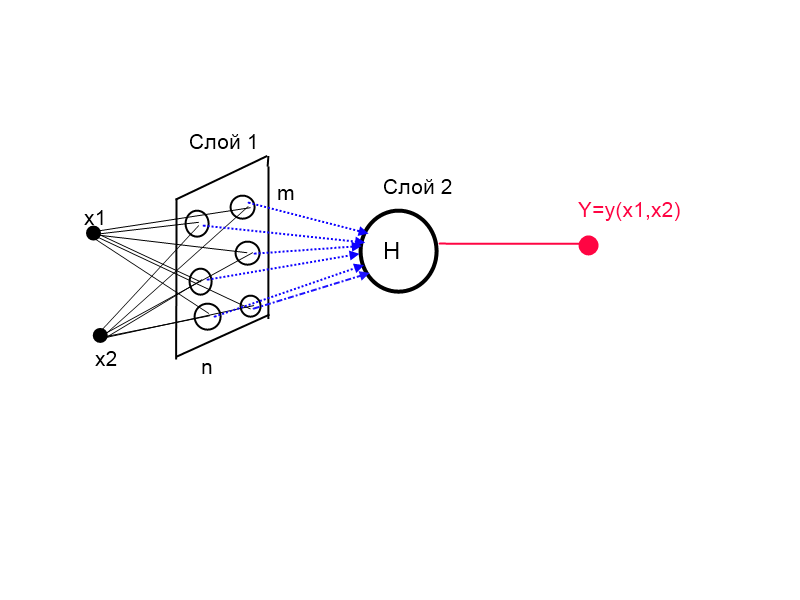
Рисунок 1. Архитектура комплексной сети (КИНСФ)
На рисунке 1 показана архитектура комплексной искусственной нейронной сети Фурье (КИНСФ), которая по сути реализует формулу 9. Здесь скрытый слой представляет собой матрицу нейронов mxn где m — число дескрипторов разложения Фурье, а n — размерность входного вектора. Веса в первом слое имеют физический смысл частот с наибольшей энергией, а веса второго слоя имеют смысл коэффициентов ряда Фурье. Таким образом, количество входов у каждого нейрона выходного слоя равно m*n, что соответствует количеству коэффициентов ряда Фурье.
На рисунке 2 представлена схема отдельного нейрона скрытого слоя.
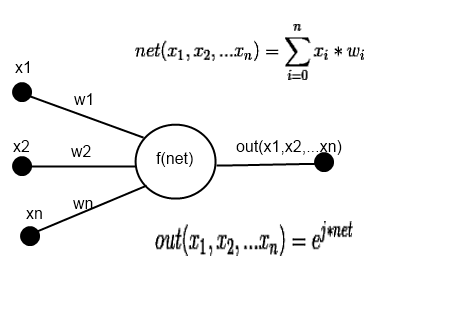
Рисунок 2. Схема нейрона скрытого слоя.
На рисунке 3 — схема нейрона выходного слоя.
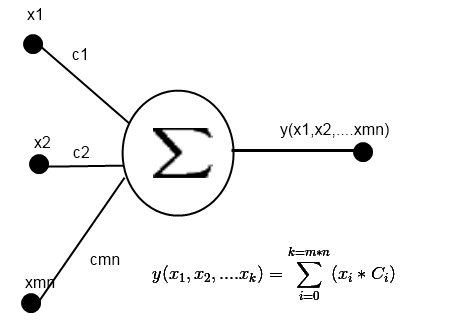
Рисунок 3. Схема нейрона выходного слоя.
Оптимизация архитектуры
Создание матрицы нейронов предполагает использование больших вычислительных ресурсов. Можно сократить количество нейронов на скрытом слое в n раз. В этом случае каждый нейрон скрытого слоя имеет n выходов, если у нас в сети n входов, то при таком подходе количество связей уменьшается n квадрат раз без потери качества аппроксимации функций. Такая нейронная сеть представлена на рисунке 4.
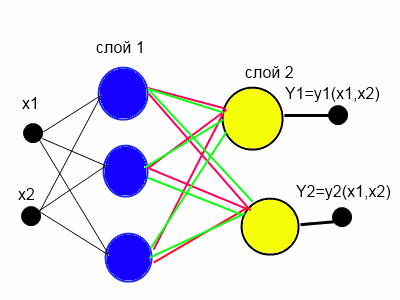
Рисунок 4. КИНСФ, сведение матрицы в вектор.
Принцип работы НС
Запишем принцип работы данной НС в матричной форме.
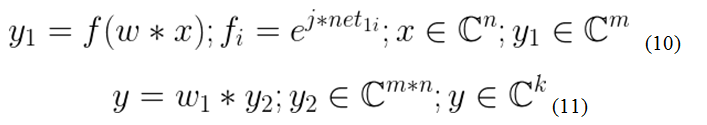
Выражение 10 описывает выход скрытого слоя, где: n — размерность вектора входного «x», m — размерность выходного вектора скрытого слоя «y1», f—активационная вектор-функция, j — мнимая единица, w—матрица весов, net1=w*x, k — количество выходов НС. Выражение 11 в свою очередь показывает работу выходного слоя, вектор «y2» получен путем n-кратного дублирования вектора y1. В приложении «А», для наглядности методов реализации, представлен листинг программы, которая работает на основе выражений 10-11.
