
Недавний отчет Google об устройстве и назначении TPU позволяет сделать однозначный вывод — без ускоренных вычислений серьезное развертывание системы ИИ просто нецелесообразно.
Большинство необходимых экономических вычислений во всем мире сегодня производится в мировых центрах обработки данных, а они с каждым годом все сильнее изменяются. Не так давно они обслуживали веб-страницы, распространяли рекламу и видеоконтент, а теперь распознают голос, идентифицируют изображение в видеопотоках и предоставляют нужную информацию именно в тот момент, когда она нам нужна.

Все чаще эти возможности активируются с помощью одной из форм искусственного интеллекта, т.н. «глубокого обучения». Это алгоритм, который учится на огромных объемах данных для создания систем, решающих такие задачи, как перевод с разных языков, диагностирование рака и обучение беспилотных автомобилей. Перемены, привносимые искусственным интеллектом в нашу жизнь, ускоряются невиданными в отрасли темпами.
Один из исследователей глубокого обучения, Джеффри Хинтон, недавно сказал в интервью «The New Yorker»: «Возьмите любую старую классификационную проблему, в которой у вас много данных, и она будет решена путем «глубокого обучения». У нас на подходе тысячи разных приложений на базе «глубокого обучения».
Посмотрите на Google. Применение новаторских исследований в глубоком обучении в их исполнении привлекло внимание всего мира: поразительная точность сервиса Google Now; знаменательная победа над величайшим в мире игроком в го; способность Google Translate работать на 100 различных языках…
«Глубокое обучение» достигло беспрецедентно эффективных результатов. Но этот подход требует, чтобы компьютеры обрабатывали огромные объемы данных именно в тот момент, в который закон Мура замедляется. «Глубокое обучение» — это новая вычислительная модель, которая требует изобретения новой вычислительной архитектуры.
Эту нишу некоторое время занимала NVIDIA. В 2010 году Дан Цирезан (Dan Ciresan), исследователь швейцарской лаборатории AI имени профессора Юргена Шмидхубера, обнаружил, что GPU NVIDIA могут использоваться для глубокого обучения нейронных сетей с ускорением в 50 раз по сравнению с CPU. Год спустя лаборатория Шмидхубера использовала графические процессоры для разработки первых нейронных сетей на основе «глубокого обучения», которые выигрывали международные конкурсы по распознаванию рукописного текста и компьютерному зрению.
Затем, в 2012 году, Алекс Крижевский (Alex Krizhevsky), тогдашний студент Университета Торонто, выиграл ныне знаменитый ежегодный конкурс ImageNet по распознаванию образов, используя пару графических процессоров. (Шмидхубер запечатлел всеобъемлющую историю влияния «глубокого обучения» с использованием GPU на современное компьютерное зрение).
Исследователи ИИ по всему миру обнаружили, что вычислительная модель NVIDIA, первоначально предназначенная для графических ускорителей и суперкомпьютеров идеально подходит для «глубокого обучения». Это, как и 3D-графика, обработка и графическое моделирование изображений в медицине, молекулярная динамика, квантовая химия и симуляция погоды, — алгоритм линейной алгебры, который массово использует параллельное вычисление тензоров или многомерных векторов. И хотя графический процессор NVIDIA Kepler, разработанный в 2009 году, открыл миру возможность использования графического ускорителя для вычислений в задачах «глубокого обучения», он никогда не был специально оптимизирован для этой задачи.

Мы решили это исправить, развивая новые поколения архитектуры GPU, сначала Maxwell, а затем Pascal, которые включали в себя множество новых архитектурных разработок, оптимизированных под «глубокое обучение». Представленная всего через четыре года после KIepler модель Tesla K80, наш основанный на Pascal ускоритель Tesla P40 Inferencing Accelerator, обеспечивает 26-кратное увеличение производительности, значительно опережая закон Мура.
