
Многие распределённые системы хранения (в том числе Cassandra, Riak, HDFS, MongoDB, Kafka, …) используют репликацию для сохранности данных. Их обычно разворачивают в конфигурации «просто пачка дисков» (Just a bunch of disks, JBOD) — вот так, без всякого RAID для обработки сбоев. Если один из дисков в ноде отказывает, то данные этого диска просто теряются. Чтобы предотвратить безвозвратную потерю данных, СУБД хранит копию (реплику) данных где-то на дисках в другой ноде.
Самым распространённым фактором репликации является 3 — это значит, что база данных хранит три копии каждого фрагмента данных на разных дисках, подключенных к трём разным компьютерам. Объяснение этому примерно такое: диски выходят из строя редко. Если диск вышел из строя, то есть время заменить его, и в это время у вас ещё две копии, с которых можно восстановить данные на новый диск. Риск выхода из строя второго диска, пока вы восстанавливаете первый, достаточно низок, а вероятность смерти всех трёх дисков одновременно настолько мала, что более вероятно погибнуть от попадания астероида.
Прикинем на салфетке: если вероятность сбоя одного диска в определённый период времени составляет 0,1% (чтобы выбрать произвольное число), тогда вероятность выхода из строя двух дисков составляет (0,001)2=10-6, а вероятность сбоя трёх дисков составляет (0,001)3=10-9, или один на миллиард. Эти вычисления предполагают, что сбои дисков происходят независимо друг от друга — что в реальности не всегда правда, например, диски из одной партии от одного производителя могут иметь схожие дефекты. Но для наших приближённых вычислений сойдёт.
Пока что торжествует здравый смысл. Звучит разумно, но, к сожалению, для многих систем хранения данных это не работает. В статье я покажу, почему так.
Так легко потерять данные, ла-ла-лааа
Если ваш кластер базы данных действительно состоит всего из трёх машин, то вероятность одновременного выхода из строя всех трёх действительно очень мала (если не считать коррелированные сбои, такие как пожар в дата-центре). Однако если вы переходите на кластеры большего размера, то вероятности изменяются. Чем больше нодов и дисков в вашем кластере, тем больше вероятность потери данных.
Это контринтуинтивная мысль. «Конечно, — подумаете вы, — каждый фрагмент данных по-прежнему реплицируется на трёх дисках. Вероятность сбоя диска не зависит от размера кластера. Так почему размер кластера имеет значение?» Но я рассчитал вероятности и начертил график, который выглядит так:
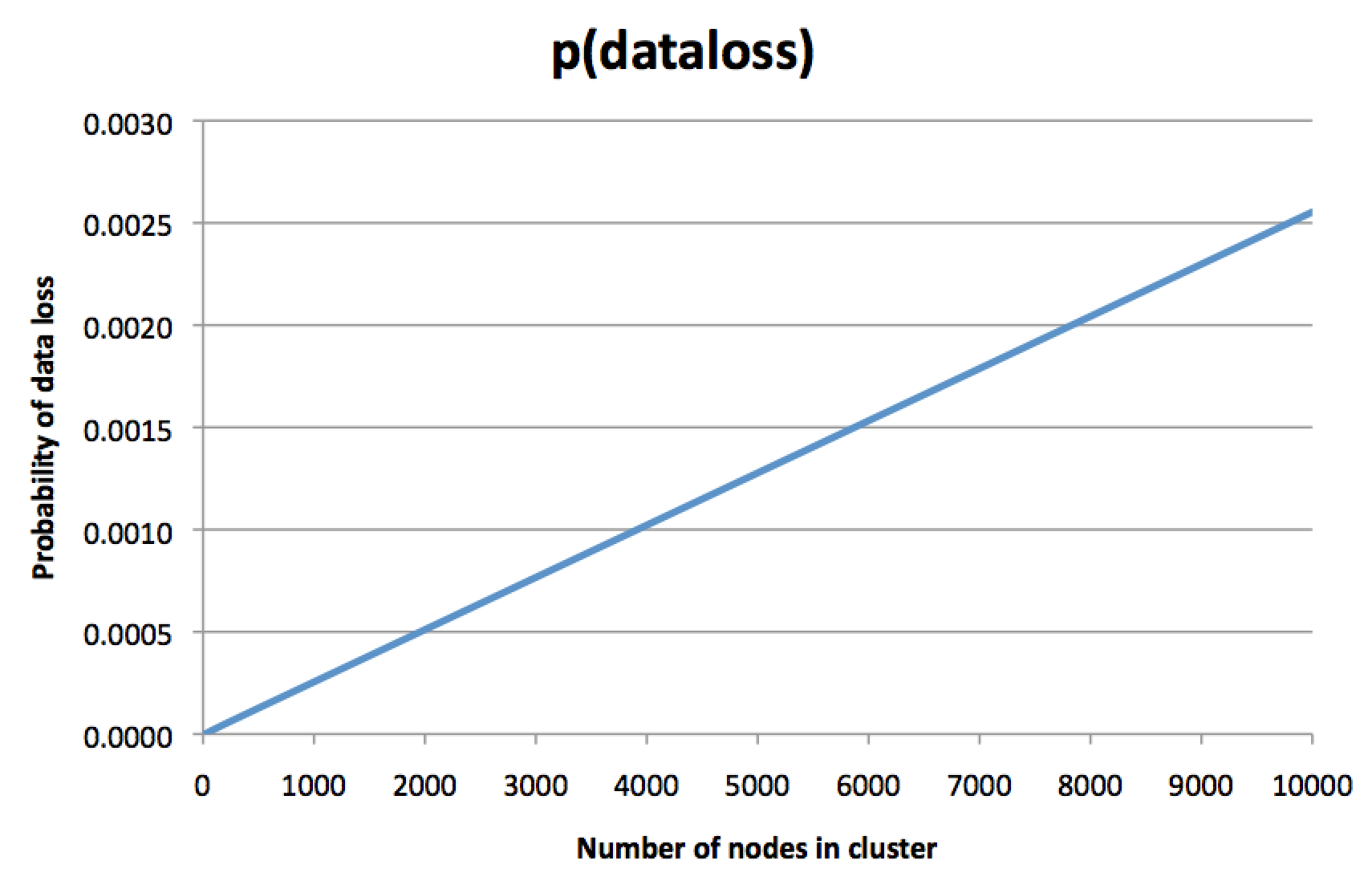