Сведение задачи обучения, к задаче обучения однослойного персептрона.
Используя физический смысл весов нейронов скрытого слоя, а именно что веса нейронов скрытого слоя представляет собой частоты. Предположив что колебания периодические можно определить начальные циклические частоты для каждого направления, и проинициализировать веса таким образом, что переходя от нейрона к нейрону частоты будут кратно увеличиваться. Так можно свести задачу обучения сложной двухслойной сети к задаче обучения однослойного персептрона. Единственная сложность заключается в том, что входы и выходы этого персептрона является комплексными. Но методы обучения данной сети мы рассмотрим в следующей статье.
Модификация КИНСФ для задач распознавания
В задачах распознавания или классификации на выходе нейронные сети необходимо получить, так называемую функцию принадлежности[3], значение которой лежит в пределах, от нуля до единицы. Для ее получения очень удобно использовать логистическую сигмоидальную функцию(Рисунок 5). преобразовав немного нейроны моей сети, возможно получить сеть для распознавания образов. Такая сеть хорошо подходит для распознавания бинарных изображений, обработанных по методу, который указан выше(выражения 1—6). Она принимает на вход комплексные числа, после чего аппроксимирует функцию принадлежности образа к классу.[4]
На рисунке 6 изображен нейрон скрытого слоя, а на рисунке 7 — выходного.
Как мы видим, схема скрытого нейрона не изменилась, чего нельзя сказать о нейронах выходного слоя.
Рисунок 6. Схема скрытого нейрона.