В течение этого времени Google разработал специальный чип ускорителя, называемый тензорным процессором, или TPU, заточенный под функцию выдачи готового результата. Его-то корпорация и ввела в эксплуатацию в 2015 году.
Не так давно команда Google опубликовала техническую информацию о преимуществах TPU. Они утверждают, среди прочего, что TPU имеет 13-кратное превосходство над K80, но не сравнивает TPU с текущим поколением P40 на основе Pascal.
Чтобы обновить сравнение Google, для количественного определения скачка производительности с K80 по P40 и для демонстрации того, как TPU сравнивается с текущей технологией NVIDIA, мы создали таблицу, приведенную ниже.
P40 сочетает вычислительную точность и пропускную способность, встроенную память и полосу пропускания памяти, чтобы достичь беспрецедентной производительности как для задачи обучения, так и для выдачи готового результата. Для обучения P40 имеет десятикратную пропускную способность и 12 терафлоп производительности 32-разрядных вычислений с плавающей запятой. Для выдачи готового результата P40 имеет высокую производительность для операций с восьмибитными целыми числами и высокую пропускную способность памяти.
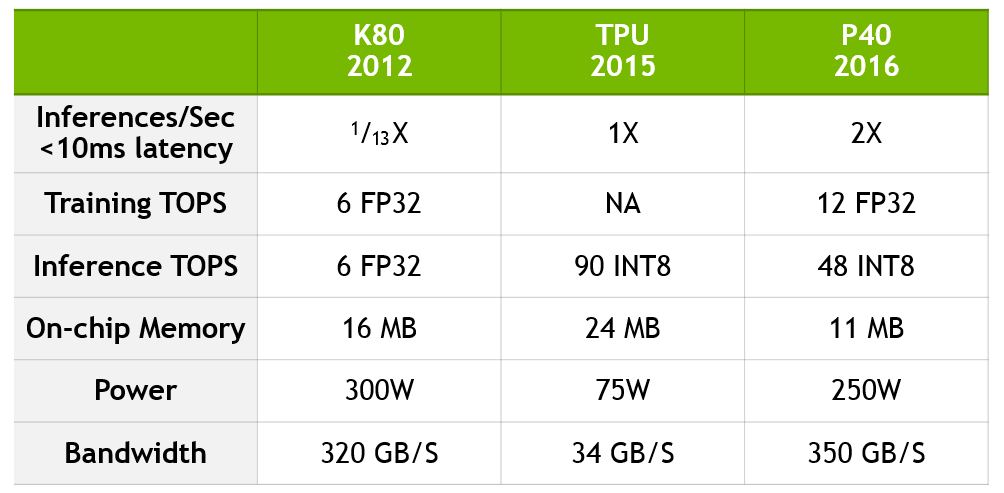
Данные основаны на отчете “In-Datacenter Performance Analysis of a Tensor Processing Unit” Jouppi et al [Jou17] и собственных данных NVIDIA. Коэффициенты производительности K80-TPU основаны на среднем коэффициенте ускорения CNN0 и CNN1 из отчета Google, который сравнивает производительность с полуготовым K80. Коэффициенты производительности K80-P40 основаны на GoogLeNet, общедоступной модели CNN с аналогичными характеристиками производительности.
В то время как Google и NVIDIA выбрали разные пути развития, есть несколько общих для этих подходов тем:
Мир компьютерных технологий переживает историческую трансформацию, которая уже упоминается как революция ИИ. Сегодня его влияние очевиднее всего в крупных дата-центрах — Alibaba, Amazon, Baidu, Facebook, Google, IBM, Microsoft, Tencent и других. Им необходимо наращивать рабочие нагрузки для ИИ, не тратя миллиарды долларов на строительство и электроснабжение новых центров обработки данных без использование специализированных технологий. Без ускоренных вычислений масштабное развитие и внедрение систем ИИ практически невозможно.