Для ясности, здесь указана не вероятность сбоя одной ноды, а вероятность необратимой потери трёх реплик какого-то фрагмента данных, так что восстановление из резервной копии (если она у вас есть) останется единственной возможностью восстановить данные. Чем больше кластер, тем более вероятна потеря данных. Наверное, вы на такое не рассчитывали, когда решили заплатить за фактор репликации 3.
На этом графике ось y слегка произвольная и зависит от многих допущений, но само направление графика пугает. Если предположить, что у ноды шанс сбоя 0,1% за некий период времени, то график показывает, что в кластере из 8000 нод шанс необратимой потери всех трёх реплик для какого-то фрагмента данных (за один и тот же период времени) составляет около 0,2%. Да, вы прочитали правильно: риск потери всех трёх копий данных почти вдвое выше, чем риск потери одной ноды! В чём тогда смысл репликации?
Интуитивно этот график можно интерпретировать следующим образом: в кластере на 8000 нод почти наверняка несколько нод всегда мёртвые в каждый момент времени. Это нормально и не является проблемой: определённый уровень сбоев и замены нод предполагался как часть рутинного обслуживания. Но если вам не повезло, то существует какой-то фрагмент данных, для которого все три реплики вошли в число тех нод, которые сейчас являются мёртвыми — и если такое произошло, то ваши данные потеряны навсегда. Потерянные данные составляют только малую часть всего набора данных в кластере, но это всё равно плохие новости, ведь при использовании фактора репликации 3 вы обычно думаете «Я вообще не хочу терять данные», а не «Меня не заботит периодическая потеря небольшого количества данных, если их немного». Может, в этом конкретном фрагменте потерянных данных действительно важная информация.
Вероятность того, что все три реплики принадлежат к числу мёртвых нод, кардинально зависит от алгоритма, который использует система для распределения данных по репликам. График вверху рассчитан с предположением, что данные распределены по разделам (шардам), и каждый раздел хранится на трёх случайно выбранных нодах (или псевдослучайно с хэш-функцией). Это случай последовательного хэширования, который применяется в Cassandra и Riak, среди прочих (насколько мне известно). Я не уверен, как работает назначение реплик в других системах, так что буду благодарен за подсказки тех, кто знает особенности работы различных систем хранения данных.
Вычисление вероятности потери данных
Позвольте показать, как я рассчитал верхний график, используя вероятностную модель реплицированной базы данных.