Рисунок 7. Схема выходного нейрона.
Эксперимент
Для эксперимента был выбран ряд картинок, одна из них представлена ниже. Перед распознаванием использовались алгоритмы бинаризация и приведения к общему виду.
Приведение к общему виду выполнялось по алгоритму, представленному выше(1-6). После чего вектор, в случае с КИНСФ подавался полностью «как есть» на искусственную нейронную сеть, а в случае с НС с сигмаидальной активационной функцией, отдельно подавались реальные и мнимые компоненты, после чего вектор распознавался. Эксперимент проводился с использованием двух типов НС. Сеть прямого распространения с сигмоидальной активационной функцией и КИНСФ. Объем обучающей выборки составил 660 векторов разбитых на 33 класса. Программа представлена на рисунке 8.

Рисунок 8. Программа для распознавания рукописного текста.
На сеть с сигмоидальной активационной функцией подаются отдельно реальные и мнимые составляющие комплексного вектора. КИНСФ и ИНС с сигмоидальной активационной функцией обучались с помощью дельта-правила 500 циклов обучения. В результате тестирования 400 изображений КИНСФ выдал точность в 87%, а ИНС с сигмоидальной активационной функцией 73%.
Код
public class KINSF_Simple
{
ComplexVector input; // Вход
ComplexVector output, //Выход
fOut; //Выход скрытого слоя
Matrix fL; // Матрица весов первого слоя
ComplexMatrix C; // Матрица весов второго слоя
int inpN, outpN, hN, n =0 ;
Complex J = new Complex(0,1); // Мнимая единица
public KINSF_Simple(int inpCout, int outpCout, int hLCount)
{
inpN = inpCout;
outpN = outpCout;
hN = hLCount;
// Инициализация весов случ. образом
fL = Statistic.rand(inpN, hN);
C = Statistic.randComplex(inpN*hN,outpN);
}
/// <summary>
/// Вектор-функция активации первого слоя
/// </summary>
/// <param name="compVect">Вход</param>
/// <returns></returns>
public ComplexVector FActiv1(ComplexVector compVect)
{
ComplexVector outp = compVect.Copy();
for(int i = 0; i<outp.N; i++)
{
outp.Vecktor[i] = Complex.Exp(J*outp.Vecktor[i]);
}
return outp;
}
/// <summary>
/// Выход первого слоя
/// </summary>
/// <param name="inp">Вход</param>
void OutputFirstLayer(ComplexVector inp)
{
input = inp;
fOut = FActiv1(inp*fL);
}
/// <summary>
/// Выход второго слоя
/// </summary>
void OutputOutLayer()
{
List<Complex> outList = new List<Complex>();
for(int i = 0; i<inpN; i++)
{
outList.AddRange(fOut.Vecktor);
}
ComplexVector outVector = new ComplexVector(outList.ToArray());
output = fOut*C;
}
/// <summary>
/// Отклик НС на входной вектор
/// </summary>
/// <param name="inp">Входной вектор</param>
/// <returns></returns>
public ComplexVector NetworkOut(ComplexVector inp)
{
OutputFirstLayer(inp);
OutputOutLayer();
return output;
}
}
Видео работы
Ниже приведено видео работы данной программы, что была в тесте. Записывал его как демонстрацию того, как можно применять ИНС. Сразу извиняюсь за вольное изложение.
Итоги
Преимущества:
Данная сеть имеет ряд преимуществ. Важнейшим является то, что эта сеть может работать с комплексными числами. Ее можно использовать для работы с сигналами, заданными в комплексном виде. Также она очень хорошо подойдет для распознавания бинарных изображений. Она может аппроксимировать функцию, оставляя все свойства преобразования Фурье, что делает ее работу легко анализируемой. Ведь именно не анализируемость работы нейронных сетей приводит к тому, что научных проектах от них все чаще отказываются, решая задачи другими методами. Также физический смысл весов позволит использовать эту нейронную сеть для численного разложения функции многих переменных в ряд Фурье.
Недостатки:
Существенным недостатком данной нейронной сети является наличие большого количества связей. Намного превышающего количество связей сетей прямого распространения типа персептрон.
Дальнейшее изучение:
В ходе дальнейшей работы над этой нейронной сетью планируется: разработать более совершенные методы обучения, доказать сходимость обучения, доказать отсутствие ошибки переобучения для любого количества нейронов на скрытом слое, построить рекуррентную нейронную сеть на базе КИНСФ, предназначенную для обработки речевых и прочих сигналов.
2. Фихтенгольц Г.М. Курс дифференциального и интегрального исчисления. Том 3. — М.: ФИЗМАТЛИТ, 2001.
3. Заде Л. Понятие лингвистической переменной и его применение к принятию приближенных решений. — М.: Мир, 1976.
4. Рутковская Д., Пилиньский М., Рутковский Л. Нейронные сети, генетические алгоритмы и нечеткие системы: Пер. с польск. И. Д. Рудинского. — М.: Горячая линия -Телеком, 2006.
Комментарии (26)
erwins22
03.02.2017 10:08Tensorflow работает с комплексными числами.

Zachar_5
03.02.2017 10:28-2Я тут ничего не могу сказать, перед тем как писать я посмотрел статьи на киберленинке и в гугле гуглил, но так и не нашел статей про сети работающие на основе ряда Фурье. Буду благодарен если Вы приведете ссылку на работу по этой теме.