Большинство необходимых экономических вычислений во всем мире сегодня производится в мировых центрах обработки данных, а они с каждым годом все сильнее изменяются. Не так давно они обслуживали веб-страницы, распространяли рекламу и видеоконтент, а теперь распознают голос, идентифицируют изображение в видеопотоках и предоставляют нужную информацию именно в тот момент, когда она нам нужна.
Все чаще эти возможности активируются с помощью одной из форм искусственного интеллекта, т.н. «глубокого обучения». Это алгоритм, который учится на огромных объемах данных для создания систем, решающих такие задачи, как перевод с разных языков, диагностирование рака и обучение беспилотных автомобилей. Перемены, привносимые искусственным интеллектом в нашу жизнь, ускоряются невиданными в отрасли темпами.
Один из исследователей глубокого обучения, Джеффри Хинтон, недавно сказал в интервью «The New Yorker»: «Возьмите любую старую классификационную проблему, в которой у вас много данных, и она будет решена путем «глубокого обучения». У нас на подходе тысячи разных приложений на базе «глубокого обучения».
Беспрецедентная эффективность
Посмотрите на Google. Применение новаторских исследований в глубоком обучении в их исполнении привлекло внимание всего мира: поразительная точность сервиса Google Now; знаменательная победа над величайшим в мире игроком в го; способность Google Translate работать на 100 различных языках…
«Глубокое обучение» достигло беспрецедентно эффективных результатов. Но этот подход требует, чтобы компьютеры обрабатывали огромные объемы данных именно в тот момент, в который закон Мура замедляется. «Глубокое обучение» — это новая вычислительная модель, которая требует изобретения новой вычислительной архитектуры.
Эту нишу некоторое время занимала NVIDIA. В 2010 году Дан Цирезан (Dan Ciresan), исследователь швейцарской лаборатории AI имени профессора Юргена Шмидхубера, обнаружил, что GPU NVIDIA могут использоваться для глубокого обучения нейронных сетей с ускорением в 50 раз по сравнению с CPU. Год спустя лаборатория Шмидхубера использовала графические процессоры для разработки первых нейронных сетей на основе «глубокого обучения», которые выигрывали международные конкурсы по распознаванию рукописного текста и компьютерному зрению.
Затем, в 2012 году, Алекс Крижевский (Alex Krizhevsky), тогдашний студент Университета Торонто, выиграл ныне знаменитый ежегодный конкурс ImageNet по распознаванию образов, используя пару графических процессоров. (Шмидхубер запечатлел всеобъемлющую историю влияния «глубокого обучения» с использованием GPU на современное компьютерное зрение).
Оптимизация для «глубокого обучения»
Исследователи ИИ по всему миру обнаружили, что вычислительная модель NVIDIA, первоначально предназначенная для графических ускорителей и суперкомпьютеров идеально подходит для «глубокого обучения». Это, как и 3D-графика, обработка и графическое моделирование изображений в медицине, молекулярная динамика, квантовая химия и симуляция погоды, — алгоритм линейной алгебры, который массово использует параллельное вычисление тензоров или многомерных векторов. И хотя графический процессор NVIDIA Kepler, разработанный в 2009 году, открыл миру возможность использования графического ускорителя для вычислений в задачах «глубокого обучения», он никогда не был специально оптимизирован для этой задачи.
Мы решили это исправить, развивая новые поколения архитектуры GPU, сначала Maxwell, а затем Pascal, которые включали в себя множество новых архитектурных разработок, оптимизированных под «глубокое обучение». Представленная всего через четыре года после KIepler модель Tesla K80, наш основанный на Pascal ускоритель Tesla P40 Inferencing Accelerator, обеспечивает 26-кратное увеличение производительности, значительно опережая закон Мура.
В течение этого времени Google разработал специальный чип ускорителя, называемый тензорным процессором, или TPU, заточенный под функцию выдачи готового результата. Его-то корпорация и ввела в эксплуатацию в 2015 году.