Предположим, что вероятность потери отдельной ноды составляет . Мы игнорируем время в этой модели, и просто смотрим на вероятность сбоя в некий произвольный промежуток времени. Например, может предположить, что — это вероятность сбоя ноды в определённый день, что имеет смысл, если примерно один день требуется для замены ноды и восстановления потерянных данных на новые диски. Для простоты я не буду проводить разницу между сбоем ноды и сбоем диска, а буду учитывать только необратимые сбои (игнорируя сбои, когда нода возвращается в строй после перезагрузки).
Пусть будет количеством нод в кластере. Тогда вероятность того, что из нод вышло из строя (предполагая, что сбои независимы друг от друга), соответствует биномиальному распределению:
Член — это вероятность, что нод вышло из строя, член — вероятность, что оставшиеся остались в строю, а — это количество различных способов выбора из нод. интерпретируется как количество сочетаний из по . Этот биномиальный коэффициент вычисляется как:
Пусть будет фактором репликации (обычно ). Если предположить, что из нод вышли из строя, какова вероятность, что конкретный раздел имеет все своих реплик на вышедших из строя нодах?
Ну, в системе с последовательным хэшированием каждый раздел назначается нодам независимым и случайным (или псевдослучайным) образом. Для данного раздела существует различных способов назначения реплик нодам, и все эти назначения могут случиться с одинаковой вероятностью. Более того, существует различных способов выбора реплик из вышедших из строя нод — это способы, при которых все реплик могут быть назначены вышедшим из строя нодам. Теперь рассчитаем ту часть назначений, которая приводит к выходу из строя всех реплик:
(Вертикальная черта после “partition lost” означает «при условии» и указывает на условную вероятность: вероятность дана при предположении, что нод вышло из строя).
Итак, вот вероятность, что все реплики одного конкретного раздела потеряны. Что насчёт кластера с разделами? Если один или более разделов потеряны, мы теряем данные. Поэтому, чтобы не потерять данные, нужно, чтобы все разделов не были потеряны:
Cassandra и Riak называют разделы как vnodes, но это то же самое. В целом, количество разделов не зависит от количества нод . В случае с Cassandra обычно имеется фиксированное количество разделов на ноде; по умолчанию (устанавливается параметром
num_tokens), и это ещё одно допущение, которое я сделал для графика вверху. В Riak количество разделов фиксируется при создании кластера, но обычно чем больше нод — тем больше разделов.Собрав всё в одно место, мы теперь можем вычислить вероятность потери одного или больше разделов в кластере размером с фактором репликации . Если число сбоев меньше, чем фактор репликации, то мы можем быть уверены, что никакие данные не потеряны. Поэтому следует добавить вероятности для всех возможных значений по количеству сбоев с :
Это слегка чрезмерная, но, мне кажется, точная оценка. И если вы подставите , и и проверите значения от 3 до 10000, то получите график вверху. Я написал небольшую программу на Ruby для этого вычисления.
Можно получить более простое приближение, используя границу объединения:
Даже если сбой одного раздела не является независимым от сбоя другого раздела, такое приближение всё ещё применимо. И кажется, что оно довольно близко соответствует точному результату: на графике вероятность потери данных выглядит как прямая линия, пропорционально количеству нод.
Приближение говорит, что эта вероятность пропорциональна количеству разделов, что то же самое исходя из фиксированного числа 256 разделов на ноду.
Более того, если мы подставим количество 10000 нод в приближение, то получим , что близко соответствует результату из программы Ruby.
А на практике...?
Является ли это проблемой на практике? Не знаю. В основном я думаю, что это интересный контринтуитивный феномен. До меня доходили слухи, что это привело к реальном потере данных в компаниях с большими кластерами баз данных, но я не видел, чтобы проблема была где-то задокументирована. Если вам известно о дискуссиях на эту тему, пожалуйста, покажите мне.
Вычисления показывают, что для снижения вероятности потери данных следует уменьшить количество разделов или увеличить фактор репликации. Использование большего количества реплик стоит денег, так что это не идеальное решение для больших кластеров, которые и так дорогие. Однако изменение количества разделов представляет интересный компромисс. Cassandra изначально использовала один раздел на ноду, но несколько лет назад переключилась на 256 разделов на ноду, чтобы достичь лучшего распределения нагрузки и более эффективного восстановления баланса. Обратной стороной, как можно видеть из вычислений, стала гораздо более высокая вероятность потери хотя бы одного из разделов.