BalinTomsk
03.02.2017 19:46+1Как можно пропустить сеть которaя в основном мировом тренде?
https://www.tensorflow.org/api_docs/python/math_ops/complex_number_functions
Danov
04.02.2017 12:39+1А разве это не просто мат библиотека для работы с комплексными числами?
Отсюда не следует, что сети в Tensorflow работают с комплексными числами. Например, если комплексное число разбивается на пару (Re,Im) и подается на сетку двумя скалярными переменными, тогда это не работа сети с комплексными числами.

devpony
03.02.2017 10:47+8Вы показали нам формулу разложения функции в бесконечный (!) ряд Фурье, потом показали нам обычный однослойный перцептрон с экспоненциальной функцией активации и утверждаете теперь, что «сеть работает на основе ряда Фурье». Нет, не работает.
1. Почему вы показываете нам бесконечный ряд, когда ваша сеть обладает конечным набором параметров?
2. Где доказательство, что коэффициенты сойдутся к коэффициентам ряда Фурье? (Подсказка: не сойдутся)
3. Почему в статье полно формул, которые вообще ничего не значат и нет ни одной важной, например формулы инициализации весов?
У вашей сети и ряда Фурье из общего только значёк экспоненты. По факту это традиционный однослойный перцептрон с очень плохой функцией активации. К слову, комплекснозначная сеть полностью аналогична такой же вещественнозначной в два раза большего размера. А привычная CNN решила бы вашу задачу распознавания на 99%.Zachar_5
03.02.2017 11:02-31) CNN нужно около 1000 образов на класс, так же CNN не имеет расчетных формул и ее архитектура подбирается эмпирически.
2) Если расписать уравнение этой сети, то Вы получите ряд Фурье для многих переменных.
3) Так же я писал, что сеть не доработана. И сейчас я занимаюсь ее доработкой.
4) Сигмоидальная функция в другой модификации, а в первой ее нет. И первая работает так же как и ряд Фурье.devpony
03.02.2017 11:36+4Вот ваша сеть:

(почему я, а не вы сделали эту картинку?)
Вот разложение функции в ряд Фурье в L2:

Где коэффициенты, к слову, определяются единственным образом как скалярное произведение функции на элементы базиса. Если честно, даже отдалённого сходства не вижу.
Но… даже если бы сходство было… У вас сумма конечная, у ряда Фурье — бесконечная. К каким именно по счёту членам ряда сойдутся ваши коэффициенты? К первым? Почему? Почему не к сорок второму? Почему в ходе оптимизации коэффициенты сойдутся к аналитическим? Похожесть (и даже одинаковость) формул этого не гарантирует и не может гарантировать.

babylon
05.02.2017 19:35На самом деле сходимость для практических задач не является необходимым условием. Возможно некоторыми коэффициентами (весами ) автор сознательно пренебрегает. Это же не чистая математика.

Halt
03.02.2017 17:17Но зачем картинки если на хабре уже давно работают формулы? Имхо, выкладывать статью в таком виде — проявлять неуважение к читателям.
Zachar_5
03.02.2017 17:44Я извиняюсь за такой вид! Не умею верстать в этом редакторе. Если подскажете как загружать doсx или pdf файлы — будет здорово. Но я не нашел.
Gryphon88
05.02.2017 18:40Извините, а откуда следует TRS-инвариантность, если мы используем классическую матрицу с квадратным пикселом? Насколько я знаю, совсем наоборот (Glenn D. Boreman "Modulation Transfer Function in Optical and ElectroOptical Systems", SPIE, 2001)
GeMir
С формулами на первой, да и на последующих «иллюстрациях» в статье стряслось что-то очень нехорошее.
Zachar_5
Я вначале в Word писал, а потом отскринил.
GeMir
Очевидно, что так делать не нужно. Ну и так далее.
babylon
Браво Захар! Очевидно, что над формулами которые Вы привели кто-то сильно подумал. Но разве оптическая сетка не вносит искажения или это где-то учтено в них.
Zachar_5
Если Вы за формулы 1-6, то это сделано для получения пространства признаков.
MadWombat
То что библиотека tensorflow умеет обращаться с комплексными числами не значит, что вариант нейронных сетей приведенный автором широко используется.