Не так давно команда Google опубликовала техническую информацию о преимуществах TPU. Они утверждают, среди прочего, что TPU имеет 13-кратное превосходство над K80, но не сравнивает TPU с текущим поколением P40 на основе Pascal.
Обновление сравнения от Google
Чтобы обновить сравнение Google, для количественного определения скачка производительности с K80 по P40 и для демонстрации того, как TPU сравнивается с текущей технологией NVIDIA, мы создали таблицу, приведенную ниже.
P40 сочетает вычислительную точность и пропускную способность, встроенную память и полосу пропускания памяти, чтобы достичь беспрецедентной производительности как для задачи обучения, так и для выдачи готового результата. Для обучения P40 имеет десятикратную пропускную способность и 12 терафлоп производительности 32-разрядных вычислений с плавающей запятой. Для выдачи готового результата P40 имеет высокую производительность для операций с восьмибитными целыми числами и высокую пропускную способность памяти.
Данные основаны на отчете “In-Datacenter Performance Analysis of a Tensor Processing Unit” Jouppi et al [Jou17] и собственных данных NVIDIA. Коэффициенты производительности K80-TPU основаны на среднем коэффициенте ускорения CNN0 и CNN1 из отчета Google, который сравнивает производительность с полуготовым K80. Коэффициенты производительности K80-P40 основаны на GoogLeNet, общедоступной модели CNN с аналогичными характеристиками производительности.
В то время как Google и NVIDIA выбрали разные пути развития, есть несколько общих для этих подходов тем:
- ИИ требует ускоренного вычисления. Специализированные ускорители обеспечивают значительную часть обработки данных, необходимую, чтобы не отставать от растущих требований «глубокого обучения» в эпоху, когда закон Мура замедляется.
- Тензорная обработка лежит в основе обеспечения производительности для глубокого обучения и выдачи готовых результатов.
- Тензорная обработка — это важная новая рабочая нагрузка, которую предприятия должны учитывать при создании современных центров обработки данных.
- Ускорение обработки тензоров может значительно снизить стоимость создания современных дата-центров.
Мир компьютерных технологий переживает историческую трансформацию, которая уже упоминается как революция ИИ. Сегодня его влияние очевиднее всего в крупных дата-центрах — Alibaba, Amazon, Baidu, Facebook, Google, IBM, Microsoft, Tencent и других. Им необходимо наращивать рабочие нагрузки для ИИ, не тратя миллиарды долларов на строительство и электроснабжение новых центров обработки данных без использование специализированных технологий. Без ускоренных вычислений масштабное развитие и внедрение систем ИИ практически невозможно.
Поделиться с друзьями
leshabirukov
Насколько я понимаю, TPU, — весьма специализированное устройство, оно умеет только перемножать большие матрицы восьмибитных целых в режиме data flow, но зато делает это эффективно. NVidia с её универсальным железом будет трудно держаться вровень с такой сырой мощью.
Chugumoto
ну как бэ да. асики — узкоспециализированные устройства. зато, как видим из таблички, на INT8 преимущество по скорости в 2 раза, а по энергопотреблению все 3… итого при одном и том же энергопотреблении разница в скорости в 6 раз не в пользу нвидии… хотя с другой стороны теслы то можно перенастроить на любой другой алгоритм позже, а вот асики — нет. только выбросить и заменить другими…
kharlashkin
Есть ещё вопрос ценообразования, возможно выбросить и заменить дешевле чем перенастроить :)
Chugumoto
ну… новые асики разработать, изготовить, и софт написать… с теслами же только софт написать… думаете замена асиков обойдется дешевле? :)
kharlashkin
Как бы Google по каким-то причинам решили заморочится, а не покупать решение у Nvidia. Причин может быть огромное количество.
leshabirukov
Перемножение матриц очень много где можно использовать.
«Модуль» (я тут работаю) в 1998 выпустил первый NeuroMatrix, с говорящим названием. Тогда бум НС сдулся, но чип выбрасывать не пришлось, он и его потомки вполне востребованы в цифровой обработке сигналов.