Думаю, что возможно разработать алгоритм назначения реплик, в котором вероятность потери данных не растёт с размером кластера или хотя бы не растёт так быстро, но где в то же время сохраняются свойства хорошего распределения нагрузки и восстановления баланса. Это было бы интересной областью дальнейшего исследования. В данном контексте мой коллега Стефан обратил внимание, что ожидаемая скорость потери данных остаётся неизменной в кластере определённого размера, независимо от алгоритма назначения реплик — другими словами, вы можете выбрать между высокой вероятностью потери малого количества данных и низкой вероятностью потери большого количества данных! Думаете, второй вариант лучше?
Вам нужны действительно большие кластеры, прежде чем этот эффект действительно проявит себя, но кластеры из тысяч нод используются в разных больших компаниях, так что было бы интересно услышать людей с опытом работы на таком масштабе. Если вероятность необратимой потери данных в кластере из 10000 нод действительно 0,25% в день, это означает 60% вероятность потери данных в год. Это намного больше, чем шанс «один из миллиарда» погибнуть-от-астероида, о котором я говорил в начале.
Знают ли о проблеме архитекторы распределённых систем данных? Если я правильно понимаю, тут кое-что следует учитывать при проектировании схем репликации. Возможно, этот пост привлечёт внимание к тому факту, что просто наличие трёх реплик не даёт вам чувствовать себя в безопасности.
Комментарии (13)

starius
30.03.2017 06:41примерно один день требуется для замены ноды и восстановления потерянных данных на новые диски
Так можно копировать данные сразу на какую-нибудь другую ноду, не дожидаясь починки вылетевшей ноды. Хотя это скорее деталь, которая не должна сказаться на характере зависимости.
А по поводу самой вероятности потери данных. Как я понял, если мы будем для каждого куска данных выбирать наугад три ноды, то начинается комбинаторика и вероятность потери хотя бы одного куска большая. А что будет, если ноды будут "стремиться" хранить одни и те же куски? То есть, скажем если кусок1 попал на ноды 1, 2, 3 и кусок2 попал на ноду 1, то он так же попал и на ноду 2 и ноду 3. То есть по сути на данных трёх нодах будет одинаковый набор кусков, на других трёх нодах — другой набор кусков, но тоже одинаковый. Интуиция подсказывает, что так мы избавимся от комбинаторики и вероятность потери хотя бы одного куска снизится.
Часто данные в кластерах хранят с использованием кодов Рида — Соломона. Краем уха я слышал, что вероятность потери куска данных в этом случае ниже, чем в случае с тройной репликацией, и места они сжирают сильно меньше. Согласуется ли это с вашими расчётами?

D_T
30.03.2017 09:34+2Так можно копировать данные сразу на какую-нибудь другую ноду, не дожидаясь починки вылетевшей ноды. Хотя это скорее деталь, которая не должна сказаться на характере зависимости.
ИМХО нужно копировать на другие ноды. Т.к. по изначальной постановке каждый кусок данных всегда в 3-х экземплярах.
Если это соблюдать, то умирание ноды должно вызывать автоматическое создание копии данных, которые на ней были, в других нодах.
Если будет так, то без разницы сколько нод в кластере и график вырождается в горизонтальную линию.
Как оно на практике — не знаю, не сталкивался. У любой автоматики есть своя цена.vesper-bot
30.03.2017 10:46Было бы логично включать авторепликацию блока на другую (живую) ноду кластера при потере одной из трех нод, хранящих этот блок. Правда, тогда расходы на репликацию данных по такому алгоритму будут расти квадратично от количества нод в кластере при постоянной вероятности выхода одной ноды из строя.

facha
30.03.2017 12:44Думаю, автор не принял во внимание, что так оно все и работает. Т.е. нужно было оценивать вероятность выхода из строя двух оставшихся реплик в течение времени, пока авторепликация еще не завершена.
DaylightIsBurning
30.03.2017 11:04Не понимаю, что тут неочевидного. Чем больше кластер, тем больше данных, чем больше данных — тем больше с ними манипуляций в единицу времени. При постоянной вероятности ошибки одной операции и линейном росте количества операций естественно, что шанс хотя бы одной ошибки растет также линейно. В данном случае ошибка — это отказ сразу трех дисков. Представьте себе, что три диска — это один диск, вероятность отказа которого равна вероятности отказа всех трех дисков за время создание одной полной реплики. Чем больше таких "тридисков" — тем выше шанс отказа одного из них. И разбиение на меньшие кластеры не поможет, так как вероятности отказа одного тридиска в в двух кластерах половинного размера и одном кластере единичного равны.
DaylightIsBurning
30.03.2017 11:08Вероятность потери любой конкретной порции данных при этом от размера кластера не зависит, что вполне соответствует интуиции. Ну во всяком случае если как причину отказа мы рассматриваем только сбои отдельных дисков.
mickvav
30.03.2017 14:25+2У вас ключевая проблема — это то, что вы считаете время восстановления фактора репликации == 3 не зависящим от числа нод. В реальности, если у вас большой кластер с нормальной матрицей коммутации, то это время обратно пропорционально числу нод — если сразу после падения ноды те машины, на которых лежат резервные копии отдельных шардов (а это можно считать, что все машины кластера!), начинают куда-то лить данные (на случайные узлы, опять же, то есть на все машины, опять же) — время, в течение которого фактор репликации снизится до 2-х уменьшится пропорционально числу узлов, а значит (в случайной модели отмирания узлов) — и вероятность умирания тоже уменьшится пропорционально числу узлов. Так что время — важный параметр, зря вы его выкинули.
DaylightIsBurning
30.03.2017 20:54время восстановления потерянной реплики (в идеале) не зависит от числа узлов т.к. упирается в скорость чтения с двух оставшихся реплик.
muon
Занятно, но есть один нюанс.
> Потерянные данные составляют только малую часть всего набора данных в кластере
Изменение размера данных меняет дело. Если считать, что и маленький, и большой кластеры собраны из одинаковых нод по N Гбайт, то в большом ребилд N Гбайт (при потере ноды) занимает примерно в P раз меньше времени (если в большом в P раз больше нод). И вероятность отказа второй ноды за время ребилда будет уже не 0,1%, а 0,1%/P, что резко просаживает правую часть графика.
DaylightIsBurning
Время ребилда не может быть меньше чем время считывания с оставшихся двух реплик, что от размеров кластера не зависит.
muon
Не могу согласиться.
Схема репликации «нода целиком на две других ноды» наивна и устарела вместе с ранними версиями DRBD. Но даже если так, то время ребилда будет определяться не скорость считывания с оставшихся двух нод, а скоростью записи на новую.
В современном мире на каждой ноде хранится несколько кусков данных (в Ceph, например, куски называются placement group, PG), реплики каждого куска находятся на своей паре нод, то есть теоретически реплики данных равномерно размазаны по всему кластеру. На практике они равномерно размазываются, пока количество нод (в терминологии Ceph ближайший синоним — OSD) не станет сильно больше количества PG на одном OSD.
Про зависимость вероятности потери данных от количества нод уже подумано и написано в документации.
DaylightIsBurning
Скорость считывания имеющегося деградировавшего куска увеличить нельзя, а запись можно временно на быстрый буфер делать (а потом перенести на более медленное хранилище), так что фундаментально скорость чтения важнее.
не важно, вся ли нода восстанавливается или диск или кусок. Если падает один жесткий диск, то нужно восстановить все фрагменты которые на нём были с других дисков. Пусть число фрагментов на диск равно Х. Число операций восстановления которые нужно произвести равно Х. Каждая операция длится Т. Шанс падения во время восстановления пропорционален 1/Т и для отдельного фрагмента не зависит от числа нод. Вероятность того, что хотя бы одна из операций восстановления упадёт пропорционален Х/Т и тоже не зависит от числа нод. При этом не важно, на одном диске лежат «вторые» копии Х или на разных. Ошибка восстановления тут — пуассоновский процесс. Шанс отказа для маленькой порции мал, но порций много, так что в среднем одно и то же.
Всё просто, существует вероятность необратимой ошибки чтения, которая обычно тем выше чем больше кусок. Однако чем больше кусок, тем меньше их надо что бы обеспечить тот же объем данных. Вероятность потери данных на совсем равна вероятности трех(степень репликации) последовательных отказов. Каждое считывание может закончится отказом. Чем больше нод, тем больше считываний (степень загрузки считаем неизменной).
muon
Мне незнакомы промышленные системы с кэшем больше самого хранилища. In-memory — да, но и в них упрётся в запись. Ну пусть будет чтение, не принципиально.
Я не понял, мы делим единицу на время и получаем что-то в герцах? Может, здесь 1/X? По существу соглашусь, второй диск может сломаться с вероятностью независимой от количества нод.Но в статье про RF=3, для потери данных нужно сломать два диска, вероятность чего пропорциональна 1/X^2, что снижает вероятность потери относительно линейной графика в статье.
И относительно маленького кластера, да.